
बिंग छवि निर्माता से छवि
खोजपूर्ण डेटा विश्लेषण (ईडीए) प्रत्येक डेटा विज्ञान परियोजना की शुरुआत में किया जाने वाला सबसे महत्वपूर्ण कार्य है।
संक्षेप में, इसमें आपके डेटा की अंतर्निहितता का पता लगाने के लिए उसकी पूरी तरह से जांच करना और उसका वर्णन करना शामिल है विशेषताएँ, मुमकिन असामान्यताएं, और छिपा हुआ पैटर्न उपयोग करें और रिश्तों.
आपके डेटा की यह समझ ही अंततः काम आएगी निम्नलिखित चरणों के माध्यम से मार्गदर्शन करें आपकी मशीन लर्निंग पाइपलाइन, डेटा प्रीप्रोसेसिंग से लेकर मॉडल निर्माण और परिणामों के विश्लेषण तक।
ईडीए की प्रक्रिया में मूल रूप से तीन मुख्य कार्य शामिल हैं:
- चरण १: डेटासेट अवलोकन और वर्णनात्मक सांख्यिकी
- चरण १: फ़ीचर मूल्यांकन और विज़ुअलाइज़ेशन, तथा
- चरण १: डेटा गुणवत्ता मूल्यांकन
जैसा कि आपने अनुमान लगाया होगा, इनमें से प्रत्येक कार्य में काफी व्यापक मात्रा में विश्लेषण शामिल हो सकते हैं, जो आपको आसानी से समझने में मदद करेंगे। एक पागल आदमी की तरह अपने पांडा डेटाफ्रेम को काटना, प्रिंट करना और प्लॉट करना।
जब तक आप काम के लिए सही उपकरण नहीं चुनते।
इस लेख में, हम इसमें गोता लगाएँगे प्रभावी ईडीए प्रक्रिया का प्रत्येक चरण, और चर्चा करें कि आपको क्यों मुड़ना चाहिए ydata-प्रोफ़ाइलिंग इसमें महारत हासिल करने के लिए अपनी वन-स्टॉप शॉप में।
सेवा मेरे सर्वोत्तम प्रथाओं का प्रदर्शन करें और अंतर्दृष्टि की जांच करें, हम इसका उपयोग करेंगे वयस्क जनगणना आय डेटासेट, कागल या यूसीआई रिपोजिटरी पर निःशुल्क उपलब्ध (लाइसेंस: CC0: सार्वजनिक डोमेन).
जब हम पहली बार किसी अज्ञात डेटासेट पर हाथ डालते हैं, तो तुरंत एक स्वचालित विचार सामने आता है: मैं किसके साथ काम कर रहा हूँ?
भविष्य के मशीन लर्निंग कार्यों में इसे कुशलतापूर्वक संभालने के लिए हमें अपने डेटा की गहरी समझ होनी चाहिए
एक सामान्य नियम के रूप में, हम परंपरागत रूप से डेटा को संख्या के सापेक्ष चिह्नित करके शुरू करते हैं टिप्पणियों, संख्या और सुविधाओं के प्रकार, कुल मिलाकर गायब दर, और का प्रतिशत नक़ल टिप्पणियों.
कुछ पांडा हेरफेर और सही चीटशीट के साथ, हम अंततः कोड के कुछ छोटे स्निपेट के साथ उपरोक्त जानकारी प्रिंट कर सकते हैं:
डेटासेट अवलोकन: वयस्क जनगणना डेटासेट। अवलोकनों की संख्या, विशेषताएँ, सुविधा प्रकार, डुप्लिकेट पंक्तियाँ और लुप्त मान। लेखक द्वारा स्निपेट.
कुल मिलाकर, आउटपुट स्वरूप आदर्श नहीं है... यदि आप पांडा से परिचित हैं, तो आप मानक भी जानते होंगे कार्य करने का ढंग ईडीए प्रक्रिया शुरू करने की - df.describe():
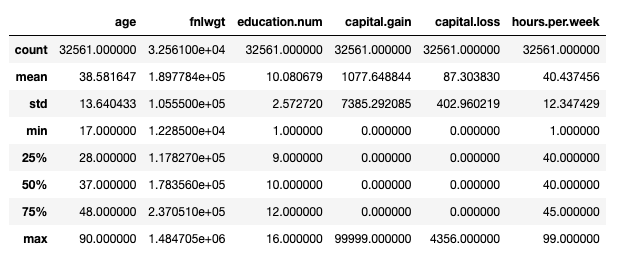
वयस्क डेटासेट: प्रस्तुत मुख्य आँकड़े df.वर्णन (). लेखक द्वारा छवि.
हालाँकि, यह केवल विचार करता है संख्यात्मक विशेषताएँ. हम एक का उपयोग कर सकते हैं df.describe(include='object') कुछ अतिरिक्त जानकारी प्रिंट करने के लिए श्रेणीबद्ध विशेषताएं (गणना, अद्वितीय, मोड, आवृत्ति), लेकिन मौजूदा श्रेणियों की एक साधारण जांच में कुछ अधिक क्रियात्मकता शामिल होगी:
डेटासेट अवलोकन: वयस्क जनगणना डेटासेट। डेटा में प्रत्येक श्रेणीगत सुविधा के लिए मौजूदा श्रेणियों और संबंधित आवृत्तियों को प्रिंट करना। लेखक द्वारा स्निपेट.
हालाँकि, हम यह कर सकते हैं - और अनुमान लगाओ, बाद के सभी ईडीए कार्य! - कोड की एक पंक्ति में, का उपयोग करते हुए ydata-प्रोफ़ाइलिंग:
यडेटा-प्रोफाइलिंग का उपयोग करके वयस्क जनगणना डेटासेट की प्रोफाइलिंग रिपोर्ट। लेखक द्वारा स्निपेट.
उपरोक्त कोड डेटा की संपूर्ण प्रोफ़ाइलिंग रिपोर्ट तैयार करता है, जिसका उपयोग हम अपनी ईडीए प्रक्रिया को आगे बढ़ाने के लिए कर सकते हैं, बिना किसी और कोड को लिखने की आवश्यकता के!
हम निम्नलिखित अनुभागों में रिपोर्ट के विभिन्न अनुभागों का अध्ययन करेंगे। किस संबंध में डेटा की समग्र विशेषताएँ, जो भी जानकारी हम खोज रहे थे वह इसमें शामिल है अवलोकन अनुभाग:
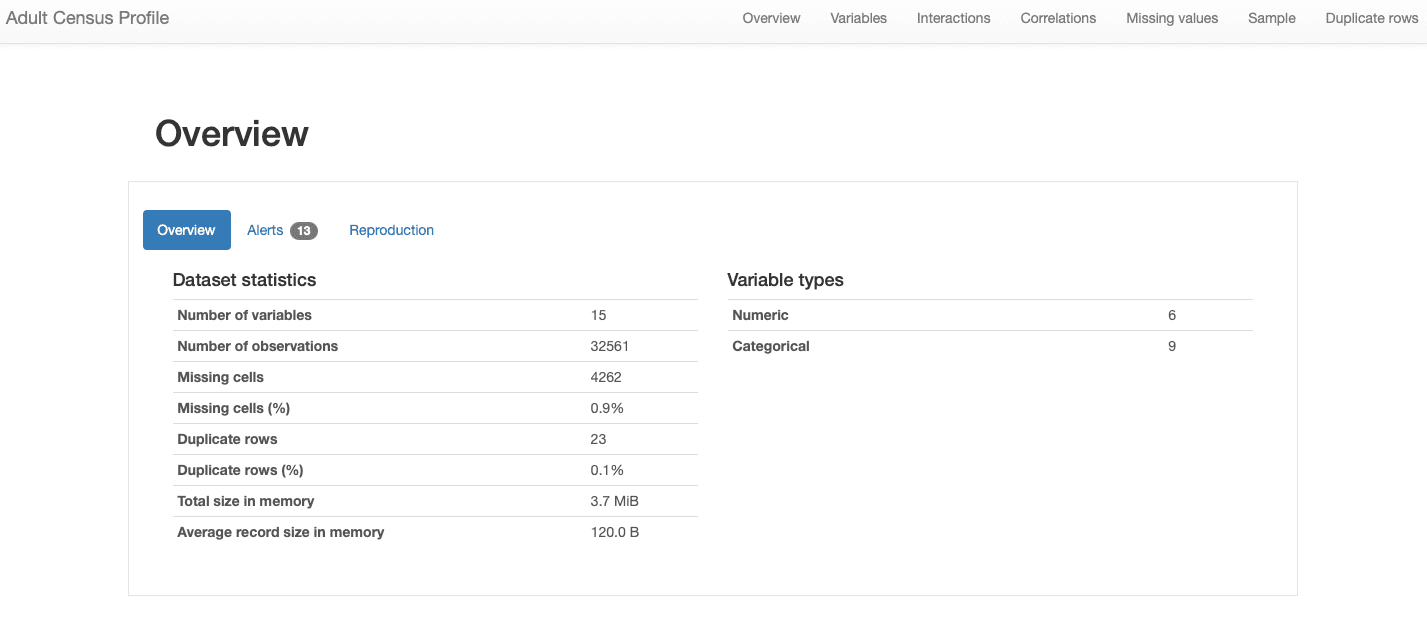
ydata-प्रोफाइलिंग: डेटा प्रोफाइलिंग रिपोर्ट - डेटासेट अवलोकन। लेखक द्वारा छवि.
हम देख सकते हैं कि हमारे डेटासेट में शामिल हैं 15 विशेषताएँ और 32561 अवलोकन, साथ में 23 डुप्लिकेट रिकॉर्ड, और 0.9% की कुल गायब दर.
इसके अतिरिक्त, डेटासेट को सही ढंग से पहचाना गया है सारणीबद्ध डेटासेट, और बल्कि विषम, दोनों को प्रस्तुत करता है संख्यात्मक और श्रेणीबद्ध विशेषताएं. के लिए समय श्रृंखला डेटा, जिसमें समय की निर्भरता है और विभिन्न प्रकार के पैटर्न प्रस्तुत करता है, ydata-profiling शामिल होगा रिपोर्ट में अन्य आँकड़े और विश्लेषण.
हम आगे का निरीक्षण कर सकते हैं कच्चा डेटा और मौजूदा डुप्लिकेट रिकॉर्ड अधिक जटिल विश्लेषण में जाने से पहले, सुविधाओं की समग्र समझ प्राप्त करें:
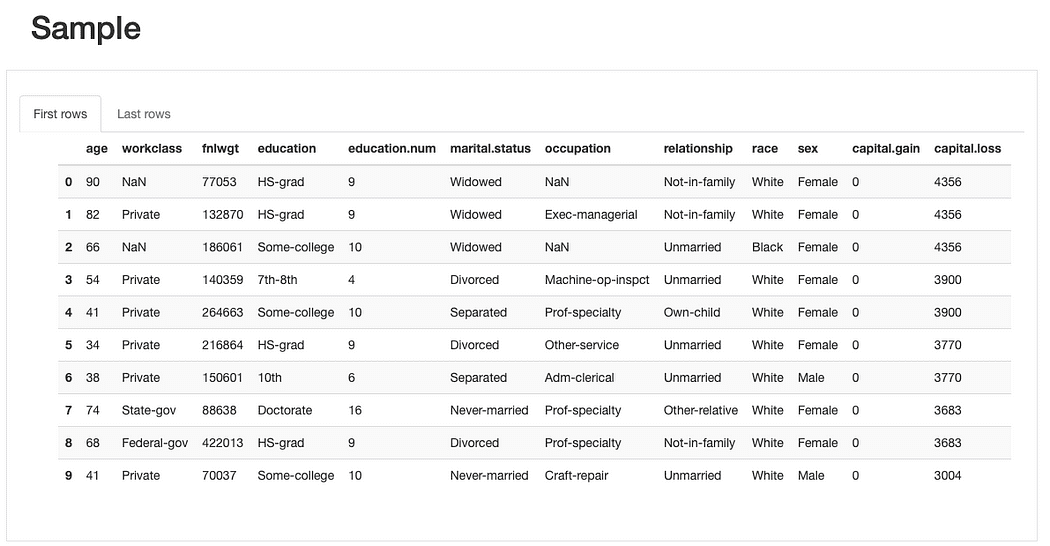
ydata-प्रोफ़ाइलिंग: डेटा प्रोफ़ाइलिंग रिपोर्ट - नमूना पूर्वावलोकन। लेखक द्वारा छवि.
संक्षिप्त नमूना पूर्वावलोकन से डेटा नमूने में, हम तुरंत देख सकते हैं कि हालाँकि डेटासेट में समग्र रूप से गायब डेटा का प्रतिशत कम है, कुछ सुविधाएँ इससे प्रभावित हो सकती हैं दूसरों से अधिक. हम एक बल्कि की पहचान भी कर सकते हैं श्रेणियों की पर्याप्त संख्या कुछ सुविधाओं के लिए, और 0-मूल्य वाली सुविधाओं के लिए (या कम से कम 0 की महत्वपूर्ण मात्रा के साथ)।
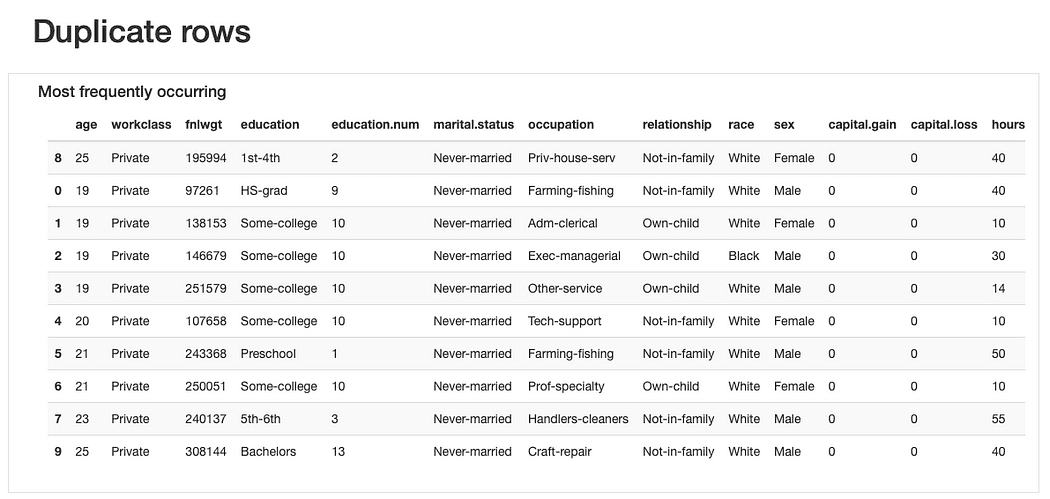
ydata-प्रोफाइलिंग: डेटा प्रोफाइलिंग रिपोर्ट - डुप्लिकेट पंक्तियों का पूर्वावलोकन। लेखक द्वारा छवि.
डुप्लिकेट पंक्तियों के संबंध में, "दोहराई गई" टिप्पणियों को ढूंढना अजीब नहीं होगा, यह देखते हुए कि अधिकांश विशेषताएं उन श्रेणियों का प्रतिनिधित्व करती हैं जहां कई लोग एक साथ "फिट" हो सकते हैं।
फिर भी, शायद ए "डेटा गंध" हो सकता है कि ये अवलोकन समान हों age मान (जो प्रशंसनीय है) और बिल्कुल वही fnlwgt जिस पर, प्रस्तुत मूल्यों को देखते हुए, विश्वास करना कठिन लगता है। इसलिए आगे के विश्लेषण की आवश्यकता होगी, लेकिन हमें करना चाहिए सबसे अधिक संभावना है कि इन डुप्लिकेट को छोड़ दें बाद में।
कुल मिलाकर, डेटा अवलोकन एक साधारण विश्लेषण हो सकता है, लेकिन एक अत्यंत प्रभावशाली, क्योंकि यह हमारी पाइपलाइन में आगामी कार्यों को परिभाषित करने में हमारी मदद करेगा।
समग्र डेटा डिस्क्रिप्टर पर एक नज़र डालने के बाद, हमें इसकी आवश्यकता है हमारे डेटासेट की सुविधाओं पर ज़ूम इन करें, उनकी व्यक्तिगत संपत्तियों पर कुछ अंतर्दृष्टि प्राप्त करने के लिए - वस्तु के एक प्रकार विश्लेषण - साथ ही उनकी बातचीत और रिश्ते - बहुभिन्नरूपी विश्लेषण.
दोनों कार्य बहुत अधिक निर्भर हैं पर्याप्त आँकड़ों और विज़ुअलाइज़ेशन की जाँच करना, जो होना आवश्यक है सुविधा के प्रकार के अनुरूप बनाया गया हाथ में (जैसे, संख्यात्मक, श्रेणीबद्ध), और व्यवहार हम विच्छेदन करना चाह रहे हैं (जैसे, अंतःक्रिया, सहसंबंध)।
आइए प्रत्येक कार्य के लिए सर्वोत्तम प्रथाओं पर एक नज़र डालें।
वस्तु के एक प्रकार विश्लेषण
प्रत्येक विशेषता की व्यक्तिगत विशेषताओं का विश्लेषण करना महत्वपूर्ण है क्योंकि इससे हमें उनके बारे में निर्णय लेने में मदद मिलेगी विश्लेषण के लिए प्रासंगिकता और डेटा तैयारी का प्रकार उन्हें इष्टतम परिणाम प्राप्त करने की आवश्यकता हो सकती है।
उदाहरण के लिए, हमें ऐसे मान मिल सकते हैं जो सीमा से बेहद बाहर हैं और उनका संदर्भ हो सकता है विसंगतियों or बाहरी कारकों के कारण. हमें इसकी आवश्यकता हो सकती है मानकीकरण करना संख्यात्मक तिथि या एक प्रदर्शन श्रेणीबद्ध का एक-हॉट एन्कोडिंग मौजूदा श्रेणियों की संख्या के आधार पर सुविधाएँ। या हमें संख्यात्मक विशेषताओं को संभालने के लिए अतिरिक्त डेटा तैयार करना पड़ सकता है स्थानांतरित या तिरछा, यदि हम जिस मशीन लर्निंग एल्गोरिदम का उपयोग करना चाहते हैं वह एक विशेष वितरण (सामान्य रूप से गाऊसी) की अपेक्षा करता है।
इसलिए सर्वोत्तम प्रथाओं में वर्णनात्मक सांख्यिकी और डेटा वितरण जैसी व्यक्तिगत संपत्तियों की गहन जांच की आवश्यकता होती है।
ये बाहरी निष्कासन, मानकीकरण, लेबल एन्कोडिंग, डेटा प्रतिरूपण, डेटा संवर्द्धन और अन्य प्रकार के प्रीप्रोसेसिंग के बाद के कार्यों की आवश्यकता पर प्रकाश डालेंगे।
चलिए जांच करते हैं race और capital.gain विस्तृत रूप में। हम तुरंत क्या पहचान सकते हैं?
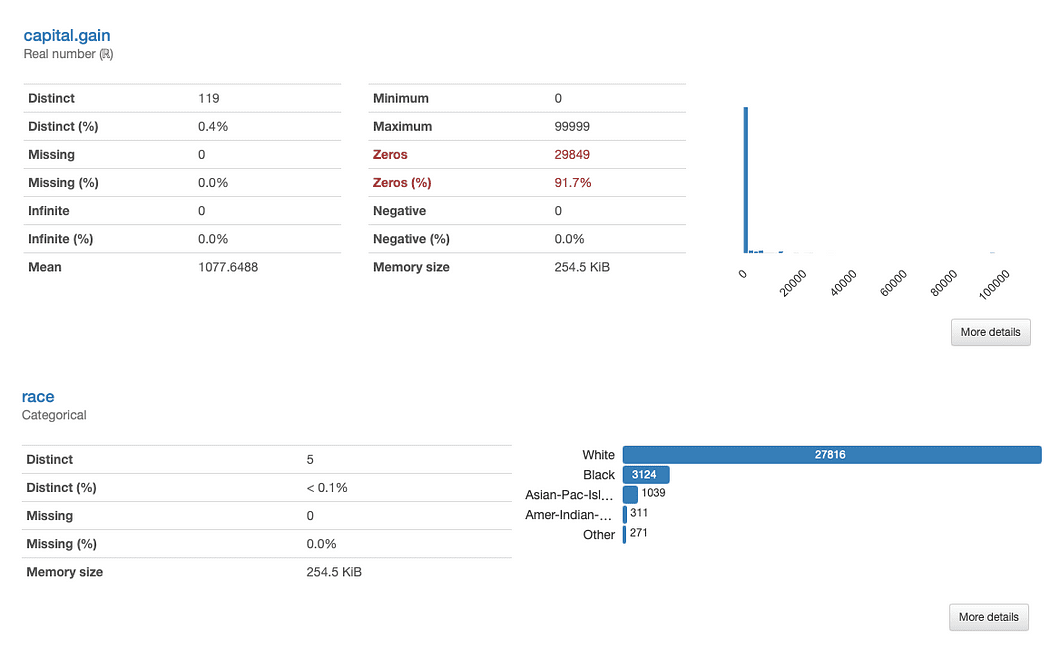
ydata-प्रोफाइलिंग: प्रोफाइलिंग रिपोर्ट (रेस और कैपिटल.गेन)। लेखक द्वारा छवि.
का मूल्यांकन पूंजी लाभ सीधा है:
डेटा वितरण को देखते हुए, हम सवाल कर सकते हैं कि क्या सुविधा हमारे विश्लेषण में कोई मूल्य जोड़ती है, क्योंकि 91.7% मान "0" हैं।
का विश्लेषण दौड़ थोड़ा अधिक जटिल है:
इसके अलावा अन्य जातियों का स्पष्ट रूप से कम प्रतिनिधित्व है White. इससे दो मुख्य मुद्दे दिमाग में आते हैं:
- एक मशीन लर्निंग एल्गोरिदम की सामान्य प्रवृत्ति है कम प्रतिनिधित्व वाली अवधारणाओं को नज़रअंदाज़ करेंकी समस्या के रूप में जाना जाता है छोटे विच्छेद, जिससे सीखने का प्रदर्शन कम हो जाता है;
- दूसरा इस मुद्दे से कुछ हद तक व्युत्पन्न है: चूंकि हम एक संवेदनशील विशेषता से निपट रहे हैं, इस "अनदेखी प्रवृत्ति" के ऐसे परिणाम हो सकते हैं जो सीधे संबंधित हैं पूर्वाग्रह और निष्पक्षता मुद्दों. कुछ ऐसा जिसे हम निश्चित रूप से अपने मॉडलों में शामिल नहीं करना चाहते।
इसे ध्यान में रखते हुए, शायद हमें ऐसा करना चाहिए डेटा संवर्द्धन करने पर विचार करें कम प्रतिनिधित्व वाली श्रेणियों पर विचार करने के साथ-साथ उन पर विचार भी किया गया मॉडल मूल्यांकन के लिए निष्पक्षता-जागरूक मेट्रिक्स, प्रदर्शन से संबंधित किसी भी विसंगति की जांच करने के लिए race मूल्यों.
जब हम डेटा गुणवत्ता सर्वोत्तम प्रथाओं (चरण 3) पर चर्चा करते हैं तो हम अन्य डेटा विशेषताओं पर अधिक विस्तार से चर्चा करेंगे जिन पर ध्यान देने की आवश्यकता है। यह उदाहरण केवल यह दर्शाता है कि प्रत्येक व्यक्तिगत विशेषता का आकलन करके हम कितनी अंतर्दृष्टि प्राप्त कर सकते हैं गुण.
अंत में, ध्यान दें कि कैसे, जैसा कि पहले उल्लेख किया गया है, विभिन्न फीचर प्रकारों के लिए अलग-अलग आँकड़ों और विज़ुअलाइज़ेशन रणनीतियों की आवश्यकता होती है:
- संख्यात्मक विशेषताएँ इनमें अक्सर माध्य, मानक विचलन, तिरछापन, कर्टोसिस और अन्य मात्रात्मक आँकड़ों के बारे में जानकारी शामिल होती है, और हिस्टोग्राम प्लॉट का उपयोग करके सबसे अच्छा प्रतिनिधित्व किया जाता है;
- श्रेणीबद्ध विशेषताएं आमतौर पर मोड, माध्यिका और आवृत्ति तालिकाओं का उपयोग करके वर्णित किया जाता है, और श्रेणी विश्लेषण के लिए बार प्लॉट का उपयोग करके दर्शाया जाता है।
ydata-प्रोफाइलिंग: प्रोफाइलिंग रिपोर्ट। प्रस्तुत आँकड़े और विज़ुअलाइज़ेशन प्रत्येक सुविधा प्रकार के अनुसार समायोजित किए जाते हैं। लेखक द्वारा स्क्रीनकास्ट।
इस तरह का विस्तृत विश्लेषण सामान्य पांडा हेरफेर के साथ करना बोझिल होगा, लेकिन सौभाग्य से ydata-profiling इसमें यह सारी कार्यक्षमता अंतर्निहित है ProfileReport हमारी सुविधा के लिए: स्निपेट में कोड की कोई अतिरिक्त पंक्तियाँ नहीं जोड़ी गईं!
बहुभिन्नरूपी विश्लेषण
बहुभिन्नरूपी विश्लेषण के लिए, सर्वोत्तम अभ्यास मुख्य रूप से दो रणनीतियों पर ध्यान केंद्रित करते हैं: विश्लेषण करना बातचीत सुविधाओं के बीच, और उनका विश्लेषण करना सहसंबंध.
इंटरैक्शन का विश्लेषण
बातचीत हमें करते हैं दृष्टिगत रूप से पता लगाएं कि सुविधाओं का प्रत्येक जोड़ा कैसे व्यवहार करता है, अर्थात, एक विशेषता के मूल्य दूसरे के मूल्यों से कैसे संबंधित हैं।
उदाहरण के लिए, वे प्रदर्शन कर सकते हैं सकारात्मक or नकारात्मक रिश्ते, इस पर निर्भर करते हैं कि किसी के मूल्यों में वृद्धि क्रमशः दूसरे के मूल्यों में वृद्धि या कमी के साथ जुड़ी हुई है या नहीं।
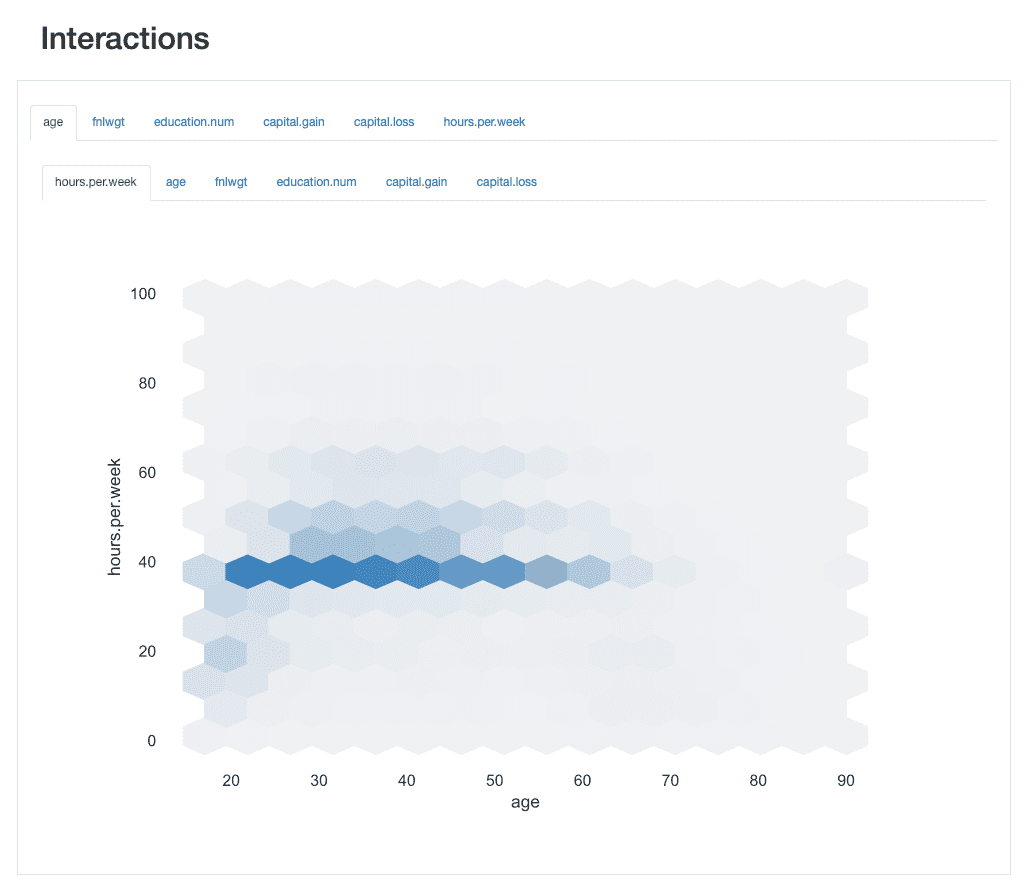
ydata-प्रोफाइलिंग: प्रोफाइलिंग रिपोर्ट - इंटरैक्शन। लेखक द्वारा छवि.
के बीच बातचीत ले रहे हैं age और hours.per.weekउदाहरण के तौर पर, हम देख सकते हैं कि कार्यबल का बड़ा हिस्सा मानक 40 घंटे काम करता है। हालाँकि, कुछ "व्यस्त मधुमक्खियाँ" हैं जो 60 से 65 वर्ष की आयु के बीच (30 या 45 घंटों तक) काम करती हैं। सप्ताह.
सहसंबंधों का विश्लेषण
इसी तरह बातचीत के लिए, सहसंबंध हमें देते हैं रिश्ते का विश्लेषण करें सुविधाओं के बीच. हालाँकि, सहसंबंध उस पर "मूल्य डालते हैं", ताकि हमारे लिए उस रिश्ते की "ताकत" निर्धारित करना आसान हो।
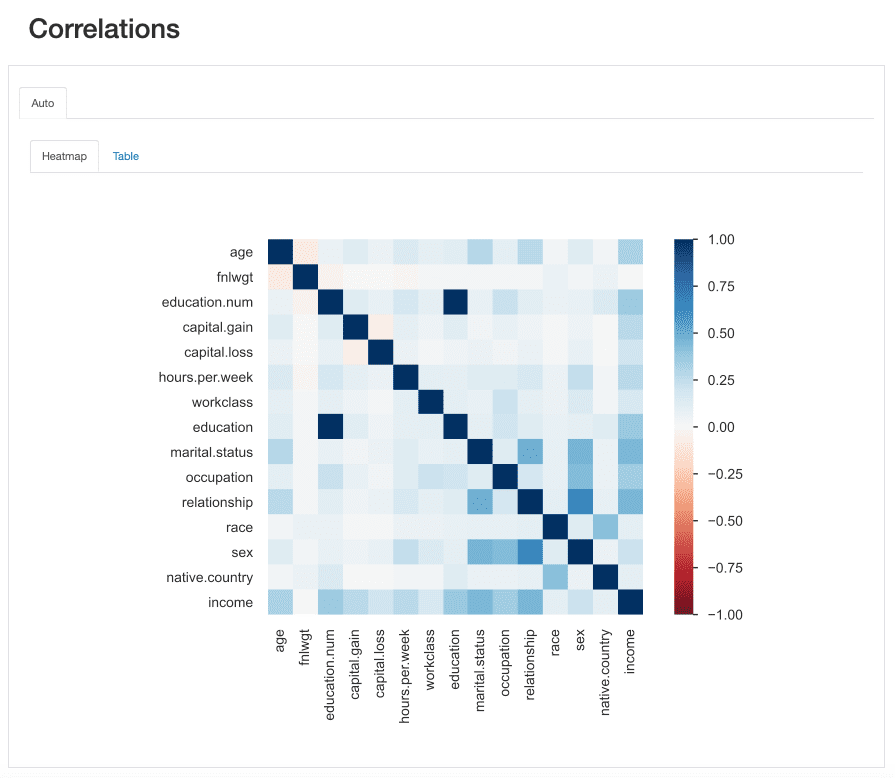
ये "ताकत" है सहसंबंध गुणांक द्वारा मापा जाता है और इसका विश्लेषण संख्यात्मक रूप से किया जा सकता है (उदाहरण के लिए, ए का निरीक्षण करना)। सहसम्बंध मैट्रिक्स) या एक के साथ हीटमैप, जो दिलचस्प पैटर्न को स्पष्ट रूप से उजागर करने के लिए रंग और छायांकन का उपयोग करता है:
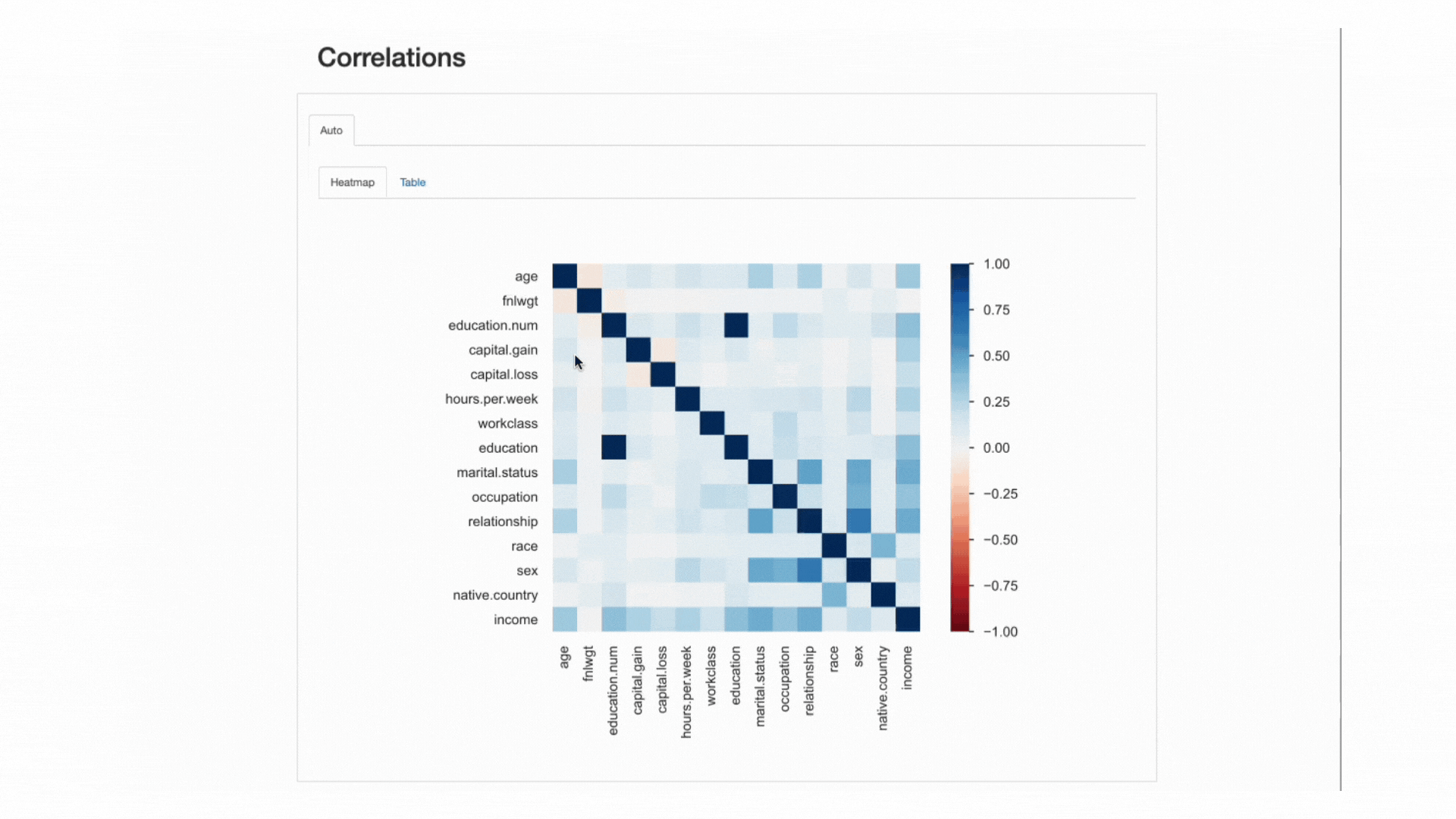
ydata-प्रोफाइलिंग: प्रोफाइलिंग रिपोर्ट - हीटमैप और सहसंबंध मैट्रिक्स। लेखक द्वारा स्क्रीनकास्ट।
हमारे डेटासेट के संबंध में, ध्यान दें कि इनके बीच संबंध कैसा है education और education.num अलग दिखना। वास्तव में, वे समान जानकारी रखते हैं, तथा education.num का एक बिनिंग मात्र है education मूल्यों.
अन्य पैटर्न जो ध्यान आकर्षित करता है वह है बीच का संबंध sex और relationship हालाँकि यह फिर से बहुत जानकारीपूर्ण नहीं है: दोनों सुविधाओं के मूल्यों को देखते हुए, हमें एहसास होगा कि ये सुविधाएँ संभवतः संबंधित हैं क्योंकि male और female के अनुरूप होगा husband और wife, क्रमशः।
इस प्रकार की अतिरेक की जाँच यह देखने के लिए की जा सकती है कि क्या हम इनमें से कुछ विशेषताओं को विश्लेषण से हटा सकते हैं (marital.status से भी संबंधित है relationship और sex; native.country और race उदाहरण के लिए, दूसरों के बीच में)।
ydata-प्रोफाइलिंग: प्रोफाइलिंग रिपोर्ट - सहसंबंध। लेखक द्वारा छवि.
हालाँकि, ऐसे अन्य सहसंबंध भी हैं जो सामने आते हैं और हमारे विश्लेषण के उद्देश्य से दिलचस्प हो सकते हैं।
उदाहरण के लिए, के बीच सहसंबंधsex और occupationया, sex और hours.per.week.
अंत में, के बीच सहसंबंध income और शेष विशेषताएं वास्तव में जानकारीपूर्ण हैं, विशेष रूप से उस स्थिति में जब हम किसी वर्गीकरण समस्या का पता लगाने का प्रयास कर रहे हों। क्या हैं ये जानना सर्वाधिक सहसंबद्ध हमारे लक्षित वर्ग की विशेषताएँ हमें पहचानने में मदद करती हैं सबसे अधिक भेदभावपूर्ण सुविधाएँ और साथ ही संभावित डेटा लीकर्स का पता लगाएं जो हमारे मॉडल को प्रभावित कर सकते हैं।
हीटमैप से ऐसा प्रतीत होता है marital.status or relationship जबकि, सबसे महत्वपूर्ण भविष्यवक्ताओं में से हैं fnlwgt उदाहरण के लिए, परिणाम पर कोई खास प्रभाव पड़ता नहीं दिख रहा है।
डेटा डिस्क्रिप्टर और विज़ुअलाइज़ेशन के समान, इंटरैक्शन और सहसंबंधों को भी मौजूदा सुविधाओं के प्रकार पर ध्यान देने की आवश्यकता है।
दूसरे शब्दों में, विभिन्न संयोजनों को विभिन्न सहसंबंध गुणांकों के साथ मापा जाएगा। डिफ़ॉल्ट रूप से, ydata-profiling सहसंबंध चलाता है auto, जिसका अर्थ है कि:
- संख्यात्मक बनाम संख्यात्मक सहसंबंधों का उपयोग करके मापा जाता है स्पीयरमैन का पद सहसंबंध गुणांक;
- श्रेणीबद्ध बनाम श्रेणीबद्ध सहसंबंधों का उपयोग करके मापा जाता है क्रैमर का वी;
- संख्यात्मक बनाम श्रेणीबद्ध सहसंबंध क्रैमर वी का भी उपयोग करते हैं, जहां संख्यात्मक विशेषता को पहले विवेचित किया जाता है;
और अगर आप चेक करना चाहते हैं अन्य सहसंबंध गुणांक (उदाहरण के लिए, पियर्सन, केंडल, फी) आप आसानी से कर सकते हैं रिपोर्ट के पैरामीटर कॉन्फ़िगर करें.
जैसे ही हम ए की ओर बढ़ते हैं डेटा-केंद्रित प्रतिमान एआई विकास में शीर्ष पर है संभावित जटिल कारक हमारे डेटा में जो उत्पन्न होता है वह आवश्यक है।
"जटिल कारकों" के साथ, हम इसका उल्लेख करते हैं त्रुटियों जो प्रसंस्करण के डेटा संग्रह के दौरान हो सकता है, या डेटा की आंतरिक विशेषताएँ वह बस इसका एक प्रतिबिंब है प्रकृति डेटा का।
इसमें शामिल है लापता डेटा, असंतुलित डेटा, स्थिर मूल्यों, डुप्लिकेट, अत्यधिक सहसंबद्ध or निरर्थक विशेषताएं, शोर डेटा, दूसरों के बीच में।
डेटा गुणवत्ता के मुद्दे: त्रुटियाँ और डेटा आंतरिक विशेषताएँ। लेखक द्वारा छवि.
किसी प्रोजेक्ट की शुरुआत में इन डेटा गुणवत्ता समस्याओं का पता लगाना (और विकास के दौरान उनकी लगातार निगरानी करना) महत्वपूर्ण है।
यदि मॉडल निर्माण चरण से पहले उनकी पहचान और समाधान नहीं किया जाता है, तो वे संपूर्ण एमएल पाइपलाइन और उसके बाद के विश्लेषणों और निष्कर्षों को खतरे में डाल सकते हैं।
एक स्वचालित प्रक्रिया के बिना, इन मुद्दों को पहचानने और संबोधित करने की क्षमता पूरी तरह से ईडीए विश्लेषण करने वाले व्यक्ति के व्यक्तिगत अनुभव और विशेषज्ञता पर छोड़ दी जाएगी, जो स्पष्ट रूप से आदर्श नहीं है। साथ ही, किसी के कंधों पर कितना भार होना चाहिए, विशेष रूप से उच्च-आयामी डेटासेट पर विचार करते हुए। आने वाली दुःस्वप्न चेतावनी!
यह इसकी सबसे अधिक प्रशंसित विशेषताओं में से एक है ydata-profiling, डेटा गुणवत्ता अलर्ट की स्वचालित पीढ़ी:
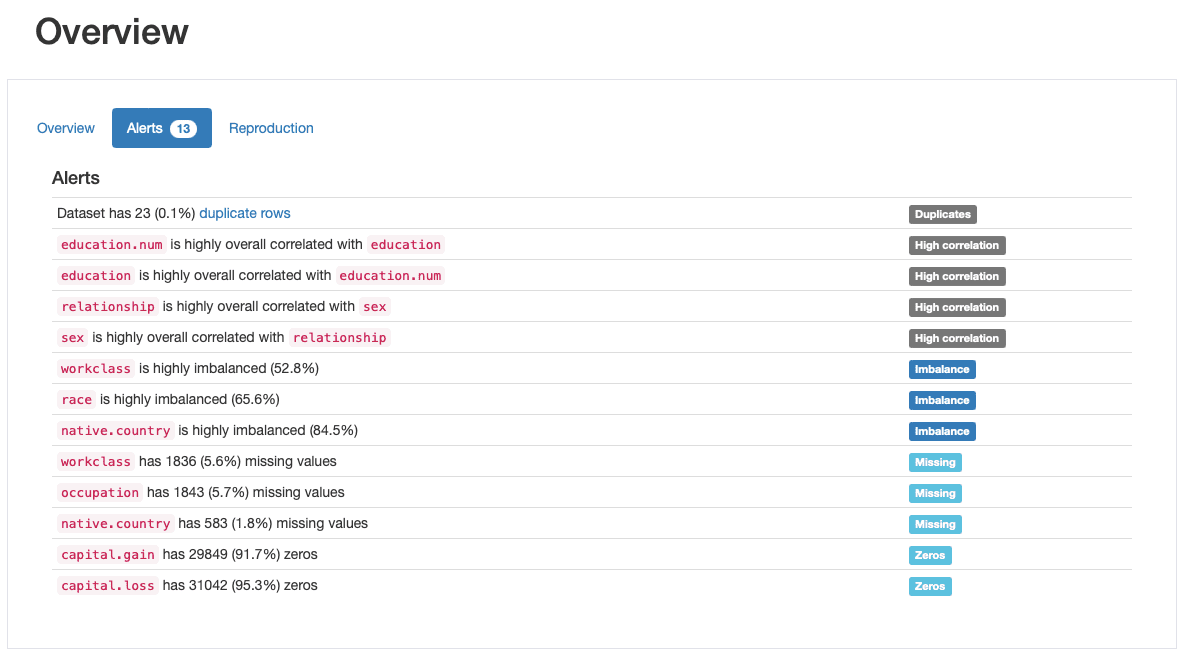
ydata-प्रोफाइलिंग: प्रोफाइलिंग रिपोर्ट - डेटा गुणवत्ता अलर्ट। लेखक द्वारा छवि.
प्रोफ़ाइल कम से कम 5 विभिन्न प्रकार की डेटा गुणवत्ता समस्याओं को आउटपुट करती है, अर्थात् duplicates, high correlation, imbalance, missing, तथा zeros.
वास्तव में, हमने इनमें से कुछ की पहचान पहले ही कर ली थी, जब हम चरण 2 से गुजरे थे: race एक अत्यधिक असंतुलित विशेषता है और capital.gain मुख्य रूप से 0 से भरा हुआ है। हमने इनके बीच गहरा संबंध भी देखा है education और education.num, तथा relationship और sex.
गुम डेटा पैटर्न का विश्लेषण
अलर्ट के व्यापक दायरे पर विचार किया गया, ydata-profiling में विशेष रूप से सहायक है लुप्त डेटा पैटर्न का विश्लेषण.
चूँकि वास्तविक दुनिया के डोमेन में गुम डेटा एक बहुत ही आम समस्या है और यह कुछ क्लासिफायर के अनुप्रयोग को पूरी तरह से प्रभावित कर सकता है या उनकी भविष्यवाणियों को गंभीर रूप से प्रभावित कर सकता है, एक और सर्वोत्तम अभ्यास लापता डेटा का सावधानीपूर्वक विश्लेषण करना है प्रतिशत और व्यवहार जो हमारी सुविधाएँ प्रदर्शित कर सकती हैं:
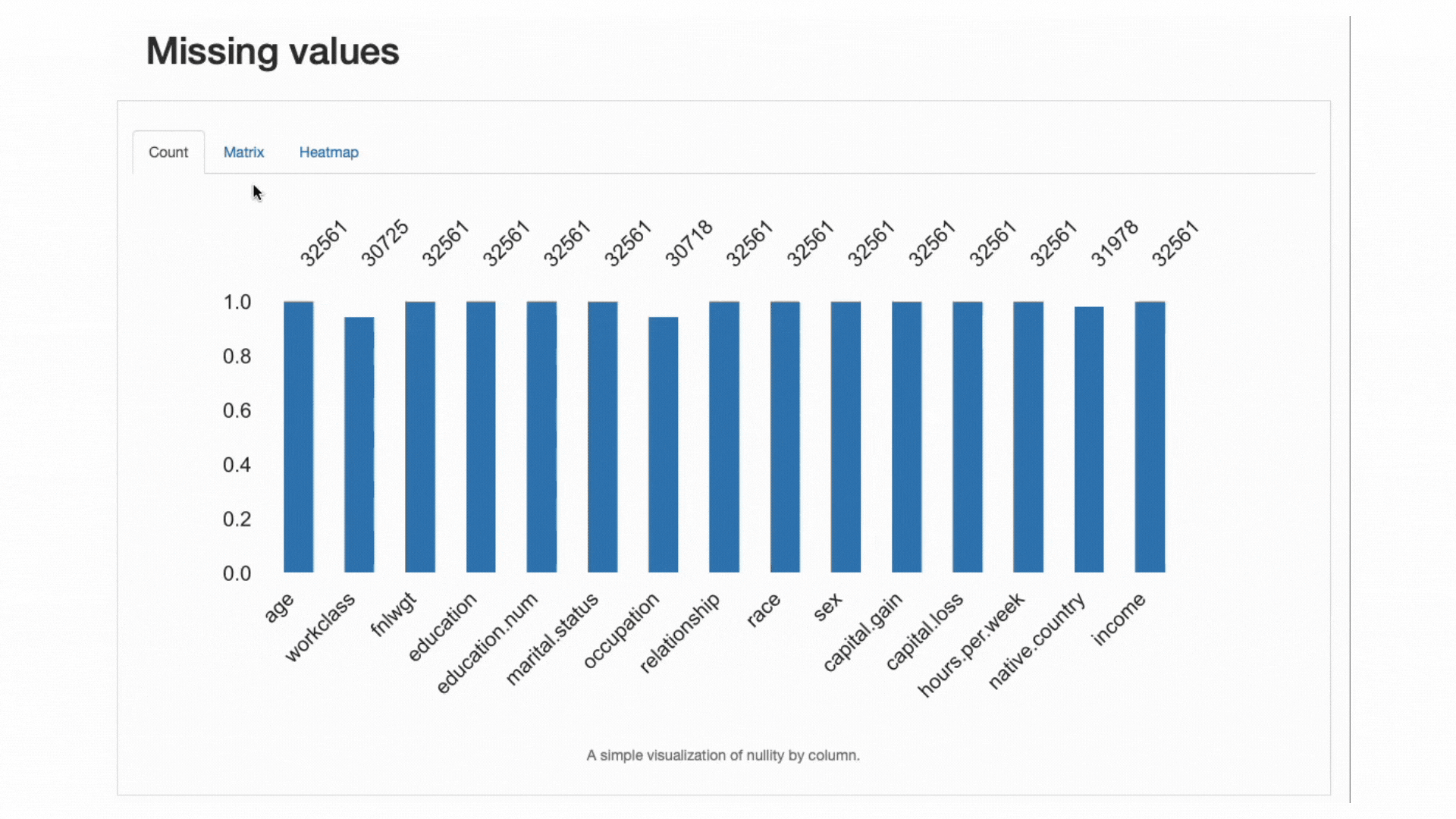
ydata-प्रोफ़ाइलिंग: प्रोफ़ाइलिंग रिपोर्ट - गुम मानों का विश्लेषण। लेखक द्वारा स्क्रीनकास्ट।
डेटा अलर्ट अनुभाग से, हमें यह पहले से ही पता था workclass, occupation, तथा native.country अनुपस्थित अवलोकन थे। हीटमैप हमें आगे बताता है कि गायब पैटर्न के साथ सीधा संबंध है in occupation और workclass: जब एक फीचर में कोई मान गायब है, तो दूसरे में भी कोई मान गायब होगा।
मुख्य अंतर्दृष्टि: डेटा प्रोफाइलिंग ईडीए से आगे जाती है!
अब तक, हम उन कार्यों पर चर्चा कर रहे हैं जो संपूर्ण ईडीए प्रक्रिया बनाते हैं और कैसे डेटा गुणवत्ता के मुद्दों और विशेषताओं का मूल्यांकन - एक प्रक्रिया जिसे हम डेटा प्रोफाइलिंग के रूप में संदर्भित कर सकते हैं - निश्चित रूप से एक सर्वोत्तम अभ्यास है।
फिर भी, यह स्पष्ट करना महत्वपूर्ण है डेटा प्रोफाइलिंग ईडीए से आगे चला जाता है. जबकि हम आम तौर पर ईडीए को किसी भी प्रकार की डेटा पाइपलाइन विकसित करने से पहले खोजपूर्ण, इंटरैक्टिव कदम के रूप में परिभाषित करते हैं, डेटा प्रोफाइलिंग एक पुनरावृत्तीय प्रक्रिया है हर कदम पर होना चाहिए डेटा प्रीप्रोसेसिंग और मॉडल बिल्डिंग का।
एक कुशल ईडीए एक सफल मशीन लर्निंग पाइपलाइन की नींव रखता है।
यह आपके डेटा पर एक डायग्नोसिस चलाने जैसा है, जिसमें आपको जो कुछ जानने की जरूरत है उसे सीखना - इसमें क्या शामिल है - यह गुण, रिश्तों, मुद्दों - ताकि आप बाद में उन्हें यथासंभव सर्वोत्तम तरीके से संबोधित कर सकें।
यह हमारे प्रेरणा चरण की शुरुआत भी है: यह ईडीए से है कि प्रश्न और परिकल्पनाएं उठने लगती हैं, और रास्ते में उन्हें मान्य या अस्वीकार करने के लिए विश्लेषण की योजना बनाई जाती है।
पूरे लेख में, हमने कवर किया है 3 मुख्य मूलभूत कदम जो आपको एक प्रभावी ईडीए के माध्यम से मार्गदर्शन करेंगे, और एक शीर्ष स्तरीय उपकरण के प्रभाव पर चर्चा की - ydata-profiling - हमें सही दिशा दिखाने के लिए, और हमारा भारी मात्रा में समय और मानसिक बोझ बचाएं।
मुझे आशा है कि यह मार्गदर्शिका आपको "डेटा जासूस खेलने" की कला में महारत हासिल करने में मदद करेगी और हमेशा की तरह, प्रतिक्रिया, प्रश्न और सुझावों की बहुत सराहना की जाती है। मुझे बताएं कि मैं किन अन्य विषयों पर लिखना चाहता हूं, या इससे भी बेहतर, यहां आकर मुझसे मिलें डेटा-केंद्रित एआई समुदाय और आइए सहयोग करें!
मिरियम सैंटोस डेटा साइंस और मशीन लर्निंग समुदायों को कच्चे, गंदे, "खराब" या अपूर्ण डेटा से स्मार्ट, बुद्धिमान, उच्च-गुणवत्ता वाले डेटा की ओर बढ़ने के बारे में शिक्षित करने पर ध्यान केंद्रित करें, जिससे मशीन लर्निंग क्लासिफायर कई उद्योगों (फिनटेक) में सटीक और विश्वसनीय निष्कर्ष निकालने में सक्षम हो सके। , हेल्थकेयर और फार्मा, टेलीकॉम और रिटेल)।
मूल। अनुमति के साथ पुनर्प्रकाशित।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- ईवीएम वित्त। विकेंद्रीकृत वित्त के लिए एकीकृत इंटरफ़ेस। यहां पहुंचें।
- क्वांटम मीडिया समूह। आईआर/पीआर प्रवर्धित। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 डेटा इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/06/data-scientist-essential-guide-exploratory-data-analysis.html?utm_source=rss&utm_medium=rss&utm_campaign=a-data-scientists-essential-guide-to-exploratory-data-analysis
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 1
- 30
- 40
- 60
- 65
- 91
- a
- क्षमता
- About
- ऊपर
- अनुपस्थित
- लेखा
- सही
- पाना
- के पार
- जोड़ा
- अतिरिक्त
- अतिरिक्त जानकारी
- पता
- जोड़ता है
- समायोजित
- वयस्क
- को प्रभावित
- फिर
- युग
- AI
- अलर्ट
- कलन विधि
- एल्गोरिदम
- सब
- साथ में
- पहले ही
- भी
- हालांकि
- कुल मिलाकर
- हमेशा
- am
- के बीच में
- बीच में
- राशि
- an
- विश्लेषण
- विश्लेषण करें
- विश्लेषण किया
- का विश्लेषण
- और
- कोई
- आवेदन
- हैं
- कला
- लेख
- AS
- आकलन
- मूल्यांकन
- जुड़े
- At
- भाग लेने के लिए
- लेखक
- स्वचालित
- स्वचालित
- उपलब्ध
- दूर
- बुरा
- बार
- BE
- किया गया
- से पहले
- शुरू
- जा रहा है
- मानना
- BEST
- सर्वोत्तम प्रथाओं
- बेहतर
- के बीच
- परे
- पूर्वाग्रह
- बिंग
- के छात्रों
- लाता है
- इमारत
- बनाया गया
- बोझ
- लेकिन
- by
- कॉल
- कर सकते हैं
- राजधानी
- सावधानी से
- ले जाना
- मामला
- श्रेणियाँ
- वर्ग
- जनगणना
- विशेषताएँ
- चेक
- जाँच
- कक्षा
- वर्गीकरण
- स्पष्ट
- कोड
- संग्रह
- रंग
- संयोजन
- कैसे
- सामान्य
- समुदाय
- पूरा
- जटिल
- व्यापक
- शामिल
- समझौता
- चिंताओं
- आचरण
- का आयोजन
- Consequences
- माना
- पर विचार
- लगातार
- सुविधा
- सह - संबंध
- सहसंबंध गुणांक
- सका
- महत्वपूर्ण
- महत्वपूर्ण
- तिथि
- डेटा विश्लेषण
- डेटा तैयारी
- आँकड़े की गुणवत्ता
- डेटा विज्ञान
- डेटासेट
- व्यवहार
- तय
- कमी
- गहरा
- चूक
- निश्चित रूप से
- निर्भरता
- निर्भर करता है
- यौगिक
- वर्णित
- विस्तार
- विस्तृत
- निर्धारित करना
- विकासशील
- विकास
- विचलन
- निदान
- विभिन्न
- प्रत्यक्ष
- दिशा
- सीधे
- चर्चा करना
- चर्चा की
- पर चर्चा
- डिस्प्ले
- वितरण
- do
- कर देता है
- डोमेन
- dont
- खींचना
- बूंद
- दौरान
- e
- से प्रत्येक
- आसान
- आसानी
- शिक्षित
- प्रभावी
- कुशल
- कुशलता
- भी
- समर्थकारी
- पूरी तरह से
- त्रुटियाँ
- विशेष रूप से
- सार
- आवश्यक
- ईथर (ईटीएच)
- और भी
- अंत में
- प्रत्येक
- सब कुछ
- जांच
- उदाहरण
- मौजूदा
- उम्मीद
- अनुभव
- विशेषज्ञता
- अन्वेषणात्मक डेटा विश्लेषण
- का पता लगाने
- अतिरिक्त
- अत्यंत
- आंख
- तथ्य
- परिचित
- दूर
- Feature
- विशेषताएं
- प्रतिक्रिया
- खोज
- फींटेच
- प्रथम
- फोकस
- निम्नलिखित
- के लिए
- सेना
- प्रारूप
- बुनियाद
- आवृत्ति
- से
- कार्यक्षमता
- मौलिक
- मूलरूप में
- आगे
- भविष्य
- लाभ
- सामान्य जानकारी
- आम तौर पर
- उत्पन्न करता है
- पीढ़ी
- मिल
- gif
- दी
- Go
- चला जाता है
- जा
- महान
- अनुमान लगाया
- गाइड
- था
- हाथ
- संभालना
- हाथ
- है
- होने
- स्वास्थ्य सेवा
- भारी
- मदद
- सहायक
- मदद करता है
- उच्च गुणवत्ता
- हाइलाइट
- अत्यधिक
- पकड़
- आशा
- घंटे
- कैसे
- How To
- तथापि
- HTTPS
- i
- आदर्श
- पहचान
- पहचान करना
- if
- की छवि
- तुरंत
- प्रभाव
- महत्वपूर्ण
- in
- शामिल
- आमदनी
- आवक
- बढ़ना
- व्यक्ति
- उद्योगों
- करें-
- जानकारीपूर्ण
- अन्तर्दृष्टि
- अंतर्दृष्टि
- प्रेरणा
- उदाहरण
- बुद्धिमान
- इरादा
- बातचीत
- बातचीत
- इंटरैक्टिव
- दिलचस्प
- में
- आंतरिक
- जांच
- जांच
- शामिल करना
- मुद्दा
- मुद्दों
- IT
- आईटी इस
- ख़तरे में डालना
- काम
- जेपीजी
- केवल
- केडनगेट्स
- केंडल
- जानना
- ज्ञान
- जानने वाला
- कुकुदता
- लेबल
- बाद में
- लेज
- बिक्रीसूत्र
- सीख रहा हूँ
- कम से कम
- बाएं
- कम
- लाइसेंस
- प्रकाश
- पसंद
- संभावित
- लाइन
- पंक्तियां
- लिंक्डइन
- थोड़ा
- देखिए
- देख
- निम्न
- मशीन
- यंत्र अधिगम
- मुख्य
- मुख्यतः
- बहुमत
- बनाना
- जोड़ - तोड़
- नक्शा
- मास्टर
- मैट्रिक्स
- मई..
- me
- मतलब
- साधन
- मापा
- मिलना
- मानसिक
- उल्लेख किया
- मेट्रिक्स
- हो सकता है
- मन
- लापता
- ML
- मोड
- आदर्श
- मॉडल
- निगरानी
- अधिक
- अधिकांश
- चाल
- बहुत
- नेविगेट करें
- आवश्यकता
- नहीं
- सामान्य रूप से
- सूचना..
- संख्या
- वस्तु
- स्पष्ट
- होते हैं
- of
- अक्सर
- on
- ONE
- केवल
- इष्टतम
- or
- आदेश
- अन्य
- अन्य
- हमारी
- आउट
- परिणाम
- उत्पादन
- कुल
- सिंहावलोकन
- जोड़ा
- पांडा
- विशेष
- अतीत
- पैटर्न
- पैटर्न उपयोग करें
- स्टाफ़
- प्रतिशतता
- निष्पादन
- प्रदर्शन
- प्रदर्शन
- शायद
- अनुमति
- व्यक्ति
- स्टाफ़
- फार्मा
- चरण
- चुनना
- पाइपलाइन
- की योजना बनाई
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- प्रशंसनीय
- बिन्दु
- हलका
- आबादी वाले
- संभव
- अभ्यास
- प्रथाओं
- भविष्यवाणियों
- मुख्य रूप से
- तैयारी
- प्रस्तुत
- प्रस्तुत
- पूर्वावलोकन
- पहले से
- छाप
- मुद्रण
- पूर्व
- मुसीबत
- प्रक्रिया
- प्रसंस्करण
- प्रोफाइल
- रूपरेखा
- परियोजना
- गुण
- सार्वजनिक
- उद्देश्य
- गुणवत्ता
- प्रश्न
- प्रशन
- दौड़
- रेंज
- मूल्यांकन करें
- बल्कि
- कच्चा
- असली दुनिया
- महसूस करना
- अभिलेख
- घटी
- प्रतिबिंब
- के बारे में
- सम्बंधित
- संबंध
- रिश्ते
- अपेक्षाकृत
- विश्वसनीय
- भरोसा करना
- शेष
- हटाने
- हटाना
- रिपोर्ट
- कोष
- प्रतिनिधित्व
- प्रतिनिधित्व
- की आवश्यकता होती है
- अपेक्षित
- कि
- क्रमश
- परिणाम
- खुदरा
- सही
- नियम
- दौड़ना
- वही
- अनुसूची
- विज्ञान
- क्षेत्र
- अनुभाग
- वर्गों
- देखना
- लगता है
- लगता है
- देखा
- संवेदनशील
- कई
- कठोरता से
- Share
- ख़रीदे
- कम
- चाहिए
- दिखाना
- महत्वपूर्ण
- सरल
- केवल
- एक साथ
- एक
- स्मार्ट
- So
- कुछ
- कुछ
- कुछ हद तक
- Spot
- ट्रेनिंग
- स्टैंड
- मानक
- खड़ा
- प्रारंभ
- शुरुआत में
- आँकड़े
- कदम
- कदम
- सरल
- रणनीतियों
- आगामी
- सफल
- ऐसा
- लेना
- लक्ष्य
- कार्य
- कार्य
- बताता है
- से
- कि
- RSI
- जानकारी
- लेकिन हाल ही
- उन
- वहाँ।
- इसलिये
- इन
- वे
- इसका
- बिलकुल
- विचार
- तीन
- यहाँ
- पहर
- सेवा मेरे
- साधन
- ऊपर का
- विषय
- की ओर
- पारंपरिक रूप से
- भयानक
- वास्तव में
- दो
- टाइप
- प्रकार
- प्रस्तुत किया हुआ
- समझ
- अद्वितीय
- अज्ञात
- जब तक
- आगामी
- us
- उपयोग
- का उपयोग करता है
- का उपयोग
- आमतौर पर
- सत्यापित करें
- मूल्य
- मान
- विभिन्न
- बनाम
- बहुत
- दृश्य
- करना चाहते हैं
- मार्ग..
- we
- सप्ताह
- भार
- कुंआ
- चला गया
- थे
- क्या
- कब
- या
- कौन कौन से
- पूरा का पूरा
- क्यों
- विकिपीडिया
- मर्जी
- साथ में
- बिना
- शब्द
- काम
- काम कर रहे
- कार्य
- होगा
- लिखना
- अभी तक
- इसलिए आप
- आपका
- जेफिरनेट
- ज़ूम






