जैसे-जैसे रोब्लॉक्स पिछले 16+ वर्षों में विकसित हुआ है, वैसे-वैसे तकनीकी बुनियादी ढांचे का पैमाना और जटिलता भी बढ़ी है जो लाखों इमर्सिव 3डी सह-अनुभवों का समर्थन करता है। हमारे द्वारा समर्थित मशीनों की संख्या पिछले दो वर्षों में तीन गुना से अधिक हो गई है, जो 36,000 जून, 30 तक लगभग 2021 से बढ़कर आज लगभग 145,000 हो गई है। दुनिया भर के लोगों के लिए हमेशा चालू रहने वाले इन अनुभवों का समर्थन करने के लिए 1,000 से अधिक आंतरिक सेवाओं की आवश्यकता होती है। लागत और नेटवर्क विलंबता को नियंत्रित करने में हमारी मदद करने के लिए, हम इन मशीनों को एक कस्टम-निर्मित और हाइब्रिड निजी क्लाउड इंफ्रास्ट्रक्चर के हिस्से के रूप में तैनात और प्रबंधित करते हैं जो मुख्य रूप से परिसर में चलती है।
हमारा बुनियादी ढांचा वर्तमान में दुनिया भर में 70 मिलियन से अधिक दैनिक सक्रिय उपयोगकर्ताओं का समर्थन करता है, जिसमें रोबॉक्स पर भरोसा करने वाले निर्माता भी शामिल हैं। अर्थव्यवस्था उनके व्यवसायों के लिए. ये सभी लाखों लोग बहुत उच्च स्तर की विश्वसनीयता की अपेक्षा करते हैं। हमारे अनुभवों की व्यापक प्रकृति को देखते हुए, अंतराल या विलंबता के लिए बहुत कम सहनशीलता है, आउटेज की तो बात ही छोड़ दें। रोबॉक्स संचार और कनेक्शन के लिए एक मंच है, जहां लोग गहन 3डी अनुभवों में एक साथ आते हैं। जब लोग अपने अवतारों के रूप में एक गहन स्थान पर संचार कर रहे होते हैं, तो मामूली देरी या गड़बड़ियां भी टेक्स्ट थ्रेड या कॉन्फ़्रेंस कॉल की तुलना में अधिक ध्यान देने योग्य होती हैं।
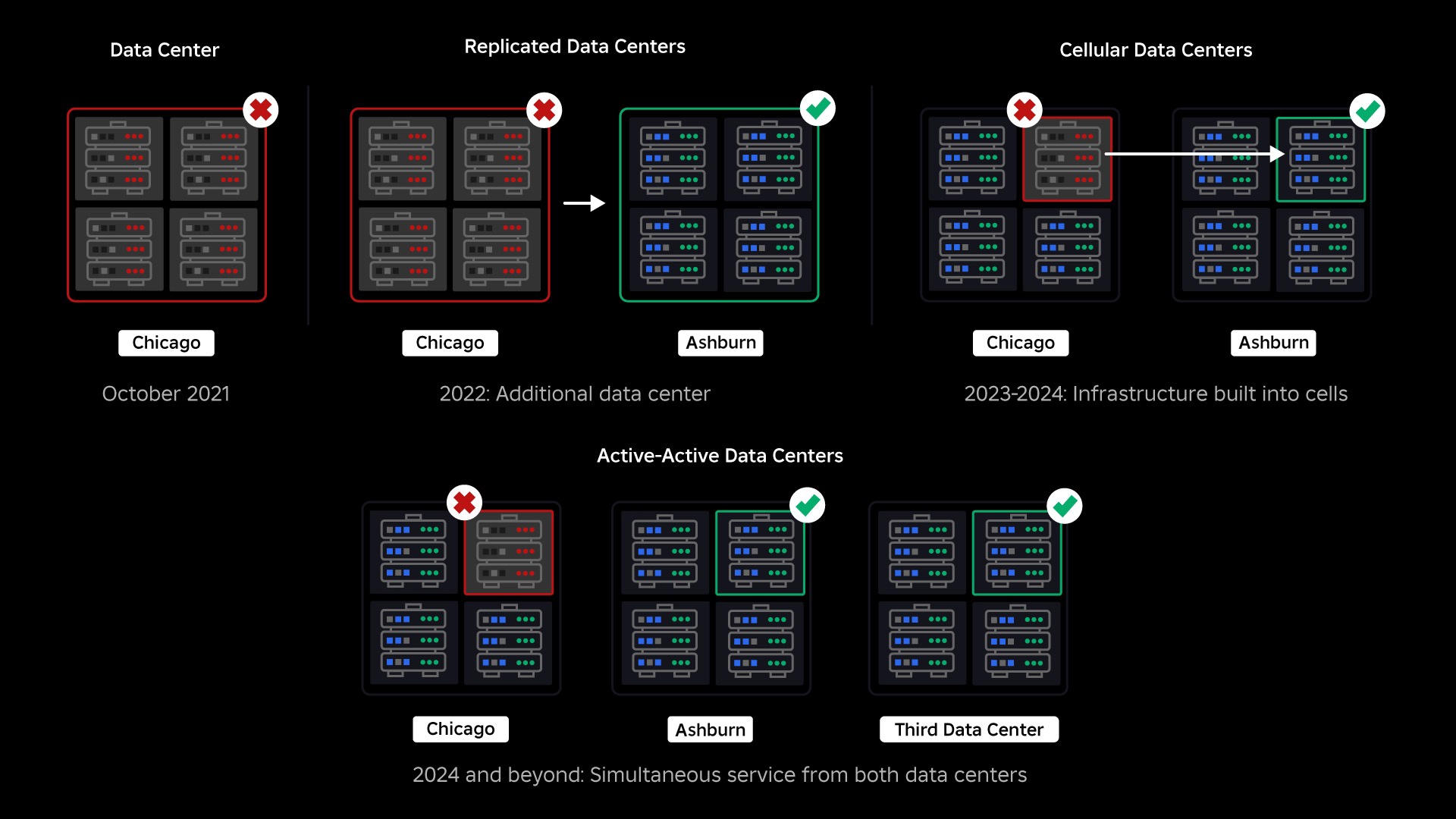
अक्टूबर, 2021 में, हमने सिस्टम-व्यापी आउटेज का अनुभव किया। इसकी शुरुआत छोटे पैमाने पर हुई, एक डेटा सेंटर में एक घटक में समस्या के साथ। लेकिन जब हम जांच कर रहे थे तो यह तेजी से फैल गया और अंततः 73 घंटे की रुकावट आ गई। उस समय, हमने दोनों को साझा किया क्या हुआ इसके बारे में विवरण और इस मुद्दे से हमारी कुछ शुरुआती सीख। तब से, हम उन सीखों का अध्ययन कर रहे हैं और अत्यधिक ट्रैफ़िक स्पाइक्स, मौसम, हार्डवेयर विफलता, सॉफ़्टवेयर बग, या बस जैसे कारकों के कारण सभी बड़े पैमाने के सिस्टम में होने वाली विफलताओं के प्रकार के लिए अपने बुनियादी ढांचे की लचीलापन बढ़ाने के लिए काम कर रहे हैं। इंसान गलतियाँ कर रहा है. जब ये विफलताएं होती हैं, तो हम यह कैसे सुनिश्चित करते हैं कि किसी एक घटक या घटकों के समूह में कोई समस्या पूरे सिस्टम में न फैल जाए? यह प्रश्न पिछले दो वर्षों से हमारा ध्यान केंद्रित रहा है और जबकि काम जारी है, हमने अब तक जो किया है उसका फल पहले से ही मिल रहा है। उदाहरण के लिए, 2023 की पहली छमाही में, हमने 125 की पहली छमाही की तुलना में प्रति माह 2022 मिलियन जुड़ाव घंटे बचाए। आज, हम अपने पहले से किए गए काम को साझा कर रहे हैं, साथ ही निर्माण के लिए अपनी दीर्घकालिक दृष्टि भी साझा कर रहे हैं। एक अधिक लचीली बुनियादी ढांचा प्रणाली।
बैकस्टॉप का निर्माण
बड़े पैमाने की बुनियादी ढांचा प्रणालियों के भीतर, छोटे पैमाने पर विफलताएं दिन में कई बार होती हैं। यदि एक मशीन में कोई समस्या है और उसे सेवा से बाहर करना पड़ता है, तो यह प्रबंधनीय है क्योंकि अधिकांश कंपनियां अपनी बैक-एंड सेवाओं के कई उदाहरण बनाए रखती हैं। इसलिए जब एक भी उदाहरण विफल हो जाता है, तो अन्य लोग कार्यभार उठा लेते हैं। इन बार-बार होने वाली विफलताओं को संबोधित करने के लिए, अनुरोधों को आम तौर पर कोई त्रुटि मिलने पर स्वचालित रूप से पुनः प्रयास करने के लिए सेट किया जाता है।
यह तब चुनौतीपूर्ण हो जाता है जब कोई सिस्टम या व्यक्ति बहुत आक्रामक तरीके से प्रयास करता है, जो उन छोटे पैमाने की विफलताओं को पूरे बुनियादी ढांचे में अन्य सेवाओं और प्रणालियों तक फैलाने का एक तरीका बन सकता है। यदि नेटवर्क या उपयोगकर्ता लगातार पर्याप्त रूप से पुनः प्रयास करता है, तो यह अंततः उस सेवा के प्रत्येक उदाहरण और संभावित रूप से विश्व स्तर पर अन्य प्रणालियों को अधिभारित कर देगा। हमारा 2021 आउटेज उस चीज़ का परिणाम था जो बड़े पैमाने के सिस्टम में काफी सामान्य है: एक विफलता छोटे से शुरू होती है और फिर सिस्टम के माध्यम से फैलती है, इतनी जल्दी बड़ी हो जाती है कि सब कुछ खत्म होने से पहले इसे हल करना मुश्किल होता है।
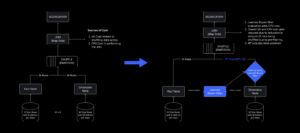
हमारे आउटेज के समय, हमारे पास एक सक्रिय डेटा सेंटर था (इसके भीतर के घटक बैकअप के रूप में कार्य करते थे)। जब किसी समस्या के कारण मौजूदा डेटा सेंटर बंद हो जाता है तो हमें नए डेटा सेंटर में मैन्युअल रूप से विफल होने की क्षमता की आवश्यकता होती है। हमारी पहली प्राथमिकता यह सुनिश्चित करना था कि हमारे पास Roblox का बैकअप परिनियोजन हो, इसलिए हमने उस बैकअप को एक अलग भौगोलिक क्षेत्र में स्थित एक नए डेटा सेंटर में बनाया। इसने सबसे खराब स्थिति के लिए अतिरिक्त सुरक्षा प्रदान की: एक डेटा सेंटर के भीतर इतने घटकों तक आउटेज फैल गया कि यह पूरी तरह से निष्क्रिय हो गया। अब हमारे पास एक डेटा सेंटर है जो कार्यभार संभाल रहा है (सक्रिय) और एक स्टैंडबाय पर है, जो बैकअप (निष्क्रिय) के रूप में काम कर रहा है। हमारा दीर्घकालिक लक्ष्य इस सक्रिय-निष्क्रिय कॉन्फ़िगरेशन से सक्रिय-सक्रिय कॉन्फ़िगरेशन की ओर बढ़ना है, जिसमें दोनों डेटा केंद्र वर्कलोड को संभालते हैं, जिसमें लोड बैलेंसर विलंबता, क्षमता और स्वास्थ्य के आधार पर उनके बीच अनुरोध वितरित करता है। एक बार यह स्थापित हो जाने के बाद, हम उम्मीद करते हैं कि पूरे रोबॉक्स के लिए और भी अधिक विश्वसनीयता होगी और कई घंटों के बजाय लगभग तुरंत ही विफल होने में सक्षम होंगे। 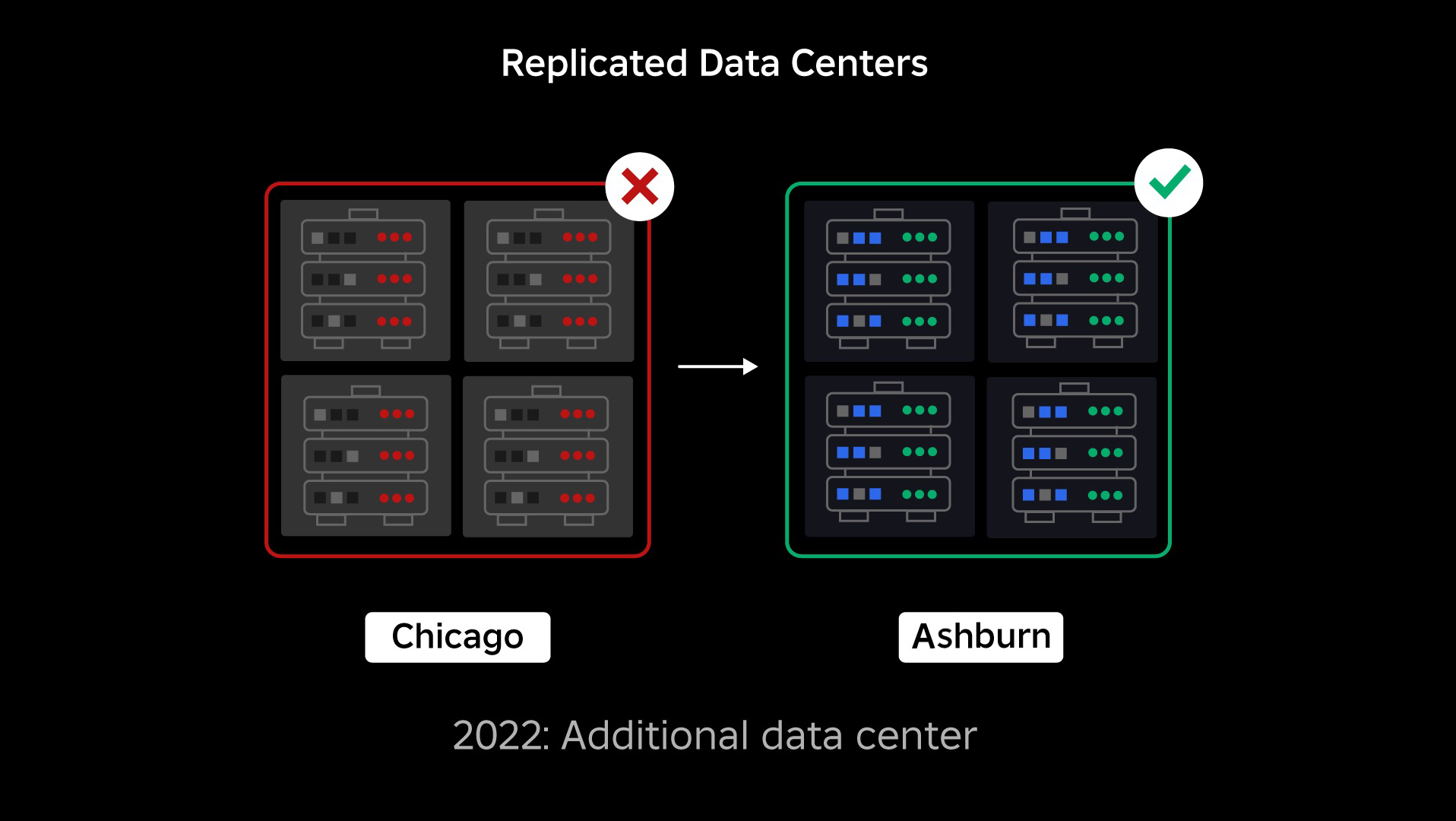
सेल्यूलर इन्फ्रास्ट्रक्चर की ओर बढ़ना
हमारी अगली प्राथमिकता संपूर्ण डेटा सेंटर के विफल होने की संभावना को कम करने के लिए प्रत्येक डेटा सेंटर के अंदर मजबूत ब्लास्ट दीवारें बनाना था। सेल (कुछ कंपनियां उन्हें क्लस्टर कहती हैं) मूल रूप से मशीनों का एक सेट हैं और हम इन दीवारों का निर्माण कैसे कर रहे हैं। हम अतिरिक्त अतिरेक के लिए कोशिकाओं के भीतर और पार दोनों जगह सेवाओं को दोहराते हैं। अंततः, हम चाहते हैं कि रोबॉक्स की सभी सेवाएँ सेल में चलें ताकि वे मजबूत ब्लास्ट दीवारों और अतिरेक दोनों से लाभ उठा सकें। यदि कोई सेल अब क्रियाशील नहीं है, तो इसे सुरक्षित रूप से निष्क्रिय किया जा सकता है। कोशिकाओं में प्रतिकृति सेल की मरम्मत के दौरान सेवा को चालू रखने में सक्षम बनाती है। कुछ मामलों में, सेल की मरम्मत का मतलब सेल का पूर्ण पुन: प्रावधान हो सकता है। पूरे उद्योग में, एक व्यक्तिगत मशीन, या मशीनों के एक छोटे सेट को पोंछना और पुन: प्रावधान करना, काफी आम है, लेकिन पूरे सेल के लिए ऐसा करना, जिसमें ~1,400 मशीनें होती हैं, ऐसा नहीं है।
इसे काम करने के लिए, इन कोशिकाओं को काफी हद तक एक समान होना चाहिए, ताकि हम कार्यभार को एक सेल से दूसरे सेल में जल्दी और कुशलता से स्थानांतरित कर सकें। हमने कुछ आवश्यकताएँ निर्धारित की हैं जिन्हें सेल में चलाने से पहले सेवाओं को पूरा करना होगा। उदाहरण के लिए, सेवाओं को कंटेनरीकृत किया जाना चाहिए, जो उन्हें अधिक पोर्टेबल बनाता है और किसी को भी ओएस स्तर पर कॉन्फ़िगरेशन परिवर्तन करने से रोकता है। हमने कोशिकाओं के लिए बुनियादी ढांचे-ए-कोड दर्शन को अपनाया है: हमारे स्रोत कोड रिपॉजिटरी में, हम सेल में मौजूद हर चीज की परिभाषा को शामिल करते हैं ताकि हम स्वचालित टूल का उपयोग करके इसे स्क्रैच से जल्दी से पुनर्निर्माण कर सकें।
वर्तमान में सभी सेवाएँ इन आवश्यकताओं को पूरा नहीं करती हैं, इसलिए हमने जहाँ संभव हो सेवा मालिकों को उन्हें पूरा करने में मदद करने के लिए काम किया है, और तैयार होने पर सेवाओं को सेल में स्थानांतरित करना आसान बनाने के लिए हमने नए टूल बनाए हैं। उदाहरण के लिए, हमारा नया परिनियोजन उपकरण स्वचालित रूप से सभी कोशिकाओं में सेवा परिनियोजन को "पट्टियाँ" देता है, इसलिए सेवा मालिकों को प्रतिकृति रणनीति के बारे में सोचने की ज़रूरत नहीं है। कठोरता का यह स्तर प्रवासन प्रक्रिया को अधिक चुनौतीपूर्ण और समय लेने वाला बनाता है, लेकिन दीर्घकालिक भुगतान एक ऐसी प्रणाली होगी जहां:
- किसी विफलता को रोकना और उसे अन्य कोशिकाओं में फैलने से रोकना बहुत आसान है;
- हमारे बुनियादी ढांचे के इंजीनियर अधिक कुशल हो सकते हैं और अधिक तेज़ी से आगे बढ़ सकते हैं; और
- जो इंजीनियर उत्पाद-स्तरीय सेवाओं का निर्माण करते हैं, जिन्हें अंततः कोशिकाओं में तैनात किया जाता है, उन्हें यह जानने या चिंता करने की ज़रूरत नहीं है कि उनकी सेवाएँ किन कोशिकाओं में चल रही हैं।
बड़ी चुनौतियों का समाधान
जिस तरह से आग की लपटों को रोकने के लिए आग के दरवाजों का उपयोग किया जाता है, उसी तरह कोशिकाएं हमारे बुनियादी ढांचे के भीतर मजबूत विस्फोट दीवारों के रूप में कार्य करती हैं ताकि किसी भी एकल कोशिका के भीतर विफलता को ट्रिगर करने वाले किसी भी मुद्दे को नियंत्रित करने में मदद मिल सके। अंततः, Roblox को बनाने वाली सभी सेवाएँ कोशिकाओं के अंदर और उनके पार अनावश्यक रूप से तैनात की जाएंगी। एक बार जब यह काम पूरा हो जाता है, तब भी समस्याएँ इतनी व्यापक रूप से फैल सकती हैं कि पूरी सेल निष्क्रिय हो सकती है, लेकिन किसी समस्या का उस सेल से आगे फैलना बेहद मुश्किल होगा। और यदि हम कोशिकाओं को विनिमेय बनाने में सफल हो जाते हैं, तो पुनर्प्राप्ति काफी तेज हो जाएगी क्योंकि हम एक अलग सेल में विफल होने में सक्षम होंगे और समस्या को अंतिम उपयोगकर्ताओं को प्रभावित करने से रोकेंगे।
जहां यह मुश्किल हो जाता है, वहां इन कोशिकाओं को पर्याप्त रूप से अलग करना है ताकि त्रुटियों के फैलने के अवसर को कम किया जा सके, साथ ही चीजों को क्रियाशील और कार्यात्मक बनाए रखा जा सके। एक जटिल बुनियादी ढांचा प्रणाली में, सेवाओं को प्रश्नों, सूचनाओं, कार्यभार आदि को साझा करने के लिए एक-दूसरे के साथ संवाद करने की आवश्यकता होती है। जैसे ही हम इन सेवाओं को कोशिकाओं में दोहराते हैं, हमें इस बारे में विचारशील होने की आवश्यकता है कि हम क्रॉस-संचार का प्रबंधन कैसे करते हैं। एक आदर्श दुनिया में, हम ट्रैफ़िक को एक अस्वस्थ कोशिका से अन्य स्वस्थ कोशिकाओं की ओर पुनर्निर्देशित करते हैं। लेकिन हम "मौत की क्वेरी" का प्रबंधन कैसे करते हैं - वह यह है के कारण एक कोशिका अस्वस्थ होगी? यदि हम उस क्वेरी को किसी अन्य सेल पर रीडायरेक्ट करते हैं, तो यह उस सेल को उसी तरह अस्वस्थ बना सकता है जिस तरह से हम बचने की कोशिश कर रहे हैं। हमें अस्वस्थ कोशिकाओं से "अच्छे" ट्रैफ़िक को स्थानांतरित करने के लिए तंत्र ढूंढने की ज़रूरत है, साथ ही उस ट्रैफ़िक का पता लगाने और उसे कम करने की आवश्यकता है जिसके कारण कोशिकाएं अस्वस्थ हो रही हैं।
अल्पावधि में, हमने प्रत्येक कंप्यूट सेल में कंप्यूटिंग सेवाओं की प्रतियां तैनात की हैं ताकि डेटा सेंटर के अधिकांश अनुरोधों को एक ही सेल द्वारा पूरा किया जा सके। हम सभी सेल में ट्रैफ़िक को संतुलित करने का काम भी कर रहे हैं। आगे देखते हुए, हमने एक अगली पीढ़ी की सेवा खोज प्रक्रिया का निर्माण शुरू कर दिया है जिसे एक सेवा जाल द्वारा लाभ उठाया जाएगा, जिसे हम 2024 में पूरा करने की उम्मीद करते हैं। यह हमें परिष्कृत नीतियों को लागू करने की अनुमति देगा जो क्रॉस-सेल संचार की अनुमति केवल तभी देंगी जब यह फेलओवर कोशिकाओं पर नकारात्मक प्रभाव नहीं डालेगा। इसके अलावा 2024 में एक ही सेल में सेवा संस्करण पर निर्भर अनुरोधों को निर्देशित करने की एक विधि भी आएगी, जो क्रॉस-सेल ट्रैफ़िक को कम करेगी और इस तरह विफलताओं के क्रॉस-सेल प्रसार के जोखिम को कम करेगी।
चरम पर, हमारी 70 प्रतिशत से अधिक बैक-एंड सेवा ट्रैफ़िक सेल से दी जा रही है और हमने सेल बनाने के तरीके के बारे में बहुत कुछ सीखा है, लेकिन हम और अधिक शोध और परीक्षण की उम्मीद करते हैं क्योंकि हम 2024 तक अपनी सेवाओं को स्थानांतरित करना जारी रखेंगे। आगे। जैसे-जैसे हम आगे बढ़ेंगे, ये विस्फोट दीवारें और अधिक मजबूत होती जाएंगी।
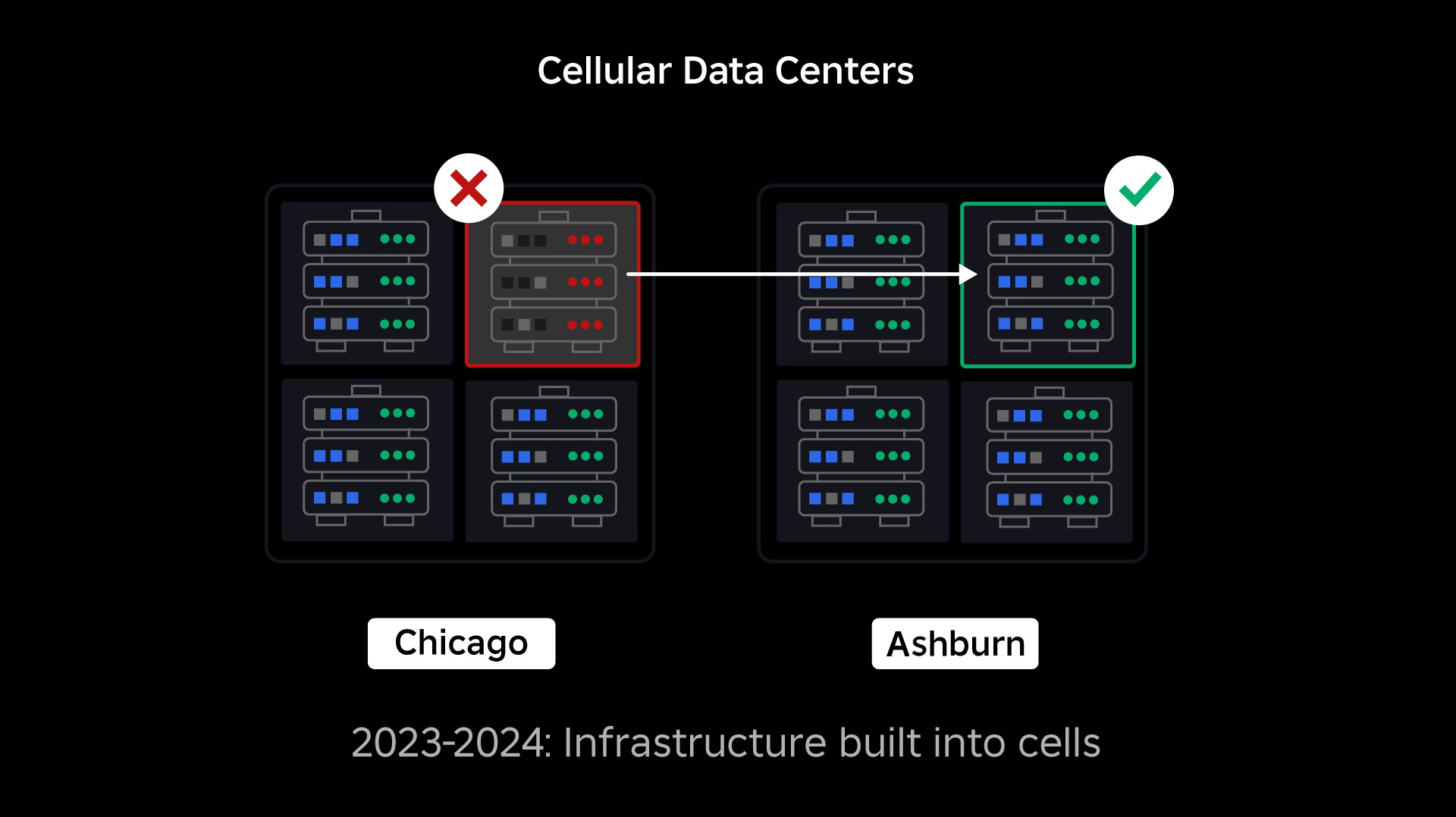
हमेशा चालू रहने वाले बुनियादी ढांचे का स्थानांतरण
रोब्लॉक्स एक वैश्विक मंच है जो दुनिया भर के उपयोगकर्ताओं का समर्थन करता है, इसलिए हम ऑफ-पीक या "डाउन टाइम" के दौरान सेवाओं को स्थानांतरित नहीं कर सकते हैं, जो हमारी सभी मशीनों को कोशिकाओं में स्थानांतरित करने और हमारी सेवाओं को उन कोशिकाओं में चलाने की प्रक्रिया को और जटिल बनाता है। . हमारे पास हमेशा चालू रहने वाले लाखों अनुभव हैं जिनका समर्थन जारी रखने की आवश्यकता है, भले ही हम उन मशीनों को स्थानांतरित करते हैं जिन पर वे चलती हैं और जो सेवाएं उनका समर्थन करती हैं। जब हमने यह प्रक्रिया शुरू की, तो हमारे पास ऐसी हज़ारों मशीनें नहीं थीं जो अप्रयुक्त पड़ी थीं और इन कार्यभारों को स्थानांतरित करने के लिए उपलब्ध थीं।
हालाँकि, हमारे पास थोड़ी संख्या में अतिरिक्त मशीनें थीं जो भविष्य की वृद्धि की प्रत्याशा में खरीदी गई थीं। शुरू करने के लिए, हमने उन मशीनों का उपयोग करके नई कोशिकाएँ बनाईं, फिर कार्यभार को उनमें स्थानांतरित कर दिया। हम दक्षता के साथ-साथ विश्वसनीयता को भी महत्व देते हैं, इसलिए जब हमारे पास "अतिरिक्त" मशीनें खत्म हो गईं तो बाहर जाने और अधिक मशीनें खरीदने के बजाय हमने उन मशीनों को मिटाकर और पुन: प्रावधान करके अधिक सेल बनाए, जिनसे हम चले गए थे। फिर हमने कार्यभार को उन पुन: प्रावधानित मशीनों पर स्थानांतरित कर दिया, और प्रक्रिया फिर से शुरू कर दी। यह प्रक्रिया जटिल है - जैसे-जैसे मशीनों को बदला जाता है और कोशिकाओं में निर्मित होने के लिए मुक्त किया जाता है, वे एक आदर्श, व्यवस्थित तरीके से मुक्त नहीं हो रही हैं। वे डेटा हॉल में भौतिक रूप से खंडित हैं, जिससे हमें उन्हें टुकड़ों में व्यवस्थित करना पड़ता है, जिसके लिए हार्डवेयर स्थानों को बड़े पैमाने पर भौतिक विफलता डोमेन के साथ संरेखित रखने के लिए हार्डवेयर-स्तरीय डीफ़्रेग्मेंटेशन प्रक्रिया की आवश्यकता होती है।
हमारी इंफ्रास्ट्रक्चर इंजीनियरिंग टीम का एक हिस्सा हमारी विरासत, या "प्री-सेल," वातावरण से मौजूदा कार्यभार को कोशिकाओं में स्थानांतरित करने पर केंद्रित है। यह कार्य तब तक जारी रहेगा जब तक हम हजारों विभिन्न बुनियादी ढांचा सेवाओं और हजारों बैक-एंड सेवाओं को नव निर्मित कोशिकाओं में स्थानांतरित नहीं कर देते। हमें उम्मीद है कि कुछ जटिल कारकों के कारण इसमें अगले पूरा साल और संभवत: 2025 तक का समय लगेगा। सबसे पहले, इस कार्य के लिए मजबूत टूलींग का निर्माण आवश्यक है। उदाहरण के लिए, जब हम एक नया सेल तैनात करते हैं तो हमें अपने उपयोगकर्ताओं को प्रभावित किए बिना बड़ी संख्या में सेवाओं को स्वचालित रूप से पुनर्संतुलित करने के लिए टूलींग की आवश्यकता होती है। हमने ऐसी सेवाएँ भी देखी हैं जो हमारे बुनियादी ढांचे के बारे में धारणाओं के साथ बनाई गई थीं। हमें इन सेवाओं को संशोधित करने की आवश्यकता है ताकि वे उन चीज़ों पर निर्भर न रहें जो भविष्य में कोशिकाओं में जाने पर बदल सकती हैं। हमने ज्ञात डिज़ाइन पैटर्न की खोज करने का एक तरीका भी लागू किया है जो सेलुलर आर्किटेक्चर के साथ अच्छी तरह से काम नहीं करेगा, साथ ही माइग्रेट की गई प्रत्येक सेवा के लिए एक व्यवस्थित परीक्षण प्रक्रिया भी लागू की है। ये प्रक्रियाएं हमें किसी सेवा के सेल के साथ असंगत होने के कारण होने वाली उपयोगकर्ता-संबंधी समस्याओं से निपटने में मदद करती हैं।
आज, लगभग 30,000 मशीनों का प्रबंधन कोशिकाओं द्वारा किया जा रहा है। यह हमारे कुल बेड़े का केवल एक अंश है, लेकिन अब तक यह एक बहुत ही सहज परिवर्तन रहा है और खिलाड़ी पर कोई नकारात्मक प्रभाव नहीं पड़ा है। हमारा अंतिम लक्ष्य हमारे सिस्टम के लिए हर महीने 99.99 प्रतिशत उपयोगकर्ता अपटाइम प्राप्त करना है, जिसका अर्थ है कि हम 0.01 प्रतिशत से अधिक सहभागिता घंटों को बाधित नहीं करेंगे। उद्योग-व्यापी, डाउनटाइम को पूरी तरह से समाप्त नहीं किया जा सकता है, लेकिन हमारा लक्ष्य किसी भी Roblox डाउनटाइम को इस हद तक कम करना है कि यह लगभग ध्यान देने योग्य न हो।
जैसे-जैसे हम बड़े होते जाते हैं, भविष्य का प्रमाण मिलता जाता है
हालाँकि हमारे शुरुआती प्रयास सफल साबित हो रहे हैं, कोशिकाओं पर हमारा काम अभी पूरा नहीं हुआ है। जैसे-जैसे रोबॉक्स का विस्तार जारी रहेगा, हम इस और अन्य तकनीकों के माध्यम से अपने सिस्टम की दक्षता और लचीलेपन में सुधार करने के लिए काम करते रहेंगे। जैसे-जैसे हम आगे बढ़ेंगे, मंच मुद्दों के प्रति तेजी से लचीला होता जाएगा, और जो भी मुद्दे होंगे वे हमारे मंच पर लोगों के लिए उत्तरोत्तर कम दिखाई देने वाले और विघटनकारी होने चाहिए।
संक्षेप में, आज तक, हमारे पास:
- दूसरा डेटा सेंटर बनाया और सफलतापूर्वक सक्रिय/निष्क्रिय स्थिति हासिल की।
- हमारे सक्रिय और निष्क्रिय डेटा केंद्रों में सेल बनाए गए और हमारे 70 प्रतिशत से अधिक बैक-एंड सेवा ट्रैफ़िक को इन सेल में सफलतापूर्वक स्थानांतरित कर दिया गया।
- सभी कोशिकाओं को एक समान रखने के लिए हमें उन आवश्यकताओं और सर्वोत्तम प्रथाओं को निर्धारित करना होगा जिनका हमें पालन करना होगा क्योंकि हम अपने बाकी बुनियादी ढांचे को स्थानांतरित करना जारी रखते हैं।
- कोशिकाओं के बीच मजबूत "विस्फोट दीवारों" के निर्माण की एक सतत प्रक्रिया शुरू हुई।
जैसे-जैसे ये कोशिकाएं अधिक विनिमेय हो जाएंगी, कोशिकाओं के बीच क्रॉसस्टॉक कम हो जाएगा। यह निगरानी, समस्या निवारण और यहां तक कि कार्यभार को स्वचालित रूप से स्थानांतरित करने के आसपास बढ़ते स्वचालन के संदर्भ में हमारे लिए कुछ बहुत ही दिलचस्प अवसरों को खोलता है।
सितंबर में हमने अपने डेटा केंद्रों पर सक्रिय/सक्रिय प्रयोग चलाना भी शुरू किया। यह एक और तंत्र है जिसका परीक्षण हम विश्वसनीयता में सुधार और विफलता समय को कम करने के लिए कर रहे हैं। इन प्रयोगों ने कई सिस्टम डिज़ाइन पैटर्न की पहचान करने में मदद की, मुख्य रूप से डेटा एक्सेस के आसपास, जिस पर हमें फिर से काम करने की ज़रूरत है क्योंकि हम पूरी तरह से सक्रिय-सक्रिय बनने की दिशा में आगे बढ़ रहे हैं। कुल मिलाकर, यह प्रयोग इतना सफल रहा कि इसे हमारे उपयोगकर्ताओं की सीमित संख्या के ट्रैफ़िक के लिए चालू रखा जा सका।
हम प्लेटफ़ॉर्म पर अधिक दक्षता और लचीलापन लाने के लिए इस कार्य को आगे बढ़ाने के लिए उत्साहित हैं। कोशिकाओं और सक्रिय-सक्रिय बुनियादी ढांचे पर यह काम, हमारे अन्य प्रयासों के साथ, हमारे लिए लाखों लोगों के लिए एक विश्वसनीय, उच्च प्रदर्शन उपयोगिता के रूप में विकसित होना और वास्तविक रूप से एक अरब लोगों को जोड़ने के लिए काम करने के पैमाने को जारी रखना संभव बना देगा। समय।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- क्षमता
- योग्य
- About
- पहुँच
- पाना
- हासिल
- के पार
- अधिनियम
- अभिनय
- सक्रिय
- जोड़ा
- अतिरिक्त
- पता
- दत्तक
- फिर
- उग्रता के साथ
- गठबंधन
- सब
- अनुमति देना
- अकेला
- साथ में
- पहले ही
- भी
- an
- और
- अन्य
- की आशा
- प्रत्याशा
- कोई
- किसी
- लगभग
- स्थापत्य
- हैं
- चारों ओर
- AS
- मान्यताओं
- At
- स्वचालित
- स्वतः
- स्वचालन
- उपलब्ध
- अवतार
- से बचने
- बैक-एंड
- बैकअप
- कसरती
- संतुलन
- आधारित
- BE
- क्योंकि
- बन
- हो जाता है
- बनने
- किया गया
- से पहले
- शुरू कर दिया
- जा रहा है
- लाभ
- BEST
- सर्वोत्तम प्रथाओं
- के बीच
- परे
- बड़ा
- बड़ा
- बिलियन
- ब्लॉग
- के छात्रों
- लाना
- लाया
- कीड़े
- निर्माण
- इमारत
- बनाया गया
- व्यवसायों
- लेकिन
- क्रय
- by
- कॉल
- कर सकते हैं
- नही सकता
- क्षमता
- मामलों
- कारण
- के कारण होता
- के कारण
- सेल
- कोशिकाओं
- सेलुलर
- केंद्र
- केंद्र
- कुछ
- चुनौतीपूर्ण
- परिवर्तन
- परिवर्तन
- समापन
- बादल
- क्लाउड इन्फ्रास्ट्रक्चर
- कोड
- कैसे
- अ रहे है
- सामान्य
- संवाद
- संवाद स्थापित
- संचार
- कंपनियों
- तुलना
- पूरा
- पूरी तरह से
- जटिल
- जटिलता
- अंग
- घटकों
- गणना करना
- कंप्यूटिंग
- सम्मेलन
- विन्यास
- जुडिये
- संबंध
- शामिल
- शामिल हैं
- जारी रखने के
- जारी
- निरंतर
- नियंत्रण
- प्रतियां
- लागत
- सका
- बनाना
- बनाना
- रचनाकारों
- वर्तमान में
- कस्टम निर्मित
- दैनिक
- तिथि
- डेटा प्राप्त करना
- डाटा केंद्र
- डेटा केन्द्रों
- तारीख
- दिन
- परिभाषा
- डिग्री
- देरी
- निर्भर
- निर्भर
- तैनात
- तैनात
- तैनाती
- डिज़ाइन
- डिजाइन पैटर्न्स
- डीआईडी
- विभिन्न
- मुश्किल
- संचालन करनेवाला
- खोज
- बाधित
- हानिकारक
- वितरण
- do
- कर देता है
- कर
- डोमेन
- किया
- dont
- दरवाजे
- नीचे
- स्र्कना
- ड्राइविंग
- दो
- दौरान
- से प्रत्येक
- शीघ्र
- आसान
- आसान
- दक्षता
- कुशल
- कुशलता
- प्रयासों
- सफाया
- सक्षम बनाता है
- समाप्त
- सगाई
- अभियांत्रिकी
- इंजीनियर्स
- पर्याप्त
- सुनिश्चित
- संपूर्ण
- पूरी तरह से
- वातावरण
- त्रुटि
- त्रुटियाँ
- अनिवार्य
- आदि
- और भी
- अंत में
- प्रत्येक
- सब कुछ
- उदाहरण
- उत्तेजित
- मौजूदा
- उम्मीद
- अनुभवी
- अनुभव
- प्रयोग
- प्रयोगों
- चरम
- अत्यंत
- कारकों
- असफल
- में नाकाम रहने
- विफल रहता है
- विफलता
- विफलताओं
- काफी
- दूर
- फैशन
- और तेज
- खोज
- आग
- प्रथम
- बेड़ा
- फोकस
- ध्यान केंद्रित
- का पालन करें
- के लिए
- आगे
- अंश
- खंडित
- मुक्त
- बारंबार
- से
- पूर्ण
- पूरी तरह से
- कार्यात्मक
- आगे
- भविष्य
- भविष्य की वृद्धि
- आम तौर पर
- भौगोलिक
- मिल
- मिल रहा
- दी
- वैश्विक
- ग्लोबली
- Go
- लक्ष्य
- चला जाता है
- जा
- अधिक से अधिक
- समूह
- आगे बढ़ें
- वयस्क
- विकास
- था
- आधा
- संभालना
- हैंडलिंग
- होना
- कठिन
- हार्डवेयर
- है
- सिर
- स्वास्थ्य
- स्वस्थ
- मदद
- मदद की
- हाई
- उच्चतर
- आशा
- घंटे
- कैसे
- How To
- तथापि
- HTTPS
- मनुष्य
- संकर
- आदर्श
- पहचान करना
- if
- immersive
- प्रभाव
- प्रभावित
- लागू करने के
- कार्यान्वित
- में सुधार
- in
- शामिल
- सहित
- असंगत
- बढ़ना
- बढ़ती
- तेजी
- व्यक्ति
- उद्योग
- करें-
- इंफ्रास्ट्रक्चर
- अंदर
- उदाहरण
- उदाहरणों
- तत्क्षण
- दिलचस्प
- आंतरिक
- में
- मुद्दा
- मुद्दों
- IT
- जून
- केवल
- रखना
- रखना
- जानना
- जानने वाला
- बड़ा
- बड़े पैमाने पर
- बड़े पैमाने पर
- विलंब
- सीखा
- छोड़ना
- छोड़ने
- विरासत
- कम
- चलो
- स्तर
- का लाभ उठाया
- पसंद
- सीमित
- भार
- स्थित
- स्थानों
- लंबे समय तक
- लंबे समय तक
- देख
- लॉट
- निम्न
- मशीन
- मशीनें
- बनाए रखना
- बनाना
- बनाता है
- निर्माण
- प्रबंधन
- कामयाब
- मैन्युअल
- बहुत
- अधिकतम-चौड़ाई
- मतलब
- अर्थ
- तंत्र
- तंत्र
- मिलना
- जाल
- तरीका
- व्यवस्थित
- हो सकता है
- विस्थापित
- पलायन
- ओर पलायन
- प्रवास
- दस लाख
- लाखों
- कम से कम
- नाबालिग
- गलतियां
- निगरानी
- महीना
- अधिक
- अधिक कुशल
- अधिकांश
- चाल
- बहुत
- विभिन्न
- चाहिए
- प्रकृति
- लगभग
- आवश्यकता
- जरूरत
- नकारात्मक
- नकारात्मक
- नेटवर्क
- नया
- नए नए
- अगला
- अगली पीढ़ी
- नहीं
- अभी
- संख्या
- संख्या
- होते हैं
- अक्टूबर
- of
- बंद
- on
- एक बार
- ONE
- चल रहे
- केवल
- अवसर
- अवसर
- or
- OS
- अन्य
- अन्य
- हमारी
- आउट
- आउटेज
- की कटौती
- के ऊपर
- कुल
- मालिकों
- भाग
- निष्क्रिय
- अतीत
- पैटर्न उपयोग करें
- का भुगतान
- शिखर
- स्टाफ़
- प्रति
- प्रतिशत
- प्रदर्शन
- लगातार
- व्यक्ति
- दर्शन
- भौतिक
- शारीरिक रूप से
- चुनना
- जगह
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- खिलाड़ी
- नीतियाँ
- पोर्टेबल
- हिस्सा
- संभावना
- संभव
- संभवतः
- संभावित
- प्रथाओं
- को रोकने के
- रोकता है
- मुख्यत
- प्राथमिकता
- निजी
- प्रक्रिया
- प्रक्रियाओं
- प्रगति
- उत्तरोत्तर
- प्रचार
- सुरक्षा
- साबित
- प्रावधान
- खरीदा
- धक्का
- प्रश्नों
- प्रश्न
- जल्दी से
- बल्कि
- तैयार
- वास्तविक
- वास्तविक समय
- संतुलित
- वसूली
- अनुप्रेषित
- को कम करने
- क्षेत्र
- विश्वसनीयता
- विश्वसनीय
- भरोसा करना
- मरम्मत
- प्रतिस्थापित
- प्रतिकृति
- कोष
- अनुरोधों
- आवश्यकताएँ
- की आवश्यकता होती है
- अनुसंधान
- पलटाव
- लचीला
- संकल्प
- बाकी
- परिणाम
- परिणामस्वरूप
- संशोधन
- जोखिम
- Roblox
- मजबूत
- रन
- दौड़ना
- चलाता है
- सुरक्षित
- वही
- बचाया
- स्केल
- परिदृश्य
- खरोंच
- Search
- दूसरा
- देखा
- पृथक करना
- सितंबर
- सेवा की
- सेवा
- सेवाएँ
- सेवारत
- सेट
- कई
- Share
- साझा
- बांटने
- पाली
- स्थानांतरण
- कम
- चाहिए
- काफी
- के बाद से
- एक
- बैठक
- छोटा
- चिकनी
- So
- अब तक
- सॉफ्टवेयर
- कुछ
- कुछ
- परिष्कृत
- स्रोत
- स्रोत कोड
- अंतरिक्ष
- spikes के
- विस्तार
- प्रसार
- प्रारंभ
- शुरू
- शुरू होता है
- स्थिति
- फिर भी
- स्ट्रेटेजी
- मजबूत
- मजबूत
- का अध्ययन
- सफल
- सफल
- सफलतापूर्वक
- सारांश
- समर्थन
- समर्थित
- सहायक
- समर्थन करता है
- प्रणाली
- सिस्टम
- लेना
- लिया
- टीम
- तकनीकी
- टेक्नोलॉजीज
- है
- अवधि
- शर्तों
- परीक्षण
- टेक्स्ट
- से
- कि
- RSI
- भविष्य
- दुनिया
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- जिसके चलते
- इन
- वे
- चीज़ें
- सोचना
- इसका
- उन
- हजारों
- यहाँ
- भर
- पहर
- बार
- सेवा मेरे
- आज
- एक साथ
- सहिष्णुता
- भी
- साधन
- उपकरण
- कुल
- की ओर
- यातायात
- संक्रमण
- ट्रिगर
- की कोशिश कर रहा
- दो
- प्रकार
- परम
- अंत में
- अनलॉक
- जब तक
- अप्रयुक्त
- के ऊपर
- उपरिकाल
- us
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ताओं
- का उपयोग
- उपयोगिता
- मूल्य
- संस्करण
- बहुत
- दिखाई
- दृष्टि
- करना चाहते हैं
- था
- मार्ग..
- we
- मौसम
- कुंआ
- थे
- क्या
- जो कुछ
- कब
- कौन कौन से
- जब
- कौन
- चौड़ा
- मर्जी
- पोंछते
- साथ में
- अंदर
- काम
- काम किया
- काम कर रहे
- विश्व
- चिंता
- होगा
- वर्ष
- साल
- जेफिरनेट