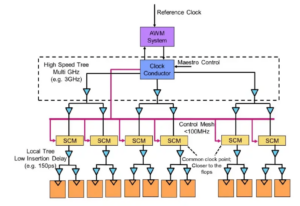
Experts à la table : Semiconductor Engineering s'est assis pour discuter de la voie à suivre en matière de mémoire dans des systèmes de plus en plus hétérogènes, avec Frank Ferro, directeur de groupe, gestion des produits chez Cadence; Steven Woo, collègue et inventeur distingué de Rambus; Jongsin Yun, technologue en mémoire à Siemens EDA; Randy White, responsable du programme de solutions de mémoire chez Keysight; et Frank Schirrmeister, vice-président des solutions et du développement commercial chez Artère. Ce qui suit sont des extraits de cette conversation. La première partie de cette discussion peut être trouvée ici.
![[De gauche à droite] : Frank Ferro, Cadence ; Steven Woo, Rambus ; Jongsin Yun, Siemens EDA ; Randy Blanc, Keysight ; et Frank Schirrmeister, Arteris.](https://platoaistream.com/wp-content/uploads/2024/01/rethinking-memory.png)
[De gauche à droite] : Frank Ferro, Cadence ; Steven Woo, Rambus ; Jongsin Yun, Siemens EDA ; Randy Blanc, Keysight ; et Frank Schirrmeister, Arteris
SE : Alors que nous luttons contre l’IA/ML et les demandes de puissance, quelles configurations doivent être repensées ? Verrons-nous un abandon de l’architecture de Von Neumann ?
Courtiser: En termes d’architectures système, une bifurcation est en cours dans l’industrie. Les applications traditionnelles qui constituent les bêtes de somme dominantes, que nous exécutons dans le cloud sur des serveurs x86, ne vont pas disparaître. Il y a des décennies de logiciels qui ont été créés et évolués et qui s'appuieront sur cette architecture pour fonctionner correctement. En revanche, l’IA/ML est une nouvelle classe. Les gens ont repensé les architectures et construit des processeurs très spécifiques à un domaine. Nous constatons qu'environ les deux tiers de l'énergie sont consacrés au simple déplacement des données entre un processeur et un appareil HBM, tandis qu'environ un tiers seulement est consacré à l'accès réel aux bits des cœurs DRAM. Le déplacement des données est désormais beaucoup plus difficile et coûteux. Nous n’allons pas nous débarrasser de la mémoire. Nous en avons besoin car les ensembles de données deviennent de plus en plus volumineux. La question est donc : « Quelle est la bonne voie à suivre ? » Il y a eu de nombreuses discussions sur le cumul. Si nous devions prendre cette mémoire et la placer directement au-dessus du processeur, cela ferait deux choses pour vous. Premièrement, la bande passante est aujourd’hui limitée par le littoral ou le périmètre de la puce. C'est là que vont les E/S. Mais si vous l'empilez directement au-dessus du processeur, vous pouvez désormais utiliser toute la zone de la puce pour les interconnexions distribuées, et vous pouvez obtenir plus de bande passante dans la mémoire elle-même, et elle peut alimenter directement le processeur. Les liens deviennent beaucoup plus courts et l'efficacité énergétique augmente probablement de l'ordre de 5X à 6X. Deuxièmement, la quantité de bande passante que vous pouvez obtenir grâce à cette plus grande interconnexion de réseau à la mémoire augmente également d'un facteur plusieurs entiers. Faire ces deux choses ensemble peut fournir plus de bande passante et la rendre plus économe en énergie. L’industrie évolue en fonction des besoins, et c’est certainement une façon pour nous de voir les systèmes de mémoire évoluer à l’avenir pour devenir plus économes en énergie et fournir plus de bande passante.
Le fer: Lorsque j'ai commencé à travailler sur HBM vers 2016, certains des clients les plus avancés m'ont demandé s'il pouvait être empilé. Ils cherchent depuis un certain temps comment empiler la DRAM par-dessus, car cela présente des avantages évidents. Du point de vue physique, le PHY devient fondamentalement négligeable, ce qui permet d'économiser beaucoup de puissance et d'efficacité. Mais vous disposez désormais d’un processeur de plusieurs 100 W doté d’une mémoire en plus. La mémoire ne supporte pas la chaleur. Il s’agit probablement du maillon le plus faible de la chaîne thermique, ce qui crée un autre défi. Il y a des avantages, mais ils doivent encore trouver comment gérer les thermiques. Il y a maintenant plus d’incitations à faire évoluer ce type d’architecture, car cela vous permet réellement d’économiser globalement en termes de performances et de puissance, et cela améliorera votre efficacité de calcul. Mais certains défis de conception physique doivent être résolus. Comme Steve le disait, nous voyons toutes sortes d’architectures apparaître. Je suis tout à fait d’accord sur le fait que les architectures GPU/CPU ne vont nulle part, elles vont toujours dominer. Dans le même temps, toutes les entreprises de la planète tentent de trouver une meilleure souricière pour réaliser leur IA. Nous voyons de la SRAM sur puce et des combinaisons de mémoire à large bande passante. LPDDR a beaucoup relevé la tête ces jours-ci quant à la manière de tirer parti du LPDDR dans le centre de données en raison de la puissance. Nous avons même vu le GDDR être utilisé dans certaines applications d’inférence d’IA, ainsi que dans tous les anciens systèmes de mémoire. Ils essaient maintenant de réduire autant que possible le nombre de DDR5 sur une empreinte. J'ai vu toutes les architectures auxquelles vous pouvez penser, qu'il s'agisse de DDR, HBM, GDDR ou autres. Cela dépend de votre cœur de processeur en termes de valeur ajoutée globale, puis de la manière dont vous pouvez percer votre architecture particulière. Le système de mémoire qui va avec, pour que vous puissiez sculpter votre CPU et votre architecture mémoire, en fonction de ce qui est disponible.
Yun : Un autre problème est la non-volatilité. Si l'IA doit gérer l'intervalle de puissance entre l'exécution d'une IA basée sur l'IoT, par exemple, nous avons besoin de beaucoup de puissance hors et sous tension, et toutes ces informations pour la formation de l'IA doivent tourner encore et encore. Si nous disposons d’un certain type de solutions permettant de stocker ces poids dans la puce afin de ne pas avoir à toujours faire des allers-retours pour le même poids, nous réaliserons alors de nombreuses économies d’énergie, en particulier pour l’IA basée sur l’IoT. Il y aura une autre solution pour répondre à ces demandes de puissance.
Schirrmeister : Ce que je trouve fascinant, du point de vue du NoC, c'est qu'il faut optimiser ces chemins depuis un processeur passant par un NoC, accédant à une interface mémoire avec un contrôleur passant potentiellement par UCIe pour transmettre un chiplet à un autre chiplet, qui a ensuite de la mémoire en mémoire. il. Ce n’est pas que les architectures Von Neumann soient mortes. Mais il existe désormais de nombreuses variantes, en fonction de la charge de travail que vous souhaitez calculer. Ils doivent être considérés dans le contexte de la mémoire, et la mémoire n’est qu’un aspect. Où obtenez-vous les données de la localité de données, comment sont-elles disposées dans cette DRAM ? Nous travaillons sur toutes ces choses, comme l'analyse des performances des mémoires, puis l'optimisation de l'architecture du système. Cela stimule beaucoup d'innovation pour de nouvelles architectures, ce à quoi je n'avais jamais pensé lorsque j'étais à l'université pour étudier Von Neumann. À l’extrême opposé, vous avez des éléments comme les maillages. Il y a maintenant beaucoup plus d’architectures intermédiaires à prendre en compte, et cela dépend de la bande passante mémoire, des capacités de calcul, etc., et cela n’augmente pas au même rythme.
Blanc: Il existe une tendance au calcul désagrégé ou au calcul distribué, ce qui signifie que l’architecte doit disposer de davantage d’outils. La hiérarchie de la mémoire s'est élargie. La sémantique est incluse, ainsi que le CXL et différentes mémoires hybrides, disponibles pour flash et en DRAM. Une application parallèle au centre de données est l’automobile. L'automobile a toujours eu ce capteur calculé avec des ECU (unités de commande électroniques). Je suis fasciné par la façon dont cela a évolué vers le centre de données. Avance rapide et nous disposons aujourd’hui de nœuds de calcul distribués, appelés contrôleurs de domaine. C'est la même chose. Il s’agit d’essayer de résoudre le fait que la puissance n’est peut-être pas un si gros problème parce que l’échelle des ordinateurs n’est pas aussi grande, mais la latence est certainement un gros problème dans le secteur automobile. ADAS a besoin d’une bande passante très élevée et vous devez faire différents compromis. Et puis, il y a davantage de capteurs mécaniques, mais des contraintes similaires dans un data center. Vous disposez d’un stockage froid qui n’a pas besoin d’avoir une faible latence, puis d’autres applications à large bande passante. C’est fascinant de voir à quel point les outils et les options offertes à l’architecte ont évolué. L’industrie a fait un très bon travail en réagissant, et nous proposons tous diverses solutions qui alimentent le marché.
SE : Comment les outils de conception de mémoire ont-ils évolué ?
Schirrmeister : Lorsque j’ai commencé à utiliser mes premières puces dans les années 90, l’outil système le plus utilisé était Excel. Depuis lors, j’ai toujours espéré que cela pourrait se briser à un moment donné pour les choses que nous faisons au niveau du système, de la mémoire, de l’analyse de la bande passante, etc. Cela a pas mal impacté mes équipes. À l’époque, c’était un truc très avancé. Mais pour revenir au point soulevé par Randy, certaines choses complexes doivent désormais être simulées à un niveau de fidélité qui n'était auparavant pas possible sans le calcul. Pour donner un exemple, supposer une certaine latence pour un accès à la DRAM peut conduire à de mauvaises décisions d'architecture et potentiellement à une mauvaise conception des architectures de transport de données sur puce. Le revers de la médaille est également vrai. Si vous supposez toujours le pire des cas, vous sur-concevrez l’architecture. Avoir des outils effectuant la DRAM et l'analyse des performances, et disposer des modèles appropriés pour les contrôleurs permet à un architecte de tout simuler, c'est un environnement fascinant dans lequel évoluer. Mon espoir des années 90 qu'Excel pourrait à un moment donné rompre en tant que un outil au niveau du système pourrait en fait se réaliser, car certains des effets dynamiques que vous ne pouvez plus effectuer dans Excel car vous devez les simuler - en particulier lorsque vous ajoutez une interface die-to-die avec des caractéristiques PHY, puis une couche de liaison des caractéristiques comme toutes les vérifications si tout était correct et potentiellement le renvoi des données. Ne pas effectuer ces simulations entraînera une architecture sous-optimale.
Le fer: La première étape de la plupart des évaluations que nous effectuons consiste à leur fournir le banc de test de la mémoire pour commencer à examiner l'efficacité de la DRAM. C'est une étape énorme, même en faisant des choses aussi simples que d'exécuter des outils locaux pour faire de la simulation DRAM, puis en passant à des simulations à part entière. Nous voyons de plus en plus de clients demander ce type de simulation. S'assurer que l'efficacité de votre DRAM atteint les années 90 est une première étape très importante dans toute évaluation.
Courtiser: Une des raisons pour lesquelles vous constatez l’essor des outils de simulation de système complet est que les DRAM sont devenues beaucoup plus complexes. Il est désormais très difficile d’être à la hauteur pour certaines de ces charges de travail complexes en utilisant des outils simples comme Excel. Si vous regardez la fiche technique de la DRAM dans les années 90, ces fiches techniques faisaient environ 40 pages. Maintenant, ils font des centaines de pages. Cela témoigne simplement de la complexité du dispositif nécessaire pour extraire les bandes passantes élevées. À cela s'ajoute le fait que la mémoire est un facteur important dans le coût du système, ainsi que dans la bande passante et la latence liées aux performances du processeur. C’est également un facteur de puissance important, de sorte que vous devez maintenant simuler à un niveau beaucoup plus détaillé. En termes de flux d'outils, les architectes système comprennent que la mémoire est un facteur déterminant. Les outils doivent donc être plus sophistiqués et s'interfacer très bien avec d'autres outils afin que l'architecte système obtienne la meilleure vue globale de ce qui se passe, en particulier de l'impact de la mémoire sur le système.
Yun : À l’heure de l’IA, de nombreux systèmes multicœurs sont utilisés, mais nous ne savons pas quelles données vont où. Cela va également plus parallèlement à la puce. La taille de la mémoire est beaucoup plus grande. Si nous utilisons le type d'IA ChatGPT, alors la gestion des données pour les modèles nécessite environ 350 Mo de données, ce qui représente une énorme quantité de données rien que pour un poids, et les entrées/sorties réelles sont beaucoup plus importantes. Cette augmentation de la quantité de données requises signifie qu’il existe de nombreux effets probabilistes que nous n’avons jamais vus auparavant. C’est un test extrêmement difficile pour voir toutes les erreurs liées à cette grande quantité de mémoire. Et l’ECC est utilisé partout, même dans la SRAM, qui n’utilisait pas traditionnellement l’ECC, mais qui est désormais très courante pour les plus grands systèmes. Tester tout cela est très difficile et doit être pris en charge par des solutions EDA pour tester toutes ces différentes conditions.
SE : À quels défis les équipes d’ingénierie sont-elles confrontées au quotidien ?
Blanc: N'importe quel jour, vous me trouverez au laboratoire. Je retrousse mes manches et j'ai les mains sales, je pique des fils, je soude, etc. Je pense beaucoup à la validation post-silicium. Nous avons parlé des premiers outils de simulation et des outils sur matrice – BiST, et des choses comme ça. En fin de compte, avant l'expédition, nous souhaitons effectuer une forme de validation du système ou de tests au niveau de l'appareil. Nous avons parlé de la manière de surmonter le mur de la mémoire. Nous colocalisons la mémoire, HBM, des choses comme ça. Si l’on regarde l’évolution de la technologie de l’emballage, nous avons commencé avec des emballages au plomb. Ils n’étaient pas très bons pour l’intégrité du signal. Des décennies plus tard, nous sommes passés à une intégrité de signal optimisée, comme les réseaux à billes (BGA). Nous ne pouvions pas y accéder, ce qui signifiait que vous ne pouviez pas le tester. Nous avons donc proposé ce concept appelé interposeur de périphérique – un interposeur BGA – et cela nous a permis de prendre en sandwich un appareil spécial qui acheminait les signaux. Ensuite, nous pourrions le connecter à l'équipement de test. Avance rapide jusqu’à aujourd’hui, et maintenant nous avons HBM et chiplets. Comment puis-je placer mon luminaire en sandwich sur l'interposeur en silicium ? Nous ne pouvons pas, et c’est là le problème. C’est un défi qui m’empêche de dormir la nuit. Comment pouvons-nous effectuer une analyse des défaillances sur le terrain avec un client OEM ou système, lorsqu'il n'obtient pas une efficacité de 90 % ? Il y a plus d'erreurs dans le lien, ils ne peuvent pas s'initialiser correctement et la formation ne fonctionne pas. Est-ce un problème d'intégrité du système ?
Schirrmeister : Ne préféreriez-vous pas faire cela depuis chez vous avec une interface virtuelle plutôt que de vous rendre au laboratoire à pied ? La réponse n’est-elle pas davantage d’analyses que vous intégrez à la puce ? Avec les chiplets, nous intégrons tout encore plus. Insérer votre fer à souder n'est pas vraiment une option, il doit donc y avoir un moyen d'analyse sur puce. Nous avons le même problème pour le NoC. Les gens regardent le NoC, vous envoyez les données, puis elles disparaissent. Nous avons besoin d'analyses à intégrer pour que les gens puissent effectuer le débogage, et cela s'étend au niveau de la fabrication, afin que vous puissiez enfin travailler à domicile et tout faire sur la base de l'analyse des puces.
Le fer: Surtout avec une mémoire à large bande passante, vous ne pouvez pas physiquement y accéder. Lorsque nous accordons une licence au PHY, nous avons également un produit qui va avec afin que vous puissiez voir chacun de ces 1,024 3 bits. Vous pouvez commencer à lire et à écrire de la DRAM à partir de l’outil afin de ne pas avoir à y entrer physiquement. J'aime l'idée de l'interposeur. Nous retirons certaines broches de l'interposeur pendant les tests, ce que vous ne pouvez pas faire dans le système. C’est vraiment un défi d’entrer dans ces systèmes 2.5D. Même du point de vue du flux des outils de conception, il semble que la plupart des entreprises créent leur propre flux individuel sur un grand nombre de ces outils 2.5D. Nous commençons à mettre au point une manière plus standardisée de construire un système XNUMXD, depuis l'intégrité du signal, la puissance, l'ensemble du flux.
Blanc: À mesure que les choses avancent, j’espère que nous pourrons toujours maintenir le même niveau de précision. Je fais partie du groupe de conformité du facteur de forme UCIe. Je cherche à caractériser un bon dé connu, un dé en or. À terme, cela prendra beaucoup plus de temps, mais nous allons trouver un juste milieu entre les performances et la précision des tests dont nous avons besoin, et la flexibilité intégrée.
Schirrmeister : Si j’examine les chipsets et leur adoption dans un environnement de production plus ouvert, les tests constituent l’un des plus grands défis pour les faire fonctionner correctement. Si je suis une grande entreprise et que j’en contrôle tous les aspects, je peux alors limiter les choses de manière appropriée afin que les tests, etc., deviennent réalisables. Si je veux reprendre le slogan de l'UCIe selon lequel l'UCI n'est qu'à une lettre du PCI, et j'imagine un avenir où l'assemblage UCIe deviendra, du point de vue de la fabrication, comme les emplacements PCI dans un PC aujourd'hui, alors les aspects de test pour cela sont vraiment difficile. Nous devons trouver une solution. Il y a beaucoup de travail à faire.
Articles Relatifs
L'avenir de la mémoire (Partie 1 du tour ci-dessus)
Des tentatives visant à résoudre les problèmes thermiques et électriques aux rôles du CXL et de l’UCIe, l’avenir offre de nombreuses opportunités pour la mémoire.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://semiengineering.com/rethinking-memory/
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 2016
- 3d
- 40
- a
- A Propos
- au dessus de
- accès
- accès
- précision
- présenter
- actually
- ADA
- ajouter
- propos
- Adoption
- Avancée
- Avantage
- avantages
- encore
- AI
- Formation IA
- AI / ML
- Tous
- permis
- permet
- aussi
- toujours
- montant
- an
- selon une analyse de l’Université de Princeton
- analytique
- ainsi que
- Une autre
- répondre
- tous
- plus
- de n'importe où
- Application
- applications
- de manière appropriée
- architectes
- architecture
- SONT
- Réservé
- autour
- arrangé
- tableau
- AS
- demandant
- d'aspect
- aspects
- Assemblée
- assumer
- At
- Tentatives
- l'automobile
- disponibles
- et
- RETOUR
- Mal
- balle
- Bande passante
- barre
- basé
- En gros
- base
- BE
- car
- devenez
- devient
- était
- before
- va
- avantages.
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Big
- plus gros
- Bit
- Pause
- apporter
- construire
- construit
- la performance des entreprises
- Développement des affaires
- mais
- by
- Cadence
- appelé
- venu
- CAN
- Peut obtenir
- capacités
- maisons
- Canaux centraux
- certaines
- Assurément
- chaîne
- challenge
- globaux
- difficile
- caractéristiques
- caractériser
- vérification
- puce
- chips
- classe
- clair
- le cloud
- du froid
- Température Contrôlée
- комбинации
- comment
- Venir
- Commun
- Sociétés
- Société
- complexe
- complexité
- conformité
- compliqué
- calcul
- ordinateurs
- informatique
- concept
- conditions
- NOUS CONTACTER
- considéré
- contraintes
- contexte
- contraste
- des bactéries
- contrôleur
- Conversation
- Core
- correct
- Prix
- pourriez
- Couples
- Processeur
- crée des
- des clients
- Clients
- données
- Centre de données
- ensembles de données
- journée
- jour après jour
- jours
- parfaite
- affaire
- décennies
- décisions
- certainement, vraiment, définitivement
- demandes
- Selon
- dépend
- Conception
- conception
- détaillé
- Développement
- dispositif
- J'ai noté la
- différent
- difficile
- directement
- Directeur
- spirituelle
- disposition
- Distingué
- distribué
- informatique distribuée
- do
- Ne fait pas
- faire
- domaine
- dominant
- fait
- Ne pas
- down
- entraîné
- driver
- pendant
- Dynamic
- "Early Bird"
- les effets
- efficace
- efficace
- Electronique
- fin
- énergie
- ENGINEERING
- Tout
- Environment
- l'équipements
- Ère
- Erreurs
- notamment
- Ether (ETH)
- évaluation
- évaluations
- Pourtant, la
- faire une éventuelle
- Chaque
- peut
- partout
- évolution
- évolue
- évolué
- évolue
- exemple
- Excel
- étendu
- cher
- S'étend
- extrême
- extrêmement
- Yeux
- Visage
- fait
- facteur
- Échec
- fascinant
- RAPIDE
- réalisable
- compagnon
- fidélité
- champ
- Figure
- finalement
- Trouvez
- Prénom
- Flash
- Flexibilité
- Retournement
- flux
- suit
- numérique
- Pour
- formulaire
- en avant
- Avant
- trouvé
- franc
- De
- plein
- plus
- avenir
- obtenez
- obtention
- Donner
- donné
- Global
- Go
- Goes
- aller
- Or
- disparu
- Bien
- bon travail
- eu
- Grille
- Réservation de groupe
- Croissance
- ait eu
- Maniabilité
- Mains
- heureux vous
- Vous avez
- ayant
- front
- vous aider
- hiérarchie
- Haute
- détient
- Accueil
- d'espérance
- Comment
- How To
- HTML
- HTTPS
- majeur
- Des centaines
- Hybride
- i
- idée
- if
- image
- impact
- impactant
- important
- améliorer
- in
- Motivation
- inclus
- à tort
- Améliore
- de plus en plus
- individuel
- industrie
- d'information
- Innovation
- à l'intérieur
- intégrer
- intégrité
- s'interconnecte
- Interfaces
- développement
- impliquant
- aide
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- SES
- lui-même
- Emploi
- juste
- Savoir
- connu
- laboratoire
- gros
- plus importantes
- le plus grand
- Latence
- plus tard
- couche
- conduire
- apprentissage
- lettre
- Niveau
- Licence
- comme
- limité
- LINK
- Gauche
- locales
- Style
- recherchez-
- Lot
- beaucoup
- Faible
- maintenir
- a prendre une
- Fabrication
- gestion
- manager
- fabrication
- de nombreuses
- Marché
- largeur maximale
- peut être
- me
- veux dire
- signifiait
- mécanique
- moyenne
- Souvenirs
- Mémoire
- pourrait
- numériques jumeaux (digital twin models)
- PLUS
- (en fait, presque toutes)
- Bougez
- déménagé
- mouvement
- en mouvement
- beaucoup
- my
- Besoin
- Besoins
- n'allons jamais
- Nouveauté
- nuit
- nœuds
- maintenant
- nombre
- of
- de rabais
- Vieux
- on
- ONE
- uniquement
- ouvert
- Opportunités
- Optimiser
- optimisé
- l'optimisation
- Option
- Options
- or
- de commander
- Autre
- Autres
- ande
- global
- Overcome
- propre
- Forfaits
- l'emballage
- pages
- Parallèle
- partie
- particulier
- pass
- chemin
- chemins
- PC
- Personnes
- effectuer
- performant
- objectifs
- Physique
- Physiquement
- broches
- planète
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- possible
- l'éventualité
- power
- président
- précédemment
- Probablement
- Problème
- Processeur
- processeurs
- Produit
- gestion des produits
- Vidéo
- Programme
- correct
- correctement
- fournir
- mettre
- question
- assez
- élevage
- Tarif
- plutôt
- en cours
- vraiment
- en relation
- compter
- conditions
- a besoin
- résoudre
- répondre
- résultat
- Débarrasser
- bon
- Augmenter
- rôle
- Roulent
- Courir
- pour le running
- même
- Épargnez
- Épargnes
- dire
- Escaliers intérieurs
- Deuxièmement
- sur le lien
- voir
- semble
- vu
- sémantique
- semi-conducteur
- envoyer
- capteur
- capteur
- serveurs
- plusieurs
- feuilles
- décalage
- navire
- côté
- Accompagnements
- Siemens
- Signal
- signaux
- Silicium
- similaires
- étapes
- simulation
- simulations
- depuis
- unique
- Taille
- fentes
- So
- Logiciels
- sur mesure
- Solutions
- quelques
- sophistiqué
- parle
- spécial
- dépensé
- La technique “squeeze”
- empiler
- empilé
- empilage
- standardisé
- point de vue
- Commencer
- j'ai commencé
- Commencez
- étapes
- Steve
- steven
- Encore
- storage
- Boutique
- Lutter
- tel
- Appareils
- sûr
- combustion propre
- Système
- table
- Prenez
- discutons-en
- équipes
- technologue
- Technologie
- conditions
- tester
- Essais
- tests
- que
- qui
- La
- El futuro
- leur
- Les
- puis
- Là.
- thermique
- Ces
- l'ont
- chose
- des choses
- penser
- Troisièmement
- this
- ceux
- pensée
- Avec
- fiable
- à
- aujourd'hui
- ensemble
- outil
- les outils
- top
- TOTALEMENT
- compromis
- traditionnel
- traditionnellement
- Formation
- transport
- Trend
- oui
- essayer
- deux
- les deux tiers
- type
- comprendre
- unités
- université
- us
- utilisé
- d'utiliser
- en utilisant
- validation
- Plus-value
- variations
- divers
- très
- vice
- Vice-président
- Voir
- Salle de conférence virtuelle
- ab
- marche
- Wall
- souhaitez
- était
- Façon..
- we
- poids
- WELL
- ont été
- Quoi
- quelle que soit
- quand
- que
- qui
- tout en
- blanc
- la totalité
- why
- sera
- comprenant
- sans
- Courtiser
- activités principales
- travailler à la maison
- de travail
- pire
- écriture
- you
- Votre
- zéphyrnet