Les données géospatiales sont des données sur des emplacements spécifiques à la surface de la Terre. Il peut représenter une zone géographique dans son ensemble ou représenter un événement associé à une zone géographique. L’analyse des données géospatiales est recherchée dans quelques secteurs. Cela implique de comprendre où les données existent d’un point de vue spatial et pourquoi elles y existent.
Il existe deux types de données géospatiales : les données vectorielles et les données raster. Les données raster sont une matrice de cellules représentées sous forme de grille, représentant principalement des photographies et des images satellite. Dans cet article, nous nous concentrons sur les données vectorielles, qui sont représentées sous forme de coordonnées géographiques de latitude et de longitude, ainsi que de lignes et de polygones (zones) les reliant ou les englobant. Les données vectorielles ont une multitude de cas d'utilisation pour obtenir des informations sur la mobilité. Les données mobiles des utilisateurs en sont l'un de ces composants, et elles proviennent principalement de la position géographique des appareils mobiles utilisant le GPS ou des éditeurs d'applications utilisant des SDK ou des intégrations similaires. Aux fins de cet article, nous appelons ces données données de mobilité.
Il s'agit d'une série en deux parties. Dans ce premier article, nous présentons les données de mobilité, leurs sources et un schéma type de ces données. Nous discutons ensuite des différents cas d'utilisation et explorons comment vous pouvez utiliser les services AWS pour nettoyer les données, comment l'apprentissage automatique (ML) peut vous aider dans cet effort et comment vous pouvez utiliser les données de manière éthique pour générer des visuels et des informations. Le deuxième article sera de nature plus technique et couvrira ces étapes en détail avec un exemple de code. Cet article ne contient pas d'exemple d'ensemble de données ni d'exemple de code, mais explique plutôt comment utiliser les données après leur achat auprès d'un agrégateur de données.
Vous pouvez utiliser Fonctionnalités géospatiales d'Amazon SageMaker pour superposer les données de mobilité sur une carte de base et fournir une visualisation en couches pour faciliter la collaboration. Le visualiseur interactif alimenté par GPU et les blocs-notes Python offrent un moyen transparent d'explorer des millions de points de données dans une seule fenêtre et de partager des informations et des résultats.
Sources et schéma
Il existe peu de sources de données sur la mobilité. Outre les pings GPS et les éditeurs d'applications, d'autres sources sont utilisées pour augmenter l'ensemble de données, telles que les points d'accès Wi-Fi, les données de flux d'enchères obtenues via la diffusion d'annonces sur les appareils mobiles et les émetteurs matériels spécifiques placés par les entreprises (par exemple, dans les magasins physiques). ). Il est souvent difficile pour les entreprises de collecter elles-mêmes ces données, elles peuvent donc les acheter auprès d’agrégateurs de données. Les agrégateurs de données collectent des données de mobilité provenant de diverses sources, les nettoient, ajoutent du bruit et rendent les données disponibles quotidiennement pour des régions géographiques spécifiques. En raison de la nature des données elles-mêmes et parce qu'elles sont difficiles à obtenir, l'exactitude et la qualité de ces données peuvent varier considérablement, et il appartient aux entreprises de les évaluer et de les vérifier en utilisant des mesures telles que les utilisateurs actifs quotidiens, le nombre total de pings quotidiens, et les pings quotidiens moyens par appareil. Le tableau suivant montre à quoi peut ressembler un schéma typique d'un flux de données quotidien envoyé par des agrégateurs de données.
| Attribut | Description |
| Identifiant ou MAID | ID de publicité mobile (MAID) de l'appareil (haché) |
| lat | Latitude de l'appareil |
| lng | Longitude de l'appareil |
| géohachage | Emplacement Geohash de l'appareil |
| type d'appareil | Système d'exploitation de l'appareil = IDFA ou GAID |
| précision_horizontale | Précision des coordonnées GPS horizontales (en mètres) |
| horodatage | Horodatage de l'événement |
| ip | adresse IP |
| alt | Altitude de l'appareil (en mètres) |
| vitesse | Vitesse de l'appareil (en mètres/seconde) |
| Pays | Code ISO à deux chiffres pour le pays d'origine |
| Etat | Codes représentant l'état |
| ville | Codes représentant la ville |
| code postal | Code postal de l'endroit où l'ID de l'appareil est affiché |
| porteur | Transporteur de l'appareil |
| fabricant_de l'appareil | Fabricant de l'appareil |
Les cas d'utilisation
Les données de mobilité ont des applications répandues dans divers secteurs. Voici quelques-uns des cas d’utilisation les plus courants :
- Métriques de densité – L’analyse du trafic piétonnier peut être combinée à la densité de population pour observer les activités et les visites de points d’intérêt (POI). Ces mesures présentent une image du nombre d'appareils ou d'utilisateurs qui s'arrêtent activement et interagissent avec une entreprise, qui peut ensuite être utilisée pour la sélection de sites ou même pour analyser les schémas de mouvement autour d'un événement (par exemple, les personnes voyageant pour une journée de match). Pour obtenir de telles informations, les données brutes entrantes passent par un processus d'extraction, de transformation et de chargement (ETL) pour identifier les activités ou les engagements à partir du flux continu de pings de localisation des appareils. Nous pouvons analyser les activités en identifiant les arrêts effectués par l'utilisateur ou l'appareil mobile en regroupant les pings à l'aide de modèles ML dans Amazon Sage Maker.
- Voyages et trajectoires – Le flux de localisation quotidien d’un appareil peut être exprimé sous la forme d’un ensemble d’activités (arrêts) et de déplacements (mouvements). Une paire d'activités peut représenter un voyage entre elles, et tracer le voyage par le dispositif en mouvement dans l'espace géographique peut conduire à cartographier la trajectoire réelle. Les modèles de trajectoire des mouvements des utilisateurs peuvent conduire à des informations intéressantes telles que les modèles de trafic, la consommation de carburant, l'urbanisme, etc. Il peut également fournir des données pour analyser l'itinéraire emprunté à partir de points publicitaires tels qu'un panneau d'affichage, identifier les itinéraires de livraison les plus efficaces pour optimiser les opérations de la chaîne d'approvisionnement ou analyser les itinéraires d'évacuation en cas de catastrophe naturelle (par exemple, évacuation en cas d'ouragan).
- Analyse de la zone de chalandise - A zone de chalandise fait référence aux lieux d'où une zone donnée attire ses visiteurs, qui peuvent être des clients ou des clients potentiels. Les commerces de détail peuvent utiliser ces informations pour déterminer l’emplacement optimal pour ouvrir un nouveau magasin, ou déterminer si deux emplacements de magasins sont trop proches l’un de l’autre avec des zones de chalandise qui se chevauchent et nuisent mutuellement à leurs activités. Ils peuvent également découvrir d'où viennent les clients réels, identifier les clients potentiels qui passent par la zone pour se rendre au travail ou à la maison, analyser des mesures de visites similaires pour les concurrents, et bien plus encore. Les entreprises de Marketing Tech (MarTech) et de Advertisement Tech (AdTech) peuvent également utiliser cette analyse pour optimiser les campagnes marketing en identifiant l'audience proche du magasin d'une marque ou pour classer les magasins en fonction de leurs performances pour la publicité extérieure.
Il existe plusieurs autres cas d'utilisation, notamment la génération d'informations de localisation pour l'immobilier commercial, l'augmentation des données d'imagerie satellite avec des chiffres de fréquentation, l'identification des centres de livraison pour les restaurants, la détermination de la probabilité d'évacuation d'un quartier, la découverte des schémas de déplacement des personnes pendant une pandémie, et bien plus encore.
Défis et utilisation éthique
L’utilisation éthique des données de mobilité peut conduire à de nombreuses informations intéressantes qui peuvent aider les organisations à améliorer leurs opérations, à réaliser un marketing efficace ou même à obtenir un avantage concurrentiel. Pour utiliser ces données de manière éthique, plusieurs étapes doivent être suivies.
Cela commence par la collecte des données elle-même. Bien que la plupart des données de mobilité restent exemptes d'informations personnelles identifiables (PII) telles que le nom et l'adresse, les collecteurs de données et les agrégateurs doivent avoir le consentement de l'utilisateur pour collecter, utiliser, stocker et partager leurs données. Les lois sur la confidentialité des données telles que le RGPD et le CCPA doivent être respectées car elles permettent aux utilisateurs de déterminer comment les entreprises peuvent utiliser leurs données. Cette première étape constitue un pas important vers une utilisation éthique et responsable des données de mobilité, mais il reste encore beaucoup à faire.
Chaque appareil se voit attribuer un identifiant de publicité mobile (MAID) haché, qui est utilisé pour ancrer les pings individuels. Cela peut être encore plus obscurci en utilisant Amazone Macie, Objet Amazon S3 Lambda, Amazon comprendre, ou même le Studio de colle AWS Détectez la transformation PII. Pour plus d'informations, reportez-vous à Techniques courantes pour détecter les données PHI et PII à l'aide des services AWS.
Outre les informations personnelles, il convient de veiller à masquer l’emplacement du domicile de l’utilisateur ainsi que d’autres emplacements sensibles tels que les bases militaires ou les lieux de culte.
La dernière étape d'une utilisation éthique consiste à dériver et à exporter uniquement des métriques agrégées à partir d'Amazon SageMaker. Cela signifie obtenir des mesures telles que le nombre moyen ou le nombre total de visiteurs, par opposition aux modèles de voyage individuels ; obtenir des tendances quotidiennes, hebdomadaires, mensuelles ou annuelles ; ou indexer les modèles de mobilité sur des données accessibles au public telles que les données de recensement.
Vue d'ensemble de la solution
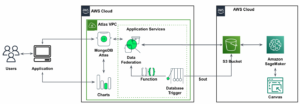
Comme mentionné précédemment, les services AWS que vous pouvez utiliser pour l'analyse des données de mobilité sont les capacités géospatiales Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend et Amazon SageMaker. Les capacités géospatiales d'Amazon SageMaker permettent aux scientifiques des données et aux ingénieurs ML de créer, former et déployer facilement des modèles à l'aide de données géospatiales. Vous pouvez transformer ou enrichir efficacement des ensembles de données géospatiales à grande échelle, accélérer la création de modèles avec des modèles ML pré-entraînés et explorer les prédictions de modèles et les données géospatiales sur une carte interactive à l'aide de graphiques 3D accélérés et d'outils de visualisation intégrés.
L'architecture de référence suivante décrit un flux de travail utilisant le ML avec des données géospatiales.
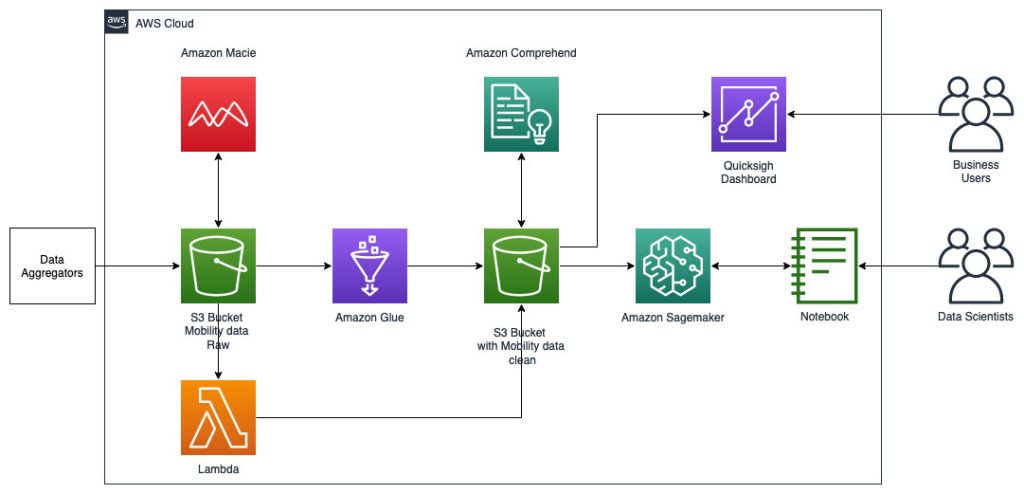
Dans ce flux de travail, les données brutes sont regroupées à partir de diverses sources de données et stockées dans un Service de stockage simple Amazon (S3) seau. Amazon Macie est utilisé sur ce compartiment S3 pour identifier et rédiger les informations personnelles. AWS Glue est ensuite utilisé pour nettoyer et transformer les données brutes au format requis, puis les données modifiées et nettoyées sont stockées dans un compartiment S3 distinct. Pour les transformations de données qui ne sont pas possibles via AWS Glue, vous utilisez AWS Lambda pour modifier et nettoyer les données brutes. Une fois les données nettoyées, vous pouvez utiliser Amazon SageMaker pour créer, entraîner et déployer des modèles ML sur les données géospatiales préparées. Vous pouvez également utiliser le Emplois Traitement géospatial fonctionnalité des capacités géospatiales d'Amazon SageMaker pour prétraiter les données, par exemple en utilisant une fonction Python et des instructions SQL pour identifier les activités à partir des données de mobilité brutes. Les data scientists peuvent accomplir ce processus en se connectant via des blocs-notes Amazon SageMaker. Vous pouvez aussi utiliser Amazon QuickSight pour visualiser les résultats commerciaux et d’autres mesures importantes à partir des données.
Capacités géospatiales d'Amazon SageMaker et tâches de traitement géospatial
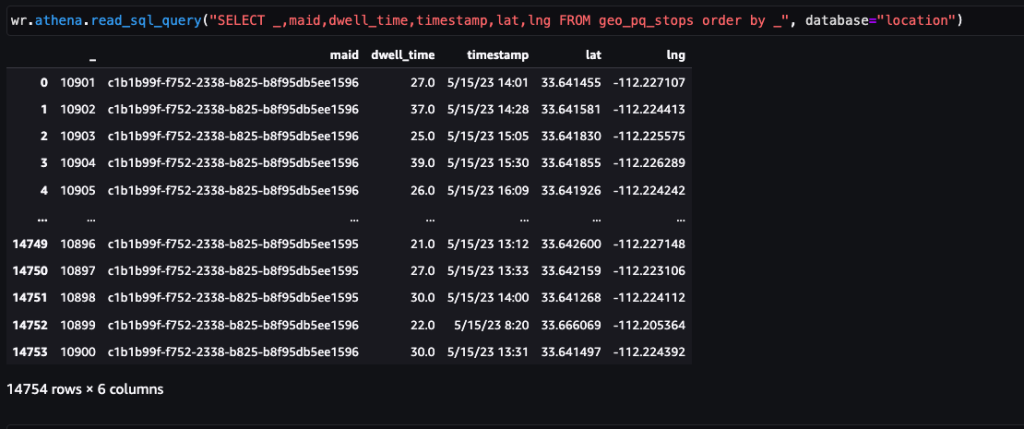
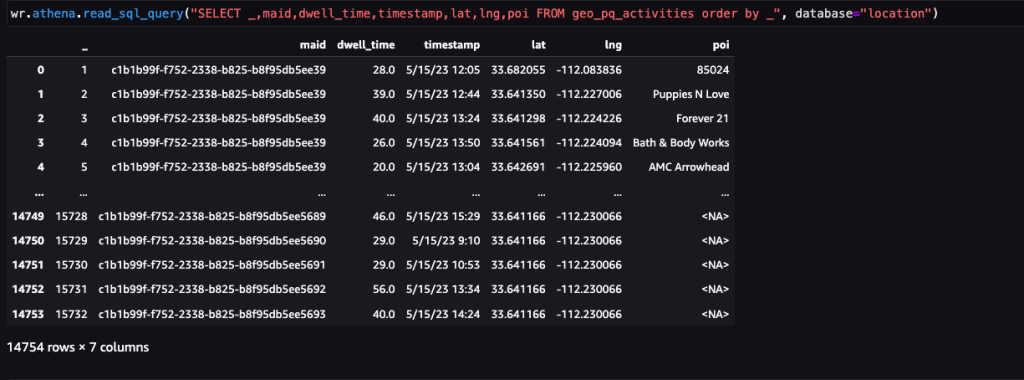
Une fois les données obtenues et introduites dans Amazon S3 avec un flux quotidien et nettoyées de toutes les données sensibles, elles peuvent être importées dans Amazon SageMaker à l'aide d'un Amazon SageMakerStudio cahier avec une image géospatiale. La capture d'écran suivante montre un exemple de pings quotidiens sur les appareils téléchargés dans Amazon S3 sous forme de fichier CSV, puis chargés dans un bloc de données pandas. Le bloc-notes Amazon SageMaker Studio avec image géospatiale est préchargé avec des bibliothèques géospatiales telles que GDAL, GeoPandas, Fiona et Shapely, et facilite le traitement et l'analyse de ces données.
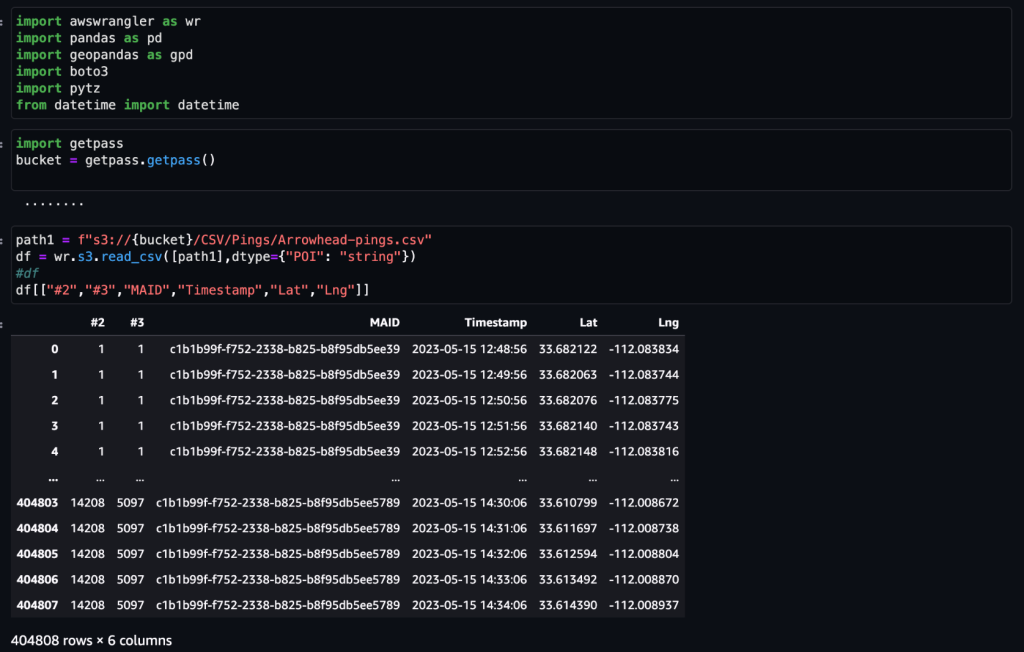
Cet exemple d'ensemble de données contient environ 400,000 5,000 pings quotidiens provenant de 14,000 15 appareils provenant de 2023 XNUMX lieux uniques, enregistrés par des utilisateurs visitant le Arrowhead Mall, un complexe commercial populaire à Phoenix, en Arizona, le XNUMX mai XNUMX. La capture d'écran précédente montre un sous-ensemble de colonnes dans le schéma de données. Le MAID La colonne représente l'ID de l'appareil, et chaque MAID génère des pings toutes les minutes relayant la latitude et la longitude de l'appareil, enregistrées dans le fichier d'exemple sous la forme Lat ainsi que les Lng colonnes.
Voici des captures d'écran de l'outil de visualisation cartographique des capacités géospatiales d'Amazon SageMaker optimisées par Foursquare Studio, illustrant la disposition des pings provenant des appareils visitant le centre commercial entre 7h00 et 6h00.
La capture d'écran suivante montre les pings du centre commercial et de ses environs.

Ce qui suit montre les pings provenant de divers magasins du centre commercial.
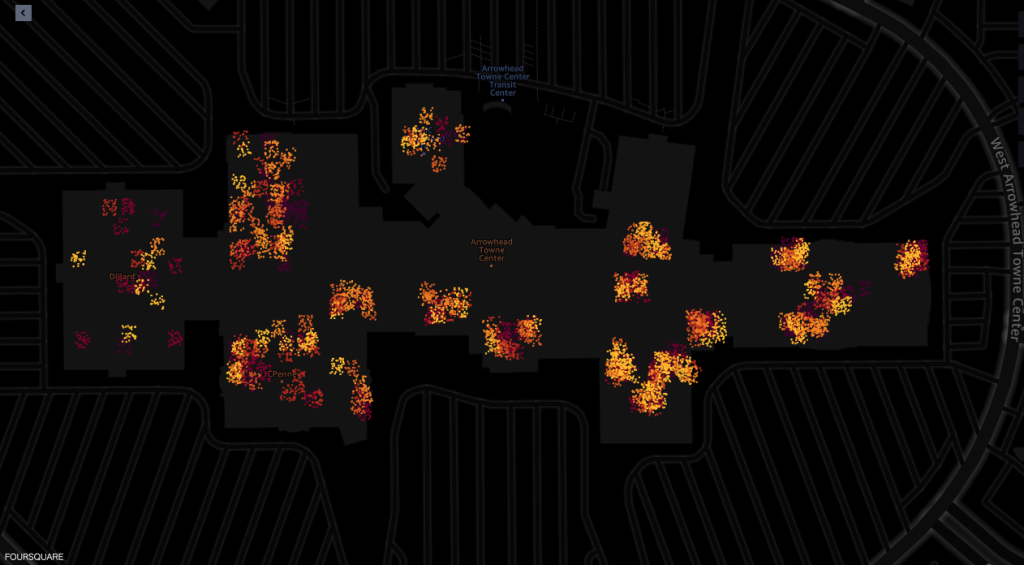
Chaque point dans les captures d'écran représente un ping provenant d'un appareil donné à un moment donné. Un groupe de pings représente des endroits populaires où les appareils se sont rassemblés ou arrêtés, tels que des magasins ou des restaurants.
Dans le cadre de l'ETL initial, ces données brutes peuvent être chargées sur des tables à l'aide d'AWS Glue. Vous pouvez créer un robot d'exploration AWS Glue pour identifier le schéma des tables de données et de formulaire en pointant vers l'emplacement des données brutes dans Amazon S3 comme source de données.

Comme mentionné ci-dessus, les données brutes (les pings quotidiens des appareils), même après l'ETL initial, représenteront un flux continu de pings GPS indiquant l'emplacement des appareils. Pour extraire des informations exploitables de ces données, nous devons identifier les arrêts et les déplacements (trajectoires). Ceci peut être réalisé en utilisant le Emplois Traitement géospatial fonctionnalité des capacités géospatiales de SageMaker. Traitement d'Amazon SageMaker utilise une expérience simplifiée et gérée sur SageMaker pour exécuter des charges de travail de traitement de données avec le conteneur géospatial spécialement conçu. L'infrastructure sous-jacente d'une tâche SageMaker Processing est entièrement gérée par SageMaker. Cette fonctionnalité permet d'exécuter du code personnalisé sur des données géospatiales stockées sur Amazon S3 en exécutant un conteneur ML géospatial sur une tâche de traitement SageMaker. Vous pouvez exécuter des opérations personnalisées sur des données géospatiales ouvertes ou privées en écrivant du code personnalisé avec des bibliothèques open source, et exécuter l'opération à grande échelle à l'aide des tâches de traitement SageMaker. L'approche basée sur les conteneurs répond aux besoins de standardisation de l'environnement de développement avec des bibliothèques open source couramment utilisées.
Pour exécuter des charges de travail à si grande échelle, vous avez besoin d'un cluster de calcul flexible, capable d'évoluer depuis des dizaines d'instances pour traiter un pâté de maisons jusqu'à des milliers d'instances pour un traitement à l'échelle planétaire. La gestion manuelle d’un cluster de calcul DIY est lente et coûteuse. Cette fonctionnalité est particulièrement utile lorsque l'ensemble de données sur la mobilité implique plusieurs villes dans plusieurs États, voire pays, et peut être utilisée pour exécuter une approche ML en deux étapes.
La première étape consiste à utiliser l’algorithme de regroupement spatial d’applications avec bruit (DBSCAN) basé sur la densité pour regrouper les arrêts des pings. L'étape suivante consiste à utiliser la méthode des machines à vecteurs de support (SVM) pour améliorer encore la précision des arrêts identifiés et également pour distinguer les arrêts avec engagements avec un POI des arrêts sans POI (comme à la maison ou au travail). Vous pouvez également utiliser la tâche SageMaker Processing pour générer des trajets et des trajectoires à partir des pings quotidiens de l'appareil en identifiant les arrêts consécutifs et en cartographiant le chemin entre les arrêts source et de destination.
Après avoir traité les données brutes (pings quotidiens de l'appareil) à grande échelle avec les tâches de traitement géospatial, le nouvel ensemble de données appelé arrêts doit avoir le schéma suivant.
| Attribut | Description |
| Identifiant ou MAID | Identifiant de publicité mobile de l'appareil (haché) |
| lat | Latitude du centre de gravité du cluster d'arrêt |
| lng | Longitude du centre de gravité du cluster d'arrêt |
| géohachage | Emplacement Geohash du POI |
| type d'appareil | Système d'exploitation de l'appareil (IDFA ou GAID) |
| horodatage | Heure de début de l'arrêt |
| temps_dwell | Temps de séjour de l'arrêt (en secondes) |
| ip | adresse IP |
| alt | Altitude de l'appareil (en mètres) |
| Pays | Code ISO à deux chiffres pour le pays d'origine |
| Etat | Codes représentant l'état |
| ville | Codes représentant la ville |
| code postal | Code postal de l'endroit où l'ID de l'appareil est visible |
| porteur | Transporteur de l'appareil |
| fabricant_de l'appareil | Fabricant de l'appareil |
Les arrêts sont consolidés en regroupant les pings par appareil. Le regroupement basé sur la densité est combiné à des paramètres tels que le seuil d'arrêt étant de 300 secondes et la distance minimale entre les arrêts étant de 50 mètres. Ces paramètres peuvent être ajustés selon votre cas d'utilisation.
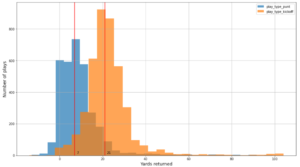
La capture d'écran suivante montre environ 15,000 400,000 arrêts identifiés à partir de XNUMX XNUMX pings. Un sous-ensemble du schéma précédent est également présent, où la colonne Dwell Time représente la durée d'arrêt, et le Lat ainsi que les Lng Les colonnes représentent la latitude et la longitude des centroïdes du cluster d'arrêts par appareil et par emplacement.
Post-ETL, les données sont stockées au format de fichier Parquet, qui est un format de stockage en colonnes qui facilite le traitement de grandes quantités de données.
La capture d'écran suivante montre les arrêts consolidés à partir des pings par appareil à l'intérieur du centre commercial et des zones environnantes.

Après avoir identifié les arrêts, cet ensemble de données peut être associé à des données de POI accessibles au public ou à des données de POI personnalisées spécifiques au cas d'utilisation pour identifier des activités, telles que l'engagement avec les marques.
La capture d'écran suivante montre les arrêts identifiés aux principaux POI (magasins et marques) à l'intérieur du centre commercial Arrowhead.
Les codes postaux du domicile ont été utilisés pour masquer l’emplacement du domicile de chaque visiteur afin de préserver la confidentialité au cas où cela ferait partie de son voyage dans l’ensemble de données. La latitude et la longitude sont dans de tels cas les coordonnées respectives du centre de gravité du code postal.
La capture d'écran suivante est une représentation visuelle de ces activités. L'image de gauche mappe les arrêts aux magasins et l'image de droite donne une idée de l'agencement du centre commercial lui-même.

Cet ensemble de données résultant peut être visualisé de plusieurs manières, dont nous discutons dans les sections suivantes.
Métriques de densité
Nous pouvons calculer et visualiser la densité des activités et des visites.
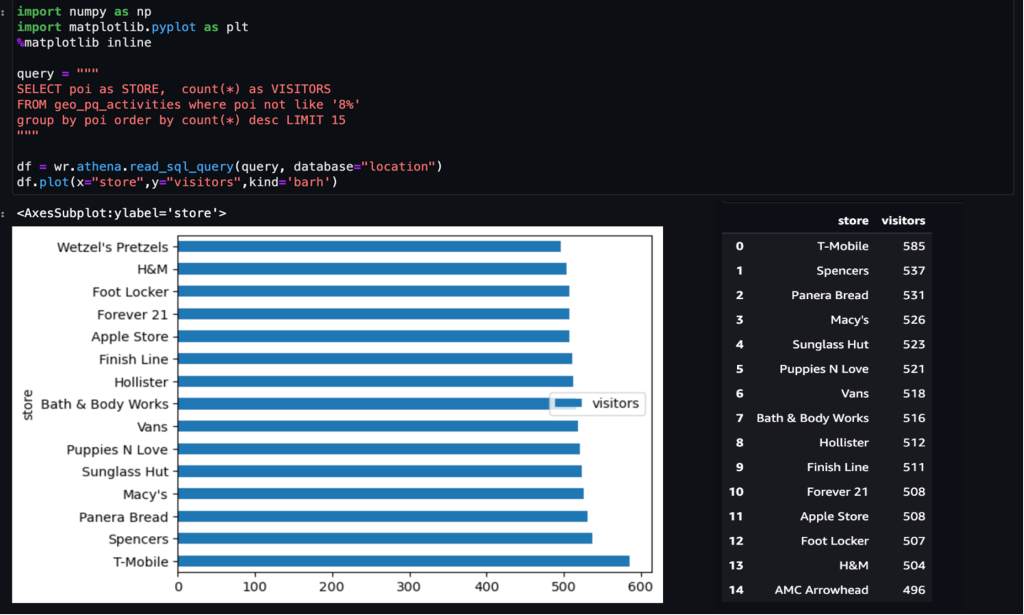
Exemple 1 – La capture d'écran suivante montre les 15 magasins les plus visités du centre commercial.
Exemple 2 – La capture d'écran suivante montre le nombre de visites sur l'Apple Store par heure.

Voyages et trajectoires
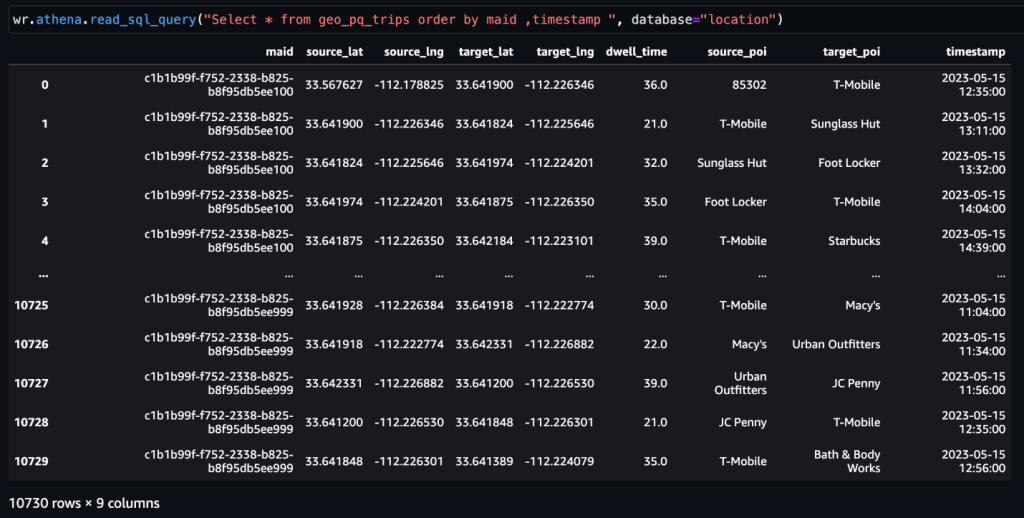
Comme mentionné précédemment, une paire d’activités consécutives représente un voyage. Nous pouvons utiliser l'approche suivante pour dériver les déplacements à partir des données d'activités. Ici, les fonctions de fenêtre sont utilisées avec SQL pour générer le trips tableau, comme indiqué dans la capture d'écran.

Après les trips est généré, les déplacements vers un POI peuvent être déterminés.
Exemple 1 – La capture d'écran suivante montre les 10 principaux magasins qui dirigent le trafic piétonnier vers l'Apple Store.

Exemple 2 – La capture d'écran suivante montre tous les déplacements vers le centre commercial Arrowhead.

Exemple 3 – La vidéo suivante montre les schémas de mouvement à l’intérieur du centre commercial.

Exemple 4 – La vidéo suivante montre les schémas de déplacement à l’extérieur du centre commercial.
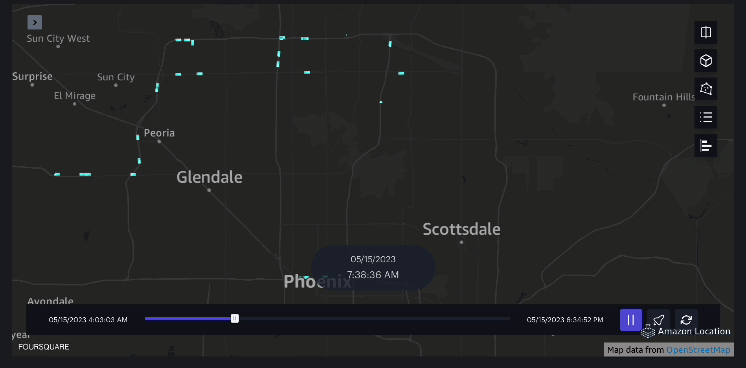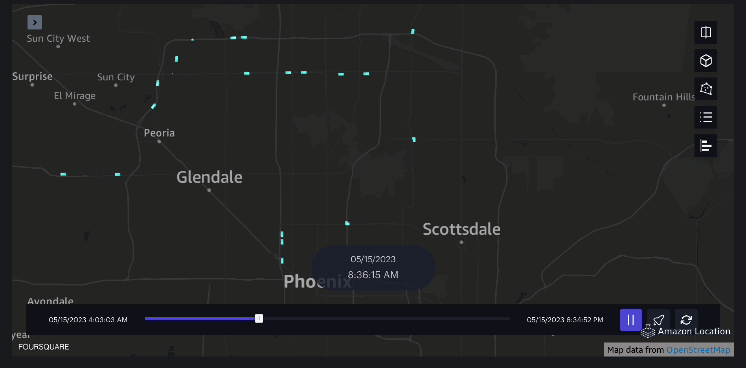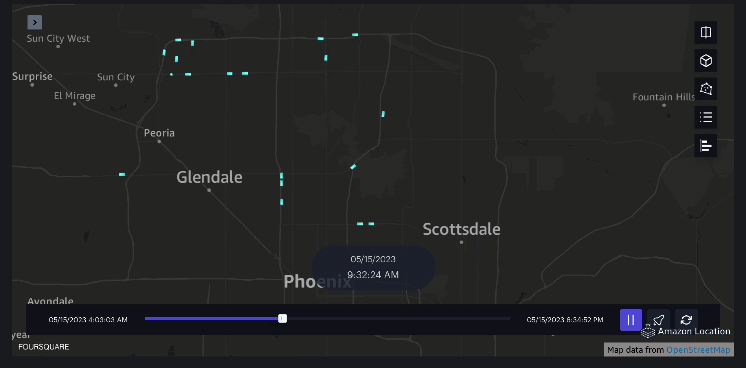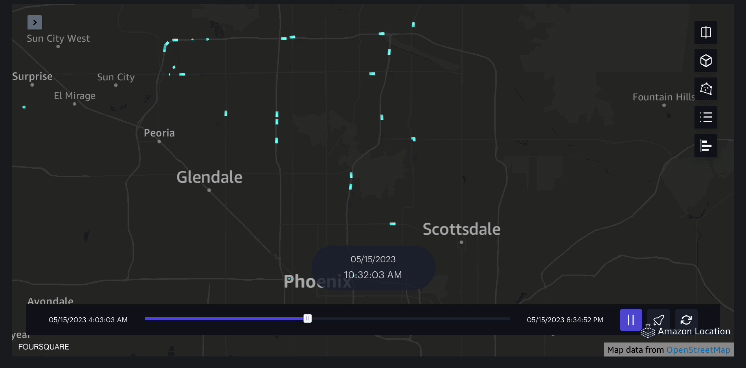
Analyse de la zone de chalandise
Nous pouvons analyser toutes les visites d’un POI et déterminer la zone de chalandise.
Exemple 1 – La capture d'écran suivante montre toutes les visites au magasin Macy's.

Exemple 2 – La capture d'écran suivante montre les 10 principaux codes postaux de la zone d'origine (limites mises en évidence) d'où les visites ont eu lieu.

Contrôle de la qualité des données
Nous pouvons vérifier la qualité des flux de données entrants quotidiens et détecter les anomalies à l’aide des tableaux de bord QuickSight et des analyses de données. La capture d'écran suivante montre un exemple de tableau de bord.

Conclusion
Les données de mobilité et leur analyse pour obtenir des informations sur les clients et obtenir un avantage concurrentiel restent un domaine de niche car il est difficile d'obtenir un ensemble de données cohérent et précis. Cependant, ces données peuvent aider les organisations à ajouter du contexte aux analyses existantes et même à produire de nouvelles informations sur les modèles de mouvement des clients. Les capacités géospatiales et les tâches de traitement géospatial d'Amazon SageMaker peuvent aider à mettre en œuvre ces cas d'utilisation et à obtenir des informations de manière intuitive et accessible.
Dans cet article, nous avons montré comment utiliser les services AWS pour nettoyer les données de mobilité, puis utiliser les capacités géospatiales d'Amazon SageMaker pour générer des ensembles de données dérivés tels que les arrêts, les activités et les déplacements à l'aide de modèles ML. Nous avons ensuite utilisé les ensembles de données dérivés pour visualiser les modèles de mouvement et générer des informations.
Vous pouvez démarrer avec les fonctionnalités géospatiales d'Amazon SageMaker de deux manières :
Pour en savoir plus, visitez le site Fonctionnalités géospatiales d'Amazon SageMaker ainsi que les Premiers pas avec Amazon SageMaker géospatial. Visitez également notre GitHub repo, qui contient plusieurs exemples de blocs-notes sur les capacités géospatiales d'Amazon SageMaker.
À propos des auteurs
 Jimy Matthews est un architecte de solutions AWS, avec une expertise en technologie IA/ML. Jimy est basé à Boston et travaille avec des entreprises clientes alors qu'elles transforment leur activité en adoptant le cloud et les aide à créer des solutions efficaces et durables. Il est passionné par sa famille, les voitures et les arts martiaux mixtes.
Jimy Matthews est un architecte de solutions AWS, avec une expertise en technologie IA/ML. Jimy est basé à Boston et travaille avec des entreprises clientes alors qu'elles transforment leur activité en adoptant le cloud et les aide à créer des solutions efficaces et durables. Il est passionné par sa famille, les voitures et les arts martiaux mixtes.
 Girish Keshav est architecte de solutions chez AWS, aidant les clients dans leur parcours de migration vers le cloud pour moderniser et exécuter les charges de travail de manière sécurisée et efficace. Il travaille avec les dirigeants des équipes technologiques pour les guider sur la sécurité des applications, l'apprentissage automatique, l'optimisation des coûts et la durabilité. Il est basé à San Francisco et adore voyager, faire de la randonnée, regarder du sport et explorer les brasseries artisanales.
Girish Keshav est architecte de solutions chez AWS, aidant les clients dans leur parcours de migration vers le cloud pour moderniser et exécuter les charges de travail de manière sécurisée et efficace. Il travaille avec les dirigeants des équipes technologiques pour les guider sur la sécurité des applications, l'apprentissage automatique, l'optimisation des coûts et la durabilité. Il est basé à San Francisco et adore voyager, faire de la randonnée, regarder du sport et explorer les brasseries artisanales.
 Jetée de Ramesh est un leader senior de l'architecture de solutions dont l'objectif est d'aider les entreprises clientes AWS à monétiser leurs actifs de données. Il conseille les dirigeants et les ingénieurs pour concevoir et créer des solutions cloud hautement évolutives, fiables et rentables, particulièrement axées sur l'apprentissage automatique, les données et l'analyse. Pendant son temps libre, il aime les grands espaces, le vélo et la randonnée avec sa famille.
Jetée de Ramesh est un leader senior de l'architecture de solutions dont l'objectif est d'aider les entreprises clientes AWS à monétiser leurs actifs de données. Il conseille les dirigeants et les ingénieurs pour concevoir et créer des solutions cloud hautement évolutives, fiables et rentables, particulièrement axées sur l'apprentissage automatique, les données et l'analyse. Pendant son temps libre, il aime les grands espaces, le vélo et la randonnée avec sa famille.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/
- :possède
- :est
- :ne pas
- :où
- $UP
- 000
- 1
- 10
- 100
- 14
- 15%
- 2023
- 300
- 361
- 3d
- 400
- 50
- 7
- 9
- a
- Qui sommes-nous
- au dessus de
- accélérer
- accéléré
- accès
- accessible
- accomplir
- précision
- Avec cette connaissance vient le pouvoir de prendre
- atteint
- infection
- activement
- activités
- présenter
- ajouter
- propos
- adhéré
- Ajusté
- L'adoption d'
- annonces
- Avantage
- Publicité
- Numérique
- Après
- Aggregator
- Agrégateurs
- AI / ML
- Aide
- algorithme
- Tous
- aux côtés de
- aussi
- Bien que
- am
- Amazon
- Amazon comprendre
- Amazon Sage Maker
- Géospatial Amazon SageMaker
- Amazon SageMakerStudio
- Amazon Web Services
- quantités
- an
- analyses
- selon une analyse de l’Université de Princeton
- analytique
- il analyse
- l'analyse
- Présentatrice
- ainsi que les
- tous
- A PART
- appli
- Apple
- Application
- sécurité de l'application
- applications
- une approche
- d'environ
- architecture
- SONT
- Réservé
- domaines
- Arizona
- autour
- Les arts
- AS
- Outils
- attribué
- associé
- At
- atteindre
- public
- augmenter
- disponibles
- moyen
- AWS
- Colle AWS
- base
- basé
- base
- BE
- car
- était
- va
- jusqu'à XNUMX fois
- offre
- Block
- boston
- frontières
- Marques
- construire
- Développement
- intégré
- la performance des entreprises
- entreprises
- mais
- by
- calculer
- appelé
- Campagnes
- CAN
- Peut obtenir
- capacités
- voitures
- maisons
- cas
- CCPA
- Cellules
- Recensement
- données de recensement
- chaîne
- vérifier
- Villes
- Ville
- espace extérieur plus propre,
- Fermer
- le cloud
- Grappe
- regroupement
- code
- codes
- collaboration
- recueillir
- collection
- collectionneurs
- Colonne
- Colonnes
- combiné
- vient
- Venir
- commercial
- immobilier commercial
- Commun
- communément
- Sociétés
- compétitif
- concurrents
- complexe
- composant
- comprendre
- calcul
- Connecter les
- consécutif
- consentement
- considérations
- cohérent
- consommation
- Contenant
- contient
- contexte
- continu
- Prix
- d'exportation
- Pays
- couverture
- couvre
- élaborer
- chenilles
- engendrent
- Customiser
- des clients
- Clients
- Tous les jours
- tableau de bord
- tableaux de bord
- données
- points de données
- confidentialité des données
- informatique
- ensembles de données
- journée
- page de livraison.
- démontré
- densité
- représentant
- déployer
- dérivé
- dériver
- Dérivé
- Conception
- destinations
- détail
- détecter
- Déterminer
- déterminé
- détermination
- Développement
- dispositif
- Compatibles
- difficile
- catastrophes
- découverte
- discuter
- distance
- distinguer
- Bricolage
- fait
- DOT
- attire
- deux
- durée
- pendant
- chacun
- Plus tôt
- plus facilement
- Easy
- Efficace
- efficace
- efficacement
- effort
- vous accompagner
- permet
- englobant
- participation
- engagements
- engageant
- Les ingénieurs
- enrichir
- Entreprise
- clients entreprise
- Environment
- notamment
- biens
- Ether (ETH)
- éthique
- Pourtant, la
- événement
- Chaque
- exemple
- cadres
- existant
- existe
- cher
- d'experience
- nous a permis de concevoir
- explorez
- Explorer
- Exporter
- exprimé
- extrait
- famille
- Fonctionnalité
- Fed
- few
- Déposez votre dernière attestation
- finale
- Trouvez
- fiona
- Prénom
- flexible
- Focus
- concentré
- suivi
- Abonnement
- Pied
- Pour
- formulaire
- le format
- Foursquare
- CADRE
- Francisco
- Gratuit
- de
- Carburant
- d’étiquettes électroniques entièrement
- fonction
- fonctions
- plus
- gagner
- jeu
- recueillies
- RGPD
- générer
- généré
- génère
- générateur
- géographique
- géographique
- ML géospatial
- obtenez
- obtention
- gif
- donné
- donne
- Goes
- gps
- graphique
- l'
- Grands espaces
- Grille
- guide
- Matériel
- haché
- Vous avez
- he
- vous aider
- utile
- aider
- aide
- ici
- Surbrillance
- très
- randonnée
- sa
- Accueil
- Horizontal
- heure
- Comment
- How To
- Cependant
- HTML
- http
- HTTPS
- Moyeux
- ouragan
- ID
- idée
- identifié
- identifier
- identifier
- IDFA
- if
- image
- Mettre en oeuvre
- important
- améliorer
- in
- Y compris
- Nouveau
- indiquant
- individuel
- secteurs
- d'information
- Infrastructure
- initiale
- à l'intérieur
- idées.
- cas
- intégrations
- Intelligence
- Interactif
- intérêt
- intéressant
- développement
- introduire
- intuitif
- implique
- IT
- SES
- lui-même
- Emploi
- Emplois
- rejoint
- chemin
- jpg
- gros
- grande échelle
- latitude
- Lois
- couches
- Disposition
- conduire
- leader
- dirigeants
- APPRENTISSAGE
- apprentissage
- à gauche
- bibliothèques
- comme
- probabilité
- lignes
- charge
- emplacement
- emplacements
- Style
- ressembler
- aime
- click
- machine learning
- Les machines
- LES PLANTES
- maintenir
- majeur
- a prendre une
- FAIT DU
- gérés
- les gérer
- manuellement
- de nombreuses
- Localisation
- cartographie
- Map
- Stratégie
- Campagnes Marketing
- technologie de marketing
- MarTech
- martial
- masque
- Matrice
- Mai..
- veux dire
- mentionné
- méthode
- Métrique
- migration
- Militaire
- des millions
- minimum
- minute
- mixte
- ML
- Breeze Mobile
- appareil mobile
- appareils mobiles
- mobilité
- modèle
- numériques jumeaux (digital twin models)
- moderniser
- modifié
- modifier
- monétiser
- mensuel
- PLUS
- (en fait, presque toutes)
- la plupart
- Bougez
- mouvement
- mouvements
- en mouvement
- plusieurs
- multitude
- must
- prénom
- Nature
- Nature
- Besoin
- Besoins
- Nouveauté
- next
- niche
- Bruit
- cahier
- ordinateurs portables
- nombre
- numéros
- objet
- observer
- obtenir
- obtenu
- obtention
- a eu lieu
- of
- souvent
- on
- ONE
- uniquement
- ouvert
- open source
- opération
- Opérations
- opposé
- optimaux
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Optimiser
- or
- organisations
- Autre
- nos
- ande
- les résultats
- l'extérieur
- au contrôle
- plus de
- paire
- pandas
- pandémie
- paramètres
- partie
- particulièrement
- pass
- passionné
- chemin
- motifs
- Personnes
- /
- effectuer
- performant
- Personnellement
- objectifs
- phénix
- photographies
- Physique
- image
- pii
- ping
- mis
- Des endroits
- et la planification de votre patrimoine
- Platon
- Intelligence des données Platon
- PlatonDonnées
- pm
- Point
- des notes bonus
- Populaire
- population
- position
- possible
- Post
- défaillances
- clients potentiels
- alimenté
- précédant
- Prédictions
- représentent
- la confidentialité
- lois sur la vie privée
- Privé
- processus
- traitement
- produire
- fournir
- publiquement
- éditeurs
- achat
- acheté
- but
- Python
- qualité
- classer
- plutôt
- raw
- les données brutes
- réal
- biens immobiliers
- enregistré
- reportez-vous
- référence
- se réfère
- régions
- fiable
- reste
- représentent
- représentation
- représenté
- représentation
- représente
- conditions
- ceux
- responsables
- Restaurants
- résultant
- Résultats
- détail
- bon
- Itinéraire
- routes
- Courir
- pour le running
- sagemaker
- Exemple d'ensemble de données
- San
- San Francisco
- satellite
- l'imagerie par satellite
- évolutive
- Escaliers intérieurs
- scientifiques
- screenshots
- SDK
- fluide
- Deuxièmement
- secondes
- les sections
- en toute sécurité
- sécurité
- sélection
- supérieur
- sensible
- envoyé
- séparé
- Série
- Services
- service
- plusieurs
- Partager
- Shopping
- devrait
- montré
- Spectacles
- similaires
- étapes
- simplifié
- unique
- site
- lent
- So
- Solutions
- Résout
- quelques
- recherché
- Identifier
- Sources
- Space
- Spatial
- groupe de neurones
- Sports
- taches
- SQL
- standardisation
- j'ai commencé
- départs
- déclarations
- États
- étapes
- Étapes
- Arrêter
- arrêté
- arrêt
- Arrête
- storage
- Boutique
- stockée
- STORES
- simple
- courant
- studio
- Ces
- tel
- la quantité
- chaîne d'approvisionnement
- Support
- Surface
- Alentours
- Durabilité
- durable
- combustion propre
- table
- tâches
- équipes
- technologie
- Technique
- techniques
- Technologie
- dizaines
- que
- qui
- Les
- La Région
- La Source
- leur
- Les
- se
- puis
- Là.
- Ces
- l'ont
- this
- ceux
- milliers
- порог
- Avec
- fiable
- à
- trop
- outil
- les outils
- top
- Top 10
- Total
- vers
- Traçant
- circulation
- Train
- trajectoire
- Transformer
- transformations
- émetteurs
- Voyage
- Voyages
- Trends
- voyage
- deux
- types
- débutante
- sous-jacent
- compréhension
- expérience unique et authentique
- téléchargé
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- utilisateurs
- Usages
- en utilisant
- utiliser
- divers
- vérifier
- via
- Vidéo
- Visiter
- visité
- visiteurs
- Visites
- visuel
- visualisation
- visualiser
- visuels
- vs
- personne(s) regarde(nt) cette fiche produit
- Façon..
- façons
- we
- web
- services Web
- hebdomadaire
- WELL
- Quoi
- quand
- qui
- WHO
- la totalité
- why
- Wi-fi
- répandu
- sera
- fenêtre
- comprenant
- sans
- activités principales
- workflow
- vos contrats
- écriture
- annuel
- you
- Votre
- zéphyrnet
- Zip