इस लेख में हम जानेंगे अपने केवल CPU कंप्यूटर पर GPT4All मॉडल को कैसे परिनियोजित और उपयोग करें (मैं एक का उपयोग कर रहा हूँ मैकबुक प्रो जीपीयू के बिना!)

अपने कंप्यूटर पर GPT4All का उपयोग करें — लेखक द्वारा चित्र
इस लेख में हम अपने स्थानीय कंप्यूटर GPT4All (एक शक्तिशाली एलएलएम) पर स्थापित करने जा रहे हैं और हम पायथॉन के साथ अपने दस्तावेज़ों के साथ इंटरैक्ट करने का तरीका जानेंगे। PDF या ऑनलाइन लेखों का संग्रह हमारे प्रश्न/उत्तरों के लिए ज्ञान का आधार होगा।
से आधिकारिक वेबसाइट GPT4All इसे इस रूप में वर्णित किया गया है उपयोग में आसान, स्थानीय रूप से चलने वाला, गोपनीयता-जागरूक चैटबॉट। किसी GPU या इंटरनेट की आवश्यकता नहीं है।
GTP4All प्रशिक्षण और परिनियोजन के लिए एक पारिस्थितिकी तंत्र है शक्तिशाली और अनुकूलित बड़े भाषा मॉडल जो चलते हैं स्थानीय स्तर पर उपभोक्ता ग्रेड सीपीयू पर।
हमारा GPT4All मॉडल एक 4GB फ़ाइल है जिसे आप डाउनलोड कर सकते हैं और GPT4All ओपन-सोर्स इकोसिस्टम सॉफ़्टवेयर में प्लग इन कर सकते हैं। नॉमिक एआई उच्च गुणवत्ता और सुरक्षित सॉफ्टवेयर पारिस्थितिक तंत्र की सुविधा प्रदान करता है, जिससे व्यक्तियों और संगठनों को स्थानीय स्तर पर अपने स्वयं के बड़े भाषा मॉडल को सहजता से प्रशिक्षित करने और लागू करने में सक्षम बनाने का प्रयास किया जाता है।
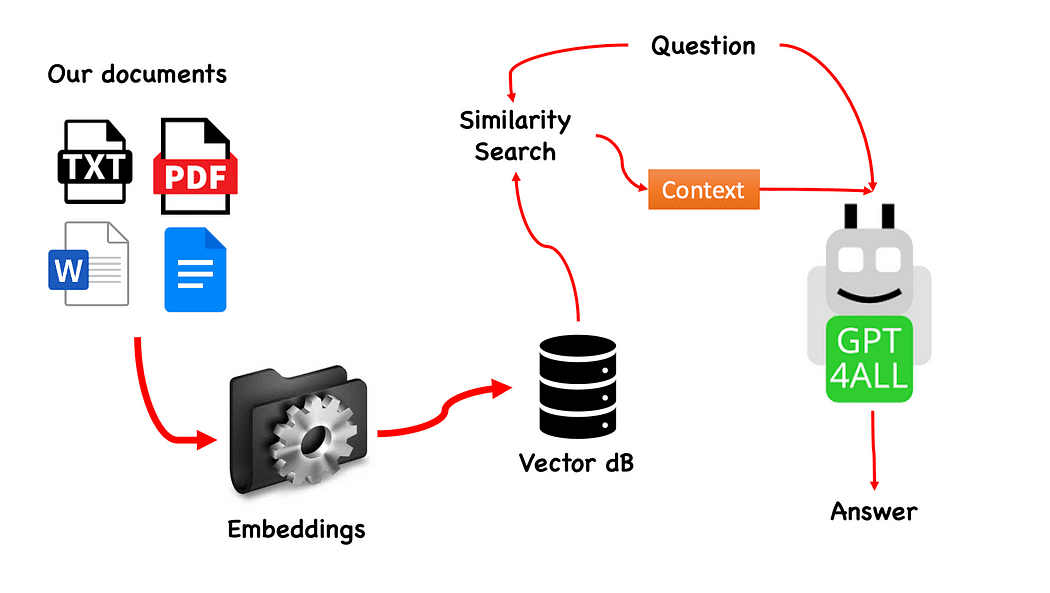
GPT4All के साथ QnA का वर्कफ़्लो — लेखक द्वारा बनाया गया
प्रक्रिया वास्तव में सरल है (जब आप इसे जानते हैं) और अन्य मॉडलों के साथ भी दोहराया जा सकता है। कदम इस प्रकार हैं:
- GPT4All मॉडल लोड करें
- उपयोग लैंगचैन हमारे दस्तावेजों को पुनः प्राप्त करने और उन्हें लोड करने के लिए
- एम्बेडिंग द्वारा सुपाच्य दस्तावेजों को छोटे टुकड़ों में विभाजित करें
- एम्बेडिंग के साथ हमारा वेक्टर डेटाबेस बनाने के लिए FAISS का उपयोग करें
- हम जिस प्रश्न को GPT4All को पास करना चाहते हैं, उसके आधार पर हमारे वेक्टर डेटाबेस पर एक समानता खोज (सिमेंटिक खोज) करें: इसका उपयोग एक के रूप में किया जाएगा प्रसंग हमारे प्रश्न के लिए
- प्रश्न और संदर्भ को GPT4All के साथ फ़ीड करें लैंगचैन और उत्तर की प्रतीक्षा करें।
तो हमें जो चाहिए वह एंबेडिंग है। एक एम्बेडिंग सूचना के एक टुकड़े का एक संख्यात्मक प्रतिनिधित्व है, उदाहरण के लिए, पाठ, दस्तावेज़, चित्र, ऑडियो, आदि। प्रतिनिधित्व जो एम्बेड किया जा रहा है, उसके शब्दार्थ अर्थ को पकड़ लेता है, और यह वही है जिसकी हमें आवश्यकता है। इस परियोजना के लिए हम भारी जीपीयू मॉडल पर भरोसा नहीं कर सकते हैं: इसलिए हम अल्पाका देशी मॉडल को डाउनलोड करेंगे और इसका उपयोग करेंगे लैंगचैन la लामासीपीपी एंबेडिंग्स. चिंता मत करो! सब कुछ चरण दर चरण समझाया गया है
एक आभासी वातावरण बनाएँ
अपने नए पायथन प्रोजेक्ट के लिए एक नया फ़ोल्डर बनाएं, उदाहरण के लिए GPT4ALL_Fabio (अपना नाम डालें ...):
mkdir GPT4ALL_Fabio
cd GPT4ALL_Fabioअगला, एक नया पायथन आभासी वातावरण बनाएँ। यदि आपके पास एक से अधिक पायथन संस्करण स्थापित हैं, तो अपना वांछित संस्करण निर्दिष्ट करें: इस मामले में मैं अपने मुख्य इंस्टॉलेशन का उपयोग करूंगा, जो कि अजगर 3.10 से जुड़ा है।
python3 -m venv .venvआदेश python3 -m venv .venv नामक एक नया आभासी वातावरण बनाता है .venv (डॉट वेनव नामक एक छिपी हुई निर्देशिका बनाएगा)।
एक आभासी वातावरण एक पृथक पायथन इंस्टॉलेशन प्रदान करता है, जो आपको सिस्टम-वाइड पायथन इंस्टॉलेशन या अन्य प्रोजेक्ट्स को प्रभावित किए बिना केवल एक विशिष्ट प्रोजेक्ट के लिए पैकेज और निर्भरता स्थापित करने की अनुमति देता है। यह अलगाव विभिन्न परियोजना आवश्यकताओं के बीच निरंतरता बनाए रखने और संभावित संघर्षों को रोकने में मदद करता है।
एक बार आभासी वातावरण बन जाने के बाद, आप इसे निम्न आदेश का उपयोग करके सक्रिय कर सकते हैं:
source .venv/bin/activate 
सक्रिय आभासी वातावरण
स्थापित करने के लिए पुस्तकालय
हम जिस परियोजना का निर्माण कर रहे हैं, उसके लिए हमें बहुत अधिक पैकेजों की आवश्यकता नहीं है। हमें केवल चाहिए:
- GPT4All के लिए अजगर बाइंडिंग
- लैंगचैन हमारे दस्तावेजों के साथ बातचीत करने के लिए
LangChain भाषा मॉडल द्वारा संचालित अनुप्रयोगों के विकास के लिए एक रूपरेखा है। यह आपको न केवल एक एपीआई के माध्यम से एक भाषा मॉडल को कॉल करने की अनुमति देता है, बल्कि एक भाषा मॉडल को डेटा के अन्य स्रोतों से भी जोड़ता है और एक भाषा मॉडल को अपने पर्यावरण के साथ इंटरैक्ट करने की अनुमति देता है।
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4LangChain के लिए आप देखते हैं कि हमने संस्करण भी निर्दिष्ट किया है। इस लाइब्रेरी को हाल ही में बहुत सारे अपडेट प्राप्त हो रहे हैं, इसलिए यह सुनिश्चित करने के लिए कि हमारा सेटअप कल भी काम करने वाला है, एक संस्करण निर्दिष्ट करना बेहतर है जिसे हम जानते हैं कि ठीक काम कर रहा है। असंरचित पीडीएफ लोडर के लिए एक आवश्यक निर्भरता है और पित्ताशय और pdf2छवि किया जा सकता है।
ध्यान दें: GitHub रिपॉजिटरी पर एक आवश्यकताएँ। txt फ़ाइल है (द्वारा सुझाई गई जेएल एसीआर) इस परियोजना से जुड़े सभी संस्करणों के साथ। आप निम्न आदेश के साथ मुख्य प्रोजेक्ट फ़ाइल निर्देशिका में इसे डाउनलोड करने के बाद, एक शॉट में स्थापना कर सकते हैं:
pip install -r requirements.txtलेख के अंत में मैंने एक बनाया समस्या निवारण के लिए खंड. इन सभी जानकारियों के साथ GitHub रेपो में एक अपडेटेड READ.ME भी है।
ध्यान रखें कि कुछ पुस्तकालयों में अजगर संस्करण के आधार पर संस्करण उपलब्ध हैं आप अपने आभासी वातावरण पर चल रहे हैं।
अपने पीसी पर मॉडल डाउनलोड करें
यह वास्तव में महत्वपूर्ण कदम है।
परियोजना के लिए हमें निश्चित रूप से GPT4All की आवश्यकता है। नोमिक एआई पर वर्णित प्रक्रिया वास्तव में जटिल है और इसके लिए ऐसे हार्डवेयर की आवश्यकता होती है जो हम सभी के पास नहीं है (मेरे जैसे)। इसलिए यहाँ मॉडल का लिंक है पहले से ही रूपांतरित और उपयोग के लिए तैयार है। अभी डाउनलोड पर क्लिक करें।
GPT4All मॉडल डाउनलोड करें
जैसा कि परिचय में संक्षेप में वर्णित किया गया है, हमें एम्बेडिंग के लिए मॉडल की भी आवश्यकता है, एक मॉडल जिसे हम बिना कुचले अपने सीपीयू पर चला सकते हैं। क्लिक करें अल्पाका-नेटिव-7बी-जीजीएमएल डाउनलोड करने के लिए यहां लिंक करें पहले से ही 4-बिट में परिवर्तित हो गया है और एम्बेडिंग के लिए हमारे मॉडल के रूप में कार्य करने के लिए तैयार है।

के आगे डाउनलोड तीर पर क्लिक करें ggml-मॉडल-q4_0.bin
हमें एम्बेडिंग की आवश्यकता क्यों है? यदि आप प्रवाह आरेख से याद करते हैं, तो हमारे ज्ञानकोष के लिए दस्तावेज़ एकत्र करने के बाद आवश्यक पहला चरण है एम्बेड उन्हें। इस अल्पाका मॉडल से LLamaCPP एम्बेडिंग पूरी तरह से काम में फिट बैठता है और यह मॉडल काफी छोटा भी है (4 Gb)। वैसे आप अपने क्यूएनए के लिए अल्पाका मॉडल का भी उपयोग कर सकते हैं!
अद्यतन 2023.05.25: मैनी विंडोज उपयोगकर्ताओं को llamaCPP एम्बेडिंग का उपयोग करने में समस्याओं का सामना करना पड़ रहा है। यह मुख्य रूप से होता है क्योंकि अजगर पैकेज की स्थापना के दौरान llama-cpp-python के साथ:
pip install llama-cpp-pythonपाइप पैकेज लाइब्रेरी के स्रोत से संकलित होने जा रहा है। विंडोज़ में आमतौर पर मशीन पर डिफ़ॉल्ट रूप से सीएमके या सी कंपाइलर स्थापित नहीं होता है। लेकिन चिंता न करें एक समाधान है
लामा-सीपीपी-पायथन की स्थापना चलाना, लैंगचैन द्वारा लामा एंबेडिंग के साथ आवश्यक है, विंडोज सीएमके सी अनुपालनकर्ता डिफ़ॉल्ट रूप से स्थापित नहीं है, इसलिए आप स्रोत से निर्माण नहीं कर सकते हैं।
Xtools और Linux वाले Mac उपयोगकर्ताओं पर, आमतौर पर C कंप्लायर OS पर पहले से ही उपलब्ध होता है।
मुद्दे से बचने के लिए आपको पूर्व अनुपालन वाले पहिये का उपयोग करना चाहिए.
यहां जाओ https://github.com/abetlen/llama-cpp-python/releases
और अपने आर्किटेक्चर और पायथन संस्करण के लिए अनुपालन व्हील की तलाश करें - आपको वील्स संस्करण 0.1.49 अवश्य लेना चाहिए क्योंकि उच्च संस्करण संगत नहीं हैं।
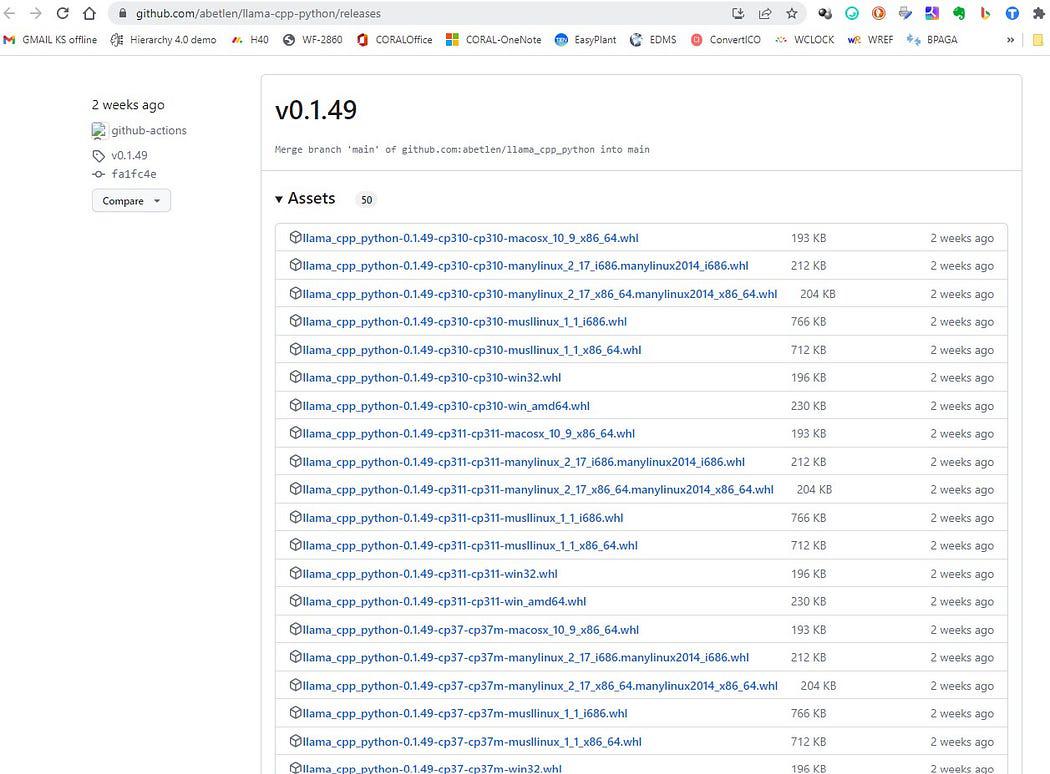
से स्क्रीनशॉट https://github.com/abetlen/llama-cpp-python/releases
मेरे मामले में मेरे पास विंडोज 10, 64 बिट, अजगर 3.10 है
तो मेरी फ़ाइल है llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
इस समस्या को GitHub रिपॉजिटरी पर ट्रैक किया गया है
डाउनलोड करने के बाद आपको दो मॉडलों को मॉडल निर्देशिका में रखना होगा, जैसा कि नीचे दिखाया गया है।

निर्देशिका संरचना और मॉडल फ़ाइलों को कहाँ रखा जाए
चूँकि हम GPT मॉडल पर अपनी बातचीत को नियंत्रित करना चाहते हैं, इसलिए हमें एक अजगर फ़ाइल बनानी होगी (चलिए इसे कॉल करते हैं) pygpt4all_test.py), निर्भरताओं को आयात करें और मॉडल को निर्देश दें। आप देखेंगे कि यह काफी आसान है।
from pygpt4all.models.gpt4all import GPT4Allयह हमारे मॉडल के लिए पायथन बाइंडिंग है। अब हम इसे कॉल कर सकते हैं और पूछना शुरू कर सकते हैं। आइए एक रचनात्मक प्रयास करें।
हम एक ऐसा फंक्शन बनाते हैं जो मॉडल से कॉलबैक को पढ़ता है, और हम GPT4All को अपना वाक्य पूरा करने के लिए कहते हैं।
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)पहला कथन हमारे कार्यक्रम को बता रहा है कि मॉडल को कहाँ खोजना है (याद रखें कि हमने ऊपर के अनुभाग में क्या किया था)
दूसरा कथन मॉडल को एक प्रतिक्रिया उत्पन्न करने और हमारे संकेत "वन्स अपॉन ए टाइम" को पूरा करने के लिए कह रहा है।
इसे चलाने के लिए, सुनिश्चित करें कि आभासी वातावरण अभी भी सक्रिय है और बस चलाएँ:
python3 pygpt4all_test.pyआपको मॉडल के लोडिंग टेक्स्ट और वाक्य के पूरा होने को देखना चाहिए। आपके हार्डवेयर संसाधनों के आधार पर इसमें थोड़ा समय लग सकता है।
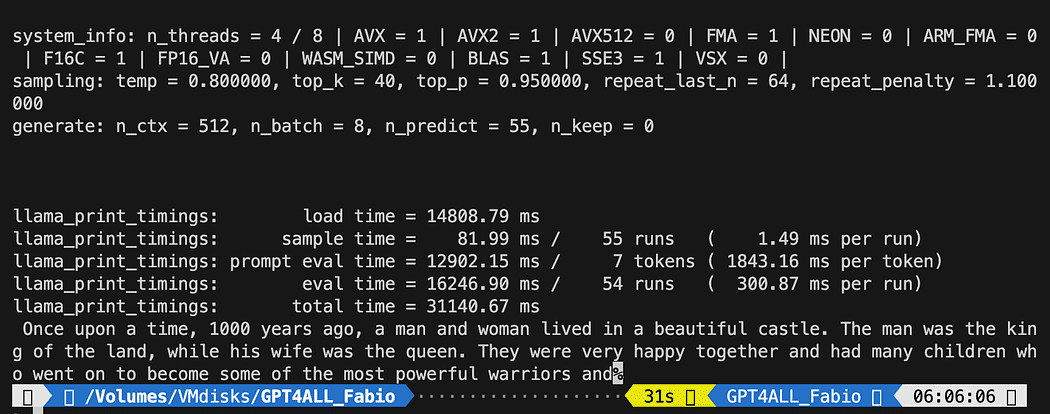
परिणाम आपके से अलग हो सकता है... लेकिन हमारे लिए महत्वपूर्ण यह है कि यह काम कर रहा है और हम कुछ उन्नत सामग्री बनाने के लिए लैंगचैन के साथ आगे बढ़ सकते हैं।
नोट (अद्यतन 2023.05.23): यदि आप pygpt4all से संबंधित किसी त्रुटि का सामना करते हैं, तो इस विषय पर दिए गए समाधान के साथ समस्या निवारण अनुभाग की जाँच करें रजनीश अग्रवाल or ऑस्कर जियोंग द्वारा।
LangChain ढांचा वास्तव में एक अद्भुत पुस्तकालय है। यह प्रदान करता है अवयव उपयोग में आसान तरीके से भाषा मॉडल के साथ काम करने के लिए, और यह भी प्रदान करता है चेन. किसी विशेष उपयोग के मामले को सर्वोत्तम रूप से पूरा करने के लिए जंजीरों को इन घटकों को विशेष तरीके से इकट्ठा करने के बारे में सोचा जा सकता है। ये एक उच्च स्तरीय इंटरफ़ेस होने का इरादा रखते हैं जिसके माध्यम से लोग किसी विशिष्ट उपयोग के मामले में आसानी से आरंभ कर सकते हैं। इन जंजीरों को भी अनुकूलन योग्य बनाया गया है।
हमारे अगले पायथन टेस्ट में हम a का उपयोग करेंगे शीघ्र टेम्पलेट. भाषा मॉडल टेक्स्ट को इनपुट के रूप में लेते हैं — उस टेक्स्ट को आमतौर पर प्रांप्ट के रूप में संदर्भित किया जाता है। आमतौर पर यह केवल एक हार्डकोडेड स्ट्रिंग नहीं है, बल्कि एक टेम्पलेट, कुछ उदाहरण और उपयोगकर्ता इनपुट का संयोजन है। LangChain निर्माण और संकेतों के साथ काम करना आसान बनाने के लिए कई वर्ग और कार्य प्रदान करता है। आइए देखें कि हम इसे कैसे कर सकते हैं।
एक नई पायथन फाइल बनाएं और इसे कॉल करें my_langचेन.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])हमने अपने GPT मॉडल के साथ सीधे इंटरैक्ट करने में सक्षम होने के लिए LangChain से प्रॉम्प्ट टेम्प्लेट और चेन और GPT4All llm क्लास का आयात किया।
फिर, अपना एलएलएम पथ सेट करने के बाद (जैसा कि हमने पहले किया था) हम कॉलबैक प्रबंधकों को तुरंत चालू करते हैं ताकि हम अपनी क्वेरी के जवाबों को पकड़ सकें।
एक टेम्पलेट बनाना वास्तव में आसान है: निम्नलिखित प्रलेखन ट्यूटोरियल हम कुछ इस तरह का उपयोग कर सकते हैं …
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])RSI टेम्पलेट चर एक बहु-पंक्ति स्ट्रिंग है जिसमें मॉडल के साथ हमारी सहभागिता संरचना होती है: घुंघराले ब्रेसिज़ में हम बाहरी चर को टेम्पलेट में सम्मिलित करते हैं, हमारे परिदृश्य में हमारा है प्रश्न.
चूंकि यह एक चर है, आप यह तय कर सकते हैं कि यह एक हार्ड-कोडेड प्रश्न है या एक उपयोगकर्ता इनपुट प्रश्न: यहाँ दो उदाहरण हैं।
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")हमारे टेस्ट रन के लिए हम यूजर इनपुट एक पर टिप्पणी करेंगे। अब हमें केवल अपने टेम्पलेट, प्रश्न और भाषा मॉडल को एक साथ जोड़ने की आवश्यकता है।
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)सत्यापित करना याद रखें कि आपका वर्चुअल वातावरण अभी भी सक्रिय है और कमांड चलाएँ:
python3 my_langchain.pyआपको मेरे से अलग परिणाम मिल सकते हैं। आश्चर्यजनक बात यह है कि आप संपूर्ण तर्क को देख सकते हैं जिसके बाद GPT4All आपके लिए उत्तर प्राप्त करने का प्रयास कर रहा है। प्रश्न को समायोजित करने से आपको बेहतर परिणाम भी मिल सकते हैं।
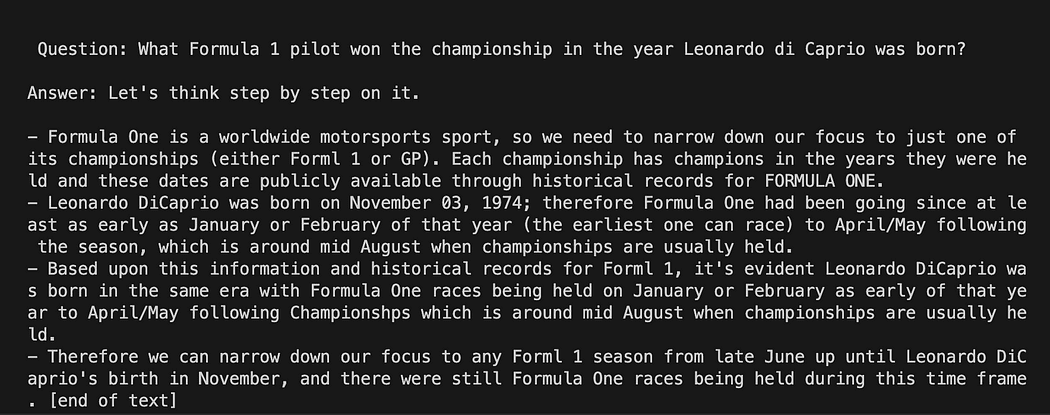
GPT4All पर प्रांप्ट टेम्पलेट के साथ लैंगचेन
यहां हम अद्भुत भाग शुरू करते हैं, क्योंकि हम GPT4All को एक चैटबॉट के रूप में उपयोग करके अपने दस्तावेज़ों से बात करने जा रहे हैं जो हमारे प्रश्नों का उत्तर देता है।
चरणों का क्रम, जिक्र करते हुए GPT4All के साथ QnA का वर्कफ़्लो, हमारी पीडीएफ फाइलों को लोड करना है, उन्हें चंक्स में बनाना है। उसके बाद हमें अपने एम्बेडिंग के लिए एक वेक्टर स्टोर की आवश्यकता होगी। हमें सूचना पुनर्प्राप्ति के लिए एक वेक्टर स्टोर में अपने खंडित दस्तावेज़ों को फीड करने की आवश्यकता है और फिर हम उन्हें इस डेटाबेस पर समानता खोज के साथ हमारे एलएलएम क्वेरी के संदर्भ के रूप में एम्बेड करेंगे।
इस उद्देश्य के लिए हम सीधे FAISS का उपयोग करने जा रहे हैं लैंगचैन पुस्तकालय। FAISS Facebook AI रिसर्च की एक ओपन-सोर्स लाइब्रेरी है, जिसे उच्च-आयामी डेटा के बड़े संग्रह में समान आइटमों को तुरंत खोजने के लिए डिज़ाइन किया गया है। यह एक डेटासेट के भीतर सबसे समान वस्तुओं को खोजने के लिए इसे आसान और तेज़ बनाने के लिए अनुक्रमण और खोज विधियाँ प्रदान करता है। यह हमारे लिए विशेष रूप से सुविधाजनक है क्योंकि यह सरल करता है सूचना की पुनर्प्राप्ति और हमें स्थानीय रूप से बनाए गए डेटाबेस को सहेजने की अनुमति दें: इसका मतलब है कि पहले निर्माण के बाद इसे किसी और उपयोग के लिए बहुत तेजी से लोड किया जाएगा।
वेक्टर इंडेक्स db का निर्माण
एक नई फाइल बनाएं और इसे कॉल करें my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeपहले पुस्तकालय वही हैं जिनका हमने पहले उपयोग किया था: इसके अतिरिक्त हम उपयोग कर रहे हैं लैंगचैन वेक्टर स्टोर अनुक्रमणिका निर्माण के लिए, लामासीपीपी एंबेडिंग्स हमारे अल्पाका मॉडल (4-बिट की मात्रा और सीपीपी लाइब्रेरी के साथ संकलित) और पीडीएफ लोडर के साथ बातचीत करने के लिए।
आइए अपने एलएलएम को उनके अपने रास्तों से लोड करें: एक एम्बेडिंग के लिए और दूसरा टेक्स्ट जनरेशन के लिए।
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)परीक्षण के लिए देखते हैं कि क्या हम सभी पीएफडी फाइलों को पढ़ने में कामयाब रहे हैं: पहला कदम प्रत्येक दस्तावेज़ पर उपयोग किए जाने वाले 3 कार्यों की घोषणा करना है। सबसे पहले निकाले गए पाठ को विखंडू में विभाजित करना है, दूसरा मेटाडेटा (जैसे पेज नंबर आदि ...) के साथ वेक्टर इंडेक्स बनाना है और आखिरी समानता खोज का परीक्षण करना है (मैं बाद में बेहतर समझाऊंगा)।
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesअब हम दस्तावेज़ों के लिए अनुक्रमणिका निर्माण का परीक्षण कर सकते हैं डॉक्स निर्देशिका: हमें वहां अपने सभी पीडीएफ डालने की जरूरत है। लैंगचैन फ़ाइल प्रकार की परवाह किए बिना, पूरे फ़ोल्डर को लोड करने की एक विधि भी है: चूंकि यह पोस्ट प्रक्रिया जटिल है, मैं इसे लामिनी मॉडल के बारे में अगले लेख में शामिल करूंगा।

मेरी डॉक्स निर्देशिका में 4 पीडीएफ फाइलें हैं
हम अपने कार्यों को सूची में पहले दस्तावेज़ पर लागू करेंगे
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)पहली पंक्तियों में हम प्राप्त करने के लिए os लाइब्रेरी का उपयोग करते हैं पीडीएफ फाइलों की सूची डॉक्स निर्देशिका के अंदर। हम फिर पहला दस्तावेज़ लोड करते हैं (doc_list [0]) के साथ डॉक्स फ़ोल्डर से लैंगचैन, विखंडू में विभाजित करें और फिर हम इसके साथ वेक्टर डेटाबेस बनाते हैं लामा एम्बेडिंग।
जैसा कि आपने देखा कि हम इसका उपयोग कर रहे हैं पीआईपीडीएफ विधि. यह उपयोग करने में थोड़ा लंबा है, क्योंकि आपको फ़ाइलों को एक-एक करके लोड करना है, लेकिन पीडीएफ का उपयोग करके लोड करना है pypdf दस्तावेजों की सरणी में आपको एक सरणी रखने की अनुमति मिलती है जहां प्रत्येक दस्तावेज़ में पृष्ठ सामग्री और मेटाडेटा होता है page संख्या। यह वास्तव में सुविधाजनक है जब आप उस संदर्भ के स्रोतों को जानना चाहते हैं जो हम अपनी क्वेरी के साथ GPT4All को देंगे। यहाँ readthedocs से उदाहरण:
से स्क्रीनशॉट लैंगचैन प्रलेखन
हम टर्मिनल से कमांड के साथ अजगर फ़ाइल चला सकते हैं:
python3 my_knowledge_qna.pyएम्बेडिंग के लिए मॉडल को लोड करने के बाद आप इंडेक्सिंग के लिए काम पर टोकन देखेंगे: चिंता न करें क्योंकि इसमें समय लगेगा, खासकर यदि आप केवल सीपीयू पर चलते हैं, मेरी तरह (इसमें 8 मिनट लगे)।
पहले वेक्टर db का समापन
जैसा कि मैं समझा रहा था कि पीआईपीडीएफ विधि धीमी है लेकिन हमें समानता खोज के लिए अतिरिक्त डेटा देती है। हमारी सभी फाइलों के माध्यम से पुनरावृति करने के लिए हम FAISS की एक सुविधाजनक विधि का उपयोग करेंगे जो हमें विभिन्न डेटाबेसों को एक साथ मर्ज करने की अनुमति देती है। अब हम क्या करते हैं कि हम पहले डीबी उत्पन्न करने के लिए उपरोक्त कोड का उपयोग करते हैं (हम इसे कॉल करेंगे db0) और लूप के लिए हम सूची में अगली फ़ाइल की अनुक्रमणिका बनाते हैं और इसे तुरंत मर्ज करते हैं db0.
यहाँ कोड है: ध्यान दें कि मैंने आपको प्रगति की स्थिति का उपयोग करने के लिए कुछ लॉग जोड़े हैं datetime.datetime.now () और समाप्ति समय के डेल्टा को प्रिंट करना और ऑपरेशन में कितना समय लगा, इसकी गणना करने के लिए समय शुरू करें (यदि आप इसे पसंद नहीं करते हैं तो आप इसे हटा सकते हैं)।
मर्ज निर्देश इस प्रकार है
# merge dbi with the existing db0
db0.merge_from(dbi)अंतिम निर्देशों में से एक हमारे डेटाबेस को स्थानीय रूप से सहेजने के लिए है: पूरी पीढ़ी को घंटों भी लग सकते हैं (आपके पास कितने दस्तावेज़ हैं इस पर निर्भर करता है) इसलिए यह वास्तव में अच्छा है कि हमें इसे केवल एक बार करना होगा!
# Save the databasae locally
db0.save_local("my_faiss_index")यहाँ पूरा कोड। जब हम अपने फ़ोल्डर से सीधे इंडेक्स लोड करने वाले GPT4All के साथ इंटरैक्ट करेंगे तो हम इसके कई हिस्सों पर टिप्पणी करेंगे।
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  अजगर फ़ाइल को चलाने में 22 मिनट लगे
अजगर फ़ाइल को चलाने में 22 मिनट लगे
अपने दस्तावेज़ों पर GPT4All से प्रश्न पूछें
अब हम यहाँ हैं। हमारे पास अपनी अनुक्रमणिका है, हम इसे लोड कर सकते हैं और एक प्रांप्ट टेम्पलेट के साथ हम GPT4All से अपने प्रश्नों का उत्तर देने के लिए कह सकते हैं। हम एक हार्ड-कोडेड प्रश्न से शुरू करते हैं और फिर हम अपने इनपुट प्रश्नों के माध्यम से लूप करेंगे।
निम्न कोड को एक पायथन फ़ाइल के अंदर रखें db_loading.py और इसे टर्मिनल से कमांड के साथ चलाएं Python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])मुद्रित पाठ उन 3 स्रोतों की सूची है जो क्वेरी के साथ सबसे अच्छी तरह मेल खाते हैं, हमें दस्तावेज़ का नाम और पृष्ठ संख्या भी देते हैं।
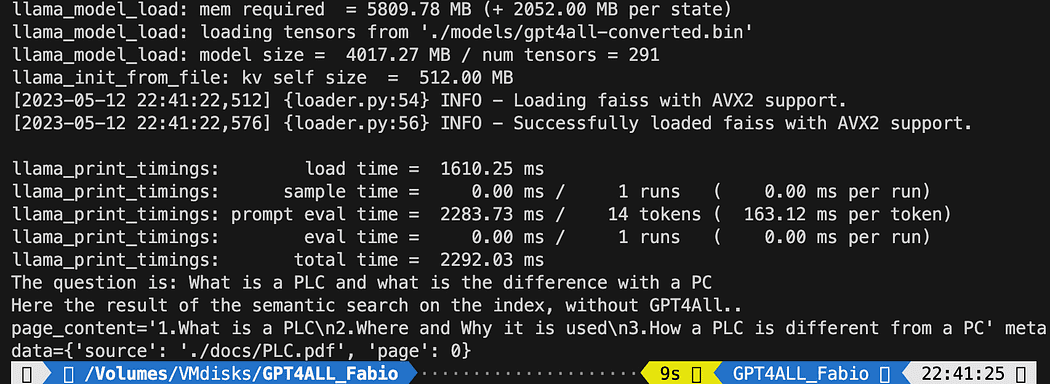
फ़ाइल चलाने वाले शब्दार्थ खोज के परिणाम db_loading.py
अब हम शीघ्र टेम्पलेट का उपयोग करके समानता खोज को अपनी क्वेरी के संदर्भ के रूप में उपयोग कर सकते हैं। 3 कार्यों के बाद सभी कोड को निम्नलिखित के साथ बदलें:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))दौड़ने के बाद आपको इस तरह का परिणाम मिलेगा (लेकिन भिन्न हो सकता है)। कमाल नहीं!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.यदि आप लाइन को बदलने के लिए उपयोगकर्ता-इनपुट प्रश्न चाहते हैं
question = "What is a PLC and what is the difference with a PC"कुछ इस तरह के साथ:
question = input("Your question: ")यह आपके लिए प्रयोग करने का समय है। अपने दस्तावेज़ों से संबंधित सभी विषयों पर अलग-अलग प्रश्न पूछें, और परिणाम देखें। सुधार के लिए एक बड़ा कमरा है, निश्चित रूप से संकेत और टेम्पलेट पर: आप देख सकते हैं यहाँ कुछ प्रेरणा के लिए. लेकिन लैंगचैन दस्तावेज़ीकरण वास्तव में आश्चर्यजनक है (मैं इसका अनुसरण कर सकता हूं !!)
आप लेख से कोड का पालन कर सकते हैं या इसे देख सकते हैं मेरा जीथब रेपो.
फैबियो मैट्रिकर्डी एक शिक्षक, शिक्षक, इंजीनियर और सीखने के प्रति उत्साही। वह 15 वर्षों से युवा छात्रों को पढ़ा रहे हैं, और अब वे नए कर्मचारियों को Key Solution Srl में प्रशिक्षित करते हैं। उन्होंने 2010 में इंडस्ट्रियल ऑटोमेशन इंजीनियर के रूप में मेरे करियर की शुरुआत की थी। किशोरावस्था से ही प्रोग्रामिंग के प्रति जुनूनी, उन्होंने सॉफ्टवेयर और मानव मशीन इंटरफेस के निर्माण की सुंदरता की खोज की ताकि कुछ जीवन में लाया जा सके। अध्यापन और कोचिंग मेरी दिनचर्या का हिस्सा है, साथ ही अध्ययन और सीखने के साथ-साथ अद्यतन प्रबंधन कौशल के साथ एक भावुक नेता कैसे बनें। पूरे इंजीनियरिंग जीवनचक्र में मशीन लर्निंग और आर्टिफिशियल इंटेलिजेंस का उपयोग करके एक बेहतर डिज़ाइन, एक भविष्य कहनेवाला सिस्टम एकीकरण की यात्रा में मेरे साथ शामिल हों।
मूल। अनुमति के साथ पुनर्प्रकाशित।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- ईवीएम वित्त। विकेंद्रीकृत वित्त के लिए एकीकृत इंटरफ़ेस। यहां पहुंचें।
- क्वांटम मीडिया समूह। आईआर/पीआर प्रवर्धित। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 डेटा इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 1
- 10
- 11
- 12
- 13
- 14
- 15 साल
- 15% तक
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- क्षमता
- योग्य
- About
- ऊपर
- पूरा
- अधिनियम
- सक्रिय
- जोड़ा
- इसके अलावा
- अतिरिक्त
- उन्नत
- प्रभावित करने वाले
- बाद
- AI
- ai शोध
- सब
- अनुमति देना
- की अनुमति देता है
- पहले ही
- भी
- am
- अद्भुत
- an
- विश्लेषण
- और
- जवाब
- कोई
- एपीआई
- अनुप्रयोगों
- लागू करें
- स्थापत्य
- हैं
- ऐरे
- लेख
- लेख
- कृत्रिम
- कृत्रिम बुद्धिमत्ता
- AS
- जुड़े
- At
- ऑडियो
- स्वचालित
- स्वतः
- स्वचालन
- उपलब्ध
- से बचने
- आधार
- आधारित
- BE
- सुंदरता
- क्योंकि
- किया गया
- से पहले
- जा रहा है
- नीचे
- BEST
- बेहतर
- के बीच
- परे
- बड़ा
- बिन
- बंधन
- बिट
- जन्म
- संक्षिप्त
- लाना
- निर्माण
- इमारत
- में निर्मित
- बसें
- लेकिन
- by
- गणना
- कॉल
- बुलाया
- कॉल
- कर सकते हैं
- नही सकता
- क्षमता
- कब्जा
- कैरियर
- ले जाना
- मामला
- कुश्ती
- CD
- कुछ
- निश्चित रूप से
- श्रृंखला
- चेन
- चैंपियनशिप
- chatbot
- ChatGPT
- चेक
- रासायनिक
- कक्षा
- कक्षाएं
- क्लिक करें
- कोचिंग
- कोड
- कोड
- इकट्ठा
- संग्रह
- संग्रह
- संयोजन
- टिप्पणी
- सामान्यतः
- संवाद
- संचार
- संगत
- पूरा
- पूरा
- समापन
- जटिल
- जटिल
- घटकों
- कंप्यूटर
- कंप्यूटर्स
- जुडिये
- जुड़ा हुआ
- निर्माण
- उपभोक्ता
- शामिल हैं
- सामग्री
- प्रसंग
- नियंत्रण
- नियंत्रक
- नियंत्रण
- सुविधाजनक
- परिवर्तित
- सका
- आवरण
- सी पी यू
- बनाना
- बनाया
- बनाता है
- बनाना
- निर्माण
- क्रिएटिव
- महत्वपूर्ण
- अनुकूलन
- दैनिक
- तिथि
- डाटाबेस
- डेटाबेस
- तारीख
- दिनांक और समय
- तय
- चूक
- परिभाषित
- डेल्टा
- निर्भरता
- निर्भर करता है
- निर्भर करता है
- तैनात
- वर्णित
- डिज़ाइन
- बनाया गया
- वांछित
- विकासशील
- युक्ति
- डिवाइस
- डीआईडी
- अंतर
- विभिन्न
- सुपाच्य
- डिजिटल
- सीधे
- अन्य वायरल पोस्ट से
- की खोज
- do
- दस्तावेज़
- दस्तावेज़ीकरण
- दस्तावेजों
- कर देता है
- नहीं करता है
- किया
- dont
- DOT
- डाउनलोड
- ड्राइविंग
- दौरान
- से प्रत्येक
- आसान
- आसानी
- आसान
- पारिस्थितिकी तंत्र
- पारिस्थितिकी प्रणालियों
- प्रयास
- एम्बेड
- एम्बेडेड
- embedding
- कर्मचारियों
- सक्षम
- समाप्त
- इंजीनियर
- अभियांत्रिकी
- दर्ज
- सरगर्म
- संपूर्ण
- वातावरण
- त्रुटि
- विशेष रूप से
- आदि
- ईथर (ईटीएच)
- और भी
- सब कुछ
- ठीक ठीक
- उदाहरण
- उदाहरण
- निष्पादन
- मौजूदा
- प्रयोग
- समझाना
- समझाया
- समझा
- बाहरी
- चेहरा
- फेसबुक
- की सुविधा
- का सामना करना पड़
- फास्ट
- और तेज
- पट्टिका
- फ़ाइलें
- खोज
- अंत
- प्रथम
- फिट
- प्रवाह
- का पालन करें
- पीछा किया
- निम्नलिखित
- इस प्रकार है
- के लिए
- प्रपत्र
- प्रारूप
- सूत्र
- फॉर्मूला 1
- ढांचा
- से
- समारोह
- कार्यों
- आगे
- उत्पन्न
- सृजन
- पीढ़ी
- मिल
- GitHub
- देना
- दी
- देता है
- देते
- जा
- अच्छा
- GPU
- ग्रेड
- हैंडलिंग
- हो जाता
- कठिन
- हार्डवेयर
- है
- he
- mmmmm
- मदद करता है
- यहाँ उत्पन्न करें
- छिपा हुआ
- हाई
- उच्चतर
- घंटे
- कैसे
- How To
- एचटीएमएल
- http
- HTTPS
- मानव
- i
- आईसीएस
- if
- छवियों
- तुरंत
- लागू करने के
- आयात
- महत्वपूर्ण
- सुधार
- in
- शामिल
- अनुक्रमणिका
- अनुक्रमणिका
- व्यक्तियों
- औद्योगिक
- औद्योगिक स्वचालन
- उद्योगों
- करें-
- निवेश
- इनपुट आउटपुट
- निविष्टियां
- स्थापित
- स्थापना
- उदाहरण
- निर्देश
- एकीकरण
- बुद्धि
- इरादा
- बातचीत
- बातचीत
- इंटरफेस
- इंटरफेस
- इंटरनेट
- में
- परिचय
- पृथक
- अलगाव
- IT
- आइटम
- यात्रा
- आईटी इस
- काम
- में शामिल होने
- यात्रा
- केवल
- केडनगेट्स
- कुंजी
- जानना
- ज्ञान
- भाषा
- बड़ा
- पिछली बार
- बाद में
- नेता
- सीख रहा हूँ
- स्तर
- पुस्तकालयों
- पुस्तकालय
- जीवन
- जीवन चक्र
- पसंद
- पंक्तियां
- LINK
- लिंक्डइन
- लिनक्स
- सूची
- थोड़ा
- भार
- लोडर
- लोड हो रहा है
- स्थानीय
- स्थानीय स्तर पर
- तर्क
- लंबा
- लंबे समय तक
- देखिए
- लॉट
- मैक
- मशीन
- यंत्र अधिगम
- मशीनरी
- मुख्य
- मुख्यतः
- बनाए रखना
- बनाना
- कामयाब
- प्रबंध
- प्रबंधक
- प्रबंधक
- विनिर्माण
- बहुत
- मई..
- अर्थ
- साधन
- याद
- मर्ज
- विलय
- मेटाडाटा
- तरीका
- तरीकों
- मन
- मिनट
- आदर्श
- मॉडल
- अधिक
- अधिकांश
- विभिन्न
- चाहिए
- my
- नाम
- देशी
- आवश्यकता
- नेटवर्क
- नया
- अगला
- अभी
- संख्या
- संख्या
- वस्तु
- of
- ऑफर
- on
- एक बार
- ONE
- ऑनलाइन
- केवल
- खुला स्रोत
- आपरेशन
- संचालन
- or
- आदेश
- संगठनों
- OS
- अन्य
- हमारी
- आउट
- उत्पादन
- के ऊपर
- अपना
- पैकेज
- संकुल
- पृष्ठ
- समानांतर
- भाग
- विशेष
- विशेष रूप से
- पास
- आवेशपूर्ण
- पथ
- PC
- पीडीएफ
- स्टाफ़
- निष्पादन
- अनुमति
- स्टाफ़
- चित्र
- टुकड़ा
- पायलट
- पौधों
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- पीएलसी
- कृप्या अ
- प्लग
- बंदरगाहों
- स्थिति
- पद
- संभावित
- बिजली
- बिजली संयंत्रों
- संचालित
- शक्तिशाली
- पूर्व
- को रोकने के
- छाप
- मुद्रण
- समस्याओं
- प्रक्रिया
- संसाधित
- प्रक्रियाओं
- कार्यक्रम
- क्रमादेशित
- प्रोग्रामिंग
- प्रगति
- परियोजना
- परियोजनाओं
- प्रोटोकॉल
- प्रदान करता है
- प्रयोजनों
- रखना
- अजगर
- गुणवत्ता
- प्रश्न
- प्रशन
- जल्दी से
- बल्कि
- पढ़ना
- तैयार
- वास्तव में
- प्राप्त
- हाल ही में
- निर्दिष्ट
- संदर्भित करता है
- भले ही
- रजिस्टरों
- सम्बंधित
- विश्वसनीयता
- भरोसा करना
- याद
- हटाना
- दोहराया गया
- की जगह
- रिपोर्ट
- कोष
- प्रतिनिधित्व
- अपेक्षित
- आवश्यकताएँ
- की आवश्यकता होती है
- अनुसंधान
- उपयुक्त संसाधन चुनें
- प्रतिक्रिया
- प्रतिक्रियाएं
- परिणाम
- परिणाम
- वापसी
- कक्ष
- रन
- दौड़ना
- s
- सुरक्षा
- वही
- सहेजें
- बचत
- परिदृश्य
- Search
- खोज
- दूसरा
- अनुभाग
- सुरक्षित
- देखना
- सेंसर
- वाक्य
- अनुक्रम
- धारावाहिक
- की स्थापना
- व्यवस्था
- कई
- शॉट
- चाहिए
- दिखाया
- समान
- सरल
- केवल
- के बाद से
- एक
- कौशल
- छोटा
- So
- सॉफ्टवेयर
- समाधान
- कुछ
- कुछ
- स्रोत
- सूत्रों का कहना है
- विशेषीकृत
- विशेष रूप से
- विशिष्ट
- विनिर्दिष्ट
- विभाजित
- Spot
- प्रारंभ
- शुरू
- शुरुआत में
- कथन
- स्थिति
- कदम
- कदम
- फिर भी
- की दुकान
- तार
- संरचना
- छात्र
- का अध्ययन
- ऐसा
- प्रणाली
- लेना
- बातचीत
- कार्य
- शिक्षक
- शिक्षण
- किशोर
- टेम्पलेट
- अंतिम
- परीक्षण
- परीक्षण चालन
- परीक्षण
- पाठ पीढ़ी
- से
- कि
- RSI
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- वे
- सोचना
- इसका
- विचार
- यहाँ
- भर
- पहर
- सेवा मेरे
- एक साथ
- टोकन
- कल
- भी
- ले गया
- विषय
- विषय
- की ओर
- रेलगाड़ी
- कोशिश
- दो
- टाइप
- ठेठ
- आम तौर पर
- अद्यतन
- अपडेट
- के ऊपर
- us
- प्रयोग
- USB के
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ताओं
- का उपयोग
- आमतौर पर
- उपयोग किया
- विभिन्न
- सत्यापित
- संस्करण
- बहुत
- के माध्यम से
- वास्तविक
- W3
- प्रतीक्षा
- करना चाहते हैं
- था
- मार्ग..
- तरीके
- we
- वेबसाइट
- कुंआ
- क्या
- एचएमबी क्या है?
- पहिया
- कब
- कौन कौन से
- कौन
- क्यों
- व्यापक रूप से
- मर्जी
- खिड़कियां
- विंडोज उपयोगकर्ता
- साथ में
- अंदर
- बिना
- जीत लिया
- काम
- काम कर रहे
- वर्ष
- साल
- इसलिए आप
- युवा
- आपका
- जेफिरनेट










