Image par auteur
Dans cet article, nous explorerons le nouveau modèle open source de pointe appelé Mixtral 8x7b. Nous apprendrons également comment y accéder à l'aide de la bibliothèque LLaMA C++ et comment exécuter de grands modèles de langage avec un calcul et une mémoire réduits.
Mixtral 8x7b est un modèle de mélange d'experts (SMoE) de haute qualité avec des pondérations ouvertes, créé par Mistral AI. Il est sous licence Apache 2.0 et surpasse Llama 2 70B sur la plupart des benchmarks tout en ayant une inférence 6 fois plus rapide. Mixtral correspond ou bat GPT3.5 sur la plupart des benchmarks standard et constitue le meilleur modèle à poids ouvert en termes de coût/performance.
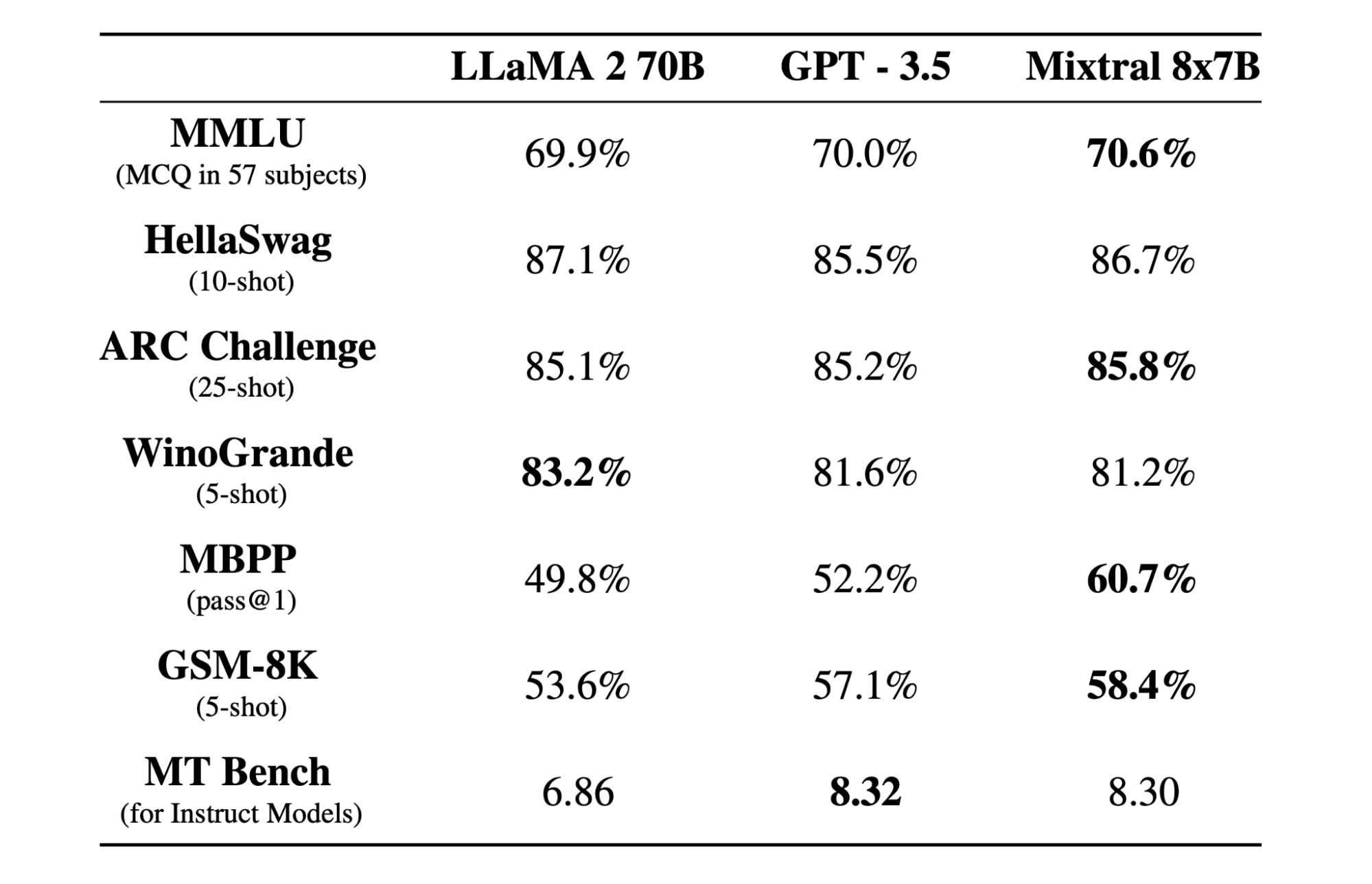
Image de Mélange d'experts
Mixtral 8x7B utilise un réseau mixte d'experts clairsemé uniquement pour les décodeurs. Cela implique un bloc de rétroaction sélectionnant parmi 8 groupes de paramètres, un réseau de routeurs choisissant deux de ces groupes pour chaque jeton, combinant leurs sorties de manière additive. Cette méthode améliore le nombre de paramètres du modèle tout en gérant le coût et la latence, le rendant aussi efficace qu'un modèle de 12.9 milliards, malgré un total de 46.7 milliards de paramètres.
Le modèle Mixtral 8x7B excelle dans la gestion d'un large contexte de 32 XNUMX jetons et prend en charge plusieurs langues, dont l'anglais, le français, l'italien, l'allemand et l'espagnol. Il démontre de solides performances en matière de génération de code et peut être affiné dans un modèle de suivi d'instructions, obtenant des scores élevés sur des benchmarks tels que MT-Bench.
LLaMA.cpp est une bibliothèque C/C++ qui fournit une interface hautes performances pour les grands modèles de langage (LLM) basés sur l'architecture LLM de Facebook. Il s'agit d'une bibliothèque légère et efficace qui peut être utilisée pour diverses tâches, notamment la génération de texte, la traduction et la réponse à des questions. LLaMA.cpp prend en charge une large gamme de LLM, notamment LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B et GPT4ALL. Il est compatible avec tous les systèmes d’exploitation et peut fonctionner aussi bien sur les CPU que sur les GPU.
Dans cette section, nous exécuterons l'application Web llama.cpp sur Colab. En écrivant quelques lignes de code, vous pourrez découvrir les nouvelles performances du modèle de pointe sur votre PC ou sur Google Colab.
Pour commencer
Tout d’abord, nous allons télécharger le référentiel GitHub llama.cpp en utilisant la ligne de commande ci-dessous :
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitAprès cela, nous changerons de répertoire dans le référentiel et installerons le llama.cpp à l'aide de la commande `make`. Nous installons le llama.cpp pour le GPU NVidia avec CUDA installé.
%cd llama.cpp
!make LLAMA_CUBLAS=1Télécharger le modèle
Nous pouvons télécharger le modèle depuis Hugging Face Hub en sélectionnant la version appropriée du fichier modèle « .gguf ». Plus d’informations sur les différentes versions peuvent être trouvées dans TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
Image de TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
Vous pouvez utiliser la commande `wget` pour télécharger le modèle dans le répertoire courant.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufAdresse externe pour le serveur LLaMA
Lorsque nous exécutons le serveur LLaMA, il nous donnera une IP localhost qui nous est inutile sur Colab. Nous avons besoin de la connexion au proxy localhost en utilisant le port proxy du noyau Colab.
Après avoir exécuté le code ci-dessous, vous obtiendrez le lien hypertexte global. Nous utiliserons ce lien pour accéder à notre webapp plus tard.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/Exécution du serveur
Pour exécuter le serveur LLaMA C++, vous devez fournir à la commande serveur l'emplacement du fichier modèle et le numéro de port correct. Il est important de s’assurer que le numéro de port correspond à celui que nous avons initié à l’étape précédente pour le port proxy.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
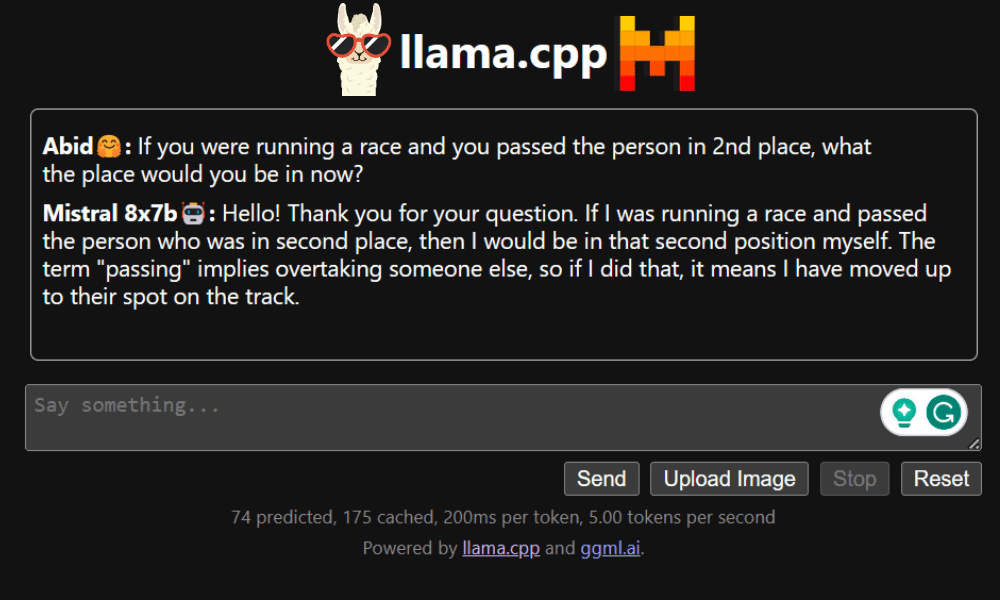
L'application Web de chat est accessible en cliquant sur le lien hypertexte du port proxy à l'étape précédente, car le serveur ne s'exécute pas localement.
Application Web LLaMA C++
Avant de commencer à utiliser le chatbot, nous devons le personnaliser. Remplacez « LLaMA » par le nom de votre modèle dans la section d'invite. De plus, modifiez le nom d’utilisateur et le nom du bot pour faire la distinction entre les réponses générées.
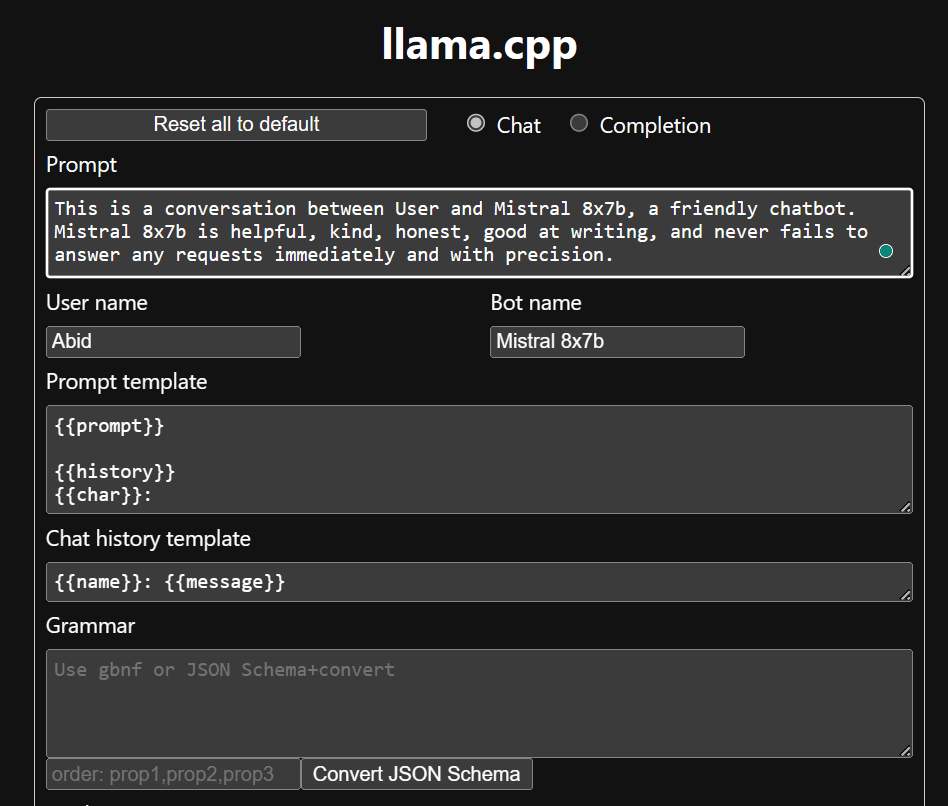
Commencez à discuter en faisant défiler vers le bas et en tapant dans la section de discussion. N'hésitez pas à poser des questions techniques auxquelles d'autres modèles open source n'ont pas réussi à répondre correctement.
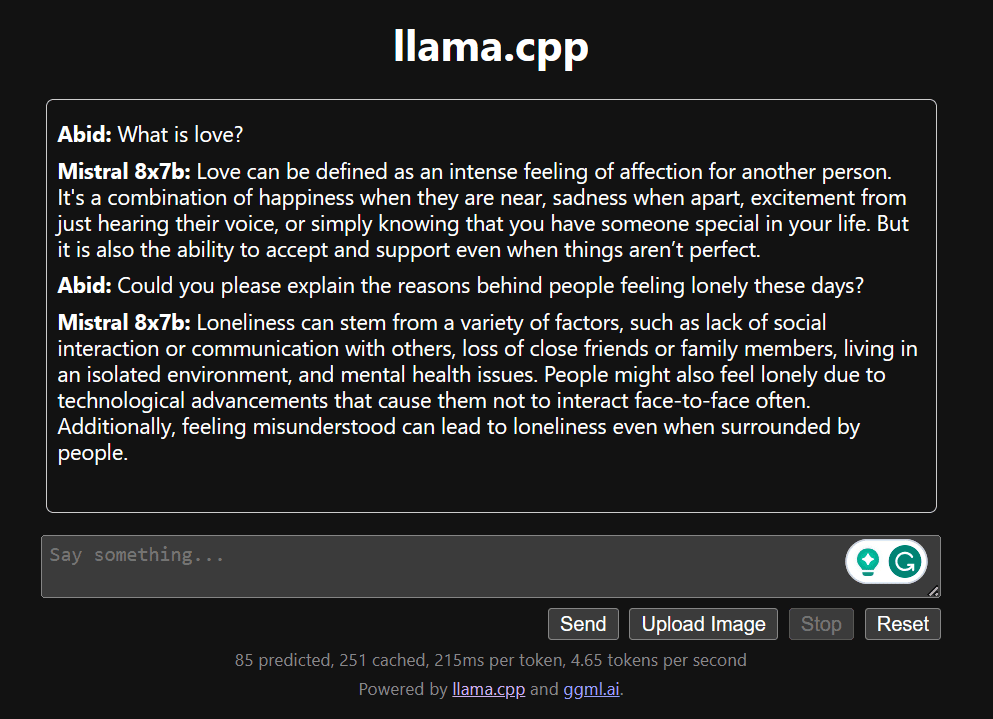
Si vous rencontrez des problèmes avec l'application, vous pouvez essayer de l'exécuter vous-même à l'aide de mon Google Colab : https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
Ce didacticiel fournit un guide complet sur la façon d'exécuter le modèle open source avancé, Mixtral 8x7b, sur Google Colab à l'aide de la bibliothèque LLaMA C++. Comparé à d'autres modèles, Mixtral 8x7b offre des performances et une efficacité supérieures, ce qui en fait une excellente solution pour ceux qui souhaitent expérimenter de grands modèles de langage mais ne disposent pas de ressources informatiques étendues. Vous pouvez facilement l’exécuter sur votre ordinateur portable ou sur un ordinateur cloud gratuit. Il est convivial et vous pouvez même déployer votre application de chat pour que d'autres puissent l'utiliser et l'expérimenter.
J'espère que vous avez trouvé utile cette solution simple pour exécuter le grand modèle. Je suis toujours à la recherche d'options simples et meilleures. Si vous avez une solution encore meilleure, faites-le-moi savoir et j'en parlerai la prochaine fois.
Abid Ali Awan (@1abidaliawan) est un spécialiste des données certifié qui aime créer des modèles d'apprentissage automatique. Actuellement, il se concentre sur la création de contenu et la rédaction de blogs techniques sur les technologies d'apprentissage automatique et de science des données. Abid est titulaire d'une maîtrise en gestion de la technologie et d'un baccalauréat en génie des télécommunications. Sa vision est de créer un produit d'IA utilisant un réseau de neurones graphiques pour les étudiants aux prises avec une maladie mentale.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :est
- :ne pas
- 1
- 12
- 27
- 46
- 7
- 8
- a
- Capable
- accès
- accédé
- la réalisation de
- En outre
- propos
- Avancée
- AI
- Tous
- aussi
- toujours
- am
- an
- ainsi que
- répondre
- Apache
- appli
- Application
- approprié
- architecture
- SONT
- AS
- demander
- basé
- BE
- commencer
- ci-dessous
- repères
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Block
- blogue
- Bot
- tous les deux
- construire
- Développement
- mais
- by
- C + +
- appelé
- CAN
- Support et maintenance de Salesforce
- Change
- le chat
- Chatbot
- bavardage
- choose
- le cloud
- code
- combinant
- par rapport
- compatible
- complet
- calcul
- calcul
- informatique
- connexion
- contenu
- création de contenu
- contexte
- correct
- Prix
- couverture
- créée
- création
- Courant
- Lecture
- personnaliser
- données
- science des données
- Data Scientist
- Degré
- offre
- démontre
- déployer
- Malgré
- distinguer
- do
- down
- download
- chacun
- même
- efficace
- efficace
- rencontre
- ENGINEERING
- Anglais
- Améliore
- Pourtant, la
- excellent
- d'experience
- expérience
- de santé
- explorez
- les
- Visage
- Échoué
- faucon
- plus rapide
- ressentir
- few
- Déposez votre dernière attestation
- mettant l'accent
- Pour
- trouvé
- gratuitement ici
- Français
- De
- fonction
- généré
- génération
- Allemand
- obtenez
- GitHub
- Donner
- Global
- GPU
- GPU
- graphique
- Réseau neuronal graphique
- Groupes
- guide
- Maniabilité
- Vous avez
- ayant
- he
- utile
- Haute
- haute performance
- de haute qualité
- sa
- détient
- d'espérance
- Comment
- How To
- HTTPS
- Moyeu
- i
- if
- maladie
- importer
- important
- in
- Y compris
- d'information
- initié
- installer
- installer
- Interfaces
- développement
- implique
- IP
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- Italien
- KDnuggetsGenericName
- Savoir
- langue
- Langues
- portatif
- gros
- Latence
- plus tard
- APPRENTISSAGE
- apprentissage
- laisser
- Bibliothèque
- Autorisé
- léger
- comme
- Gamme
- lignes
- LINK
- Flamme
- localement
- emplacement
- recherchez-
- aime
- click
- machine learning
- a prendre une
- Fabrication
- gestion
- les gérer
- maître
- allumettes
- me
- Mémoire
- mental
- Maladie mentale
- méthode
- mélange
- modèle
- numériques jumeaux (digital twin models)
- modifier
- PLUS
- (en fait, presque toutes)
- plusieurs
- my
- prénom
- Besoin
- réseau et
- Neural
- Réseau neuronal
- Nouveauté
- next
- nombre
- Nvidia
- of
- on
- ONE
- ouvert
- open source
- d'exploitation
- systèmes d'exploitation
- Options
- or
- Autre
- Autres
- nos
- Surperforme
- sortie
- sorties
- propre
- paramètre
- paramètres
- PC
- performant
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- Post
- précédent
- Produit
- professionels
- correctement
- fournir
- fournit
- procuration
- question
- fréquemment posées
- gamme
- Prix Réduit
- en ce qui concerne
- remplacer
- dépôt
- un article
- Resources
- réponses
- toupie
- Courir
- pour le running
- s
- Sciences
- Scientifique
- scores
- défilement
- Section
- la sélection
- serveur
- étapes
- depuis
- sur mesure
- Identifier
- Espagnol
- Standard
- state-of-the-art
- étapes
- STRONG
- Luttant
- Étudiante
- haut
- Les soutiens
- sûr
- Système
- tâches
- Technique
- Les technologies
- Technologie
- télécommunication
- texte
- génération de texte
- qui
- La
- leur
- Ces
- this
- ceux
- fiable
- à
- jeton
- Tokens
- Total
- Traduction
- Essai
- tutoriel
- deux
- sous
- us
- utilisé
- d'utiliser
- Utilisateur
- convivial
- Usages
- en utilisant
- variété
- divers
- version
- vision
- souhaitez
- we
- web
- application Web
- qui
- tout en
- WHO
- large
- Large gamme
- sera
- comprenant
- écriture
- you
- Votre
- zéphyrnet