
Image par auteur
Lorsque vous travaillez avec des données et différentes variables, il est facile d'affecter une variable ou une valeur supérieure à l'autre. Nous pouvons supposer qu'une variable ou un point de données spécifique a eu plus d'impact sur la sortie, mais dans quelle mesure sommes-nous sûrs que les autres variables ont un impact égal ?
En statistiques, le taux de base peut être considéré comme des probabilités de classes inconditionnelles sur des « preuves caractéristiques ». Vous pouvez voir le taux de base comme votre hypothèse de probabilité antérieure.
Les taux de base sont des outils importants en recherche. Par exemple, si nous sommes une entreprise pharmaceutique et que nous sommes en train de développer et de distribuer un nouveau vaccin, nous voulons examiner le succès du traitement. Si nous avons 4000 personnes qui sont prêtes à se faire vacciner, et notre taux de base est de 1/25.
Cela signifie que seulement 160 personnes seront guéries avec succès par le traitement sur 4000 personnes. Dans le monde pharmaceutique, il s'agit d'un taux de réussite très faible. C'est ainsi que les taux de base peuvent être utilisés pour améliorer la recherche et la précision et garantir que le produit fonctionnera bien.
Si nous divisons les mots, cela nous donnera une meilleure compréhension. L'erreur signifie une croyance erronée ou un raisonnement erroné. Si nous combinons maintenant cela avec notre définition du taux de base ci-dessus.
L'erreur de taux de base, également connue sous le nom de biais de taux de base et de négligence du taux de base, est la probabilité de juger une situation spécifique, sans prendre en considération toutes les données pertinentes.
L'erreur du taux de base contient des informations sur le taux de base ainsi que d'autres informations pertinentes. Cela peut être dû à diverses raisons, telles que l'absence d'examen et d'analyse approfondis des données, ou l'ignorance pour favoriser une partie spécifique des données.
Le sophisme du taux de base décrit la tendance d'une personne à ne pas tenir compte des informations existantes sur le taux de base, à pousser et à être en faveur des nouvelles informations. Cela va à l'encontre des règles fondamentales du raisonnement fondé sur des preuves.
Vous entendrez généralement parler de cela dans le secteur financier. Par exemple, les investisseurs baseront leurs tactiques d'achat ou de partage sur des informations irrationnelles, ce qui entraînera des fluctuations sur le marché, même s'ils connaissent le taux de base.
Nous avons donc maintenant une meilleure compréhension du taux de base et de l'erreur du taux de base. Quelle est sa pertinence et son impact en Data Science ?
Nous avons parlé de « probabilités de classes » et de « prise en compte de toutes les données pertinentes ». Si vous êtes un data scientist ou un ingénieur en apprentissage automatique, ou si vous mettez le pied dans la porte, vous saurez à quel point les probabilités et les données pertinentes sont importantes pour produire des résultats précis, le processus d'apprentissage de votre modèle d'apprentissage automatique et la production de modèles hautes performances.
Pour analyser et faire des prédictions sur les données ou pour que votre modèle d'apprentissage automatique produise des résultats précis, vous devez prendre en compte chaque élément de données. Lorsque vous parcourez vos données la première fois que vous les voyez, vous pouvez considérer certaines parties comme pertinentes et d’autres comme non pertinentes. Cependant, ceci est votre jugement et n’est pas encore factuel tant qu’une analyse appropriée n’a pas été effectuée.
Comme mentionné ci-dessus, le taux de base initial vous aide à garantir la précision et à produire des modèles performants. Alors, comment pouvons-nous faire cela en science des données ?
Matrice de confusion
Une matrice de confusion est une mesure de performance qui fournit un résumé des résultats de prédiction sur un problème de classification. Les matrices de confusion sont toutes basées sur le résultat : Vrai, Faux, Positif et Négatif.
La matrice de confusion représente les prédictions de notre modèle pendant la phase de test. Les faux négatifs et les faux positifs dans la matrice de confusion sont des exemples d’erreurs liées au taux de base.
- True Positive (TP) – votre modèle a prédit du positif et c'est positif
- Vrai négatif (TN) : votre modèle a prédit un résultat négatif et il est négatif.
- Faux positif (FP) : votre modèle a prédit un résultat positif et il est négatif.
- Faux négatif (FN) : votre modèle a prédit un résultat négatif et il est positif.
Une matrice de confusion peut calculer 5 métriques différentes pour nous aider à mesurer la validité de notre modèle :
- Mauvaise classification = FP + FN / TP + TN + FP + FN
- Précision = TP / TP + FP
- Précision = TP + TN / TP + TN + FP + FN
- Spécificité = VN / VN + FP
- Sensibilité alias Rappel = TP / TP + FN
Pour mieux comprendre une matrice de confusion, il est préférable de regarder une visualisation :
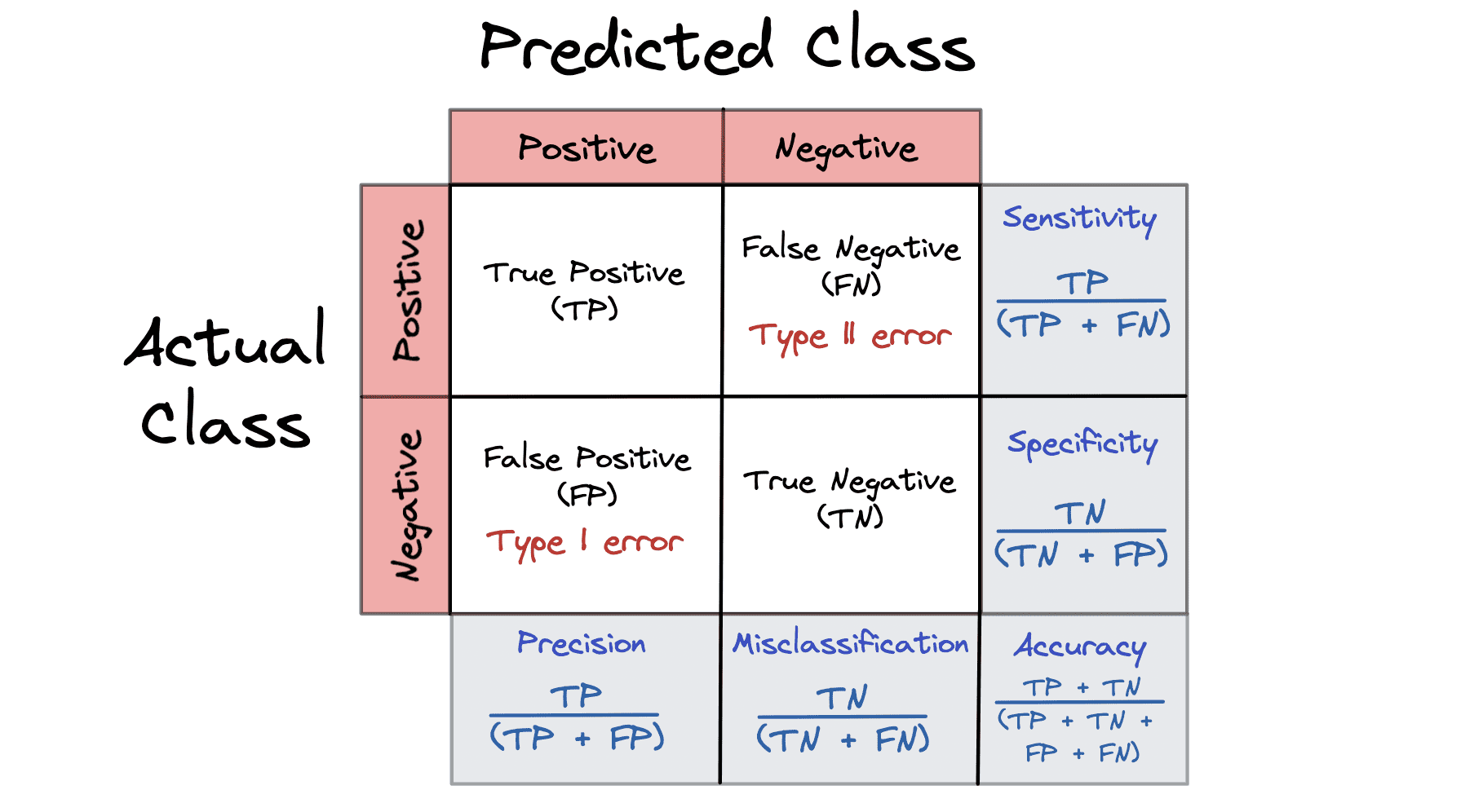
Image par auteur
Au fur et à mesure que vous parcourez cet article, vous pouvez probablement penser à diverses causes d'erreur de taux de base, telles que la non-prise en compte de toutes les données pertinentes, une erreur humaine ou un manque de précision.
Bien que tout cela soit vrai et ajoute à la cause de l'erreur du taux de base. Ils sont tous liés au plus gros problème d'ignorer les informations sur le taux de base en premier lieu. Les informations sur le taux de base sont souvent ignorées car elles sont considérées comme non pertinentes, cependant, les informations sur le taux de base peuvent faire économiser beaucoup de temps et d'argent. L'utilisation des informations disponibles sur le taux de base vous permet d'être plus précis dans l'établissement des probabilités quant à savoir si un événement donné se produira.
L'utilisation des informations sur le taux de base vous aidera à éviter les erreurs de taux de base.
Être conscient des erreurs telles que les opinions, les processus automatiques, etc. vous permettra de lutter contre le problème de l'erreur du taux de base et de réduire les erreurs potentielles. Lorsque vous mesurez la probabilité qu'un certain événement se produise, les méthodes bayésiennes peuvent vous aider à réduire l'erreur du taux de base.
Le taux de base est important en science des données car il vous permet d'acquérir une compréhension de base de la manière d'évaluer votre étude ou projet et d'affiner votre modèle, offrant ainsi une augmentation globale de la précision et des performances.
Si vous souhaitez regarder une vidéo sur l'erreur de taux de base dans le domaine médical, regardez cette vidéo : Paradoxe des tests médicaux
Nisha Arya est Data Scientist, rédacteur technique indépendant et Community Manager chez KDnuggets. Elle est particulièrement intéressée à fournir des conseils de carrière en science des données ou des tutoriels et des connaissances théoriques sur la science des données. Elle souhaite également explorer les différentes façons dont l'intelligence artificielle est/peut bénéficier à la longévité de la vie humaine. Une apprenante passionnée, cherchant à élargir ses connaissances techniques et ses compétences en écriture, tout en aidant à guider les autres.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- Frapper l'avenir avec Adryenn Ashley. Accéder ici.
- La source: https://www.kdnuggets.com/2023/04/base-rate-fallacy-impact-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-base-rate-fallacy-and-its-impact-on-data-science
- :possède
- :est
- :ne pas
- $UP
- a
- Qui sommes-nous
- au dessus de
- précision
- Avec cette connaissance vient le pouvoir de prendre
- conseils
- à opposer à
- Tous
- permet
- aussi
- an
- analyser
- selon une analyse de l’Université de Princeton
- l'analyse
- ainsi que
- SONT
- autour
- article
- artificiel
- intelligence artificielle
- AS
- hypothèse
- At
- Automatique
- disponibles
- base
- basé
- Bayésien
- BE
- philosophie
- profiter
- Améliorée
- biais
- Le plus grand
- Bit
- élargir
- Achat
- by
- calculer
- CAN
- Carrière
- Causes
- les causes
- certaines
- vérifier
- les classes
- classification
- lutter contre la
- combiner
- Communautés
- Société
- confusion
- Considérer
- considération
- considéré
- données
- science des données
- Data Scientist
- Malgré
- développement
- différent
- Porte
- pendant
- ingénieur
- assurer
- erreur
- Erreurs
- etc
- événement
- Chaque
- preuve
- Examiner
- exemple
- exemples
- existant
- explorez
- Les faits
- défectueux
- champ
- la traduction de documents financiers
- Prénom
- première fois
- fluctuation
- Pied
- Pour
- freelance
- fondamental
- obtention
- Donner
- donné
- Goes
- aller
- plus grand
- guide
- EN COURS
- Vous avez
- ayant
- entendre
- aider
- aider
- aide
- haute performance
- Comment
- How To
- Cependant
- HTTPS
- humain
- Ignorance
- Impact
- important
- améliorer
- in
- Améliore
- industrie
- d'information
- initiale
- Intelligence
- intéressé
- développement
- Investisseurs
- aide
- IT
- SES
- KDnuggetsGenericName
- Vif
- Savoir
- spécialisées
- connu
- Peindre
- Conduit
- apprenant
- apprentissage
- VIE
- comme
- longévité
- Style
- Lot
- Faible
- click
- machine learning
- faire
- Fabrication
- manager
- Marché
- Matrice
- Mai..
- veux dire
- mesurer
- mesure
- médical
- mentionné
- méthodes
- Métrique
- pourrait
- modèle
- numériques jumeaux (digital twin models)
- de l'argent
- PLUS
- Besoin
- négatif
- Nouveauté
- maintenant
- of
- on
- ONE
- uniquement
- Avis
- or
- Autre
- Autres
- nos
- Résultat
- sortie
- global
- partie
- particulièrement
- les pièces
- Personnes
- effectuer
- performant
- Pharmaceutique
- phase
- Place
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- positif
- défaillances
- précis
- La précision
- prédit
- prédiction
- Prédictions
- Avant
- probabilité
- Probablement
- Problème
- processus
- les process
- produire
- Produit
- Projet
- correct
- correctement
- fournit
- aportando
- Push
- Tarif
- Tarifs
- Les raisons
- réduire
- pertinence
- pertinent
- représente
- un article
- Résultats
- s
- Épargnez
- balayage
- Sciences
- Scientifique
- recherche
- partage
- situation
- compétences
- So
- quelques
- Quelqu'un
- groupe de neurones
- scission
- statistiques
- Étude
- succès
- Avec succès
- tel
- RÉSUMÉ
- tactique
- Prenez
- prise
- technologie
- Technique
- tester
- Essais
- que
- qui
- La
- leur
- Ces
- this
- complètement
- Avec
- fiable
- à
- les outils
- traitement
- oui
- tutoriels
- typiquement
- inconditionnel
- comprendre
- compréhension
- us
- d'utiliser
- Plus-value
- variété
- divers
- Vidéo
- Montres
- façons
- we
- WELL
- Quoi
- Qu’est ce qu'
- que
- qui
- Si l’achat
- WHO
- sera
- prêt
- vœux
- comprenant
- des mots
- de travail
- world
- pourra
- écrivain
- écriture
- you
- Votre
- zéphyrnet








