संपादक द्वारा छवि
ओपनएआई के जीपीटी-3, गूगल के बीईआरटी और मेटा के एलएलएएमए जैसे बड़े भाषा मॉडल (एलएलएम) पाठ की एक विस्तृत श्रृंखला उत्पन्न करने की अपनी क्षमता के साथ विभिन्न क्षेत्रों में क्रांति ला रहे हैं - मार्केटिंग कॉपी और डेटा साइंस स्क्रिप्ट से लेकर कविता तक।
भले ही चैटजीपीटी का सहज ज्ञान युक्त इंटरफ़ेस आज अधिकांश लोगों के उपकरणों में होने में कामयाब रहा है, फिर भी विविध सॉफ्टवेयर एकीकरणों में एलएलएम का उपयोग करने के लिए अभी भी अप्रयुक्त संभावनाओं का एक विशाल परिदृश्य मौजूद है।
मुखय परेशानी?
अधिकांश अनुप्रयोगों को एलएलएम के साथ अधिक तरल और देशी संचार की आवश्यकता होती है।
और यहीं पर लैंगचेन की शुरूआत होती है!
यदि आप जेनरेटिव एआई और एलएलएम में रुचि रखते हैं, तो यह ट्यूटोरियल आपके लिए तैयार किया गया है।
चलिए, शुरू करते हैं!
यदि आप किसी गुफा में रह रहे हैं और आपको हाल ही में कोई खबर नहीं मिली है, तो मैं बड़े भाषा मॉडल या एलएलएम के बारे में संक्षेप में बताऊंगा।
एलएलएम एक परिष्कृत कृत्रिम बुद्धिमत्ता प्रणाली है जो मानव जैसी पाठ्य समझ और पीढ़ी की नकल करने के लिए बनाई गई है। विशाल डेटा सेट पर प्रशिक्षण द्वारा, ये मॉडल जटिल पैटर्न को समझते हैं, भाषाई सूक्ष्मताओं को समझते हैं, और सुसंगत आउटपुट उत्पन्न करते हैं।
यदि आप सोच रहे हैं कि इन AI-संचालित मॉडलों के साथ कैसे इंटरैक्ट किया जाए, तो ऐसा करने के दो मुख्य तरीके हैं:
- सबसे आम और सीधा तरीका है मॉडल से बात करना या चैट करना। इसमें एक संकेत तैयार करना, उसे एआई-संचालित मॉडल पर भेजना और प्रतिक्रिया के रूप में टेक्स्ट-आधारित आउटपुट प्राप्त करना शामिल है।
- एक अन्य विधि पाठ को संख्यात्मक सरणियों में परिवर्तित करना है। इस प्रक्रिया में एआई के लिए एक संकेत तैयार करना और बदले में एक संख्यात्मक सरणी प्राप्त करना शामिल है। जिसे आमतौर पर "एम्बेडिंग" के रूप में जाना जाता है। इसने वेक्टर डेटाबेस और सिमेंटिक खोज में हाल ही में वृद्धि का अनुभव किया है।
और यह वास्तव में ये दो मुख्य समस्याएं हैं जिन्हें लैंगचेन संबोधित करने का प्रयास करता है। यदि आप एलएलएम के साथ बातचीत की मुख्य समस्याओं में रुचि रखते हैं, तो आप इस लेख को देख सकते हैं यहाँ उत्पन्न करें.
लैंगचेन एलएलएम के आसपास निर्मित एक ओपन-सोर्स फ्रेमवर्क है। यह मेज पर उपकरण, घटकों और इंटरफेस का एक शस्त्रागार लाता है जो एलएलएम-संचालित अनुप्रयोगों की वास्तुकला को सुव्यवस्थित करता है।
लैंगचेन के साथ, भाषा मॉडल के साथ जुड़ना, विविध घटकों को आपस में जोड़ना और एपीआई और डेटाबेस जैसी संपत्तियों को शामिल करना आसान हो गया है। यह सहज ज्ञान युक्त रूपरेखा एलएलएम अनुप्रयोग विकास यात्रा को काफी सरल बनाती है।
लॉन्ग चेन का मुख्य विचार यह है कि हम अधिक परिष्कृत एलएलएम-संचालित समाधान बनाने के लिए विभिन्न घटकों या मॉड्यूल, जिन्हें चेन भी कहा जाता है, को एक साथ जोड़ सकते हैं।
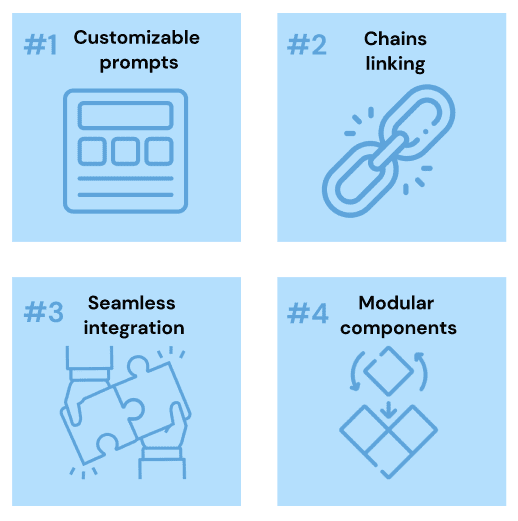
लैंगचेन की कुछ असाधारण विशेषताएं यहां दी गई हैं:
- हमारी बातचीत को मानकीकृत करने के लिए अनुकूलन योग्य शीघ्र टेम्पलेट।
- परिष्कृत उपयोग के मामलों के लिए तैयार किए गए चेन लिंक घटक।
- ओपनएआई के जीपीटी और हगिंगफेस हब सहित अग्रणी भाषा मॉडल के साथ निर्बाध एकीकरण।
- किसी विशिष्ट समस्या या कार्य का आकलन करने के लिए मिक्स-एंड-मैच दृष्टिकोण के लिए मॉड्यूलर घटक।
लेखक द्वारा छवि
लैंगचेन को अनुकूलनशीलता और मॉड्यूलर डिजाइन पर ध्यान केंद्रित करने के लिए जाना जाता है।
लैंगचेन के पीछे मुख्य विचार प्राकृतिक भाषा प्रसंस्करण अनुक्रम को अलग-अलग हिस्सों में तोड़ना है, जिससे डेवलपर्स को उनकी आवश्यकताओं के आधार पर वर्कफ़्लो को अनुकूलित करने की अनुमति मिलती है।
ऐसी बहुमुखी प्रतिभा लैंगचेन को विभिन्न स्थितियों और उद्योगों में एआई समाधान बनाने के लिए एक प्रमुख विकल्प के रूप में स्थापित करती है।
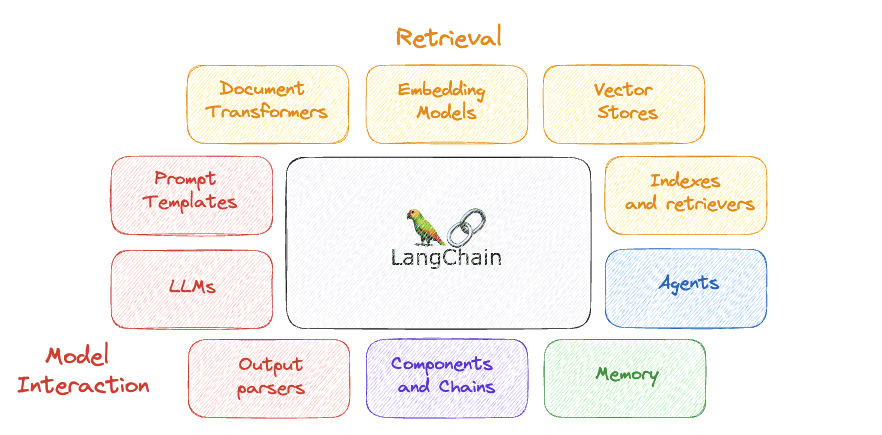
इसके कुछ सबसे महत्वपूर्ण घटक हैं…
लेखक द्वारा छवि
1. एलएलएम
एलएलएम मूलभूत घटक हैं जो मानव-जैसे पाठ को समझने और उत्पन्न करने के लिए बड़ी मात्रा में प्रशिक्षण डेटा का लाभ उठाते हैं। वे लैंगचेन के भीतर कई परिचालनों के मूल में हैं, जो पाठ इनपुट का विश्लेषण, व्याख्या और प्रतिक्रिया करने के लिए आवश्यक भाषा प्रसंस्करण क्षमताएं प्रदान करते हैं।
उपयोग: चैटबॉट्स को सशक्त बनाना, विभिन्न अनुप्रयोगों के लिए मानव-जैसा पाठ तैयार करना, सूचना पुनर्प्राप्ति में सहायता करना और अन्य भाषा प्रसंस्करण करना
2. शीघ्र टेम्पलेट्स
एलएलएम के साथ बातचीत करने के लिए संकेत मौलिक हैं, और विशिष्ट कार्यों पर काम करते समय, उनकी संरचना समान होती है। प्रॉम्प्ट टेम्प्लेट, जो श्रृंखलाओं में प्रयोग करने योग्य पूर्व निर्धारित संकेत हैं, विशिष्ट मान जोड़कर "संकेतों" के मानकीकरण की अनुमति देते हैं। यह किसी भी एलएलएम की अनुकूलनशीलता और अनुकूलन को बढ़ाता है।
उपयोग: एलएलएम के साथ बातचीत की प्रक्रिया का मानकीकरण।
3. आउटपुट पार्सर्स
आउटपुट पार्सर ऐसे घटक हैं जो श्रृंखला में पिछले चरण से कच्चा आउटपुट लेते हैं और इसे एक संरचित प्रारूप में परिवर्तित करते हैं। इस संरचित डेटा को बाद के चरणों में अधिक प्रभावी ढंग से उपयोग किया जा सकता है या अंतिम उपयोगकर्ता को प्रतिक्रिया के रूप में वितरित किया जा सकता है।
उपयोग: उदाहरण के लिए, एक चैटबॉट में, एक आउटपुट पार्सर एक भाषा मॉडल से मूल पाठ प्रतिक्रिया ले सकता है, जानकारी के मुख्य टुकड़े निकाल सकता है और उन्हें एक संरचित उत्तर में प्रारूपित कर सकता है।
4. अवयव और जंजीरें
लैंगचेन में, प्रत्येक घटक भाषा प्रसंस्करण अनुक्रम में एक विशेष कार्य के लिए जिम्मेदार मॉड्यूल के रूप में कार्य करता है। इन घटकों को फॉर्म से जोड़ा जा सकता है चेन अनुकूलित वर्कफ़्लो के लिए.
उपयोग: एक विशिष्ट चैटबॉट में भावना का पता लगाने और प्रतिक्रिया जनरेटर श्रृंखला उत्पन्न करना।
5। याद
लैंगचेन में मेमोरी एक घटक को संदर्भित करती है जो वर्कफ़्लो के भीतर जानकारी के लिए भंडारण और पुनर्प्राप्ति तंत्र प्रदान करती है। यह घटक डेटा के अस्थायी या लगातार भंडारण की अनुमति देता है जिसे एलएलएम के साथ बातचीत के दौरान अन्य घटकों द्वारा एक्सेस और हेरफेर किया जा सकता है।
उपयोग: यह उन परिदृश्यों में उपयोगी है जहां डेटा को प्रसंस्करण के विभिन्न चरणों में बनाए रखने की आवश्यकता होती है, उदाहरण के लिए, संदर्भ-जागरूक प्रतिक्रियाएं प्रदान करने के लिए चैटबॉट में वार्तालाप इतिहास संग्रहीत करना।
6। एजेंटों
एजेंट स्वायत्त घटक हैं जो उनके द्वारा संसाधित किए गए डेटा के आधार पर कार्रवाई करने में सक्षम हैं। वे लैंगचेन वर्कफ़्लो के भीतर विशिष्ट कार्य करने के लिए अन्य घटकों, बाहरी सिस्टम या उपयोगकर्ताओं के साथ बातचीत कर सकते हैं।
उपयोग: उदाहरण के लिए, एक एजेंट उपयोगकर्ता इंटरैक्शन को संभाल सकता है, आने वाले अनुरोधों को संसाधित कर सकता है, और उचित प्रतिक्रिया उत्पन्न करने के लिए श्रृंखला के माध्यम से डेटा के प्रवाह को समन्वयित कर सकता है।
7. इंडेक्स और रिट्रीवर्स
इंडेक्स और रिट्रीवर्स डेटा को कुशलतापूर्वक प्रबंधित करने और उस तक पहुंचने में महत्वपूर्ण भूमिका निभाते हैं। इंडेक्स मॉडल के प्रशिक्षण डेटा से जानकारी और मेटाडेटा रखने वाली डेटा संरचनाएं हैं। दूसरी ओर, रिट्रीवर्स ऐसे तंत्र हैं जो निर्दिष्ट मानदंडों के आधार पर प्रासंगिक डेटा लाने के लिए इन सूचकांकों के साथ बातचीत करते हैं और मॉडल को प्रासंगिक संदर्भ प्रदान करके बेहतर उत्तर देने की अनुमति देते हैं।
उपयोग: वे बड़े डेटासेट से प्रासंगिक डेटा या दस्तावेज़ों को शीघ्रता से लाने में सहायक होते हैं, जो सूचना पुनर्प्राप्ति या प्रश्न उत्तर जैसे कार्यों के लिए आवश्यक है।
8. दस्तावेज़ ट्रांसफार्मर
लैंगचेन में, दस्तावेज़ ट्रांसफॉर्मर दस्तावेज़ों को संसाधित करने और बदलने के लिए डिज़ाइन किए गए विशेष घटक हैं जो उन्हें आगे के विश्लेषण या प्रसंस्करण के लिए उपयुक्त बनाते हैं। इन परिवर्तनों में टेक्स्ट सामान्यीकरण, फीचर निष्कर्षण, या टेक्स्ट को एक अलग प्रारूप में परिवर्तित करना जैसे कार्य शामिल हो सकते हैं।
उपयोग: बाद के प्रसंस्करण चरणों के लिए पाठ डेटा तैयार करना, जैसे मशीन लर्निंग मॉडल द्वारा विश्लेषण या कुशल पुनर्प्राप्ति के लिए अनुक्रमण।
9. एम्बेडिंग मॉडल
इनका उपयोग उच्च-आयामी स्थान में टेक्स्ट डेटा को संख्यात्मक वैक्टर में परिवर्तित करने के लिए किया जाता है। ये मॉडल शब्दों और वाक्यांशों के बीच अर्थ संबंधी संबंधों को पकड़ते हैं, जिससे मशीन-पठनीय प्रतिनिधित्व सक्षम होता है। वे लैंगचेन पारिस्थितिकी तंत्र के भीतर विभिन्न डाउनस्ट्रीम प्राकृतिक भाषा प्रसंस्करण (एनएलपी) कार्यों की नींव बनाते हैं।
उपयोग: पाठ का संख्यात्मक प्रतिनिधित्व प्रदान करके अर्थ संबंधी खोजों, समानता तुलनाओं और अन्य मशीन-शिक्षण कार्यों को सुविधाजनक बनाना।
10. वेक्टर स्टोर
डेटाबेस प्रणाली का प्रकार जो एम्बेडिंग के माध्यम से जानकारी संग्रहीत करने और खोजने में माहिर है, अनिवार्य रूप से पाठ-जैसे डेटा के संख्यात्मक प्रतिनिधित्व का विश्लेषण करता है। वेक्टरस्टोर इन एम्बेडिंग के लिए भंडारण सुविधा के रूप में कार्य करता है।
उपयोग: अर्थ संबंधी समानता के आधार पर कुशल खोज की अनुमति देना।
पीआईपी का उपयोग करके इसे इंस्टॉल करना
पहली चीज़ जो हमें करनी है वह यह सुनिश्चित करना है कि हमारे वातावरण में लैंगचेन स्थापित है।
pip install langchain
पर्यावरण सेटअप
लैंगचेन का उपयोग करने का मतलब आम तौर पर अन्य घटकों के बीच विविध मॉडल प्रदाताओं, डेटा स्टोर, एपीआई के साथ एकीकरण करना है। और जैसा कि आप पहले से ही जानते हैं, किसी भी एकीकरण की तरह, लैंगचेन के संचालन के लिए प्रासंगिक और सही एपीआई कुंजियाँ प्रदान करना महत्वपूर्ण है।
कल्पना कीजिए कि हम अपने OpenAI API का उपयोग करना चाहते हैं। हम इसे दो तरीकों से आसानी से पूरा कर सकते हैं:
- कुंजी को पर्यावरण चर के रूप में सेट करना
OPENAI_API_KEY="..."
or
import os
os.environ['OPENAI_API_KEY'] = “...”
यदि आप पर्यावरण चर स्थापित नहीं करना चुनते हैं, तो आपके पास OpenAI LLM क्लास शुरू करते समय openai_api_key नामित पैरामीटर के माध्यम से सीधे कुंजी प्रदान करने का विकल्प होता है:
- कुंजी को सीधे संबंधित कक्षा में सेट करें।
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")एलएलएम के बीच स्विच करना सरल हो जाता है
लैंगचेन एक एलएलएम क्लास प्रदान करता है जो हमें ओपनएआई और हगिंग फेस जैसे विभिन्न भाषा मॉडल प्रदाताओं के साथ बातचीत करने की अनुमति देता है।
किसी भी एलएलएम के साथ शुरुआत करना काफी आसान है, क्योंकि किसी भी एलएलएम की सबसे बुनियादी और आसानी से लागू होने वाली कार्यक्षमता सिर्फ टेक्स्ट तैयार करना है।
हालाँकि, एक ही समय में अलग-अलग एलएलएम से एक ही संकेत पूछना इतना आसान नहीं है।
यहीं पर लैंगचेन की शुरुआत होती है...
किसी भी एलएलएम की सबसे आसान कार्यक्षमता पर वापस लौटते हुए, हम आसानी से लैंगचेन के साथ एक एप्लिकेशन बना सकते हैं जो एक स्ट्रिंग प्रॉम्प्ट प्राप्त करता है और हमारे निर्दिष्ट एलएलएम का आउटपुट लौटाता है।
लेखक द्वारा कोड
हम बस एक ही संकेत का उपयोग कर सकते हैं और कोड की कुछ पंक्तियों के भीतर दो अलग-अलग मॉडलों की प्रतिक्रिया प्राप्त कर सकते हैं!
लेखक द्वारा कोड
प्रभावशाली... ठीक है?
शीघ्र टेम्पलेट्स के साथ हमारे संकेतों को संरचना देना
भाषा मॉडल (एलएलएम) के साथ एक आम समस्या जटिल अनुप्रयोगों को आगे बढ़ाने में उनकी असमर्थता है। लैंगचेन संकेत बनाने की प्रक्रिया को सुव्यवस्थित करने के लिए एक समाधान की पेशकश करके इसे संबोधित करता है, जो अक्सर किसी कार्य को परिभाषित करने की तुलना में अधिक जटिल होता है क्योंकि इसमें एआई के व्यक्तित्व को रेखांकित करने और तथ्यात्मक सटीकता सुनिश्चित करने की आवश्यकता होती है। इसके एक महत्वपूर्ण हिस्से में दोहरावदार बॉयलरप्लेट टेक्स्ट शामिल है। लैंगचेन प्रॉम्प्ट टेम्प्लेट की पेशकश करके इसे कम करता है, जो नए प्रॉम्प्ट में बॉयलरप्लेट टेक्स्ट को स्वचालित रूप से शामिल करता है, इस प्रकार त्वरित निर्माण को सरल बनाता है और विभिन्न कार्यों में स्थिरता सुनिश्चित करता है।
लेखक द्वारा कोड
आउटपुट पार्सर्स के साथ संरचित प्रतिक्रियाएँ प्राप्त करना
चैट-आधारित इंटरैक्शन में, मॉडल का आउटपुट केवल टेक्स्ट होता है। फिर भी, सॉफ्टवेयर अनुप्रयोगों के भीतर, एक संरचित आउटपुट होना बेहतर है क्योंकि यह आगे की प्रोग्रामिंग क्रियाओं की अनुमति देता है। उदाहरण के लिए, डेटासेट बनाते समय, CSV या JSON जैसे विशिष्ट प्रारूप में प्रतिक्रिया प्राप्त करना वांछित होता है। यह मानते हुए कि एआई से सुसंगत और उपयुक्त रूप से स्वरूपित प्रतिक्रिया प्राप्त करने के लिए एक संकेत तैयार किया जा सकता है, इस आउटपुट को प्रबंधित करने के लिए उपकरणों की आवश्यकता है। लैंगचेन संरचित आउटपुट को प्रभावी ढंग से संभालने और उपयोग करने के लिए आउटपुट पार्सर टूल की पेशकश करके इस आवश्यकता को पूरा करता है।
लेखक द्वारा कोड
आप मेरे यहां जाकर पूरा कोड जांच सकते हैं GitHub.
अभी कुछ समय पहले, चैटजीपीटी की उन्नत क्षमताओं ने हमें आश्चर्यचकित कर दिया था। फिर भी, तकनीकी वातावरण लगातार बदल रहा है, और अब लैंगचेन जैसे उपकरण हमारी उंगलियों पर हैं, जो हमें कुछ ही घंटों में अपने व्यक्तिगत कंप्यूटर से उत्कृष्ट प्रोटोटाइप तैयार करने की अनुमति देते हैं।
लैंगचेन, एक स्वतंत्र रूप से उपलब्ध पायथन प्लेटफॉर्म, उपयोगकर्ताओं को एलएलएम (भाषा मॉडल मॉडल) द्वारा संचालित एप्लिकेशन विकसित करने का एक साधन प्रदान करता है। यह प्लेटफ़ॉर्म विभिन्न प्रकार के मूलभूत मॉडलों के लिए एक लचीला इंटरफ़ेस प्रदान करता है, त्वरित हैंडलिंग को सुव्यवस्थित करता है और वर्तमान दस्तावेज़ीकरण के अनुसार, शीघ्र टेम्पलेट्स, अधिक एलएलएम, बाहरी जानकारी और एजेंटों के माध्यम से अन्य संसाधनों जैसे तत्वों के लिए एक नेक्सस के रूप में कार्य करता है।
चैटबॉट, डिजिटल सहायक, भाषा अनुवाद उपकरण और भावना विश्लेषण उपयोगिताओं की कल्पना करें; ये सभी एलएलएम-सक्षम एप्लिकेशन लैंगचेन के साथ जीवंत हो उठते हैं। डेवलपर्स इस प्लेटफ़ॉर्म का उपयोग विशिष्ट आवश्यकताओं को संबोधित करते हुए कस्टम-अनुरूप भाषा मॉडल समाधान तैयार करने के लिए करते हैं।
जैसे-जैसे प्राकृतिक भाषा प्रसंस्करण का क्षितिज विस्तारित होता है, और इसे अपनाना गहरा होता है, इसके अनुप्रयोगों का दायरा असीमित लगता है।
जोसेप फेरर बार्सिलोना से एक एनालिटिक्स इंजीनियर है। उन्होंने भौतिकी इंजीनियरिंग में स्नातक किया है और वर्तमान में मानव गतिशीलता पर लागू डेटा साइंस क्षेत्र में काम कर रहे हैं। वह डेटा विज्ञान और प्रौद्योगिकी पर केंद्रित अंशकालिक सामग्री निर्माता हैं। आप उससे संपर्क कर सकते हैं लिंक्डइन, ट्विटर or मध्यम.
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/how-to-make-large-language-models-play-nice-with-your-software-using-langchain?utm_source=rss&utm_medium=rss&utm_campaign=how-to-make-large-language-models-play-nice-with-your-software-using-langchain
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 7
- a
- क्षमता
- पहुँचा
- तक पहुँचने
- पूरा
- शुद्धता
- के पार
- अभिनय
- कार्रवाई
- कार्य करता है
- जोड़ने
- पता
- पतों
- को संबोधित
- दत्तक ग्रहण
- उन्नत
- एजेंट
- एजेंटों
- पूर्व
- AI
- ऐ संचालित
- सब
- अनुमति देना
- की अनुमति दे
- की अनुमति देता है
- पहले ही
- भी
- के बीच में
- राशियाँ
- an
- विश्लेषण
- विश्लेषिकी
- विश्लेषण करें
- का विश्लेषण
- लंगर
- और
- कोई
- एपीआई
- एपीआई
- आवेदन
- अनुप्रयोग विकास
- अनुप्रयोगों
- लागू
- दृष्टिकोण
- उपयुक्त
- स्थापत्य
- हैं
- चारों ओर
- ऐरे
- शस्त्रागार
- लेख
- कृत्रिम
- कृत्रिम बुद्धिमत्ता
- AS
- पूछ
- आकलन
- संपत्ति
- सहायकों
- At
- स्वायत्त
- उपलब्ध
- एडब्ल्यूई
- वापस
- बार्सिलोना
- आधारित
- बुनियादी
- BE
- बन
- हो जाता है
- किया गया
- पीछे
- बेहतर
- के बीच
- असीम
- तोड़कर
- संक्षिप्त
- लाता है
- निर्माण
- इमारत
- बनाया गया
- by
- कर सकते हैं
- क्षमताओं
- सक्षम
- कब्जा
- मामला
- मामलों
- पूरा करता है
- गुफा
- श्रृंखला
- चेन
- chatbot
- chatbots
- ChatGPT
- बातें
- चेक
- चुनाव
- चुनें
- कक्षा
- कोड
- सुसंगत
- कैसे
- सामान्य
- सामान्यतः
- संचार
- तुलना
- जटिल
- अंग
- घटकों
- कंप्यूटर्स
- जुडिये
- जुड़ा हुआ
- संगत
- संपर्क करें
- सामग्री
- प्रसंग
- कन्वर्सेशन (Conversation)
- रूपांतरण
- बदलना
- परिवर्तित
- समन्वय
- मूल
- सही
- शिल्प
- तैयार
- बनाना
- बनाना
- निर्माण
- निर्माता
- मापदंड
- महत्वपूर्ण
- वर्तमान
- वर्तमान में
- अनुकूलन
- अनुकूलित
- अनुकूलित
- तिथि
- डेटा विज्ञान
- डेटा सेट
- डाटाबेस
- डेटाबेस
- गहरा
- परिभाषित करने
- दिया गया
- बचाता है
- डिज़ाइन
- निर्दिष्ट
- बनाया गया
- वांछित
- खोज
- विकसित करना
- डेवलपर्स
- विकास
- डिवाइस
- विभिन्न
- डिजिटल
- प्रत्यक्ष
- सीधे
- देख लेना
- अलग
- विशिष्ट
- कई
- do
- दस्तावेज़
- दस्तावेज़ीकरण
- दस्तावेजों
- नीचे
- दौरान
- से प्रत्येक
- सबसे आसान
- आसानी
- आसान
- पारिस्थितिकी तंत्र
- प्रभावी रूप से
- कुशल
- कुशलता
- तत्व
- embedding
- समर्थकारी
- समाप्त
- मनोहन
- इंजीनियर
- अभियांत्रिकी
- बढ़ाता है
- विशाल
- सुनिश्चित
- वातावरण
- ख़राब करना
- आवश्यक
- अनिवार्य
- स्थापित करना
- ईथर (ईटीएच)
- कभी बदलते
- उदाहरण
- फैलता
- अनुभवी
- समझाना
- बाहरी
- उद्धरण
- निष्कर्षण
- चेहरा
- सुविधा
- तथ्यात्मक
- Feature
- विशेषताएं
- कुछ
- खेत
- उंगलियों
- प्रथम
- लचीला
- प्रवाह
- तरल पदार्थ
- फोकस
- ध्यान केंद्रित
- के लिए
- प्रपत्र
- प्रारूप
- बुनियाद
- मूलभूत
- ढांचा
- आज़ादी से
- से
- कार्यक्षमता
- मौलिक
- आगे
- उत्पन्न
- सृजन
- पीढ़ी
- उत्पादक
- जनरेटिव एआई
- जनक
- मिल
- मिल रहा
- Go
- गूगल की
- मुट्ठी
- हाथ
- संभालना
- हैंडलिंग
- है
- होने
- he
- उसे
- इतिहास
- पकड़े
- क्षितिज
- घंटे
- कैसे
- How To
- HTTPS
- हब
- हगिंग फ़ेस
- मानव
- मैं करता हूँ
- विचार
- if
- आयात
- महत्वपूर्ण
- in
- असमर्थता
- शामिल
- सहित
- आवक
- शामिल
- अनुक्रमणिका
- व्यक्ति
- उद्योगों
- करें-
- की शुरुआत
- निवेश
- स्थापित
- उदाहरण
- सहायक
- घालमेल
- एकीकरण
- एकीकरण
- बुद्धि
- बातचीत
- बातचीत
- बातचीत
- बातचीत
- रुचि
- इंटरफेस
- इंटरफेस
- जोड़ने
- में
- जटिल
- सहज ज्ञान युक्त
- शामिल
- मुद्दा
- IT
- आईटी इस
- यात्रा
- JSON
- केवल
- केडनगेट्स
- कुंजी
- Instagram पर
- Kicks
- जानना
- जानने वाला
- परिदृश्य
- भाषा
- बड़ा
- प्रमुख
- सीख रहा हूँ
- बाएं
- लीवरेज
- जीवन
- पसंद
- पंक्तियां
- LINK
- लिंक्डइन
- जीवित
- लामा
- लंबा
- मशीन
- यंत्र अधिगम
- मुख्य
- बनाना
- बनाता है
- प्रबंधन
- कामयाब
- प्रबंध
- चालाकी से
- बहुत
- विपणन (मार्केटिंग)
- मई..
- साधन
- तंत्र
- तंत्र
- केवल
- मेटाडाटा
- तरीका
- हो सकता है
- गतिशीलता
- आदर्श
- मॉडल
- मॉड्यूलर
- मॉड्यूल
- मॉड्यूल
- अधिक
- अधिकांश
- my
- नामांकित
- देशी
- प्राकृतिक
- प्राकृतिक भाषा
- प्राकृतिक भाषा संसाधन
- आवश्यक
- आवश्यकता
- की जरूरत है
- नया
- समाचार
- बंधन
- अच्छा
- NLP
- अभी
- of
- की पेशकश
- अक्सर
- on
- एक बार
- खुला स्रोत
- OpenAI
- आपरेशन
- संचालन
- विकल्प
- or
- OS
- अन्य
- हमारी
- रूपरेखा
- उत्पादन
- outputs के
- बकाया
- प्राचल
- भाग
- विशेष
- भागों
- पैटर्न उपयोग करें
- स्टाफ़
- निष्पादन
- प्रदर्शन
- स्टाफ़
- व्यक्तिगत कम्प्यूटर्स
- मुहावरों
- भौतिक विज्ञान
- टुकड़े
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- प्ले
- कविता
- पदों
- संभावित
- ठीक - ठीक
- बेहतर
- मुख्य
- मुसीबत
- समस्याओं
- प्रक्रिया
- प्रसंस्करण
- उत्पादन
- प्रोग्रामिंग
- संकेतों
- प्रोटोटाइप
- प्रदान करना
- प्रदाताओं
- प्रदान करता है
- प्रदान कर
- अजगर
- प्रश्न
- जल्दी से
- बिल्कुल
- कच्चा
- क्षेत्र
- प्राप्त
- हाल
- संदर्भित करता है
- रिश्ते
- प्रासंगिक
- बार - बार आने वाला
- जवाब दें
- प्रतिनिधित्व
- अनुरोधों
- की आवश्यकता होती है
- आवश्यकता
- आवश्यकताएँ
- की आवश्यकता होती है
- उपयुक्त संसाधन चुनें
- प्रतिक्रिया
- प्रतिक्रिया
- प्रतिक्रियाएं
- जिम्मेदार
- बरकरार रखा
- वापसी
- रिटर्न
- क्रांति
- सही
- भूमिका
- s
- वही
- परिदृश्यों
- विज्ञान
- विज्ञान और प्रौद्योगिकी
- लिपियों
- Search
- खोजें
- सेक्टर्स
- लगता है
- भेजना
- भावुकता
- अनुक्रम
- कार्य करता है
- सेट
- सेट
- की स्थापना
- महत्वपूर्ण
- समान
- सरल
- सरल बनाने
- केवल
- स्थितियों
- So
- सॉफ्टवेयर
- समाधान
- समाधान ढूंढे
- कुछ
- परिष्कृत
- अंतरिक्ष
- विशेषीकृत
- माहिर
- विशिष्ट
- विनिर्दिष्ट
- ट्रेनिंग
- चरणों
- मानकीकरण
- शुरू
- फिर भी
- भंडारण
- की दुकान
- भंडार
- सुवीही
- व्यवस्थित बनाने
- तार
- संरचना
- संरचित
- संरचनाओं
- आगामी
- काफी हद तक
- ऐसा
- उपयुक्त
- की आपूर्ति
- निश्चित
- रेला
- प्रणाली
- सिस्टम
- तालिका
- अनुरूप
- लेना
- ले जा
- में बात कर
- कार्य
- कार्य
- प्रौद्योगिकीय
- टेक्नोलॉजी
- टेम्पलेट्स
- अस्थायी
- आदत
- टेक्स्ट
- शाब्दिक
- से
- कि
- RSI
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- वे
- बात
- इसका
- उन
- हालांकि?
- यहाँ
- इस प्रकार
- सेवा मेरे
- आज
- एक साथ
- उपकरण
- प्रशिक्षण
- बदालना
- परिवर्तनों
- ट्रान्सफ़ॉर्मर
- अनुवाद करें
- ट्यूटोरियल
- दो
- आम तौर पर
- समझना
- समझ
- अप्रयुक्त
- us
- प्रयोग करने योग्य
- उपयोग
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ताओं
- का उपयोग
- उपयोगिताओं
- उपयोग
- मान
- परिवर्तनशील
- विविधता
- विभिन्न
- व्यापक
- चंचलता
- बहुत
- के माध्यम से
- करना चाहते हैं
- मार्ग..
- तरीके
- we
- क्या
- एचएमबी क्या है?
- कब
- कौन कौन से
- पूरा का पूरा
- चौड़ा
- साथ में
- अंदर
- आश्चर्य
- शब्द
- वर्कफ़्लो
- workflows
- काम कर रहे
- अभी तक
- इसलिए आप
- आपका
- जेफिरनेट