Cet article est co-écrit avec Pramod Nayak, LakshmiKanth Mannem et Vivek Aggarwal du Low Latency Group du LSEG.
L'analyse des coûts de transaction (TCA) est largement utilisée par les traders, les gestionnaires de portefeuille et les courtiers pour l'analyse pré-négociation et post-négociation, et les aide à mesurer et à optimiser les coûts de transaction et l'efficacité de leurs stratégies de négociation. Dans cet article, nous analysons les spreads bid-ask des options du Historique des ticks LSEG – PCAP ensemble de données utilisant Amazon Athena pour Apache Spark. Nous vous montrons comment accéder aux données, définir des fonctions personnalisées à appliquer sur les données, interroger et filtrer l'ensemble de données et visualiser les résultats de l'analyse, le tout sans avoir à vous soucier de la mise en place de l'infrastructure ou de la configuration de Spark, même pour de grands ensembles de données.
Contexte
Options Price Reporting Authority (OPRA) sert de processeur d'informations sur les titres crucial, collectant, consolidant et diffusant les rapports de dernières ventes, les cotations et les informations pertinentes pour les options américaines. Avec 18 bourses d'options américaines actives et plus de 1.5 million de contrats éligibles, l'OPRA joue un rôle central en fournissant des données de marché complètes.
Le 5 février 2024, la Securities Industry Automation Corporation (SIAC) devrait mettre à niveau le flux OPRA de 48 à 96 canaux de multidiffusion. Cette amélioration vise à optimiser la distribution des symboles et l'utilisation de la capacité des lignes en réponse à l'activité commerciale croissante et à la volatilité du marché des options américain. La SIAC a recommandé aux entreprises de se préparer à des débits de données de pointe pouvant atteindre 37.3 Gbits par seconde.
Même si la mise à niveau ne modifie pas immédiatement le volume total des données publiées, elle permet à l'OPRA de diffuser les données à un rythme nettement plus rapide. Cette transition est cruciale pour répondre aux demandes du marché dynamique des options.
OPRA se distingue comme l’un des flux les plus volumineux, avec un pic de 150.4 milliards de messages en une seule journée au troisième trimestre 3 et une marge de capacité requise de 2023 milliards de messages sur une seule journée. La capture de chaque message est essentielle pour l'analyse des coûts de transaction, la surveillance de la liquidité du marché, l'évaluation des stratégies de trading et les études de marché.
À propos des données
Historique des ticks LSEG – PCAP est un référentiel basé sur le cloud, dépassant 30 Po, hébergeant des données de marché mondial de très haute qualité. Ces données sont méticuleusement capturées directement dans les centres de données d'échange, à l'aide de processus de capture redondants stratégiquement positionnés dans les principaux centres de données d'échange primaires et de sauvegarde du monde entier. La technologie de capture de LSEG garantit une capture de données sans perte et utilise une source de temps GPS pour une précision d'horodatage à la nanoseconde. De plus, des techniques sophistiquées d’arbitrage de données sont utilisées pour combler de manière transparente toute lacune dans les données. Après la capture, les données subissent un traitement et un arbitrage méticuleux, puis sont normalisées au format Parquet à l'aide de Ultra Direct en temps réel de LSEG (RTUD) gestionnaires d’alimentation.
Le processus de normalisation, qui fait partie intégrante de la préparation des données pour l'analyse, génère jusqu'à 6 To de fichiers Parquet compressés par jour. Le volume massif de données est attribué à la nature globale de l'OPRA, couvrant plusieurs bourses et comportant de nombreux contrats d'options caractérisés par divers attributs. La volatilité accrue du marché et l'activité de tenue de marché sur les bourses d'options contribuent également au volume de données publiées sur l'OPRA.
Les attributs de Tick History – PCAP permettent aux entreprises d’effectuer diverses analyses, notamment les suivantes :
- Analyse pré-négociation – Évaluer l’impact potentiel du commerce et explorer différentes stratégies d’exécution basées sur des données historiques
- Évaluation post-négociation – Mesurer les coûts d’exécution réels par rapport à des références pour évaluer les performances des stratégies d’exécution
- Optimisé exécution – Affiner les stratégies d'exécution en fonction des modèles de marché historiques pour minimiser l'impact sur le marché et réduire les coûts globaux de négociation
- La gestion des risques – Identifier les modèles de dérapage, identifier les valeurs aberrantes et gérer de manière proactive les risques associés aux activités de trading
- Attribution des performances – Séparez l’impact des décisions de trading des décisions d’investissement lors de l’analyse des performances du portefeuille
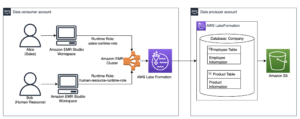
L'ensemble de données LSEG Tick History – PCAP est disponible en Échange de données AWS et accessible sur Marketplace AWS . Avec Échange de données AWS pour Amazon S3, vous pouvez accéder aux données PCAP directement à partir du LSEG Service de stockage simple Amazon (Amazon S3), éliminant ainsi le besoin pour les entreprises de stocker leur propre copie des données. Cette approche rationalise la gestion et le stockage des données, offrant aux clients un accès immédiat à des données PCAP ou normalisées de haute qualité avec une facilité d'utilisation, d'intégration et économies substantielles de stockage de données.
Athéna pour Apache Spark
Pour les efforts d'analyse, Athéna pour Apache Spark offre une expérience de bloc-notes simplifiée accessible via la console Athena ou les API Athena, vous permettant de créer des applications Apache Spark interactives. Avec un temps d'exécution Spark optimisé, Athena facilite l'analyse de pétaoctets de données en augmentant dynamiquement le nombre de moteurs Spark en moins d'une seconde. De plus, les bibliothèques Python courantes telles que pandas et NumPy sont parfaitement intégrées, permettant la création d'une logique d'application complexe. La flexibilité s'étend à l'importation de bibliothèques personnalisées à utiliser dans les blocs-notes. Athena for Spark prend en charge la plupart des formats de données ouvertes et s'intègre parfaitement à Colle AWS Catalogue de données.
Ensemble de données
Pour cette analyse, nous avons utilisé l'ensemble de données LSEG Tick History – PCAP OPRA du 17 mai 2023. Cet ensemble de données comprend les éléments suivants :
- Meilleure offre et offre (BBO) – Signale l’offre la plus élevée et la demande la plus basse pour un titre à une bourse donnée
- Meilleures offres et offres nationales (NBBO) – Signale l’offre la plus élevée et la demande la plus basse pour un titre sur toutes les bourses
- Métiers – Enregistre les transactions terminées sur toutes les bourses
L'ensemble de données implique les volumes de données suivants :
- Métiers – 160 Mo répartis sur environ 60 fichiers Parquet compressés
- l'équipe BBO – 2.4 To répartis sur environ 300 fichiers Parquet compressés
- NBO – 2.8 To répartis sur environ 200 fichiers Parquet compressés
Aperçu de l'analyse
L'analyse des données de l'historique des ticks OPRA pour l'analyse des coûts de transaction (TCA) implique l'examen minutieux des cotations du marché et des transactions autour d'un événement commercial spécifique. Nous utilisons les métriques suivantes dans le cadre de cette étude :
- Spread coté (QS) – Calculé comme la différence entre la demande BBO et l’offre BBO
- Diffusion efficace (ES) – Calculé comme la différence entre le prix de transaction et le point médian du BBO (offre BBO + (offre BBO – offre BBO)/2)
- Spread effectif/coté (EQF) – Calculé comme (ES / QS) * 100
Nous calculons ces spreads avant la transaction et également à quatre intervalles après la transaction (juste après, 1 seconde, 10 secondes et 60 secondes après la transaction).
Configurer Athena pour Apache Spark
Pour configurer Athena pour Apache Spark, procédez comme suit :
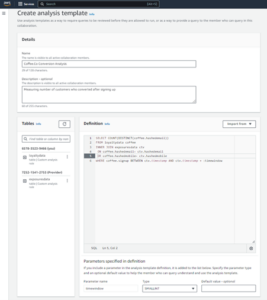
- Sur la console Athena, sous Commencez, sélectionnez Analysez vos données à l'aide de PySpark et Spark SQL.
- Si c'est la première fois que vous utilisez Athena Spark, choisissez Créer un groupe de travail.

- Pour Nom du groupe de travail¸ saisissez un nom pour le groupe de travail, tel que
tca-analysis. - Dans le Moteur d'analyse section, sélectionnez Apache Spark.
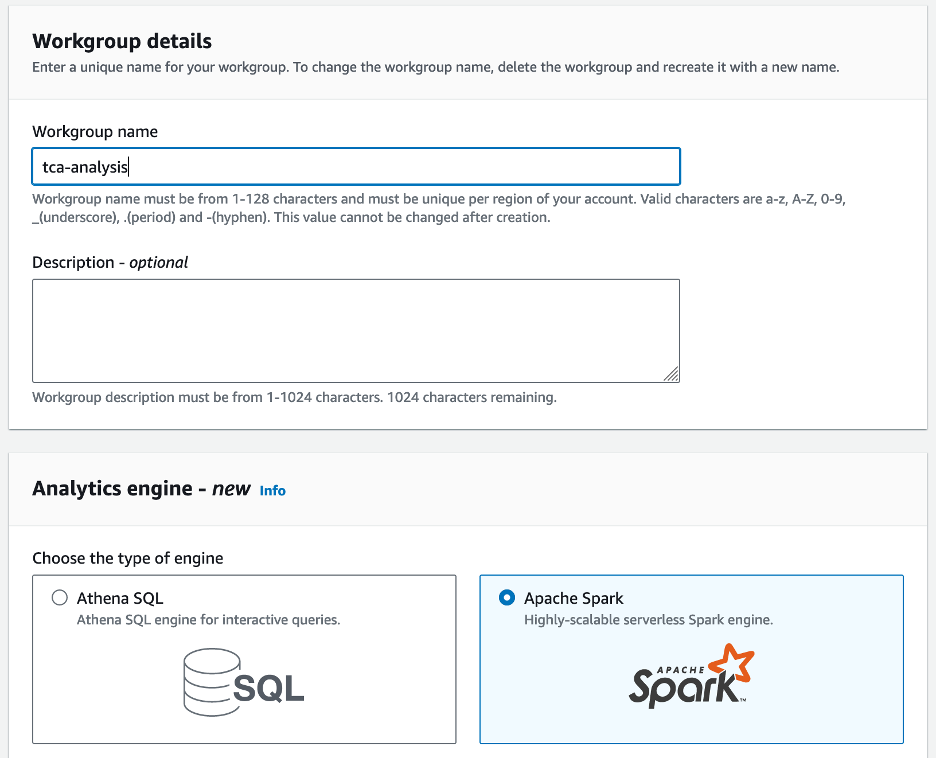
- Dans le Configurations supplémentaires section, vous pouvez choisir Utiliser les valeurs par défaut ou fournir une coutume Gestion des identités et des accès AWS (IAM) et emplacement Amazon S3 pour les résultats des calculs.
- Selectionnez Créer un groupe de travail.
- Après avoir créé le groupe de travail, accédez au Carnets onglet et choisissez Créer un cahier.
- Saisissez un nom pour votre bloc-notes, tel que
tca-analysis-with-tick-history. - Selectionnez Création pour créer votre carnet.
Lancez votre bloc-notes
Si vous avez déjà créé un groupe de travail Spark, sélectionnez Lancer l'éditeur de bloc-notes sous Commencez.
![]()
Une fois votre bloc-notes créé, vous serez redirigé vers l'éditeur de bloc-notes interactif.
![]()
Nous pouvons maintenant ajouter et exécuter le code suivant sur notre bloc-notes.
Créer une analyse
Effectuez les étapes suivantes pour créer une analyse :
- Importez des bibliothèques communes :
- Créez nos trames de données pour BBO, NBBO et les métiers :
- Nous pouvons désormais identifier une transaction à utiliser pour l'analyse des coûts de transaction :
Nous obtenons la sortie suivante :
Nous utilisons les informations commerciales mises en évidence pour le produit commercial (tp), le prix commercial (tpr) et la durée de la transaction (tt).
- Ici, nous créons un certain nombre de fonctions d'assistance pour notre analyse
- Dans la fonction suivante, nous créons l'ensemble de données qui contient toutes les cotations avant et après la transaction. Athena Spark détermine automatiquement le nombre de DPU à lancer pour traiter notre ensemble de données.
- Appelons maintenant la fonction d'analyse TCA avec les informations de notre métier sélectionné :
Visualisez les résultats de l'analyse
Créons maintenant les blocs de données que nous utilisons pour notre visualisation. Chaque trame de données contient des citations pour l'un des cinq intervalles de temps pour chaque flux de données (BBO, NBBO) :
Dans les sections suivantes, nous fournissons un exemple de code pour créer différentes visualisations.
Tracez QS et NBBO avant la transaction
Utilisez le code suivant pour tracer le spread coté et le NBBO avant la transaction :
![]()
Tracez le QS pour chaque marché et NBBO après la transaction
Utilisez le code suivant pour tracer le spread coté pour chaque marché et NBBO immédiatement après la transaction :
![]()
Tracez QS pour chaque intervalle de temps et chaque marché pour BBO
Utilisez le code suivant pour tracer le spread coté pour chaque intervalle de temps et chaque marché pour BBO :
![]()
Tracez ES pour chaque intervalle de temps et marché pour BBO
Utilisez le code suivant pour tracer le spread effectif pour chaque intervalle de temps et marché pour BBO :
Tracer l'EQF pour chaque intervalle de temps et marché pour BBO
Utilisez le code suivant pour tracer le spread effectif/coté pour chaque intervalle de temps et marché pour BBO :
Performances de calcul d'Athena Spark
Lorsque vous exécutez un bloc de code, Athena Spark détermine automatiquement le nombre de DPU nécessaires pour effectuer le calcul. Dans le dernier bloc de code, où nous appelons le tca_analysis fonction, nous demandons en fait à Spark de traiter les données, puis nous convertissons les trames de données Spark résultantes en trames de données Pandas. Cela constitue la partie de traitement la plus intensive de l'analyse, et lorsqu'Athena Spark exécute ce bloc, il affiche la barre de progression, le temps écoulé et le nombre de DPU qui traitent actuellement les données. Par exemple, dans le calcul suivant, Athena Spark utilise 18 DPU.
![]()
Lorsque vous configurez votre notebook Athena Spark, vous avez la possibilité de définir le nombre maximum de DPU qu'il peut utiliser. La valeur par défaut est de 20 DPU, mais nous avons testé ce calcul avec 10, 20 et 40 DPU pour démontrer comment Athena Spark évolue automatiquement pour exécuter notre analyse. Nous avons observé qu'Athena Spark évolue de manière linéaire, prenant 15 minutes et 21 secondes lorsque l'ordinateur portable était configuré avec un maximum de 10 DPU, 8 minutes et 23 secondes lorsque l'ordinateur portable était configuré avec 20 DPU et 4 minutes et 44 secondes lorsque l'ordinateur portable était configuré avec un maximum de 40 DPU. configuré avec XNUMX DPU. Étant donné qu'Athena Spark facture en fonction de l'utilisation du DPU, avec une granularité par seconde, le coût de ces calculs est similaire, mais si vous définissez une valeur DPU maximale plus élevée, Athena Spark peut renvoyer le résultat de l'analyse beaucoup plus rapidement. Pour plus de détails sur les tarifs d'Athena Spark, veuillez cliquer sur ici.
Conclusion
Dans cet article, nous avons montré comment utiliser les données OPRA haute fidélité de Tick History-PCAP de LSEG pour effectuer des analyses des coûts de transaction à l'aide d'Athena Spark. La disponibilité des données OPRA en temps opportun, complétée par les innovations en matière d'accessibilité d'AWS Data Exchange pour Amazon S3, réduit stratégiquement le temps d'analyse pour les entreprises cherchant à créer des informations exploitables pour les décisions commerciales critiques. OPRA génère environ 7 To de données Parquet normalisées chaque jour, et gérer l'infrastructure pour fournir des analyses basées sur les données OPRA est un défi.
L'évolutivité d'Athena dans la gestion du traitement des données à grande échelle pour l'historique des tiques – PCAP pour les données OPRA en fait un choix incontournable pour les organisations à la recherche de solutions d'analyse rapides et évolutives dans AWS. Cet article montre l'interaction transparente entre l'écosystème AWS et les données Tick History-PCAP et comment les institutions financières peuvent tirer parti de cette synergie pour piloter une prise de décision basée sur les données pour les stratégies de trading et d'investissement critiques.
À propos des auteurs
![]() Pramod Nayak est le directeur de la gestion des produits du groupe Low Latency chez LSEG. Pramod a plus de 10 ans d'expérience dans le secteur des technologies financières, en se concentrant sur le développement de logiciels, l'analyse et la gestion de données. Pramod est un ancien ingénieur logiciel passionné par les données de marché et le trading quantitatif.
Pramod Nayak est le directeur de la gestion des produits du groupe Low Latency chez LSEG. Pramod a plus de 10 ans d'expérience dans le secteur des technologies financières, en se concentrant sur le développement de logiciels, l'analyse et la gestion de données. Pramod est un ancien ingénieur logiciel passionné par les données de marché et le trading quantitatif.
![]() Lakshmi Kanth Mannem est chef de produit au sein du groupe Low Latency de LSEG. Il se concentre sur les produits de données et de plateforme pour le secteur des données de marché à faible latence. LakshmiKanth aide ses clients à créer les solutions les plus optimales pour leurs besoins en données de marché.
Lakshmi Kanth Mannem est chef de produit au sein du groupe Low Latency de LSEG. Il se concentre sur les produits de données et de plateforme pour le secteur des données de marché à faible latence. LakshmiKanth aide ses clients à créer les solutions les plus optimales pour leurs besoins en données de marché.
![]() Vivek Aggarwal est ingénieur de données senior au sein du groupe Low Latency du LSEG. Vivek travaille au développement et à la maintenance de pipelines de données pour le traitement et la fourniture de flux de données de marché capturés et de flux de données de référence.
Vivek Aggarwal est ingénieur de données senior au sein du groupe Low Latency du LSEG. Vivek travaille au développement et à la maintenance de pipelines de données pour le traitement et la fourniture de flux de données de marché capturés et de flux de données de référence.
![]() Alket Memushaj est architecte principal au sein de l'équipe de développement du marché des services financiers chez AWS. Alket est responsable de la stratégie technique et travaille avec des partenaires et des clients pour déployer même les charges de travail des marchés financiers les plus exigeantes sur le cloud AWS.
Alket Memushaj est architecte principal au sein de l'équipe de développement du marché des services financiers chez AWS. Alket est responsable de la stratégie technique et travaille avec des partenaires et des clients pour déployer même les charges de travail des marchés financiers les plus exigeantes sur le cloud AWS.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- Qui sommes-nous
- accès
- accédé
- accessibilité
- accessible
- à travers
- infection
- activité
- présenter
- actually
- ajouter
- En outre
- adresser
- Avantage
- Après
- à opposer à
- Aggarwal
- vise
- Tous
- Permettre
- déjà
- Amazon
- Amazone Athéna
- Amazon Web Services
- an
- analyses
- selon une analyse de l’Université de Princeton
- Analytique
- analytique
- il analyse
- l'analyse
- ainsi que le
- tous
- Apache
- Apache Spark
- Apis
- Application
- applications
- Appliquer
- une approche
- d'environ
- arbitrage
- arbitrage
- SONT
- autour
- AS
- demander
- Evaluer
- associé
- At
- attributs
- autorité
- automatiquement
- Automation
- disponibilité
- disponibles
- AWS
- sauvegarde
- barre
- basé
- BE
- car
- before
- repères
- LES MEILLEURS
- jusqu'à XNUMX fois
- offre
- Milliards
- Block
- courtiers
- construire
- mais
- by
- calculer
- calculé
- calcul
- Appelez-nous
- CAN
- Compétences
- capital
- Marchés de capitaux
- capturer
- capturé
- Capturer
- catalogue
- Centres
- difficile
- Voies
- caractérisé
- des charges
- le choix
- Selectionnez
- CLIENTS
- le cloud
- code
- Collecte
- Commun
- irrésistible
- complet
- Complété
- composants électriques
- complet
- comprend
- Conduire
- configurée
- Configurer
- Console
- la consolidation
- contient
- contrats
- contribuer
- convertir
- SOCIÉTÉ
- Prix
- Costs
- co-écrit
- engendrent
- créée
- création
- critique
- crucial
- Lecture
- Customiser
- Clients
- Tiret
- données
- les centres de données
- ingénieur de données
- D'échange de données
- gestion des données
- informatique
- stockage de données
- data-driven
- ensembles de données
- journée
- La prise de décision
- décisions
- Réglage par défaut
- Vous permet de définir
- page de livraison.
- exigeant
- demandes
- démontrer
- démontré
- déployer
- détails
- détermine
- développement
- Développement
- équipe de développement
- différence
- différent
- directement
- Directeur
- distribué
- distribution
- plusieurs
- double
- motivation
- Dynamic
- dynamiquement
- dynamique
- chacun
- facilité
- facilité d'utilisation
- risque numérique
- éditeur
- Efficace
- efficacité
- admissibles
- l'élimination
- employés
- employant
- permettre
- permet
- englobant
- efforts
- Moteur
- ingénieur
- Moteurs
- Ce renforcement
- Assure
- Entrer
- escalade
- Ether (ETH)
- évaluer
- évaluation
- Pourtant, la
- événement
- Chaque
- exemple
- échange
- Échanges
- exécution
- Découvrez
- explorez
- express
- S'étend
- plus rapide
- Doté d'
- Février
- figues
- Fichiers
- remplir
- une fonction filtre
- la traduction de documents financiers
- Institutions financières
- services financiers
- technologie financière
- entreprises
- Prénom
- première fois
- cinq
- Flexibilité
- se concentre
- mettant l'accent
- Abonnement
- Pour
- le format
- Ancien
- Avant
- quatre
- CADRE
- de
- fonction
- fonctions
- plus
- lacunes
- génère
- obtenez
- donné
- Global
- marché global
- Go
- aller
- gps
- Réservation de groupe
- Maniabilité
- Vous avez
- ayant
- he
- hauteur
- aide
- de haute qualité
- augmentation
- le plus élevé
- Surbrillance
- historique
- Histoire
- logement
- Comment
- How To
- http
- HTTPS
- IAM
- identifier
- Active
- if
- Immédiat
- immédiatement
- Impact
- importer
- in
- Y compris
- increased
- industrie
- d'information
- Infrastructure
- innovations
- idées.
- les établissements privés
- intégrale
- des services
- l'intégration
- l'interaction
- Interactif
- développement
- complexe
- un investissement
- implique
- IT
- jpg
- juste
- gros
- grande échelle
- Nom de famille
- Latence
- lancer
- moins
- bibliothèques
- Gamme
- Liquidité
- emplacement
- logique
- recherchez-
- Faible
- le plus bas
- le maintien
- majeur
- FAIT DU
- Fabrication
- gérer
- gestion
- manager
- Gestionnaires
- les gérer
- manière
- de nombreuses
- Marché
- Données du marché
- impact sur le marché
- Étude de marché
- Volatilité du marché
- tenue de marché
- Marchés
- massif
- mastering
- maximales
- Mai..
- mesurer
- message
- messages
- méticuleux
- méticuleusement
- Métrique
- million
- minimiser
- minutes
- Stack monitoring
- PLUS
- Par ailleurs
- (en fait, presque toutes)
- beaucoup
- plusieurs
- prénom
- Nature
- NAVIGUER
- Besoin
- Besoins
- Aucun
- cahier
- ordinateurs portables
- nombre
- nombreux
- numpy
- observée
- of
- code
- Offres Speciales
- on
- ONE
- optimaux
- Optimiser
- optimisé
- Option
- Options
- or
- organisations
- nos
- ande
- sortie
- plus de
- global
- propre
- pandas
- partie
- partenaires,
- passionné
- motifs
- Courant
- /
- effectuer
- performant
- pivot
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- joue
- veuillez cliquer
- parcelle
- portefeuille
- gestionnaires de portefeuille
- positionnée
- Post
- post-transaction
- défaillances
- La précision
- Préparer
- en train de préparer
- prix
- établissement des prix
- primaire
- Directeur
- processus
- les process
- traitement
- Processeur
- Produit
- gestion des produits
- chef de produit
- Produits
- Progrès
- fournir
- aportando
- publié
- Python
- Q3
- quantitatif
- Quantité
- question
- citations
- Tarif
- Tarifs
- Lire
- réal
- en temps réel
- recommandé
- Articles
- Rouge
- réduire
- réduit
- référence
- refinitiv
- Rapports
- Rapports
- dépôt
- exigence
- a besoin
- un article
- réponse
- responsables
- résultat
- résultant
- Résultats
- retourner
- risques
- Rôle
- Courir
- fonctionne
- SOLDE
- Évolutivité
- évolutive
- Balance
- mise à l'échelle
- fluide
- de façon transparente
- Deuxièmement
- secondes
- Section
- les sections
- titres
- sécurité
- recherche
- Sélectionner
- choisi
- supérieur
- séparé
- sert
- Services
- set
- mise
- montrer
- Spectacles
- de façon significative
- similaires
- étapes
- simplifié
- unique
- glissement
- Logiciels
- développement de logiciels
- Software Engineer
- Solutions
- sophistiqué
- enjambant
- Spark
- groupe de neurones
- propagation
- les pâtes à tartiner
- peuplements
- Étapes
- storage
- Boutique
- Stratégiquement
- les stratégies
- de Marketing
- rationalise
- Étude
- ultérieur
- tel
- SWIFT
- symbole
- synergie
- Prenez
- prise
- équipe
- Technique
- techniques
- Technologie
- examiné
- que
- qui
- Les
- les informations
- leur
- Les
- puis
- Ces
- this
- Avec
- tique
- fiable
- opportun
- horodatage
- Titre
- à
- Total
- tp
- TPR
- commerce
- Les commerçants
- métiers
- Commerce
- Stratégies de trading
- stratégie de négociation
- transaction
- coûts de transaction
- transformer
- transition
- Ultra
- sous
- subit
- améliorer
- us
- Utilisation
- utilisé
- d'utiliser
- Usages
- en utilisant
- Utilisant
- Plus-value
- divers
- visualisation
- visualiser
- Volatilité
- le volume
- volumes
- était
- we
- web
- services Web
- quand
- qui
- largement
- sera
- comprenant
- dans les
- sans
- Groupe De Travail
- de travail
- vos contrats
- partout dans le monde
- s'inquiéter
- X
- années
- you
- Votre
- zéphyrnet