In 2021 ainsi que 2020, nous vous avons parlé des nouvelles fonctionnalités de Redshift d'Amazon qui facilitent, accélèrent et rendent plus rentable l'analyse de toutes vos données et la recherche d'informations riches et puissantes. En 2022, nous sommes heureux d'annoncer que l'équipe Amazon Redshift était au travail. Nous avons travaillé à rebours des exigences des clients et annoncé plusieurs nouvelles fonctionnalités pour rendre l'analyse de toutes vos données plus facile, plus rapide et plus rentable. Cet article couvre certaines de ces nouvelles fonctionnalités.
Chez AWS, pour les données et l'analytique, notre stratégie est de vous offrir une architecture de données moderne qui vous aide à vous libérer des silos de données ; avoir des services de données, d'analyse, d'apprentissage automatique (ML) et d'intelligence artificielle spécialement conçus pour utiliser le bon outil pour le bon travail ; et disposent de services ouverts, gouvernés, sécurisés et entièrement gérés pour rendre l'analyse accessible à tous. Au sein de l'architecture de données moderne d'AWS, Amazon Redshift, en tant qu'entrepôt de données cloud, reste un élément clé, vous permettant d'exécuter des analyses SQL complexes à grande échelle et des performances sur des téraoctets à des pétaoctets de données structurées et non structurées, et de rendre les informations largement disponibles grâce à l'informatique décisionnelle populaire ( BI) et des outils d'analyse. Nous continuons à travailler en amont des exigences des clients et, en 2022, nous avons lancé plus de 40 fonctionnalités dans Amazon Redshift pour aider les clients dans leurs principaux cas d'utilisation d'entreposage de données, notamment :
- Analyse en libre-service
- Ingestion facile des données
- Partage de données et collaboration
- Science des données et apprentissage automatique
- Analyses sécurisées et fiables
- Meilleures analyses de performance des prix
Approfondissons et discutons des nouvelles fonctionnalités d'Amazon Redshift dans ces domaines.
Analyse en libre-service
Les clients continuent de nous dire que les données et les analyses deviennent omniprésentes et que tout le monde dans leur organisation a besoin d'analyses. Nous avons annoncé Amazon Redshift sans serveur (en avant-première) en 2021 pour faciliter l'exécution et la mise à l'échelle des analyses en quelques secondes sans avoir à provisionner et à gérer l'infrastructure d'entrepôt de données. En juillet 2022, nous avons annoncé la disponibilité générale de Redshift Serverless, et depuis lors, des milliers de clients, dont Peloton, Broadridge Financials et NextGen Healthcare, l'ont utilisé pour analyser rapidement et facilement leurs données. Amazon Redshift Serverless alloue automatiquement et adapte intelligemment la capacité de l'entrepôt de données pour fournir des performances élevées pour toutes vos analyses, et vous ne payez que le calcul utilisé pour la durée des charges de travail sur une base par seconde. Depuis GA, nous avons ajouté des fonctionnalités telles que balisage des ressources, une surveillance simplifiée et une disponibilité dans des régions AWS supplémentaires pour simplifier davantage la facturation et étendre la portée à d'autres régions du monde.
En 2021, nous avons lancé Amazon Redshift Query Editor V2, un outil Web gratuit permettant aux analystes de données, aux data scientists et aux développeurs d'explorer, d'analyser et de collaborer sur les données des entrepôts de données et des lacs de données Amazon Redshift. En 2022, Query Editor V2 a reçu des améliorations supplémentaires telles que prise en charge des ordinateurs portables pour une meilleure collaboration pour créer, organiser et annoter les requêtes ; accès utilisateur via informations d'identification du fournisseur d'identité (IdP) pour l'authentification unique ; et la possibilité d'exécuter plusieurs requêtes simultanément pour améliorer la productivité des développeurs.
L'autonomie est un autre domaine dans lequel nous travaillons activement pour utiliser des optimisations basées sur le ML et offrir aux clients un entrepôt de données auto-apprenant et auto-optimisant. En 2022, nous avons annoncé la disponibilité générale de Vues matérialisées automatisées (AutoMV) pour améliorer les performances des requêtes (réduire le temps d'exécution total) sans aucun effort de l'utilisateur en créant et en maintenant automatiquement des vues matérialisées. Les AutoMV, combinés à l'actualisation automatique, à l'actualisation incrémentielle et à la réécriture automatique des requêtes pour les vues matérialisées, ont rendu les vues matérialisées sans maintenance, vous offrant automatiquement des performances plus rapides. De plus, le optimisation automatique des tables (ATO) pour l'optimisation des schémas et gestion automatique de la charge de travail (auto WLM) pour l'optimisation de la charge de travail a obtenu d'autres améliorations pour de meilleures performances de requête.
Ingestion facile des données
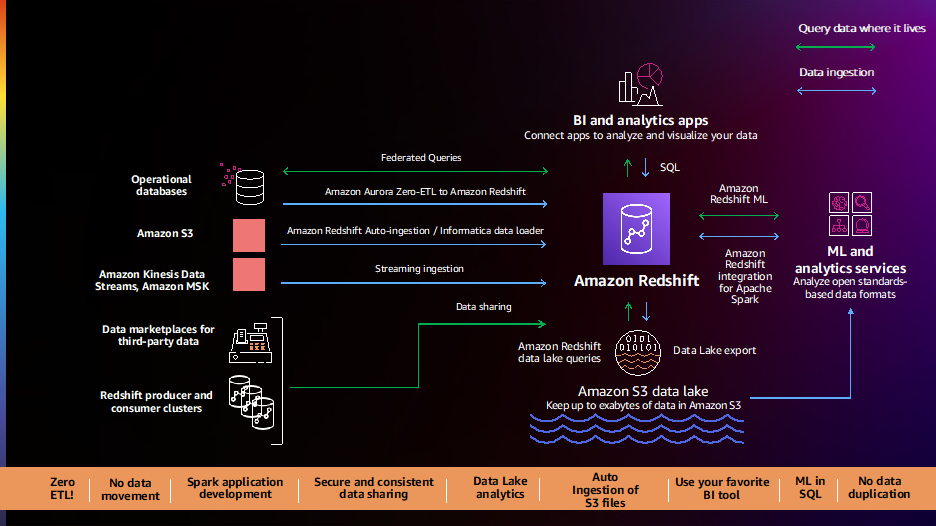
Les clients nous disent que leurs données sont réparties sur plusieurs sources de données telles que des bases de données transactionnelles, des entrepôts de données, des lacs de données et des systèmes de mégadonnées. Ils veulent avoir la flexibilité d'intégrer ces données avec des pipelines de données sans code/faible code, sans ETL ou d'analyser ces données sur place sans les déplacer. Les clients nous disent que leurs pipelines de données actuels sont complexes, manuels, rigides et lents, ce qui se traduit par des vues de données incomplètes, incohérentes et obsolètes, ce qui limite les informations. Les clients nous ont demandé une meilleure voie à suivre et nous sommes heureux d'annoncer un certain nombre de nouvelles fonctionnalités pour simplifier et automatiser les pipelines de données.
Intégration Amazon Aurora sans ETL avec Amazon Redshift (préversion) vous permet d'exécuter des analyses et du ML en temps quasi réel sur des pétaoctets de données transactionnelles. Il offre une solution sans code pour créer des données transactionnelles à partir de plusieurs Amazon Aurora bases de données disponibles dans les entrepôts de données Amazon Redshift quelques secondes après leur écriture sur Aurora, éliminant ainsi le besoin de créer et de maintenir des pipelines de données complexes. Grâce à cette fonctionnalité, les clients Aurora peuvent également accéder aux fonctionnalités d'Amazon Redshift telles que l'analyse SQL complexe, le ML intégré, le partage de données et l'accès fédéré à plusieurs magasins de données et lacs de données. Cette fonctionnalité est désormais disponible en avant-première pour Édition compatible Amazon Aurora MySQL version 3 (avec compatibilité MySQL 8.0), et vous pouvez demander l'accès à l'aperçu.
Amazon Redshift prend désormais en charge copie automatique depuis Amazon S3 (aperçu) pour simplifier le chargement des données depuis Service de stockage simple Amazon (Amazon S3) dans Amazon Redshift. Vous pouvez désormais configurer des règles d'ingestion de fichiers en continu (tâches de copie) pour suivre vos chemins Amazon S3 et charger automatiquement de nouveaux fichiers sans avoir besoin d'outils supplémentaires ou de solutions personnalisées. Les travaux de copie peuvent être surveillés via des tables système, et ils gardent automatiquement une trace des fichiers précédemment chargés et les excluent du processus d'ingestion pour éviter la duplication des données. Cette fonctionnalité est désormais disponible en avant-première ; vous pouvez essayer cette fonctionnalité en créant un nouveau cluster à l'aide de la piste de prévisualisation.
Les clients continuent de nous dire qu'ils ont besoin d'analyses instantanées, instantanées et en temps réel, et nous sommes heureux d'annoncer la disponibilité générale de la prise en charge de l'ingestion de flux dans Amazon Redshift pour Flux de données Amazon Kinesis ainsi que Amazon Managed Streaming pour Apache Kafka (AmazonMSK). Cette fonctionnalité élimine le besoin d'organiser les données de streaming dans Amazon S3 avant de les ingérer dans Amazon Redshift, ce qui vous permet d'obtenir une faible latence, mesurée en secondes, tout en ingérant des centaines de mégaoctets de données de streaming par seconde dans vos entrepôts de données. Vous pouvez utiliser SQL dans Amazon Redshift pour vous connecter et ingérer directement des données à partir de plusieurs flux de données Kinesis ou rubriques MSK, créer des vues matérialisées de flux à actualisation automatique avec des transformations au-dessus des flux directement pour accéder aux données de flux et combiner des données en temps réel avec des données historiques. données pour une meilleure compréhension. Par exemple, Adobe a intégré l'ingestion de streaming Amazon Redshift dans le cadre de sa plate-forme d'expérience Adobe pour ingérer et analyser, en temps réel, les flux de clics et les données de session du Web et des applications pour diverses applications telles que les applications CRM et d'assistance client.
Les clients nous ont dit qu'ils souhaitaient une intégration simple et prête à l'emploi entre Amazon Redshift, les outils de BI et ETL (extraction, transformation et chargement) et des applications métier telles que Salesforce et Marketo. Nous avons le plaisir de vous annoncer la disponibilité générale de Chargeur de données Informatica pour Amazon Redshift, qui vous permet d'utiliser gratuitement Informatica Data Loader pour le chargement de données à grande vitesse et en grand volume dans Amazon Redshift. Vous pouvez simplement sélectionner l'option Informatica Data Loader sur la console Amazon Redshift. Une fois dans Informatica Data Loader, vous pouvez vous connecter à des sources telles que Salesforce ou Marketo, choisir Amazon Redshift comme cible et commencer à charger vos données.
Partage de données et collaboration
Les clients continuent de nous dire qu'ils souhaitent analyser toutes leurs données propriétaires et tierces et mettre à la disposition de leurs clients, partenaires et fournisseurs les riches informations basées sur les données. Nous avons lancé de nouvelles fonctionnalités en 2021, telles que Partage de données ainsi que Intégration AWS Data Exchange, pour vous faciliter l'analyse de toutes vos données et les partager au sein et à l'extérieur de vos organisations.
Orion est un excellent exemple de client utilisant le partage de données. Orion fournit des solutions de données en temps réel en tant que service (DaaS) aux clients du secteur des services financiers, tels que les fournisseurs de gestion de patrimoine, de gestion d'actifs et de gestion d'investissements. Ils disposent de plus de 2,500 XNUMX sources de données qui sont principalement des bases de données SQL Server hébergées à la fois sur site et dans AWS. Les données sont diffusées à l'aide de connecteurs Kafka dans Amazon Redshift. Ils ont un cluster producteur qui reçoit toutes ces données et utilise ensuite le partage de données pour partager des données en temps réel pour la collaboration. Il s'agit d'une architecture multi-tenant qui sert plusieurs clients. Compte tenu de la sensibilité de leurs données, le partage de données est un moyen d'isoler la charge de travail entre les clusters et de partager ces données en toute sécurité avec les utilisateurs finaux.
En 2022, nous avons continué à investir dans ce domaine pour améliorer les performances, la gouvernance et la productivité des développeurs avec de nouvelles fonctionnalités pour faciliter, simplifier et accélérer le partage et la collaboration sur les données.
Alors que les clients créent des configurations de partage de données à grande échelle, ils ont demandé une gouvernance et une sécurité simplifiées pour les données partagées, et nous ajoutons contrôle d'accès centralisé avec AWS Lake Formation pour les partages de données Amazon Redshift afin de permettre le partage de données en direct sur plusieurs entrepôts de données Amazon Redshift. Avec cette fonctionnalité, Amazon Redshift prend désormais en charge la gouvernance simplifiée des partages de données Amazon Redshift en utilisant Formation AWS Lake comme une seule fenêtre pour gérer de manière centralisée les données ou les autorisations sur les partages de données. Vous pouvez afficher, modifier et auditer les autorisations, y compris la sécurité au niveau des lignes et des colonnes sur les tables et les vues dans les partages de données Amazon Redshift, à l'aide des API Lake Formation et du Console de gestion AWS, et permettre aux partages de données Amazon Redshift d'être découverts et consommés par d'autres entrepôts de données Amazon Redshift.
Science des données et apprentissage automatique
Les clients continuent de nous dire qu'ils veulent que leurs systèmes de données et d'analyse les aident à répondre à un large éventail de questions, de ce qui se passe dans leur entreprise (analyse descriptive) à pourquoi cela se produit (analyse diagnostique) et ce qui se passera dans le futur. (analyses prédictives). Amazon Redshift fournit des fonctionnalités telles que l'analyse SQL complexe, l'analyse des lacs de données et Amazon Redshift ML pour les clients d'analyser leurs données et de découvrir des informations puissantes. Décalage vers le rouge ML intègre Amazon Redshift avec Amazon Sage Maker, un service de ML entièrement géré, vous permettant de créer, d'entraîner et de déployer des modèles de ML à l'aide de commandes SQL familières.
Les clients nous ont également demandé une meilleure intégration entre Amazon Redshift et Apache Spark, nous sommes donc ravis d'annoncer Intégration Amazon Redshift pour Apache Spark pour rendre les entrepôts de données facilement accessibles pour les applications basées sur Spark. Désormais, les développeurs utilisant AWS Analytics et les services ML tels que Amazon DME, Colle AWS, et SageMaker peut créer sans effort des applications Apache Spark qui lisent et écrivent dans leurs entrepôts de données Amazon Redshift. Amazon EMR et AWS Glue regroupent le connecteur Redshift-Spark afin que vous puissiez facilement vous connecter à votre entrepôt de données à partir de vos applications basées sur Spark. Vous pouvez utiliser plusieurs fonctionnalités de refoulement pour des opérations telles que les fonctions de tri, d'agrégation, de limitation, de jointure et scalaire afin que seules les données pertinentes soient déplacées de votre entrepôt de données Amazon Redshift vers l'application Spark consommatrice. Vous pouvez également rendre vos applications plus sécurisées en utilisant Gestion des identités et des accès AWS (IAM) des informations d'identification pour se connecter à Amazon Redshift.
Analyses sécurisées et fiables
Les clients continuent de nous dire que leurs entrepôts de données sont des systèmes critiques qui nécessitent une disponibilité, une fiabilité et une sécurité élevées. Nous avons lancé un certain nombre de nouvelles fonctionnalités en 2022 dans ce domaine.
Amazon Redshift prend désormais en charge Déploiements multi-AZ (en préversion) pour les clusters basés sur des instances RA3, ce qui permet d'exécuter votre entrepôt de données dans plusieurs zones de disponibilité AWS simultanément et de fonctionner en continu dans des scénarios de défaillance imprévus à l'échelle de la zone de disponibilité. La prise en charge multi-AZ est déjà disponible pour Redshift Serverless. Un déploiement Amazon Redshift Multi-AZ vous permet de récupérer en cas de défaillance de la zone de disponibilité sans aucune intervention de l'utilisateur. Un entrepôt de données Amazon Redshift Multi-AZ est accessible en tant qu'entrepôt de données unique avec un point de terminaison et vous aide à optimiser les performances en répartissant automatiquement le traitement de la charge de travail sur plusieurs zones de disponibilité. Aucune modification de l'application n'est nécessaire pour maintenir la continuité des activités pendant les pannes imprévues.
En 2022, nous avons lancé des fonctionnalités telles que le contrôle d'accès basé sur les rôles, la sécurité au niveau des lignes et le masquage des données (en préversion) pour vous permettre de gérer plus facilement l'accès et de décider qui a accès à quelles données, y compris la dissimulation des informations personnellement identifiables (PII ) comme les numéros de carte de crédit.
Vous pouvez utiliser contrôle d'accès basé sur les rôles (RBAC) pour contrôler l'accès de l'utilisateur final aux données à un niveau large ou granulaire en fonction du rôle et des autorisations de l'utilisateur final. Avec RBAC, vous pouvez créer un rôle à l'aide de SQL, accorder un ensemble d'autorisations granulaires au rôle, puis attribuer ce rôle aux utilisateurs finaux. Les rôles peuvent se voir accorder des autorisations au niveau de l'objet, de la colonne et du système. En outre, RBAC introduit des rôles système prêts à l'emploi pour les administrateurs de base de données, les opérateurs, les administrateurs de sécurité ou des rôles personnalisés.
Sécurité au niveau des lignes (RLS) simplifie la conception et la mise en œuvre d'un accès précis aux lignes des tables. Avec RLS, vous pouvez restreindre l'accès à un sous-ensemble de lignes dans une table en fonction du rôle de travail des utilisateurs ou des autorisations avec SQL.
Prise en charge d'Amazon Redshift pour masquage dynamique des données (DDM), désormais disponible en version préliminaire, vous permet de simplifier la protection des informations personnelles telles que les numéros de sécurité sociale, les numéros de carte de crédit et les numéros de téléphone dans votre entrepôt de données Amazon Redshift. Avec le masquage dynamique des données, vous contrôlez l'accès à vos données via de simples politiques de masquage basées sur SQL qui déterminent comment Amazon Redshift renvoie les données sensibles à l'utilisateur au moment de la requête. Vous pouvez créer des politiques de masquage pour définir des valeurs de données masquées cohérentes, préservant le format et irréversibles. Vous pouvez appliquer une politique de masquage sur une colonne spécifique ou une liste de colonnes dans une table. De plus, vous avez la possibilité de choisir comment afficher les données masquées. Par exemple, vous pouvez masquer complètement les données, remplacer des valeurs réelles partielles par des caractères génériques ou définir votre propre façon de masquer les données à l'aide d'expressions SQL, Python ou AWS Lambda fonctions définies par l'utilisateur. En outre, vous pouvez appliquer une stratégie de masquage conditionnel basée sur d'autres colonnes, qui protège de manière sélective les données de colonne dans une table en fonction des valeurs d'une ou plusieurs colonnes différentes.
Nous avons également annoncé des améliorations à journalisation des audits, intégration native avec Annuaire actif Microsoft Azureet soutien à rôles IAM par défaut dans des régions supplémentaires pour simplifier davantage la gestion de la sécurité.
Meilleures analyses de performance des prix
Les clients continuent de nous dire qu'ils ont besoin d'entrepôts de données rapides et rentables qui offrent des performances élevées à n'importe quelle échelle tout en maintenant des coûts bas. Depuis le jour 1 depuis Lancement d'Amazon Redshift en 2012, nous avons adopté une approche basée sur les données et utilisé la télémétrie de la flotte pour créer un service d'entrepôt de données cloud qui vous offre les meilleures performances de prix à n'importe quelle échelle. Au fil des années, nous avons évolué L'architecture d'Amazon Redshift et lancé des fonctionnalités telles que Stockage géré par Redshift (RMS) pour la séparation du stockage et du calcul, Spectre Amazon Redshift pour les requêtes de lac de données, optimisation automatique des tables pour l'optimisation du schéma physique, gestion automatique de la charge de travail pour hiérarchiser les charges de travail et allouer le bon calcul et la bonne mémoire, redimensionner le cluster pour faire évoluer le calcul et le stockage verticalement, et mise à l'échelle de la simultanéité pour faire évoluer dynamiquement le calcul vers l'extérieur ou vers l'intérieur. Notre repères de performance continuer à démontrer le leadership d'Amazon Redshift en matière de prix et de performances.
En 2022, nous avons ajouté de nouvelles fonctionnalités telles que la disponibilité générale de mise à l'échelle de la concurrence pour les opérations d'écriture comme COPY, INSERT, UPDATE et DELETE pour prendre en charge des utilisateurs et des requêtes simultanés pratiquement illimités. Nous avons également introduit des améliorations de performances pour le traitement des données basé sur des chaînes grâce à des analyses vectorielles sur des colonnes de chaînes légères, économes en CPU et codées par dictionnaire, ce qui permet au moteur de base de données de fonctionner directement sur des données compressées.
Nous avons également ajouté la prise en charge des opérateurs SQL tels que FUSIONNER (opérateur unique pour les insertions ou mises à jour) ; CONNECY_BY (pour les requêtes hiérarchiques) ; ENSEMBLES DE GROUPEMENT, ROLLUP et CUBE (pour les rapports multidimensionnels) ; et augmenté la taille du type de données SUPER à 16 Mo pour faciliter la migration des entrepôts de données hérités vers Amazon Redshift.
Conclusion
Nos clients continuent de nous dire que les données et l'analyse restent une priorité absolue pour eux et que la nécessité d'extraire de manière rentable plus de valeur commerciale de leurs données pendant ces périodes est plus prononcée qu'à tout autre moment dans le passé. Amazon Redshift, en tant qu'entrepôt de données cloud, vous permet d'exécuter des analyses SQL complexes avec une échelle et des performances sur des téraoctets à des pétaoctets de données structurées et non structurées et de rendre les informations largement disponibles via des outils de BI et d'analyse populaires.
Bien que nous ayons lancé plus de 40 fonctionnalités en 2022 et que le rythme de l'innovation continue de s'accélérer, il reste le jour 1 et nous attendons avec impatience de vous entendre sur la façon dont ces fonctionnalités vous aident à libérer plus de valeur pour vos organisations. Nous vous invitons à essayer ces nouvelles fonctionnalités et à nous contacter via votre équipe de compte AWS si vous avez d'autres commentaires.
A propos de l'auteure
 Manan Goël est un leader de la mise sur le marché des produits pour les services d'analyse AWS, y compris Amazon Redshift chez AWS. Il a plus de 25 ans d'expérience et connaît bien les bases de données, l'entreposage de données, l'informatique décisionnelle et l'analyse. Manan est titulaire d'un MBA de l'Université Duke et d'un BS en génie électronique et des communications.
Manan Goël est un leader de la mise sur le marché des produits pour les services d'analyse AWS, y compris Amazon Redshift chez AWS. Il a plus de 25 ans d'expérience et connaît bien les bases de données, l'entreposage de données, l'informatique décisionnelle et l'analyse. Manan est titulaire d'un MBA de l'Université Duke et d'un BS en génie électronique et des communications.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- capacité
- A Propos
- accélérer
- accès
- Accès aux données
- accédé
- accessible
- Compte
- atteindre
- à travers
- infection
- activement
- ajoutée
- ajout
- Supplémentaire
- En outre
- Adobe
- Tous
- permet
- déjà
- Amazon
- Amazon DME
- Analystes
- analytique
- il analyse
- l'analyse
- ainsi que
- Annoncer
- annoncé
- Une autre
- répondre
- Apache
- Apache Spark
- Apis
- Application
- applications
- Appliquer
- une approche
- architecture
- Réservé
- domaines
- artificiel
- intelligence artificielle
- atout
- la gestion d'actifs
- audit
- Aurora
- auteur
- auto
- automatiser
- Automatique
- automatiquement
- disponibilité
- disponibles
- AWS
- Colle AWS
- Azure
- basé
- base
- devenir
- before
- va
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Big
- Big Data
- facturation
- Pause
- vaste
- Broadridge
- construire
- Développement
- intégré
- la performance des entreprises
- applications commerciales
- continuité de l'activité
- l'intelligence d'entreprise
- capacités
- Compétences
- carte
- maisons
- cas
- Modifications
- caractères
- Selectionnez
- choose
- CLIENTS
- le cloud
- Grappe
- collaborons
- collaboration
- collection
- Colonne
- Colonnes
- combiner
- combiné
- commentaires
- Communications
- compatibilité
- complètement
- complexe
- composant
- calcul
- concurrent
- NOUS CONTACTER
- cohérent
- Console
- consommées
- continuer
- a continué
- continue
- continu
- des bactéries
- rentable
- Costs
- couvre
- engendrent
- La création
- Lettres de créance
- crédit
- carte de crédit
- Crédits
- CRM
- Courant
- Customiser
- des clients
- Support à la clientèle
- Clients
- sont adaptées
- données
- D'échange de données
- Lac de données
- informatique
- partage de données
- entrepôt de données
- entrepôts de données
- data-driven
- Base de données
- bases de données
- journée
- profond
- livrer
- démontrer
- déployer
- déploiement
- Conception
- Déterminer
- Développeur
- mobiles
- différent
- directement
- découvrez
- découvert
- discuter
- distribué
- distribuer
- Duc
- université de Duke
- pendant
- Dynamic
- plus facilement
- même
- éditeur
- effort
- Electronique
- élimine
- l'élimination
- permettre
- permet
- permettant
- Endpoint
- Moteur
- ENGINEERING
- Ether (ETH)
- tout le monde
- évolué
- exemple
- échange
- excité
- Développer vous
- d'experience
- explorez
- expressions
- extrait
- Échec
- familier
- RAPIDE
- plus rapide
- Fonctionnalité
- Fonctionnalités:
- Déposez votre dernière attestation
- Fichiers
- la traduction de documents financiers
- services financiers
- financières
- Trouvez
- FLOTTE
- Flexibilité
- formation
- Avant
- gratuitement ici
- De
- d’étiquettes électroniques entièrement
- fonctions
- plus
- avenir
- Général
- obtenez
- gif
- Donner
- donné
- donne
- Don
- en verre.
- Aller au marché
- gouvernance
- subvention
- accordée
- l'
- arriver
- heureux vous
- Dur
- ayant
- la médecine
- entendre
- vous aider
- aide
- Cacher
- Haute
- historique
- détient
- Comment
- How To
- HTML
- HTTPS
- Des centaines
- IAM
- Identite
- la mise en oeuvre
- améliorer
- amélioré
- améliorations
- in
- Y compris
- increased
- industrie
- d'information
- Infrastructure
- Innovation
- Inserts
- idées.
- intégrer
- des services
- Intègre
- l'intégration
- Intelligence
- intervention
- introduit
- Introduit
- Investir
- un investissement
- nous invitons les riders XCO et DH à rouler sur nos pistes haute performance, et leurs supporters à profiter du spectacle. Pour le XNUMXe anniversaire, nous visons GRAND ! Vous allez vouloir être là ! Nous accueillerons la légendaire traversée de l'étant avec de la musique en direct ! Nous aurons également des divertissements pour les jeunes et les jeunes de cœur pendant l'après-midi. Vous ne voudrez pas manquer ça !
- seul
- IT
- Emploi
- Emplois
- rejoindre
- Juillet
- kafka
- XNUMX éléments à
- en gardant
- ACTIVITES
- Flux de données Kinesis
- lac
- grande échelle
- Latence
- lancer
- lancé
- leader
- Leadership
- apprentissage
- Legacy
- Niveau
- léger
- LIMIT
- Liste
- le travail
- données en direct
- charge
- chargeur
- chargement
- Style
- Faible
- click
- machine learning
- LES PLANTES
- maintenir
- facile
- a prendre une
- Fabrication
- gérer
- gérés
- gestion
- Manuel
- Marketo
- masque
- Maximisez
- Mémoire
- émigrer
- ML
- numériques jumeaux (digital twin models)
- Villas Modernes
- modifier
- surveillé
- Stack monitoring
- PLUS
- en mouvement
- plusieurs
- MySQL
- indigène
- Besoin
- nécessaire
- Besoins
- Nouveauté
- Nouvelles fonctionnalités
- nombre
- numéros
- Offres Speciales
- ONE
- ouvert
- fonctionner
- opération
- Opérations
- opérateur
- opérateurs
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Option
- organisation
- organisations
- Autre
- Les pannes
- au contrôle
- propre
- Rythme
- paquet
- pain
- partie
- partenaires,
- passé
- Payer
- peloton
- performant
- autorisations
- Personnellement
- Téléphone
- Physique
- pii
- Place
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- heureux
- politiques
- politique
- Populaire
- Post
- solide
- Analyses prédictives
- empêcher
- Aperçu
- précédemment
- prix
- qui se déroulent
- Prioriser
- priorité
- processus
- traitement
- producteur
- Produit
- productivité
- L'utilisation de sélénite dans un espace est un excellent moyen de neutraliser l'énergie instable ou négative.
- fournir
- de voiture.
- fournisseurs
- fournit
- disposition
- Python
- fréquemment posées
- vite.
- gamme
- nous joindre
- Lire
- réal
- en temps réel
- données en temps réel à grande vitesse.
- reçoit
- Récupérer
- réduire
- régions
- pertinent
- fiabilité
- fiable
- reste
- remplacer
- rapport
- Rapports
- Exigences
- restreindre
- résultant
- Retours
- Avis
- réécriture
- Rich
- rigide
- Rôle
- rôle
- Cumulatif
- Courir
- pour le running
- sagemaker
- force de vente
- Escaliers intérieurs
- Balance
- mise à l'échelle
- scénarios
- Sciences
- scientifiques
- Deuxièmement
- secondes
- sécurisé
- en toute sécurité
- sécurité
- sensible
- Sensibilité
- Sans serveur
- sert
- service
- Services
- Session
- set
- Sets
- plusieurs
- Partager
- commun
- partage
- montrer
- étapes
- simplifié
- simplifier
- simplement
- simultanément
- depuis
- unique
- Séance
- Taille
- lent
- So
- Réseaux sociaux
- sur mesure
- Solutions
- quelques
- Sources
- Spark
- groupe de neurones
- SQL
- Étape
- storage
- STORES
- de Marketing
- streaming
- streaming
- flux
- structuré
- données structurées et non structurées
- tel
- Super
- fournisseurs
- Support
- Les soutiens
- combustion propre
- Système
- table
- Target
- équipe
- La
- El futuro
- leur
- des tiers.
- milliers
- Avec
- fiable
- fois
- à
- outil
- les outils
- top
- Les sujets
- Total
- -nous
- suivre
- Train
- transactionnel
- Transformer
- transformations
- omniprésent
- imprévu
- université
- illimité
- ouvrir
- Mises à jour
- Actualités
- us
- utilisé
- Utilisateur
- utilisateurs
- Utilisant
- Plus-value
- Valeurs
- divers
- version
- Voir
- vues
- pratiquement
- Entrepots
- Entreposage
- Richesse
- gestion de patrimoine
- web
- Basé sur le Web
- Quoi
- Qu’est ce qu'
- qui
- tout en
- WHO
- large
- Large gamme
- largement
- sera
- dans les
- sans
- activités principales
- travaillé
- de travail
- partout dans le monde
- écrire
- code écrit
- an
- années
- Votre
- zéphyrnet
- zones