कई छोटे और बड़े संगठन, अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस) पर अपने एनालिटिक्स वर्कलोड को स्थानांतरित करने और आधुनिकीकरण करने के लिए काम कर रहे हैं। ग्राहकों के AWS पर स्थानांतरित होने के कई कारण हैं, लेकिन मुख्य कारणों में से एक बुनियादी ढांचे, पैचिंग, मॉनिटरिंग, बैकअप और बहुत कुछ बनाए रखने में समय बर्बाद करने के बजाय पूरी तरह से प्रबंधित सेवाओं का उपयोग करने की क्षमता है। नेतृत्व और विकास दल वर्तमान बुनियादी ढांचे को बनाए रखने के बजाय वर्तमान समाधानों को अनुकूलित करने और यहां तक कि नए उपयोग के मामलों के साथ प्रयोग करने में अधिक समय व्यतीत कर सकते हैं।
एडब्ल्यूएस पर तेजी से आगे बढ़ने की क्षमता के साथ, जब आप स्केल करना जारी रखते हैं तो आपको प्राप्त होने वाले और संसाधित होने वाले डेटा के प्रति भी जिम्मेदार होना होगा। इन जिम्मेदारियों में डेटा गोपनीयता कानूनों और विनियमों का अनुपालन करना और अपस्ट्रीम स्रोतों से व्यक्तिगत पहचान योग्य जानकारी (पीआईआई) या संरक्षित स्वास्थ्य जानकारी (पीएचआई) जैसे संवेदनशील डेटा को संग्रहीत या उजागर नहीं करना शामिल है।
इस पोस्ट में, हम एक उच्च-स्तरीय वास्तुकला और एक विशिष्ट उपयोग के मामले से गुजरते हैं जो दर्शाता है कि आप डेटा गोपनीयता चिंताओं को दूर करने के लिए बड़ी मात्रा में विकास समय खर्च किए बिना अपने संगठन के डेटा प्लेटफ़ॉर्म को कैसे बढ़ाना जारी रख सकते हैं। हम उपयोग करते हैं एडब्ल्यूएस गोंद पीआईआई डेटा को लोड करने से पहले उसका पता लगाना, छिपाना और संशोधित करना अमेज़न ओपन सर्च सर्विस.
समाधान अवलोकन
निम्नलिखित चित्र उच्च-स्तरीय समाधान वास्तुकला को दर्शाता है। हमने अपने डिज़ाइन की सभी परतों और घटकों को इसके अनुरूप परिभाषित किया है AWS वेल-आर्किटेक्चर्ड फ्रेमवर्क डेटा एनालिटिक्स लेंस.
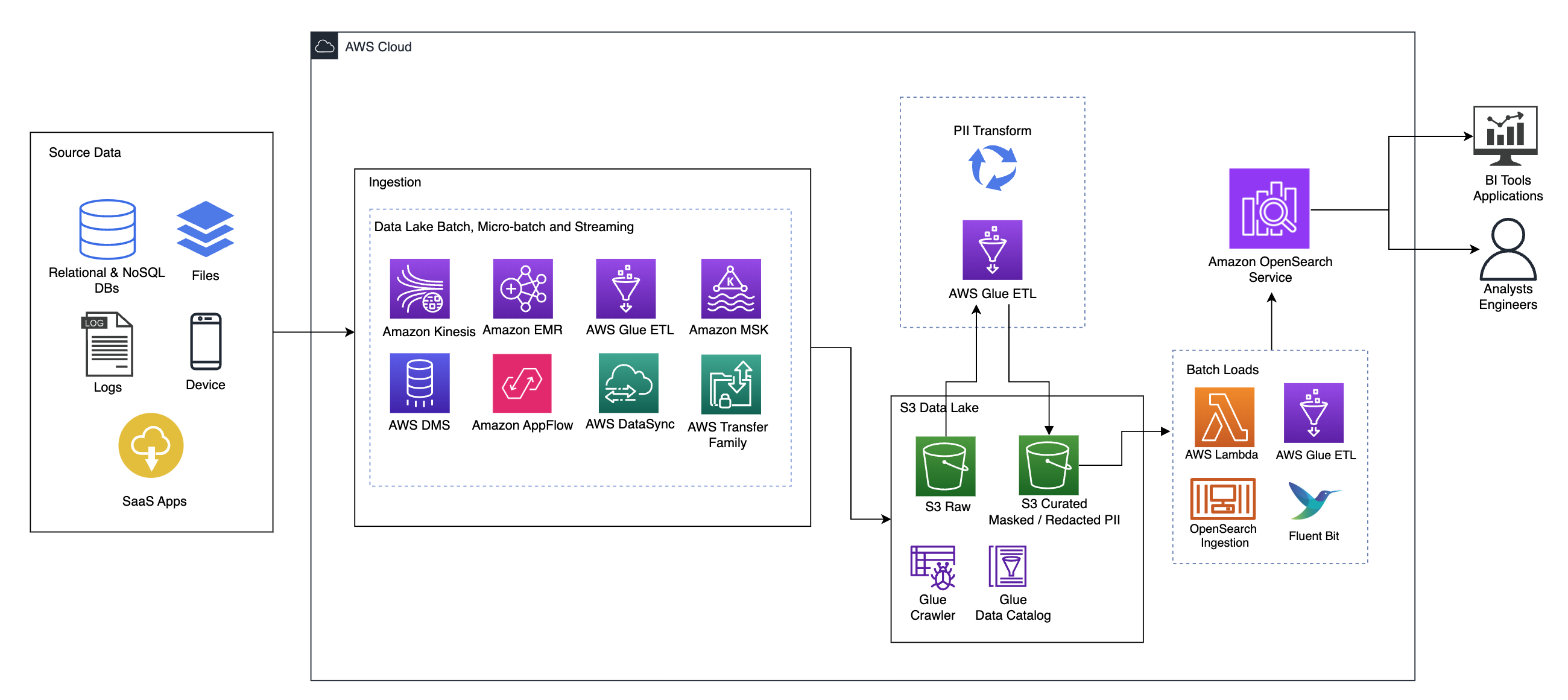
वास्तुकला में कई घटक शामिल हैं:
स्रोत डेटा
डेटा कई दसियों से लेकर सैकड़ों स्रोतों से आ सकता है, जिनमें डेटाबेस, फ़ाइल स्थानांतरण, लॉग, सेवा के रूप में सॉफ़्टवेयर (SaaS) एप्लिकेशन और बहुत कुछ शामिल हैं। इन चैनलों के माध्यम से और उनके डाउनस्ट्रीम स्टोरेज और अनुप्रयोगों में कौन सा डेटा आता है, इस पर संगठनों का हमेशा नियंत्रण नहीं हो सकता है।
अंतर्ग्रहण: डेटा लेक बैच, माइक्रो-बैच और स्ट्रीमिंग
कई संगठन अपने स्रोत डेटा को बैच, माइक्रो-बैच और स्ट्रीमिंग नौकरियों सहित विभिन्न तरीकों से अपने डेटा लेक में डालते हैं। उदाहरण के लिए, अमेज़ॅन ईएमआर, एडब्ल्यूएस गोंद, तथा एडब्ल्यूएस डेटाबेस प्रवासन सेवा (एडब्ल्यूएस डीएमएस) का उपयोग बैच और स्ट्रीमिंग ऑपरेशन करने के लिए किया जा सकता है जो डेटा लेक पर सिंक हो जाते हैं अमेज़न सरल भंडारण सेवा (अमेज़न S3)। अमेज़न ऐपफ्लो इसका उपयोग विभिन्न SaaS अनुप्रयोगों से डेटा लेक में डेटा स्थानांतरित करने के लिए किया जा सकता है। एडब्ल्यूएस डेटासिंक और एडब्ल्यूएस स्थानांतरण परिवार कई अलग-अलग प्रोटोकॉल पर डेटा लेक से फ़ाइलों को ले जाने में मदद मिल सकती है। अमेज़ॅन किनिस और Amazon MSK में डेटा को सीधे Amazon S3 पर डेटा लेक में स्ट्रीम करने की क्षमता भी है।
S3 डेटा लेक
अपने डेटा लेक के लिए Amazon S3 का उपयोग करना आधुनिक डेटा रणनीति के अनुरूप है। यह प्रदर्शन, विश्वसनीयता या उपलब्धता से समझौता किए बिना कम लागत वाला भंडारण प्रदान करता है। इस दृष्टिकोण के साथ, आप आवश्यकतानुसार अपने डेटा में गणना ला सकते हैं और केवल उसे चलाने के लिए आवश्यक क्षमता के लिए भुगतान कर सकते हैं।
इस आर्किटेक्चर में, कच्चा डेटा विभिन्न स्रोतों (आंतरिक और बाहरी) से आ सकता है, जिसमें संवेदनशील डेटा हो सकता है।
एडब्ल्यूएस ग्लू क्रॉलर का उपयोग करके, हम डेटा की खोज और कैटलॉग कर सकते हैं, जो हमारे लिए टेबल स्कीमा का निर्माण करेगा, और अंततः किसी भी संवेदनशील डेटा का पता लगाने और उसे छिपाने या संशोधित करने के लिए पीआईआई ट्रांसफॉर्म के साथ एडब्ल्यूएस ग्लू ईटीएल का उपयोग करना आसान बना देगा। डेटा लेक में.
व्यावसायिक संदर्भ और डेटासेट
हमारे दृष्टिकोण के मूल्य को प्रदर्शित करने के लिए, आइए कल्पना करें कि आप एक वित्तीय सेवा संगठन के लिए डेटा इंजीनियरिंग टीम का हिस्सा हैं। आपकी आवश्यकताएं संवेदनशील डेटा का पता लगाना और उसे छुपाना है क्योंकि यह आपके संगठन के क्लाउड वातावरण में शामिल है। डेटा का उपभोग डाउनस्ट्रीम विश्लेषणात्मक प्रक्रियाओं द्वारा किया जाएगा। भविष्य में, आपके उपयोगकर्ता आंतरिक बैंकिंग सिस्टम से एकत्रित डेटा स्ट्रीम के आधार पर ऐतिहासिक भुगतान लेनदेन को सुरक्षित रूप से खोजने में सक्षम होंगे। ऑपरेशन टीमों, ग्राहकों और इंटरफ़ेसिंग अनुप्रयोगों के खोज परिणामों को संवेदनशील क्षेत्रों में छुपाया जाना चाहिए।
निम्न तालिका समाधान के लिए प्रयुक्त डेटा संरचना को दर्शाती है। स्पष्टता के लिए, हमने कच्चे से क्यूरेटेड कॉलम नामों को मैप किया है। आप देखेंगे कि इस स्कीम के भीतर कई फ़ील्ड को संवेदनशील डेटा माना जाता है, जैसे पहला नाम, अंतिम नाम, सामाजिक सुरक्षा नंबर (एसएसएन), पता, क्रेडिट कार्ड नंबर, फोन नंबर, ईमेल और आईपीवी 4 पता।
| कच्चे स्तंभ का नाम | क्यूरेटेड कॉलम का नाम | प्रकार |
| c0 | पहला नाम | स्ट्रिंग |
| c1 | अंतिम नाम | स्ट्रिंग |
| c2 | एसएसएन | स्ट्रिंग |
| c3 | पता | स्ट्रिंग |
| c4 | पोस्टकोड | स्ट्रिंग |
| c5 | देश | स्ट्रिंग |
| c6 | buy_site | स्ट्रिंग |
| c7 | क्रेडिट कार्ड नंबर | स्ट्रिंग |
| c8 | क्रेडिट_कार्ड_प्रदाता | स्ट्रिंग |
| c9 | मुद्रा | स्ट्रिंग |
| c10 | खरीद मूल्य | पूर्णांक |
| c11 | कार्यवाही की तिथि | डेटा |
| c12 | फ़ोन नंबर | स्ट्रिंग |
| c13 | ईमेल | स्ट्रिंग |
| c14 | ipv4 | स्ट्रिंग |
केस का उपयोग करें: ओपनसर्च सेवा पर लोड करने से पहले पीआईआई बैच का पता लगाना
निम्नलिखित आर्किटेक्चर को लागू करने वाले ग्राहकों ने विभिन्न प्रकार के एनालिटिक्स को बड़े पैमाने पर चलाने के लिए अमेज़ॅन एस 3 पर अपना डेटा लेक बनाया है। यह समाधान उन ग्राहकों के लिए उपयुक्त है जिन्हें ओपनसर्च सेवा में वास्तविक समय में अंतर्ग्रहण की आवश्यकता नहीं है और वे डेटा एकीकरण टूल का उपयोग करने की योजना बनाते हैं जो एक शेड्यूल पर चलते हैं या घटनाओं के माध्यम से ट्रिगर होते हैं।
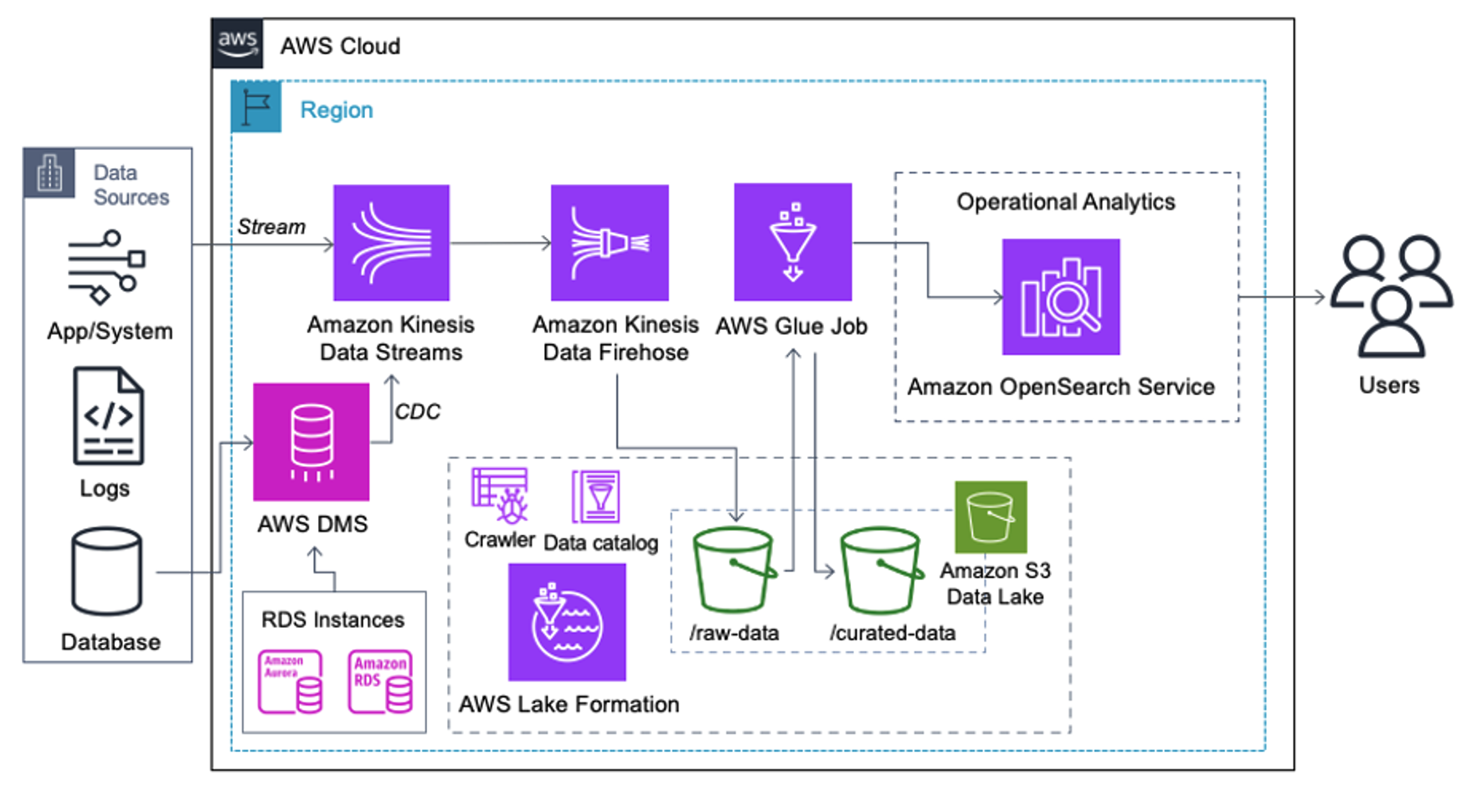
अमेज़ॅन S3 पर डेटा रिकॉर्ड आने से पहले, हम सभी डेटा स्ट्रीम को विश्वसनीय और सुरक्षित रूप से डेटा लेक में लाने के लिए एक अंतर्ग्रहण परत लागू करते हैं। संरचित और अर्ध-संरचित डेटा धाराओं के त्वरित सेवन के लिए काइनेसिस डेटा स्ट्रीम को अंतर्ग्रहण परत के रूप में तैनात किया गया है। इनके उदाहरण रिलेशनल डेटाबेस परिवर्तन, एप्लिकेशन, सिस्टम लॉग या क्लिकस्ट्रीम हैं। परिवर्तन डेटा कैप्चर (सीडीसी) उपयोग के मामलों के लिए, आप एडब्ल्यूएस डीएमएस के लक्ष्य के रूप में किनेसिस डेटा स्ट्रीम का उपयोग कर सकते हैं। संवेदनशील डेटा वाले स्ट्रीम उत्पन्न करने वाले एप्लिकेशन या सिस्टम को तीन समर्थित तरीकों में से एक के माध्यम से किनेसिस डेटा स्ट्रीम में भेजा जाता है: अमेज़ॅन किनेसिस एजेंट, जावा के लिए एडब्ल्यूएस एसडीके, या किनेसिस प्रोड्यूसर लाइब्रेरी। अंतिम चरण के रूप में, अमेज़न Kinesis डेटा Firehose हमें हमारे S3 डेटा लेक गंतव्य में डेटा के वास्तविक समय बैचों को विश्वसनीय रूप से लोड करने में मदद करता है।
निम्नलिखित स्क्रीनशॉट दिखाता है कि किनेसिस डेटा स्ट्रीम के माध्यम से डेटा कैसे प्रवाहित होता है डेटा व्यूअर और नमूना डेटा पुनर्प्राप्त करता है जो कच्चे S3 उपसर्ग पर आता है। इस आर्किटेक्चर के लिए, हमने अनुशंसित अनुसार S3 उपसर्गों के लिए डेटा जीवनचक्र का पालन किया डेटा लेक फाउंडेशन.
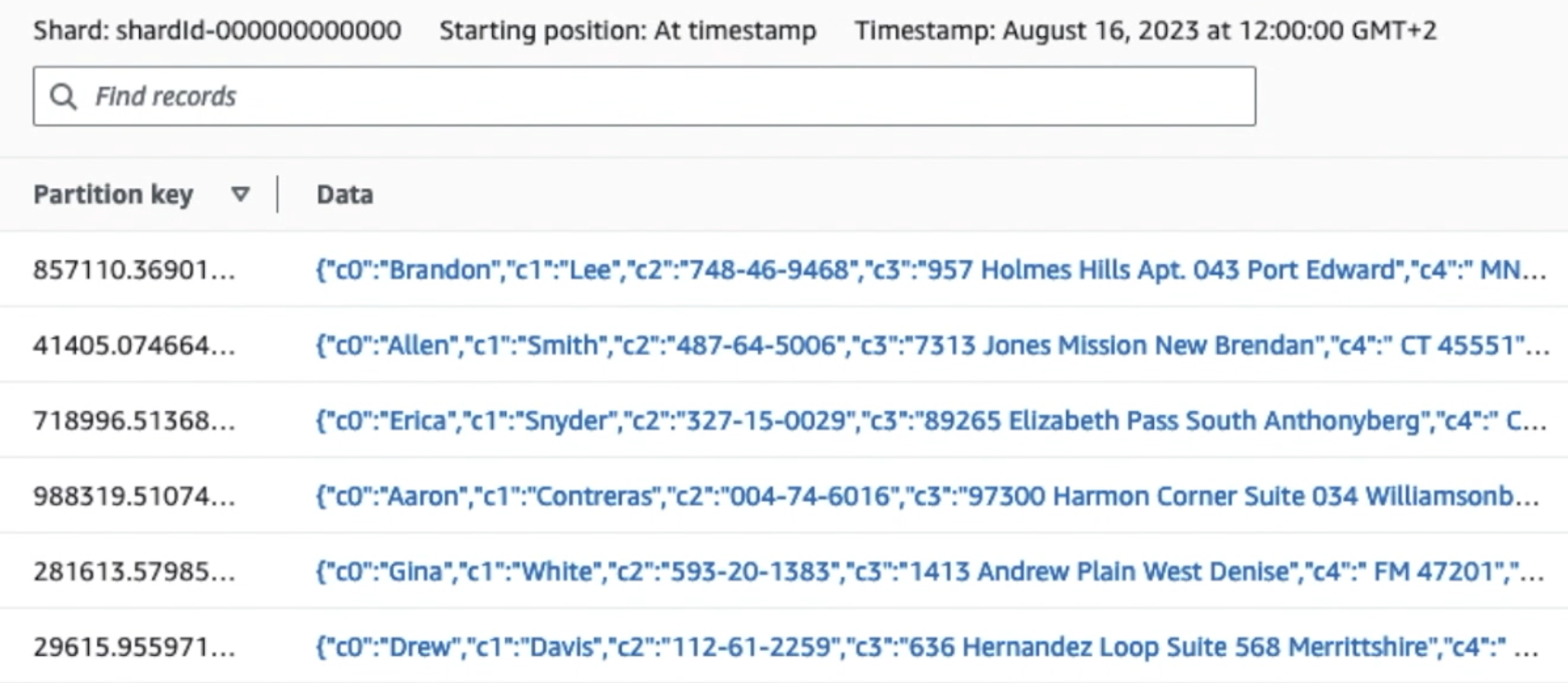
जैसा कि आप निम्नलिखित स्क्रीनशॉट में पहले रिकॉर्ड के विवरण से देख सकते हैं, JSON पेलोड पिछले अनुभाग की तरह ही स्कीमा का अनुसरण करता है। आप बिना संशोधित डेटा को किनेसिस डेटा स्ट्रीम में प्रवाहित होते हुए देख सकते हैं, जो बाद के चरणों में अस्पष्ट हो जाएगा।
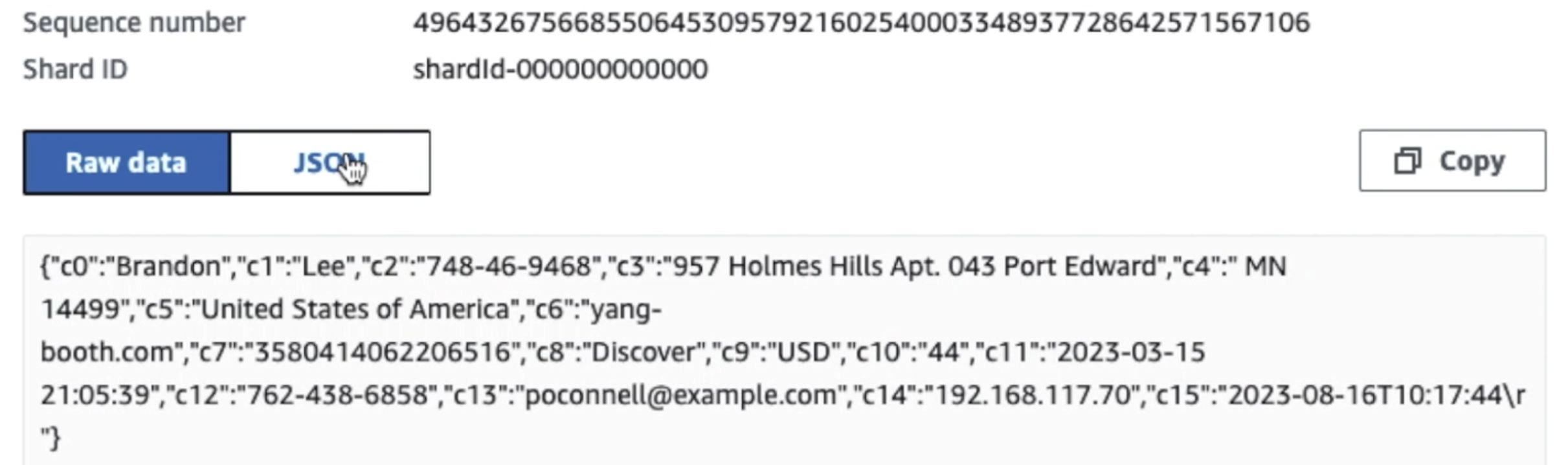
डेटा को एकत्र करने और काइनेसिस डेटा स्ट्रीम में शामिल करने और काइनेसिस डेटा फ़ायरहोज़ का उपयोग करके एस3 बकेट में वितरित करने के बाद, आर्किटेक्चर की प्रोसेसिंग परत कार्यभार संभाल लेती है। हम अपनी पाइपलाइन में संवेदनशील डेटा का पता लगाने और मास्किंग को स्वचालित करने के लिए AWS ग्लू PII ट्रांसफॉर्म का उपयोग करते हैं। जैसा कि निम्नलिखित वर्कफ़्लो आरेख में दिखाया गया है, हमने एडब्ल्यूएस ग्लू स्टूडियो में अपने परिवर्तन कार्य को लागू करने के लिए एक नो-कोड, विज़ुअल ईटीएल दृष्टिकोण अपनाया।
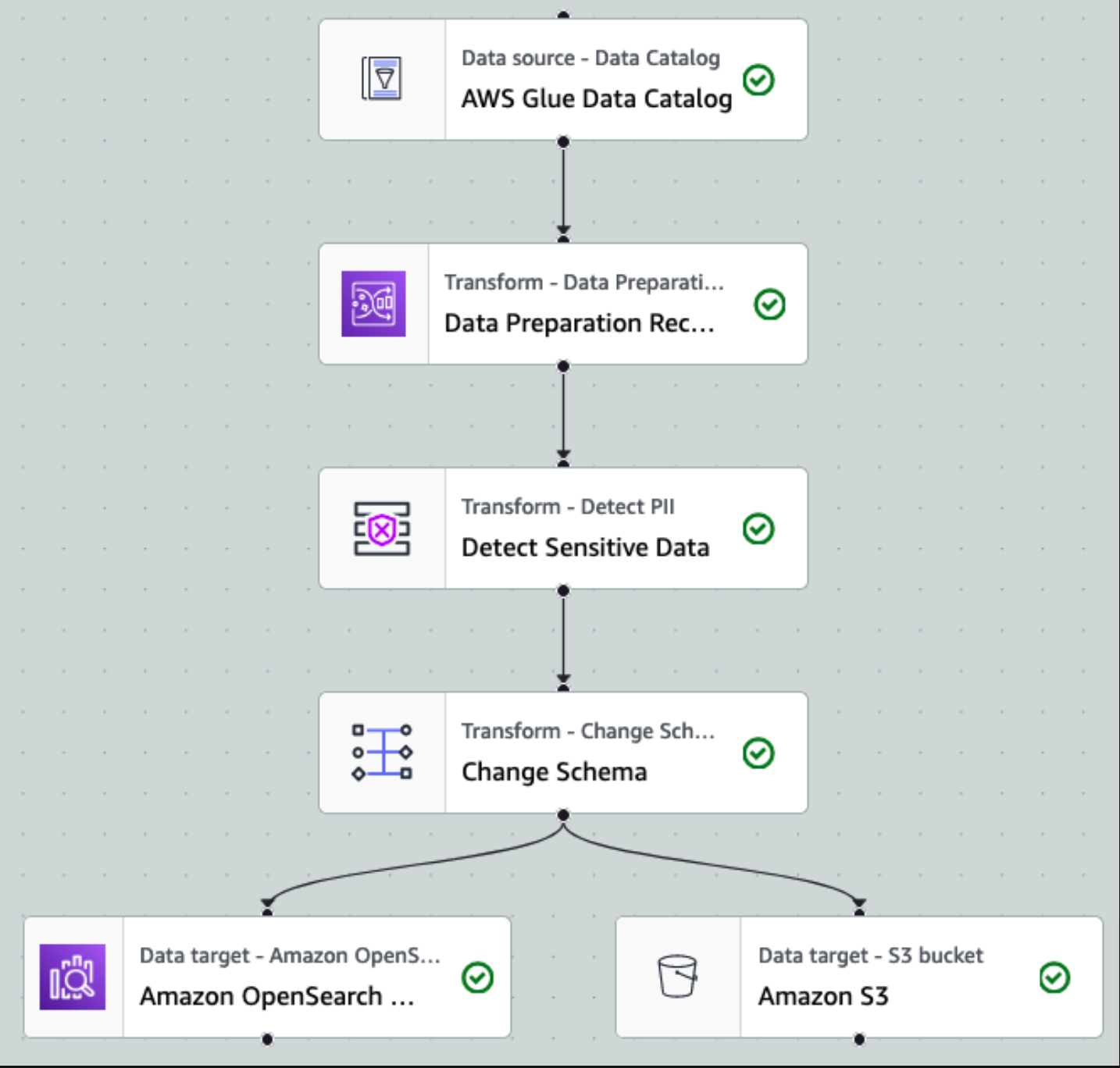
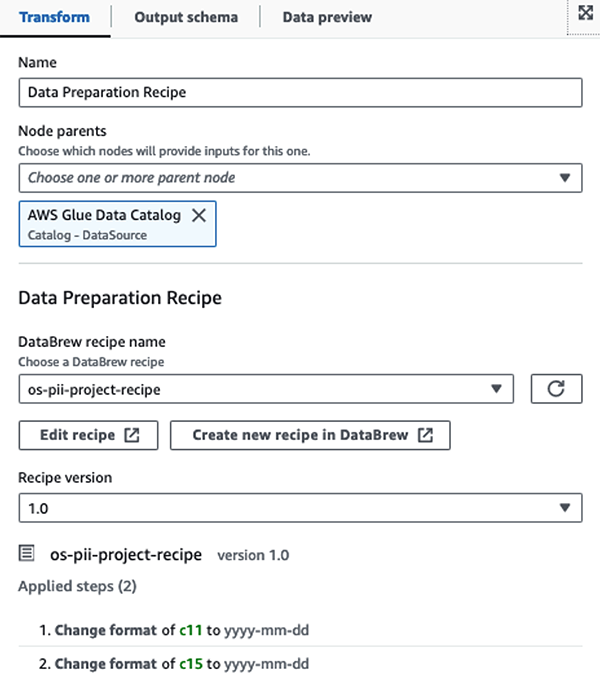
सबसे पहले, हम स्रोत डेटा कैटलॉग तालिका को रॉ से एक्सेस करते हैं pii_data_db डेटाबेस। तालिका में पिछले अनुभाग में प्रस्तुत स्कीमा संरचना है। कच्चे संसाधित डेटा का ट्रैक रखने के लिए, हमने इसका उपयोग किया नौकरी बुकमार्क.

हम उपयोग AWS ग्लू स्टूडियो विज़ुअल ETL जॉब में AWS ग्लू डेटाब्रू रेसिपी अपेक्षित ओपनसर्च के साथ संगत होने के लिए दो दिनांक विशेषताओं को रूपांतरित करना प्रारूपों. यह हमें पूर्ण नो-कोड अनुभव प्राप्त करने की अनुमति देता है।
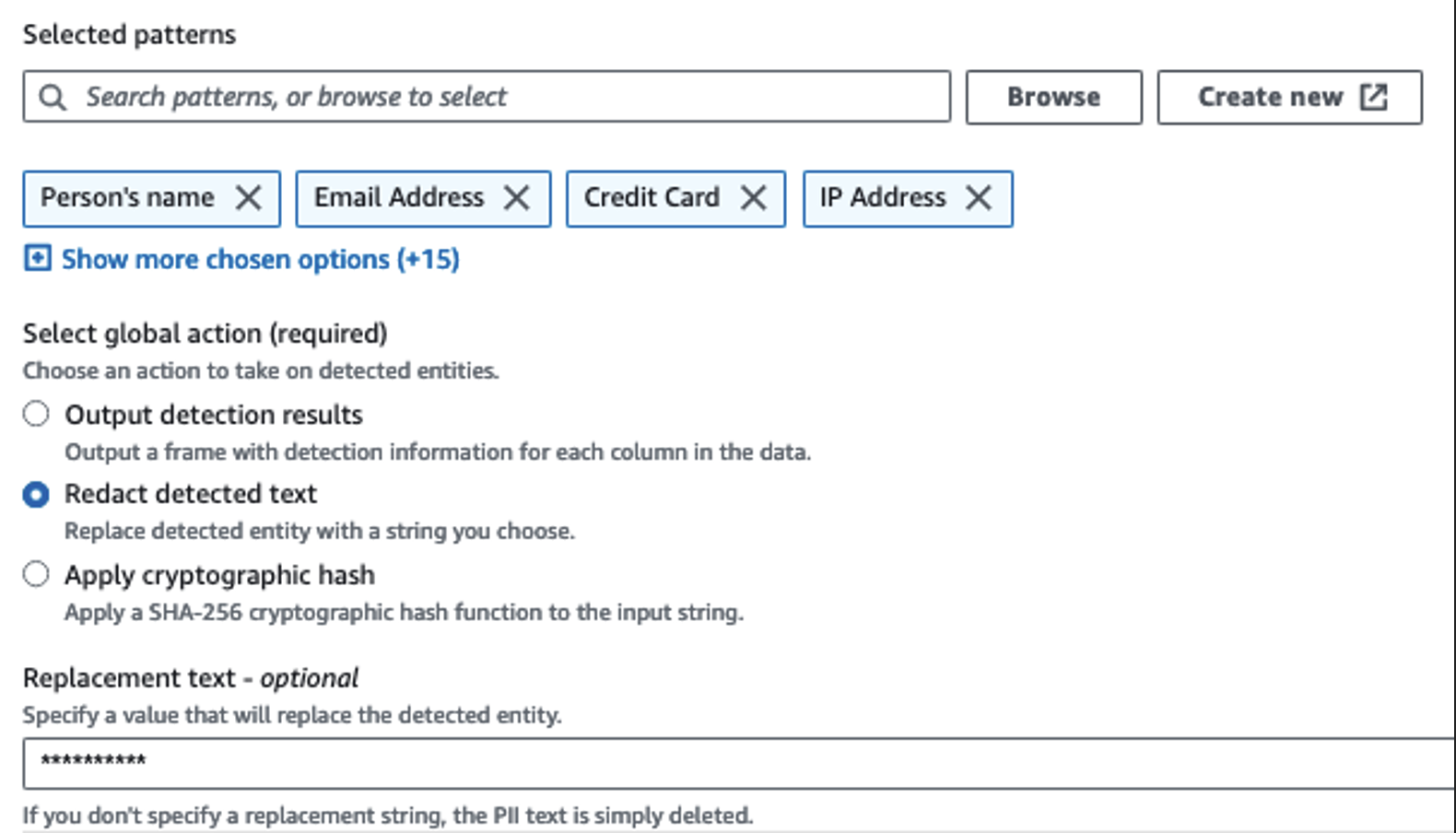
हम संवेदनशील कॉलमों की पहचान करने के लिए डिटेक्ट पीआईआई क्रिया का उपयोग करते हैं। हमने AWS ग्लू को डेटासेट से चयनित पैटर्न, डिटेक्शन थ्रेशोल्ड और पंक्तियों के नमूना भाग के आधार पर इसे निर्धारित करने दिया। हमारे उदाहरण में, हमने ऐसे पैटर्न का उपयोग किया जो विशेष रूप से संयुक्त राज्य अमेरिका (जैसे एसएसएन) पर लागू होते हैं और अन्य देशों के संवेदनशील डेटा का पता नहीं लगा सकते हैं। आप अपने उपयोग के मामले में लागू उपलब्ध श्रेणियों और स्थानों की तलाश कर सकते हैं या अन्य देशों के संवेदनशील डेटा के लिए पहचान इकाइयां बनाने के लिए एडब्ल्यूएस ग्लू में नियमित अभिव्यक्ति (रेगेक्स) का उपयोग कर सकते हैं।
AWS ग्लू द्वारा प्रदान की जाने वाली सही नमूना पद्धति का चयन करना महत्वपूर्ण है। इस उदाहरण में, यह ज्ञात है कि स्ट्रीम से आने वाले डेटा में प्रत्येक पंक्ति में संवेदनशील डेटा होता है, इसलिए डेटासेट में 100% पंक्तियों का नमूना लेना आवश्यक नहीं है। यदि आपके पास ऐसी आवश्यकता है जहां डाउनस्ट्रीम स्रोतों में किसी भी संवेदनशील डेटा की अनुमति नहीं है, तो आपके द्वारा चुने गए पैटर्न के लिए 100% डेटा का नमूना लेने पर विचार करें, या संपूर्ण डेटासेट को स्कैन करें और यह सुनिश्चित करने के लिए प्रत्येक व्यक्तिगत सेल पर कार्य करें कि सभी संवेदनशील डेटा का पता लगाया गया है। नमूनाकरण से आपको जो लाभ मिलता है वह कम लागत है क्योंकि आपको अधिक डेटा स्कैन नहीं करना पड़ता है।

संवेदनशील डेटा को मास्क करते समय डिटेक्ट पीआईआई क्रिया आपको एक डिफ़ॉल्ट स्ट्रिंग का चयन करने की अनुमति देती है। हमारे उदाहरण में, हम स्ट्रिंग ********** का उपयोग करते हैं।
हम नाम बदलने और अनावश्यक कॉलम जैसे हटाने के लिए मैपिंग लागू करें ऑपरेशन का उपयोग करते हैं ingestion_year, ingestion_month, तथा ingestion_day. यह चरण हमें किसी एक कॉलम के डेटा प्रकार को बदलने की भी अनुमति देता है (purchase_value) स्ट्रिंग से पूर्णांक तक।

इस बिंदु से, कार्य दो आउटपुट गंतव्यों में विभाजित हो जाता है: ओपनसर्च सेवा और अमेज़ॅन एस3।
हमारा प्रावधानित ओपनसर्च सेवा क्लस्टर इसके माध्यम से जुड़ा हुआ है गोंद के लिए ओपन सर्च अंतर्निर्मित कनेक्टर. हम उस ओपनसर्च इंडेक्स को निर्दिष्ट करते हैं जिस पर हम लिखना चाहते हैं और कनेक्टर क्रेडेंशियल्स, डोमेन और पोर्ट को संभालता है। नीचे दिए गए स्क्रीन शॉट में, हम निर्दिष्ट इंडेक्स को लिखते हैं index_os_pii.
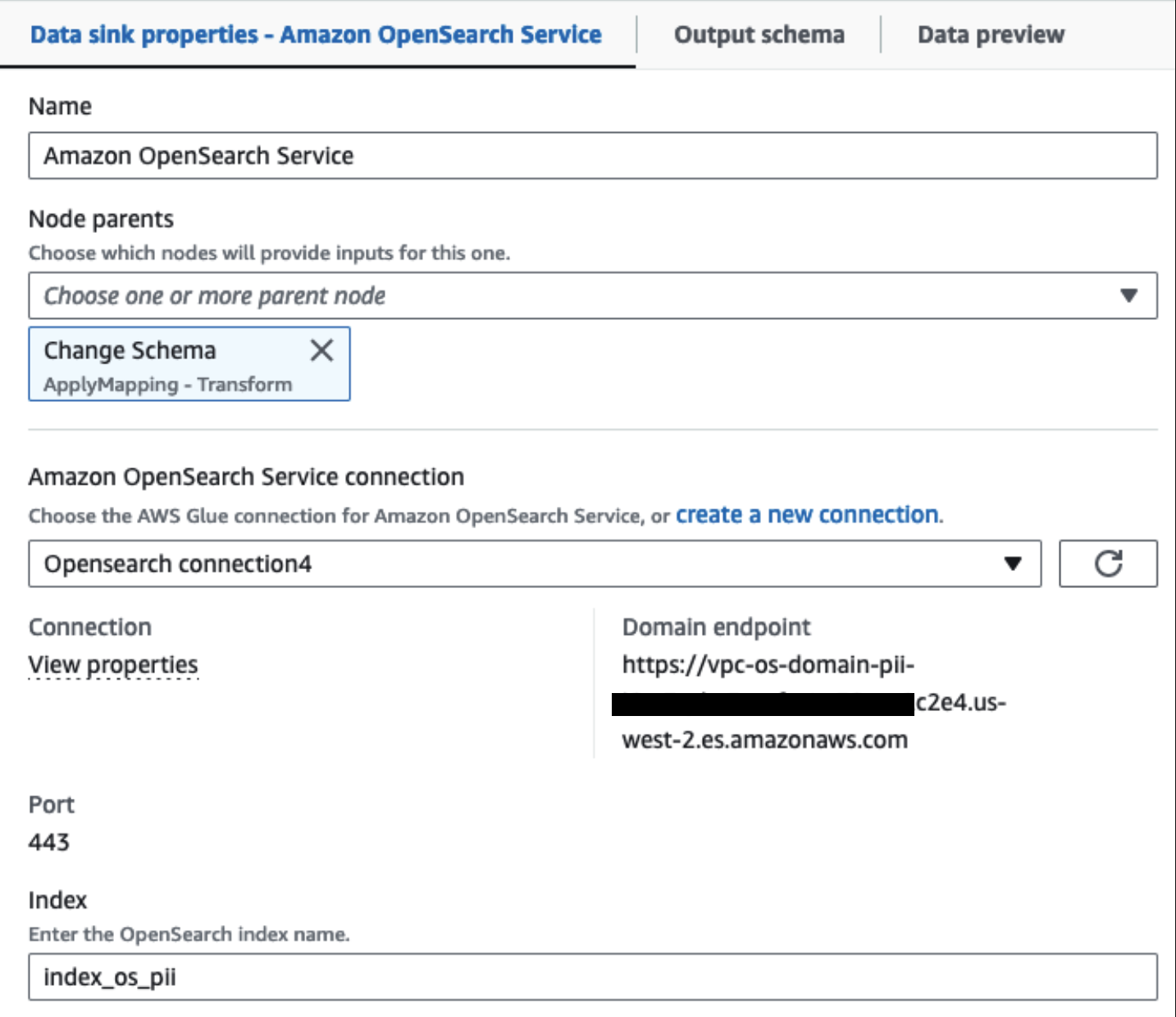
हम नकाबपोश डेटासेट को क्यूरेटेड S3 उपसर्ग में संग्रहीत करते हैं। वहां, हमारे पास डेटा को एक विशिष्ट उपयोग के मामले में सामान्यीकृत किया गया है और डेटा वैज्ञानिकों द्वारा या तदर्थ रिपोर्टिंग आवश्यकताओं के लिए सुरक्षित उपभोग किया गया है।
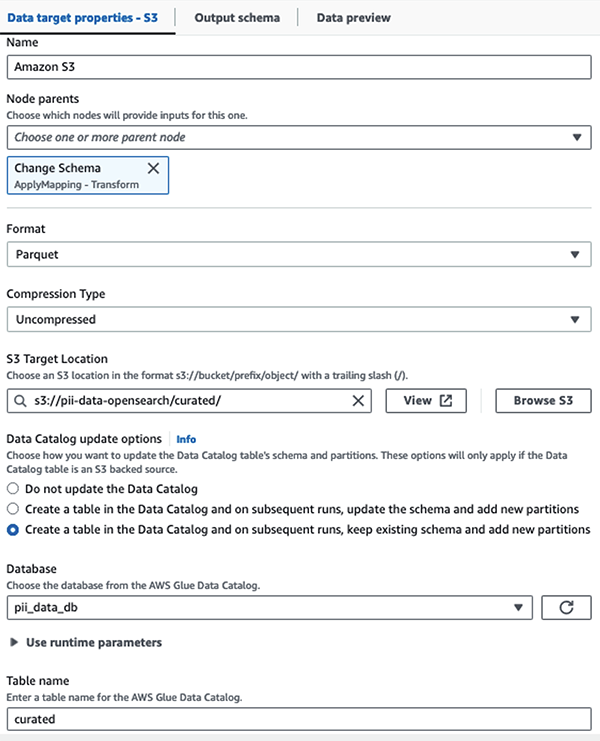
एकीकृत शासन, अभिगम नियंत्रण और सभी डेटासेट और डेटा कैटलॉग तालिकाओं के ऑडिट ट्रेल्स के लिए, आप इसका उपयोग कर सकते हैं AWS झील निर्माण. यह आपको AWS ग्लू डेटा कैटलॉग तालिकाओं और अंतर्निहित डेटा तक पहुंच को केवल उन उपयोगकर्ताओं और भूमिकाओं तक सीमित रखने में मदद करता है जिन्हें ऐसा करने के लिए आवश्यक अनुमति दी गई है।
बैच कार्य सफलतापूर्वक चलने के बाद, आप खोज क्वेरी या रिपोर्ट चलाने के लिए ओपनसर्च सेवा का उपयोग कर सकते हैं। जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है, पाइपलाइन बिना किसी कोड विकास प्रयास के संवेदनशील फ़ील्ड को स्वचालित रूप से छिपा देती है।

आप परिचालन डेटा से रुझानों की पहचान कर सकते हैं, जैसे कि क्रेडिट कार्ड प्रदाता द्वारा फ़िल्टर किए गए प्रति दिन लेनदेन की मात्रा, जैसा कि पिछले स्क्रीनशॉट में दिखाया गया है। आप वे स्थान और डोमेन भी निर्धारित कर सकते हैं जहां उपयोगकर्ता खरीदारी करते हैं। transaction_date विशेषता हमें समय के साथ इन रुझानों को देखने में मदद करती है। निम्नलिखित स्क्रीनशॉट लेन-देन की सभी जानकारी को उचित रूप से संपादित करते हुए एक रिकॉर्ड दिखाता है।
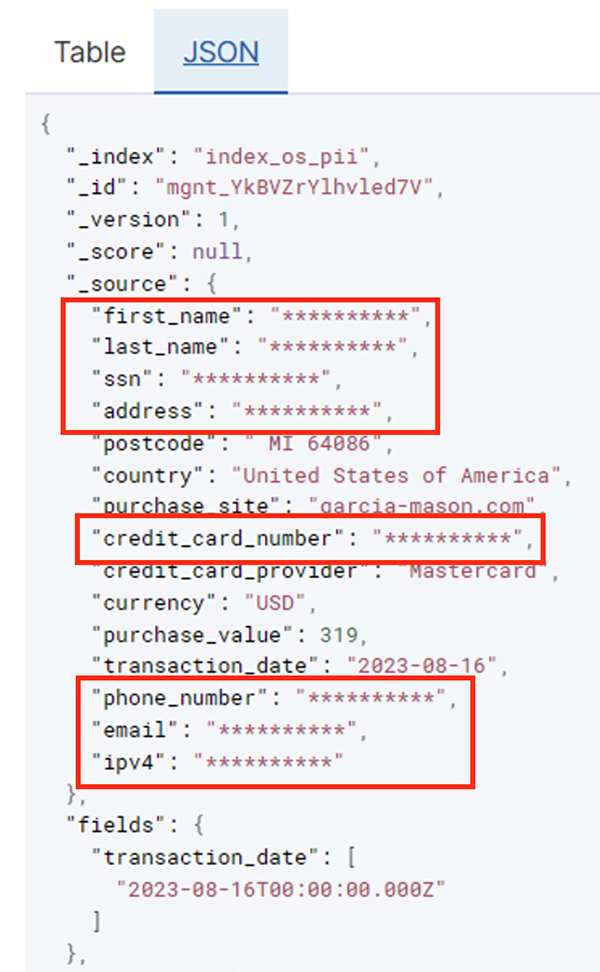
Amazon OpenSearch में डेटा कैसे लोड करें, इसके वैकल्पिक तरीकों के लिए देखें अमेज़ॅन ओपनसर्च सेवा में स्ट्रीमिंग डेटा लोड हो रहा है.
इसके अलावा, संवेदनशील डेटा को अन्य AWS समाधानों का उपयोग करके भी खोजा और छिपाया जा सकता है। उदाहरण के लिए, आप उपयोग कर सकते हैं अमेज़ॅन मैकी S3 बकेट के अंदर संवेदनशील डेटा का पता लगाने के लिए, और फिर उपयोग करें Amazon Comprehend पता लगाए गए संवेदनशील डेटा को संशोधित करने के लिए। अधिक जानकारी के लिए देखें AWS सेवाओं का उपयोग करके PHI और PII डेटा का पता लगाने की सामान्य तकनीकें.
निष्कर्ष
इस पोस्ट में आपके वातावरण में संवेदनशील डेटा को संभालने के महत्व और अनुपालन में बने रहने के लिए विभिन्न तरीकों और आर्किटेक्चर पर चर्चा की गई है, साथ ही आपके संगठन को तेजी से बढ़ने की अनुमति भी दी गई है। अब आपको इस बात की अच्छी समझ होनी चाहिए कि अपने डेटा का पता कैसे लगाया जाए, मास्क किया जाए या कैसे संशोधित किया जाए और उसे Amazon OpenSearch सेवा में कैसे लोड किया जाए।
लेखक के बारे में
 माइकल हैमिल्टन एक सीनियर एनालिटिक्स सॉल्यूशंस आर्किटेक्ट है जो एंटरप्राइज़ ग्राहकों को AWS पर उनके एनालिटिक्स वर्कलोड को आधुनिक बनाने और सरल बनाने में मदद करने पर ध्यान केंद्रित कर रहा है। जब वह काम नहीं कर रहे होते हैं तो उन्हें माउंटेन बाइकिंग और अपनी पत्नी और तीन बच्चों के साथ समय बिताना अच्छा लगता है।
माइकल हैमिल्टन एक सीनियर एनालिटिक्स सॉल्यूशंस आर्किटेक्ट है जो एंटरप्राइज़ ग्राहकों को AWS पर उनके एनालिटिक्स वर्कलोड को आधुनिक बनाने और सरल बनाने में मदद करने पर ध्यान केंद्रित कर रहा है। जब वह काम नहीं कर रहे होते हैं तो उन्हें माउंटेन बाइकिंग और अपनी पत्नी और तीन बच्चों के साथ समय बिताना अच्छा लगता है।
 डेनियल रोज़ोज़ नीदरलैंड में AWS के ग्राहकों को सहायता देने वाला एक वरिष्ठ समाधान वास्तुकार है। उनका जुनून सरल डेटा और एनालिटिक्स समाधानों की इंजीनियरिंग करना और ग्राहकों को आधुनिक डेटा आर्किटेक्चर की ओर बढ़ने में मदद करना है। काम के अलावा, उन्हें टेनिस खेलना और बाइक चलाना पसंद है।
डेनियल रोज़ोज़ नीदरलैंड में AWS के ग्राहकों को सहायता देने वाला एक वरिष्ठ समाधान वास्तुकार है। उनका जुनून सरल डेटा और एनालिटिक्स समाधानों की इंजीनियरिंग करना और ग्राहकों को आधुनिक डेटा आर्किटेक्चर की ओर बढ़ने में मदद करना है। काम के अलावा, उन्हें टेनिस खेलना और बाइक चलाना पसंद है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :हैस
- :है
- :नहीं
- :कहाँ
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- क्षमता
- योग्य
- त्वरित
- पहुँच
- अधिनियम
- कार्य
- Ad
- पता
- एजेंट
- सब
- की अनुमति दी
- की अनुमति दे
- की अनुमति देता है
- भी
- हमेशा
- वीरांगना
- अमेज़ॅन किनिस
- अमेज़ॅन वेब सेवा
- अमेज़ॅन वेब सेवा (एडब्ल्यूएस)
- राशि
- राशियाँ
- an
- विश्लेषणात्मक
- विश्लेषिकी
- और
- कोई
- उपयुक्त
- अनुप्रयोगों
- लागू करें
- दृष्टिकोण
- उचित रूप से
- स्थापत्य
- हैं
- AS
- At
- विशेषताओं
- आडिट
- को स्वचालित रूप से
- स्वतः
- उपलब्धता
- उपलब्ध
- एडब्ल्यूएस
- एडब्ल्यूएस गोंद
- बैकअप
- बैंकिंग
- बैंकिंग सिस्टम
- आधारित
- BE
- क्योंकि
- किया गया
- से पहले
- जा रहा है
- नीचे
- लाभ
- लाना
- निर्माण
- बनाया गया
- में निर्मित
- लेकिन
- by
- कर सकते हैं
- क्षमताओं
- क्षमता
- कब्जा
- कार्ड
- मामला
- मामलों
- सूची
- श्रेणियाँ
- सीडीसी
- सेल
- परिवर्तन
- परिवर्तन
- चैनलों
- बच्चे
- चुना
- स्पष्टता
- बादल
- समूह
- कोड
- स्तंभ
- स्तंभ
- कैसे
- आता है
- अ रहे है
- संगत
- आज्ञाकारी
- घटकों
- शामिल
- गणना करना
- चिंताओं
- जुड़ा हुआ
- विचार करना
- माना
- प्रयुक्त
- खपत
- शामिल
- प्रसंग
- जारी रखने के
- नियंत्रण
- सही
- लागत
- सका
- देशों
- बनाना
- साख
- श्रेय
- क्रेडिट कार्ड
- क्यूरेट
- वर्तमान
- ग्राहक
- तिथि
- डेटा विश्लेषण
- डेटा एकीकरण
- डेटा लेक
- डेटा प्लेटफार्म
- गोपनीय आँकड़ा
- डेटा रणनीति
- डाटाबेस
- डेटाबेस
- डेटासेट
- तारीख
- दिन
- चूक
- परिभाषित
- दिया गया
- दिखाना
- दर्शाता
- तैनात
- डिज़ाइन
- गंतव्य
- स्थलों
- विवरण
- पता लगाना
- पता चला
- खोज
- निर्धारित करना
- विकास
- विकास दल
- विभिन्न
- सीधे
- अन्य वायरल पोस्ट से
- की खोज
- चर्चा की
- do
- डोमेन
- डोमेन
- dont
- से प्रत्येक
- प्रयासों
- ईमेल
- अभियांत्रिकी
- सुनिश्चित
- उद्यम
- उद्यम ग्राहकों
- संपूर्ण
- संस्थाओं
- वातावरण
- ईथर (ईटीएच)
- और भी
- घटनाओं
- प्रत्येक
- उदाहरण
- उदाहरण
- अपेक्षित
- अनुभव
- भाव
- बाहरी
- फास्ट
- फ़ील्ड
- पट्टिका
- फ़ाइलें
- वित्तीय
- वित्तीय सेवाओं
- प्रथम
- बहता हुआ
- प्रवाह
- ध्यान केंद्रित
- पीछा किया
- निम्नलिखित
- इस प्रकार है
- के लिए
- ढांचा
- से
- पूर्ण
- पूरी तरह से
- भविष्य
- सृजन
- मिल
- अच्छा
- शासन
- दी गई
- हैंडल
- हैंडलिंग
- है
- he
- स्वास्थ्य
- स्वास्थ्य जानकारी
- मदद
- मदद
- मदद करता है
- उच्च स्तर
- उसके
- ऐतिहासिक
- कैसे
- How To
- एचटीएमएल
- http
- HTTPS
- सैकड़ों
- पहचान करना
- if
- दिखाता है
- कल्पना करना
- लागू करने के
- महत्व
- महत्वपूर्ण
- in
- शामिल
- सहित
- अनुक्रमणिका
- व्यक्ति
- करें-
- इंफ्रास्ट्रक्चर
- अंदर
- एकीकरण
- आंतरिक
- में
- IT
- जावा
- काम
- नौकरियां
- जेपीजी
- JSON
- रखना
- किनेसिस डेटा फायरहोज
- किनेसिस डेटा स्ट्रीम
- जानने वाला
- झील
- भूमि
- भूमि
- बड़ा
- पिछली बार
- बाद में
- कानून
- कानून और नियम
- परत
- परतों
- नेतृत्व
- चलो
- पुस्तकालय
- जीवन चक्र
- पसंद
- लाइन
- भार
- लोड हो रहा है
- स्थानों
- देखिए
- कम लागत
- मुख्य
- को बनाए रखने
- बनाना
- कामयाब
- बहुत
- मानचित्रण
- मुखौटा
- मई..
- तरीका
- तरीकों
- विस्थापित
- प्रवास
- आधुनिक
- आधुनिकीकरण
- निगरानी
- अधिक
- पहाड़
- चाल
- चलती
- बहुत
- विभिन्न
- चाहिए
- नाम
- नामों
- आवश्यक
- आवश्यकता
- जरूरत
- ज़रूरत
- की जरूरत है
- नीदरलैंड्स
- नया
- नहीं
- नोड्स
- सूचना..
- अभी
- संख्या
- of
- ऑफर
- on
- ONE
- केवल
- आपरेशन
- परिचालन
- संचालन
- के अनुकूलन के
- ऑप्शंस
- or
- संगठन
- संगठनों
- अन्य
- हमारी
- उत्पादन
- बाहर
- के ऊपर
- भाग
- जुनून
- पैच
- पैटर्न उपयोग करें
- वेतन
- भुगतान
- प्रति
- निष्पादन
- प्रदर्शन
- अनुमतियाँ
- व्यक्तिगत रूप से
- फ़ोन
- Pii
- पाइपलाइन
- योजना
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- खेल
- बिन्दु
- हिस्सा
- पद
- पूर्ववर्ती
- प्रस्तुत
- पिछला
- एकांत
- गोपनीयता कानून
- संसाधित
- प्रक्रियाओं
- प्रसंस्करण
- उत्पादक
- संरक्षित
- प्रोटोकॉल
- प्रदाता
- प्रदान करता है
- खरीद
- प्रश्नों
- जल्दी से
- बल्कि
- कच्चा
- कच्चा डेटा
- वास्तविक समय
- कारण
- प्राप्त
- व्यंजन विधि
- की सिफारिश की
- रिकॉर्ड
- अभिलेख
- घटी
- उल्लेख
- नियमित
- नियम
- विश्वसनीयता
- रहना
- हटाना
- रिपोर्टिंग
- रिपोर्ट
- की आवश्यकता होती है
- आवश्यकता
- आवश्यकताएँ
- जिम्मेदारियों
- जिम्मेदार
- रोकना
- परिणाम
- भूमिकाओं
- आरओडब्ल्यू
- रन
- चलाता है
- सास
- त्याग
- सुरक्षित
- सुरक्षित
- वही
- स्केल
- स्कैन
- अनुसूची
- वैज्ञानिकों
- स्क्रीन
- एसडीके
- Search
- अनुभाग
- सुरक्षित रूप से
- सुरक्षा
- देखना
- चयन
- चयनित
- वरिष्ठ
- संवेदनशील
- भेजा
- सेवा
- सेवाएँ
- शॉट
- चाहिए
- दिखाया
- दिखाता है
- सरल
- को आसान बनाने में
- छोटा
- So
- सोशल मीडिया
- सॉफ्टवेयर
- एक सेवा के रूप में सॉफ्टवेयर
- समाधान
- समाधान ढूंढे
- स्रोत
- सूत्रों का कहना है
- विशिष्ट
- विशेष रूप से
- विनिर्दिष्ट
- बिताना
- खर्च
- विभाजन
- चरणों
- राज्य
- कदम
- भंडारण
- की दुकान
- सरल
- स्ट्रेटेजी
- धारा
- स्ट्रीमिंग
- नदियों
- तार
- संरचना
- संरचित
- स्टूडियो
- आगामी
- सफलतापूर्वक
- ऐसा
- उपयुक्त
- समर्थित
- सहायक
- प्रणाली
- सिस्टम
- तालिका
- लेता है
- लक्ष्य
- टीम
- टीमों
- तकनीक
- टेनिस
- है
- से
- कि
- RSI
- भविष्य
- नीदरलैंड
- स्रोत
- लेकिन हाल ही
- फिर
- वहाँ।
- इन
- इसका
- उन
- तीन
- द्वार
- यहाँ
- पहर
- सेवा मेरे
- ले गया
- उपकरण
- ट्रैक
- लेनदेन
- स्थानांतरण
- स्थानान्तरण
- बदालना
- परिवर्तन
- रुझान
- शुरू हो रहा
- दो
- टाइप
- प्रकार
- अंत में
- आधारभूत
- समझ
- एकीकृत
- यूनाइटेड
- संयुक्त राज्य अमेरिका
- us
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ताओं
- का उपयोग
- मूल्य
- विविधता
- विभिन्न
- के माध्यम से
- दृश्य
- चलना
- था
- तरीके
- we
- वेब
- वेब सेवाओं
- क्या
- कब
- कौन कौन से
- जब
- कौन
- पत्नी
- मर्जी
- साथ में
- अंदर
- बिना
- काम
- वर्कफ़्लो
- काम कर रहे
- लिखना
- इसलिए आप
- आपका
- जेफिरनेट