ओपनएआई व्हिस्पर एमआईटी लाइसेंस के साथ एक उन्नत स्वचालित वाक् पहचान (एएसआर) मॉडल है। एएसआर तकनीक प्रतिलेखन सेवाओं, आवाज सहायकों और श्रवण बाधित व्यक्तियों के लिए पहुंच बढ़ाने में उपयोगिता पाती है। इस अत्याधुनिक मॉडल को वेब से एकत्र किए गए बहुभाषी और मल्टीटास्क पर्यवेक्षित डेटा के विशाल और विविध डेटासेट पर प्रशिक्षित किया गया है। इसकी उच्च सटीकता और अनुकूलनशीलता इसे आवाज से संबंधित कार्यों की एक विस्तृत श्रृंखला के लिए एक मूल्यवान संपत्ति बनाती है।
मशीन लर्निंग और कृत्रिम बुद्धिमत्ता के निरंतर विकसित होते परिदृश्य में, अमेज़न SageMaker एक व्यापक पारिस्थितिकी तंत्र प्रदान करता है। सेजमेकर डेटा वैज्ञानिकों, डेवलपर्स और संगठनों को बड़े पैमाने पर मशीन लर्निंग मॉडल विकसित करने, प्रशिक्षित करने, तैनात करने और प्रबंधित करने का अधिकार देता है। उपकरणों और क्षमताओं की एक विस्तृत श्रृंखला की पेशकश करते हुए, यह डेटा प्री-प्रोसेसिंग और मॉडल विकास से लेकर सहज तैनाती और निगरानी तक, संपूर्ण मशीन लर्निंग वर्कफ़्लो को सरल बनाता है। सेजमेकर का उपयोगकर्ता के अनुकूल इंटरफेस इसे एआई की पूरी क्षमता को अनलॉक करने के लिए एक महत्वपूर्ण मंच बनाता है, जो इसे कृत्रिम बुद्धिमत्ता के क्षेत्र में गेम-चेंजिंग समाधान के रूप में स्थापित करता है।
इस पोस्ट में, हमने सेजमेकर की क्षमताओं की खोज शुरू की है, विशेष रूप से व्हिस्पर मॉडल की मेजबानी पर ध्यान केंद्रित किया है। ऐसा करने के लिए हम दो तरीकों पर गहराई से विचार करेंगे: एक व्हिस्पर पायटोरच मॉडल का उपयोग करना और दूसरा व्हिस्पर मॉडल के हगिंग फेस कार्यान्वयन का उपयोग करना। इसके अतिरिक्त, हम सेजमेकर के अनुमान विकल्पों की गहन जांच करेंगे, उनकी तुलना गति, लागत, पेलोड आकार और स्केलेबिलिटी जैसे मापदंडों से करेंगे। यह विश्लेषण उपयोगकर्ताओं को व्हिस्पर मॉडल को उनके विशिष्ट उपयोग के मामलों और प्रणालियों में एकीकृत करते समय सूचित निर्णय लेने का अधिकार देता है।
समाधान अवलोकन
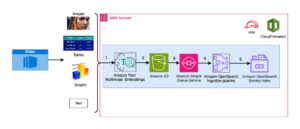
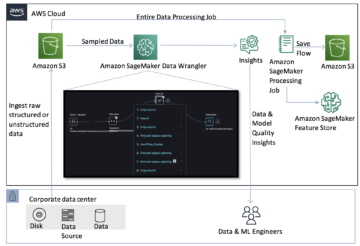
निम्नलिखित चित्र इस समाधान के मुख्य घटकों को दर्शाता है।
- अमेज़ॅन सेजमेकर पर मॉडल को होस्ट करने के लिए, पहला कदम मॉडल कलाकृतियों को सहेजना है। ये कलाकृतियाँ तैनाती और पुनर्प्रशिक्षण सहित विभिन्न अनुप्रयोगों के लिए आवश्यक मशीन लर्निंग मॉडल के आवश्यक घटकों को संदर्भित करती हैं। उनमें मॉडल पैरामीटर, कॉन्फ़िगरेशन फ़ाइलें, प्री-प्रोसेसिंग घटक, साथ ही मेटाडेटा, जैसे संस्करण विवरण, लेखकत्व और इसके प्रदर्शन से संबंधित कोई भी नोट्स शामिल हो सकते हैं। यह ध्यान रखना महत्वपूर्ण है कि PyTorch और हगिंग फेस कार्यान्वयन के लिए व्हिस्पर मॉडल में विभिन्न मॉडल कलाकृतियाँ शामिल हैं।
- इसके बाद, हम कस्टम अनुमान स्क्रिप्ट बनाते हैं। इन स्क्रिप्ट्स के भीतर, हम परिभाषित करते हैं कि मॉडल को कैसे लोड किया जाना चाहिए और अनुमान प्रक्रिया निर्दिष्ट करें। यह वह जगह भी है जहां हम आवश्यकतानुसार कस्टम पैरामीटर शामिल कर सकते हैं। इसके अतिरिक्त, आप आवश्यक पायथन पैकेजों को एक में सूचीबद्ध कर सकते हैं
requirements.txtफ़ाइल। मॉडल की तैनाती के दौरान, ये पायथन पैकेज प्रारंभिक चरण में स्वचालित रूप से स्थापित हो जाते हैं। - फिर हम या तो PyTorch या हगिंग फेस डीप लर्निंग कंटेनर (DLC) का चयन करते हैं जो प्रदान और रखरखाव किया जाता है एडब्ल्यूएस. ये कंटेनर गहन शिक्षण ढांचे और अन्य आवश्यक पायथन पैकेजों के साथ पूर्व-निर्मित डॉकर छवियां हैं। अधिक जानकारी के लिए आप इसे चेक कर सकते हैं संपर्क.
- मॉडल कलाकृतियों, कस्टम अनुमान स्क्रिप्ट और चयनित डीएलसी के साथ, हम क्रमशः PyTorch और Hugging Face के लिए Amazon SageMaker मॉडल बनाएंगे।
- अंत में, मॉडल को सेजमेकर पर तैनात किया जा सकता है और निम्नलिखित विकल्पों के साथ उपयोग किया जा सकता है: वास्तविक समय अनुमान समापन बिंदु, बैच ट्रांसफॉर्म नौकरियां, और अतुल्यकालिक अनुमान समापन बिंदु। हम इस पोस्ट में बाद में इन विकल्पों पर अधिक विस्तार से विचार करेंगे।
इस समाधान के लिए उदाहरण नोटबुक और कोड इस पर उपलब्ध हैं गिटहब भंडार.
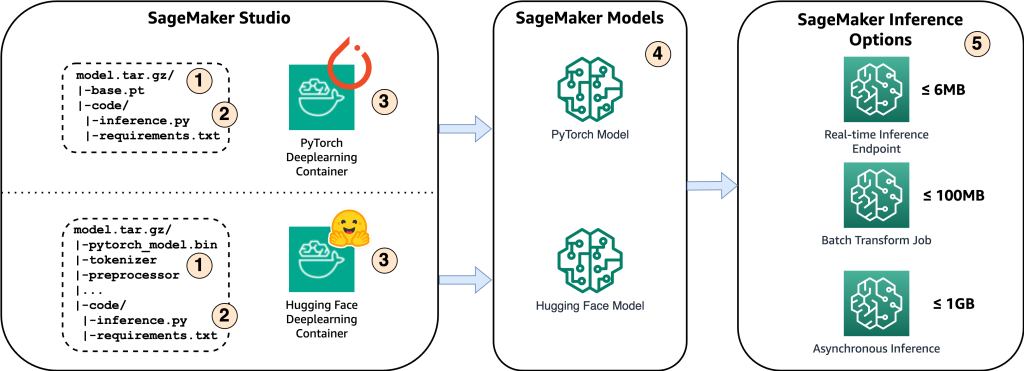
चित्र 1. प्रमुख समाधान घटकों का अवलोकन
Walkthrough
अमेज़ॅन सेजमेकर पर व्हिस्पर मॉडल की मेजबानी
इस अनुभाग में, हम क्रमशः PyTorch और Hugging Face Frameworks का उपयोग करके Amazon SageMaker पर व्हिस्पर मॉडल को होस्ट करने के चरणों की व्याख्या करेंगे। इस समाधान के साथ प्रयोग करने के लिए, आपको एक AWS खाता और Amazon SageMaker सेवा तक पहुंच की आवश्यकता होगी।
पायटोरच ढांचा
- मॉडल कलाकृतियाँ सहेजें
मॉडल को होस्ट करने का पहला विकल्प इसका उपयोग करना है व्हिस्पर आधिकारिक पायथन पैकेज, जिसका उपयोग करके स्थापित किया जा सकता है pip install openai-whisper. यह पैकेज एक PyTorch मॉडल प्रदान करता है। स्थानीय रिपॉजिटरी में मॉडल कलाकृतियों को सहेजते समय, पहला कदम मॉडल के सीखने योग्य मापदंडों, जैसे कि तंत्रिका नेटवर्क में प्रत्येक परत के मॉडल वजन और पूर्वाग्रह को 'पीटी' फ़ाइल के रूप में सहेजना है। आप विभिन्न मॉडल आकारों में से चुन सकते हैं, जिनमें 'छोटा,' 'आधार,' 'छोटा,' 'मध्यम,' और 'बड़ा' शामिल हैं। बड़े मॉडल आकार उच्च सटीकता प्रदर्शन प्रदान करते हैं, लेकिन लंबी अनुमान विलंबता की कीमत पर आते हैं। इसके अतिरिक्त, आपको मॉडल स्टेट डिक्शनरी और डायमेंशन डिक्शनरी को सहेजना होगा, जिसमें एक पायथन डिक्शनरी शामिल है जो अन्य मेटाडेटा और कस्टम कॉन्फ़िगरेशन के साथ, PyTorch मॉडल की प्रत्येक परत या पैरामीटर को उसके संबंधित सीखने योग्य पैरामीटर पर मैप करती है। नीचे दिया गया कोड दिखाता है कि व्हिस्पर PyTorch कलाकृतियों को कैसे सहेजा जाए।
- डीएलसी चुनें
अगला कदम इसमें से पूर्व-निर्मित डीएलसी का चयन करना है संपर्क. निम्नलिखित सेटिंग्स पर विचार करके सही छवि चुनते समय सावधान रहें: फ्रेमवर्क (PyTorch), फ्रेमवर्क संस्करण, कार्य (अनुमान), पायथन संस्करण, और हार्डवेयर (यानी, GPU)। जब भी संभव हो फ्रेमवर्क और पायथन के लिए नवीनतम संस्करणों का उपयोग करने की अनुशंसा की जाती है, क्योंकि इससे बेहतर प्रदर्शन होता है और पिछले रिलीज से ज्ञात समस्याओं और बग का समाधान होता है।
- अमेज़ॅन सेजमेकर मॉडल बनाएं
अगला, हम इसका उपयोग करते हैं सेजमेकर पायथन एसडीके PyTorch मॉडल बनाने के लिए। PyTorch मॉडल बनाते समय पर्यावरण चर जोड़ना याद रखना महत्वपूर्ण है। डिफ़ॉल्ट रूप से, TorchServe केवल 6MB तक फ़ाइल आकार को संसाधित कर सकता है, उपयोग किए गए अनुमान प्रकार की परवाह किए बिना।
निम्न तालिका विभिन्न PyTorch संस्करणों के लिए सेटिंग्स दिखाती है:
| ढांचा | पर्यावरण चर |
| PyTorch 1.8 (TorchServe पर आधारित) | 'TS_MAX_REQUEST_SIZE': '100000000'' TS_MAX_RESPONSE_SIZE': '100000000'' TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (MMS पर आधारित) | 'MMS_MAX_REQUEST_SIZE': '1000000000'' MMS_MAX_RESPONSE_SIZE': '1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Inference.py में मॉडल लोडिंग विधि को परिभाषित करें
रिवाज में inference.py स्क्रिप्ट, हम पहले CUDA-सक्षम GPU की उपलब्धता की जाँच करते हैं। यदि ऐसा कोई GPU उपलब्ध है, तो हम असाइन करते हैं 'cuda' डिवाइस को DEVICE चर; अन्यथा, हम असाइन करते हैं 'cpu' उपकरण। यह चरण सुनिश्चित करता है कि मॉडल को कुशल गणना के लिए उपलब्ध हार्डवेयर पर रखा गया है। हम व्हिस्पर पायथन पैकेज का उपयोग करके PyTorch मॉडल को लोड करते हैं।
हगिंग फेस फ्रेमवर्क
- मॉडल कलाकृतियाँ सहेजें
दूसरा विकल्प उपयोग करना है गले मिलते चेहरे की फुसफुसाहट कार्यान्वयन। का उपयोग करके मॉडल को लोड किया जा सकता है AutoModelForSpeechSeq2Seq ट्रांसफार्मर वर्ग. सीखने योग्य पैरामीटर को बाइनरी (बिन) फ़ाइल में सहेजा जाता है save_pretrained तरीका। हगिंग फेस मॉडल ठीक से काम करता है यह सुनिश्चित करने के लिए टोकननाइज़र और प्रीप्रोसेसर को भी अलग से सहेजने की आवश्यकता है। वैकल्पिक रूप से, आप दो पर्यावरण चर सेट करके सीधे हगिंग फेस हब से अमेज़ॅन सेजमेकर पर एक मॉडल तैनात कर सकते हैं: HF_MODEL_ID और HF_TASK. अधिक जानकारी के लिए कृपया इसे देखें वेबपेज.
- डीएलसी चुनें
PyTorch फ्रेमवर्क के समान, आप उसी में से एक पूर्व-निर्मित हगिंग फेस DLC चुन सकते हैं संपर्क. एक डीएलसी का चयन करना सुनिश्चित करें जो नवीनतम हगिंग फेस ट्रांसफार्मर का समर्थन करता है और इसमें जीपीयू समर्थन शामिल है।
- अमेज़ॅन सेजमेकर मॉडल बनाएं
इसी प्रकार, हम इसका उपयोग करते हैं सेजमेकर पायथन एसडीके हगिंग फेस मॉडल बनाने के लिए। हगिंग फेस व्हिस्पर मॉडल में एक डिफ़ॉल्ट सीमा है जहां यह केवल 30 सेकंड तक के ऑडियो सेगमेंट को संसाधित कर सकता है। इस सीमा को संबोधित करने के लिए, आप इसे शामिल कर सकते हैं chunk_length_s हगिंग फेस मॉडल बनाते समय पर्यावरण चर में पैरामीटर, और बाद में मॉडल लोड करते समय इस पैरामीटर को कस्टम अनुमान स्क्रिप्ट में पास करें। अंत में, हगिंग फेस कंटेनर के लिए पेलोड आकार और प्रतिक्रिया टाइमआउट बढ़ाने के लिए पर्यावरण चर सेट करें।
| ढांचा | पर्यावरण चर |
|
हगिंगफेस अनुमान कंटेनर (एमएमएस पर आधारित) |
'MMS_MAX_REQUEST_SIZE': '2000000000'' MMS_MAX_RESPONSE_SIZE': '2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Inference.py में मॉडल लोडिंग विधि को परिभाषित करें
हगिंग फेस मॉडल के लिए कस्टम अनुमान स्क्रिप्ट बनाते समय, हम एक पाइपलाइन का उपयोग करते हैं, जो हमें पास करने की अनुमति देती है chunk_length_s एक पैरामीटर के रूप में. यह पैरामीटर मॉडल को अनुमान के दौरान लंबी ऑडियो फ़ाइलों को कुशलतापूर्वक संसाधित करने में सक्षम बनाता है।
Amazon SageMaker पर विभिन्न अनुमान विकल्पों की खोज
PyTorch और Hugging Face मॉडल दोनों के लिए अनुमान विकल्प चुनने के चरण समान हैं, इसलिए हम नीचे उनके बीच अंतर नहीं करेंगे। हालाँकि, यह ध्यान देने योग्य है कि, इस पोस्ट को लिखने के समय, सर्वर रहित अनुमान सेजमेकर का विकल्प जीपीयू का समर्थन नहीं करता है, और परिणामस्वरूप, हम इस उपयोग-मामले के लिए इस विकल्प को बाहर कर देते हैं।
हम मॉडल को वास्तविक समय के समापन बिंदु के रूप में तैनात कर सकते हैं, जो मिलीसेकंड में प्रतिक्रियाएँ प्रदान करता है। हालाँकि, यह ध्यान रखना महत्वपूर्ण है कि यह विकल्प 6 एमबी से कम के प्रोसेसिंग इनपुट तक सीमित है। हम सीरिएलाइज़र को एक ऑडियो सीरिएलाइज़र के रूप में परिभाषित करते हैं, जो इनपुट डेटा को तैनात मॉडल के लिए उपयुक्त प्रारूप में परिवर्तित करने के लिए जिम्मेदार है। हम अनुमान के लिए एक GPU इंस्टेंस का उपयोग करते हैं, जिससे ऑडियो फ़ाइलों की त्वरित प्रोसेसिंग की अनुमति मिलती है। अनुमान इनपुट एक ऑडियो फ़ाइल है जो स्थानीय रिपॉजिटरी से है।
दूसरा अनुमान विकल्प बैच ट्रांसफॉर्म जॉब है, जो 100 एमबी तक इनपुट पेलोड को संसाधित करने में सक्षम है। हालाँकि, इस विधि में कुछ मिनट का विलंब हो सकता है। प्रत्येक इंस्टेंस एक समय में केवल एक बैच अनुरोध को संभाल सकता है, और इंस्टेंस की शुरुआत और शटडाउन के लिए भी कुछ मिनटों की आवश्यकता होती है। अनुमान परिणाम अमेज़ॅन सिंपल स्टोरेज सर्विस में सहेजे जाते हैं (अमेज़न S3) बैच ट्रांसफ़ॉर्म कार्य पूरा होने पर बकेट।
बैच ट्रांसफार्मर को कॉन्फ़िगर करते समय, शामिल करना सुनिश्चित करें max_payload = 100 बड़े पेलोड को प्रभावी ढंग से संभालने के लिए। अनुमान इनपुट किसी ऑडियो फ़ाइल के लिए Amazon S3 पथ या Amazon S3 बकेट फ़ोल्डर होना चाहिए जिसमें ऑडियो फ़ाइलों की सूची हो, जिनमें से प्रत्येक का आकार 100 एमबी से छोटा हो।
बैच ट्रांसफॉर्म कुंजी द्वारा इनपुट में अमेज़ॅन एस 3 ऑब्जेक्ट्स को विभाजित करता है और अमेज़ॅन एस 3 ऑब्जेक्ट्स को उदाहरणों में मैप करता है। उदाहरण के लिए, जब आपके पास कई ऑडियो फ़ाइलें होती हैं, तो एक इंस्टेंस इनपुट1.wav को प्रोसेस कर सकता है, और दूसरा इंस्टेंस स्केलेबिलिटी बढ़ाने के लिए इनपुट2.wav नाम की फ़ाइल को प्रोसेस कर सकता है। बैच ट्रांसफ़ॉर्म आपको कॉन्फ़िगर करने की अनुमति देता है max_concurrent_transforms प्रत्येक व्यक्तिगत ट्रांसफार्मर कंटेनर में किए गए HTTP अनुरोधों की संख्या बढ़ाने के लिए। हालाँकि, यह ध्यान रखना महत्वपूर्ण है कि (max_concurrent_transforms* max_payload) 100 एमबी से अधिक नहीं होना चाहिए।
अंत में, अमेज़ॅन सेजमेकर एसिंक्रोनस इंट्रेंस एक साथ कई अनुरोधों को संसाधित करने, मध्यम विलंबता की पेशकश करने और 1 जीबी तक के इनपुट पेलोड का समर्थन करने के लिए आदर्श है। यह विकल्प उत्कृष्ट स्केलेबिलिटी प्रदान करता है, जो एंडपॉइंट के लिए ऑटोस्केलिंग समूह के कॉन्फ़िगरेशन को सक्षम करता है। जब अनुरोधों में वृद्धि होती है, तो ट्रैफ़िक को संभालने के लिए यह स्वचालित रूप से बढ़ जाता है, और एक बार सभी अनुरोध संसाधित हो जाने पर, लागत बचाने के लिए समापन बिंदु 0 तक कम हो जाता है।
एसिंक्रोनस अनुमान का उपयोग करके, परिणाम स्वचालित रूप से अमेज़ॅन S3 बकेट में सहेजे जाते हैं। में AsyncInferenceConfig, आप सफल या असफल पूर्णताओं के लिए सूचनाएं कॉन्फ़िगर कर सकते हैं। इनपुट पथ ऑडियो फ़ाइल के Amazon S3 स्थान की ओर इंगित करता है। अतिरिक्त विवरण के लिए, कृपया कोड देखें GitHub.
वैकल्पिक: जैसा कि पहले उल्लेख किया गया है, हमारे पास अतुल्यकालिक अनुमान समापन बिंदु के लिए एक ऑटोस्केलिंग समूह को कॉन्फ़िगर करने का विकल्प है, जो इसे अनुमान अनुरोधों में अचानक वृद्धि को संभालने की अनुमति देता है। इसमें एक कोड उदाहरण दिया गया है गिटहब भंडार. निम्नलिखित आरेख में, आप दो मीट्रिक प्रदर्शित करने वाला एक लाइन चार्ट देख सकते हैं अमेज़ॅन क्लाउडवॉच: ApproximateBacklogSize और ApproximateBacklogSizePerInstance. प्रारंभ में, जब 1000 अनुरोध ट्रिगर किए गए थे, तो अनुमान को संभालने के लिए केवल एक उदाहरण उपलब्ध था। तीन मिनट के लिए, बैकलॉग का आकार लगातार तीन से अधिक हो गया (कृपया ध्यान दें कि इन नंबरों को कॉन्फ़िगर किया जा सकता है), और ऑटोस्केलिंग समूह ने बैकलॉग को कुशलतापूर्वक साफ़ करने के लिए अतिरिक्त उदाहरणों को स्पिन करके प्रतिक्रिया दी। इसके परिणामस्वरूप इसमें उल्लेखनीय कमी आई ApproximateBacklogSizePerInstance, प्रारंभिक चरण की तुलना में बैकलॉग अनुरोधों को बहुत तेजी से संसाधित करने की अनुमति देता है।

चित्र 2. अमेज़ॅन क्लाउडवॉच मेट्रिक्स में अस्थायी परिवर्तनों को दर्शाने वाला लाइन चार्ट
अनुमान विकल्पों के लिए तुलनात्मक विश्लेषण
विभिन्न अनुमान विकल्पों की तुलना सामान्य ऑडियो प्रोसेसिंग उपयोग मामलों पर आधारित है। वास्तविक समय अनुमान सबसे तेज़ अनुमान गति प्रदान करता है लेकिन पेलोड आकार को 6 एमबी तक सीमित रखता है। यह अनुमान प्रकार ऑडियो कमांड सिस्टम के लिए उपयुक्त है, जहां उपयोगकर्ता वॉयस कमांड या बोले गए निर्देशों का उपयोग करके डिवाइस या सॉफ़्टवेयर को नियंत्रित या इंटरैक्ट करते हैं। ध्वनि आदेश आम तौर पर आकार में छोटे होते हैं, और कम अनुमान विलंबता यह सुनिश्चित करने के लिए महत्वपूर्ण है कि लिखित आदेश तुरंत बाद की कार्रवाइयों को ट्रिगर कर सकें। बैच ट्रांसफ़ॉर्म निर्धारित ऑफ़लाइन कार्यों के लिए आदर्श है, जब प्रत्येक ऑडियो फ़ाइल का आकार 100 एमबी से कम होता है, और तेज़ अनुमान प्रतिक्रिया समय के लिए कोई विशिष्ट आवश्यकता नहीं होती है। अतुल्यकालिक अनुमान 1 जीबी तक के अपलोड की अनुमति देता है और मध्यम अनुमान विलंबता प्रदान करता है। यह अनुमान प्रकार फिल्मों, टीवी श्रृंखलाओं और रिकॉर्ड किए गए सम्मेलनों को ट्रांसक्रिप्ट करने के लिए उपयुक्त है जहां बड़ी ऑडियो फ़ाइलों को संसाधित करने की आवश्यकता होती है।
वास्तविक समय और अतुल्यकालिक अनुमान विकल्प दोनों ऑटोस्केलिंग क्षमताएं प्रदान करते हैं, जिससे अनुरोधों की मात्रा के आधार पर एंडपॉइंट इंस्टेंस को स्वचालित रूप से ऊपर या नीचे स्केल करने की अनुमति मिलती है। बिना अनुरोध वाले मामलों में, ऑटोस्केलिंग अनावश्यक उदाहरणों को हटा देती है, जिससे आपको प्रावधानित उदाहरणों से जुड़ी लागतों से बचने में मदद मिलती है जो सक्रिय रूप से उपयोग में नहीं हैं। हालाँकि, वास्तविक समय के अनुमान के लिए, कम से कम एक निरंतर उदाहरण को बरकरार रखा जाना चाहिए, जिससे समापन बिंदु लगातार संचालित होने पर उच्च लागत हो सकती है। इसके विपरीत, अतुल्यकालिक अनुमान उपयोग में न होने पर इंस्टेंस वॉल्यूम को 0 तक कम करने की अनुमति देता है। बैच ट्रांसफॉर्म जॉब को कॉन्फ़िगर करते समय, जॉब को प्रोसेस करने के लिए कई इंस्टेंस का उपयोग करना और एक इंस्टेंस को कई अनुरोधों को संभालने में सक्षम करने के लिए max_concurrent_transforms को समायोजित करना संभव है। इसलिए, सभी तीन अनुमान विकल्प बड़ी मापनीयता प्रदान करते हैं।
सफाई करना
एक बार जब आप समाधान का उपयोग पूरा कर लें, तो अतिरिक्त लागत से बचने के लिए सेजमेकर एंडपॉइंट को हटाना सुनिश्चित करें। आप क्रमशः वास्तविक समय और अतुल्यकालिक अनुमान समापन बिंदुओं को हटाने के लिए दिए गए कोड का उपयोग कर सकते हैं।
निष्कर्ष
इस पोस्ट में, हमने आपको दिखाया कि कैसे विभिन्न उद्योगों में ऑडियो प्रोसेसिंग के लिए मशीन लर्निंग मॉडल तैनात करना आवश्यक हो गया है। व्हिस्पर मॉडल को एक उदाहरण के रूप में लेते हुए, हमने प्रदर्शित किया कि कैसे PyTorch या हगिंग फेस दृष्टिकोण का उपयोग करके Amazon SageMaker पर ओपन-सोर्स ASR मॉडल होस्ट किया जाए। अन्वेषण में अमेज़ॅन सेजमेकर पर विभिन्न अनुमान विकल्प शामिल थे, जो ऑडियो डेटा को कुशलतापूर्वक संभालने, भविष्यवाणियां करने और लागतों को प्रभावी ढंग से प्रबंधित करने में अंतर्दृष्टि प्रदान करते थे। इस पोस्ट का उद्देश्य ऑडियो-संबंधित कार्यों के लिए व्हिस्पर मॉडल का लाभ उठाने और अनुमान रणनीतियों पर सूचित निर्णय लेने में रुचि रखने वाले शोधकर्ताओं, डेवलपर्स और डेटा वैज्ञानिकों के लिए ज्ञान प्रदान करना है।
सेजमेकर पर मॉडल तैनात करने के बारे में अधिक विस्तृत जानकारी के लिए, कृपया इसे देखें डेवलपर गाइड. इसके अतिरिक्त, व्हिस्पर मॉडल को सेजमेकर जम्पस्टार्ट का उपयोग करके तैनात किया जा सकता है। अतिरिक्त विवरण के लिए, कृपया जाँच करें स्वचालित वाक् पहचान के लिए व्हिस्पर मॉडल अब अमेज़न सेजमेकर जम्पस्टार्ट में उपलब्ध हैं पद।
बेझिझक इस प्रोजेक्ट के लिए नोटबुक और कोड देखें GitHub और अपनी टिप्पणी हमारे साथ साझा करें।
लेखक के बारे में
 यिंग होउ, पीएचडी, AWS में मशीन लर्निंग प्रोटोटाइपिंग आर्किटेक्ट हैं। उनकी रुचि के प्राथमिक क्षेत्रों में जेनएआई, कंप्यूटर विजन, एनएलपी और समय श्रृंखला डेटा भविष्यवाणी पर ध्यान देने के साथ डीप लर्निंग शामिल है। अपने खाली समय में, वह अपने परिवार के साथ अच्छे पल बिताना, उपन्यासों में डूबना और यूके के राष्ट्रीय उद्यानों में घूमना पसंद करती हैं।
यिंग होउ, पीएचडी, AWS में मशीन लर्निंग प्रोटोटाइपिंग आर्किटेक्ट हैं। उनकी रुचि के प्राथमिक क्षेत्रों में जेनएआई, कंप्यूटर विजन, एनएलपी और समय श्रृंखला डेटा भविष्यवाणी पर ध्यान देने के साथ डीप लर्निंग शामिल है। अपने खाली समय में, वह अपने परिवार के साथ अच्छे पल बिताना, उपन्यासों में डूबना और यूके के राष्ट्रीय उद्यानों में घूमना पसंद करती हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- त्वरित
- पहुँच
- एक्सेसिबिलिटी
- लेखा
- शुद्धता
- के पार
- कार्रवाई
- सक्रिय रूप से
- जोड़ना
- अतिरिक्त
- इसके अतिरिक्त
- पता
- को समायोजित
- उन्नत
- AI
- करना
- सब
- की अनुमति दे
- की अनुमति देता है
- साथ में
- भी
- वीरांगना
- अमेज़न SageMaker
- अमेज़ॅन वेब सेवा
- an
- विश्लेषण
- और
- अन्य
- कोई
- अनुप्रयोगों
- दृष्टिकोण
- हैं
- क्षेत्रों के बारे में जानकारी का उपयोग करके ट्रेडिंग कर सकते हैं।
- ऐरे
- कृत्रिम
- कृत्रिम बुद्धिमत्ता
- AS
- आस्ति
- सहायकों
- जुड़े
- At
- ऑडियो
- ग्रन्थकारिता
- स्वचालित
- स्वतः
- उपलब्धता
- उपलब्ध
- से बचने
- एडब्ल्यूएस
- आधार
- आधारित
- BE
- बन
- नीचे
- बेहतर
- के बीच
- पूर्वाग्रहों
- बिन
- के छात्रों
- कीड़े
- लेकिन
- by
- कर सकते हैं
- क्षमताओं
- सक्षम
- सावधान
- मामलों
- परिवर्तन
- चार्ट
- चेक
- चुनें
- चुनने
- कक्षा
- स्पष्ट
- कोड
- कैसे
- टिप्पणी
- सामान्य
- की तुलना
- तुलना
- पूरा
- समापन
- घटकों
- व्यापक
- गणना
- कंप्यूटर
- Computer Vision
- आचरण
- सम्मेलनों
- विन्यास
- कॉन्फ़िगर किया गया
- को विन्यस्त
- पर विचार
- लगातार
- शामिल
- कंटेनर
- कंटेनरों
- लगातार
- इसके विपरीत
- नियंत्रण
- परिवर्तित
- सही
- इसी
- लागत
- लागत
- सका
- सी पी यू
- बनाना
- बनाना
- महत्वपूर्ण
- रिवाज
- तिथि
- निर्णय
- कमी
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- चूक
- परिभाषित
- साबित
- तैनात
- तैनात
- तैनाती
- तैनाती
- विस्तार
- विस्तृत
- विवरण
- विकसित करना
- डेवलपर्स
- विकास
- युक्ति
- डिवाइस
- विभिन्न
- में अंतर
- आयाम
- सीधे
- प्रदर्शित
- डुबकी
- कई
- डाक में काम करनेवाला मज़दूर
- नहीं करता है
- कर
- नीचे
- दौरान
- e
- से प्रत्येक
- पूर्व
- पारिस्थितिकी तंत्र
- प्रभावी रूप से
- कुशल
- कुशलता
- सरल
- भी
- अन्य
- प्रारंभ
- अधिकार
- सक्षम
- सक्षम बनाता है
- समर्थकारी
- धरना
- endpoint
- अंतबिंदु
- बढ़ाना
- बढ़ाने
- सुनिश्चित
- सुनिश्चित
- संपूर्ण
- वातावरण
- आवश्यक
- स्थापना
- ईथर (ईटीएच)
- परीक्षा
- उदाहरण
- से अधिक
- को पार कर
- उत्कृष्ट
- प्रयोग
- समझाना
- अन्वेषण
- तलाश
- चेहरा
- विफल रहे
- असत्य
- परिवार
- फास्ट
- और तेज
- सबसे तेजी से
- कुछ
- पट्टिका
- फ़ाइलें
- पाता
- प्रथम
- फोकस
- ध्यान केंद्रित
- निम्नलिखित
- के लिए
- प्रारूप
- ढांचा
- चौखटे
- मुक्त
- से
- पूर्ण
- GPU
- GPUs
- महान
- समूह
- संभालना
- हैंडलिंग
- हार्डवेयर
- है
- सुनवाई
- मदद
- उसे
- हाई
- उच्चतर
- हाइकिंग
- मेजबान
- होस्टिंग
- कैसे
- How To
- तथापि
- एचटीएमएल
- http
- HTTPS
- हब
- हगिंग फ़ेस
- i
- आदर्श
- if
- illustrating
- की छवि
- छवियों
- कार्यान्वयन
- कार्यान्वयन
- आयात
- महत्वपूर्ण
- in
- में गहराई
- शामिल
- शामिल
- सहित
- सम्मिलित
- बढ़ना
- तेजी
- व्यक्ति
- व्यक्तियों
- उद्योगों
- करें-
- सूचित
- प्रारंभिक
- शुरू में
- शुरूआत
- निवेश
- निविष्टियां
- अंतर्दृष्टि
- स्थापित
- उदाहरण
- उदाहरणों
- निर्देश
- घालमेल
- बुद्धि
- बातचीत
- ब्याज
- रुचि
- इंटरफेस
- में
- मुद्दों
- IT
- आईटी इस
- काम
- नौकरियां
- जेपीजी
- कुंजी
- ज्ञान
- जानने वाला
- परिदृश्य
- बड़ा
- अंततः
- विलंब
- बाद में
- ताज़ा
- परत
- नेतृत्व
- सीख रहा हूँ
- कम से कम
- लाभ
- लाइसेंस
- सीमा
- सीमित
- लाइन
- सूची
- भार
- लोड हो रहा है
- स्थानीय
- स्थान
- लंबा
- लंबे समय तक
- निम्न
- मशीन
- यंत्र अधिगम
- बनाया गया
- मुख्य
- बनाना
- बनाता है
- निर्माण
- प्रबंधन
- प्रबंध
- मैप्स
- मई..
- उल्लेख किया
- मेटाडाटा
- तरीका
- तरीकों
- मेट्रिक्स
- हो सकता है
- मिलीसेकेंड
- मिनट
- एमआईटी
- ML
- आदर्श
- मॉडल
- मध्यम
- लम्हें
- निगरानी
- अधिक
- चलचित्र
- बहुत
- विभिन्न
- चाहिए
- नामांकित
- राष्ट्रीय
- राष्ट्रीय उद्यान
- आवश्यक
- आवश्यकता
- जरूरत
- नेटवर्क
- तंत्रिका
- तंत्रिका नेटवर्क
- अगला
- NLP
- नहीं
- नोट
- नोटबुक
- नोट्स
- अधिसूचना
- सूचनाएं
- ध्यान देने योग्य बात
- अभी
- संख्या
- संख्या
- वस्तु
- वस्तुओं
- निरीक्षण
- of
- प्रस्ताव
- की पेशकश
- ऑफर
- सरकारी
- ऑफ़लाइन
- on
- एक बार
- ONE
- केवल
- खुला स्रोत
- संचालित
- विकल्प
- ऑप्शंस
- or
- आदेश
- संगठनों
- OS
- अन्य
- अन्यथा
- आउट
- सिंहावलोकन
- पैकेज
- संकुल
- प्राचल
- पैरामीटर
- पार्कों
- पास
- पथ
- निष्पादन
- प्रदर्शन
- चरण
- पाइपलाइन
- केंद्रीय
- रखा हे
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- कृप्या अ
- अंक
- संभव
- पद
- संभावित
- भविष्यवाणी
- भविष्यवाणियों
- को रोकने के
- पिछला
- प्राथमिक
- प्रक्रिया
- संसाधित
- प्रसंस्करण
- प्रोसेसर
- परियोजना
- अच्छी तरह
- प्रोटोटाइप
- प्रदान करना
- बशर्ते
- प्रदान करता है
- प्रदान कर
- अजगर
- pytorch
- गुणवत्ता
- रेंज
- वास्तविक समय
- क्षेत्र
- मान्यता
- की सिफारिश की
- दर्ज
- घटी
- उल्लेख
- भले ही
- सम्बंधित
- विज्ञप्ति
- याद
- हटाना
- हटा देगा
- कोष
- का अनुरोध
- अनुरोधों
- की आवश्यकता होती है
- अपेक्षित
- आवश्यकता
- शोधकर्ताओं
- क्रमश
- प्रतिक्रिया
- प्रतिक्रियाएं
- जिम्मेदार
- परिणाम
- परिणामस्वरूप
- परिणाम
- बरकरार रखा
- फिर से शिक्षित करना
- वापसी
- sagemaker
- वही
- सहेजें
- बचाया
- बचत
- अनुमापकता
- स्केल
- तराजू
- अनुसूचित
- वैज्ञानिकों
- लिपि
- लिपियों
- दूसरा
- सेकंड
- अनुभाग
- खंड
- चयन
- चयनित
- का चयन
- कई
- सेवा
- सेवाएँ
- सेट
- की स्थापना
- सेटिंग्स
- Share
- वह
- चाहिए
- पता चला
- दिखाता है
- शटडाउन
- महत्वपूर्ण
- सरल
- सरल
- आकार
- आकार
- छोटा
- छोटे
- So
- सॉफ्टवेयर
- समाधान
- विशिष्ट
- विशेष रूप से
- विनिर्दिष्ट
- भाषण
- वाक् पहचान
- गति
- खर्च
- बात
- प्रारंभ
- राज्य
- राज्य के-the-कला
- कदम
- कदम
- भंडारण
- रणनीतियों
- आगामी
- सफल
- ऐसा
- अचानक
- उपयुक्त
- समर्थन
- सहायक
- समर्थन करता है
- निश्चित
- रेला
- सिस्टम
- तालिका
- लेना
- ले जा
- कार्य
- कार्य
- टेक्नोलॉजी
- से
- कि
- RSI
- यूके
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इसलिये
- इन
- वे
- इसका
- तीन
- पहर
- समय श्रृंखला
- बार
- सेवा मेरे
- उपकरण
- मशाल
- यातायात
- रेलगाड़ी
- प्रशिक्षित
- बदालना
- ट्रांसफार्मर
- ट्रान्सफ़ॉर्मर
- ट्रिगर
- शुरू हो रहा
- tv
- टी वी श्रृंखला
- दो
- टाइप
- आम तौर पर
- Uk
- के अंतर्गत
- अनलॉकिंग
- के ऊपर
- us
- उपयोग
- प्रयुक्त
- उपयोगकर्ता के अनुकूल
- उपयोगकर्ताओं
- का उपयोग
- उपयोगिता
- उपयोग
- उपयोग
- मूल्यवान
- मूल्य
- परिवर्तनशील
- विभिन्न
- व्यापक
- संस्करण
- दृष्टि
- आवाज़
- मौखिक आदेश
- आयतन
- प्रतीक्षा
- करना चाहते हैं
- था
- we
- वेब
- वेब सेवाओं
- कुंआ
- थे
- कब
- जब कभी
- कौन कौन से
- फुसफुसाना
- चौड़ा
- विस्तृत श्रृंखला
- साथ में
- अंदर
- वर्कफ़्लो
- कार्य
- लायक
- लिख रहे हैं
- इसलिए आप
- आपका
- जेफिरनेट