Il s'agit d'une idée intéressante, qui utilise le parallélisme spéculatif pris en charge par le matériel pour accélérer la simulation, avec une particularité nécessitant un matériel personnalisé. Paul Cunningham (vice-président principal/directeur général, vérification chez Cadence), Raúl Camposano (silicon catalyst, entrepreneur, ancien CTO de Synopsys et maintenant CTO de Silvaco) et moi-même poursuivons notre série sur les idées de recherche. Comme toujours, les commentaires sont les bienvenus.

L'innovation
Le choix de ce mois-ci est Chronos : un parallélisme spéculatif efficace pour les accélérateurs. Les auteurs ont présenté l'article lors de la conférence 2020 sur le support architectural pour les langages de programmation et les systèmes d'exploitation et sont du MIT.
L'exploitation du parallélisme à l'aide de processeurs multicœurs est une option pour les applications où le parallélisme va de soi. D’autres algorithmes pourraient ne pas être aussi facilement partitionnés mais pourraient bénéficier d’une exécution spéculative exploitant le parallélisme intrinsèque. Habituellement, l'exécution spéculative dépend de la cohérence du cache, ce qui représente une surcharge importante, en particulier pour la simulation. Cette méthode contourne le besoin de cohérence, en localisant physiquement l'exécution des tâches pour calculer les tuiles par objet cible en lecture-écriture, garantissant ainsi que la détection des conflits peut être détectée localement, sans avoir besoin d'une gestion globale de la cohérence. Les tâches peuvent s'exécuter de manière spéculative en parallèle ; tout conflit détecté peut être déroulé d'une tâche via ses tâches enfants, puis réexécuté sans qu'il soit nécessaire de bloquer les autres threads.
Un autre point à noter ici. Cette méthode prend en charge la simulation basée sur le délai, contrairement à la plupart des techniques d'accélération matérielle.
le point de vue de Paul
Wow, quel merveilleux article à indice d'octane élevé du MIT ! Lorsqu'on m'interroge sur le calcul parallèle, je pense immédiatement aux threads, aux mutex et à la cohérence de la mémoire. C’est bien sûr ainsi que sont conçus les processeurs multicœurs modernes. Mais ce n’est pas le seul moyen de prendre en charge la parallélisation matérielle.
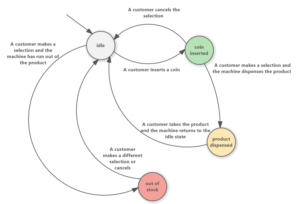
Cet article propose une architecture alternative de parallélisation appelée Chronos, basée sur une file d'attente ordonnée de tâches. Au moment de l'exécution, les tâches sont exécutées dans l'ordre d'horodatage et chaque tâche peut créer de nouvelles sous-tâches qui sont ajoutées dynamiquement à la file d'attente. L'exécution commence par la mise en file d'attente de certaines tâches initiales et se termine lorsqu'il n'y a plus de tâches dans la file d'attente.
Les tâches dans la file d'attente sont confiées à plusieurs éléments de traitement (PE) en parallèle, ce qui signifie que Chronos exécute de manière spéculative les tâches futures avant que la tâche en cours ne soit terminée. Si la tâche actuelle invalide toute tâche future exécutée de manière spéculative, alors les actions de ces tâches futures sont « annulées » et elles sont remises en file d'attente. Implémenter correctement ce concept dans le matériel n'est pas facile, mais pour l'utilisateur extérieur, c'est magnifique : il vous suffit de coder votre algorithme comme si la file d'attente des tâches était exécutée en série sur un seul PE. Pas besoin de coder des mutex ou de vous soucier d'un blocage.
Les auteurs implémentent Chronos dans SystemVerilog et le compilent sur un FPGA. Une grande partie du document est consacrée à expliquer comment ils ont implémenté la file d'attente des tâches et tout déroulement matériel nécessaire pour une efficacité maximale. Chronos s'appuie sur quatre algorithmes bien adaptés à une architecture basée sur une file d'attente de tâches. Chaque algorithme est implémenté de deux manières : d'abord en utilisant un PE dédié spécifique à l'algorithme, et ensuite en utilisant un processeur RISC-V intégré 32 bits open source prêt à l'emploi comme PE. Les performances de Chronos sont ensuite comparées aux implémentations logicielles multithread des algorithmes exécutés sur un serveur Intel Xeon avec un prix similaire à celui du FPGA utilisé pour Chronos. Les résultats sont impressionnants : Chronos évolue de 3 à 15 fois mieux que l'utilisation du serveur Xeon. Cependant, en comparant le tableau 3 à la figure 14, je m'inquiète un peu du fait que la plupart de ces gains proviennent des PE spécifiques à l'algorithme plutôt que de l'architecture Chronos elle-même.
Étant donné qu'il s'agit d'un blog de vérification, j'ai naturellement zoomé sur le benchmark de simulation au niveau de la porte. L'industrie de l'EDA a investi massivement pour tenter de paralléliser la simulation logique et il s'est avéré difficile de constater des gains importants au-delà de quelques cas d'utilisation spécifiques. Cela est principalement dû au fait que les performances de la plupart des simulations du monde réel sont dominées par les instructions de chargement/stockage manquantes dans le cache L3 et envoyées vers la DRAM. Il n'y a qu'un seul cas de test évalué dans cet article et il s'agit d'un minuscule additionneur de sauvegarde de report de 32 bits. Si vous lisez ce blog et que vous souhaitez effectuer une analyse comparative plus approfondie, faites-le-moi savoir : si Chronos peut vraiment bien s'adapter aux simulations du monde réel, cela aurait une énorme valeur commerciale !
Le point de vue de Raul
La principale contribution de cet article est la Modèle d'exécution de tâches ordonnées spatialement localisées (SLOT) ce qui est efficace pour les accélérateurs matériels qui exploitent le parallélisme et la spéculation, ainsi que pour les applications qui génèrent des tâches de manière dynamique au moment de l'exécution. La prise en charge du parallélisme dynamique est inévitable pour la simulation et la synchronisation spéculative est une option intéressante, mais la surcharge de cohérence est trop élevée.
SLOT évite le besoin de cohérence en limitant chaque tâche à opérer (écrire) sur un seul objet et prend en charge les tâches ordonnées pour permettre l'atomicité multi-objets. Les applications SLOT sont des tâches ordonnées et créées dynamiquement, caractérisées par un horodatage et un identifiant d'objet. Les horodatages spécifient les contraintes de commande ; les identifiants d'objet spécifient les dépendances des données, c'est-à-dire que les tâches dépendent des données si et seulement si elles ont le même identifiant d'objet. (s'il existe une dépendance en lecture, la tâche peut être exécutée de manière spéculative). La détection des conflits devient locale (sans structures de suivi complexes) en mappant les identifiants d'objet sur des cœurs ou des tuiles et en envoyant chaque tâche là où son identifiant d'objet est mappé.
La Chronos Le système a été implémenté dans le cadre AWS FPGA en tant que système avec 16 tuiles, chacune avec 4 éléments de traitement spécifiques à l'application (PE), fonctionnant à 125 MHz. Ce système est comparé à une base de référence composée d'un Intel Xeon E20-40v2.4 à 5 GHz à 2676 cœurs/3 threads, choisi spécifiquement parce que son prix est comparable à celui du FPGA (environ 2 $/heure). En exécutant une seule tâche sur un PE, Chronos est 2.45 fois plus rapide que la ligne de base. À mesure que le nombre de tâches simultanées augmente, l'implémentation de Chronos évolue jusqu'à une accélération relative de 44.9x sur 8 tuiles, correspondant à une accélération de 15.3x par rapport à l'implémentation du processeur. Ils ont également comparé une implémentation basée sur RISC-V à usage général plutôt que sur des PE spécifiques à une application ; Les PE étaient 5 fois plus rapides que RISC-V.
J'ai trouvé le document impressionnant car il couvre tout, du concept à la définition du modèle d'exécution SLOT en passant par la mise en œuvre du matériel et la comparaison détaillée avec un processeur Xeon traditionnel pour 4 applications. L'effort est conséquent, Chronos, c'est plus de 20,000 5.4 lignes de SystemVerilog. Le résultat est une accélération moyenne de 4x (sur les XNUMX applications) par rapport aux versions logicielles parallèles, en raison d'un plus grand parallélisme et d'une plus grande utilisation de l'exécution spéculative. L'article vaut également la peine d'être lu pour son application à des tâches non liées à la simulation ; le document comprend trois exemples.
Partagez cet article via:
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://semiwiki.com/eda/326261-speculation-for-simulation-innovation-in-verification/
- :est
- 000
- 2020
- 8
- a
- A Propos
- accélérer
- accélération
- accélérateurs
- ACM
- actes
- ajoutée
- algorithme
- algorithmes
- alternative
- toujours
- ainsi que le
- attirant
- Application
- spécifique à l'application
- applications
- architectural
- architecture
- SONT
- AS
- At
- auteurs
- AWS
- basé
- Baseline
- BE
- pour créer les plus
- car
- devient
- before
- va
- référence
- référencé
- profiter
- Améliorée
- Au-delà
- Big
- Bit
- Blog
- by
- cachette
- Cadence
- appelé
- CAN
- porter
- cas
- Catalyseur
- caractérisé
- enfant
- choisi
- code
- commercial
- comparable
- par rapport
- comparant
- Comparaison
- Complété
- complexe
- calcul
- calcul
- concept
- concurrent
- Congrès
- conflit
- Qui consiste
- contraintes
- continuer
- contribution
- Correspondant
- cours
- couvre
- Processeur
- engendrent
- créée
- CTO
- Courant
- Customiser
- données
- dévoué
- Dépendance
- dépend
- un
- détaillé
- détecté
- Détection
- difficile
- Dynamic
- dynamiquement
- e
- chacun
- même
- efficace
- efficace
- effort
- éléments
- intégré
- permettre
- se termine
- assurer
- Entrepreneur
- notamment
- peut
- exemples
- exécuter
- exécution
- exécution
- expliquant
- Exploiter
- plus rapide
- Réactions
- few
- Figure
- Prénom
- Pour
- Ancien
- trouvé
- fpga
- Framework
- De
- avenir
- Gains
- Général
- générer
- Intel GHz
- Global
- aller
- Matériel
- Vous avez
- fortement
- ici
- Haute
- Comment
- Cependant
- HTTPS
- majeur
- i
- ID
- idée
- et idées cadeaux
- immédiatement
- Mettre en oeuvre
- la mise en oeuvre
- mis en œuvre
- la mise en œuvre
- impressionnant
- in
- inclut
- Augmente
- industrie
- inévitable
- initiale
- Innovation
- Des instructions
- Intel
- intéressé
- intéressant
- intrinsèque
- investi
- IT
- SES
- lui-même
- Savoir
- Langues
- lignes
- locales
- localement
- situé
- Entrée
- FAIT DU
- gestion
- cartographie
- largeur maximale
- maximales
- veux dire
- Mémoire
- méthode
- pourrait
- manquant
- MIT
- modèle
- Villas Modernes
- PLUS
- (en fait, presque toutes)
- plusieurs
- nécessaire
- Besoin
- Nouveauté
- nombre
- objet
- of
- on
- ONE
- ouvert
- open source
- fonctionner
- d'exploitation
- systèmes d'exploitation
- Option
- de commander
- Autre
- au contrôle
- P&E
- Papier
- Parallèle
- paul
- performant
- Physiquement
- en particulier pendant la préparation
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- Point
- Post
- présenté
- prix
- traitement
- processeurs
- Programmation
- langages de programmation
- propose
- proven
- but
- Putting
- plutôt
- Lire
- en cours
- réal
- monde réel
- un article
- restreindre
- résultat
- Résultats
- pour le running
- même
- Épargnez
- Escaliers intérieurs
- Balance
- Deuxièmement
- envoi
- supérieur
- Série
- Étagère
- Silicium
- similaires
- simulation
- unique
- So
- Logiciels
- quelques
- Identifier
- groupe de neurones
- spécifiquement
- spéculation
- Ces
- Support
- Les soutiens
- synchronisation
- combustion propre
- Système
- table
- TAG
- Target
- Tâche
- tâches
- techniques
- qui
- La
- Ces
- trois
- Avec
- horodatage
- à
- trop
- Tracking
- traditionnel
- torsion
- utilisé
- Utilisateur
- d'habitude
- Vérification
- via
- Façon..
- façons
- bienvenu
- WELL
- Quoi
- qui
- comprenant
- sans
- merveilleux
- world
- vaut
- pourra
- écrire
- Votre
- zéphyrnet