Sponsored Posts

Les défis de la construction de modèles multimodaux à partir de zéro
Pour de nombreux cas d’utilisation du machine learning, les organisations s’appuient uniquement sur des données tabulaires et des modèles arborescents comme XGBoost et LightGBM. En effet, l’apprentissage profond est tout simplement trop difficile pour la plupart des équipes ML. Les défis courants comprennent :
- Manque de connaissances spécialisées nécessaires pour développer des modèles complexes d’apprentissage profond
- Les frameworks comme PyTorch et Tensorflow obligent les équipes à écrire des milliers de lignes de code sujettes aux erreurs humaines.
- La formation des pipelines DL distribués nécessite une connaissance approfondie de l'infrastructure et peut prendre des semaines pour former des modèles.
En conséquence, les équipes passent à côté de signaux précieux cachés dans les données non structurées comme le texte et les images.
Développement rapide de modèles avec des systèmes déclaratifs
Les nouveaux systèmes d'apprentissage automatique déclaratif, comme l'open source que Ludwig a lancé chez Uber, offrent une approche low-code de l'automatisation du ML qui permet aux équipes de données de créer et de déployer plus rapidement des modèles de pointe avec un simple fichier de configuration. Plus précisément, Predibase, la principale plate-forme de ML déclarative low-code, aux côtés de Ludwig, facilite la création de modèles d'apprentissage profond multimodaux en <15 lignes de code.
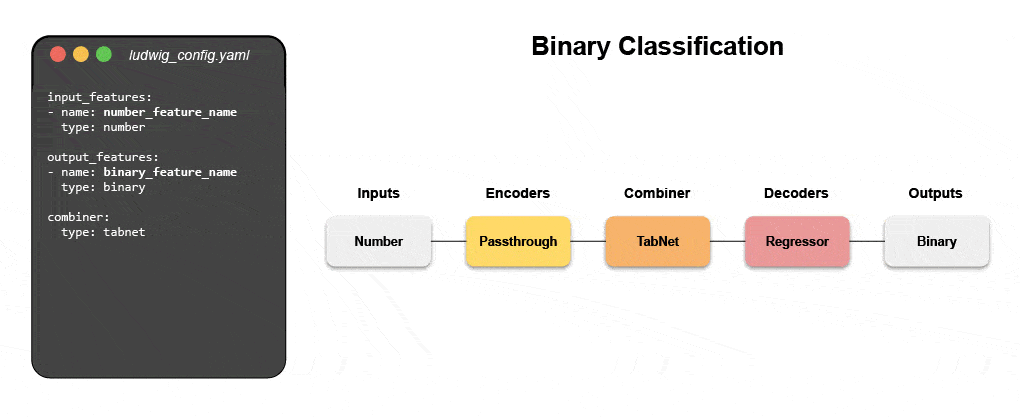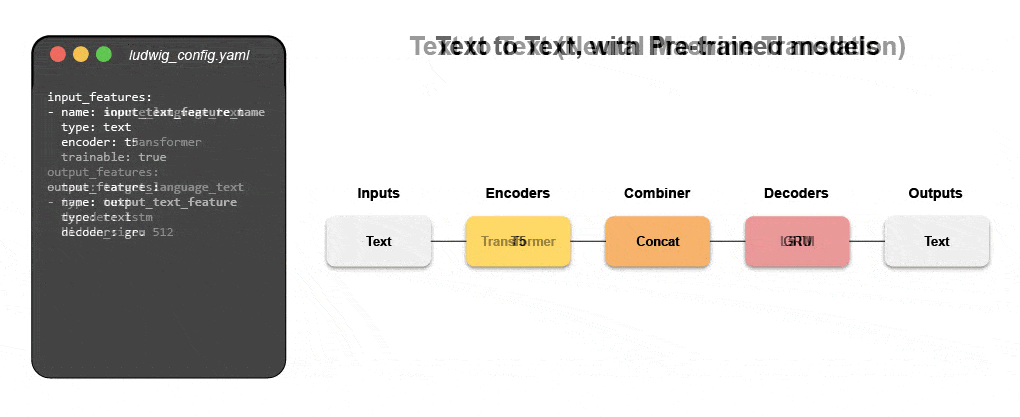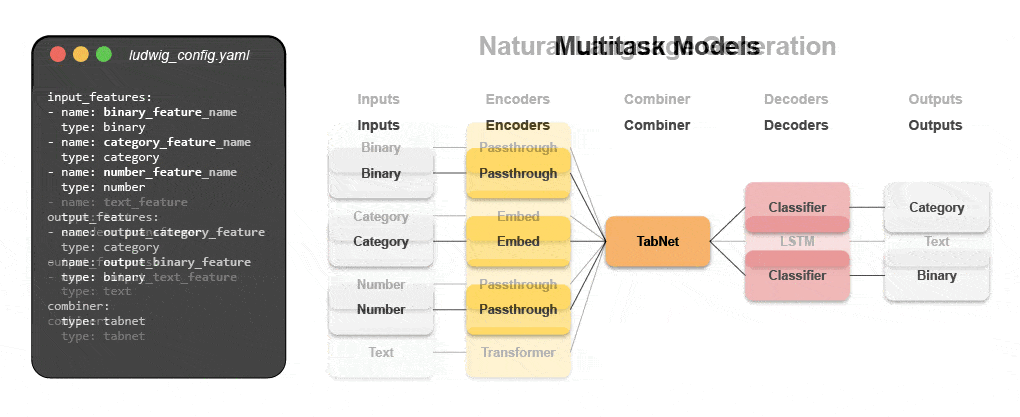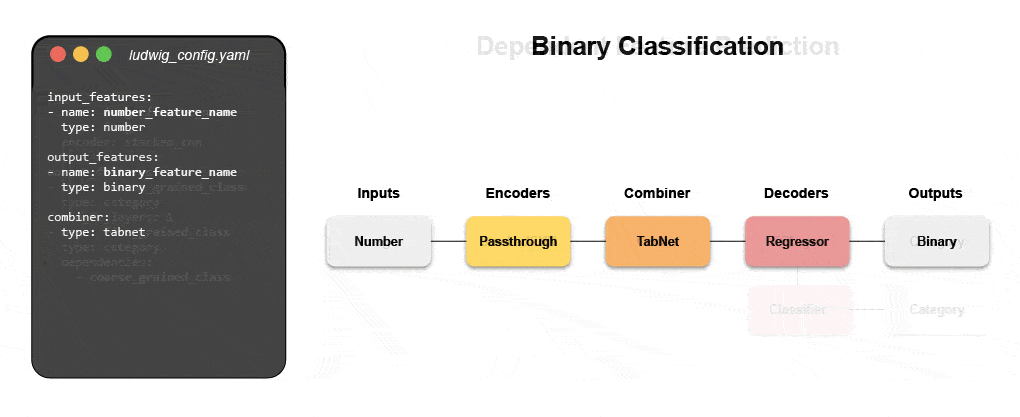
Découvrez comment créer un modèle multimodal avec le ML déclaratif
Rejoignez notre prochain webinaire et un didacticiel en direct pour en savoir plus sur les systèmes déclaratifs comme Ludwig et suivre les instructions étape par étape pour créer un modèle de prédiction d'avis client multimodal tirant parti du texte et des données tabulaires.
Dans cette séance, vous apprendrez à :
- Entraînez, itérez et déployez rapidement un modèle multimodal pour les prédictions des avis clients,
- Utilisez des outils de ML déclaratif low-code pour réduire considérablement le temps nécessaire à la création de plusieurs modèles de ML,
- Exploitez les données non structurées aussi facilement que les données structurées avec Ludwig et Predibase open source
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.kdnuggets.com/2023/01/predibase-multi-modal-deep-learning-less-15-lines-code.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-modal-deep-learning-in-less-than-15-lines-of-code
- a
- Qui sommes-nous
- ainsi que
- une approche
- automatiser
- car
- construire
- Développement
- globaux
- code
- Commun
- complexe
- configuration
- des clients
- données
- profond
- l'apprentissage en profondeur
- déployer
- développer
- Développement
- distribué
- Dramatiquement
- même
- permet
- erreur
- expert
- plus rapide
- Déposez votre dernière attestation
- suivre
- de
- gif
- Dur
- caché
- Comment
- How To
- HTML
- HTTPS
- humain
- satellite
- in
- comprendre
- Infrastructure
- Des instructions
- IT
- KDnuggetsGenericName
- spécialisées
- conduisant
- APPRENTISSAGE
- apprentissage
- en tirant parti
- lignes
- le travail
- click
- machine learning
- faire
- de nombreuses
- ML
- modèle
- numériques jumeaux (digital twin models)
- (en fait, presque toutes)
- plusieurs
- nécessaire
- open source
- organisations
- Platon
- Intelligence des données Platon
- PlatonDonnées
- prédiction
- Prédictions
- pytorch
- réduire
- exigent
- a besoin
- résultat
- Avis
- Session
- signaux
- étapes
- simplement
- spécifiquement
- j'ai commencé
- state-of-the-art
- étapes
- structuré
- Système
- Prenez
- prend
- équipes
- tensorflow
- La
- milliers
- fiable
- à
- trop
- les outils
- Train
- tutoriel
- prochain
- cas d'utilisation
- Précieux
- Semaines
- sera
- dans les
- écrire
- XGBoost
- Votre
- zéphyrnet





