Service Amazon OpenSearch est un service géré qui simplifie la sécurisation, le déploiement et l'exploitation des clusters OpenSearch à grande échelle dans le cloud AWS. L'année dernière, nous avons présenté Contre-pression d'indexation des fragments et les controle d'admission, qui surveille les ressources du cluster et le trafic entrant pour rejeter de manière sélective les requêtes qui poseraient autrement des risques de stabilité, comme un manque de mémoire et affecteraient les performances du cluster en raison des conflits de mémoire, de la saturation du processeur et de la surcharge du GC, etc.
Nous sommes maintenant ravis de présenter Search Backpressure et le contrôle d'admission basé sur le processeur pour OpenSearch Service, ce qui améliore encore la résilience des clusters. Ces améliorations sont disponibles pour toutes les versions OpenSearch 1.3 ou supérieures.
Recherche contre-pression
La contre-pression empêche un système d'être submergé par le travail. Pour ce faire, il contrôle le taux de trafic ou en supprimant une charge excessive afin d'éviter les pannes et la perte de données, d'améliorer les performances et d'éviter une panne totale du système.
La contre-pression de recherche est un mécanisme permettant d'identifier et d'annuler les demandes de recherche gourmandes en ressources en cours lorsqu'un nœud est sous la contrainte. Il est efficace contre les charges de travail de recherche avec une utilisation anormalement élevée des ressources (telles que des requêtes complexes, des requêtes lentes, de nombreux accès ou des agrégations lourdes), qui pourraient autrement provoquer des pannes de nœud et affecter la santé du cluster.
Search Backpressure est construit au-dessus du cadre de suivi des ressources de tâche, qui fournit une API facile à utiliser pour surveiller l'utilisation des ressources de chaque tâche. Search Backpressure utilise un thread d'arrière-plan qui mesure périodiquement l'utilisation des ressources du nœud et attribue un score d'annulation à chaque tâche de recherche en cours en fonction de facteurs tels que le temps CPU, les allocations de tas et le temps écoulé. Un score d'annulation plus élevé correspond à une demande de recherche plus gourmande en ressources. Les demandes de recherche sont annulées dans l'ordre décroissant de leur score d'annulation pour récupérer rapidement les nœuds, mais le nombre d'annulations est limité pour éviter un travail inutile.
Le diagramme suivant illustre le workflow de recherche de contre-pression.
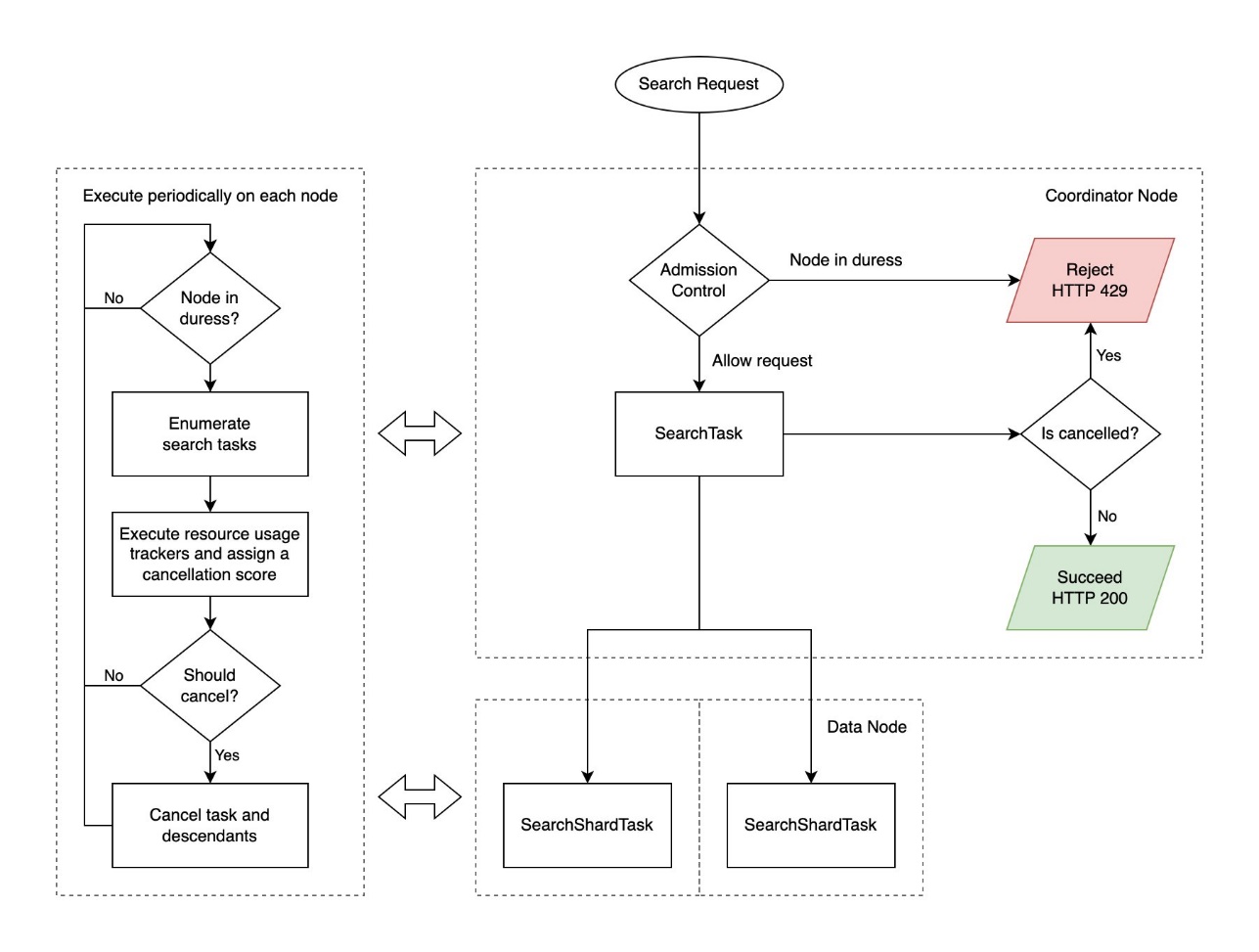
Les requêtes de recherche renvoient un code d'état HTTP 429 "Too Many Requests" lors de l'annulation. OpenSearch renvoie des résultats partiels si seules certaines partitions échouent et que des résultats partiels sont autorisés. Voir le code suivant :
Surveillance de la contre-pression de recherche
Vous pouvez surveiller l'état détaillé de Search Backpressure à l'aide de l'API node stats :
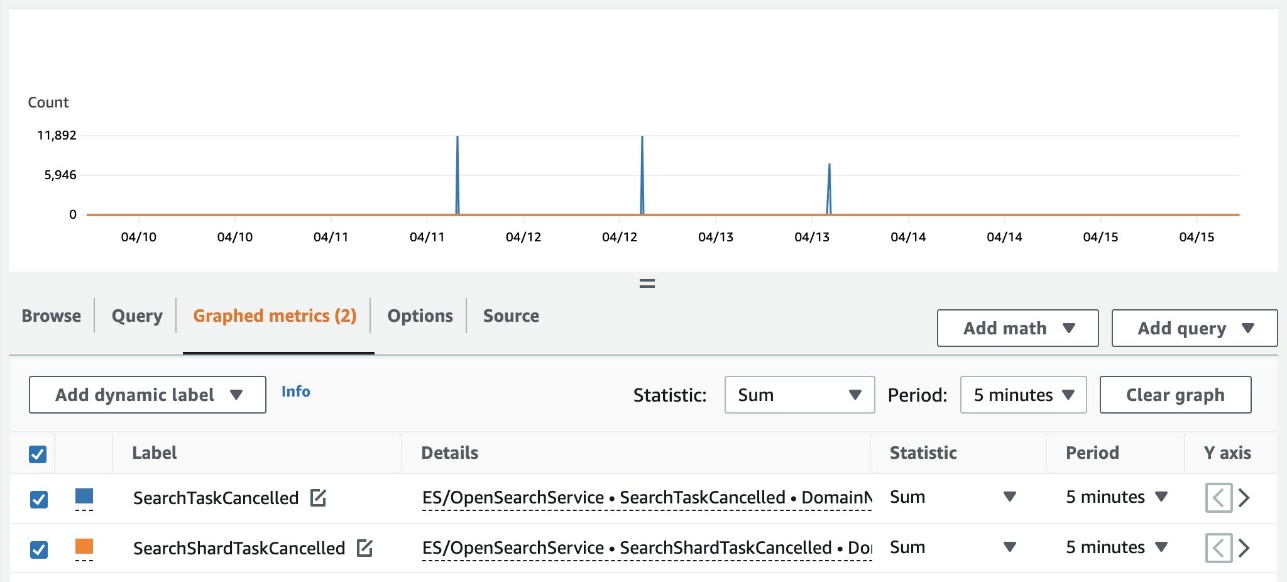
Vous pouvez également afficher le récapitulatif des annulations à l'échelle du cluster à l'aide de Amazon Cloud Watch. Les métriques suivantes sont désormais disponibles dans ES/OpenSearchService espace de noms :
- RechercherTâcheAnnulé – Le nombre d'annulations de nœud coordinateur
- RechercheShardTaskAnnulée – Le nombre d'annulations de nœuds de données
La capture d'écran suivante montre un exemple de suivi de ces métriques sur la console CloudWatch.
Contrôle d'admission basé sur le processeur
Le contrôle d'admission est un mécanisme de contrôle d'accès qui limite de manière proactive le nombre de demandes à un nœud en fonction de sa capacité actuelle, à la fois pour les augmentations organiques et les pics de trafic.
En plus de la pression de la mémoire JVM et des seuils de taille des requêtes, il surveille désormais également l'utilisation moyenne mobile du processeur de chaque nœud pour rejeter les appels entrants. _search et les _bulk demandes. Il empêche les nœuds d'être submergés par un trop grand nombre de requêtes entraînant des points chauds, des problèmes de performances, des délais d'expiration des requêtes et d'autres échecs en cascade. Les requêtes excessives renvoient un code d'état HTTP 429 "Too Many Requests" lors du rejet.
Gestion des erreurs HTTP 429
Vous recevrez des erreurs HTTP 429 si vous envoyez un trafic excessif à un nœud. Cela indique soit des ressources de cluster insuffisantes, soit des demandes de recherche gourmandes en ressources, soit un pic involontaire de la charge de travail.
La contre-pression de recherche fournit la raison du rejet, ce qui peut aider à affiner les demandes de recherche gourmandes en ressources. Pour les pics de trafic, nous recommandons de nouvelles tentatives côté client avec une temporisation et une gigue exponentielle.
Vous pouvez également suivre ces guides de dépannage pour déboguer les rejets excessifs :
Conclusion
La contre-pression de recherche est un mécanisme réactif pour éliminer une charge excessive, tandis que le contrôle d'admission est un mécanisme proactif pour limiter le nombre de requêtes à un nœud au-delà de sa capacité. Les deux fonctionnent en tandem pour améliorer la résilience globale d'un cluster OpenSearch.
La contre-pression est disponible dans Opensearch, et nous recherchons toujours apports extérieurs. Vous pouvez vous référer au RFC pour commencer.
À propos des auteurs
 Ketan Verma est un SDE senior travaillant sur Amazon OpenSearch Service. Il est passionné par la construction de systèmes distribués à grande échelle, l'amélioration des performances et la simplification d'idées complexes avec des abstractions simples. En dehors du travail, il aime lire et améliorer ses compétences de barista à domicile.
Ketan Verma est un SDE senior travaillant sur Amazon OpenSearch Service. Il est passionné par la construction de systèmes distribués à grande échelle, l'amélioration des performances et la simplification d'idées complexes avec des abstractions simples. En dehors du travail, il aime lire et améliorer ses compétences de barista à domicile.
 Suresh NS est un SDE senior travaillant sur Amazon OpenSearch Service. Il est passionné par la résolution de problèmes dans les systèmes distribués à grande échelle.
Suresh NS est un SDE senior travaillant sur Amazon OpenSearch Service. Il est passionné par la résolution de problèmes dans les systèmes distribués à grande échelle.
 Pritkumar Ladani est un SDE-2 fonctionnant sur Amazon OpenSearch Service. Il aime contribuer au développement de logiciels open source et est passionné par les systèmes distribués. Il est joueur de badminton amateur et aime faire de la randonnée.
Pritkumar Ladani est un SDE-2 fonctionnant sur Amazon OpenSearch Service. Il aime contribuer au développement de logiciels open source et est passionné par les systèmes distribués. Il est joueur de badminton amateur et aime faire de la randonnée.
 Boukhtawar Khan est un ingénieur principal travaillant sur Amazon OpenSearch Service. Il s'intéresse à la construction de systèmes distribués et autonomes. Il est mainteneur et contributeur actif à OpenSearch.
Boukhtawar Khan est un ingénieur principal travaillant sur Amazon OpenSearch Service. Il s'intéresse à la construction de systèmes distribués et autonomes. Il est mainteneur et contributeur actif à OpenSearch.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Financement EVM. Interface unifiée pour la finance décentralisée. Accéder ici.
- Groupe de médias quantiques. IR/PR amplifié. Accéder ici.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/improved-resiliency-with-backpressure-and-admission-control-for-amazon-opensearch-service/
- :est
- 1
- 1.3
- 100
- 26
- 7
- 77
- a
- A Propos
- infection
- ajout
- à opposer à
- Tous
- allocations
- aussi
- toujours
- amateur
- Amazon
- Amazon Web Services
- an
- et les
- api
- SONT
- AS
- At
- autonome
- systèmes autonomes
- disponibles
- moyen
- éviter
- AWS
- fond
- barista
- basé
- va
- Au-delà
- tous les deux
- Développement
- construit
- mais
- by
- CAN
- Compétences
- Causes
- le cloud
- Grappe
- code
- complexe
- Console
- contribuer
- contributeur
- des bactéries
- contrôle
- Coordinatrice
- correspond
- pourriez
- Processeur
- Courant
- données
- La perte de données
- déployer
- détaillé
- Développement
- distribué
- systèmes distribués
- deux
- chacun
- facile à utiliser
- Efficace
- non plus
- ingénieur
- Améliore
- erreur
- Erreurs
- Ether (ETH)
- exemple
- dépassé
- excité
- exponentiel
- facteurs
- FAIL
- Échec
- suivre
- Abonnement
- Pour
- Framework
- De
- plus
- gardiennage
- obtenez
- Guides
- he
- Santé
- lourd
- vous aider
- Haute
- augmentation
- sa
- Hits
- Accueil
- HOT
- http
- HTTPS
- et idées cadeaux
- identifier
- if
- illustre
- Impact
- améliorer
- amélioré
- améliorations
- l'amélioration de
- in
- Nouveau
- Augmente
- indice
- indique
- intéressé
- introduire
- introduit
- IT
- SES
- jpg
- gros
- grande échelle
- Nom
- L'année dernière
- conduisant
- comme
- LIMIT
- limites
- charge
- recherchez-
- perte
- FAIT DU
- gérés
- de nombreuses
- les mesures
- mécanisme
- Mémoire
- Métrique
- Surveiller
- moniteurs
- PLUS
- nœud
- nœuds
- maintenant
- nombre
- of
- on
- uniquement
- ouvert
- open source
- fonctionner
- or
- de commander
- biologique
- Autre
- autrement
- ande
- au contrôle
- global
- accablé
- passionné
- performant
- phase
- Platon
- Intelligence des données Platon
- PlatonDonnées
- joueur
- la parfaite pression
- empêcher
- empêche
- Directeur
- Cybersécurité
- d'ouvrabilité
- fournit
- requêtes
- vite.
- Tarif
- Lire
- raison
- recevoir
- recommander
- Récupérer
- nécessaire
- demandes
- ressource
- gourmande en ressources
- Resources
- Résultats
- retourner
- Retours
- risques
- Roulant
- Escaliers intérieurs
- But
- Rechercher
- sécurisé
- sur le lien
- envoyer
- supérieur
- service
- Services
- hangar
- Spectacles
- étapes
- simplifiant
- Taille
- compétences
- lent
- So
- Logiciels
- développement de logiciels
- Résoudre
- quelques
- Identifier
- épi
- pointes
- Stabilité
- j'ai commencé
- Région
- stats
- Statut
- tel
- RÉSUMÉ
- combustion propre
- Système
- tandem
- Tâche
- qui
- Le
- leur
- Ces
- fiable
- à
- trop
- top
- Total
- vers
- Tracking
- circulation
- oui
- type
- sous
- sur
- Utilisation
- Usages
- en utilisant
- Voir
- était
- we
- web
- services Web
- quand
- qui
- tout en
- comprenant
- activités principales
- workflow
- de travail
- pourra
- an
- you
- zéphyrnet