ए में समान कॉलम ढूँढना डेटा लेक कई डेटा स्रोतों में डेटा की सफाई और एनोटेशन, स्कीमा मिलान, डेटा खोज और विश्लेषण में महत्वपूर्ण अनुप्रयोग हैं। असमान स्रोतों से डेटा को सटीक रूप से खोजने और उसका विश्लेषण करने में असमर्थता डेटा वैज्ञानिकों, चिकित्सा शोधकर्ताओं, शिक्षाविदों से लेकर वित्तीय और सरकारी विश्लेषकों तक सभी के लिए एक संभावित दक्षता हत्यारे का प्रतिनिधित्व करती है।
पारंपरिक समाधानों में लेक्सिकल कीवर्ड खोज या रेगुलर एक्सप्रेशन मैचिंग शामिल है, जो डेटा गुणवत्ता के मुद्दों जैसे अनुपस्थित कॉलम नाम या विविध डेटासेट में विभिन्न कॉलम नामकरण परंपराओं के लिए अतिसंवेदनशील होते हैं (उदाहरण के लिए, zip_code, zcode, postalcode).
इस पोस्ट में, हम स्तंभ नाम, स्तंभ सामग्री या दोनों के आधार पर समान स्तंभों की खोज के लिए एक समाधान प्रदर्शित करते हैं। घोल प्रयोग करता है अनुमानित निकटतम पड़ोसी एल्गोरिदम में उपलब्ध अमेज़न ओपन सर्च सर्विस शब्दार्थ समान स्तंभों की खोज करने के लिए। खोज को सुविधाजनक बनाने के लिए, हम पूर्व-प्रशिक्षित ट्रांसफॉर्मर मॉडल का उपयोग करके डेटा लेक में अलग-अलग कॉलम के लिए सुविधाओं का प्रतिनिधित्व (एम्बेडिंग) बनाते हैं। वाक्य-ट्रांसफार्मर पुस्तकालय in अमेज़न SageMaker. अंत में, हमारे समाधान के साथ बातचीत करने और परिणामों की कल्पना करने के लिए, हम एक इंटरैक्टिव बनाते हैं स्ट्रीमलाइट वेब एप्लिकेशन चल रहा है AWS फरगेट.
हम ए शामिल करते हैं कोड ट्यूटोरियल आपके लिए नमूना डेटा या अपने स्वयं के डेटा पर समाधान चलाने के लिए संसाधनों को परिनियोजित करने के लिए।
समाधान अवलोकन
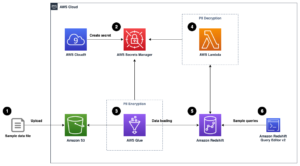
निम्नलिखित आर्किटेक्चर आरेख सिमेंटिक रूप से समान कॉलम खोजने के लिए दो-चरण कार्यप्रवाह दिखाता है। पहला चरण चलता है AWS स्टेप फ़ंक्शंस वर्कफ़्लो जो सारणीबद्ध स्तंभों से एम्बेडिंग बनाता है और OpenSearch सेवा खोज अनुक्रमणिका बनाता है। दूसरा चरण, या ऑनलाइन निष्कर्ष चरण, फरगेट के माध्यम से स्ट्रीमलिट एप्लिकेशन चलाता है। वेब एप्लिकेशन इनपुट खोज क्वेरी एकत्र करता है और OpenSearch सर्विस इंडेक्स से क्वेरी के अनुमानित k-सबसे-समान कॉलम को पुनर्प्राप्त करता है।

चित्रा 1. समाधान वास्तुकला
स्वचालित वर्कफ़्लो निम्न चरणों में आगे बढ़ता है:
- उपयोगकर्ता सारणीबद्ध डेटासेट को एक में अपलोड करता है अमेज़न सरल भंडारण सेवा (अमेज़न S3) बकेट, जो आह्वान करता है a AWS लाम्बा फ़ंक्शन जो स्टेप फ़ंक्शंस वर्कफ़्लो को आरंभ करता है।
- कार्यप्रवाह एक के साथ शुरू होता है एडब्ल्यूएस गोंद कार्य जो CSV फ़ाइलों को परिवर्तित करता है अपाचे लकड़ी की छत डेटा स्वरूप।
- SageMaker प्रोसेसिंग जॉब पूर्व-प्रशिक्षित मॉडल या कस्टम कॉलम एम्बेडिंग मॉडल का उपयोग करके प्रत्येक कॉलम के लिए एम्बेडिंग बनाता है। SageMaker प्रोसेसिंग जॉब Amazon S3 में प्रत्येक तालिका के लिए कॉलम एम्बेडिंग सहेजता है।
- एक लैम्ब्डा फ़ंक्शन पिछले चरण में निर्मित स्तंभ एम्बेडिंग को अनुक्रमित करने के लिए OpenSearch सेवा डोमेन और क्लस्टर बनाता है।
- अंत में, फारगेट के साथ एक इंटरैक्टिव स्ट्रीमलिट वेब एप्लिकेशन को तैनात किया गया है। वेब एप्लिकेशन समान कॉलम के लिए ओपनसर्च सर्विस डोमेन को खोजने के लिए इनपुट प्रश्नों के लिए उपयोगकर्ता के लिए एक इंटरफ़ेस प्रदान करता है।
आप कोड ट्यूटोरियल से डाउनलोड कर सकते हैं GitHub इस समाधान को नमूना डेटा या अपने स्वयं के डेटा पर आज़माने के लिए। इस ट्यूटोरियल के लिए आवश्यक संसाधनों को परिनियोजित करने के निर्देश पर उपलब्ध हैं Github.
पूर्वापेक्षाएँ
इस समाधान को लागू करने के लिए, आपको निम्नलिखित की आवश्यकता होगी:
- An AWS खाता.
- एडब्ल्यूएस सेवाओं जैसे AWS क्लाउड डेवलपमेंट किट (AWS CDK), लैम्ब्डा, ओपनसर्च सर्विस और सेजमेकर प्रोसेसिंग।
- खोज अनुक्रमणिका बनाने के लिए एक सारणीबद्ध डेटासेट। आप अपना स्वयं का सारणीबद्ध डेटा ला सकते हैं या नमूना डेटासेट डाउनलोड कर सकते हैं GitHub.
एक खोज सूचकांक बनाएँ
पहला चरण कॉलम सर्च इंजन इंडेक्स बनाता है। निम्नलिखित आंकड़ा इस चरण को चलाने वाले स्टेप फ़ंक्शंस वर्कफ़्लो को दिखाता है।

चित्रा 2 - चरण कार्य वर्कफ़्लो - एकाधिक एम्बेडिंग मॉडल
डेटासेट
इस पोस्ट में, हमने 400 से अधिक सारणीबद्ध डेटासेट से 25 से अधिक स्तंभों को शामिल करने के लिए एक खोज अनुक्रमणिका का निर्माण किया है। डेटासेट निम्नलिखित सार्वजनिक स्रोतों से उत्पन्न होते हैं:
अनुक्रमणिका में शामिल तालिकाओं की पूरी सूची के लिए, कोड ट्यूटोरियल देखें GitHub.
आप नमूना डेटा बढ़ाने या अपना स्वयं का खोज अनुक्रमणिका बनाने के लिए अपना स्वयं का सारणीबद्ध डेटासेट ला सकते हैं। हम दो लैम्ब्डा फ़ंक्शंस शामिल करते हैं जो अलग-अलग CSV फ़ाइलों या CSV फ़ाइलों के एक बैच के लिए क्रमशः खोज इंडेक्स बनाने के लिए स्टेप फ़ंक्शंस वर्कफ़्लो आरंभ करते हैं।
CSV को Parquet में बदलें
कच्ची CSV फाइलें AWS गोंद के साथ Parquet डेटा प्रारूप में परिवर्तित हो जाती हैं। Parquet एक स्तंभ-उन्मुख प्रारूप फ़ाइल स्वरूप है जिसे बड़े डेटा एनालिटिक्स में पसंद किया जाता है जो कुशल संपीड़न और एन्कोडिंग प्रदान करता है। हमारे प्रयोगों में, कच्चे CSV फ़ाइलों की तुलना में Parquet डेटा प्रारूप ने भंडारण आकार में महत्वपूर्ण कमी की पेशकश की। हमने अन्य डेटा स्वरूपों (उदाहरण के लिए JSON और NDJSON) को परिवर्तित करने के लिए Parquet को एक सामान्य डेटा प्रारूप के रूप में भी उपयोग किया क्योंकि यह उन्नत नेस्टेड डेटा संरचनाओं का समर्थन करता है।
सारणीबद्ध स्तंभ एम्बेडिंग बनाएँ
इस पोस्ट में नमूना सारणीबद्ध डेटासेट में अलग-अलग तालिका स्तंभों के लिए एम्बेडिंग निकालने के लिए, हम निम्नलिखित पूर्व-प्रशिक्षित मॉडल का उपयोग करते हैं sentence-transformers पुस्तकालय। अतिरिक्त मॉडल के लिए देखें पूर्व प्रशिक्षित मॉडल.
सेजमेकर प्रोसेसिंग जॉब चलता है create_embeddings.py(कोड) एक मॉडल के लिए। कई मॉडलों से एम्बेडिंग निकालने के लिए, वर्कफ़्लो समानांतर सेजमेकर प्रोसेसिंग जॉब चलाता है जैसा कि स्टेप फ़ंक्शंस वर्कफ़्लो में दिखाया गया है। हम एम्बेडिंग के दो सेट बनाने के लिए मॉडल का उपयोग करते हैं:
- column_name_embeddings - कॉलम नामों की एंबेडिंग (हेडर)
- column_content_embeddings - कॉलम में सभी पंक्तियों का औसत एम्बेडिंग
कॉलम एम्बेडिंग प्रक्रिया के बारे में अधिक जानकारी के लिए, कोड ट्यूटोरियल देखें GitHub.
बड़े डेटासेट पर कॉलम एम्बेडिंग प्राप्त करने के लिए SageMaker प्रसंस्करण चरण का एक विकल्प SageMaker बैच रूपांतरण बनाना है। इसके लिए मॉडल को सेजमेकर एंडपॉइंट पर तैनात करने की आवश्यकता होगी। अधिक जानकारी के लिए देखें बैच ट्रांसफॉर्म का प्रयोग करें.
OpenSearch सेवा के साथ अनुक्रमणिका एम्बेडिंग
इस चरण के अंतिम चरण में, एक लैम्ब्डा फ़ंक्शन कॉलम एम्बेडिंग को OpenSearch सेवा अनुमानित k-निकटतम-पड़ोसी में जोड़ता है (केएनएन) खोज सूचकांक. प्रत्येक मॉडल को अपना स्वयं का खोज सूचकांक सौंपा गया है। अनुमानित केएनएन सर्च इंडेक्स पैरामीटर के बारे में अधिक जानकारी के लिए, देखें k-एनएन.
एक वेब ऐप के साथ ऑनलाइन अनुमान और शब्दार्थ खोज
कार्यप्रवाह का दूसरा चरण चलता है a स्ट्रीमलाइट वेब एप्लिकेशन जहां आप इनपुट प्रदान कर सकते हैं और OpenSearch सेवा में अनुक्रमित शब्दार्थ समान स्तंभों की खोज कर सकते हैं। एप्लिकेशन परत एक का उपयोग करती है आवेदन लोड Balancer, फरगेट, और लैम्ब्डा। समाधान के हिस्से के रूप में एप्लिकेशन इंफ्रास्ट्रक्चर स्वचालित रूप से तैनात किया जाता है।
एप्लिकेशन आपको एक इनपुट प्रदान करने और शब्दार्थ समान कॉलम नाम, कॉलम सामग्री, या दोनों के लिए खोज करने की अनुमति देता है। इसके अतिरिक्त, आप खोज से लौटने के लिए एम्बेडिंग मॉडल और निकटतम पड़ोसियों की संख्या का चयन कर सकते हैं। एप्लिकेशन इनपुट प्राप्त करता है, इनपुट को निर्दिष्ट मॉडल के साथ एम्बेड करता है, और उपयोग करता है ओपनसर्च सर्विस में केएनएन सर्च अनुक्रमित कॉलम एम्बेडिंग खोजने के लिए और दिए गए इनपुट के सबसे समान कॉलम खोजने के लिए। प्रदर्शित किए गए खोज परिणामों में तालिका के नाम, कॉलम के नाम और पहचान किए गए कॉलम के लिए समानता स्कोर, साथ ही आगे की खोज के लिए अमेज़न S3 में डेटा के स्थान शामिल हैं।
निम्नलिखित आंकड़ा वेब एप्लिकेशन का एक उदाहरण दिखाता है। इस उदाहरण में, हमने अपने डेटा लेक में उन स्तंभों की खोज की जो समान हैं Column Names (पेलोड प्रकार) करने के लिए district (पेलोड). आवेदन का इस्तेमाल किया all-MiniLM-L6-v2 जैसा एम्बेडिंग मॉडल और लौट आया 10 (k) हमारे OpenSearch सेवा अनुक्रमणिका से निकटतम पड़ोसी।
आवेदन वापस कर दिया transit_district, city, borough, तथा location OpenSearch सेवा में अनुक्रमित डेटा के आधार पर चार सबसे समान स्तंभों के रूप में। यह उदाहरण डेटासेट में शब्दार्थ के समान स्तंभों की पहचान करने के लिए खोज दृष्टिकोण की क्षमता को प्रदर्शित करता है।

चित्रा 3: वेब एप्लिकेशन यूजर इंटरफेस
क्लीन अप
इस ट्यूटोरियल में AWS CDK द्वारा बनाए गए संसाधनों को हटाने के लिए, निम्नलिखित कमांड चलाएँ:
cdk destroy --allनिष्कर्ष
इस पोस्ट में, हमने सारणीबद्ध स्तंभों के लिए सिमेंटिक सर्च इंजन बनाने के लिए एंड-टू-एंड वर्कफ़्लो प्रस्तुत किया।
पर उपलब्ध हमारे कोड ट्यूटोरियल के साथ अपने स्वयं के डेटा पर आज ही आरंभ करें GitHub. यदि आप अपने उत्पादों और प्रक्रियाओं में एमएल के उपयोग में तेजी लाने में सहायता चाहते हैं, तो कृपया संपर्क करें अमेज़न मशीन लर्निंग सॉल्यूशंस लैब.
लेखक के बारे में
![]() कच्ची ओडोमेने AWS AI में एप्लाइड साइंटिस्ट हैं। वह AWS ग्राहकों के लिए व्यावसायिक समस्याओं को हल करने के लिए AI/ML समाधान बनाता है।
कच्ची ओडोमेने AWS AI में एप्लाइड साइंटिस्ट हैं। वह AWS ग्राहकों के लिए व्यावसायिक समस्याओं को हल करने के लिए AI/ML समाधान बनाता है।
![]() टेलर मैकनेली अमेज़न मशीन लर्निंग सॉल्यूशंस लैब में डीप लर्निंग आर्किटेक्ट हैं। वह AWS पर AI/ML का लाभ उठाने के लिए विभिन्न उद्योगों के ग्राहकों की मदद करता है। वह अपने परिवार और ऊर्जावान कुत्ते के साथ एक अच्छा कप कॉफी, बाहर और समय का आनंद लेता है।
टेलर मैकनेली अमेज़न मशीन लर्निंग सॉल्यूशंस लैब में डीप लर्निंग आर्किटेक्ट हैं। वह AWS पर AI/ML का लाभ उठाने के लिए विभिन्न उद्योगों के ग्राहकों की मदद करता है। वह अपने परिवार और ऊर्जावान कुत्ते के साथ एक अच्छा कप कॉफी, बाहर और समय का आनंद लेता है।
![]() ऑस्टिन वेल्च अमेज़न एमएल सॉल्यूशंस लैब में डेटा साइंटिस्ट हैं। वह AWS सार्वजनिक क्षेत्र के ग्राहकों को उनके AI और क्लाउड अपनाने में तेजी लाने में मदद करने के लिए कस्टम डीप लर्निंग मॉडल विकसित करता है। अपने खाली समय में उन्हें पढ़ना, यात्रा करना और जिउ-जित्सु पसंद है।
ऑस्टिन वेल्च अमेज़न एमएल सॉल्यूशंस लैब में डेटा साइंटिस्ट हैं। वह AWS सार्वजनिक क्षेत्र के ग्राहकों को उनके AI और क्लाउड अपनाने में तेजी लाने में मदद करने के लिए कस्टम डीप लर्निंग मॉडल विकसित करता है। अपने खाली समय में उन्हें पढ़ना, यात्रा करना और जिउ-जित्सु पसंद है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- क्षमता
- About
- अनुपस्थित
- में तेजी लाने के
- तेज
- सही रूप में
- के पार
- अतिरिक्त
- इसके अतिरिक्त
- जोड़ता है
- दत्तक ग्रहण
- उन्नत
- AI
- ऐ / एमएल
- सब
- की अनुमति देता है
- वैकल्पिक
- वीरांगना
- अमेज़ॅन मशीन लर्निंग
- अमेज़न एमएल सॉल्यूशंस लैब
- विश्लेषकों
- विश्लेषिकी
- विश्लेषण करें
- और
- अपाचे
- आवेदन
- अनुप्रयोगों
- लागू
- दृष्टिकोण
- स्थापत्य
- सौंपा
- स्वचालित
- स्वतः
- उपलब्ध
- औसत
- एडब्ल्यूएस
- एडब्ल्यूएस गोंद
- आधारित
- क्योंकि
- बड़ा
- बड़ा डेटा
- लाना
- निर्माण
- इमारत
- बनाता है
- व्यापार
- सफाई
- बादल
- बादल को गोद लेना
- समूह
- कोड
- कॉफी
- एकत्र
- स्तंभ
- स्तंभ
- सामान्य
- तुलना
- संपर्क करें
- सामग्री
- कन्वेंशनों
- बदलना
- परिवर्तित
- बनाना
- बनाया
- बनाता है
- कप
- रिवाज
- ग्राहक
- तिथि
- डेटा विश्लेषण
- डेटा लेक
- आँकड़े की गुणवत्ता
- आँकड़े वाला वैज्ञानिक
- डेटासेट
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- दिखाना
- दर्शाता
- तैनात
- तैनात
- तैनाती
- को नष्ट
- विकास
- विकसित
- विभिन्न
- खोज
- मूर्खता
- कई
- कुत्ता
- डोमेन
- डाउनलोड
- से प्रत्येक
- दक्षता
- कुशल
- शुरू से अंत तक
- endpoint
- इंजन
- ईथर (ईटीएच)
- हर कोई
- उदाहरण
- अन्वेषण
- उद्धरण
- की सुविधा
- सुपरिचय
- परिवार
- विशेषताएं
- आकृति
- पट्टिका
- फ़ाइलें
- अंतिम
- अंत में
- वित्तीय
- खोज
- खोज
- प्रथम
- निम्नलिखित
- प्रारूप
- से
- पूर्ण
- समारोह
- कार्यों
- आगे
- मिल
- दी
- अच्छा
- सरकार
- हेडर
- मदद
- मदद करता है
- कैसे
- How To
- एचटीएमएल
- HTTPS
- पहचान
- पहचान करना
- लागू करने के
- महत्वपूर्ण
- in
- असमर्थता
- शामिल
- शामिल
- अनुक्रमणिका
- व्यक्ति
- उद्योगों
- करें-
- इंफ्रास्ट्रक्चर
- आरंभ
- आरंभ
- निवेश
- निर्देश
- बातचीत
- इंटरैक्टिव
- इंटरफेस
- का आह्वान
- शामिल करना
- मुद्दों
- IT
- काम
- नौकरियां
- JSON
- प्रयोगशाला
- झील
- बड़ा
- परत
- सीख रहा हूँ
- लाभ
- पुस्तकालय
- सूची
- भार
- स्थानों
- मशीन
- यंत्र अधिगम
- मिलान
- मेडिकल
- ML
- आदर्श
- मॉडल
- अधिक
- अधिकांश
- विभिन्न
- नाम
- नामों
- नामकरण
- आवश्यकता
- पड़ोसियों
- संख्या
- प्रस्तुत
- ऑनलाइन
- अन्य
- सड़क पर
- अपना
- समानांतर
- पैरामीटर
- भाग
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- कृप्या अ
- पद
- संभावित
- वरीय
- प्रस्तुत
- पिछला
- समस्याओं
- प्राप्ति
- प्रक्रिया
- प्रक्रियाओं
- प्रसंस्करण
- प्रस्तुत
- उत्पाद
- प्रदान करना
- प्रदान करता है
- सार्वजनिक
- गुणवत्ता
- कच्चा
- पढ़ना
- प्राप्त
- नियमित
- का प्रतिनिधित्व करता है
- की आवश्यकता होती है
- अपेक्षित
- शोधकर्ताओं
- उपयुक्त संसाधन चुनें
- क्रमश
- परिणाम
- वापसी
- रन
- दौड़ना
- sagemaker
- वैज्ञानिक
- वैज्ञानिकों
- Search
- search engine
- खोज
- दूसरा
- सेक्टर
- सेवा
- सेवाएँ
- सेट
- दिखाया
- दिखाता है
- महत्वपूर्ण
- समान
- सरल
- एक
- आकार
- समाधान
- समाधान ढूंढे
- हल
- सूत्रों का कहना है
- विनिर्दिष्ट
- ट्रेनिंग
- शुरू
- कदम
- कदम
- भंडारण
- ऐसा
- समर्थन करता है
- उपयुक्त
- तालिका
- RSI
- लेकिन हाल ही
- यहाँ
- पहर
- सेवा मेरे
- आज
- बदालना
- ट्रान्सफ़ॉर्मर
- यात्रा का
- ट्यूटोरियल
- उपयोग
- उपयोगकर्ता
- यूजर इंटरफेस
- विभिन्न
- वेब
- वेब एप्लीकेशन
- कौन कौन से
- वर्कफ़्लो
- होगा
- आपका
- जेफिरनेट