Apache Hudi est un format de table ouvert qui apporte des fonctionnalités de base de données et d'entrepôt de données aux lacs de données. Apache Hudi aide les ingénieurs de données à gérer des défis complexes, tels que la gestion d'ensembles de données en constante évolution avec des transactions tout en maintenant les performances des requêtes. Les ingénieurs de données utilisent Apache Hudi pour diffuser les charges de travail ainsi que pour créer des pipelines de données incrémentiels efficaces. Hudi fournit les tables, transactions, insertions et suppressions efficaces, index avancés, services d'ingestion de flux, Les données regroupement ainsi que compactage optimisations, et Contrôle de la concurrence, tout en conservant vos données dans des formats de fichiers open source. Les optimisations avancées des performances de Hudi accélèrent les charges de travail analytiques avec tous les moteurs de requêtes populaires, notamment Apache Spark, Presto, Trino, Hive, etc.
De nombreux clients AWS ont adopté Apache Hudi sur leurs lacs de données construits sur Amazon S3 à l'aide Colle AWS, un service d'intégration de données sans serveur qui facilite la découverte, la préparation, le déplacement et l'intégration de données provenant de plusieurs sources à des fins d'analyse, d'apprentissage automatique (ML) et de développement d'applications. Robot d'exploration AWS Glue est un composant d'AWS Glue, qui vous permet de créer automatiquement des métadonnées de table à partir du contenu des données sans nécessiter de définition manuelle des métadonnées.
Les robots d'exploration AWS Glue prennent désormais en charge les tables Apache Hudi, simplifiant l'adoption de Catalogue de données AWS Glue comme le catalogue des tables Hudi. Un cas d'utilisation typique consiste à enregistrer des tables Hudi, qui n'ont pas de définition de table de catalogue. Un autre cas d'utilisation typique est la migration à partir d'autres catalogues Hudi, tels que le métastore Hive. Lors de la migration à partir d'autres catalogues Hudi, vous pouvez créer et planifier un robot d'exploration AWS Glue et fournir un ou plusieurs chemins Amazon S3 où se trouvent les fichiers de table Hudi. Vous avez la possibilité de fournir la profondeur maximale des chemins Amazon S3 que le robot d'exploration AWS Glue peut parcourir. À chaque exécution, les robots d'exploration AWS Glue extrairont les informations sur le schéma et la partition et mettront à jour le catalogue de données AWS Glue avec les modifications du schéma et de la partition. Les robots d'exploration AWS Glue mettent à jour le dernier emplacement du fichier de métadonnées dans le catalogue de données AWS Glue que les moteurs analytiques AWS peuvent utiliser directement.
Avec ce lancement, vous pouvez créer et planifier un robot d'exploration AWS Glue pour enregistrer des tables Hudi dans AWS Glue Data Catalog. Vous pouvez ensuite fournir un ou plusieurs chemins Amazon S3 où se trouvent les tables Hudi. Vous avez la possibilité de fournir la profondeur maximale des chemins Amazon S3 que les robots d'exploration peuvent parcourir. À chaque exécution du robot, le robot inspecte chacun des chemins S3 et catalogue les informations de schéma, telles que les nouvelles tables, les suppressions et les mises à jour des schémas dans le catalogue de données AWS Glue. Les robots d'exploration inspectent les informations sur les partitions et ajoutent les partitions nouvellement ajoutées à AWS Glue Data Catalog. Les robots d'exploration mettent également à jour le dernier emplacement du fichier de métadonnées dans le catalogue de données AWS Glue que les moteurs analytiques AWS peuvent utiliser directement.
Cet article montre comment fonctionne cette nouvelle fonctionnalité d'exploration des tables Hudi.
Comment le robot d'exploration AWS Glue fonctionne avec les tables Hudi
Les tableaux Hudi ont deux catégories, avec des implications spécifiques pour chacune :
- Copie en écriture (CoW) – Les données sont stockées sous forme de colonnes (Parquet), et chaque mise à jour crée une nouvelle version des fichiers lors d'une écriture.
- Fusionner en lecture (MoR) – Les données sont stockées en utilisant une combinaison de formats en colonnes (Parquet) et en lignes (Avro). Les mises à jour sont enregistrées par ligne
deltafichiers et sont compactés selon les besoins pour créer de nouvelles versions des fichiers en colonnes.
Avec les ensembles de données CoW, chaque fois qu'un enregistrement est mis à jour, le fichier qui contient l'enregistrement est réécrit avec les valeurs mises à jour. Avec un ensemble de données MoR, chaque fois qu'il y a une mise à jour, Hudi écrit uniquement la ligne de l'enregistrement modifié. MoR est mieux adapté aux charges de travail lourdes en écriture ou en modification avec moins de lectures. CoW est mieux adapté aux charges de travail lourdes en lecture sur des données qui changent moins fréquemment.
Hudi propose trois types de requêtes pour accéder aux données :
- Requêtes instantanées – Requêtes qui voient le dernier instantané de la table à partir d’une action de validation ou de compactage donnée. Pour les tables MoR, les requêtes d'instantané exposent l'état le plus récent de la table en fusionnant les fichiers de base et delta de la dernière tranche de fichier au moment de la requête.
- Requêtes incrémentielles – Les requêtes ne voient que les nouvelles données écrites dans la table, depuis une validation ou un compactage donné. Cela fournit efficacement des flux de modifications pour permettre des pipelines de données incrémentiels.
- Lire des requêtes optimisées – Pour les tables MoR, les requêtes voient les dernières données compactées. Pour les tables CoW, les requêtes voient les dernières données validées.
Pour les tables de copie sur écriture, les robots d'exploration créent une seule table dans le catalogue de données AWS Glue avec le Serde ReadOptimized. org.apache.hudi.hadoop.HoodieParquetInputFormat.
Pour les tables de fusion après lecture, les robots d'exploration créent deux tables dans AWS Glue Data Catalog pour le même emplacement de table :
- Un tableau avec suffixe
_ro, qui utilise le Serde ReadOptimizedorg.apache.hudi.hadoop.HoodieParquetInputFormat - Un tableau avec suffixe
_rt, qui utilise RealTime Serde permettant les requêtes Snapshot :org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Au cours de chaque analyse, pour chaque chemin Hudi fourni, les robots d'exploration effectuent un appel d'API de liste Amazon S3, filtrent en fonction du .hoodie dossiers et recherchez le fichier de métadonnées le plus récent dans ce dossier de métadonnées de la table Hudi.
Explorez une table Hudi CoW à l'aide du robot d'exploration AWS Glue
Dans cette section, voyons comment explorer un Hudi CoW à l'aide des robots d'exploration AWS Glue.
Pré-requis
Voici les prérequis pour ce tutoriel :
- Installer et configurer Interface de ligne de commande AWS (AWS CLI).
- Créez votre compartiment S3 si vous ne l'avez pas.
- Créez votre rôle IAM pour AWS Glue si vous ne l'avez pas. Vous avez besoin
s3:GetObjectens3://your_s3_bucket/data/sample_hudi_cow_table/. - Exécutez la commande suivante pour copier l'exemple de table Hudi dans votre compartiment S3. (Remplacer
your_s3_bucketavec le nom de votre compartiment S3.)
Cette instruction vous guide pour copier des exemples de données, mais vous pouvez facilement créer n'importe quelle table Hudi à l'aide d'AWS Glue. En savoir plus dans Présentation de la prise en charge native d'Apache Hudi, Delta Lake et Apache Iceberg sur AWS Glue pour Apache Spark, partie 2 : AWS Glue Studio Visual Editor.
Créer un robot Hudi
Dans cette instruction, créez le robot via la console. Suivez les étapes suivantes pour créer un robot Hudi :
- Sur la console AWS Glue, choisissez Rampeurs.
- Selectionnez Créer un robot.
- Pour Nom, Entrer
hudi_cow_crawler. Choisir Suivant. - Sous Configuration de la source de données, choisir Ajouter une source de données.
- Pour La source de données, choisissez Mauvais.
- Pour Inclure les chemins de la table Hudi, Entrer
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Remplaceryour_s3_bucketavec le nom de votre compartiment S3.) - Selectionnez Ajouter une source de données Hudi.
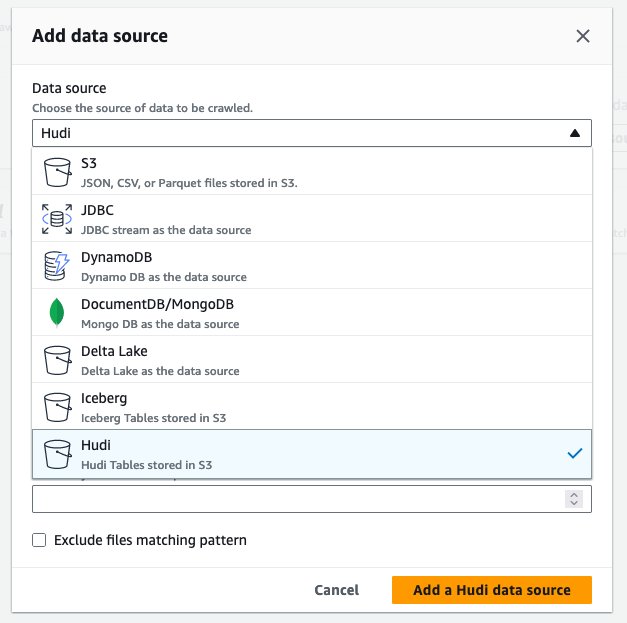
- Selectionnez Suivant.
- Pour Rôle IAM existant, choisissez votre rôle IAM, puis choisissez Suivant.
- Pour Base de données cible, choisissez Ajouter une base de données, puis le Ajouter une base de données boîte de dialogue apparaît. Pour Nom de la base de données, Entrer
hudi_crawler_blog, Puis choisissez Création. Choisir Suivant. - Selectionnez Créer un robot.
Maintenant, un nouveau robot Hudi a été créé avec succès. L'exécution du robot d'exploration peut être déclenchée via la console ou via le SDK ou l'AWS CLI à l'aide du StartCrawl API. Il pourrait également être programmé via la console pour déclencher les robots à des moments précis. Dans cette instruction, exécutez le robot via la console.
- Selectionnez Exécuter le robot.
- Attendez que le robot d'exploration se termine.
Une fois le robot exécuté, vous pouvez voir la définition de la table Hudi dans la console AWS Glue :
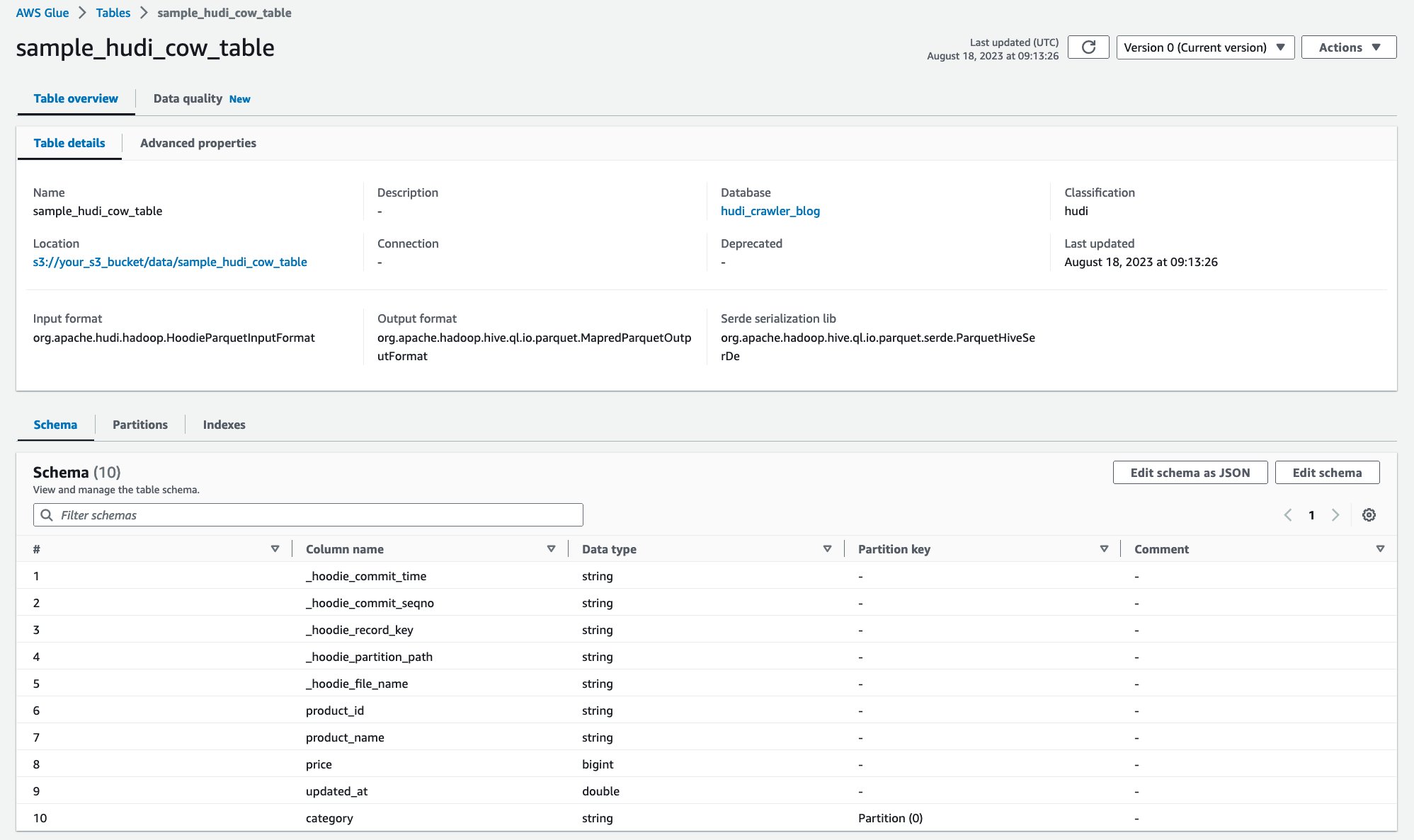
Vous avez réussi à analyser la table Hudi CoR avec des données sur Amazon S3 et à créer une table AWS Glue Data Catalog avec le schéma renseigné. Après avoir créé la définition de table sur AWS Glue Data Catalog, les services d'analyse AWS tels qu'Amazon Athena peuvent interroger la table Hudi.
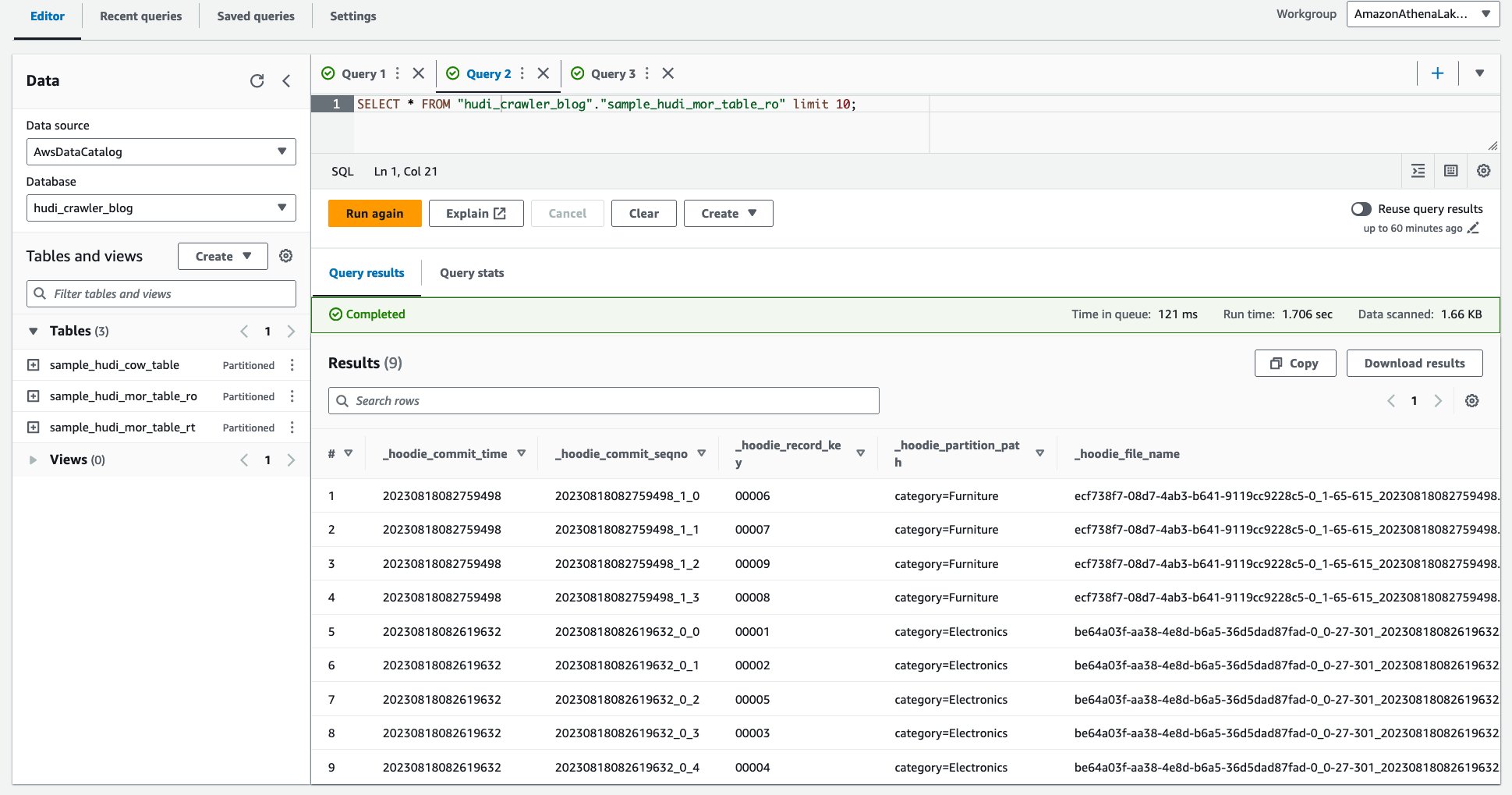
Suivez les étapes suivantes pour lancer des requêtes sur Athena :
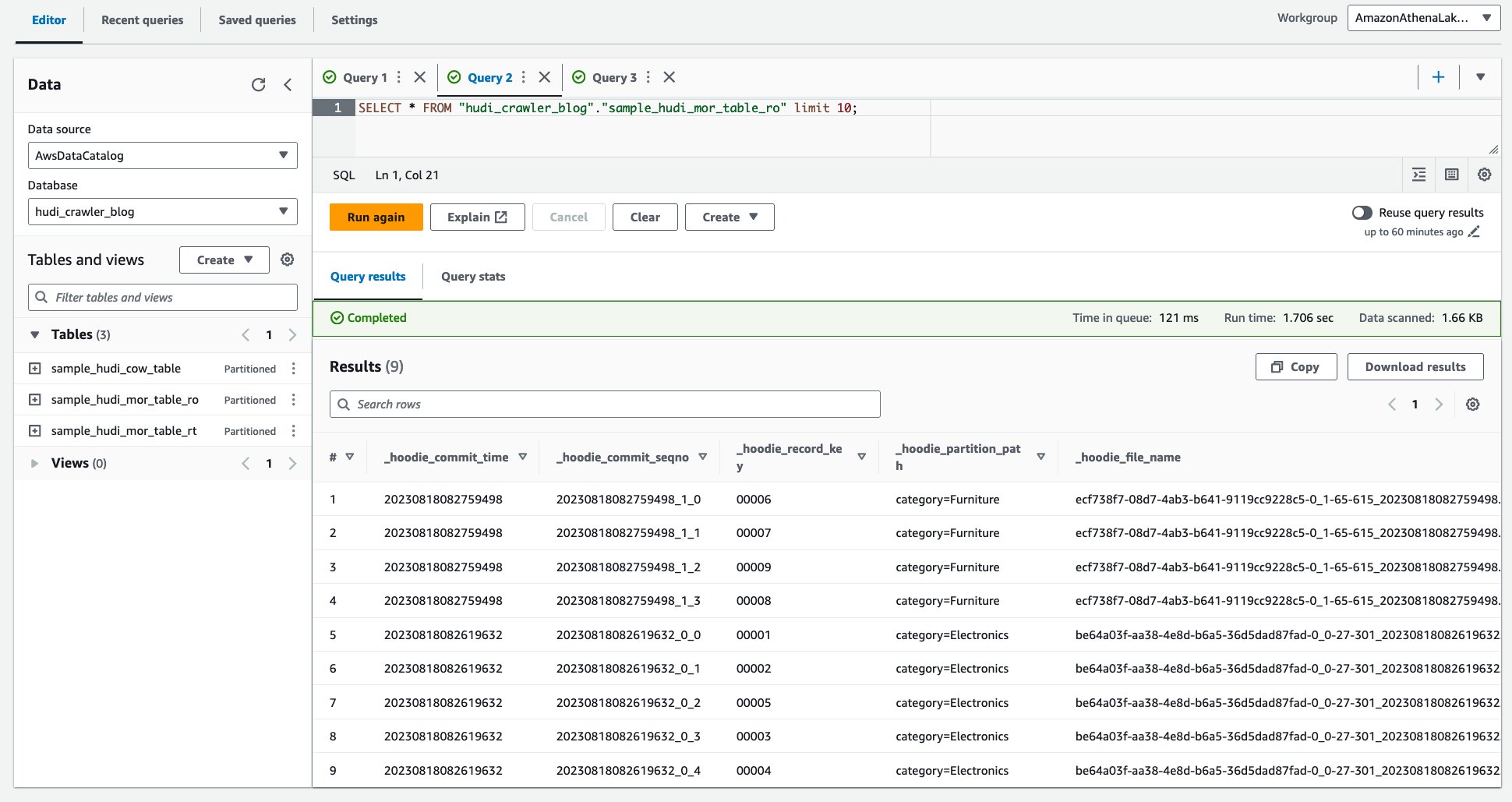
- Ouvrez la console Amazon Athena.
- Exécutez la requête suivante.
La capture d'écran suivante montre notre sortie :
Explorez une table Hudi MoR à l'aide du robot d'exploration AWS Glue avec les autorisations de données AWS Lake Formation
Dans cette section, voyons comment explorer une table Hudi MoR à l'aide d'AWS Glue. Cette fois, vous utilisez l'autorisation de données AWS Lake Formation pour analyser les sources de données Amazon S3 au lieu de l'autorisation IAM et Amazon S3. Ceci est facultatif, mais cela simplifie les configurations d'autorisations lorsque votre lac de données est géré par les autorisations AWS Lake Formation.
Pré-requis
Voici les prérequis pour ce tutoriel :
- Installer et configurer Interface de ligne de commande AWS (AWS CLI).
- Créez votre compartiment S3 si vous ne l'avez pas.
- Créez votre rôle IAM pour AWS Glue si vous ne l'avez pas. Vous avez besoin
lakeformation:GetDataAccess. Mais tu n'as pas besoins3:GetObjectens3://your_s3_bucket/data/sample_hudi_mor_table/parce que nous utilisons l'autorisation de données de Lake Formation pour accéder aux fichiers. - Exécutez la commande suivante pour copier l'exemple de table Hudi dans votre compartiment S3. (Remplacer
your_s3_bucketavec le nom de votre compartiment S3.)
En plus des étapes de traitement, effectuez les étapes suivantes pour mettre à jour les paramètres d'AWS Glue Data Catalog afin d'utiliser les autorisations de Lake Formation pour contrôler les ressources du catalogue au lieu du contrôle d'accès basé sur IAM :
- Connectez-vous à la console Lake Formation en tant qu'administrateur de lac de données.
- Si c'est la première fois que vous accédez à la console Lake Formation, ajoutez-vous en tant qu'administrateur du lac de données.
- Sous Administration, choisissez Paramètres du catalogue de données.
- Pour Autorisations par défaut pour les bases de données et les tables nouvellement créées, désélectionner Utiliser uniquement le contrôle d'accès IAM pour les nouvelles bases de données ainsi que Utiliser uniquement le contrôle d'accès IAM pour les nouvelles tables dans les nouvelles bases de données.
- Pour Paramètre de version multi-comptes, choisissez Version 3.
- Selectionnez Épargnez.
L'étape suivante consiste à enregistrer votre compartiment S3 dans les emplacements des lacs de données Lake Formation :
- Sur la console Lake Formation, choisissez Emplacements des lacs de donnéeset choisissez Enregistrer l'emplacement.
- Pour Chemin Amazon S3, Entrer
s3://your_s3_bucket/. (Remplaceryour_s3_bucketavec le nom de votre compartiment S3.) - Selectionnez Enregistrer l'emplacement.
Ensuite, accordez au rôle d'analyseur Glue l'accès à l'emplacement des données afin que l'analyseur puisse utiliser l'autorisation Lake Formation pour accéder aux données et créer des tables à l'emplacement :
- Sur la console Lake Formation, choisissez Emplacements des données et choisissez Subvention.
- Pour Utilisateurs et rôles IAM, sélectionnez le rôle IAM que vous avez utilisé pour le robot d'exploration.
- Pour Emplacement de stockage, Entrer
s3://your_s3_bucket/data/. (Remplaceryour_s3_bucketavec le nom de votre compartiment S3.) - Selectionnez Subvention.
Ensuite, accordez le rôle d'analyseur pour créer des tables sous la base de données hudi_crawler_blog:
- Sur la console Lake Formation, choisissez Autorisations du lac de données.
- Selectionnez Subvention.
- Pour Directeurs d'école, choisissez Utilisateurs et rôles IAM, puis choisissez le rôle du robot d'exploration.
- Pour Balises LF ou ressources de catalogue, choisissez Ressources de catalogue de données nommées.
- Pour Base de données, choisissez la base de données
hudi_crawler_blog. - Sous Autorisations de base de données, sélectionnez Créer une table.
- Selectionnez Subvention.
Créez un robot d'exploration Hudi avec les autorisations de données de Lake Formation
Suivez les étapes suivantes pour créer un robot Hudi :
- Sur la console AWS Glue, choisissez Rampeurs.
- Selectionnez Créer un robot.
- Pour Nom, Entrer
hudi_mor_crawler. Choisir Suivant. - Sous Configuration de la source de données, choisir Ajouter une source de données.
- Pour La source de données, choisissez Mauvais.
- Pour Inclure les chemins de la table Hudi, Entrer
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Remplaceryour_s3_bucketavec le nom de votre compartiment S3.) - Selectionnez Ajouter une source de données Hudi.
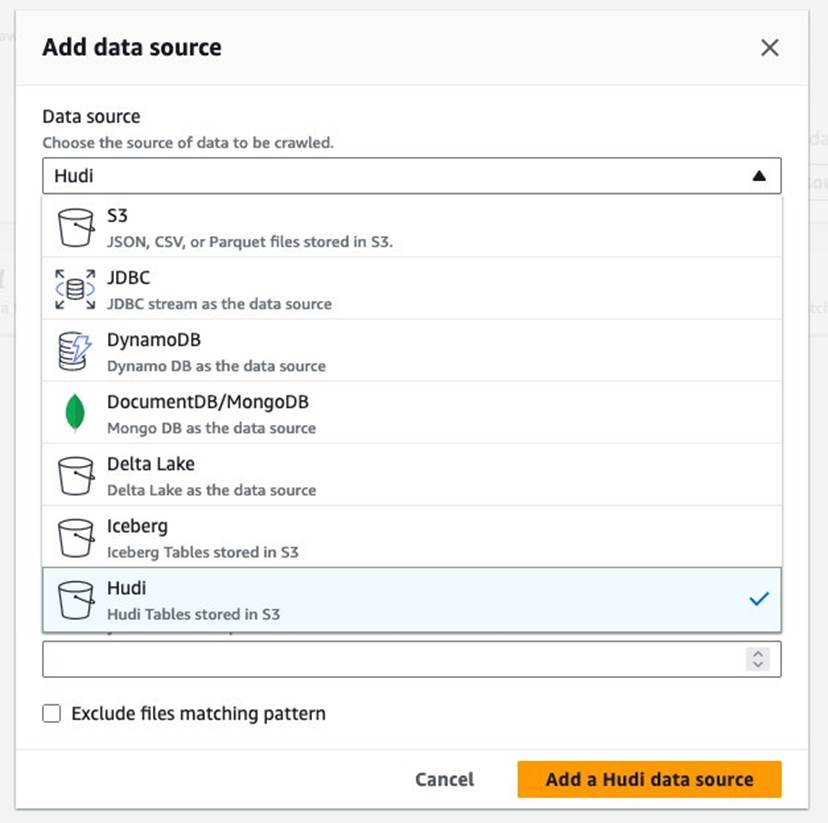
- Selectionnez Suivant.
- Pour Rôle IAM existant, choisissez votre rôle IAM.
- Sous Configuration de Lake Formation – en option, sélectionnez Utiliser les informations d'identification de Lake Formation pour explorer la source de données S3.
- Selectionnez Suivant.
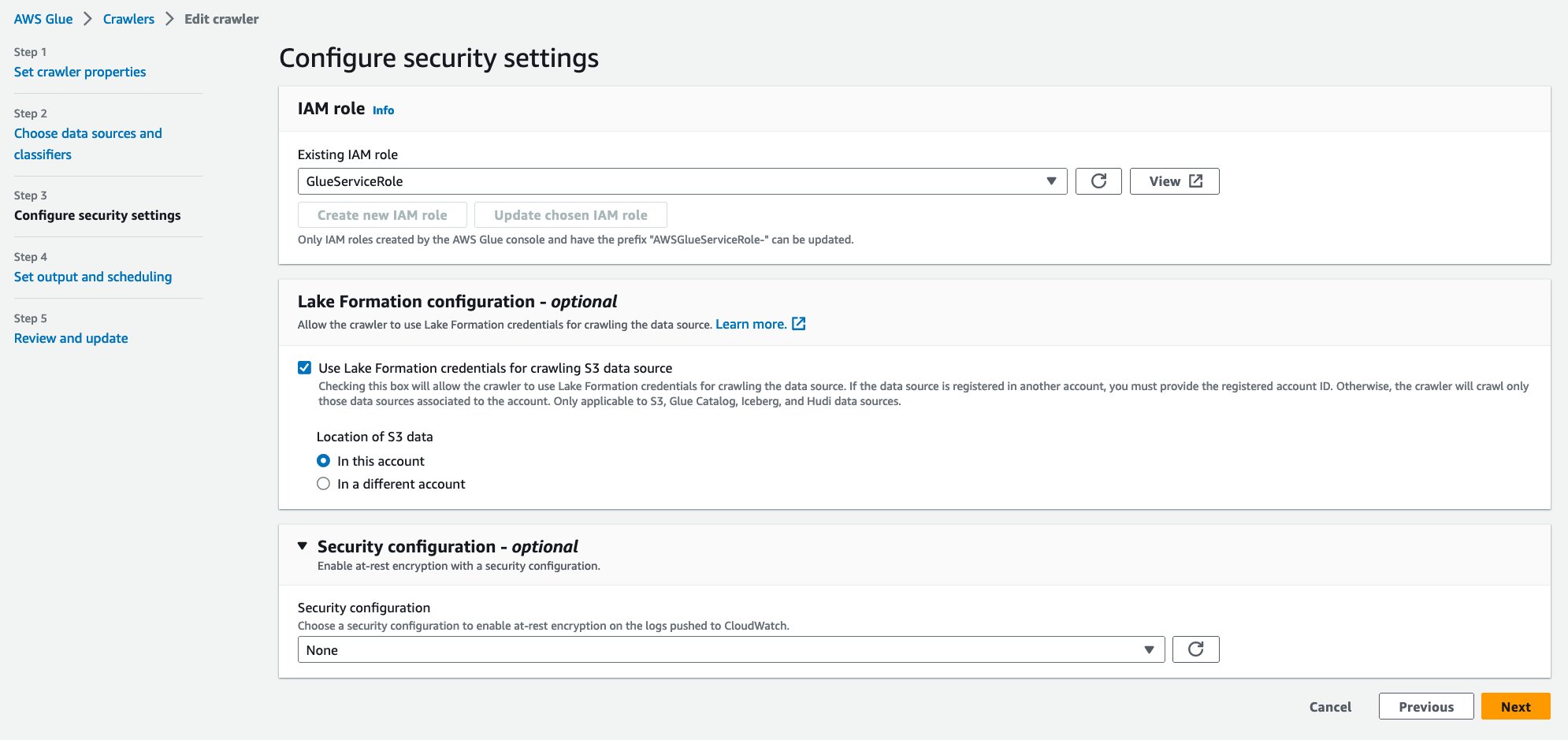
- Pour Base de données cible, choisissez
hudi_crawler_blog. Choisir Suivant. - Selectionnez Créer un robot.
Maintenant, un nouveau robot Hudi a été créé avec succès. Le robot d'exploration utilise les informations d'identification de Lake Formation pour analyser les fichiers Amazon S3. Lançons le nouveau robot :
- Selectionnez Exécuter le robot.
- Attendez que le robot d'exploration se termine.
Une fois l'analyseur exécuté, vous pouvez voir deux tables de la définition de table Hudi dans la console AWS Glue :
sample_hudi_mor_table_ro(lire le tableau optimisé)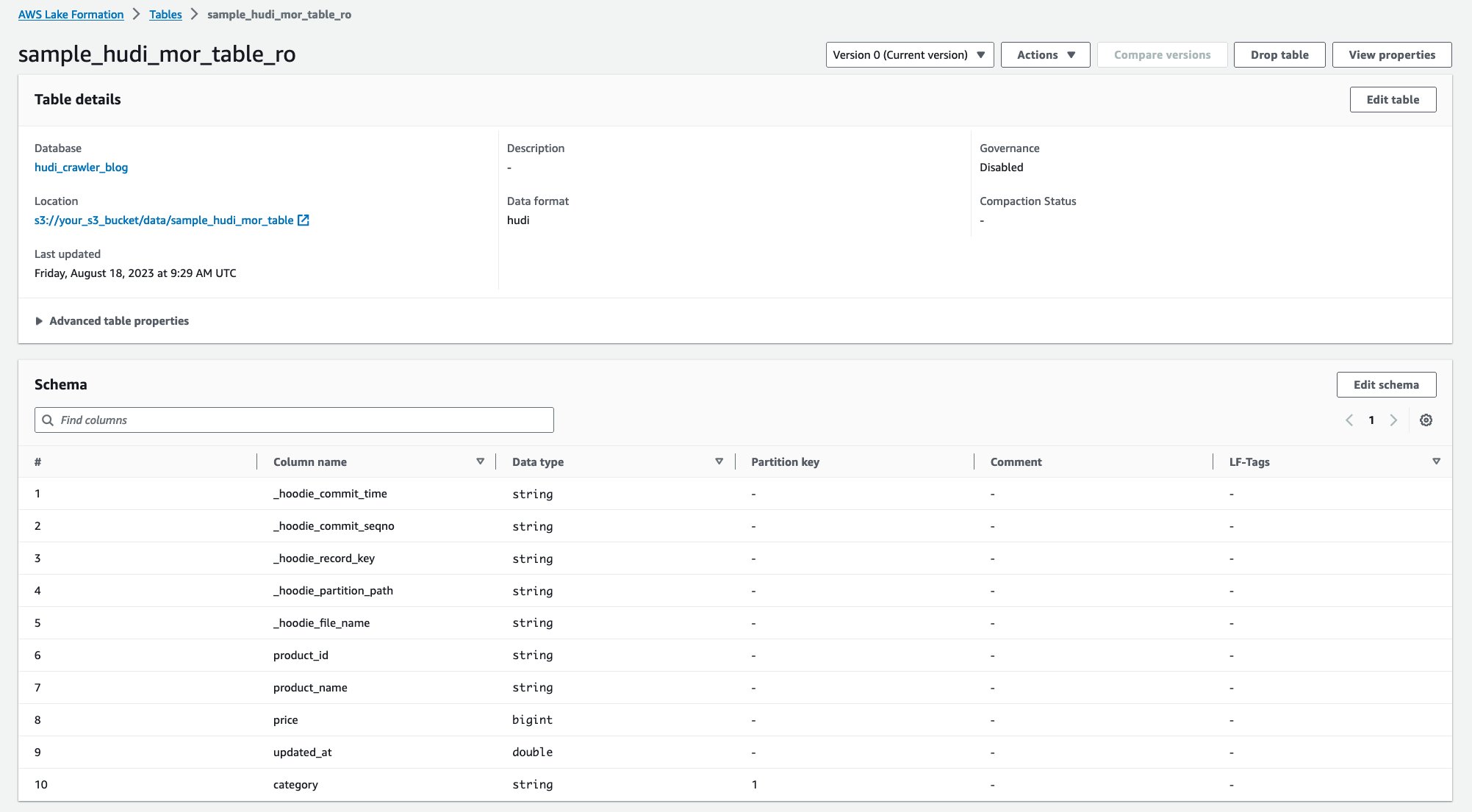
sample_hudi_mor_table_rt(tableau en temps réel)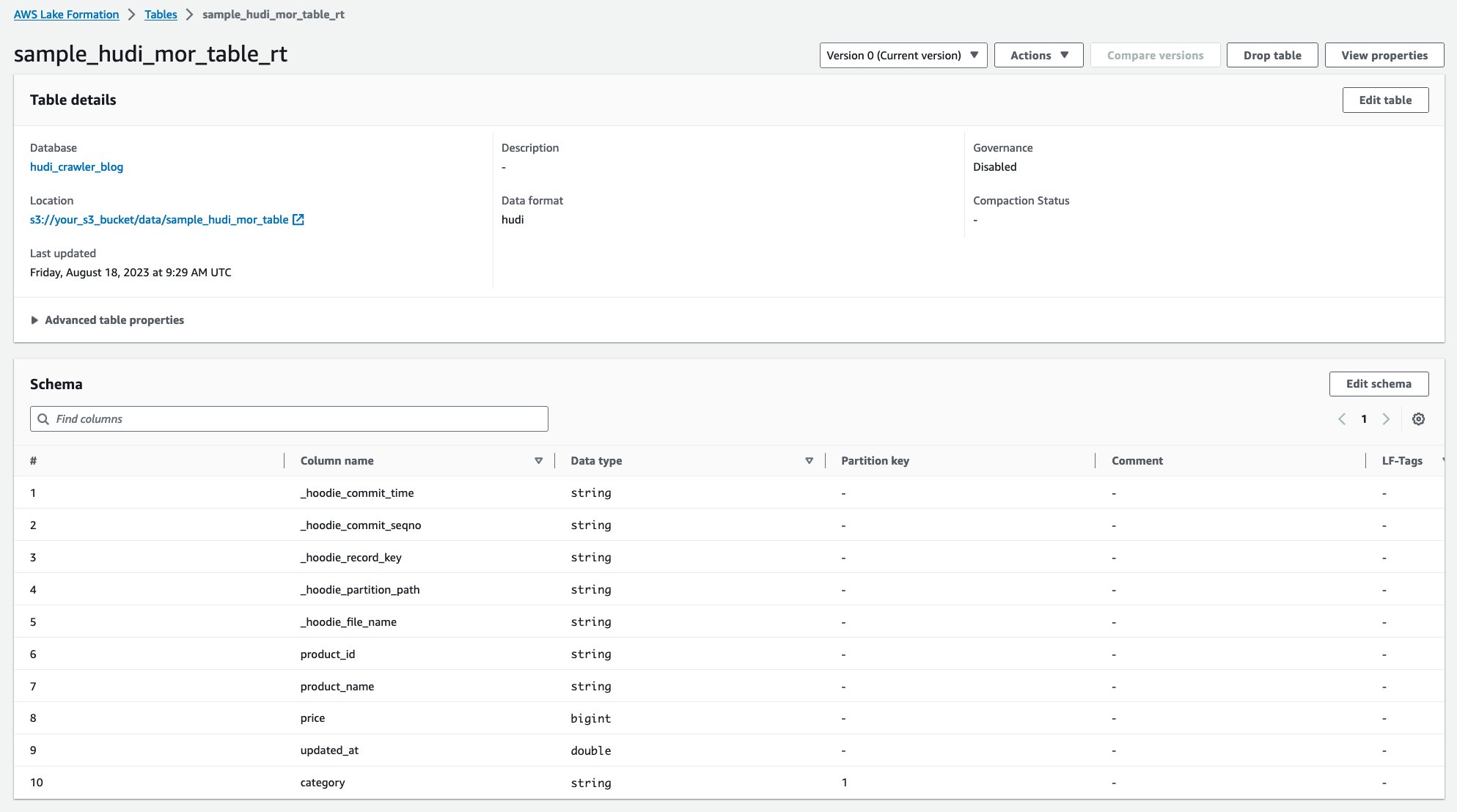
Vous avez enregistré le compartiment du lac de données auprès de Lake Formation et activé l'accès par exploration au lac de données à l'aide des autorisations de Lake Formation. Vous avez réussi à analyser la table Hudi MoR avec des données sur Amazon S3 et à créer une table AWS Glue Data Catalog avec le schéma renseigné. Après avoir créé les définitions de table sur AWS Glue Data Catalog, les services d'analyse AWS tels qu'Amazon Athena peuvent interroger la table Hudi.
Suivez les étapes suivantes pour lancer des requêtes sur Athena :
- Ouvrez la console Amazon Athena.
- Exécutez la requête suivante.
La capture d'écran suivante montre notre sortie :
- Exécutez la requête suivante.
La capture d'écran suivante montre notre sortie :
Contrôle d'accès précis à l'aide des autorisations AWS Lake Formation
Pour appliquer un contrôle d'accès précis sur la table Hudi, vous pouvez bénéficier des autorisations AWS Lake Formation. Les autorisations de Lake Formation vous permettent de restreindre l'accès à des tables, colonnes ou lignes spécifiques, puis d'interroger les tables Hudi via Amazon Athena avec un contrôle d'accès précis. Configurons l'autorisation Lake Formation pour la table Hudi MoR.
Pré-requis
Voici les prérequis pour ce tutoriel :
- Complétez la section précédente Explorez une table Hudi MoR à l'aide du robot d'exploration AWS Glue avec les autorisations de données AWS Lake Formation.
- Créez un utilisateur IAM DataAnalyst, qui dispose d'une stratégie gérée par AWS AmazonAthenaAccèsComplet.
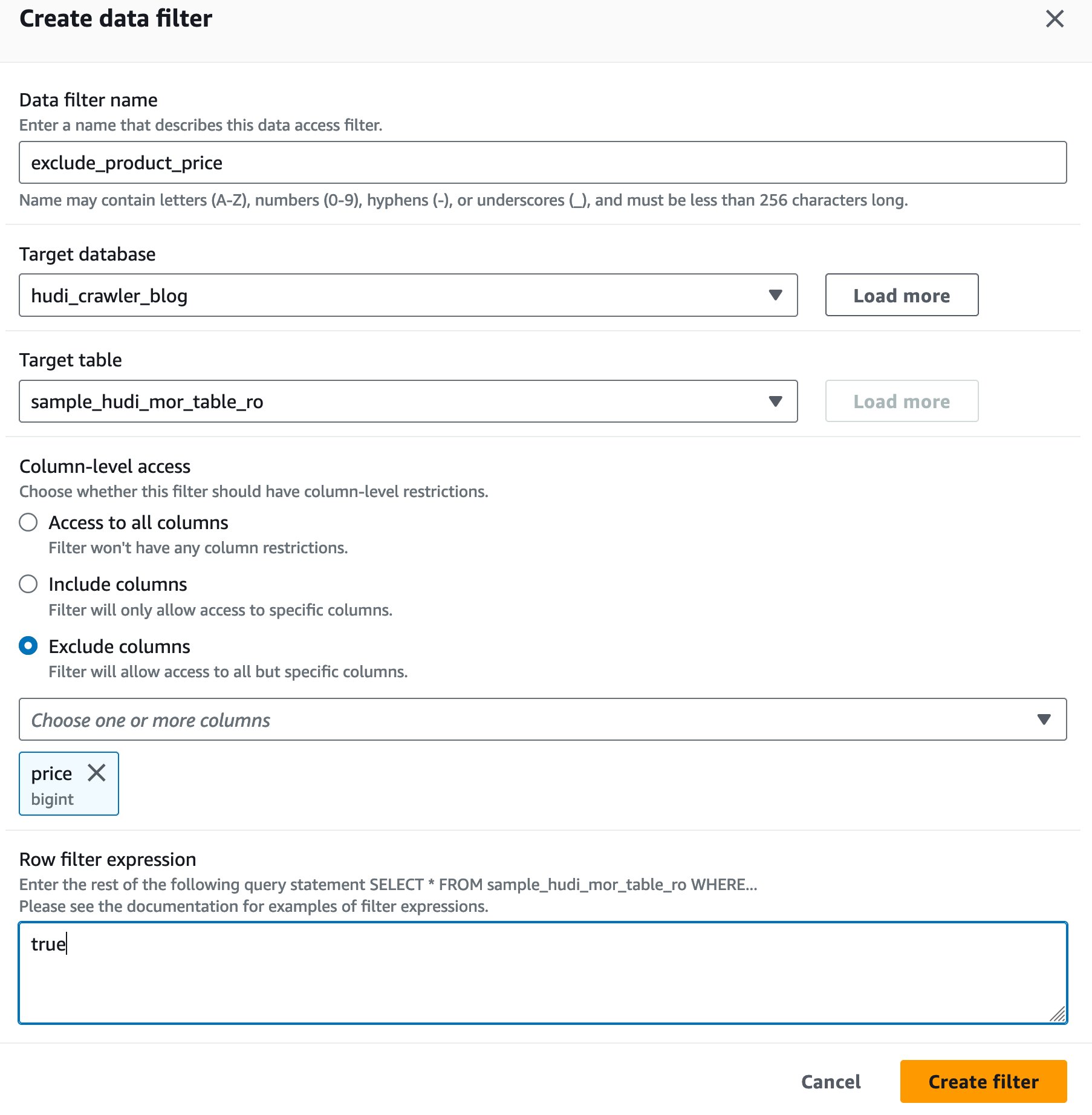
Créer un filtre de cellule de données Lake Formation
Commençons par configurer un filtre pour la table optimisée en lecture MoR.
- Connectez-vous à la console Lake Formation en tant qu'administrateur de lac de données.
- Selectionnez Filtres de données.
- Selectionnez Créer un nouveau filtre.
- Pour Nom du filtre de données, Entrer
exclude_product_price. - Pour Base de données cible, choisissez la base de données
hudi_crawler_blog. - Pour Tableau cible, choisissez le tableau
sample_hudi_mor_table_ro. - Pour Au niveau de la colonne accéder, sélectionner Exclure les colonnes, et choisissez le prix de la colonne.
- Pour Expression de filtre de ligne, Entrer
true. - Selectionnez Créer un filtre.
Accorder des autorisations Lake Formation à l'utilisateur DataAnalyst
Effectuez les étapes suivantes pour accorder l'autorisation de Lake Formation au DataAnalyst utilisateur
- Sur la console Lake Formation, choisissez Autorisations du lac de données.
- Selectionnez Subvention.
- Pour Directeurs d'école, choisissez Utilisateurs et rôles IAM, et choisissez l'utilisateur
DataAnalyst. - Pour Balises LF ou ressources de catalogue, choisissez Ressources de catalogue de données nommées.
- Pour Base de données, choisissez la base de données
hudi_crawler_blog. - Pour Tableau – facultatif, choisissez le tableau
sample_hudi_mor_table_ro. - Pour Filtres de données – facultatif, sélectionnez
exclude_product_price. - Pour Autorisations de filtre de données, sélectionnez Sélectionnez.
- Selectionnez Subvention.
Vous avez accordé l'autorisation à Lake Formation sur la base de données hudi_crawler_blog et le tableau sample_hudi_mor_table_ro, à l'exclusion de la colonne price à l’utilisateur DataAnalyst. Validons maintenant l'accès des utilisateurs aux données à l'aide d'Athena.
- Connectez-vous à la console Athena en tant qu'utilisateur DataAnalyst.
- Dans l'éditeur de requêtes, exécutez la requête suivante :
La capture d'écran suivante montre notre sortie :
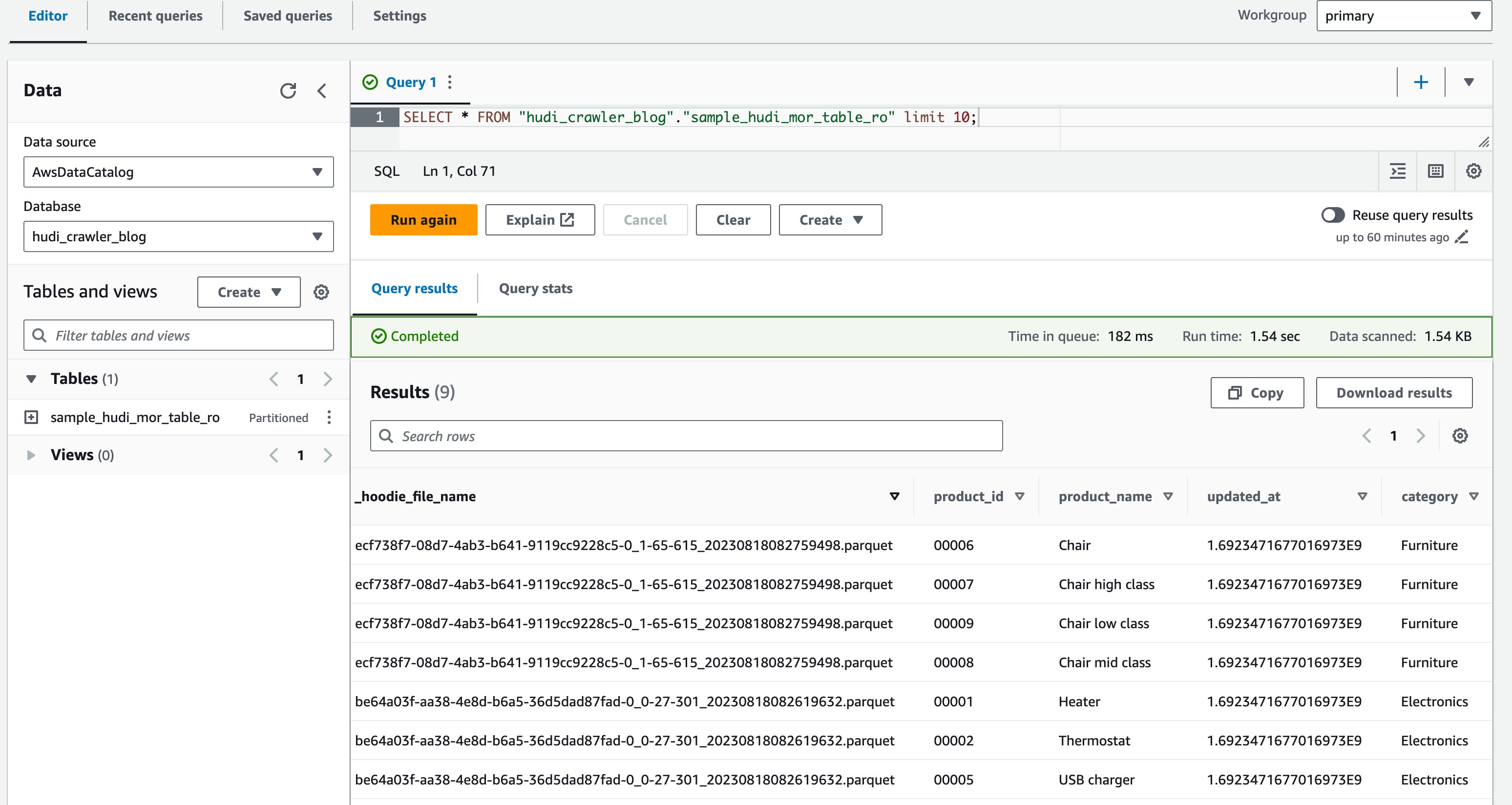
Vous avez maintenant validé que la colonne price n'est pas affiché, mais les autres colonnes product_id, product_name, update_atet une category sont indiqués.
Nettoyer
Pour éviter des frais indésirables sur votre compte AWS, supprimez les ressources AWS suivantes :
- Supprimer la base de données AWS Glue
hudi_crawler_blog. - Supprimer les robots d'exploration AWS Glue
hudi_cow_crawlerainsi quehudi_mor_crawler. - Supprimez les fichiers Amazon S3 sous
s3://your_s3_bucket/data/sample_hudi_cow_table/ainsi ques3://your_s3_bucket/data/sample_hudi_mor_table/.
Conclusion
Cet article a montré comment les robots d'exploration AWS Glue fonctionnent pour les tables Hudi. Grâce à la prise en charge du robot d'exploration Hudi, vous pouvez rapidement passer à l'utilisation d'AWS Glue Data Catalog comme catalogue de tables Hudi principal. Vous pouvez commencer à créer votre lac de données transactionnelles sans serveur à l'aide de Hudi sur AWS à l'aide d'AWS Glue, d'AWS Glue Data Catalog et des contrôles d'accès précis de Lake Formation pour les tables et les formats pris en charge par les moteurs d'analyse AWS.
À propos des auteurs
 Noritaka Sekiyama est architecte Big Data principal au sein de l'équipe AWS Glue. Il travaille à Tokyo, au Japon. Il est responsable de la création d'artefacts logiciels pour aider les clients. Dans ses temps libres, il aime faire du vélo avec son vélo de route.
Noritaka Sekiyama est architecte Big Data principal au sein de l'équipe AWS Glue. Il travaille à Tokyo, au Japon. Il est responsable de la création d'artefacts logiciels pour aider les clients. Dans ses temps libres, il aime faire du vélo avec son vélo de route.
 Kyle Duong est ingénieur en développement logiciel au sein de l'équipe AWS Glue et Lake Formation. Il est passionné par la création de technologies Big Data et de systèmes distribués.
Kyle Duong est ingénieur en développement logiciel au sein de l'équipe AWS Glue et Lake Formation. Il est passionné par la création de technologies Big Data et de systèmes distribués.
 Sandeep Adwankar est chef de produit technique senior chez AWS. Basé dans la région de la baie de Californie, il travaille avec des clients du monde entier pour traduire les exigences commerciales et techniques en produits qui permettent aux clients d'améliorer la façon dont ils gèrent, sécurisent et accèdent aux données.
Sandeep Adwankar est chef de produit technique senior chez AWS. Basé dans la région de la baie de Californie, il travaille avec des clients du monde entier pour traduire les exigences commerciales et techniques en produits qui permettent aux clients d'améliorer la façon dont ils gèrent, sécurisent et accèdent aux données.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :possède
- :est
- :ne pas
- :où
- $UP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- Capable
- A Propos
- accès
- Accès aux données
- accès
- Compte
- Action
- ajouter
- ajoutée
- ajout
- adopté
- Adoption
- Avancée
- Après
- Tous
- permettre
- Permettre
- permet
- aussi
- Amazon
- Amazone Athéna
- Amazon Web Services
- an
- Analytique
- analytique
- ainsi que
- Une autre
- tous
- Apache
- Apache Spark
- api
- apparaît
- Application
- Le développement d'applications
- Appliquer
- SONT
- Réservé
- autour
- AS
- At
- automatiquement
- éviter
- AWS
- Colle AWS
- Formation AWS Lake
- base
- basé
- baie
- BE
- car
- était
- profiter
- Améliorée
- Big
- Big Data
- Apportez le
- Développement
- construit
- la performance des entreprises
- mais
- by
- Californie
- Appelez-nous
- CAN
- capacités
- aptitude
- maisons
- catalogue
- catalogues
- catégories
- cellule
- globaux
- Change
- modifié
- Modifications
- des charges
- Selectionnez
- Colonne
- Colonnes
- combinaison
- commettre
- engagé
- complet
- complexe
- composant
- configuration
- Console
- contient
- contenu
- continuellement
- des bactéries
- contrôles
- pourriez
- chenilles
- engendrent
- créée
- crée des
- Lettres de créance
- Clients
- données
- intégration de données
- Lac de données
- entrepôt de données
- Base de données
- bases de données
- ensembles de données
- définition
- définitions
- Delta
- démontré
- démontre
- profondeur
- Développement
- directement
- découvrez
- distribué
- systèmes distribués
- do
- pendant
- chacun
- plus facilement
- même
- éditeur
- de manière efficace
- efficace
- permettre
- activé
- ingénieur
- Les ingénieurs
- Moteurs
- Entrer
- Ether (ETH)
- évolution
- à l'exclusion
- extrait
- plus rapide
- moins
- Déposez votre dernière attestation
- Fichiers
- une fonction filtre
- filtres
- Trouvez
- Prénom
- première fois
- Abonnement
- Pour
- le format
- formation
- fréquemment
- De
- donné
- globe
- Go
- subvention
- accordée
- Guides
- Hadoop
- Vous avez
- he
- vous aider
- aide
- sa
- Ruche
- Comment
- How To
- HTML
- HTTPS
- IAM
- if
- implications
- améliorer
- in
- Y compris
- incrémental
- d'information
- plutôt ;
- intégrer
- l'intégration
- Interfaces
- développement
- Découvrez le tout nouveau
- IT
- Japon
- jpg
- en gardant
- lac
- des lacs
- Nouveautés
- lancer
- APPRENTISSAGE
- apprentissage
- moins
- LIMIT
- Gamme
- Liste
- situé
- emplacement
- emplacements
- Connecté
- click
- machine learning
- le maintien
- a prendre une
- FAIT DU
- gérer
- gérés
- manager
- les gérer
- Manuel
- maximales
- fusion
- Métadonnées
- migrer
- migration
- ML
- PLUS
- (en fait, presque toutes)
- Bougez
- plusieurs
- prénom
- indigène
- Besoin
- nécessaire
- Nouveauté
- nouvellement
- next
- maintenant
- of
- on
- ONE
- uniquement
- ouvert
- open source
- optimisé
- Option
- or
- Autre
- nos
- sortie
- partie
- passionné
- chemin
- chemins
- performant
- autorisation
- autorisations
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Populaire
- peuplé
- Post
- Préparer
- conditions préalables
- précédent
- prix
- primaire
- Directeur
- traitement
- Produit
- chef de produit
- Produits
- fournir
- à condition de
- fournit
- requêtes
- vite.
- Lire
- réal
- en temps réel
- en temps réel
- récent
- record
- vous inscrire
- inscrit
- remplacer
- Exigences
- Resources
- responsables
- restreindre
- routières
- Rôle
- RANGÉE
- Courir
- même
- calendrier
- prévu
- Sdk
- Section
- sécurisé
- sur le lien
- Sélectionner
- supérieur
- Sans serveur
- service
- Services
- set
- Paramétres
- montré
- Spectacles
- simplifie
- depuis
- unique
- Tranche
- Instantané
- So
- Logiciels
- développement de logiciels
- Identifier
- Sources
- Spark
- groupe de neurones
- Commencer
- Région
- étapes
- Étapes
- stockée
- streaming
- flux
- studio
- Avec succès
- tel
- Support
- Appareils
- synchroniser.
- Système
- table
- équipe
- Technique
- Les technologies
- qui
- La
- leur
- puis
- Là.
- l'ont
- this
- trois
- Avec
- fiable
- fois
- à
- tokyo
- top
- transactionnel
- Transactions
- traduire
- traverser
- déclencher
- déclenché
- tutoriel
- deux
- types
- débutante
- sous
- indésirable
- Mises à jour
- a actualisé
- Actualités
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- utilisateurs
- Usages
- en utilisant
- VALIDER
- validé
- Valeurs
- version
- visuel
- Entrepots
- we
- web
- services Web
- WELL
- quand
- qui
- tout en
- WHO
- sera
- comprenant
- sans
- activités principales
- vos contrats
- écrire
- code écrit
- you
- Votre
- vous-même
- zéphyrnet