
Image créée avec DALL-E3
L'intelligence artificielle a été une révolution complète dans le monde de la technologie.
Sa capacité à imiter l’intelligence humaine et à effectuer des tâches qui étaient autrefois considérées comme du domaine exclusivement humain étonne encore la plupart d’entre nous.
Cependant, quelle que soit la qualité de ces derniers progrès de l’IA, il y a toujours place à l’amélioration.
Et c’est précisément là qu’intervient l’ingénierie rapide !
Entrez dans ce domaine qui peut améliorer considérablement la productivité des modèles d'IA.
Découvrons tout cela ensemble !
L'ingénierie rapide est un domaine en croissance rapide au sein de l'IA qui se concentre sur l'amélioration de l'efficience et de l'efficacité des modèles de langage. Il s’agit de créer des invites parfaites pour guider les modèles d’IA afin de produire les résultats souhaités.
Pensez-y comme à apprendre à donner de meilleures instructions à quelqu'un pour vous assurer qu'il comprend et exécute correctement une tâche.
Pourquoi l'ingénierie rapide est importante
- Productivité améliorée : En utilisant des invites de haute qualité, les modèles d’IA peuvent générer des réponses plus précises et plus pertinentes. Cela signifie moins de temps consacré aux corrections et plus de temps à exploiter les capacités de l'IA.
- Rapport coût-efficacité: La formation de modèles d’IA nécessite beaucoup de ressources. L'ingénierie des invites peut réduire le besoin de recyclage en optimisant les performances du modèle grâce à de meilleures invites.
- Versatilité: Une invite bien conçue peut rendre les modèles d’IA plus polyvalents, leur permettant de s’attaquer à un plus large éventail de tâches et de défis.
Avant de plonger dans les techniques les plus avancées, rappelons deux des techniques d’ingénierie rapide les plus utiles (et basiques).
Pensée séquentielle avec « Pensons étape par étape »
Aujourd'hui, il est bien connu que la précision des modèles LLM est considérablement améliorée lorsqu'on ajoute la séquence de mots « Pensons étape par étape ».
Pourquoi… pourriez-vous demander ?
Eh bien, c'est parce que nous forçons le modèle à diviser n'importe quelle tâche en plusieurs étapes, garantissant ainsi que le modèle dispose de suffisamment de temps pour traiter chacune d'elles.
Par exemple, je pourrais contester GPT3.5 avec l'invite suivante :
Si Jean a 5 poires, puis en mange 2, en achète 5 autres, puis en donne 3 à son ami, combien de poires a-t-il ?
Le modèle me donnera une réponse tout de suite. Cependant, si j'ajoute le dernier « Pensons étape par étape », j'oblige le modèle à générer un processus de réflexion en plusieurs étapes.
Invite à quelques prises de vue
Alors que l'invite Zero-shot consiste à demander au modèle d'effectuer une tâche sans fournir de contexte ni de connaissances préalables, la technique d'invite en quelques coups implique que nous présentons au LLM quelques exemples de notre résultat souhaité ainsi qu'une question spécifique.
Par exemple, si nous voulons proposer un modèle qui définit n’importe quel terme en utilisant un ton poétique, cela pourrait être assez difficile à expliquer. Droite?
Cependant, nous pourrions utiliser les invites suivantes pour orienter le modèle dans la direction souhaitée.
Votre tâche consiste à répondre dans un style cohérent aligné sur le style suivant.
: Apprenez-moi la résilience.
: La résilience est comme un arbre qui se plie avec le vent mais ne se brise jamais.
C’est la capacité de rebondir face à l’adversité et de continuer à avancer.
: Votre contribution ici.
Si vous ne l’avez pas encore essayé, vous pouvez défier GPT.
Cependant, comme je suis presque sûr que la plupart d’entre vous connaissent déjà ces techniques de base, je vais essayer de vous mettre au défi avec quelques techniques avancées.
1. Invite de chaîne de pensée (CoT)
Introduit par Google en 2022, cette méthode consiste à demander au modèle de subir plusieurs étapes de raisonnement avant de fournir la réponse finale.
Cela vous semble familier, n'est-ce pas ? Si c'est le cas, vous avez tout à fait raison.
C'est comme fusionner à la fois la pensée séquentielle et l'invite à quelques tirs.
Comment s’y prendre?
Essentiellement, les invites CoT demandent au LLM de traiter les informations de manière séquentielle. Cela signifie que nous expliquons comment résoudre un premier problème avec un raisonnement en plusieurs étapes, puis envoyons au modèle notre tâche réelle, en nous attendant à ce qu'il imite une chaîne de pensée comparable lorsqu'il répond à la requête réelle que nous voulons qu'il résolve.
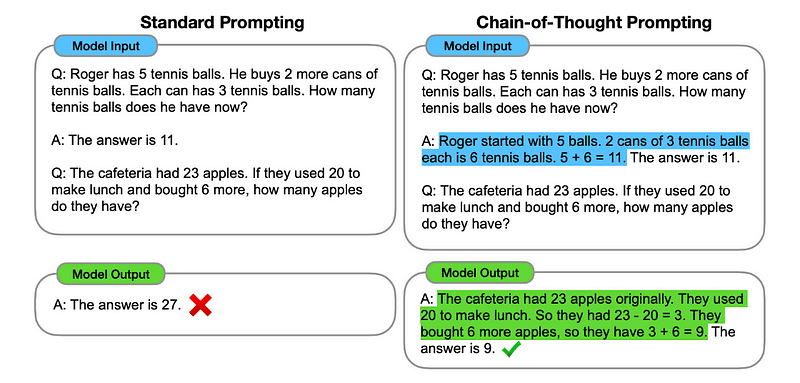
Image prise du papier.
Ainsi, en suivant le tout premier exemple, nous pourrions fournir une invite avec le premier problème et une explication séquentielle de la façon de le résoudre. Ensuite, nous pouvons envoyer nos commentaires et voir comment la magie opère !
Si Jean a 5 poires, puis en mange 2, en achète 5 autres, puis en donne 3 à son ami, combien de poires a-t-il ? Réfléchissons étape par étape.
Allons-y étape par étape. John commence avec 5 poires. Il mange 2 poires, il lui reste donc 5-2 = 3 poires. Ensuite, il achète 5 poires supplémentaires. Il lui reste donc maintenant 3 + 5 = 8 poires. Finalement, il donne 3 poires à son ami. Il lui reste donc 8–3 = 5 poires. Ainsi, après toutes ces étapes, Jean a 5 poires.
Votre contribution ici.
Cependant, la plupart d’entre vous doivent réfléchir… Dois-je penser à une manière séquentielle de résoudre un problème chaque fois que je souhaite poser une question sur ChatGPT ?
Eh bien… vous n'êtes pas le premier ! Et cela nous amène à…
2. Chaîne de pensée automatique (Auto-CoT)
En 2022, Zhang et ses collègues ont introduit une méthode pour éviter ce processus manuel. Il y a deux raisons principales d’éviter toute tâche manuelle :
- Cela peut être ennuyeux.
- Cela peut donner de mauvais résultats, par exemple lorsque notre processus mental est erroné.
Ils ont suggéré d'utiliser des LLM combinés à l'invite « Pensons étape par étape » pour produire séquentiellement des chaînes de raisonnement pour chaque démonstration.
Cela signifie demander à ChatGPT comment résoudre n'importe quel problème de manière séquentielle, puis utiliser ce même exemple pour l'entraîner à résoudre tout autre problème.
3. Auto-cohérence
L’auto-cohérence est une autre technique d’incitation intéressante qui vise à améliorer la chaîne de pensée conduisant à des problèmes de raisonnement plus complexes.
Alors… quelle est la principale différence ?
L'idée principale de l'auto-cohérence est d'être conscient que nous pouvons former le modèle avec un mauvais exemple. Imaginez simplement que je résous le problème précédent avec un mauvais processus mental :
Si Jean a 5 poires, puis en mange 2, en achète 5 autres, puis en donne 3 à son ami, combien de poires a-t-il ? Réfléchissons étape par étape.
Commencez avec 5 poires. John mange 2 poires. Ensuite, il donne 3 poires à son ami. Ces actions peuvent être combinées : 2 (mangées) + 3 (données) = 5 poires au total concernées. Maintenant, soustrayez le nombre total de poires affectées des 5 poires initiales : 5 (initiale) – 5 (affectées) = 0 poire restante.
Ensuite, toute autre tâche que j’enverrai au modèle sera fausse.
C'est pourquoi l'auto-cohérence implique d'échantillonner différents chemins de raisonnement, chacun d'eux contenant une chaîne de pensée, puis de laisser le LLM choisir le chemin le meilleur et le plus cohérent pour résoudre le problème.
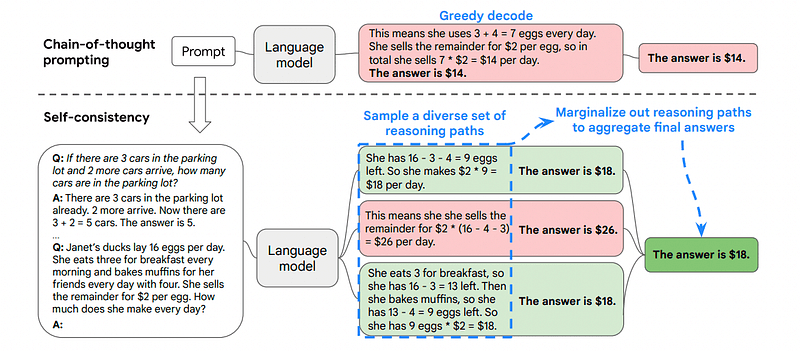
Image prise du papier
Dans ce cas, et en reprenant le tout premier exemple, nous pouvons montrer au modèle différentes manières de résoudre le problème.
Si Jean a 5 poires, puis en mange 2, en achète 5 autres, puis en donne 3 à son ami, combien de poires a-t-il ?
Commencez avec 5 poires. Jean mange 2 poires, ce qui lui laisse 5–2 = 3 poires. Il achète 5 poires supplémentaires, ce qui porte le total à 3 + 5 = 8 poires. Finalement, il donne 3 poires à son ami, il lui reste donc 8-3 = 5 poires.
Si Jean a 5 poires, puis en mange 2, en achète 5 autres, puis en donne 3 à son ami, combien de poires a-t-il ?
Commencez avec 5 poires. Il achète ensuite 5 poires supplémentaires. John mange 2 poires maintenant. Ces actions peuvent être combinées : 2 (mangées) + 5 (achetées) = 7 poires au total. Soustrayez la poire que Jon a mangée de la quantité totale de poires 7 (quantité totale) – 2 (mangée) = 5 poires restantes.
Votre contribution ici.
Et voici la dernière technique.
4. Invite de connaissances générales
Une pratique courante d'ingénierie rapide consiste à compléter une requête avec des connaissances supplémentaires avant d'envoyer l'appel d'API final à GPT-3 ou GPT-4.
Selon Jiacheng Liu et Cie, nous pouvons toujours ajouter quelques connaissances à toute demande afin que le LLM connaisse mieux la question.
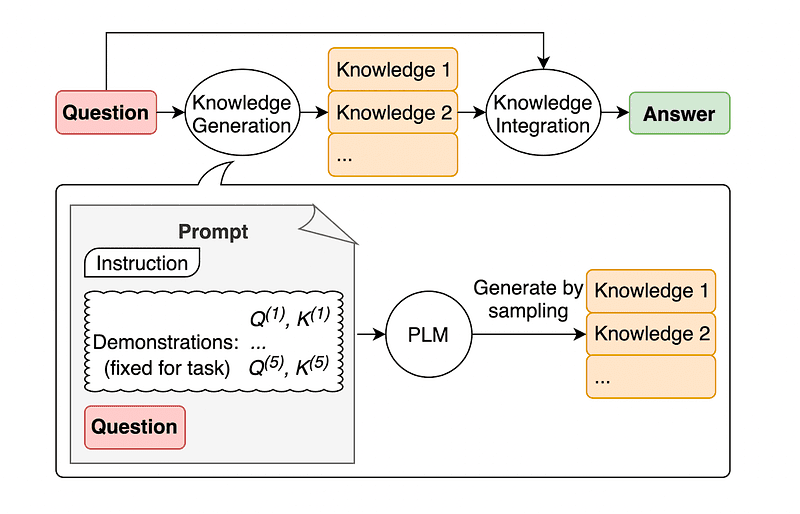
Image prise du papier.
Ainsi, par exemple, lorsque nous demandons à ChatGPT si une partie du golf essaie d'obtenir un total de points plus élevé que d'autres, cela nous validera. Mais l’objectif principal du golf est tout le contraire. C'est pourquoi on peut ajouter quelques connaissances préalables lui disant « Le joueur avec le score le plus bas gagne ».

Alors... qu'est-ce qui est drôle si nous disons exactement la réponse au modèle ?
Dans ce cas, cette technique est utilisée pour améliorer la façon dont LLM interagit avec nous.
Ainsi, plutôt que d'extraire un contexte supplémentaire d'une base de données externe, les auteurs de l'article recommandent que le LLM produise ses propres connaissances. Ces connaissances auto-générées sont ensuite intégrées dans l'invite pour renforcer le raisonnement de bon sens et donner de meilleurs résultats.
C'est donc ainsi que les LLM peuvent être améliorés sans augmenter leur ensemble de données de formation !
L'ingénierie rapide est devenue une technique essentielle pour améliorer les capacités du LLM. En itérant et en améliorant les invites, nous pouvons communiquer de manière plus directe avec les modèles d'IA et ainsi obtenir des résultats plus précis et contextuellement pertinents, économisant ainsi du temps et des ressources.
Pour les passionnés de technologie, les data scientists et les créateurs de contenu, comprendre et maîtriser l’ingénierie rapide peut être un atout précieux pour exploiter tout le potentiel de l’IA.
En combinant des invites de saisie soigneusement conçues avec ces techniques plus avancées, disposer des compétences en ingénierie des invites vous donnera sans aucun doute un avantage dans les années à venir.
Joseph Ferrier est un ingénieur analytique de Barcelone. Il est diplômé en génie physique et travaille actuellement dans le domaine de la science des données appliquée à la mobilité humaine. Il est un créateur de contenu à temps partiel axé sur la science et la technologie des données. Vous pouvez le contacter sur LinkedIn, Twitter or Moyenne.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- :possède
- :est
- :ne pas
- :où
- $UP
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- capacité
- A Propos
- précision
- Avec cette connaissance vient le pouvoir de prendre
- actes
- présenter
- ajouter
- ajoutant
- Supplémentaire
- Avancée
- Après
- encore
- AI
- Modèles AI
- vise
- aligné
- même
- Tous
- Permettre
- le long de
- déjà
- toujours
- am
- montant
- an
- analytique
- ainsi que le
- Une autre
- répondre
- tous
- api
- appliqué
- SONT
- AS
- demander
- demandant
- atout
- auteurs
- Automatique
- éviter
- conscients
- et
- RETOUR
- Mal
- Barcelona
- Essentiel
- BE
- car
- était
- before
- va
- LES MEILLEURS
- Améliorée
- traversin
- renforcer
- Forage
- tous les deux
- acheté
- Rebondir
- Pause
- pauses
- Apportez le
- plus large
- mais
- Buys
- by
- Appelez-nous
- CAN
- capacités
- prudemment
- maisons
- chaîne
- Chaînes
- challenge
- globaux
- ChatGPT
- Selectionnez
- collègues
- combiné
- combinant
- comment
- vient
- Venir
- Commun
- communiquer
- comparable
- complet
- complexe
- considéré
- cohérent
- contact
- contenu
- créateurs de contenu
- contexte
- Corrections
- correctement
- pourriez
- créée
- créateur
- créateurs
- Lecture
- données
- science des données
- Base de données
- Définit
- livrer
- un
- voulu
- différence
- différent
- direction
- découvrez
- plongée
- do
- domaine
- domaines
- down
- chacun
- Edge
- efficacité
- efficace
- émergé
- ingénieur
- ENGINEERING
- de renforcer
- améliorer
- assez
- assurer
- Les amateurs de
- exactement
- exemple
- exemples
- exécuter
- attend
- Expliquer
- explication
- familier
- few
- champ
- finale
- finalement
- Prénom
- concentré
- se concentre
- Abonnement
- Pour
- forçant
- Avant
- Ami
- De
- plein
- drôle
- Général
- générer
- obtenez
- Donner
- donné
- donne
- Go
- objectif
- golf
- Bien
- guide
- Dur
- Exploiter
- Vous avez
- ayant
- he
- ici
- de haute qualité
- augmentation
- lui
- sa
- Comment
- How To
- Cependant
- HTTPS
- humain
- intelligence humaine
- i
- idée
- if
- image
- améliorer
- amélioré
- amélioration
- l'amélioration de
- in
- croissant
- d'information
- initiale
- contribution
- instance
- Des instructions
- des services
- Intelligence
- interagit
- intéressant
- développement
- introduit
- implique
- IT
- SES
- John
- jon
- juste
- KDnuggetsGenericName
- XNUMX éléments à
- coup de pied
- Kicks
- Savoir
- spécialisées
- sait
- langue
- Nom de famille
- En retard
- Conduit
- Sauter
- apprentissage
- départ
- à gauche
- moins
- laisser
- location
- en tirant parti
- comme
- baisser
- la magie
- Entrée
- a prendre une
- Fabrication
- manière
- Manuel
- de nombreuses
- mastering
- Matière
- me
- veux dire
- mental
- fusion
- méthode
- pourrait
- mobilité
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- (en fait, presque toutes)
- en mouvement
- plusieurs
- must
- Besoin
- n'allons jamais
- aucune
- maintenant
- obtenir
- of
- on
- une fois
- opposé
- l'optimisation
- or
- Autre
- Autres
- nos
- ande
- sortie
- sorties
- au contrôle
- propre
- Papier
- partie
- chemin
- parfaite
- effectuer
- performant
- Physique
- pivot
- Platon
- Intelligence des données Platon
- PlatonDonnées
- joueur
- Point
- défaillances
- pratique
- précisément
- représentent
- assez
- précédent
- Problème
- d'ouvrabilité
- processus
- produire
- productivité
- fournir
- aportando
- tirant
- question
- assez
- gamme
- plutôt
- réal
- Les raisons
- recommander
- réduire
- se réfère
- pertinent
- nécessaire
- la résilience
- gourmande en ressources
- Resources
- répondre
- réponse
- réponses
- Résultats
- recyclage
- Révolution
- bon
- Salle
- s
- même
- économie
- Sciences
- Science et technologie
- scientifiques
- But
- sur le lien
- envoyer
- envoi
- Séquence
- set
- plusieurs
- montrer
- de façon significative
- compétence
- So
- uniquement
- RÉSOUDRE
- Résoudre
- quelques
- Quelqu'un
- quelque chose
- groupe de neurones
- dépensé
- étapes
- Commencer
- départs
- diriger
- étapes
- Étapes
- Encore
- Catégorie
- sûr
- tacle
- tâches
- Tâche
- tâches
- technologie
- technique
- techniques
- Technologie
- dire
- terme
- que
- qui
- La
- Les
- puis
- Là.
- donc
- Ces
- l'ont
- penser
- En pensant
- this
- pensée
- Avec
- Ainsi
- fiable
- à
- TON
- Total
- TOTALEMENT
- Train
- Formation
- arbre
- essayé
- Essai
- essayer
- deux
- ultime
- sous
- subir
- comprendre
- compréhension
- indubitablement
- us
- utilisé
- d'utiliser
- en utilisant
- VALIDER
- Précieux
- divers
- polyvalente
- très
- souhaitez
- Façon..
- façons
- we
- bien connu
- ont été
- quand
- qui
- why
- sera
- Vent
- comprenant
- dans les
- sans
- Word
- de travail
- world
- faux
- années
- encore
- Rendement
- you
- Votre
- zéphyrnet







