यह AWS और Voxel51 द्वारा सह-लिखित एक संयुक्त पोस्ट है। Voxel51, FiftyOne के पीछे की कंपनी है, जो उच्च-गुणवत्ता वाले डेटासेट और कंप्यूटर विज़न मॉडल बनाने के लिए ओपन-सोर्स टूलकिट है।
एक रिटेल कंपनी ग्राहकों को कपड़े खरीदने में मदद करने के लिए एक मोबाइल ऐप बना रही है। इस ऐप को बनाने के लिए, उन्हें एक उच्च-गुणवत्ता वाले डेटासेट की आवश्यकता होती है जिसमें कपड़ों की छवियां होती हैं, जिन्हें विभिन्न श्रेणियों के साथ लेबल किया जाता है। इस पोस्ट में, हम दिखाते हैं कि डेटा की सफाई, प्रीप्रोसेसिंग और शून्य-शॉट वर्गीकरण मॉडल के साथ प्री-लेबलिंग के माध्यम से मौजूदा डेटासेट का पुनरुत्पादन कैसे करें। इक्यावन, और इन लेबलों को इसके साथ समायोजित करना अमेज़ॅन सैजमेकर ग्राउंड ट्रुथ.
आप अपने डेटा लेबलिंग प्रोजेक्ट को गति देने के लिए ग्राउंड ट्रुथ और फिफ्टीवन का उपयोग कर सकते हैं। हम बताते हैं कि उच्च गुणवत्ता वाले लेबल वाले डेटासेट बनाने के लिए दो एप्लिकेशन को एक साथ कैसे उपयोग किया जाए। हमारे उदाहरण उपयोग मामले के लिए, हम साथ काम करते हैं Fashion200K डेटासेट, ICCV 2017 में जारी किया गया।
समाधान अवलोकन
ग्राउंड ट्रुथ पूरी तरह से स्व-सेवारत और प्रबंधित डेटा लेबलिंग सेवा है जो डेटा वैज्ञानिकों, मशीन लर्निंग (एमएल) इंजीनियरों और शोधकर्ताओं को उच्च-गुणवत्ता वाले डेटासेट बनाने के लिए सशक्त बनाती है। इक्यावन by वोक्सेल51 कंप्यूटर विज़न डेटासेट को क्यूरेट करने, विज़ुअलाइज़ करने और मूल्यांकन करने के लिए एक ओपन-सोर्स टूलकिट है ताकि आप अपने उपयोग के मामलों में तेजी लाकर बेहतर मॉडल का प्रशिक्षण और विश्लेषण कर सकें।
निम्नलिखित अनुभागों में, हम प्रदर्शित करते हैं कि निम्नलिखित कैसे करें:
- डेटासेट को FiftyOne में विज़ुअलाइज़ करें
- FiftyOne में डेटासेट को फ़िल्टरिंग और इमेज डिडुप्लीकेशन से साफ़ करें
- फिफ्टीवन में शून्य-शॉट वर्गीकरण के साथ साफ किए गए डेटा को प्री-लेबल करें
- ग्राउंड ट्रूथ के साथ छोटे क्यूरेटेड डेटासेट को लेबल करें
- ग्राउंड ट्रूथ से फिफ्टीवन में लेबल किए गए परिणामों को इंजेक्ट करें और फिफ्टीवन में लेबल किए गए परिणामों की समीक्षा करें
केस अवलोकन का उपयोग करें
मान लीजिए कि आप एक खुदरा कंपनी के मालिक हैं और उपयोगकर्ताओं को यह तय करने में मदद करने के लिए कि क्या पहनना है, वैयक्तिकृत अनुशंसाएँ देने के लिए एक मोबाइल एप्लिकेशन बनाना चाहते हैं। आपके संभावित उपयोगकर्ता एक ऐसे एप्लिकेशन की तलाश कर रहे हैं जो उन्हें बताए कि उनकी अलमारी में कौन से कपड़े एक साथ अच्छी तरह से काम करते हैं। आप यहां एक अवसर देखते हैं: यदि आप अच्छे परिधानों की पहचान कर सकते हैं, तो आप इसका उपयोग कपड़ों की नई वस्तुओं की सिफारिश करने के लिए कर सकते हैं जो ग्राहक के पास पहले से मौजूद कपड़ों के पूरक हों।
आप एंड-यूज़र के लिए चीजों को जितना संभव हो उतना आसान बनाना चाहते हैं। आदर्श रूप से, आपके एप्लिकेशन का उपयोग करने वाले किसी व्यक्ति को केवल अपनी अलमारी में कपड़ों की तस्वीरें लेने की आवश्यकता होती है, और आपके एमएल मॉडल पर्दे के पीछे अपना जादू चलाते हैं। आप एक सामान्य-उद्देश्य वाले मॉडल को प्रशिक्षित कर सकते हैं या प्रत्येक उपयोगकर्ता की अनूठी शैली के लिए किसी प्रकार की प्रतिक्रिया के साथ एक मॉडल को ठीक कर सकते हैं।
हालांकि, सबसे पहले, आपको यह पहचानने की आवश्यकता है कि उपयोगकर्ता किस प्रकार के कपड़ों को कैप्चर कर रहा है। क्या यह शर्ट है? पैंट? या कुछ और? आखिरकार, आप शायद ऐसे आउटफिट की सिफारिश नहीं करना चाहेंगे जिसमें कई ड्रेस या कई टोपी हों।
इस प्रारंभिक चुनौती का समाधान करने के लिए, आप विभिन्न पैटर्न और शैलियों के साथ कपड़ों के विभिन्न लेखों की छवियों से युक्त एक प्रशिक्षण डेटासेट बनाना चाहते हैं। सीमित बजट के साथ प्रोटोटाइप करने के लिए, आप मौजूदा डेटासेट का उपयोग करके बूटस्ट्रैप करना चाहते हैं।
इस पोस्ट में प्रक्रिया को समझने और आपको समझाने के लिए, हम ICCV 200 में जारी Fashion2017K डेटासेट का उपयोग करते हैं। यह एक स्थापित और अच्छी तरह से उद्धृत डेटासेट है, लेकिन यह आपके उपयोग के मामले के लिए सीधे अनुकूल नहीं है।
यद्यपि कपड़ों के लेख श्रेणियों (और उपश्रेणियों) के साथ लेबल किए जाते हैं और मूल उत्पाद विवरण से निकाले गए विभिन्न सहायक टैग होते हैं, डेटा को व्यवस्थित रूप से पैटर्न या शैली की जानकारी के साथ लेबल नहीं किया जाता है। आपका लक्ष्य इस मौजूदा डेटासेट को अपने कपड़ों के वर्गीकरण मॉडल के लिए एक मजबूत प्रशिक्षण डेटासेट में बदलना है। आपको स्टाइल लेबल के साथ लेबलिंग स्कीमा को बढ़ाते हुए, डेटा को साफ़ करने की आवश्यकता है। और आप इसे जल्दी और कम से कम खर्च में करना चाहते हैं।
स्थानीय रूप से डेटा डाउनलोड करें
सबसे पहले, में दिए गए निर्देशों का पालन करते हुए Women.tar Zip फ़ाइल और लेबल फ़ोल्डर (इसके सभी सबफ़ोल्डर के साथ) डाउनलोड करें Fashion200K डेटासेट GitHub रिपॉजिटरी. उन दोनों को अनज़िप करने के बाद, मूल निर्देशिका Fashion200k बनाएँ, और इसमें लेबल और महिला फ़ोल्डर ले जाएँ। सौभाग्य से, इन छवियों को पहले ही ऑब्जेक्ट डिटेक्शन बाउंडिंग बॉक्स में क्रॉप कर दिया गया है, इसलिए हम ऑब्जेक्ट डिटेक्शन के बारे में चिंता करने के बजाय वर्गीकरण पर ध्यान केंद्रित कर सकते हैं।
इसके मोनिकर में "200K" के बावजूद, हमारे द्वारा निकाली गई महिला निर्देशिका में 338,339 चित्र हैं। आधिकारिक Fashion200K डेटासेट उत्पन्न करने के लिए, डेटासेट के लेखकों ने 300,000 से अधिक उत्पादों को ऑनलाइन क्रॉल किया, और केवल चार से अधिक शब्दों वाले विवरण वाले उत्पादों ने कटौती की। हमारे उद्देश्यों के लिए, जहां उत्पाद विवरण आवश्यक नहीं है, हम क्रॉल की गई सभी छवियों का उपयोग कर सकते हैं।
आइए देखें कि यह डेटा कैसे व्यवस्थित किया जाता है: महिला फ़ोल्डर के भीतर, छवियों को शीर्ष-स्तरीय लेख प्रकार (स्कर्ट, टॉप, पैंट, जैकेट और कपड़े), और लेख प्रकार उपश्रेणी (ब्लाउज, टी-शर्ट, लंबी बाजू वाली) द्वारा व्यवस्थित किया जाता है। सबसे ऊपर)।
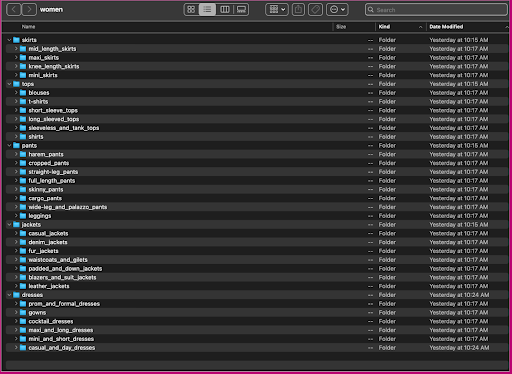
उपश्रेणी निर्देशिकाओं के भीतर, प्रत्येक उत्पाद प्रविष्टि के लिए एक उपनिर्देशिका होती है। इनमें से प्रत्येक में छवियों की एक चर संख्या होती है। उदाहरण के लिए, क्रॉप्ड_पैंट उपश्रेणी में निम्नलिखित उत्पाद प्रविष्टियां और संबंधित चित्र शामिल हैं।
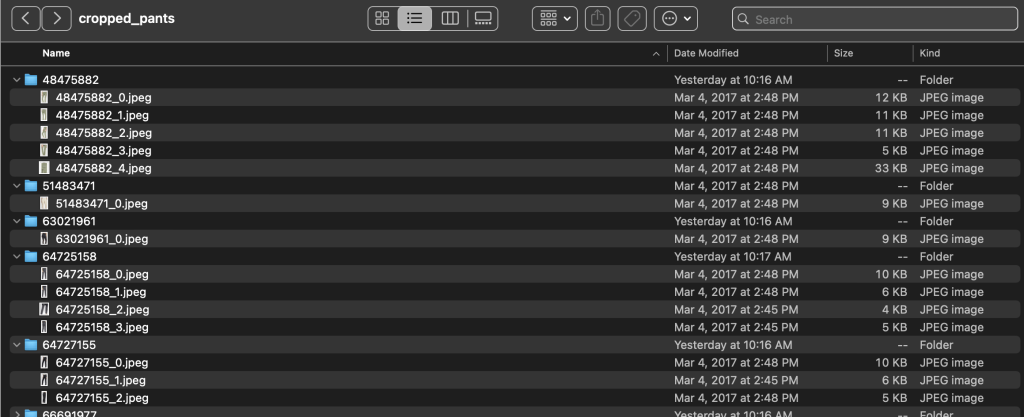
लेबल फ़ोल्डर में प्रशिक्षण और परीक्षण विभाजन दोनों के लिए प्रत्येक शीर्ष-स्तरीय लेख प्रकार के लिए एक पाठ फ़ाइल होती है। इन पाठ फ़ाइलों में से प्रत्येक के भीतर प्रत्येक छवि के लिए एक अलग पंक्ति है, जो उत्पाद विवरण से संबंधित फ़ाइल पथ, एक स्कोर और टैग निर्दिष्ट करती है।
क्योंकि हम डेटासेट को फिर से तैयार कर रहे हैं, हम सभी ट्रेन और परीक्षण छवियों को जोड़ते हैं। हम इनका उपयोग उच्च-गुणवत्ता वाले एप्लिकेशन-विशिष्ट डेटासेट बनाने के लिए करते हैं। इस प्रक्रिया को पूरा करने के बाद, हम परिणामी डेटासेट को बेतरतीब ढंग से नई ट्रेन और परीक्षण विभाजन में विभाजित कर सकते हैं।
FiftyOne में डेटासेट इंजेक्ट करें, देखें और क्यूरेट करें
यदि आपने पहले से ऐसा नहीं किया है, तो पाइप का उपयोग करके ओपन-सोर्स फिफ्टीऑन स्थापित करें:
एक नए आभासी (वेनव या कोंडा) वातावरण में ऐसा करना एक सर्वोत्तम अभ्यास है। फिर संबंधित मॉड्यूल आयात करें। बेस लाइब्रेरी, इफ्टीवन, फिफ्टीवन ब्रेन, जिसमें बिल्ट-इन एमएल पद्धतियां हैं, फिफ्टीवन जू आयात करें, जिससे हम एक मॉडल लोड करेंगे जो हमारे लिए जीरो-शॉट लेबल उत्पन्न करेगा, और व्यूफिल्ड, जो हमें प्रभावी रूप से फ़िल्टर करने देता है हमारे डेटासेट में डेटा:
आप ग्लोब और ओएस पायथन मॉड्यूल भी आयात करना चाहते हैं, जो हमें निर्देशिका सामग्री पर पथ और पैटर्न मिलान के साथ काम करने में मदद करेगा:
अब हम डेटासेट को FiftyOne में लोड करने के लिए तैयार हैं। सबसे पहले, हम Fashion200k नाम का एक डेटासेट बनाते हैं और इसे लगातार बनाते हैं, जो हमें कम्प्यूटेशनल रूप से गहन संचालन के परिणामों को बचाने की अनुमति देता है, इसलिए हमें केवल एक बार उक्त मात्राओं की गणना करने की आवश्यकता होती है।
अब हम उत्पाद निर्देशिकाओं के भीतर सभी छवियों को जोड़ते हुए, सभी उपश्रेणी निर्देशिकाओं के माध्यम से पुनरावृति कर सकते हैं। हम प्रत्येक नमूने में एक फिफ्टीवन वर्गीकरण लेबल जोड़ते हैं जिसका फ़ील्ड नाम article_type है, जो छवि की शीर्ष-स्तरीय लेख श्रेणी द्वारा पॉप्युलेट किया गया है। हम टैग के रूप में श्रेणी और उपश्रेणी दोनों जानकारी भी जोड़ते हैं:
इस बिंदु पर, हम एक सत्र शुरू करके FiftyOne ऐप में अपने डेटासेट की कल्पना कर सकते हैं:
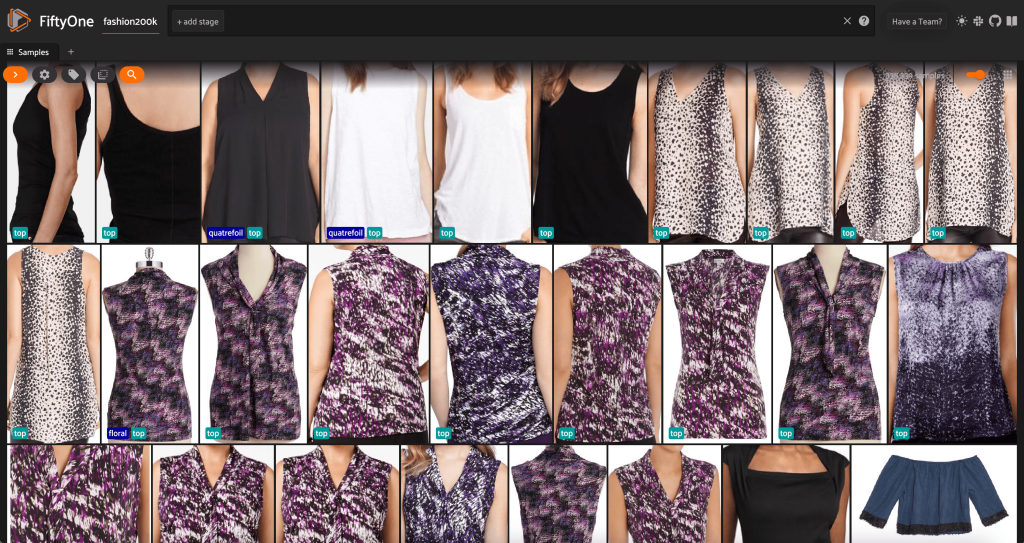
हम दौड़कर पायथन में डेटासेट का सारांश भी प्रिंट कर सकते हैं print(dataset):
हम से टैग भी जोड़ सकते हैं labels हमारे डेटासेट में नमूने के लिए निर्देशिका:
आंकड़ों पर नजर डालें तो कुछ बातें साफ होती हैं:
- कम रिज़ॉल्यूशन वाली कुछ छवियां काफी दानेदार हैं। ऐसा इसलिए हो सकता है क्योंकि ये इमेज ऑब्जेक्ट डिटेक्शन बाउंडिंग बॉक्स में शुरुआती इमेज को क्रॉप करके जनरेट की गई थीं.
- कुछ कपड़े इंसान पहनता है तो कुछ खुद ही फोटो खिंचवा लेता है। इन विवरणों को इसके द्वारा समझाया गया है
viewpointसंपत्ति। - एक ही उत्पाद की बहुत सारी छवियां बहुत समान हैं, इसलिए कम से कम शुरुआत में, प्रति उत्पाद एक से अधिक छवियों को शामिल करने से बहुत अधिक पूर्वानुमान शक्ति नहीं जुड़ सकती है। अधिकांश भाग के लिए, प्रत्येक उत्पाद की पहली छवि (अंत में
_0.jpeg) सबसे साफ है।
प्रारंभ में, हम अपने कपड़ों की शैली वर्गीकरण मॉडल को इन छवियों के नियंत्रित उपसमुच्चय पर प्रशिक्षित करना चाह सकते हैं। इसके लिए, हम अपने उत्पादों की उच्च-रिज़ॉल्यूशन छवियों का उपयोग करते हैं, और प्रति उत्पाद एक प्रतिनिधि नमूने के लिए हमारे विचार को सीमित करते हैं।
सबसे पहले, हम कम-रिज़ॉल्यूशन वाली छवियों को फ़िल्टर करते हैं। हम उपयोग करते हैं compute_metadata() डेटासेट में प्रत्येक छवि के लिए पिक्सेल में छवि की चौड़ाई और ऊंचाई की गणना और संग्रह करने की विधि। फिर हम फिफ्टीवन को नियुक्त करते हैं ViewField न्यूनतम अनुमत चौड़ाई और ऊंचाई मानों के आधार पर छवियों को फ़िल्टर करने के लिए। निम्न कोड देखें:
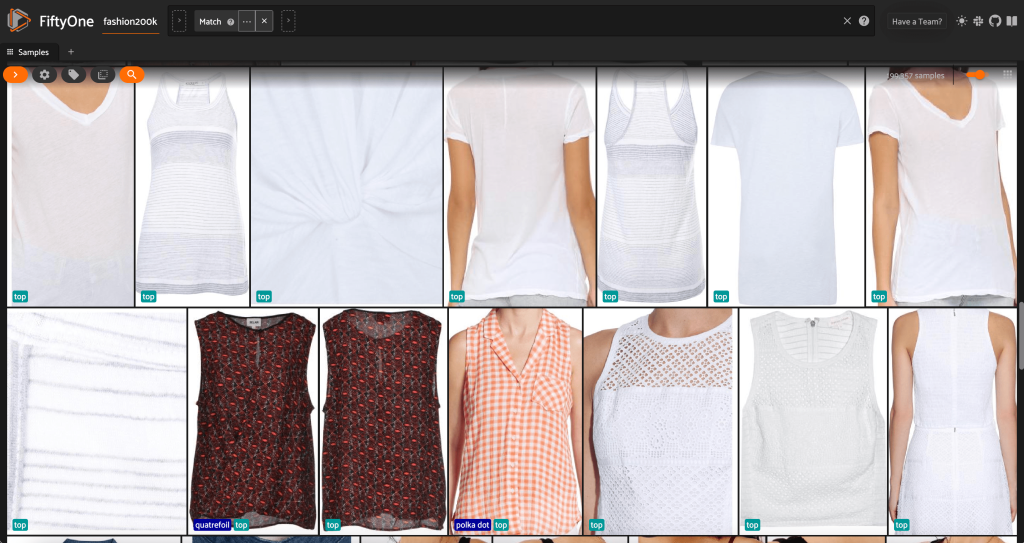
इस उच्च-रिज़ॉल्यूशन सबसेट में 200,000 से कम नमूने हैं।
इस दृष्टिकोण से, हम अपने डेटासेट में एक नया दृश्य बना सकते हैं जिसमें प्रत्येक उत्पाद के लिए केवल एक प्रतिनिधि नमूना (अधिकतम) हो। हम उपयोग करते हैं ViewField एक बार फिर, फ़ाइल पथों के लिए पैटर्न मिलान जो समाप्त होता है _0.jpeg:
आइए इस उपसमुच्चय में छवियों के बेतरतीब ढंग से फेरबदल किए गए क्रम को देखें:
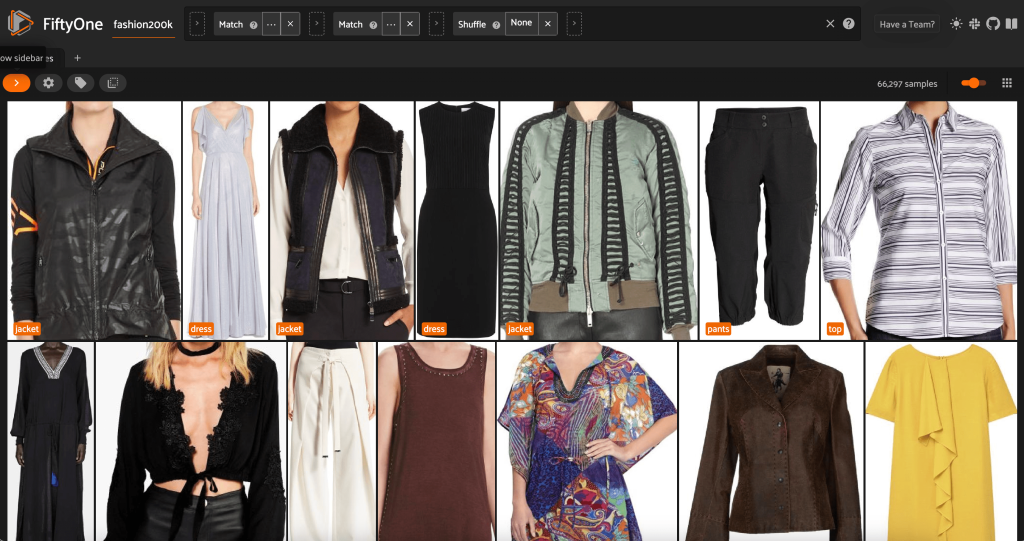
डेटासेट में अनावश्यक छवियों को हटा दें
इस दृश्य में 66,297 छवियां हैं, या मूल डेटासेट का केवल 19% से अधिक है। हालांकि, जब हम दृश्य को देखते हैं, तो हम देखते हैं कि बहुत से समान उत्पाद हैं। इन सभी प्रतियों को रखने से प्रदर्शन में उल्लेखनीय सुधार के बिना, हमारे लेबलिंग और मॉडल प्रशिक्षण में केवल लागत ही बढ़ेगी। इसके बजाय, एक छोटा डेटासेट बनाने के लिए जो अभी भी समान पंच पैक करता है, निकट डुप्लिकेट से छुटकारा पाएं।
क्योंकि ये छवियां सटीक डुप्लिकेट नहीं हैं, हम पिक्सेल-वार समानता की जांच नहीं कर सकते। सौभाग्य से, हम अपने डेटासेट को साफ करने में मदद के लिए फिफ्टीवन ब्रेन का उपयोग कर सकते हैं। विशेष रूप से, हम प्रत्येक छवि के लिए एक एम्बेडिंग की गणना करेंगे—छवि का प्रतिनिधित्व करने वाला एक निम्न-आयामी वेक्टर—और फिर उन छवियों की तलाश करेंगे जिनके एम्बेडिंग वैक्टर एक दूसरे के करीब हैं। सदिश जितने निकट होंगे, चित्र उतने ही अधिक समान होंगे।
हम प्रत्येक छवि के लिए 512-आयामी एम्बेडिंग वेक्टर उत्पन्न करने के लिए एक CLIP मॉडल का उपयोग करते हैं, और इन एम्बेडिंग को हमारे डेटासेट में नमूने पर फ़ील्ड एम्बेडिंग में संग्रहीत करते हैं:
फिर हम उपयोग करके एम्बेडिंग के बीच निकटता की गणना करते हैं cosine समानता, और जोर देकर कहते हैं कि कोई भी दो वैक्टर जिनकी समानता कुछ सीमा से अधिक है, डुप्लिकेट होने की संभावना है। कोसाइन समानता स्कोर [0, 1] की सीमा में है, और डेटा को देखते हुए, थ्रेश = 0.5 का थ्रेशोल्ड स्कोर लगभग सही लगता है। दोबारा, यह बिल्कुल सही होने की जरूरत नहीं है। कुछ निकट-डुप्लिकेट छवियां हमारी भविष्य कहनेवाला शक्ति को बर्बाद करने की संभावना नहीं हैं, और कुछ गैर-डुप्लिकेट छवियों को फेंकने से मॉडल के प्रदर्शन पर भौतिक प्रभाव नहीं पड़ता है।
हम कथित डुप्लिकेट को यह सत्यापित करने के लिए देख सकते हैं कि वे वास्तव में अनावश्यक हैं:
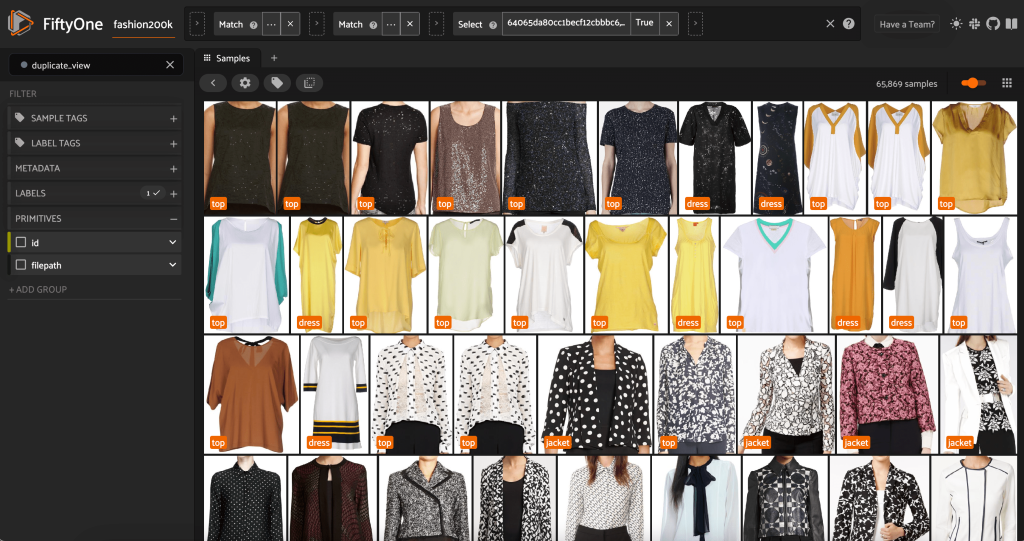
जब हम परिणाम से खुश होते हैं और मानते हैं कि ये छवियां वास्तव में डुप्लिकेट के पास हैं, तो हम रखने के लिए समान नमूनों के प्रत्येक सेट से एक नमूना चुन सकते हैं और अन्य को अनदेखा कर सकते हैं:
अब इस दृश्य में 3,729 चित्र हैं। डेटा को साफ करके और Fashion200K डेटासेट के एक उच्च-गुणवत्ता वाले उपसमुच्चय की पहचान करके, FiftyOne हमें अपना ध्यान 300,000 से अधिक छवियों से केवल 4,000 से कम तक सीमित करने देता है, जो 98% की कमी का प्रतिनिधित्व करता है। लगभग-डुप्लिकेट छवियों को हटाने के लिए एम्बेडिंग का उपयोग करने से हमारी छवियों की कुल संख्या 90% से अधिक कम हो गई है, इस डेटा पर प्रशिक्षित किए जाने वाले किसी भी मॉडल पर बहुत कम प्रभाव के साथ।
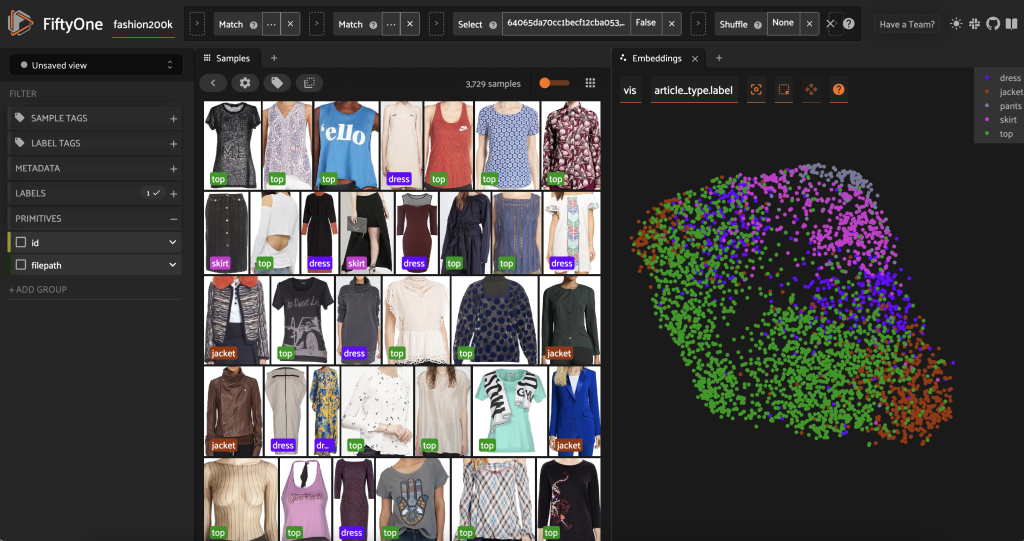
इस उपसमुच्चय को प्री-लेबल करने से पहले, हम उन एम्बेडिंग की कल्पना करके डेटा को बेहतर ढंग से समझ सकते हैं जिनकी हमने पहले ही गणना कर ली है। हम फिफ्टीवन ब्रेन के बिल्ट-इन का उपयोग कर सकते हैं compute_visualization() विधि, जो 512-आयामी एम्बेडिंग वैक्टर को द्वि-आयामी अंतरिक्ष में प्रोजेक्ट करने के लिए यूनिफ़ॉर्म मैनिफोल्ड सन्निकटन (UMAP) तकनीक को नियोजित करती है ताकि हम उनकी कल्पना कर सकें:
हम एक नया खोलते हैं एम्बेडिंग पैनल FiftyOne ऐप में और लेख प्रकार द्वारा रंग, और हम देख सकते हैं कि ये एम्बेडिंग मोटे तौर पर लेख प्रकार (अन्य बातों के अलावा!) की धारणा को कूटबद्ध करते हैं।
अब हम इस डेटा को प्री-लेबल करने के लिए तैयार हैं।
इन अत्यधिक अद्वितीय, उच्च-रिज़ॉल्यूशन वाली छवियों का निरीक्षण करके, हम अपने पूर्व-लेबलिंग शून्य-शॉट वर्गीकरण में कक्षाओं के रूप में उपयोग करने के लिए शैलियों की एक अच्छी प्रारंभिक सूची तैयार कर सकते हैं। इन छवियों को पूर्व-लेबल करने में हमारा लक्ष्य आवश्यक रूप से प्रत्येक छवि को सही ढंग से लेबल करना नहीं है। बल्कि, हमारा लक्ष्य मानव व्याख्याकारों के लिए एक अच्छा प्रारंभिक बिंदु प्रदान करना है ताकि हम लेबलिंग समय और लागत को कम कर सकें।
फिर हम इस एप्लिकेशन के लिए शून्य-शॉट वर्गीकरण मॉडल को तुरंत चालू कर सकते हैं। हम एक CLIP मॉडल का उपयोग करते हैं, जो छवियों और प्राकृतिक भाषा दोनों पर प्रशिक्षित एक सामान्य-उद्देश्य वाला मॉडल है। हम एक CLIP मॉडल को टेक्स्ट प्रांप्ट "स्टाइल में कपड़े" के साथ इंस्टेंट करते हैं, ताकि एक इमेज दी गई हो, मॉडल उस क्लास को आउटपुट करेगा जिसके लिए "स्टाइल में कपड़े [क्लास]" सबसे उपयुक्त है। CLIP खुदरा या फ़ैशन-विशिष्ट डेटा पर प्रशिक्षित नहीं है, इसलिए यह सही नहीं होगा, लेकिन यह आपको लेबलिंग और एनोटेशन लागतों में बचा सकता है।
फिर हम इस मॉडल को अपने कम किए गए उपसमुच्चय पर लागू करते हैं और परिणामों को एक में संग्रहीत करते हैं article_style खेत:
फिफ्टीवन ऐप को एक बार फिर लॉन्च करते हुए, हम इन पूर्वानुमानित स्टाइल लेबल्स के साथ छवियों की कल्पना कर सकते हैं। हम भविष्यवाणी आत्मविश्वास के आधार पर छाँटते हैं इसलिए हम सबसे भरोसेमंद शैली की भविष्यवाणियों को पहले देखते हैं:
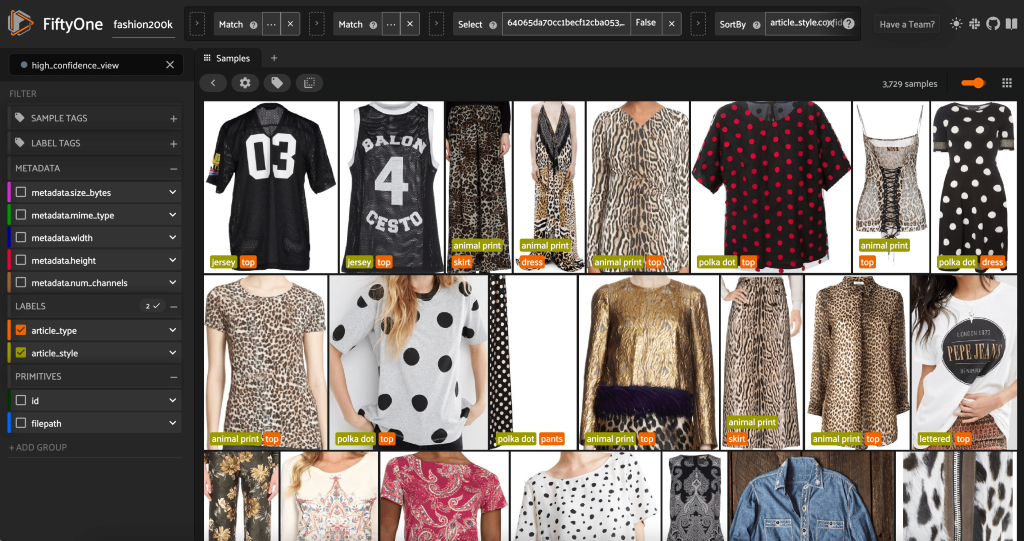
हम देख सकते हैं कि उच्चतम आत्मविश्वास की भविष्यवाणी "जर्सी," "पशु प्रिंट," "पोल्का डॉट," और "लेटरेड" शैलियों के लिए प्रतीत होती है। यह समझ में आता है, क्योंकि ये शैलियाँ अपेक्षाकृत भिन्न हैं। ऐसा भी लगता है कि, अधिकांश भाग के लिए, पूर्वानुमानित शैली लेबल सटीक हैं।
हम सबसे कम आत्मविश्वास वाली शैली की भविष्यवाणियों को भी देख सकते हैं:
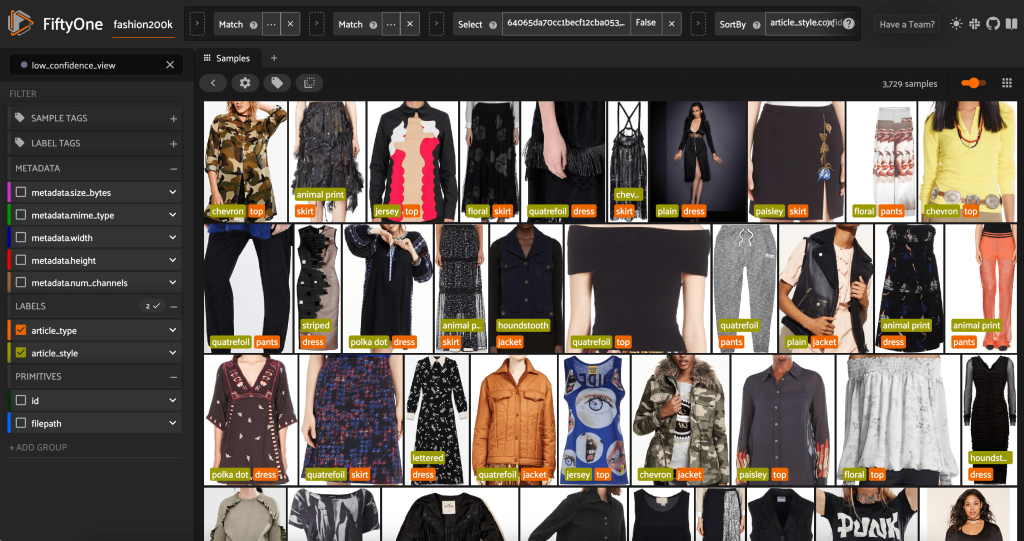
इनमें से कुछ छवियों के लिए उपयुक्त शैली श्रेणी प्रदान की गई सूची में है, और कपड़ों के लेख को गलत तरीके से लेबल किया गया है। उदाहरण के लिए, ग्रिड में पहली छवि स्पष्ट रूप से "छलावरण" होनी चाहिए न कि "शेवरॉन"। हालांकि, अन्य मामलों में, उत्पाद शैली श्रेणियों में बड़े करीने से फिट नहीं होते हैं। दूसरी पंक्ति में दूसरी छवि में पोशाक, उदाहरण के लिए, बिल्कुल "धारीदार" नहीं है, लेकिन समान लेबलिंग विकल्प दिए जाने पर, एक मानव एनोटेटर भी विवादित हो सकता है। जैसा कि हम अपने डेटासेट का निर्माण करते हैं, हमें यह तय करने की आवश्यकता है कि क्या इस तरह के किनारे के मामलों को हटाना है, नई शैली श्रेणियां जोड़ना है या डेटासेट को बढ़ाना है।
फिफ्टीवन से अंतिम डेटासेट निर्यात करें
निम्न कोड के साथ अंतिम डेटासेट निर्यात करें:
हम फ़ोल्डर में एक छोटा डेटासेट निर्यात कर सकते हैं, उदाहरण के लिए, 16 छवियां 200kFashionDatasetExportResult-16Images. हम इसका उपयोग करते हुए ग्राउंड ट्रूथ एडजस्टमेंट जॉब बनाते हैं:
संशोधित डेटासेट अपलोड करें, लेबल प्रारूप को जमीनी सच्चाई में बदलें, Amazon S3 पर अपलोड करें और समायोजन कार्य के लिए एक मेनिफेस्ट फ़ाइल बनाएं
हम मिलान करने के लिए डेटासेट में लेबल को परिवर्तित कर सकते हैं आउटपुट मेनिफेस्ट स्कीमा ग्राउंड ट्रुथ बाउंडिंग बॉक्स जॉब की, और छवियों को एक पर अपलोड करें अमेज़न सरल भंडारण सेवा (अमेज़ॅन S3) लॉन्च करने के लिए बाल्टी a ग्राउंड ट्रुथ एडजस्टमेंट जॉब:
निम्नलिखित कोड के साथ मेनिफेस्ट फ़ाइल को Amazon S3 पर अपलोड करें:
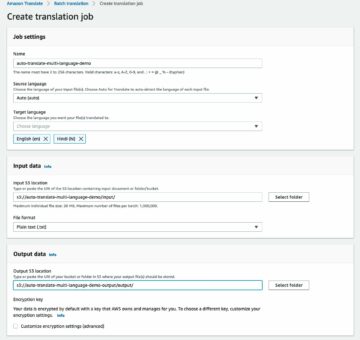
ग्राउंड ट्रूथ के साथ सही स्टाइल वाले लेबल बनाएं
ग्राउंड ट्रूथ का उपयोग करके स्टाइल लेबल्स के साथ अपने डेटा को एनोटेट करने के लिए, बाउंडिंग बॉक्स लेबलिंग जॉब शुरू करने के लिए आवश्यक चरणों को पूरा करें। ग्राउंड ट्रूथ के साथ शुरुआत करना उसी S3 बकेट में डेटासेट के साथ गाइड करें।
- SageMaker कंसोल पर, ग्राउंड ट्रुथ लेबलिंग कार्य बनाएँ।
- ठीक इनपुट डेटासेट स्थान प्रकट होने के लिए जिसे हमने पिछले चरणों में बनाया था।
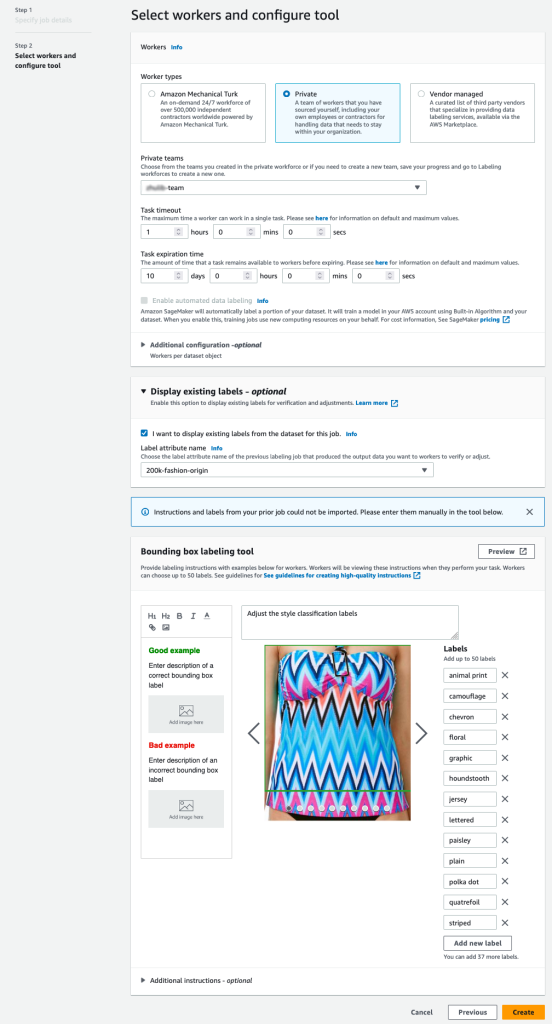
- के लिए एक S3 पथ निर्दिष्ट करें आउटपुट डेटासेट स्थान.
- के लिए IAM भूमिका, चुनें एक कस्टम IAM भूमिका दर्ज करें शाही सेना, फिर भूमिका ARN दर्ज करें।
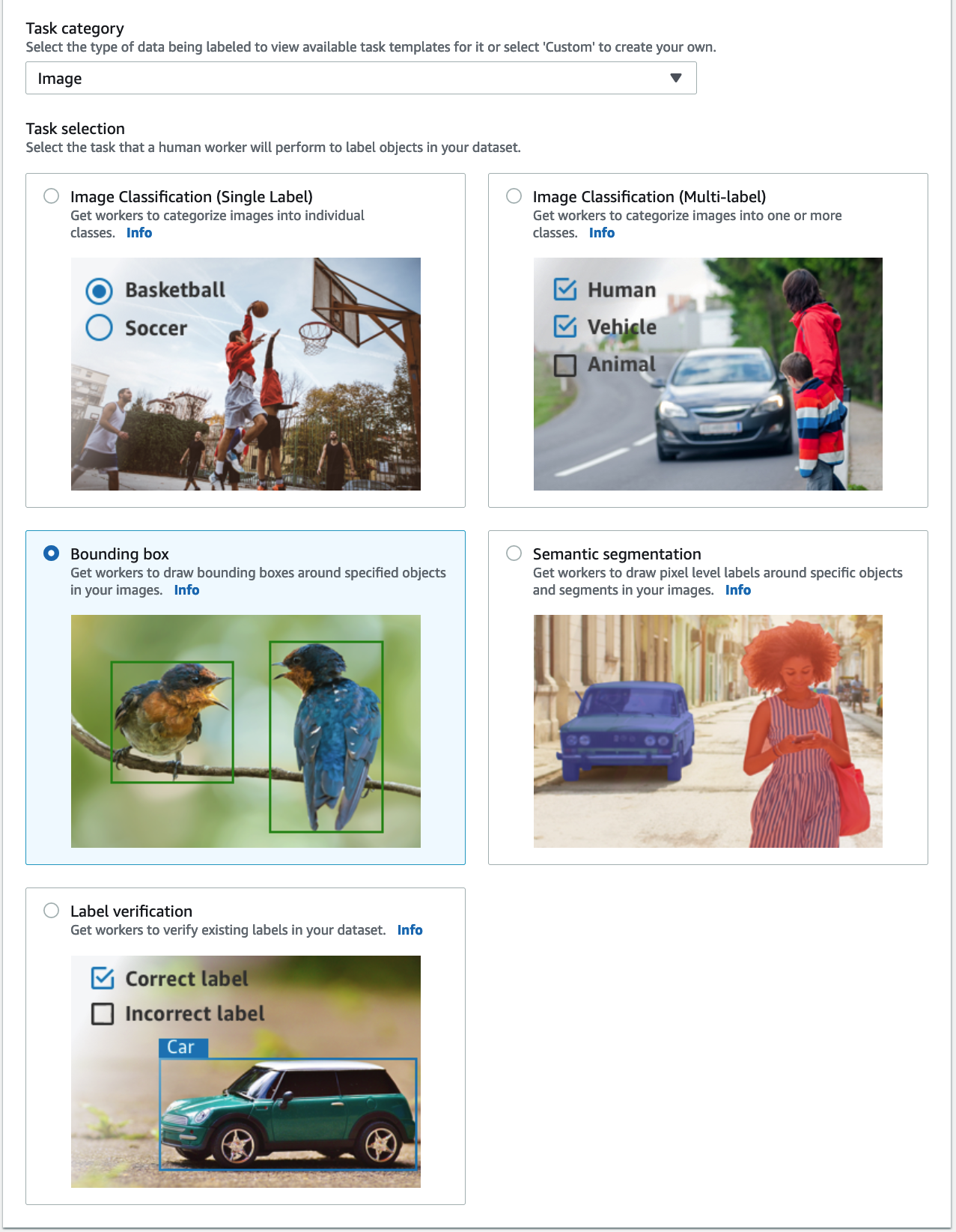
- के लिए कार्य श्रेणी, चुनें छवि का चयन करें और डिब्बा का सीमा.
- चुनें अगला.
- में कर्मी अनुभाग, उस प्रकार के कार्यबल का चयन करें जिसका आप उपयोग करना चाहते हैं।
आप के माध्यम से एक कार्यबल का चयन कर सकते हैं अमेज़ॅन मैकेनिकल तुर्क, तृतीय-पक्ष विक्रेता, या आपका अपना निजी कार्यबल। अपने कार्यबल विकल्पों के बारे में अधिक विवरण के लिए, देखें Workforces बनाएँ और प्रबंधित करें. - विस्तार मौजूदा-लेबल प्रदर्शन विकल्प का चयन करें और मैं इस कार्य के लिए डेटासेट से मौजूदा लेबल प्रदर्शित करना चाहता हूं।
- के लिए लेबल विशेषता नाम, अपने मेनिफेस्ट से वह नाम चुनें जो उन लेबल से मेल खाता हो जिन्हें आप समायोजन के लिए प्रदर्शित करना चाहते हैं।
आप केवल उन लेबलों के लिए लेबल विशेषता नाम देखेंगे जो आपके द्वारा पिछले चरणों में चुने गए कार्य प्रकार से मेल खाते हैं। - के लिए मैन्युअल रूप से लेबल दर्ज करें बाउंडिंग बॉक्स लेबलिंग टूल.
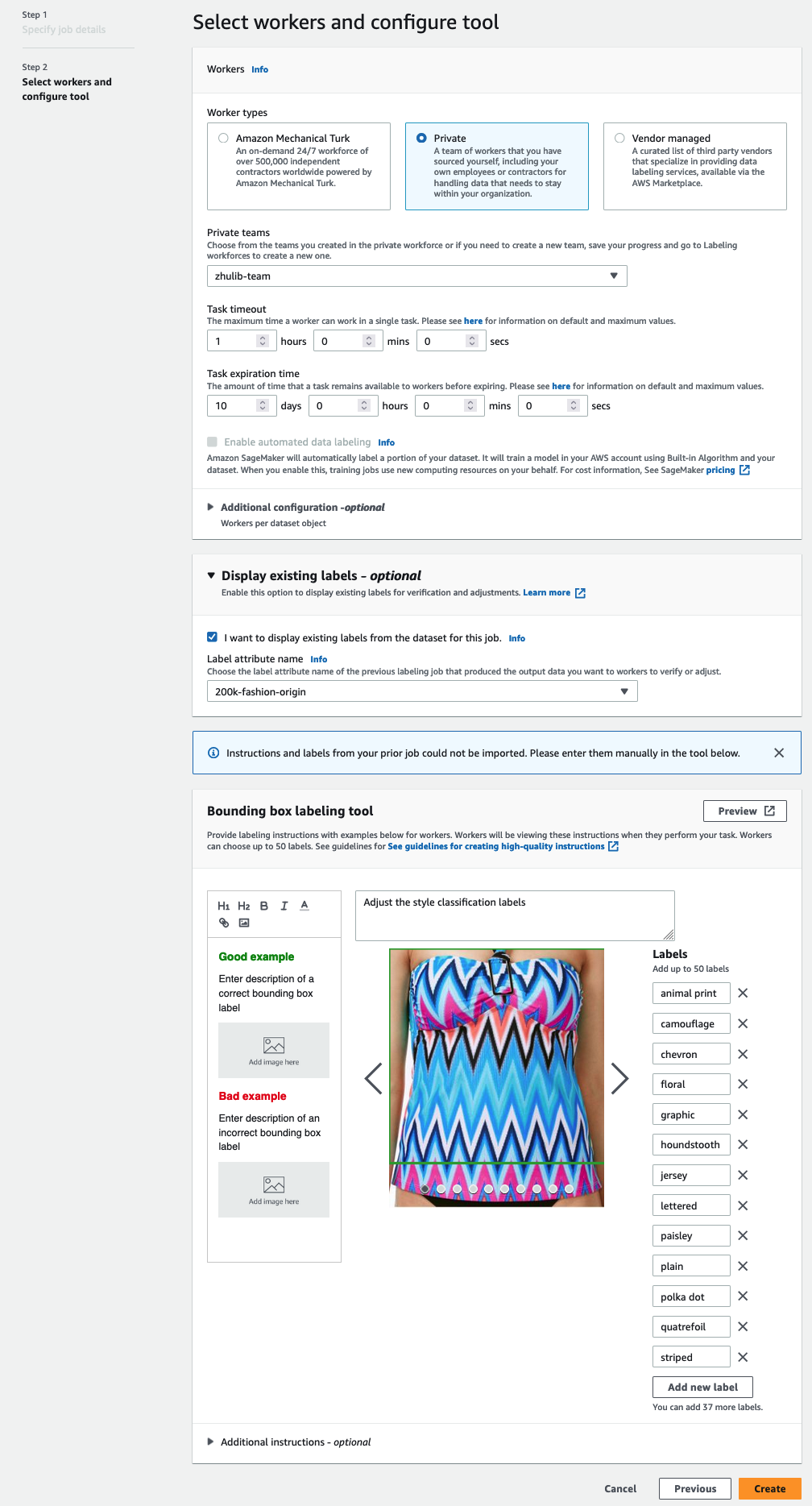 लेबल में वही लेबल होने चाहिए जिनका उपयोग सार्वजनिक डेटासेट में किया जाता है। आप नए लेबल जोड़ सकते हैं। निम्नलिखित स्क्रीनशॉट दिखाता है कि आप कर्मचारियों को कैसे चुन सकते हैं और अपने लेबलिंग कार्य के लिए टूल को कैसे कॉन्फ़िगर कर सकते हैं।
लेबल में वही लेबल होने चाहिए जिनका उपयोग सार्वजनिक डेटासेट में किया जाता है। आप नए लेबल जोड़ सकते हैं। निम्नलिखित स्क्रीनशॉट दिखाता है कि आप कर्मचारियों को कैसे चुन सकते हैं और अपने लेबलिंग कार्य के लिए टूल को कैसे कॉन्फ़िगर कर सकते हैं।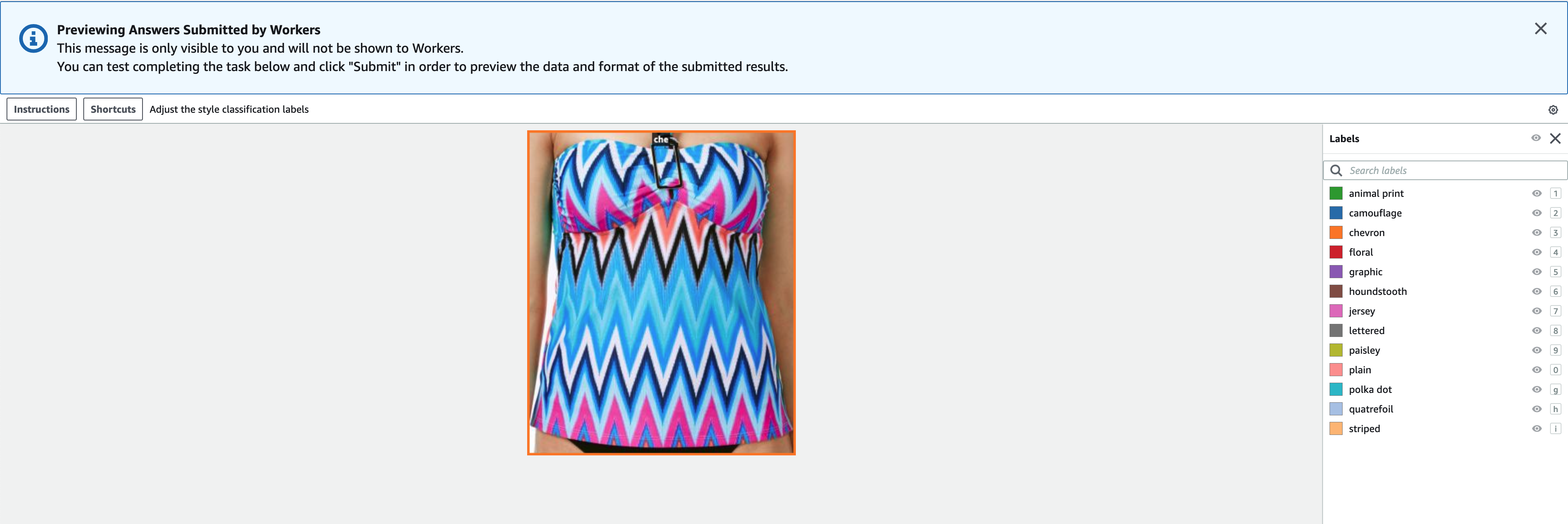
- चुनें पूर्वावलोकन छवि और मूल एनोटेशन का पूर्वावलोकन करने के लिए।
हमने अब ग्राउंड ट्रुथ में एक लेबलिंग जॉब बनाया है। हमारा काम पूरा होने के बाद, हम नए उत्पन्न लेबल किए गए डेटा को FiftyOne में लोड कर सकते हैं। ग्राउंड ट्रुथ आउटपुट डेटा को ग्राउंड ट्रुथ आउटपुट मेनिफ़ेस्ट में उत्पन्न करता है। आउटपुट मेनिफेस्ट फ़ाइल पर अधिक विवरण के लिए, देखें बाउंडिंग बॉक्स जॉब आउटपुट. निम्न कोड इस आउटपुट मेनिफ़ेस्ट स्वरूप का एक उदाहरण दिखाता है:
फिफ्टीवन में ग्राउंड ट्रूथ से लेबल किए गए परिणामों की समीक्षा करें
कार्य पूर्ण होने के बाद, Amazon S3 से लेबलिंग कार्य का आउटपुट मेनिफ़ेस्ट डाउनलोड करें।
आउटपुट मेनिफेस्ट फ़ाइल पढ़ें:
एक FiftyOne डेटासेट बनाएं और मैनिफ़ेस्ट लाइन को डेटासेट में सैंपल में बदलें:
अब आप फिफ्टीवन में ग्राउंड ट्रूथ से उच्च गुणवत्ता वाले लेबल किए गए डेटा को देख सकते हैं।
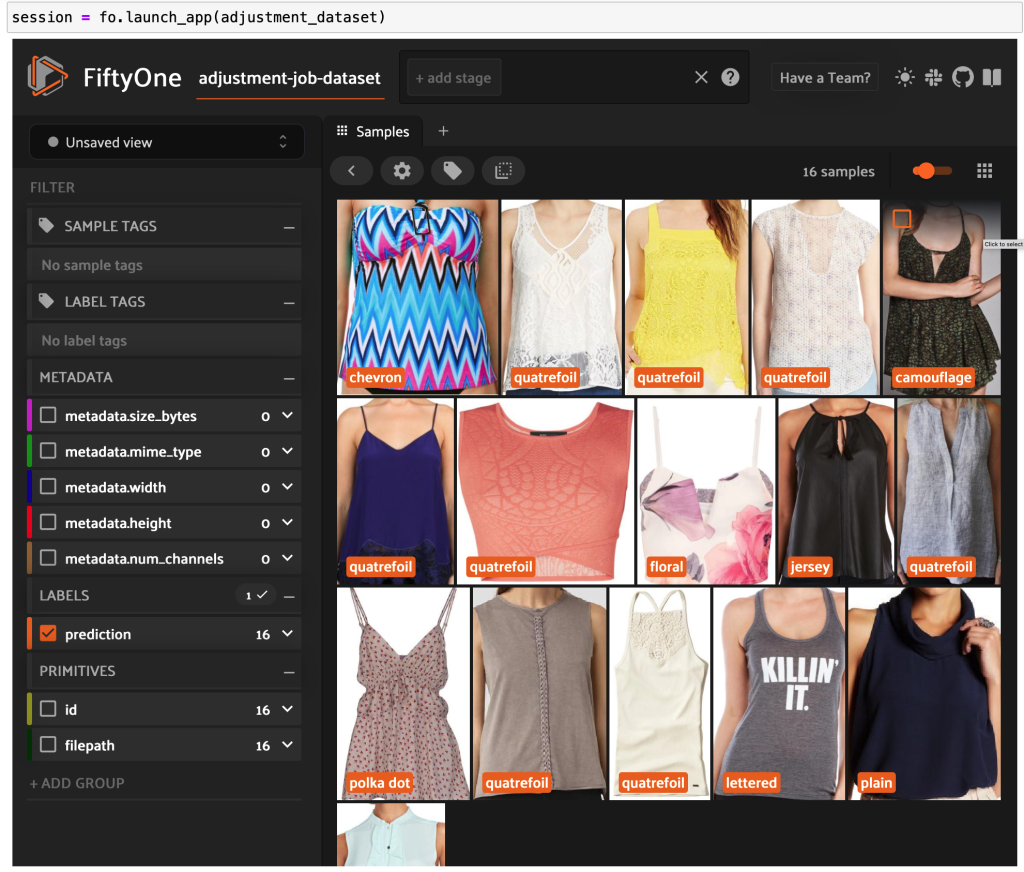
निष्कर्ष
इस पोस्ट में, हमने दिखाया कि किस प्रकार की शक्ति का संयोजन करके उच्च-गुणवत्ता वाले डेटासेट का निर्माण किया जाता है इक्यावन by वोक्सेल51, एक ओपन-सोर्स टूलकिट जो आपको अपने डेटासेट को प्रबंधित, ट्रैक, विज़ुअलाइज़ और क्यूरेट करने की अनुमति देता है, और ग्राउंड ट्रुथ, एक डेटा लेबलिंग सेवा है जो आपको कई बिल्ट तक पहुंच प्रदान करके एमएल सिस्टम को प्रशिक्षित करने के लिए आवश्यक डेटासेट को कुशलतापूर्वक और सटीक रूप से लेबल करने की अनुमति देती है। -इन टास्क टेम्प्लेट और मैकेनिकल तुर्क, थर्ड-पार्टी वेंडर्स या आपके अपने निजी वर्कफोर्स के माध्यम से विविध कार्यबल तक पहुंच।
हम आपको एक FiftyOne उदाहरण स्थापित करके और आरंभ करने के लिए ग्राउंड ट्रूथ कंसोल का उपयोग करके इस नई कार्यक्षमता को आज़माने के लिए प्रोत्साहित करते हैं। जमीनी सच्चाई के बारे में अधिक जानने के लिए देखें लेबल डेटा, अमेज़ॅन सैजमेकर डेटा लेबलिंग एफएक्यू, और एडब्ल्यूएस मशीन लर्निंग ब्लॉग.
से जुड़ें मशीन लर्निंग और एआई समुदाय यदि आपके कोई प्रश्न या प्रतिक्रिया है!
फिफ्टीवन समुदाय में शामिल हों!
आज कंप्यूटर दृष्टि में कुछ सबसे चुनौतीपूर्ण समस्याओं को हल करने के लिए पहले से ही FiftyOne का उपयोग कर रहे हजारों इंजीनियरों और डेटा वैज्ञानिकों में शामिल हों!
लेखक के बारे में
शैलेन्द्र छाबड़ा वर्तमान में Amazon SageMaker ह्यूमन-इन-द-लूप (HIL) सेवाओं के लिए उत्पाद प्रबंधन के प्रमुख हैं। इससे पहले, शैलेंद्र ने Microsoft टीम मीटिंग्स के लिए भाषा और संवादात्मक इंटेलिजेंस को इनक्यूबेट किया और नेतृत्व किया, Amazon Alexa Techstars Startup Accelerator में EIR थे, उत्पाद और मार्केटिंग के VP चर्चा.io, क्लिपबोर्ड में उत्पाद और विपणन के प्रमुख (सेल्सफोर्स द्वारा अधिग्रहित), और स्वेप में लीड उत्पाद प्रबंधक (Nuance द्वारा अधिग्रहित)। कुल मिलाकर, शैलेंद्र ने उन उत्पादों के निर्माण, शिप और बाजार में मदद की है, जिन्होंने एक अरब से अधिक लोगों के जीवन को प्रभावित किया है।
याकूब मार्क्स Voxel51 में एक मशीन लर्निंग इंजीनियर और डेवलपर इवेंजलिस्ट हैं, जहां वे दुनिया के डेटा में पारदर्शिता और स्पष्टता लाने में मदद करते हैं। Voxel51 में शामिल होने से पहले, जैकब ने उभरते संगीतकारों को जोड़ने और रचनात्मक सामग्री को प्रशंसकों के साथ साझा करने में मदद करने के लिए एक स्टार्टअप की स्थापना की। इससे पहले उन्होंने गूगल एक्स, सैमसंग रिसर्च और वोल्फ्राम रिसर्च में काम किया था। पिछले जन्म में, जैकब एक सैद्धांतिक भौतिक विज्ञानी थे, जिन्होंने स्टैनफोर्ड में अपनी पीएचडी पूरी की, जहाँ उन्होंने पदार्थ के क्वांटम चरणों की जाँच की। अपने खाली समय में, जैकब को चढ़ाई करना, दौड़ना और विज्ञान कथा उपन्यास पढ़ना पसंद है।
जेसन कोरसो Voxel51 के सह-संस्थापक और सीईओ हैं, जहां वे अत्याधुनिक लचीले सॉफ्टवेयर के माध्यम से दुनिया के डेटा में पारदर्शिता और स्पष्टता लाने में मदद करने के लिए रणनीति बनाते हैं। वह मिशिगन विश्वविद्यालय में रोबोटिक्स, इलेक्ट्रिकल इंजीनियरिंग और कंप्यूटर साइंस के प्रोफेसर भी हैं, जहां वे कंप्यूटर दृष्टि, प्राकृतिक भाषा और भौतिक प्लेटफार्मों के चौराहे पर अत्याधुनिक समस्याओं पर ध्यान केंद्रित करते हैं। अपने खाली समय में, जेसन को अपने परिवार के साथ समय बिताना, पढ़ना, प्रकृति में रहना, बोर्ड गेम खेलना और सभी प्रकार की रचनात्मक गतिविधियों का आनंद मिलता है।
ब्रायन मूर Voxel51 के सह-संस्थापक और CTO हैं, जहां वे तकनीकी रणनीति और दृष्टि का नेतृत्व करते हैं। उन्होंने मिशिगन विश्वविद्यालय से इलेक्ट्रिकल इंजीनियरिंग में पीएचडी की है, जहां उनका शोध बड़े पैमाने पर मशीन सीखने की समस्याओं के लिए कुशल एल्गोरिदम पर केंद्रित था, जिसमें कंप्यूटर दृष्टि अनुप्रयोगों पर विशेष जोर दिया गया था। अपने खाली समय में, वह बैडमिंटन, गोल्फ, लंबी पैदल यात्रा और अपने जुड़वां यॉर्कशायर टेरियर्स के साथ खेलना पसंद करते हैं।
झुलिंग बाई Amazon Web Services में एक सॉफ्टवेयर डेवलपमेंट इंजीनियर है। वह मशीन सीखने की समस्याओं को हल करने के लिए बड़े पैमाने पर वितरित सिस्टम विकसित करने पर काम करती है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोआईस्ट्रीम। Web3 डेटा इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- मिंटिंग द फ्यूचर डब्ल्यू एड्रिएन एशले। यहां पहुंचें।
- PREIPO® के साथ PRE-IPO कंपनियों में शेयर खरीदें और बेचें। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- About
- में तेजी लाने के
- तेज
- त्वरक
- पहुँच
- सही
- सही रूप में
- प्राप्त
- गतिविधियों
- जोड़ना
- जोड़ने
- पता
- समायोजित
- समायोजन
- बाद
- फिर
- AI
- एलेक्सा
- एल्गोरिदम
- सब
- की अनुमति देता है
- अकेला
- पहले ही
- भी
- वीरांगना
- अमेज़ॅन एलेक्सिया
- अमेज़न SageMaker
- अमेज़ॅन सैजमेकर ग्राउंड ट्रुथ
- अमेज़ॅन वेब सेवा
- के बीच में
- an
- विश्लेषण करें
- और
- जानवर
- कोई
- अनुप्रयोग
- आवेदन
- अनुप्रयोगों
- लागू करें
- उपयुक्त
- हैं
- व्यवस्था की
- लेख
- लेख
- AS
- जुड़े
- At
- लेखकों
- दूर
- एडब्ल्यूएस
- आधार
- आधारित
- BE
- क्योंकि
- बन
- किया गया
- से पहले
- पीछे
- परदे के पीछे
- जा रहा है
- मानना
- BEST
- बेहतर
- के बीच
- बिलियन
- मंडल
- बोर्ड खेल
- हड्डी
- जूते का फीता
- के छात्रों
- मुक्केबाज़ी
- बक्से
- दिमाग
- टूटना
- लाना
- लाया
- बजट
- निर्माण
- इमारत
- में निर्मित
- लेकिन
- खरीदने के लिए
- by
- कर सकते हैं
- कैप्चरिंग
- मामला
- मामलों
- श्रेणियाँ
- वर्ग
- मुख्य कार्यपालक अधिकारी
- चुनौती
- चुनौतीपूर्ण
- चेक
- चुनें
- स्पष्टता
- कक्षा
- कक्षाएं
- वर्गीकरण
- सफाई
- स्पष्ट
- स्पष्ट रूप से
- ग्राहक
- क्लाइम्बिंग
- समापन
- करीब
- वस्त्र
- कपड़ा
- सह-संस्थापक
- कोड
- गठबंधन
- संयोजन
- कंपनी
- पूरक हैं
- पूरा
- पूरा
- गणना करना
- कंप्यूटर
- कम्प्यूटर साइंस
- Computer Vision
- कंप्यूटर विजन एप्लीकेशन
- आत्मविश्वास
- आश्वस्त
- जुडिये
- विचार
- मिलकर
- कंसोल
- शामिल हैं
- सामग्री
- अंतर्वस्तु
- नियंत्रित
- संवादी
- बदलना
- प्रतियां
- मूल
- संशोधित
- मेल खाती है
- लागत
- लागत
- बनाना
- बनाया
- क्रिएटिव
- साख
- सीटीओ
- क्यूरेट
- क्यूरेटिंग
- वर्तमान में
- रिवाज
- ग्राहक
- ग्राहक
- कट गया
- अग्रणी
- तिथि
- डेटासेट
- तय
- दिखाना
- डेनिम
- गहराई
- विवरण
- विवरण
- खोज
- डेवलपर
- विकासशील
- विकास
- विभिन्न
- सीधे
- निर्देशिकाओं
- डिस्प्ले
- अलग
- वितरित
- वितरित प्रणाली
- कई
- do
- नहीं करता है
- कुत्ता
- कर
- किया
- dont
- DOT
- नीचे
- डाउनलोड
- डुप्लिकेट
- e
- से प्रत्येक
- आसान
- Edge
- प्रभाव
- कुशल
- कुशलता
- इलेक्ट्रिकल इंजीनियरिंग
- embedding
- कस्र्न पत्थर
- जोर
- रोजगार
- अधिकार
- समझाया
- प्रोत्साहित करना
- समाप्त
- इंजीनियर
- अभियांत्रिकी
- इंजीनियर्स
- दर्ज
- वातावरण
- समानता
- आवश्यक
- स्थापित
- ईथर (ईटीएच)
- का मूल्यांकन
- इंजीलवादी
- ठीक ठीक
- उदाहरण
- मौजूदा
- निर्यात
- काफी
- परिवार
- प्रशंसकों
- प्रतिक्रिया
- कुछ
- कल्पना
- खेत
- फ़ील्ड
- पट्टिका
- फ़ाइलें
- फ़िल्टर
- छानने
- अंतिम
- प्रथम
- फिट
- लचीला
- फोकस
- ध्यान केंद्रित
- केंद्रित
- निम्नलिखित
- के लिए
- प्रपत्र
- प्रारूप
- भाग्यवश
- स्थापित
- चार
- मुक्त
- से
- पूरी तरह से
- कार्यक्षमता
- Games
- सामान्य उद्देश्य
- उत्पन्न
- उत्पन्न
- मिल
- GitHub
- देना
- दी
- लक्ष्य
- गोल्फ
- अच्छा
- गूगल
- अधिक से अधिक
- ग्रिड
- जमीन
- समूह
- गाइड
- खुश
- है
- he
- सिर
- ऊंचाई
- मदद
- मदद की
- सहायक
- मदद करता है
- यहाँ उत्पन्न करें
- उच्च गुणवत्ता
- उच्च संकल्प
- उच्चतम
- अत्यधिक
- हाइकिंग
- उसके
- रखती है
- कैसे
- How To
- तथापि
- एचटीएमएल
- http
- HTTPS
- मानव
- i
- आई ए एम
- ID
- पहचान करना
- पहचान
- आईडी
- if
- की छवि
- छवियों
- प्रभाव
- आयात
- में सुधार लाने
- in
- अन्य में
- सहित
- गलत रूप से
- इनक्यूबेट
- करें-
- प्रारंभिक
- शुरू में
- स्थापित
- स्थापित कर रहा है
- उदाहरण
- बजाय
- निर्देश
- बुद्धि
- प्रतिच्छेदन
- में
- IT
- आईटी इस
- जर्सी
- काम
- शामिल होने
- संयुक्त
- JSON
- केवल
- रखना
- रखना
- लेबल
- लेबलिंग
- लेबल
- भाषा
- बड़े पैमाने पर
- लांच
- शुरू करने
- नेतृत्व
- बिक्रीसूत्र
- जानें
- सीख रहा हूँ
- कम से कम
- नेतृत्व
- बाएं
- चलें
- पुस्तकालय
- जीवन
- पसंद
- संभावित
- सीमा
- सीमित
- लाइन
- पंक्तियां
- सूची
- लिस्टिंग
- लिस्टिंग
- थोड़ा
- लाइव्स
- भार
- देखिए
- देख
- लॉट
- निम्न
- मशीन
- यंत्र अधिगम
- बनाया गया
- जादू
- बनाना
- बनाता है
- प्रबंधन
- कामयाब
- प्रबंध
- प्रबंधक
- बहुत
- नक्शा
- बाजार
- विपणन (मार्केटिंग)
- मैच
- मिलान
- वास्तव में
- बात
- मई..
- यांत्रिक
- मीडिया
- बैठकों
- मेटा
- मेटाडाटा
- तरीका
- तरीकों
- मिशिगन
- माइक्रोसॉफ्ट
- Microsoft टीम
- हो सकता है
- न्यूनतम
- ML
- मोबाइल
- मोबाइल एप्लिकेशन
- आदर्श
- मॉडल
- मॉड्यूल
- अधिक
- अधिकांश
- चाल
- बहुत
- विभिन्न
- संगीतकारों
- चाहिए
- नाम
- नामांकित
- नामों
- प्राकृतिक
- प्राकृतिक भाषा
- प्रकृति
- निकट
- अनिवार्य रूप से
- आवश्यक
- आवश्यकता
- की जरूरत है
- नया
- काफ़ी
- धारणा
- अभी
- अति सूक्ष्म अंतर
- संख्या
- वस्तु
- ऑब्जेक्ट डिटेक्शन
- वस्तुओं
- of
- सरकारी
- on
- एक बार
- ONE
- ऑनलाइन
- केवल
- खुला
- खुला स्रोत
- संचालन
- अवसर
- ऑप्शंस
- or
- संगठित
- मूल
- OS
- अन्य
- अन्य
- हमारी
- आउट
- उल्लिखित
- उत्पादन
- के ऊपर
- अपना
- मालिक
- पैक्स
- बनती
- भाग
- विशेष
- अतीत
- पथ
- पैटर्न
- पैटर्न उपयोग करें
- उत्तम
- प्रदर्शन
- व्यक्ति
- निजीकृत
- पदार्थ के चरण
- भौतिक
- चुनना
- तस्वीरें
- प्लेड
- मैदान
- प्लेटफार्म
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- खेल
- बिन्दु
- आबादी वाले
- संभव
- पद
- बिजली
- अभ्यास
- भविष्यवाणी
- भविष्यवाणी
- भविष्यवाणियों
- पूर्वावलोकन
- पिछला
- पहले से
- छाप
- पूर्व
- निजी
- शायद
- समस्याओं
- प्रक्रिया
- एस्ट्रो मॉल
- उत्पाद प्रबंधन
- उत्पादन प्रबंधक
- उत्पाद
- प्रोफेसर
- परियोजना
- संपत्ति
- भावी
- प्रोटोटाइप
- प्रदान करना
- बशर्ते
- प्रदान कर
- सार्वजनिक
- पंच
- प्रयोजनों
- अजगर
- मात्रा
- प्रशन
- जल्दी से
- रेंज
- बल्कि
- पढ़ना
- तैयार
- की सिफारिश
- सिफारिशें
- को कम करने
- घटी
- कमी
- अपेक्षाकृत
- रिहा
- प्रासंगिक
- हटाना
- प्रतिनिधि
- का प्रतिनिधित्व
- अपेक्षित
- अनुसंधान
- शोधकर्ताओं
- संकल्प
- रोकना
- परिणाम
- जिसके परिणामस्वरूप
- परिणाम
- खुदरा
- वापसी
- की समीक्षा
- छुटकारा
- रोबोटिक्स
- मजबूत
- भूमिका
- लगभग
- आरओडब्ल्यू
- नाश
- दौड़ना
- sagemaker
- कहा
- salesforce
- वही
- सैमसंग
- सहेजें
- दृश्यों
- विज्ञान
- साइंस फिक्शन
- वैज्ञानिकों
- स्कोर
- मूल
- दूसरा
- अनुभाग
- वर्गों
- देखना
- लगता है
- लगता है
- चयनित
- भावना
- अलग
- सेवा
- सेवाएँ
- सत्र
- सेट
- Share
- वह
- चाहिए
- दिखाना
- दिखाता है
- हाँ
- समान
- सरल
- छोटे
- So
- सॉफ्टवेयर
- सॉफ्टवेयर विकास
- हल
- कुछ
- कोई
- कुछ
- अंतरिक्ष
- बिताना
- खर्च
- विभाजित
- विभाजन
- स्टैनफोर्ड
- प्रारंभ
- शुरू
- शुरुआत में
- स्टार्टअप
- स्टार्टअप त्वरक
- राज्य के-the-कला
- कदम
- फिर भी
- भंडारण
- की दुकान
- स्ट्रेटेजी
- अंदाज
- शैलियों
- सारांश
- समर्थित
- सिस्टम
- लेना
- कार्य
- टीमों
- तकनीकी
- Techstars
- बताता है
- टेम्पलेट्स
- परीक्षण
- से
- कि
- RSI
- लेकिन हाल ही
- उन
- फिर
- सैद्धांतिक
- वहाँ।
- इन
- वे
- चीज़ें
- सोचना
- तीसरे दल
- इसका
- हजारों
- द्वार
- यहाँ
- फेंकना
- पहर
- सेवा मेरे
- एक साथ
- साधन
- टूलकिट
- ऊपर का
- शीर्ष स्तर के
- सबसे ऊपर है
- कुल
- छुआ
- ट्रैक
- रेलगाड़ी
- प्रशिक्षित
- प्रशिक्षण
- बदालना
- ट्रांसपेरेंसी
- <strong>उद्देश्य</strong>
- सच
- मोड़
- दो
- टाइप
- प्रकार
- के अंतर्गत
- समझना
- अद्वितीय
- विश्वविद्यालय
- यूनिवर्सिटी ऑफ मिशिगन
- अपडेट
- us
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ताओं
- का उपयोग
- मान
- विविधता
- विभिन्न
- विक्रेताओं
- सत्यापित
- बहुत
- के माध्यम से
- देखें
- वास्तविक
- दृष्टि
- करना चाहते हैं
- था
- we
- वेब
- वेब सेवाओं
- कुंआ
- थे
- क्या
- कब
- या
- कौन कौन से
- विकिपीडिया
- मर्जी
- साथ में
- अंदर
- बिना
- महिलाओं
- शब्द
- काम
- काम किया
- श्रमिकों
- कार्यबल
- कार्य
- दुनिया की
- चिंता
- होगा
- लिखना
- X
- इसलिए आप
- आपका
- जेफिरनेट
- ज़िप
- चिड़ियाघर