Deux technologies algorithmiques logicielles récentes –– la conduite autonome (ADAS/AD) et l’IA générative (GenAI) –– maintiennent la communauté de l’ingénierie des semi-conducteurs éveillée la nuit.
Alors que les ADAS aux niveaux 2 et 3 sont sur la bonne voie, les AD aux niveaux 4 et 5 sont loin de la réalité, provoquant une baisse de l'enthousiasme et de l'argent du capital-risque. Aujourd’hui, GenAI retient l’attention et les sociétés de capital-risque investissent avec impatience des milliards de dollars.
Les deux technologies reposent sur des algorithmes modernes et complexes. Le traitement de leur formation et de leur inférence partage quelques attributs, certains critiques, d'autres importants mais non essentiels : voir tableau I.

Les progrès logiciels remarquables dans ces technologies n’ont jusqu’à présent pas été reproduits par les progrès du matériel algorithmique permettant d’accélérer leur exécution. Par exemple, les processeurs algorithmiques de pointe n'ont pas les performances nécessaires pour répondre aux requêtes ChatGPT-4 en une ou deux secondes au coût de 2 ¢ par requête, la référence établie par la recherche Google, ou pour traiter les données massives. collectées par les capteurs AD en moins de 20 millisecondes.
Jusqu’à ce que la start-up française VSORA investisse de l’intelligence pour résoudre le goulot d’étranglement de la mémoire connu sous le nom de mur de mémoire.
Le mur de la mémoire
Le mur de mémoire du processeur a été décrit pour la première fois par Wulf et McKee en 1994. Depuis, les accès à la mémoire sont devenus le goulot d'étranglement des performances informatiques. Les progrès en matière de performances des processeurs ne se sont pas reflétés dans les progrès de l'accès à la mémoire, ce qui oblige les processeurs à attendre de plus en plus longtemps les données fournies par les mémoires. En fin de compte, l’efficacité du processeur tombe bien en dessous de 100 % d’utilisation.
Pour résoudre le problème, l'industrie des semi-conducteurs a créé une structure de mémoire hiérarchique à plusieurs niveaux avec plusieurs niveaux de cache plus proches du processeur, ce qui réduit la quantité de trafic avec les mémoires principales et externes plus lentes.
Les performances des processeurs AD et GenAI dépendent plus que d’autres types d’appareils informatiques d’une large bande passante mémoire.
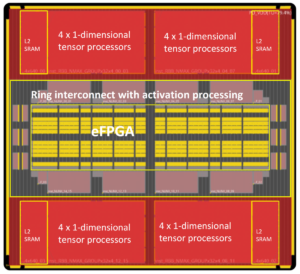
VSORA, fondée en 2015 pour cibler les applications 5G, a inventé une architecture brevetée qui réduit la structure hiérarchique de la mémoire en une large bande passante élevée et une mémoire étroitement couplée (TCM) accessible en un seul cycle d'horloge.
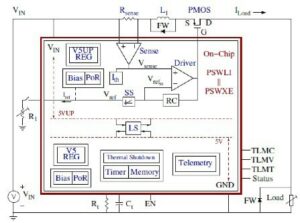
Du point de vue des cœurs de processeur, le TCM ressemble et agit comme une mer de registres en termes de Mo par rapport aux kilo-octets de registres physiques réels. La possibilité d'accéder à n'importe quelle cellule mémoire du TMC en un seul cycle permet d'obtenir une vitesse d'exécution élevée, une faible latence et une faible consommation d'énergie. Il nécessite également moins de surface en silicium. Le chargement de nouvelles données depuis la mémoire externe dans le TCM pendant le traitement des données actuelles n'affecte pas le débit du système. Fondamentalement, l'architecture permet une utilisation à plus de 80 % des unités de traitement grâce à sa conception. Il est néanmoins possible d'ajouter du cache et de la mémoire bloc-notes si le concepteur du système le souhaite. Voir la figure 1.
")
Grâce à une structure de mémoire de type registre implémentée dans pratiquement toutes les mémoires de toutes les applications, l'avantage de l'approche mémoire VSORA ne peut être surestimé. En règle générale, les processeurs GenAI de pointe offrent un pourcentage d’efficacité à un chiffre. Par exemple, un processeur GenAI avec un débit nominal d'un pétaflops de performances nominales mais une efficacité inférieure à 5 % offre des performances utilisables inférieures à 50 téraflops. Au lieu de cela, l’architecture VSORA atteint une efficacité plus de 10 fois supérieure.
Les accélérateurs algorithmiques de VSORA
VSORA a introduit deux classes d'accélérateurs algorithmiques : la famille Tyr pour les applications AD et la famille Jotunn pour l'accélération GenAI. Les deux offrent un débit exceptionnel, une latence minimale et une faible consommation d’énergie dans un faible encombrement en silicium.
Avec des performances nominales allant jusqu'à trois pétaflops, ils offrent une efficacité de mise en œuvre typique de 50 à 80 %, quel que soit le type d'algorithme, et une consommation électrique maximale de 30 watts/pétaflops. Ce sont des attributs stellaires, qui n’ont encore été signalés par aucun accélérateur d’IA concurrent.
Tyr et Jotunn sont entièrement programmables et intègrent des capacités IA et DSP, bien que dans des quantités différentes, et prennent en charge la sélection à la volée d'arithmétique de 8 bits à 64 bits, en nombres entiers ou en virgule flottante. Leur programmabilité s’adapte à un univers d’algorithmes, ce qui les rend indépendants des algorithmes. Plusieurs types différents de parcimonie sont également pris en charge.
Les attributs des processeurs VSORA les propulsent à l'avant-garde du paysage concurrentiel du traitement algorithmique.
Logiciel de support VSORA
VSORA a conçu une plate-forme de compilation/validation unique adaptée à son architecture matérielle pour garantir que ses appareils SoC complexes et hautes performances disposent d'un grand support logiciel.
Destiné à placer le concepteur algorithmique dans le cockpit, une gamme de niveaux hiérarchiques de vérification/validation –– ESL, hybride, RTL et gate –– fournissent un retour d'information par bouton-poussoir à l'ingénieur algorithmique en réponse aux explorations de l'espace de conception. Cela l'aide à sélectionner le meilleur compromis entre performances, latence, puissance et surface. Le code de programmation écrit à un niveau élevé d'abstraction peut être mappé en ciblant différents cœurs de traitement de manière transparente pour l'utilisateur.
L'interfaçage entre les cœurs peut être mis en œuvre au sein du même silicium, entre des puces sur le même PCB ou via une connexion IP. La synchronisation entre les cœurs est gérée automatiquement au moment de la compilation et ne nécessite pas d'opérations logicielles en temps réel.
Un obstacle à la conduite autonome L4/L5 et à l’inférence générative de l’IA à la périphérie
Une solution réussie doit également inclure la programmabilité sur le terrain. Les algorithmes évoluent rapidement, poussés par de nouvelles idées qui rendent obsolètes du jour au lendemain l'état de l'art d'hier. La possibilité de faire évoluer un algorithme sur le terrain constitue un avantage notable.
Alors que les entreprises hyperscale ont assemblé d’immenses fermes de calcul avec une multitude de processeurs les plus performants pour gérer des algorithmes logiciels avancés, l’approche n’est pratique que pour la formation, pas pour l’inférence en périphérie.
La formation est généralement basée sur une arithmétique à virgule flottante de 32 ou 64 bits qui génère de gros volumes de données. Il n'impose pas de latence stricte et tolère une consommation d'énergie élevée ainsi qu'un coût substantiel.
L'inférence à la périphérie est généralement effectuée sur une arithmétique à virgule flottante de 8 bits qui génère un peu moins de quantités de données, mais impose une latence sans compromis, une faible consommation d'énergie et un faible coût.
Impact de la consommation d'énergie sur la latence et l'efficacité
La consommation d'énergie des circuits intégrés CMOS est dominée par le mouvement des données et non par leur traitement.
Une étude de l'Université de Stanford dirigée par le professeur Mark Horowitz a montré que la consommation électrique de l'accès à la mémoire consomme des ordres de grandeur plus élevés que les calculs logiques numériques de base. Voir tableau II.

Les accélérateurs AD et GenAI sont d’excellents exemples d’appareils dominés par le mouvement des données, ce qui pose un défi pour contenir la consommation d’énergie.
Conclusion
L’inférence AD et GenAI pose des défis non triviaux pour parvenir à des implémentations réussies. VSORA peut fournir une solution matérielle complète et un logiciel de support pour répondre à toutes les exigences critiques pour gérer l'accélération AD L4/L5 et GenAI comme GPT-4 à des coûts commercialement viables.
Plus de détails sur VSORA et ses Tyr et Jotunn peuvent être trouvés sur www.vsora.com.
À propos de Lauro Rizzatti
Lauro Rizzatti est conseiller d'affaires auprès de VSORA, une startup innovante proposant des solutions IP sur silicium et des puces de silicium, ainsi qu'un consultant en vérification réputé et un expert du secteur en émulation matérielle. Auparavant, il a occupé des postes en gestion, marketing produit, marketing technique et ingénierie.
Lisez aussi:
Soitec façonne l'avenir de l'industrie des semi-conducteurs
ISO 21434 pour le développement de SoC soucieux de la cybersécurité
Maintenance prédictive dans le contexte de la sécurité fonctionnelle automobile
Partagez cet article via:
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://semiwiki.com/automotive/336201-long-standing-roadblock-to-viable-l4-l5-autonomous-driving-and-generative-ai-inference-at-the-edge/
- :possède
- :est
- :ne pas
- $UP
- 000
- 1
- 10
- 1800
- 1994
- 20
- 30
- 50
- 5G
- a
- capacité
- Qui sommes-nous
- abstraction
- accélérer
- accélération
- accélérateur
- accélérateurs
- accès
- accédé
- accès
- atteindre
- Atteint
- à travers
- actes
- présenter
- Ad
- ADA
- ajouter
- propos
- Avancée
- progrès
- Avantage
- conseiller
- affecter
- AI
- algorithme
- algorithmique
- algorithmes
- Tous
- permet
- aussi
- montant
- quantités
- an
- ainsi que les
- répondre
- tous
- applications
- une approche
- architecture
- SONT
- Réservé
- Art
- AS
- At
- précaution
- attributs
- automatiquement
- l'automobile
- autonome
- Bande passante
- basé
- Essentiel
- En gros
- BE
- devenez
- était
- ci-dessous
- référence
- LES MEILLEURS
- jusqu'à XNUMX fois
- milliards
- tous les deux
- la performance des entreprises
- mais
- by
- cachette
- CAN
- ne peut pas
- capacités
- capital
- causer
- cellule
- challenge
- globaux
- chips
- les classes
- horloge
- Poste de pilotage
- code
- s'effondre
- commercialement
- Communautés
- Sociétés
- compétitif
- complexe
- compliqué
- complet
- compromis
- calculs
- calcul
- informatique
- connexion
- consultant
- consommation
- contiennent
- contexte
- Prix
- Costs
- accouplé
- Processeur
- créée
- critique
- Courant
- En investissant dans une technologie de pointe, les restaurants peuvent non seulement rester compétitifs dans un marché en constante évolution, mais aussi améliorer significativement l'expérience de leurs clients.
- cycle
- données
- informatique
- livrer
- livré
- offre
- dense
- dépend
- décrit
- Conception
- un
- Création de Design
- détails
- Compatibles
- différent
- numérique
- chiffres
- do
- dollars
- entraîné
- conduite
- Goutte
- Drops
- vivement
- Edge
- efficace
- non plus
- fin
- énergie
- Consommation d'énergie
- ingénieur
- ENGINEERING
- assurer
- à leurs besoins.
- ESL
- essential
- établies
- JAMAIS
- évolue
- exemple
- exemples
- exécution
- expert
- externe
- famille
- loin
- Fermes
- Réactions
- few
- champ
- Figure
- Prénom
- flottant
- numérique
- Pour
- Premier plan
- trouvé
- Fondée
- Français
- de
- d’étiquettes électroniques entièrement
- fonctionnel
- avenir
- génère
- génératif
- IA générative
- Recherche Google
- plus grand
- manipuler
- Matériel
- Vous avez
- he
- Tenue
- aide
- ici
- Haute
- haute performance
- le plus élevé
- lui
- Horowitz
- http
- HTTPS
- majeur
- Hybride
- i
- ICS
- et idées cadeaux
- if
- ii
- la mise en oeuvre
- implémentations
- mis en œuvre
- important
- imposer
- in
- comprendre
- industrie
- Expert de l'industrie
- technologie innovante
- instance
- plutôt ;
- intégrer
- développement
- introduit
- A inventé
- Investir
- investi
- IP
- IT
- SES
- jpg
- sauts
- en gardant
- connu
- paysage d'été
- gros
- Latence
- LED
- moins
- Niveau
- niveaux
- comme
- chargement
- logique
- de longue date
- plus long
- LOOKS
- Faible
- Entrée
- facile
- Fabrication
- gérés
- gestion
- mandats
- marque
- Stratégie
- massif
- largeur maximale
- Découvrez
- Souvenirs
- Mémoire
- millisecondes
- minimal
- Villas Modernes
- de l'argent
- PLUS
- mouvement
- plusieurs
- foules
- Nouveauté
- nuit
- noté
- remarquable
- maintenant
- obsolète
- of
- offrant
- on
- ONE
- uniquement
- Opérations
- or
- de commander
- passer commande
- Autre
- Autres
- plus de
- du jour au lendemain
- exagéré
- contribution
- Courant
- /
- pourcentage
- performant
- effectué
- objectifs
- Physique
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Beaucoup
- Point
- positions
- possibilité
- Post
- power
- Méthode
- précédemment
- Prime
- Problème
- processus
- traité
- traitement
- Processeur
- processeurs
- Produit
- Professeur
- programmable
- Programmation
- Progrès
- Propulser
- mettre
- requêtes
- gamme
- rapidement
- Lire
- en temps réel
- Réalité
- récent
- réduit
- Indépendamment
- registres
- remarquables
- répliquées
- Signalé
- exigent
- Exigences
- a besoin
- réponse
- même
- MER
- Rechercher
- secondes
- sur le lien
- sélection
- semi-conducteur
- capteur
- plusieurs
- Partager
- Partages
- devrait
- montré
- Silicium
- depuis
- unique
- petit
- So
- Logiciels
- sur mesure
- Solutions
- RÉSOUDRE
- quelques
- quelque peu
- Identifier
- Space
- vitesse
- dépensé
- Stanford
- Stanford University
- Commencez
- Région
- state-of-the-art
- Stellaire
- Encore
- rationalisé
- strict
- structure
- Étude
- Ces
- réussi
- Support
- Appareils
- Appuyer
- synchronisation
- combustion propre
- table
- Target
- ciblage
- Technique
- Les technologies
- que
- qui
- Les
- El futuro
- leur
- Les
- Là.
- Ces
- l'ont
- this
- trois
- Avec
- débit
- fermement
- fiable
- fois
- à
- aujourd'hui
- suivre
- traditionnel
- circulation
- Formation
- de manière transparente
- deux
- type
- types
- débutante
- typiquement
- expérience unique et authentique
- unités
- Univers
- université
- jusqu'à
- améliorer
- utilisable
- Utilisateur
- en utilisant
- VCs
- entreprise
- capital-risque
- Vérification
- Versus
- via
- viable
- pratiquement
- volumes
- attendez
- Wall
- était
- Façon..
- WELL
- quand
- tout en
- large
- vœux
- comprenant
- dans les
- code écrit
- encore
- rendements
- zéphyrnet