Studio de colle AWS est une interface graphique qui facilite la création, l'exécution et la surveillance des tâches d'extraction, de transformation et de chargement (ETL) dans Colle AWS. Il vous permet de composer visuellement des workflows de transformation de données à l'aide de nœuds qui représentent différentes étapes de traitement des données, qui sont ensuite converties automatiquement en code à exécuter.
Studio de colle AWS récemment publié 10 transformations visuelles supplémentaires pour permettre de créer des travaux plus avancés de manière visuelle sans compétences de codage. Dans cet article, nous discutons des cas d'utilisation potentiels qui reflètent les besoins ETL courants.
Les nouvelles transformations qui seront présentées dans cet article sont les suivantes : concaténer, diviser la chaîne, tableau en colonnes, ajouter l'horodatage actuel, faire pivoter les lignes en colonnes, annuler le pivot des colonnes en lignes, rechercher, exploser le tableau ou mapper en colonnes, colonne dérivée et traitement d'équilibrage automatique. .
Vue d'ensemble de la solution
Dans ce cas d'utilisation, nous avons des fichiers JSON avec des opérations d'options sur actions. Nous souhaitons effectuer certaines transformations avant de stocker les données pour faciliter leur analyse, et nous souhaitons également produire un résumé séparé de l'ensemble de données.
Dans cet ensemble de données, chaque ligne représente une transaction de contrats d'option. Les options sont des instruments financiers qui donnent le droit, mais non l'obligation, d'acheter ou de vendre des actions à un prix fixe (appelé prix d'exercice) avant une date d'expiration définie.
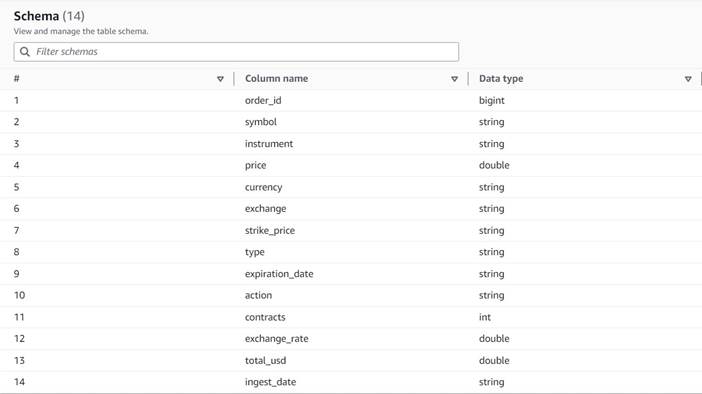
Des données d'entrée
Les données suivent le schéma suivant :
- numéro de commande – Un identifiant unique
- symbole – Un code généralement basé sur quelques lettres pour identifier la société qui émet les actions sous-jacentes
- instrument – Le nom qui identifie l'option spécifique achetée ou vendue
- monnaie – Le code de devise ISO dans lequel le prix est exprimé
- prix – Le montant qui a été payé pour l'achat de chaque contrat d'option (sur la plupart des bourses, un contrat vous permet d'acheter ou de vendre 100 actions)
- échange – Le code du centre d'échange ou du lieu où l'option a été négociée
- vendu - Une liste du nombre de contrats qui ont été alloués pour remplir l'ordre de vente lorsqu'il s'agit d'une transaction de vente
- acheté - Une liste du nombre de contrats qui ont été alloués pour remplir l'ordre d'achat lorsqu'il s'agit d'un échange d'achat
Voici un exemple des données synthétiques générées pour cet article :
Exigences ETL
Ces données ont un certain nombre de caractéristiques uniques, que l'on trouve souvent sur les systèmes plus anciens, qui rendent les données plus difficiles à utiliser.
Voici les exigences ETL :
- Le nom de l'instrument contient des informations précieuses destinées à être comprises par les humains ; nous voulons le normaliser dans des colonnes séparées pour une analyse plus facile.
- Les attributs
boughtainsi quesolds'excluent mutuellement ; nous pouvons les regrouper dans une seule colonne avec les numéros de contrat et avoir une autre colonne indiquant si les contrats ont été achetés ou vendus dans cet ordre. - Nous souhaitons conserver les informations sur les attributions de contrats individuels, mais sous forme de lignes individuelles au lieu d'obliger les utilisateurs à traiter un tableau de nombres. Nous pourrions additionner les chiffres, mais nous perdrions des informations sur la façon dont l'ordre a été rempli (indiquant la liquidité du marché). Au lieu de cela, nous choisissons de dénormaliser le tableau afin que chaque ligne ait un seul nombre de contrats, en divisant les commandes avec plusieurs nombres en lignes séparées. Dans un format en colonnes compressé, la taille supplémentaire de l'ensemble de données de cette répétition est souvent faible lorsque la compression est appliquée, il est donc acceptable de rendre l'ensemble de données plus facile à interroger.
- Nous voulons générer un tableau récapitulatif du volume pour chaque type d'option (call et put) pour chaque action. Cela donne une indication du sentiment du marché pour chaque action et du marché en général (avidité contre peur).
- Pour activer les résumés commerciaux globaux, nous voulons fournir pour chaque opération le total général et normaliser la devise en dollars américains, en utilisant une référence de conversion approximative.
- Nous voulons ajouter la date à laquelle ces transformations ont eu lieu. Cela pourrait être utile, par exemple, pour avoir une référence sur le moment où la conversion de devise a été effectuée.
Sur la base de ces exigences, le travail produira deux résultats :
- Un fichier CSV avec un résumé du nombre de contrats pour chaque symbole et type
- Une table de catalogue pour garder un historique de la commande, après avoir fait les transformations indiquées
Pré-requis
Vous aurez besoin de votre propre compartiment S3 pour suivre ce cas d'utilisation. Pour créer un nouveau bucket, reportez-vous à Créer un bucket.
Générer des données synthétiques
Pour suivre cet article (ou expérimenter vous-même ce type de données), vous pouvez générer cet ensemble de données de manière synthétique. Le script Python suivant peut être exécuté dans un environnement Python avec Boto3 installé et un accès à Service de stockage simple Amazon (Amazon S3).
Pour générer les données, procédez comme suit :
- Sur AWS Glue Studio, créez une nouvelle tâche avec l'option Éditeur de script shell Python.
- Donnez un nom au travail et sur le Détails du poste onglet, sélectionnez un rôle approprié et un nom pour le script Python.
- Dans le Détails du poste section, développez Propriétés avancées et faites défiler jusqu'à Paramètres du travail.
- Entrez un paramètre nommé
--bucketet affectez comme valeur le nom du bucket que vous souhaitez utiliser pour stocker les exemples de données. - Entrez le script suivant dans l'éditeur de shell AWS Glue :
- Exécutez la tâche et attendez qu'elle s'affiche comme terminée avec succès dans l'onglet Exécutions (cela ne devrait prendre que quelques secondes).
Chaque exécution générera un fichier JSON avec 1,000 XNUMX lignes sous le compartiment spécifié et le préfixe transformsblog/inputdata/. Vous pouvez exécuter la tâche plusieurs fois si vous souhaitez tester avec plus de fichiers d'entrée.
Chaque ligne des données synthétiques est une ligne de données représentant un objet JSON comme suit :
Créer la tâche visuelle AWS Glue
Pour créer la tâche visuelle AWS Glue, procédez comme suit :
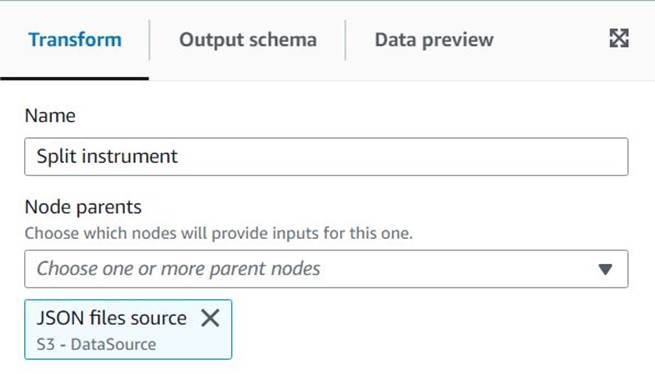
- Accédez à AWS Glue Studio et créez une tâche à l'aide de l'option Visuel avec une toile vierge.
- Modifier
Untitled jobpour lui donner un nom et lui attribuer un rôle adapté à AWS Glue sur le Détails du poste languette. - Ajoutez une source de données S3 (vous pouvez la nommer
JSON files source) et entrez l'URL S3 sous laquelle les fichiers sont stockés (par exemple,s3://<your bucket name>/transformsblog/inputdata/), puis sélectionnez JSON comme format de données. - Sélectionnez Déduire le schéma il définit donc le schéma de sortie en fonction des données.
À partir de ce nœud source, vous continuerez à enchaîner les transformations. Lors de l'ajout de chaque transformation, assurez-vous que le nœud sélectionné est le dernier ajouté afin qu'il soit affecté en tant que parent, sauf indication contraire dans les instructions.
Si vous n'avez pas sélectionné le bon parent, vous pouvez toujours modifier le parent en le sélectionnant et en choisissant un autre parent dans le volet de configuration.
Pour chaque nœud ajouté, vous lui donnerez un nom spécifique (afin que l'objectif du nœud s'affiche dans le graphique) et une configuration sur le Transformer languette.
Chaque fois qu'une transformation modifie le schéma (par exemple, ajouter une nouvelle colonne), le schéma de sortie doit être mis à jour afin qu'il soit visible pour les transformations en aval. Vous pouvez modifier manuellement le schéma de sortie, mais il est plus pratique et plus sûr de le faire en utilisant l'aperçu des données.
De plus, vous pouvez ainsi vérifier que la transformation fonctionne jusqu'à présent comme prévu. Pour ce faire, ouvrez le Aperçu des données onglet avec la transformation sélectionnée et démarrez une session de prévisualisation. Une fois que vous avez vérifié que les données transformées sont conformes à vos attentes, accédez à la Schéma de sortie onglet et choisissez Utiliser le schéma d'aperçu des données pour mettre à jour le schéma automatiquement.
Lorsque vous ajoutez de nouveaux types de transformations, l'aperçu peut afficher un message concernant une dépendance manquante. Lorsque cela se produit, choisissez Fin de session et le démarrer un nouveau, de sorte que l'aperçu récupère le nouveau type de nœud.
Extraire les informations sur l'instrument
Commençons par traiter les informations sur le nom de l'instrument pour les normaliser dans des colonnes plus faciles d'accès dans la table de sortie résultante.
- Ajouter un Chaîne fractionnée noeud et nommez-le
Split instrument, qui tokenisera la colonne d'instrument à l'aide d'une regex d'espace :s+(un seul espace ferait l'affaire dans ce cas, mais cette manière est plus flexible et visuellement plus claire). - Nous souhaitons conserver telles quelles les informations d'origine sur l'instrument. Saisissez donc un nouveau nom de colonne pour le tableau divisé :
instrument_arr.
- Ajouter un Tableau en colonnes noeud et nommez-le
Instrument columnspour convertir la colonne de tableau que vous venez de créer en nouveaux champs, à l'exception desymbol, pour lequel nous avons déjà une colonne. - Sélectionnez la colonne
instrument_arr, ignorez le premier jeton et dites-lui d'extraire les colonnes de sortiemonth, day, year, strike_price, typeutilisation d'index2, 3, 4, 5, 6(les espaces après les virgules sont pour la lisibilité, ils n'impactent pas la configuration).
L'année extraite est exprimée avec deux chiffres seulement ; mettons un palliatif pour supposer que c'est dans ce siècle s'ils n'utilisent que deux chiffres.
- Ajouter un Colonne dérivée noeud et nommez-le
Four digits year. - Entrer
yearcomme colonne dérivée afin qu'elle la remplace, puis saisissez l'expression SQL suivante :CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Pour plus de commodité, nous construisons un expiration_date champ qu'un utilisateur peut avoir comme référence de la dernière date à laquelle l'option peut être exercée.
- Ajouter un Concaténer des colonnes noeud et nommez-le
Build expiration date. - Nommez la nouvelle colonne
expiration_date, sélectionnez les colonnesyear,monthetday(dans cet ordre), et un trait d'union comme espaceur.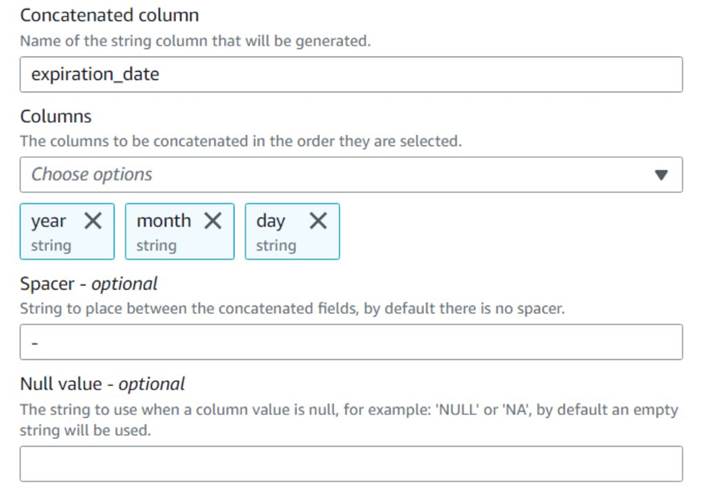
Jusqu'à présent, le diagramme devrait ressembler à l'exemple suivant.
![]()
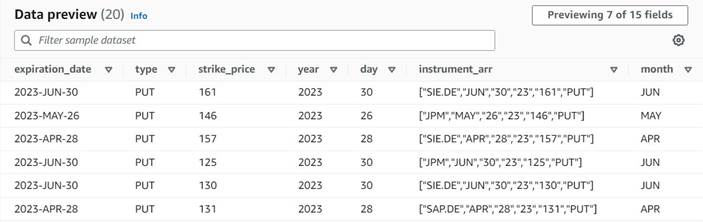
L'aperçu des données des nouvelles colonnes jusqu'à présent devrait ressembler à la capture d'écran suivante.
Normaliser le nombre de contrats
Chacune des lignes des données indique le nombre de contrats de chaque option qui ont été achetés ou vendus et les lots sur lesquels les commandes ont été remplies. Sans perdre les informations sur les lots individuels, nous voulons avoir chaque montant sur une ligne individuelle avec une valeur de montant unique, tandis que le reste des informations est répliqué dans chaque ligne produite.
Tout d'abord, fusionnons les montants dans une seule colonne.
- Ajouter un Dépivoter les colonnes en lignes noeud et nommez-le
Unpivot actions. - Choisissez les colonnes
boughtainsi quesoldpour annuler le pivot et stocker les noms et les valeurs dans des colonnes nomméesactionainsi quecontracts, Respectivement.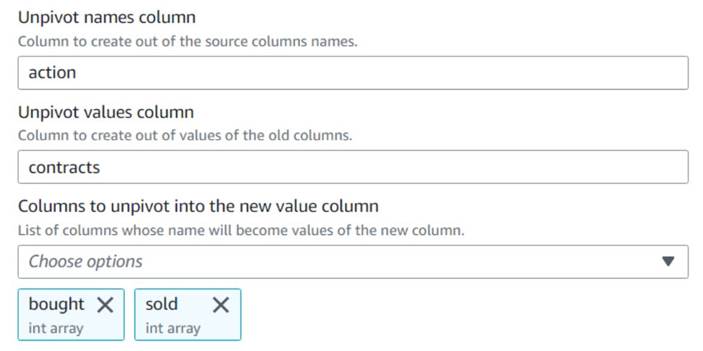
Notez dans l'aperçu que la nouvelle colonnecontractsest toujours un tableau de nombres après cette transformation.
- Ajouter un Décomposer le tableau ou la carte en lignes rangée nommée
Explode contracts. - Choisissez le
contractscolonne et entrercontractscomme nouvelle colonne pour la remplacer (nous n'avons pas besoin de conserver le tableau d'origine).
L'aperçu montre maintenant que chaque ligne a un seul contracts montant, et le reste des champs sont les mêmes.
Cela signifie également que order_id n'est plus une clé unique. Pour vos propres cas d'utilisation, vous devez décider comment modéliser vos données et si vous souhaitez dénormaliser ou non.
La capture d'écran suivante est un exemple de ce à quoi ressemblent les nouvelles colonnes après les transformations jusqu'à présent.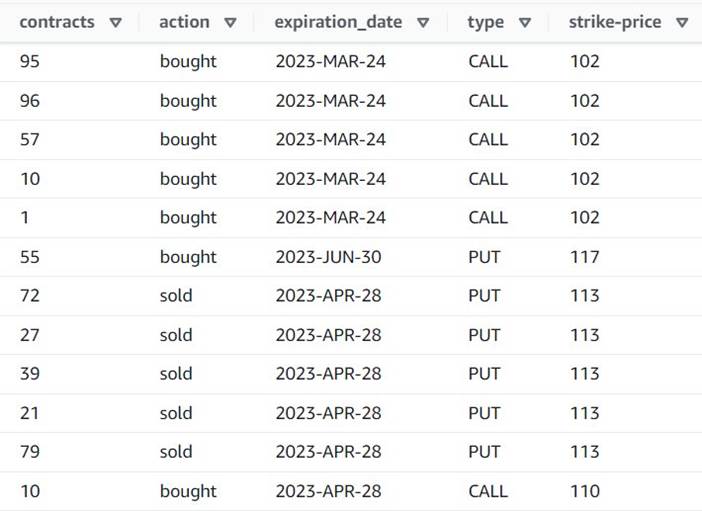
Créer un tableau récapitulatif
Vous créez maintenant un tableau récapitulatif avec le nombre de contrats négociés pour chaque type et chaque symbole boursier.
Supposons, à des fins d'illustration, que les fichiers traités appartiennent à une seule journée, ce résumé donne donc aux utilisateurs professionnels des informations sur l'intérêt et le sentiment du marché ce jour-là.
- Ajouter un Sélectionnez les champs nœud et sélectionnez les colonnes suivantes à conserver pour le résumé :
symbol,typeetcontracts.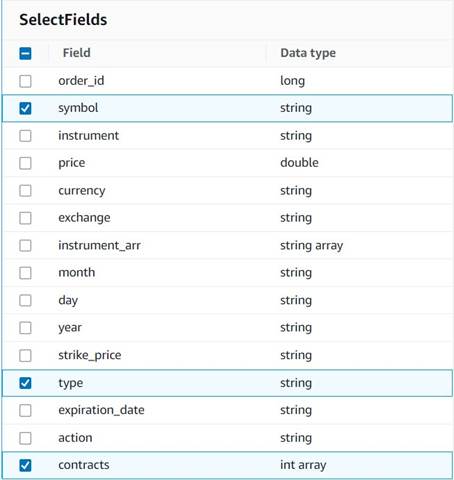
- Ajouter un Faire pivoter les lignes en colonnes noeud et nommez-le
Pivot summary. - Agrégé sur le
contractscolonne utilisantsumet choisir de convertirtypecolonne.
Normalement, vous le stockeriez sur une base de données ou un fichier externe pour référence ; dans cet exemple, nous l'enregistrons en tant que fichier CSV sur Amazon S3.
- Ajouter un Traitement de l'équilibrage automatique noeud et nommez-le
Single output file. - Bien que ce type de transformation soit normalement utilisé pour optimiser le parallélisme, nous l'utilisons ici pour réduire la sortie à un seul fichier. Par conséquent, entrez
1dans la configuration du nombre de partitions.
- Ajoutez une cible S3 et nommez-la
CSV Contract summary. - Choisissez CSV comme format de données et entrez un chemin S3 où le rôle de travail est autorisé à stocker des fichiers.
La dernière partie du travail devrait maintenant ressembler à l'exemple suivant.![]()
- Enregistrez et exécutez la tâche. Utilisez le Fonctionne onglet pour vérifier quand il a terminé avec succès.
Vous trouverez un fichier sous ce chemin qui est un CSV, même s'il n'a pas cette extension. Vous devrez probablement ajouter l'extension après l'avoir téléchargée pour l'ouvrir.
Sur un outil qui peut lire le CSV, le résumé devrait ressembler à l'exemple suivant.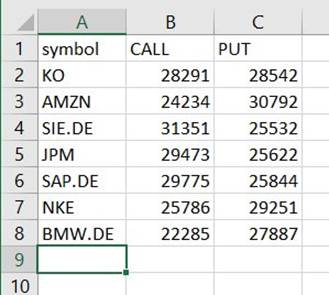
Nettoyer les colonnes temporaires
En prévision de l'enregistrement des commandes dans un tableau historique pour une analyse future, nettoyons certaines colonnes temporaires créées en cours de route.
- Ajouter un Déposer des champs noeud avec le
Explode contractsnœud sélectionné comme parent (nous branchons le pipeline de données pour générer une sortie distincte). - Sélectionnez les champs à supprimer :
instrument_arr,month,dayetyear.
Le reste, nous voulons le conserver afin qu'il soit enregistré dans le tableau historique que nous créerons plus tard.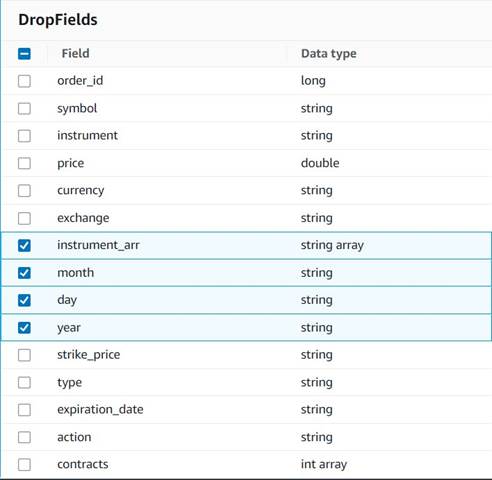
Normalisation monétaire
Ces données synthétiques contiennent des opérations fictives sur deux devises, mais dans un système réel, vous pourriez obtenir des devises sur les marchés du monde entier. Il est utile de standardiser les devises traitées dans une seule devise de référence afin qu'elles puissent être facilement comparées et agrégées pour les rapports et l'analyse.
Nous utilisons Amazone Athéna pour simuler un tableau avec des conversions de devises approximatives qui est mis à jour périodiquement (ici, nous supposons que nous traitons les commandes suffisamment rapidement pour que la conversion soit un représentant raisonnable à des fins de comparaison).
- Ouvrez la console Athena dans la même région où vous utilisez AWS Glue.
- Exécutez la requête suivante pour créer la table en définissant un emplacement S3 où vos rôles Athena et AWS Glue peuvent lire et écrire. En outre, vous souhaiterez peut-être stocker la table dans une base de données différente de celle
default(si vous faites cela, mettez à jour le nom qualifié de la table en conséquence dans les exemples fournis). - Saisissez quelques exemples de conversions dans le tableau :
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Vous devriez maintenant pouvoir afficher le tableau avec la requête suivante :
SELECT * FROM default.exchange_rates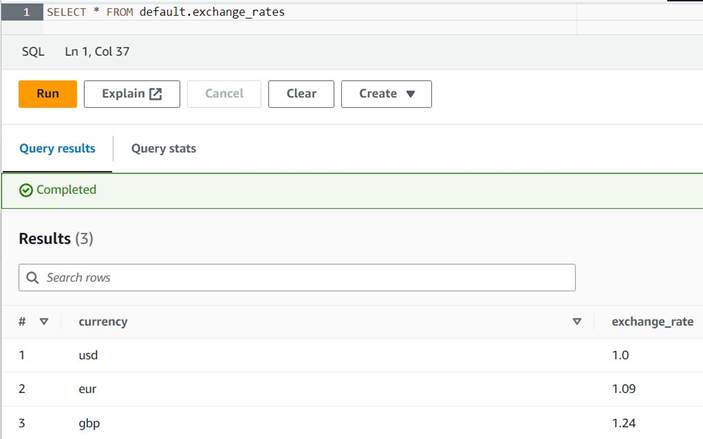
- De retour sur la tâche visuelle AWS Glue, ajoutez un Lookup nœud (en tant qu'enfant de
Drop Fields) et nommez-leExchange rate. - Entrez le nom qualifié de la table que vous venez de créer, en utilisant
currencycomme touche et sélectionnez laexchange_ratechamp à utiliser.
Étant donné que le champ porte le même nom dans les données et dans la table de recherche, nous pouvons simplement entrer le nomcurrencyet n'ont pas besoin de définir un mappage.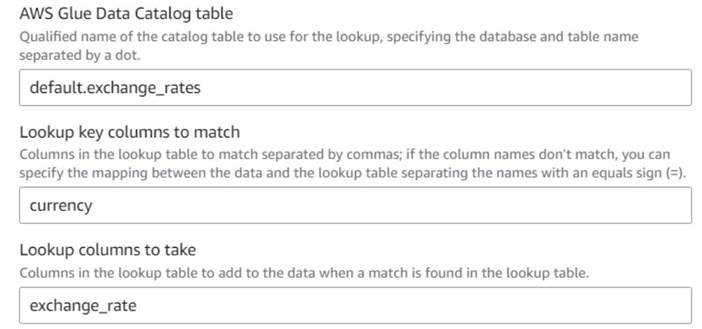
Au moment d'écrire ces lignes, la transformation Lookup n'est pas prise en charge dans l'aperçu des données et elle affichera une erreur indiquant que la table n'existe pas. Ceci est uniquement pour l'aperçu des données et n'empêche pas le travail de s'exécuter correctement. Les quelques étapes restantes de la publication ne vous obligent pas à mettre à jour le schéma. Si vous devez exécuter un aperçu des données sur d'autres nœuds, vous pouvez supprimer temporairement le nœud de recherche, puis le remettre en place. - Ajouter un Colonne dérivée noeud et nommez-le
Total in usd. - Nommez la colonne dérivée
total_usdet utilisez l'expression SQL suivante :round(contracts * price * exchange_rate, 2)
- Ajouter un Ajouter l'horodatage actuel noeud et nommez la colonne
ingest_date. - Utiliser le format
%Y-%m-%dpour votre horodatage (à des fins de démonstration, nous utilisons simplement la date ; vous pouvez la rendre plus précise si vous le souhaitez).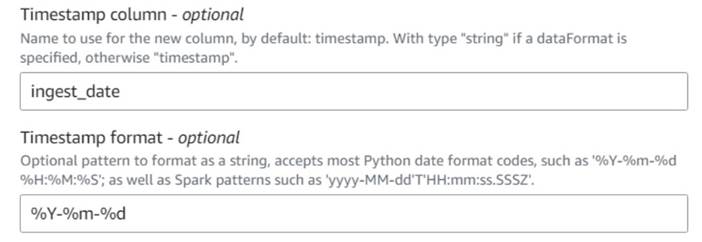
Enregistrer le tableau des commandes historiques
Pour enregistrer le tableau des commandes historiques, procédez comme suit :
- Ajoutez un nœud cible S3 et nommez-le
Orders table. - Configurez le format Parquet avec une compression rapide et fournissez un chemin cible S3 sous lequel stocker les résultats (séparé du résumé).
- Sélectionnez Créer une table dans le catalogue de données et lors des exécutions suivantes, mettre à jour le schéma et ajouter de nouvelles partitions.
- Saisissez une base de données cible et un nom pour la nouvelle table, par exemple :
option_orders.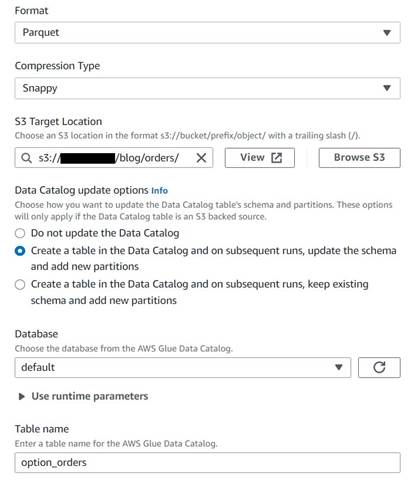
La dernière partie du diagramme devrait maintenant ressembler à ce qui suit, avec deux branches pour les deux sorties séparées.![]()
Après avoir exécuté la tâche avec succès, vous pouvez utiliser un outil tel qu'Athena pour examiner les données produites par la tâche en interrogeant la nouvelle table. Vous pouvez trouver le tableau sur la liste Athena et choisir Tableau de prévisualisation ou exécutez simplement une requête SELECT (en mettant à jour le nom de la table avec le nom et le catalogue que vous avez utilisés) :
SELECT * FROM default.option_orders limit 10
Le contenu de votre tableau doit ressembler à la capture d'écran suivante.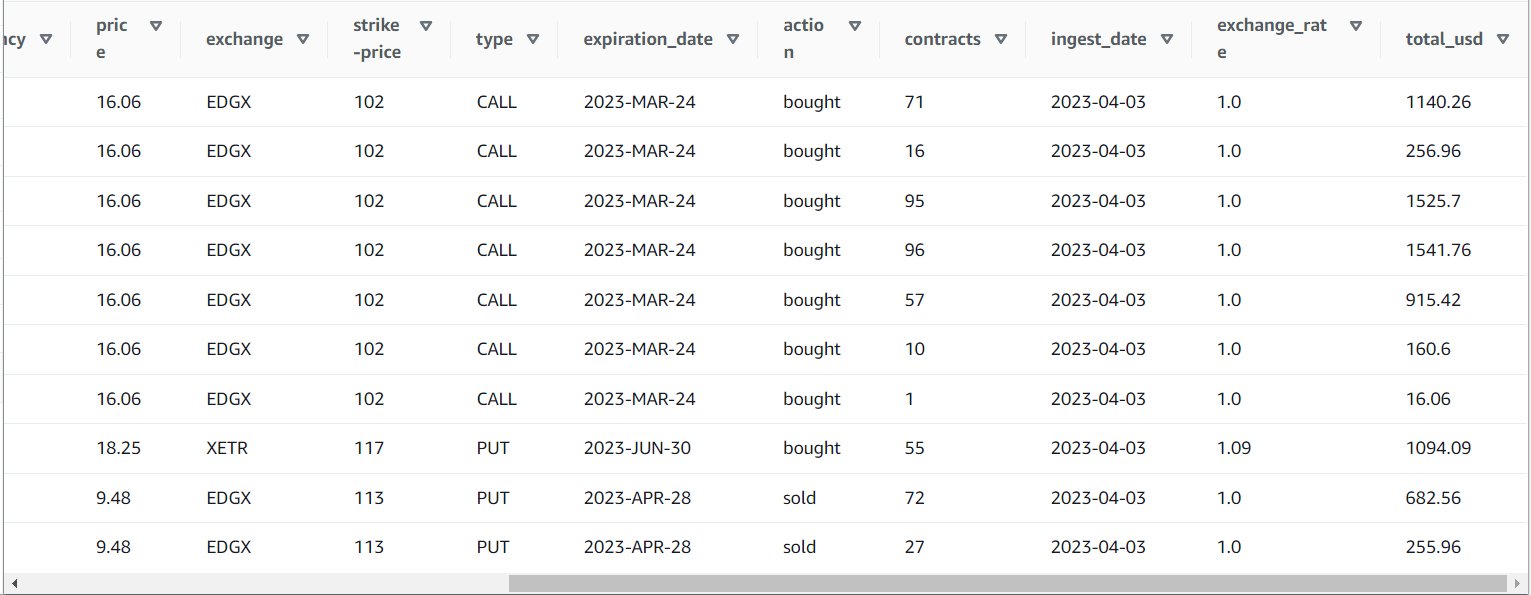
Nettoyer
Si vous ne souhaitez pas conserver cet exemple, supprimez les deux tâches que vous avez créées, les deux tables dans Athena et les chemins S3 où les fichiers d'entrée et de sortie étaient stockés.
Conclusion
Dans cet article, nous avons montré comment les nouvelles transformations d'AWS Glue Studio peuvent vous aider à effectuer des transformations plus avancées avec une configuration minimale. Cela signifie que vous pouvez implémenter plus de cas d'utilisation ETL sans avoir à écrire et à maintenir de code. Les nouvelles transformations sont déjà disponibles sur AWS Glue Studio, vous pouvez donc les utiliser dès aujourd'hui dans vos tâches visuelles.
A propos de l'auteure
![]() Gonzalo herreros est architecte Big Data senior au sein de l'équipe AWS Glue.
Gonzalo herreros est architecte Big Data senior au sein de l'équipe AWS Glue.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- Frapper l'avenir avec Adryenn Ashley. Accéder ici.
- Achetez et vendez des actions de sociétés PRE-IPO avec PREIPO®. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :possède
- :est
- :ne pas
- :où
- $UP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- Capable
- Qui sommes-nous
- acceptable
- accès
- en conséquence
- ajouter
- ajoutée
- ajoutant
- Avancée
- Après
- Tous
- consacrée
- allocations
- permettre
- permet
- le long de
- déjà
- aussi
- toujours
- Amazon
- montant
- quantités
- an
- selon une analyse de l’Université de Princeton
- il analyse
- ainsi que
- Une autre
- tous
- appliqué
- approximatif
- avr
- SONT
- argument
- tableau
- AS
- attribué
- At
- attributs
- automatiquement
- disponibles
- AWS
- Colle AWS
- RETOUR
- basé
- BE
- before
- va
- Big
- Big Data
- vide
- BMW
- tous les deux
- acheté
- branches
- construire
- la performance des entreprises
- mais
- acheter
- by
- Appelez-nous
- CAN
- maisons
- cas
- catalogue
- Canaux centraux
- siècle
- Modifications
- caractéristiques
- vérifier
- enfant
- Selectionnez
- choose
- plus clair
- code
- Codage
- Colonne
- Colonnes
- Commun
- par rapport
- Comparaison
- complet
- Complété
- configuration
- Console
- consolider
- contient
- contenu
- contrat
- contrats
- commodité
- Conversion
- conversions
- convertir
- converti
- SOCIÉTÉ
- pourriez
- engendrent
- créée
- La création
- devises
- Devise
- Courant
- JOUR
- données
- Base de données
- Date
- Dates
- datetime
- journée
- affaire
- traitement
- décider
- Réglage par défaut
- défini
- démontré
- Dépendance
- Dérivé
- Malgré
- détails
- différent
- chiffres
- discuter
- do
- Ne fait pas
- faire
- dollars
- Ne pas
- double
- down
- Goutte
- chuté
- chacun
- plus facilement
- même
- Easy
- éditeur
- permettre
- assez
- Entrer
- Environment
- erreur
- Ether (ETH)
- EUR
- exemple
- exemples
- Sauf
- échange
- Échanges
- Exclusive
- exister
- Développer vous
- attendu
- expérience
- expiration
- exprimé
- extension
- externe
- supplémentaire
- extrait
- loin
- peur
- few
- fictif
- champ
- Des champs
- Déposez votre dernière attestation
- Fichiers
- remplir
- rempli
- la traduction de documents financiers
- Instruments financiers
- Trouvez
- Prénom
- fixé
- flexible
- suivre
- Abonnement
- suit
- Pour
- le format
- trouvé
- de
- avenir
- GBP
- Général
- généralement
- générer
- généré
- obtenez
- Donner
- donne
- Go
- graphique
- Cupidité
- Maniabilité
- arrive
- Vous avez
- ayant
- aider
- ici
- historique
- Histoire
- Comment
- How To
- HTML
- http
- HTTPS
- Les êtres humains
- i
- identifie
- identifier
- if
- Impact
- Mettre en oeuvre
- importer
- in
- index
- indiqué
- indique
- indiquant
- indication
- individuel
- d'information
- contribution
- instance
- plutôt ;
- Des instructions
- instrument
- instruments
- intérêt
- Interfaces
- développement
- ISO
- IT
- SES
- Emploi
- Emplois
- jpg
- json
- juste
- XNUMX éléments à
- ACTIVITES
- Genre
- Nom de famille
- plus tard
- comme
- LIMIT
- Gamme
- Liquidité
- Liste
- charge
- emplacement
- plus long
- Style
- ressembler
- LOOKS
- rechercher
- perdre
- pas à perdre
- LES PLANTES
- maintenir
- faire
- FAIT DU
- manuellement
- Localisation
- cartographie
- Marché
- Sentiment du marché
- Marchés
- Mai..
- veux dire
- aller
- message
- pourrait
- minimum
- manquant
- modèle
- Surveiller
- PLUS
- (en fait, presque toutes)
- plusieurs
- mutuellement
- prénom
- Nommé
- noms
- Besoin
- Besoins
- Nouveauté
- aucune
- nœud
- nœuds
- normalement
- maintenant
- nombre
- numéros
- objet
- of
- souvent
- on
- ONE
- uniquement
- ouvert
- opération
- Opérations
- Optimiser
- Option
- Options
- or
- de commander
- passer commande
- original
- Autre
- autrement
- sortie
- plus de
- global
- Commande
- propre
- payé
- pain
- paramètre
- partie
- chemin
- Choix
- pipeline
- Pivoter
- Place
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Post
- défaillances
- Méthode
- précis
- empêcher
- Aperçu
- prix
- Probablement
- processus
- traitement
- produire
- Produit
- fournir
- à condition de
- fournit
- achat
- but
- des fins
- mettre
- Python
- qualifié
- augmenter
- aléatoire
- Lire
- réal
- raisonnable
- réduire
- refléter
- région
- restant
- supprimez
- répliquées
- Rapports
- représentent
- représentant
- représentation
- représente
- exigent
- Exigences
- a besoin
- respectivement
- REST
- résultant
- Résultats
- Avis
- Rôle
- rôle
- RANGÉE
- Courir
- pour le running
- plus sûre
- même
- sève
- Épargnez
- économie
- volute
- secondes
- choisi
- la sélection
- vendre
- supérieur
- sentiment
- séparé
- Session
- Sets
- mise
- Partages
- coquillage
- devrait
- montrer
- Spectacles
- similaires
- étapes
- unique
- Taille
- compétences
- petit
- So
- jusqu'à présent
- vendu
- quelques
- quelque chose
- Identifier
- Space
- espaces
- groupe de neurones
- spécifié
- scission
- Tableur
- SQL
- Commencer
- Étapes
- Encore
- stock
- storage
- Boutique
- stockée
- Chaîne
- studio
- ultérieur
- Avec succès
- convient
- RÉSUMÉ
- Appareils
- symbole
- haute
- données synthétiques
- synthétiquement
- combustion propre
- Système
- table
- Prenez
- Target
- équipe
- dire
- temporaire
- Dix
- tester
- que
- qui
- Les
- Le graphique
- les informations
- le monde
- Les
- puis
- donc
- Ces
- l'ont
- this
- ceux
- fiable
- fois
- horodatage
- à
- aujourd'hui
- jeton
- tokenize
- a
- outil
- Total
- commerce
- échangés
- Transformer
- De La Carrosserie
- transformations
- transformé
- deux
- type
- sous
- sous-jacent
- comprendre
- unique
- jusqu'à
- Mises à jour
- a actualisé
- la mise à jour
- URL
- us
- US Dollars
- USD
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- utilisateurs
- en utilisant
- Précieux
- Des informations précieuses
- Plus-value
- Valeurs
- Lieu
- vérifié
- vérifier
- Voir
- visible
- le volume
- vs
- attendez
- souhaitez
- était
- Façon..
- we
- ont été
- Quoi
- quand
- qui
- tout en
- sera
- comprenant
- sans
- workflows
- de travail
- world
- pourra
- écrire
- écriture
- an
- you
- Votre
- zéphyrnet











