Un nouveau système d'intelligence artificielle (IA) basé sur l'apprentissage par renforcement profond (DRL) peut réagir aux attaquants dans un environnement simulé et bloquer 95 % des cyberattaques avant qu'elles ne dégénèrent.
C'est selon les chercheurs du Pacific Northwest National Laboratory du Department of Energy qui ont construit une simulation abstraite du conflit numérique entre les attaquants et les défenseurs dans un réseau et formé quatre réseaux de neurones DRL différents pour maximiser les récompenses en évitant les compromis et en minimisant les perturbations du réseau.
Les attaquants simulés ont utilisé une série de tactiques basées sur le MITRE ATT & CK classification du cadre pour passer de la phase initiale d'accès et de reconnaissance à d'autres phases d'attaque jusqu'à ce qu'elles atteignent leur but : la phase d'impact et d'exfiltration.
La formation réussie du système d'IA sur l'environnement d'attaque simplifié démontre que les réponses défensives aux attaques en temps réel pourraient être gérées par un modèle d'IA, déclare Samrat Chatterjee, un scientifique des données qui a présenté le travail de l'équipe lors de la réunion annuelle de l'Association pour la Advancement of Artificial Intelligence à Washington, DC le 14 février.
« Vous ne voulez pas passer à des architectures plus complexes si vous ne pouvez même pas montrer la promesse de ces techniques », dit-il. "Nous voulions d'abord démontrer que nous pouvons réellement former un DRL avec succès et montrer de bons résultats de test, avant d'aller de l'avant."
L'application des techniques d'apprentissage automatique et d'intelligence artificielle à différents domaines de la cybersécurité est devenue une tendance brûlante au cours de la dernière décennie, depuis l'intégration précoce de l'apprentissage automatique dans les passerelles de sécurité des e-mails au début des 2010 aux efforts plus récents pour utiliser ChatGPT pour analyser le code ou effectuer une analyse médico-légale. Maintenant, la plupart des produits de sécurité ont - ou prétendent avoir - quelques fonctionnalités alimentées par des algorithmes d'apprentissage automatique formés sur de grands ensembles de données.
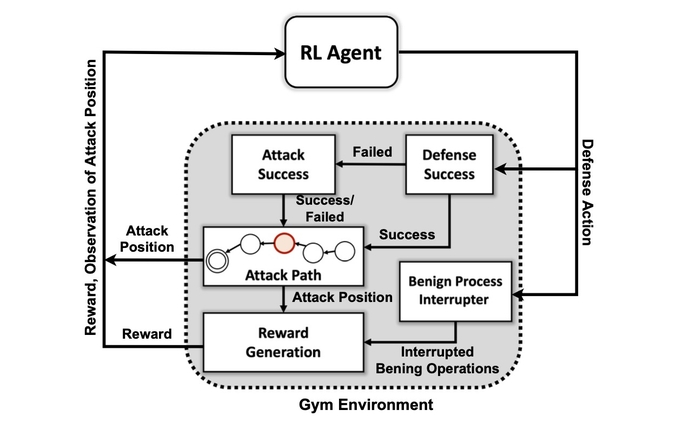
Pourtant, la création d'un système d'IA capable de défense proactive continue d'être une aspiration plutôt que pratique. Alors qu'une variété d'obstacles subsistent pour les chercheurs, la recherche du PNNL montre qu'un défenseur de l'IA pourrait être possible à l'avenir.
"L'évaluation de plusieurs algorithmes DRL formés dans divers contextes contradictoires est une étape importante vers des solutions pratiques de cyberdéfense autonomes", a déclaré l'équipe de recherche du PNNL. indiqué dans leur article. "Nos expériences suggèrent que les algorithmes DRL sans modèle peuvent être efficacement formés sous des profils d'attaque à plusieurs étapes avec différents niveaux de compétence et de persistance, donnant des résultats de défense favorables dans des contextes contestés."
Comment le système utilise MITRE ATT&CK
Le premier objectif de l'équipe de recherche était de créer un environnement de simulation personnalisé basé sur une boîte à outils open source connue sous le nom de Salle de sport IA ouverte. En utilisant cet environnement, les chercheurs ont créé des entités d'attaquants de différents niveaux de compétence et de persistance avec la possibilité d'utiliser un sous-ensemble de 7 tactiques et 15 techniques du cadre MITRE ATT&CK.
Les objectifs des agents attaquants sont de parcourir les sept étapes de la chaîne d'attaque, de l'accès initial à l'exécution, de la persistance au commandement et au contrôle, et de la collecte à l'impact.
Pour l'attaquant, adapter sa tactique à l'état de l'environnement et aux actions actuelles du défenseur peut être complexe, explique Chatterjee du PNNL.
"L'adversaire doit naviguer d'un état de reconnaissance initial jusqu'à un état d'exfiltration ou d'impact", dit-il. "Nous n'essayons pas de créer une sorte de modèle pour arrêter un adversaire avant qu'il ne pénètre dans l'environnement - nous supposons que le système est déjà compromis."
Les chercheurs ont utilisé quatre approches de réseaux de neurones basées sur l'apprentissage par renforcement. L'apprentissage par renforcement (RL) est une approche d'apprentissage automatique qui émule le système de récompense du cerveau humain. Un réseau de neurones apprend en renforçant ou en affaiblissant certains paramètres pour les neurones individuels afin de récompenser les meilleures solutions, telles que mesurées par un score indiquant la performance du système.
L'apprentissage par renforcement permet essentiellement à l'ordinateur de créer une bonne approche, mais pas parfaite, du problème à résoudre, explique Mahantesh Halappanavar, chercheur au PNNL et auteur de l'article.
"Sans utiliser d'apprentissage par renforcement, nous pourrions toujours le faire, mais ce serait un très gros problème qui n'aura pas assez de temps pour trouver un bon mécanisme", dit-il. "Notre recherche… nous donne ce mécanisme où l'apprentissage par renforcement profond imite en quelque sorte une partie du comportement humain lui-même, dans une certaine mesure, et il peut explorer très efficacement cet espace très vaste."
Pas prêt pour le premier temps
Les expériences ont montré qu'une méthode d'apprentissage par renforcement spécifique, connue sous le nom de Deep Q Network, créait une solution solide au problème défensif, attraper 97% des attaquants dans le jeu de données de test. Pourtant, la recherche n'est que le début. Les professionnels de la sécurité ne devraient pas chercher un compagnon d'intelligence artificielle pour les aider à réagir aux incidents et à la criminalistique de sitôt.
Parmi les nombreux problèmes qui restent à résoudre, il y a l'apprentissage par renforcement et les réseaux de neurones profonds pour expliquer les facteurs qui ont influencé leurs décisions, un domaine de recherche appelé apprentissage par renforcement explicable (XRL).
De plus, la robustesse des algorithmes d'IA et la recherche de moyens efficaces de former les réseaux de neurones sont deux problèmes qui doivent être résolus, déclare Chatterjee du PNNL.
"Créer un produit - ce n'était pas la principale motivation de cette recherche", dit-il. "Il s'agissait davantage d'expérimentation scientifique et de découverte algorithmique."
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- capacité
- A Propos
- RÉSUMÉ
- accès
- Selon
- actes
- actually
- ajout
- avancement
- contradictoire
- agents
- AI
- Alimenté par l'IA
- algorithmique
- algorithmes
- Tous
- permet
- déjà
- selon une analyse de l’Université de Princeton
- il analyse
- et les
- annuel
- Application
- une approche
- approches
- Réservé
- artificiel
- intelligence artificielle
- Intelligence artificielle (AI)
- Association
- attaquer
- Attaques
- auteur
- autonome
- basé
- devenez
- before
- Améliorée
- jusqu'à XNUMX fois
- Big
- Block
- Cerveau
- construit
- appelé
- ne peut pas
- capable
- certaines
- chaîne
- ChatGPT
- réclamer
- classification
- collection
- comment
- complexe
- Compromise
- ordinateur
- Conduire
- conflit
- continue
- des bactéries
- pourriez
- engendrent
- créée
- La création
- Courant
- Customiser
- cyber
- cyber-attaques
- Cybersécurité
- données
- Data Scientist
- ensemble de données
- ensembles de données
- dc
- décennie
- décision
- décisions
- profond
- réseaux de neurones profonds
- défenseurs
- Défense
- défensive
- démontrer
- démontre
- Département
- Ministère de l'Énergie
- différent
- numérique
- découverte
- Perturbation
- plusieurs
- DOE
- "Early Bird"
- de manière efficace
- efficace
- efficacement
- efforts
- sécurité de messagerie
- énergie
- assez
- entités
- Environment
- essentiellement
- Ether (ETH)
- évaluer
- Pourtant, la
- exécution
- exfiltration
- Expliquer
- explorez
- facteurs
- Fonctionnalités:
- few
- Des champs
- trouver
- Prénom
- flux
- Légal
- forensics
- Avant
- trouvé
- Framework
- De
- avenir
- obtenez
- obtention
- donne
- objectif
- Objectifs
- Bien
- main
- aider
- HOT
- Comment
- HTTPS
- humain
- Haies
- Impact
- important
- in
- incident
- réponse à l'incident
- indiquant
- individuel
- influencé
- initiale
- l'intégration
- Intelligence
- IT
- lui-même
- Genre
- connu
- laboratoire
- gros
- apprentissage
- niveaux
- Style
- click
- machine learning
- Entrée
- de nombreuses
- largeur maximale
- Maximisez
- mécanisme
- réunion
- méthode
- réduisant au minimum
- modèle
- PLUS
- motivation
- Bougez
- en mouvement
- plusieurs
- Nationales
- NAVIGUER
- Besoin
- réseau et
- réseaux
- Neural
- Réseau neuronal
- les réseaux de neurones
- Neurones
- ouvert
- open source
- Autre
- Pacifique
- Papier
- paramètres
- passé
- parfaite
- effectue
- persistance
- phase
- Platon
- Intelligence des données Platon
- PlatonDonnées
- possible
- alimenté
- Méthode
- présenté
- prévention
- Prime
- Cybersécurité
- Problème
- d'ouvrabilité
- Produits
- ,une équipe de professionnels qualifiés
- Profils
- PROMETTONS
- RE
- atteint
- Réagir
- Réagit
- solutions
- réal
- en temps réel
- récent
- apprentissage par renforcement
- rester
- un article
- chercheur
- chercheurs
- réponse
- Récompenser
- Programme de fidélité
- solidité
- dit
- Scientifique
- sécurité
- Série
- set
- Paramétres
- sept
- devrait
- montrer
- Spectacles
- simplifié
- simulation
- compétence
- sur mesure
- Solutions
- quelques
- disponible
- Identifier
- l'espace
- groupe de neurones
- Commencer
- Région
- étapes
- Étapes
- Encore
- Arrêter
- renforcement
- STRONG
- réussi
- Avec succès
- combustion propre
- tactique
- équipe
- techniques
- Essais
- Le
- El futuro
- L'État
- leur
- Avec
- fiable
- à
- Boîte à outils
- vers
- Train
- qualifié
- Formation
- Trend
- sous
- us
- utilisé
- variété
- Vaste
- voulu
- Washington
- façons
- tout en
- WHO
- sera
- dans les
- sans
- activités principales
- pourra
- élastique
- zéphyrnet











