Dans le la première partie Dans cette série en trois parties, nous avons présenté une solution qui démontre comment automatiser la détection de la falsification de documents et de la fraude à grande échelle à l'aide de l'IA AWS et des services d'apprentissage automatique (ML) pour un cas d'utilisation de souscription hypothécaire.
Dans cet article, nous présentons une approche pour développer un modèle de vision par ordinateur basé sur l'apprentissage profond pour détecter et mettre en évidence les fausses images lors de la souscription de prêts hypothécaires. Nous fournissons des conseils sur la création, la formation et le déploiement de réseaux d'apprentissage profond sur Amazon Sage Maker.
Dans la troisième partie, nous montrons comment implémenter la solution sur Détecteur de fraude Amazon.
Vue d'ensemble de la solution
Pour atteindre l'objectif de détection de la falsification de documents lors de la souscription de prêts hypothécaires, nous utilisons un modèle de vision par ordinateur hébergé sur SageMaker pour notre solution de détection de falsification d'images. Ce modèle reçoit une image de test en entrée et génère une prédiction de probabilité de contrefaçon en sortie. L'architecture du réseau est illustrée dans le diagramme suivant.
La falsification d'images implique principalement quatre techniques : l'épissage, le déplacement de copie, la suppression et l'amélioration. Selon les caractéristiques du faux, différents indices peuvent servir de base à la détection et à la localisation. Ces indices incluent les artefacts de compression JPEG, les incohérences des bords, les modèles de bruit, la cohérence des couleurs, la similarité visuelle, la cohérence EXIF et le modèle de caméra.
Compte tenu du vaste domaine de la détection des contrefaçons d’images, nous utilisons l’algorithme d’analyse du niveau d’erreur (ELA) comme méthode illustrative pour détecter les contrefaçons. Nous avons sélectionné la technique ELA pour cet article pour les raisons suivantes :
- Il est plus rapide à mettre en œuvre et peut facilement détecter la falsification des images.
- Il fonctionne en analysant les niveaux de compression de différentes parties d'une image. Cela lui permet de détecter des incohérences pouvant indiquer une falsification, par exemple si une zone a été copiée et collée à partir d'une autre image enregistrée à un niveau de compression différent.
- Il est efficace pour détecter les falsifications plus subtiles ou transparentes qui peuvent être difficiles à repérer à l'œil nu. Même de petites modifications apportées à une image peuvent introduire des anomalies de compression détectables.
- Il ne nécessite pas d'avoir l'image originale non modifiée à des fins de comparaison. ELA peut identifier les signes de falsification uniquement au sein de l’image interrogée elle-même. D'autres techniques nécessitent souvent de comparer l'original non modifié.
- Il s'agit d'une technique légère qui repose uniquement sur l'analyse des artefacts de compression dans les données d'image numérique. Cela ne dépend pas d'un matériel spécialisé ou d'une expertise médico-légale. Cela rend ELA accessible en tant qu’outil d’analyse de premier passage.
- L’image ELA de sortie peut clairement mettre en évidence les différences dans les niveaux de compression, rendant les zones falsifiées visiblement évidentes. Cela permet même à un non-expert de reconnaître les signes d'une éventuelle manipulation.
- Il fonctionne sur de nombreux types d'images (tels que JPEG, PNG et GIF) et ne nécessite que l'analyse de l'image elle-même. D'autres techniques médico-légales peuvent être plus limitées en termes de formats ou d'exigences en matière d'image originale.
Cependant, dans des scénarios réels où vous pouvez avoir une combinaison de documents d'entrée (JPEG, PNG, GIF, TIFF, PDF), nous vous recommandons d'utiliser ELA en conjonction avec diverses autres méthodes, telles que détecter les incohérences dans les bords, modèles de bruit, uniformité des couleurs, Cohérence des données EXIF, identification du modèle de caméraet la uniformité des polices. Nous visons à mettre à jour le code de cet article avec des techniques supplémentaires de détection de contrefaçon.
Le principe sous-jacent d'ELA suppose que les images d'entrée sont au format JPEG, connu pour sa compression avec perte. Néanmoins, la méthode peut toujours être efficace même si les images d'entrée étaient à l'origine dans un format sans perte (tel que PNG, GIF ou BMP) et ensuite converties en JPEG pendant le processus de falsification. Lorsque l’ELA est appliqué aux formats originaux sans perte, il indique généralement une qualité d’image constante sans aucune détérioration, ce qui rend difficile l’identification des zones modifiées. Dans les images JPEG, la norme attendue est que l’image entière présente des niveaux de compression similaires. Cependant, si une section particulière de l’image affiche un niveau d’erreur nettement différent, cela suggère souvent qu’une modification numérique a été effectuée.
ELA met en évidence les différences dans le taux de compression JPEG. Les régions avec une coloration uniforme auront probablement un résultat ELA inférieur (par exemple, une couleur plus foncée par rapport aux bords très contrastés). Les éléments à rechercher pour identifier une falsification ou une modification sont les suivants :
- Des bords similaires doivent avoir une luminosité similaire dans le résultat ELA. Tous les bords à contraste élevé doivent se ressembler, et tous les bords à faible contraste doivent se ressembler. Avec une photo originale, les bords à faible contraste doivent être presque aussi brillants que les bords à contraste élevé.
- Des textures similaires doivent avoir une coloration similaire sous ELA. Les zones avec plus de détails de surface, comme un gros plan d'un ballon de basket, auront probablement un résultat ELA plus élevé qu'une surface lisse.
- Quelle que soit la couleur réelle de la surface, toutes les surfaces planes doivent avoir à peu près la même couleur sous ELA.
Les images JPEG utilisent un système de compression avec perte. Chaque réencodage (réenregistrement) de l'image ajoute une perte de qualité supplémentaire à l'image. Plus précisément, l'algorithme JPEG fonctionne sur une grille de 8×8 pixels. Chaque carré 8×8 est compressé indépendamment. Si l'image n'est absolument pas modifiée, alors tous les carrés 8 × 8 devraient avoir des potentiels d'erreur similaires. Si l'image n'est pas modifiée et réenregistrée, alors chaque carré devrait se dégrader à peu près au même rythme.
ELA enregistre l'image à un niveau de qualité JPEG spécifié. Cette nouvelle sauvegarde introduit un nombre connu d'erreurs sur l'ensemble de l'image. L'image réenregistrée est ensuite comparée à l'image originale. Si une image est modifiée, alors chaque carré 8 × 8 touché par la modification devrait avoir un potentiel d'erreur plus élevé que le reste de l'image.
Les résultats d’ELA dépendent directement de la qualité de l’image. Vous voudrez peut-être savoir si quelque chose a été ajouté, mais si l'image est copiée plusieurs fois, ELA peut uniquement permettre de détecter les réenregistrements. Essayez de trouver la version de la meilleure qualité de l’image.
Avec de la formation et de la pratique, ELA peut également apprendre à identifier la mise à l'échelle, la qualité, le recadrage et les transformations de l'image. Par exemple, si une image non JPEG contient des lignes de grille visibles (1 pixel de large dans des carrés de 8 × 8), cela signifie que l'image a commencé au format JPEG et a été convertie au format non JPEG (tel que PNG). Si certaines zones de l'image manquent de lignes de grille ou si les lignes de grille se déplacent, cela indique une épissure ou une partie dessinée dans l'image non JPEG.
Dans les sections suivantes, nous démontrons les étapes de configuration, de formation et de déploiement du modèle de vision par ordinateur.
Pré-requis
Pour suivre cet article, remplissez les conditions préalables suivantes :
- Avoir un compte AWS.
- Mettre en place Amazon SageMakerStudio. Vous pouvez lancer rapidement SageMaker Studio à l'aide des préréglages par défaut, facilitant ainsi un lancement rapide. Pour plus d'informations, reportez-vous à Amazon SageMaker simplifie la configuration d'Amazon SageMaker Studio pour les utilisateurs individuels.
- Ouvrez SageMaker Studio et lancez un terminal système.
- Exécutez la commande suivante dans le terminal :
git clone https://github.com/aws-samples/document-tampering-detection.git - Le coût total d'exécution de SageMaker Studio pour un utilisateur et les configurations de l'environnement de bloc-notes est de 7.314 USD par heure.
Configurer le carnet de formation du modèle
Effectuez les étapes suivantes pour configurer votre carnet de formation :
- Ouvrez le
tampering_detection_training.ipynbfichier du répertoire document-falsification-detection. - Configurez l'environnement du notebook avec l'image TensorFlow 2.6 Python 3.8 CPU ou GPU optimisé.
Vous pouvez rencontrer un problème de disponibilité insuffisante ou atteindre la limite de quota pour les instances GPU au sein de votre compte AWS lors de la sélection d'instances optimisées pour le GPU. Pour augmenter le quota, visitez la console Service Quotas et augmentez la limite de service pour le type d'instance spécifique dont vous avez besoin. Vous pouvez également utiliser un environnement de portable optimisé pour le processeur dans de tels cas. - Pour Noyau, choisissez Python3.
- Pour Type d'instance, choisissez ml.m5d.24xlarge ou toute autre grande instance.
Nous avons sélectionné un type d'instance plus grand pour réduire le temps de formation du modèle. Avec un environnement de bloc-notes ml.m5d.24xlarge, le coût horaire est de 7.258 USD par heure.
Exécuter le carnet de formation
Exécutez chaque cellule du bloc-notes tampering_detection_training.ipynb en ordre. Nous discutons de certaines cellules plus en détail dans les sections suivantes.
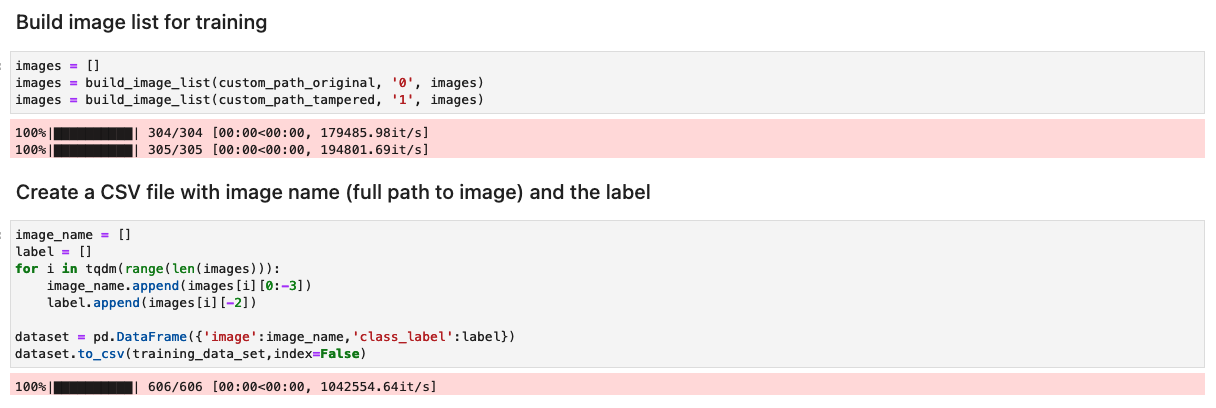
Préparez l'ensemble de données avec une liste d'images originales et falsifiées
Avant d'exécuter la cellule suivante dans le bloc-notes, préparez un ensemble de données de documents originaux et falsifiés en fonction des besoins spécifiques de votre entreprise. Pour cet article, nous utilisons un exemple d’ensemble de données de fiches de paie et de relevés bancaires falsifiés. L'ensemble de données est disponible dans le répertoire images du GitHub référentiel.

Le portable lit les images originales et falsifiées du images/training répertoire.
L'ensemble de données pour la formation est créé à l'aide d'un fichier CSV avec deux colonnes : le chemin d'accès au fichier image et l'étiquette de l'image (0 pour l'image originale et 1 pour l'image falsifiée).
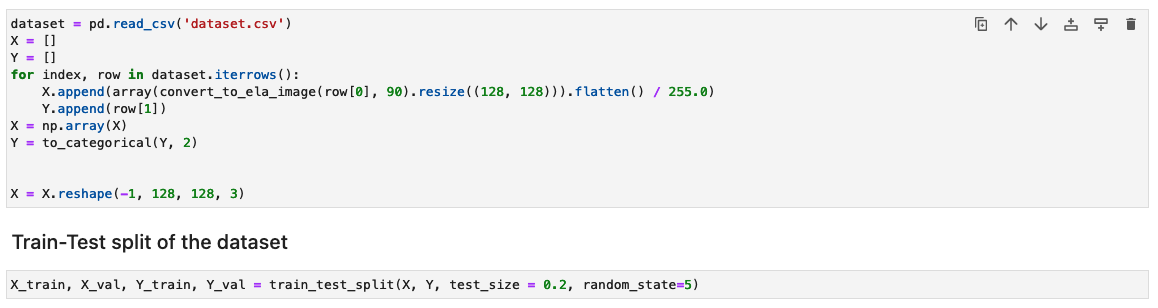
Traitez l'ensemble de données en générant les résultats ELA de chaque image d'entraînement
Dans cette étape, nous générons le résultat ELA (avec une qualité de 90 %) de l'image de formation d'entrée. La fonction convert_to_ela_image prend deux paramètres : path, qui est le chemin d’accès à un fichier image, et quality, représentant le paramètre de qualité pour la compression JPEG. La fonction effectue les étapes suivantes :
- Convertissez l'image au format RVB et réenregistrez l'image sous forme de fichier JPEG avec la qualité spécifiée sous le nom tempresaved.jpg.
- Calculez la différence entre l'image originale et l'image JPEG réenregistrée (ELA) pour déterminer la différence maximale de valeurs de pixels entre les images originales et réenregistrées.
- Calculez un facteur d'échelle basé sur la différence maximale pour ajuster la luminosité de l'image ELA.
- Améliorez la luminosité de l’image ELA à l’aide du facteur d’échelle calculé.
- Redimensionnez le résultat ELA à 128x128x3, où 3 représente le nombre de canaux afin de réduire la taille d'entrée pour la formation.
- Renvoie l'image ELA.
Dans les formats d'image avec perte tels que JPEG, le processus d'enregistrement initial entraîne une perte de couleur considérable. Cependant, lorsque l'image est chargée puis réencodée dans le même format avec perte, la dégradation des couleurs est généralement moindre. Les résultats de l'ELA mettent l'accent sur les zones de l'image les plus susceptibles de subir une dégradation des couleurs lors de la réenregistrement. Généralement, les altérations apparaissent de manière visible dans les régions présentant un potentiel de dégradation plus élevé que le reste de l’image.
Ensuite, les images sont traitées dans un tableau NumPy pour la formation. Nous divisons ensuite l'ensemble de données d'entrée de manière aléatoire en données de formation et de test ou de validation (80/20). Vous pouvez ignorer les avertissements lors de l'exécution de ces cellules.
En fonction de la taille de l'ensemble de données, l'exécution de ces cellules peut prendre du temps. Pour l’exemple d’ensemble de données que nous avons fourni dans ce référentiel, cela peut prendre 5 à 10 minutes.
Configurer le modèle CNN
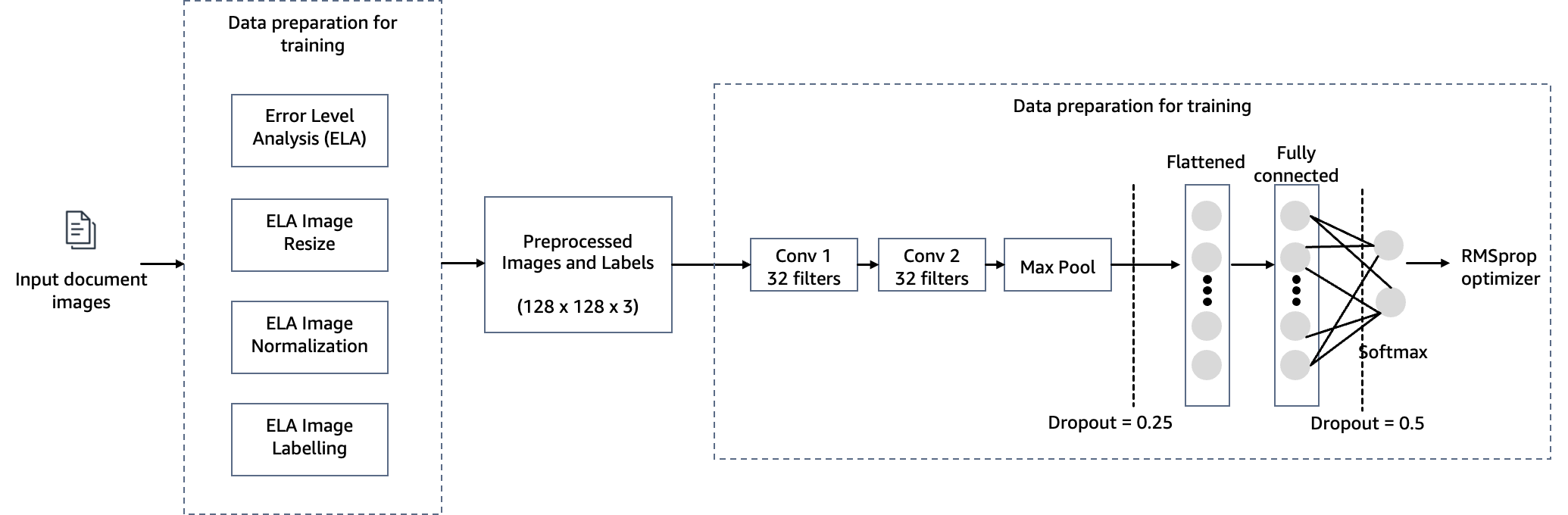
Dans cette étape, nous construisons une version minimale du réseau VGG avec de petits filtres convolutifs. Le VGG-16 se compose de 13 couches convolutives et de trois couches entièrement connectées. La capture d'écran suivante illustre l'architecture de notre modèle de réseau neuronal convolutif (CNN).
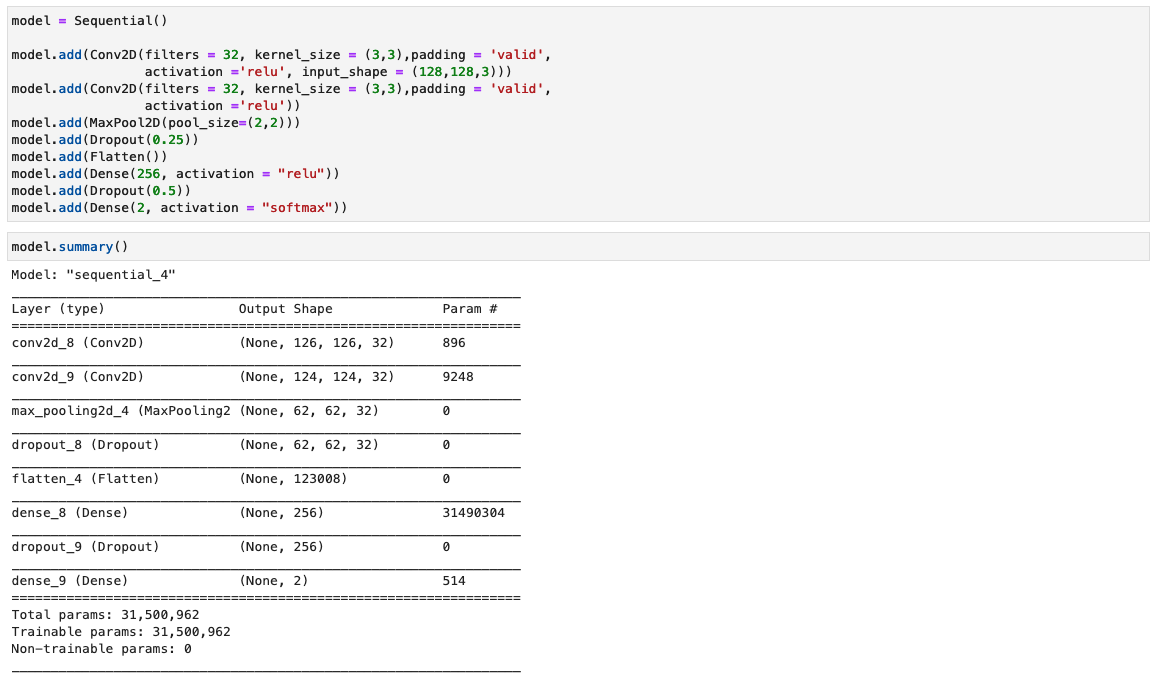
Notez les configurations suivantes :
- Entrée – Le modèle prend une taille d’entrée d’image de 128x128x3.
- Couches convolutives – Les couches convolutives utilisent un champ récepteur minimal (3×3), la plus petite taille possible qui capture toujours haut/bas et gauche/droite. Ceci est suivi d’une fonction d’activation d’unité linéaire rectifiée (ReLU) qui réduit le temps de formation. Il s'agit d'une fonction linéaire qui affichera l'entrée si elle est positive ; sinon, la sortie est nulle. La foulée de convolution est fixée à la valeur par défaut (1 pixel) pour conserver la résolution spatiale préservée après la convolution (la foulée est le nombre de décalages de pixels sur la matrice d'entrée).
- Couches entièrement connectées – Le réseau comporte deux couches entièrement connectées. La première couche dense utilise l'activation ReLU et la seconde utilise softmax pour classer l'image comme originale ou falsifiée.
Vous pouvez ignorer les avertissements lors de l'exécution de ces cellules.
Enregistrez les artefacts du modèle
Enregistrez le modèle entraîné avec un nom de fichier unique (par exemple, basé sur la date et l'heure actuelles) dans un répertoire nommé model.

Le modèle est enregistré au format Keras avec l'extension .keras. Nous enregistrons également les artefacts du modèle dans un répertoire nommé 1 contenant les signatures sérialisées et l'état nécessaire pour les exécuter, y compris les valeurs de variables et les vocabulaires à déployer sur un runtime SageMaker (dont nous parlerons plus loin dans cet article).
Mesurer les performances du modèle
La courbe de perte suivante montre la progression de la perte du modèle au fil des époques d'entraînement (itérations).
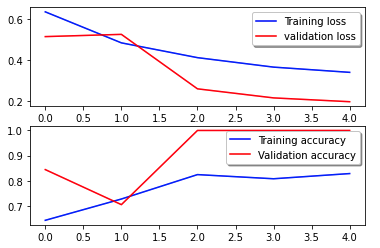
La fonction de perte mesure dans quelle mesure les prédictions du modèle correspondent aux objectifs réels. Des valeurs inférieures indiquent un meilleur alignement entre les prédictions et les valeurs réelles. La diminution des pertes au fil des époques signifie que le modèle s’améliore. La courbe de précision illustre la précision du modèle sur les époques d'entraînement. La précision est le rapport entre les prédictions correctes et le nombre total de prédictions. Une précision plus élevée indique un modèle plus performant. En règle générale, la précision augmente pendant la formation à mesure que le modèle apprend des modèles et améliore sa capacité prédictive. Ceux-ci vous aideront à déterminer si le modèle est surajusté (fonctionne bien sur les données d'entraînement mais médiocre sur les données invisibles) ou sous-ajusté (n'apprend pas suffisamment à partir des données d'entraînement).
La matrice de confusion suivante représente visuellement la façon dont le modèle distingue avec précision entre les classes positives (image falsifiée, représentée par la valeur 1) et négatives (image non falsifiée, représentée par la valeur 0).
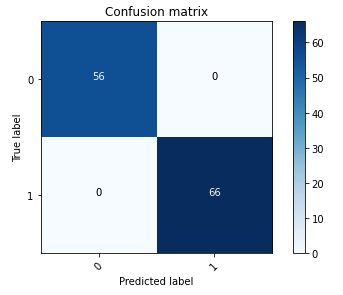
Après la formation du modèle, notre prochaine étape consiste à déployer le modèle de vision par ordinateur en tant qu'API. Cette API sera intégrée aux applications métiers en tant que composant du workflow de souscription. Pour y parvenir, nous utilisons Amazon SageMaker Inference, un service entièrement géré. Ce service s'intègre de manière transparente aux outils MLOps, permettant un déploiement de modèles évolutif, une inférence rentable, une gestion améliorée des modèles en production et une complexité opérationnelle réduite. Dans cet article, nous déployons le modèle comme point de terminaison d'inférence en temps réel. Cependant, il est important de noter que, en fonction du flux de travail de vos applications métier, le déploiement du modèle peut également être personnalisé sous forme de traitement par lots, de gestion asynchrone ou via une architecture de déploiement sans serveur.
Configurer le notebook de déploiement de modèle
Effectuez les étapes suivantes pour configurer votre bloc-notes de déploiement de modèle :
- Ouvrez le
tampering_detection_model_deploy.ipynbfichier du répertoire de détection de falsification de documents. - Configurez l’environnement du notebook avec l’image Data Science 3.0.
- Pour Noyau, choisissez Python3.
- Pour Type d'instance, choisissez ml.t3.moyen.
Avec un environnement de notebook ml.t3.medium, le coût horaire est de 0.056 USD.
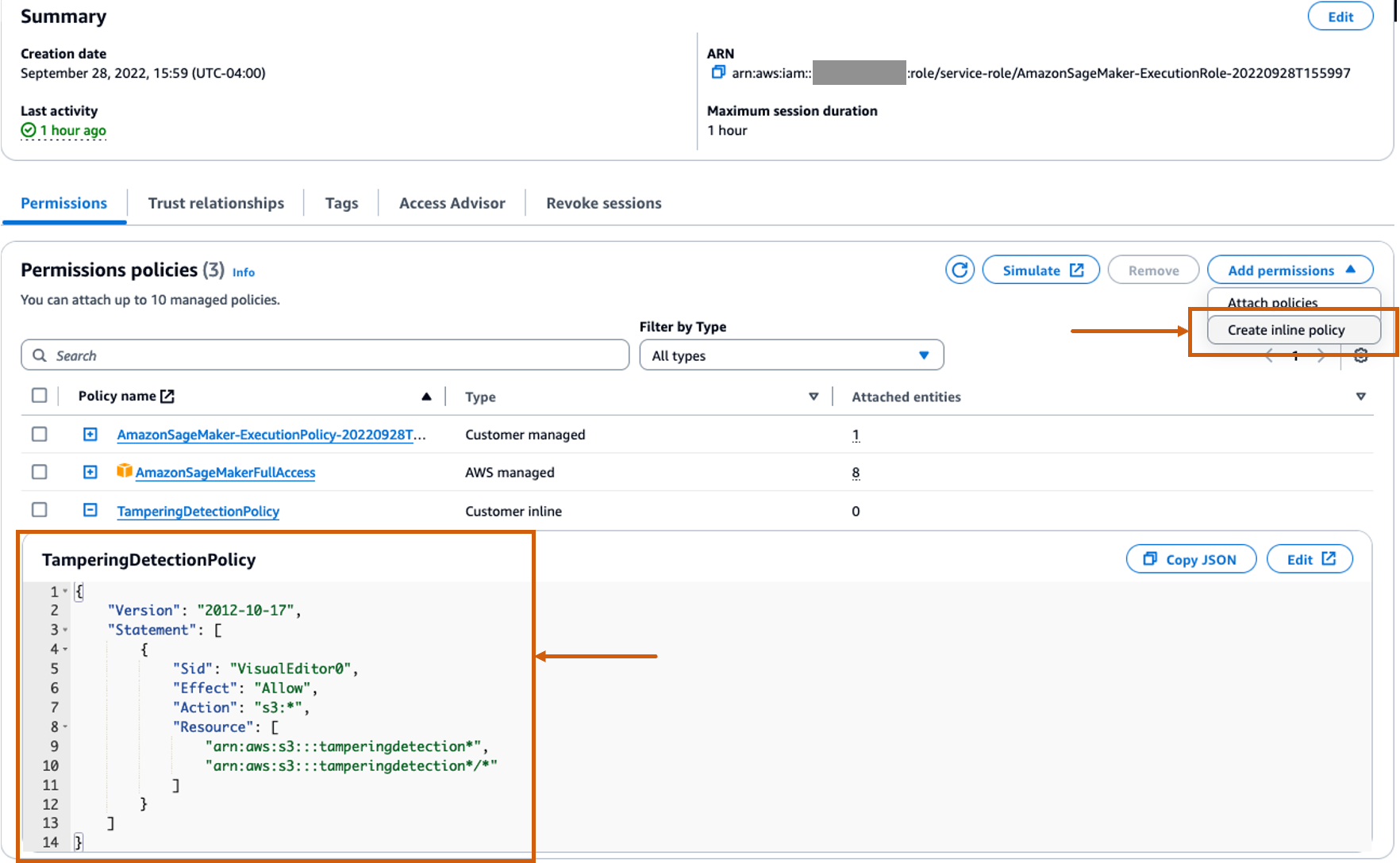
Créez une stratégie en ligne personnalisée pour le rôle SageMaker afin d'autoriser toutes les actions Amazon S3
Les Gestion des identités et des accès AWS (IAM) pour SageMaker sera au format AmazonSageMaker- ExecutionRole-<random numbers>. Assurez-vous que vous utilisez le bon rôle. Le nom du rôle se trouve sous les détails de l'utilisateur dans les configurations du domaine SageMaker.

Mettez à jour le rôle IAM pour inclure une stratégie en ligne pour autoriser tous Service de stockage simple Amazon (Amazon S3). Cela sera nécessaire pour automatiser la création et la suppression des compartiments S3 qui stockeront les artefacts du modèle. Vous pouvez limiter l'accès à des compartiments S3 spécifiques. Notez que nous avons utilisé un caractère générique pour le nom du compartiment S3 dans la stratégie IAM (tamperingdetection*).
Exécuter le notebook de déploiement
Exécutez chaque cellule du bloc-notes tampering_detection_model_deploy.ipynb en ordre. Nous discutons de certaines cellules plus en détail dans les sections suivantes.
Créer un compartiment S3
Exécutez la cellule pour créer un compartiment S3. Le bucket sera nommé tamperingdetection<current date time> et dans la même région AWS que votre environnement SageMaker Studio.

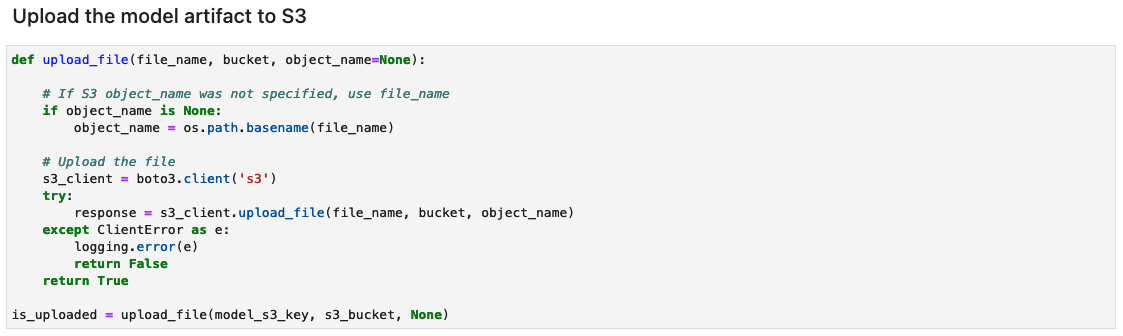
Créez l'archive d'artefacts de modèle et téléchargez-la sur Amazon S3
Créez un fichier tar.gz à partir des artefacts du modèle. Nous avons enregistré les artefacts du modèle dans un répertoire nommé 1, contenant les signatures sérialisées et l'état nécessaire pour les exécuter, y compris les valeurs des variables et les vocabulaires à déployer dans le runtime SageMaker. Vous pouvez également inclure un fichier d'inférence personnalisé appelé inference.py dans le dossier de code de l'artefact de modèle. L'inférence personnalisée peut être utilisée pour le prétraitement et le post-traitement de l'image d'entrée.
![]()
Créer un point de terminaison d'inférence SageMaker
La cellule permettant de créer un point de terminaison d’inférence SageMaker peut prendre quelques minutes.
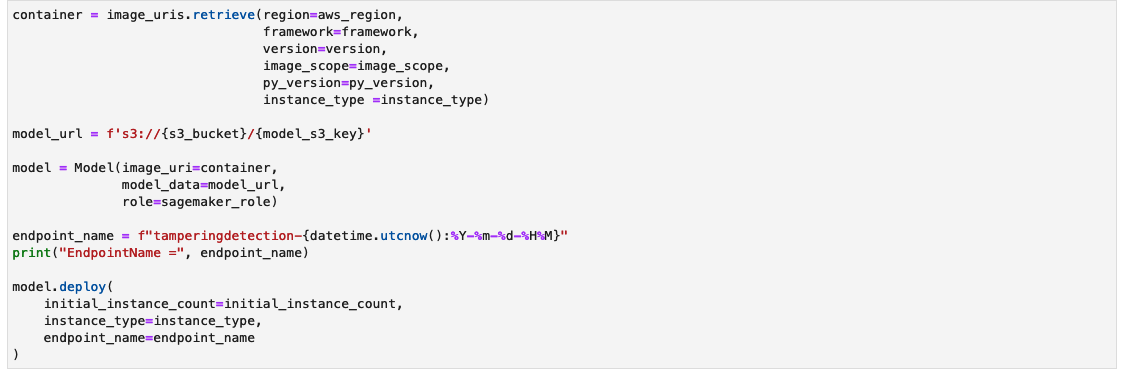
Tester le point de terminaison d'inférence
La fonction check_image prétraite une image en tant qu'image ELA, l'envoie à un point de terminaison SageMaker pour inférence, récupère et traite les prédictions du modèle et imprime les résultats. Le modèle prend un tableau NumPy de l'image d'entrée comme image ELA pour fournir des prédictions. Les prédictions sont sorties sous la forme 0, représentant une image non falsifiée, et 1, représentant une image falsifiée.

Invoquons le modèle avec une image non altérée d'un bulletin de paie et vérifions le résultat.

Le modèle renvoie la classification 0, ce qui représente une image non falsifiée.
Invoquons maintenant le modèle avec une image falsifiée d'un bulletin de paie et vérifions le résultat.

Le modèle génère la classification 1, représentant une image falsifiée.
Limites
Bien qu'ELA soit un excellent outil pour aider à détecter les modifications, il existe un certain nombre de limitations, telles que les suivantes :
- Un seul changement de pixel ou un ajustement mineur des couleurs peut ne pas générer de changement notable dans l'ELA car JPEG fonctionne sur une grille.
- ELA identifie uniquement les régions ayant des niveaux de compression différents. Si une image de qualité inférieure est fusionnée en une image de qualité supérieure, l'image de qualité inférieure peut apparaître comme une région plus sombre.
- La mise à l'échelle, la recoloration ou l'ajout de bruit à une image modifiera l'image entière, créant un potentiel de niveau d'erreur plus élevé.
- Si une image est réenregistrée plusieurs fois, elle peut alors se trouver entièrement à un niveau d'erreur minimum, où davantage de réenregistrements ne modifient pas l'image. Dans ce cas, l'ELA renverra une image noire et aucune modification ne pourra être identifiée grâce à cet algorithme.
- Avec Photoshop, le simple fait d'enregistrer l'image peut auto-affiner les textures et les bords, créant ainsi un potentiel de niveau d'erreur plus élevé. Cet artefact n'identifie pas de modification intentionnelle ; il identifie qu'un produit Adobe a été utilisé. Techniquement, ELA apparaît comme une modification car Adobe a effectué automatiquement une modification, mais la modification n'était pas nécessairement intentionnelle de la part de l'utilisateur.
Nous recommandons d'utiliser ELA avec d'autres techniques évoquées précédemment dans le blog afin de détecter un plus grand nombre de cas de manipulation d'images. ELA peut également servir d'outil indépendant pour examiner visuellement les disparités d'images, en particulier lorsque la formation d'un modèle basé sur CNN devient difficile.
Nettoyer
Pour supprimer les ressources que vous avez créées dans le cadre de cette solution, procédez comme suit :
- Exécutez les cellules du bloc-notes sous le Nettoyer section. Cela supprimera les éléments suivants :
- Point de terminaison d’inférence SageMaker – Le nom du point de terminaison d’inférence sera
tamperingdetection-<datetime>. - Objets dans le compartiment S3 et le compartiment S3 lui-même – Le nom du bucket sera
tamperingdetection<datetime>.
- Point de terminaison d’inférence SageMaker – Le nom du point de terminaison d’inférence sera
- arrêter les ressources du bloc-notes SageMaker Studio.
Conclusion
Dans cet article, nous avons présenté une solution de bout en bout pour détecter la falsification de documents et la fraude à l'aide du deep learning et de SageMaker. Nous avons utilisé ELA pour prétraiter les images et identifier les écarts dans les niveaux de compression pouvant indiquer une manipulation. Ensuite, nous avons formé un modèle CNN sur cet ensemble de données traité pour classer les images comme originales ou falsifiées.
Le modèle peut atteindre de solides performances, avec une précision supérieure à 95 % avec un ensemble de données (falsifiées et originales) adaptées aux besoins de votre entreprise. Cela indique qu'il peut détecter de manière fiable les faux documents tels que les fiches de paie et les relevés bancaires. Le modèle entraîné est déployé sur un point de terminaison SageMaker pour permettre une inférence à faible latence à grande échelle. En intégrant cette solution dans les flux de travail hypothécaires, les institutions peuvent automatiquement signaler les documents suspects pour une enquête plus approfondie sur la fraude.
Bien que puissant, ELA présente certaines limites dans l’identification de certains types de manipulations plus subtiles. Dans les prochaines étapes, le modèle pourrait être amélioré en incorporant des techniques médico-légales supplémentaires dans la formation et en utilisant des ensembles de données plus vastes et plus diversifiés. Dans l'ensemble, cette solution montre comment vous pouvez utiliser le deep learning et les services AWS pour créer des solutions efficaces qui améliorent l'efficacité, réduisent les risques et préviennent la fraude.
Dans la partie 3, nous montrons comment mettre en œuvre la solution sur Amazon Fraud Detector.
À propos des auteurs
 Anup Ravindranath est un architecte de solutions senior chez Amazon Web Services (AWS) basé à Toronto, au Canada, travaillant avec des organisations de services financiers. Il aide les clients à transformer leurs entreprises et à innover sur le cloud.
Anup Ravindranath est un architecte de solutions senior chez Amazon Web Services (AWS) basé à Toronto, au Canada, travaillant avec des organisations de services financiers. Il aide les clients à transformer leurs entreprises et à innover sur le cloud.
 Vinnie Saini est architecte de solutions senior chez Amazon Web Services (AWS) basé à Toronto, Canada. Elle a aidé les clients des services financiers à se transformer sur le cloud, avec des solutions basées sur l'IA et le ML reposant sur de solides piliers fondamentaux de l'excellence architecturale.
Vinnie Saini est architecte de solutions senior chez Amazon Web Services (AWS) basé à Toronto, Canada. Elle a aidé les clients des services financiers à se transformer sur le cloud, avec des solutions basées sur l'IA et le ML reposant sur de solides piliers fondamentaux de l'excellence architecturale.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/train-and-host-a-computer-vision-model-for-tampering-detection-on-amazon-sagemaker-part-2/
- :possède
- :est
- :ne pas
- :où
- $UP
- 056
- 1
- 100
- 13
- 195
- 258
- 408
- 75
- 8
- 95%
- a
- capacité
- Qui sommes-nous
- accès
- accessible
- Compte
- précision
- avec précision
- atteindre
- à travers
- Agis
- actes
- Activation
- présenter
- ajoutée
- ajoutant
- Supplémentaire
- Ajoute
- régler
- Le réglage
- Adobe
- Après
- à opposer à
- AI
- objectif
- algorithme
- alignement
- Tous
- permettre
- permet
- presque
- le long de
- aux côtés de
- aussi
- modifié
- Amazon
- Détecteur de fraude Amazon
- Amazon Sage Maker
- Amazon SageMakerStudio
- Amazon Web Services
- Amazon Web Services (AWS)
- montant
- an
- selon une analyse de l’Université de Princeton
- il analyse
- l'analyse
- ainsi que les
- Une autre
- tous
- api
- apparaître
- apparaît
- applications
- appliqué
- une approche
- d'environ
- architectural
- architecture
- Archive
- SONT
- Réservé
- domaines
- tableau
- AS
- suppose
- At
- automatiser
- automatiquement
- disponibilité
- disponibles
- AWS
- Banque
- basé
- Basketball
- BE
- car
- devient
- était
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Noir
- Blog
- renforcer
- Brillanti
- construire
- Développement
- la performance des entreprises
- applications commerciales
- entreprises
- mais
- by
- calculé
- appelé
- appareil photo
- CAN
- Canada
- captures
- maisons
- cas
- Attraper
- cellule
- Cellules
- certaines
- difficile
- Change
- Modifications
- Voies
- caractéristiques
- vérifier
- Selectionnez
- les classes
- classification
- Classer
- clairement
- le cloud
- CNN
- code
- Couleur
- Colonnes
- combinaison
- comparer
- par rapport
- Comparaison
- complet
- complètement
- complexité
- composant
- ordinateur
- Vision par ordinateur
- Configurer
- confusion
- conjonction
- connecté
- considérable
- cohérent
- consiste
- Console
- construire
- contient
- convertir
- converti
- réseau de neurones convolutifs
- correct
- Prix
- pourriez
- Processeur
- engendrent
- créée
- La création
- création
- Courant
- courbe
- Customiser
- Clients
- plus foncé
- données
- science des données
- ensembles de données
- Date
- réduction
- profond
- l'apprentissage en profondeur
- Réglage par défaut
- démontrer
- démontre
- dénote
- dense
- dépendre
- dépendant
- Selon
- déployer
- déployé
- déployer
- déploiement
- détail
- détails
- détecter
- Détection
- Déterminer
- développer
- diagramme
- différence
- différences
- différent
- numérique
- directement
- discuter
- discuté
- affiche
- distingue
- plusieurs
- do
- document
- INSTITUTIONNELS
- Ne fait pas
- domaine
- tiré
- entraîné
- pendant
- chacun
- même
- Edge
- Efficace
- efficace
- mettre en relief
- employant
- permettre
- permettant
- end-to-end
- Endpoint
- améliorée
- Ce renforcement
- assez
- Tout
- entièrement
- Environment
- époques
- erreur
- Erreurs
- notamment
- Ether (ETH)
- Pourtant, la
- Chaque
- Examiner
- exemple
- Excellence
- excellent
- exposer
- Exposant
- expansif
- attendu
- nous a permis de concevoir
- extension
- œil
- faciliter
- facteur
- few
- champ
- Déposez votre dernière attestation
- filtres
- la traduction de documents financiers
- services financiers
- Trouvez
- Prénom
- fixé
- plat
- suivre
- suivi
- Abonnement
- Pour
- Légal
- forensics
- forgé
- le format
- trouvé
- Fondation
- Fondatrice
- quatre
- fraude
- de
- d’étiquettes électroniques entièrement
- fonction
- plus
- généralement
- générer
- génère
- générateur
- gif
- Git
- Bien
- GPU
- plus grand
- Grille
- l'orientation
- ait eu
- Maniabilité
- Dur
- Matériel
- Vous avez
- ayant
- he
- vous aider
- aider
- aide
- augmentation
- Souligner
- Faits saillants
- Frappé
- hôte
- organisé
- heure
- Comment
- How To
- Cependant
- HTML
- http
- HTTPS
- IAM
- identifié
- identifie
- identifier
- identifier
- Identite
- IEEE
- if
- ignorer
- illustre
- image
- satellite
- percutants
- Mettre en oeuvre
- important
- améliore
- l'amélioration de
- in
- comprendre
- Y compris
- incohérences
- incorporation
- Améliore
- Augmente
- indépendant
- indépendamment
- indiquer
- indique
- individuel
- d'information
- initiale
- initier
- innovons
- contribution
- instance
- cas
- les établissements privés
- des services
- Intègre
- Intégration
- Intentionnel
- développement
- introduire
- Introduit
- enquête
- implique
- aide
- IT
- itérations
- SES
- lui-même
- jpg
- XNUMX éléments à
- keras
- Savoir
- connu
- Libellé
- Peindre
- gros
- plus importantes
- plus tard
- lancer
- couche
- poules pondeuses
- Conduit
- APPRENTISSAGE
- apprentissage
- moins
- Niveau
- niveaux
- léger
- comme
- probabilité
- Probable
- LIMIT
- limites
- linéaire
- lignes
- Liste
- Localisation
- Style
- perte
- baisser
- click
- machine learning
- LES PLANTES
- principalement
- a prendre une
- FAIT DU
- Fabrication
- gérés
- gestion
- Manipulation
- de nombreuses
- Match
- Matrice
- maximales
- Mai..
- veux dire
- les mesures
- moyenne
- Découvrez
- méthode
- méthodes
- minimal
- minimum
- mineur
- minutes
- ML
- MLOps
- modèle
- Modifications
- modifié
- modifier
- PLUS
- Hypothéquer
- (en fait, presque toutes)
- plusieurs
- prénom
- Nommé
- nécessairement
- Besoin
- nécessaire
- négatif
- réseau et
- réseaux
- Neural
- Réseau neuronal
- Néanmoins
- next
- aucune
- Bruit
- noter
- cahier
- nombre
- numpy
- objectif
- évident
- of
- souvent
- on
- ONE
- uniquement
- exploite
- opérationnel
- optimisé
- or
- de commander
- organisations
- original
- initialement
- Autre
- autrement
- nos
- les résultats
- sortie
- sorties
- plus de
- global
- paramètre
- paramètres
- partie
- particulier
- les pièces
- chemin
- motifs
- /
- performant
- effectué
- effectuer
- effectue
- photo
- photoshop
- image
- piliers
- pixel
- Platon
- Intelligence des données Platon
- PlatonDonnées
- parcelle
- politique
- partieInvestir dans des appareils économes en énergie et passer à l'éclairage
- positif
- possible
- Post
- défaillances
- potentiels
- solide
- pratique
- prédiction
- Prédictions
- prédictive
- Préparer
- conditions préalables
- représentent
- présenté
- conservé
- empêcher
- précédemment
- impressions
- processus
- traité
- les process
- traitement
- Produit
- Vidéo
- progression
- fournir
- à condition de
- Python
- qualité
- Interrogé
- plus rapidement
- aléatoire
- gamme
- Nos tests de diagnostic produisent des résultats rapides et précis sans nécessiter d'équipement de laboratoire complexe et coûteux,
- Tarif
- rapport
- monde réel
- en temps réel
- royaume
- Les raisons
- reçoit
- reconnaître
- recommander
- rectifié
- réduire
- Prix Réduit
- réduit
- reportez-vous
- région
- régions
- reprise
- compter
- enlèvement
- supprimez
- rendu
- dépôt
- représenté
- représentation
- représente
- exigent
- conditions
- Exigences
- a besoin
- Résolution
- Resources
- REST
- limité
- résultat
- Résultats
- retourner
- RGB
- Analyse
- Rôle
- Courir
- pour le running
- sagemaker
- Inférence SageMaker
- même
- Exemple d'ensemble de données
- Épargnez
- sauvé
- économie
- évolutive
- Escaliers intérieurs
- mise à l'échelle
- scénarios
- Sciences
- fluide
- de façon transparente
- Deuxièmement
- Section
- les sections
- choisi
- la sélection
- envoie
- supérieur
- Série
- besoin
- Sans serveur
- service
- Services
- set
- installation
- elle
- décalage
- Changements
- devrait
- Spectacles
- Signatures
- signifie
- Signes
- similaires
- étapes
- simplifie
- unique
- Taille
- petit
- lisse
- sur mesure
- Solutions
- quelques
- quelque chose
- Spatial
- spécialisé
- groupe de neurones
- spécifiquement
- spécifié
- scission
- Spot
- carré
- carrés
- j'ai commencé
- Région
- déclarations
- étapes
- Étapes
- Encore
- storage
- Boutique
- foulée
- STRONG
- studio
- Par la suite
- tel
- Suggère
- sûr
- Surface
- sensible
- soupçonneux
- rapidement
- combustion propre
- Prenez
- prend
- objectifs
- techniquement
- technique
- techniques
- tensorflow
- terminal
- tester
- Essais
- que
- qui
- Les
- L'État
- leur
- Les
- puis
- Là.
- Ces
- des choses
- this
- trois
- Avec
- fiable
- fois
- à
- outil
- les outils
- toronto
- Total
- touché
- Train
- qualifié
- Formation
- Transformer
- transformations
- oui
- Essai
- deux
- type
- types
- typiquement
- sous
- sous-jacent
- souscription
- expérience unique et authentique
- unité
- Mises à jour
- sur
- USD
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- Usages
- en utilisant
- validation
- Plus-value
- Valeurs
- variable
- divers
- version
- visible
- vision
- Visiter
- visuel
- visuellement
- souhaitez
- était
- we
- web
- services Web
- WELL
- ont été
- Quoi
- quand
- qui
- large
- sera
- comprenant
- dans les
- sans
- workflow
- workflows
- de travail
- vos contrats
- you
- Votre
- zéphyrnet
- zéro