Redshift d'Amazon, un entrepôt de données cloud largement utilisé, a considérablement évolué pour répondre aux exigences de performances des charges de travail les plus exigeantes. Cet article couvre l'une de ces nouvelles fonctionnalités : la clé de tri de la présentation des données multidimensionnelles.
Amazon Redshift améliore désormais les performances de vos requêtes en prenant en charge les clés de tri de présentation de données multidimensionnelles, qui sont un nouveau type de clé de tri qui trie les données d'une table par prédicats de filtre plutôt que par colonnes physiques de la table. Les clés de tri de présentation de données multidimensionnelles amélioreront considérablement les performances des analyses de tables, en particulier lorsque votre charge de travail de requête contient des filtres d'analyse répétitives.
Amazon Redshift offre déjà la capacité de optimisation automatique des tables (ATO), qui optimise automatiquement la conception des tables en appliquant des clés de tri et de distribution sans nécessiter l'intervention de l'administrateur. Dans cet article, nous présentons les clés de tri de présentation de données multidimensionnelles en tant que fonctionnalité supplémentaire offerte par ATO et renforcée par l'algorithme de conseiller de clé de tri d'Amazon Redshift.
Clés de tri de présentation de données multidimensionnelles
Lorsque vous définissez une table avec la clé de tri AUTO, Amazon Redshift ATO analyse l'historique de vos requêtes et sélectionne automatiquement soit une clé de tri à une seule colonne, soit une clé de tri de présentation de données multidimensionnelle pour votre table, en fonction de l'option la mieux adaptée à votre charge de travail. Lorsque la disposition des données multidimensionnelles est sélectionnée, Amazon Redshift construira une fonction de tri multidimensionnel qui colocalise les lignes généralement accessibles par les mêmes requêtes, et la fonction de tri est ensuite utilisée lors des exécutions de requêtes pour ignorer les blocs de données et même ignorer l'analyse du prédicat individuel. Colonnes.
Considérez la requête utilisateur suivante, qui constitue un modèle de requête dominant dans la charge de travail de l'utilisateur :
Amazon Redshift stocke les données de chaque colonne dans des blocs de disque de 1 Mo et stocke les valeurs minimales et maximales dans chaque bloc dans le cadre des métadonnées de la table. Si une requête utilise un prédicat à plage restreinte, Amazon Redshift peut utiliser les valeurs minimales et maximales pour ignorer rapidement un grand nombre de blocs lors des analyses de table. Cependant, le filtre de cette requête sur la colonne de sous-région ne peut pas être utilisé pour déterminer les blocs à ignorer en fonction des valeurs minimales et maximales. Par conséquent, Amazon Redshift analyse toutes les lignes de la table des titres :
Lorsque la requête de l'utilisateur a été exécutée avec titles en utilisant une clé de tri à une seule colonne sur subregion, le résultat de la requête précédente est le suivant :
Cela montre que l'analyse de la table a lu 2,164,081,640 XNUMX XNUMX XNUMX lignes.
Pour améliorer les analyses sur le titles table, Amazon Redshift peut décider automatiquement d'utiliser une clé de tri de présentation de données multidimensionnelle. Toutes les lignes qui satisfont à la lower(subregion) like '%United States%' Le prédicat serait colocalisé dans une région dédiée de la table et, par conséquent, Amazon Redshift analysera uniquement les blocs de données qui satisfont au prédicat.
Lorsque la requête de l'utilisateur est exécutée avec titles à l'aide d'une clé de tri de présentation de données multidimensionnelle qui comprend lower(subregion) like '%United States%' comme prédicat, le résultat du sys_query_detail la requête est la suivante :
Cela montre que l'analyse de la table a lu 152,324,046 7 XNUMX lignes, soit seulement XNUMX % de l'original, et qu'elle a utilisé la clé de tri de la disposition des données multidimensionnelles.
Notez que cet exemple utilise une seule requête pour présenter la fonctionnalité de présentation des données multidimensionnelles, mais Amazon Redshift prendra en compte toutes les requêtes exécutées sur la table et pourra créer plusieurs régions pour satisfaire les prédicats les plus couramment exécutés.
Prenons un autre exemple, avec cette fois des prédicats plus complexes et plusieurs requêtes.
Imaginez avoir une table items (cost int, available int, demand int) avec quatre lignes, comme indiqué dans l'exemple suivant.
| #identifiant | sables moins coûteux | disponibles | demande |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Votre charge de travail dominante se compose de deux requêtes :
- Modèle de requêtes à 70 % :
- Modèle de requêtes à 20 % :
Avec les techniques de tri traditionnelles, vous pouvez choisir de trier le tableau sur la colonne des coûts, de sorte que l'évaluation des cost > 3 bénéficiera du tri. Ainsi, le tableau des éléments après tri à l'aide d'un seul cost La colonne ressemblera à ce qui suit.
| #identifiant | sables moins coûteux | disponibles | demande |
| Région n°1, avec un coût <= 3 | |||
| Région n°2, avec un coût > 3 | |||
| #identifiant | sables moins coûteux | disponibles | demande |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
En utilisant ce tri traditionnel, nous pouvons immédiatement exclure les deux premières lignes (bleues) avec l'ID 4 et l'ID 2, car elles ne satisfont pas cost > 3.
D'un autre côté, avec une clé de tri de présentation de données multidimensionnelle, le tableau sera trié en fonction d'une combinaison des deux prédicats courants dans la charge de travail de l'utilisateur, qui sont cost > 3 ainsi que available < demand. Par conséquent, les lignes du tableau sont triées en quatre régions.
| #identifiant | sables moins coûteux | disponibles | demande |
| Région n°1, avec un coût <= 3 et disponible < demande | |||
| Région n°2, avec un coût <= 3 et une disponibilité >= demande | |||
| Région n°3, avec un coût > 3 et disponible < demande | |||
| Région n°4, avec un coût > 3 et une disponibilité >= demande | |||
| #identifiant | sables moins coûteux | disponibles | demande |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Ce concept est encore plus puissant lorsqu'il est appliqué à des blocs entiers plutôt qu'à des lignes simples, lorsqu'il est appliqué à des prédicats complexes qui utilisent des opérateurs non adaptés aux techniques de tri traditionnelles (telles que like), et lorsqu'il est appliqué à plus de deux prédicats.
Tableaux système
Les tables système Amazon Redshift suivantes indiqueront aux utilisateurs si des présentations de données multidimensionnelles sont utilisées sur leurs tables et requêtes :
- Pour déterminer si une table particulière utilise une clé de tri de présentation de données multidimensionnelle, vous pouvez vérifier si
sortkey1in svv_table_info est égal àAUTO(SORTKEY(padb_internal_mddl_key_col)). - Pour déterminer si une requête particulière utilise une présentation de données multidimensionnelle pour accélérer les analyses de table, vous pouvez vérifier
step_attributedans le sys_query_detail voir. La valeur sera égale àmulti-dimensionalsi la clé de tri de présentation des données multidimensionnelles de la table a été utilisée lors de l'analyse.
Références de performance
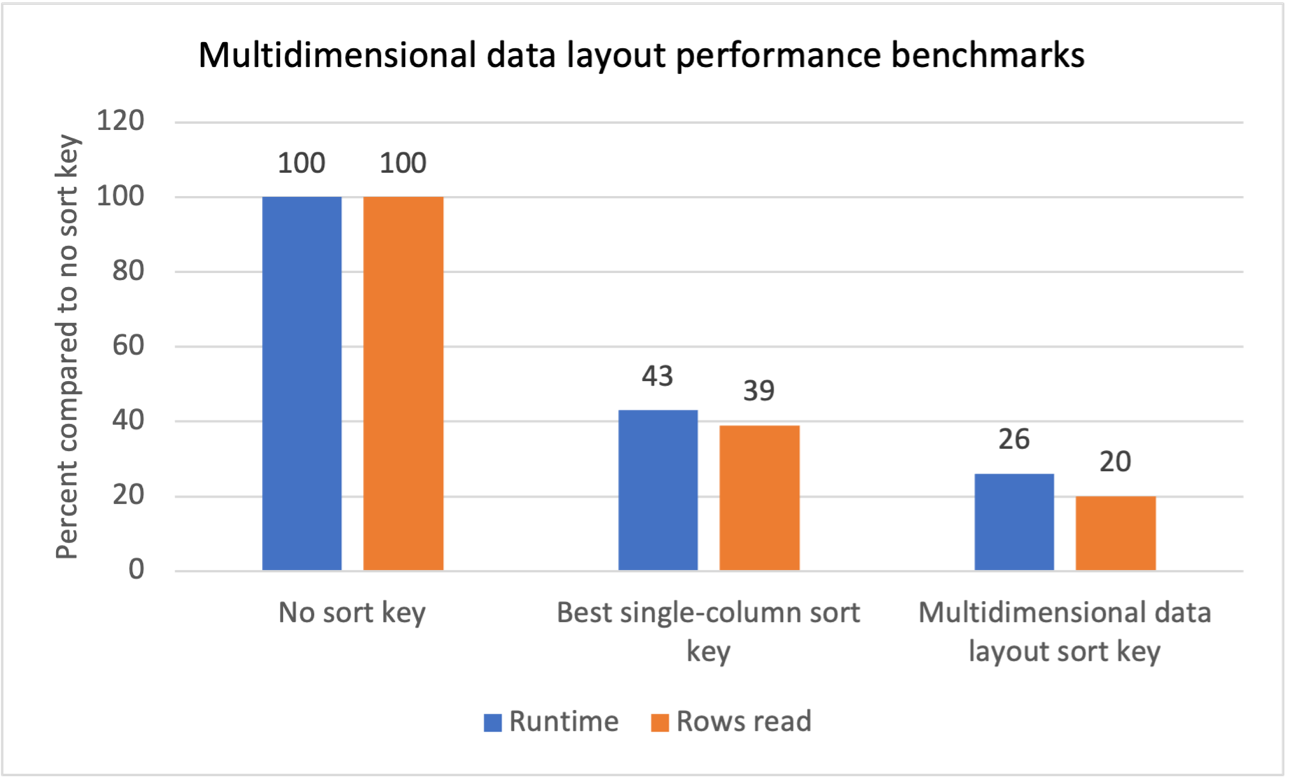
Nous avons effectué des tests de référence internes pour plusieurs charges de travail avec des filtres d'analyse répétitives et avons constaté que l'introduction de clés de tri de présentation de données multidimensionnelles a produit les résultats suivants :
- Une réduction totale du temps d’exécution de 74 % par rapport à l’absence de clé de tri.
- Une réduction totale du temps d'exécution de 40 % par rapport à la meilleure clé de tri à colonne unique sur chaque table.
- Une réduction de 80 % du nombre total de lignes lues dans les tables par rapport à l'absence de clé de tri.
- Une réduction de 47 % du nombre total de lignes lues dans les tables par rapport à la meilleure clé de tri à colonne unique sur chaque table.
Comparaison des fonctionnalités
Avec l'introduction de clés de tri de présentation de données multidimensionnelles, vos tableaux peuvent désormais être triés par expressions basées sur les prédicats de filtre courants dans votre charge de travail. Le tableau suivant fournit une comparaison des fonctionnalités d'Amazon Redshift par rapport à deux concurrents.
| Fonctionnalité | Redshift d'Amazon | Concurrent A | Concurrent B |
| Prise en charge du tri sur les colonnes | Oui | Oui | Oui |
| Prise en charge du tri par expression | Oui | Oui | Non |
| Sélection automatique des colonnes pour le tri | Oui | Non | Oui |
| Sélection automatique des expressions pour le tri | Oui | Non | Non |
| Sélection automatique entre le tri des colonnes ou le tri des expressions | Oui | Non | Non |
| Utilisation automatique des propriétés de tri des expressions lors des analyses | Oui | Non | Non |
Considérations
Gardez à l’esprit les points suivants lorsque vous utilisez une présentation de données multidimensionnelle :
- La disposition des données multidimensionnelles est activée lorsque vous définissez votre table sur SORTKEY AUTO.
- Amazon Redshift Advisor choisira automatiquement soit une clé de tri à colonne unique, soit une disposition de données multidimensionnelles pour le tableau en analysant votre charge de travail historique.
- Amazon Redshift ATO ajuste les résultats du tri de la disposition des données multidimensionnelles en fonction de la manière dont les requêtes en cours interagissent avec la charge de travail.
- Amazon Redshift ATO gère les clés de tri de présentation de données multidimensionnelles de la même manière qu'il le fait actuellement pour les clés de tri existantes. Faire référence à Travailler avec l'optimisation automatique des tables pour plus de détails sur ATO.
- Les clés de tri de présentation de données multidimensionnelles fonctionneront à la fois avec les clusters provisionnés et les groupes de travail sans serveur.
- Les clés de tri de présentation de données multidimensionnelles fonctionneront avec vos données existantes tant que AUTO SORTKEY est activée sur votre table et qu'une charge de travail avec des filtres d'analyse répétitives est détectée. Le tableau sera réorganisé en fonction des résultats de la fonction de tri multidimensionnel.
- Pour désactiver les clés de tri de présentation des données multidimensionnelles pour une table, utilisez alter table :
ALTER TABLE table_name ALTER SORTKEY NONE. Cela désactive la fonctionnalité de clé de tri AUTO sur la table. - Les clés de tri de présentation des données multidimensionnelles sont conservées lors de la restauration ou de la migration de votre cluster provisionné vers un cluster sans serveur ou vice versa.
Conclusion
Dans cet article, nous avons montré que les clés de tri de présentation de données multidimensionnelles peuvent améliorer considérablement les performances d'exécution des requêtes pour les charges de travail où les requêtes dominantes ont des filtres d'analyse répétitifs.
Pour créer un cluster de prévisualisation à partir de la console Amazon Redshift, accédez au Clusters page et choisissez Créer un cluster d'aperçu. Vous pouvez créer un cluster dans les régions USA Est (Ohio), USA Est (Virginie du Nord), USA Ouest (Oregon), Asie-Pacifique (Tokyo), Europe (Irlande) et Europe (Stockholm) et tester vos charges de travail.
Nous serions ravis d’entendre vos commentaires sur cette nouvelle fonctionnalité et attendons avec impatience vos commentaires sur cet article.
À propos des auteurs
 Milind Oké est un architecte de solutions spécialisé en entrepôt de données basé à New York. Il crée des solutions d'entrepôt de données depuis plus de 15 ans et se spécialise dans Amazon Redshift.
Milind Oké est un architecte de solutions spécialisé en entrepôt de données basé à New York. Il crée des solutions d'entrepôt de données depuis plus de 15 ans et se spécialise dans Amazon Redshift.
 Jialin Ding est un scientifique appliqué au sein du Learned Systems Group, spécialisé dans l'application de techniques d'apprentissage automatique et d'optimisation pour améliorer les performances des systèmes de données tels qu'Amazon Redshift.
Jialin Ding est un scientifique appliqué au sein du Learned Systems Group, spécialisé dans l'application de techniques d'apprentissage automatique et d'optimisation pour améliorer les performances des systèmes de données tels qu'Amazon Redshift.
 Yanzhu Ji est chef de produit au sein de l'équipe Amazon Redshift. Elle a de l'expérience dans la vision et la stratégie des produits dans les produits et plates-formes de données leaders de l'industrie. Elle possède des compétences exceptionnelles dans la création de produits logiciels substantiels à l'aide de techniques de développement Web, de conception de systèmes, de bases de données et de programmation distribuée. Dans sa vie personnelle, Yanzhu aime peindre, photographier et jouer au tennis.
Yanzhu Ji est chef de produit au sein de l'équipe Amazon Redshift. Elle a de l'expérience dans la vision et la stratégie des produits dans les produits et plates-formes de données leaders de l'industrie. Elle possède des compétences exceptionnelles dans la création de produits logiciels substantiels à l'aide de techniques de développement Web, de conception de systèmes, de bases de données et de programmation distribuée. Dans sa vie personnelle, Yanzhu aime peindre, photographier et jouer au tennis.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :possède
- :est
- :ne pas
- :où
- 1
- 100
- 15 ans
- 15%
- 152
- 7
- 8
- 9
- a
- accélérer
- accédé
- Supplémentaire
- conseiller
- Après
- à opposer à
- algorithme
- Tous
- déjà
- Amazon
- Amazon Web Services
- an
- il analyse
- l'analyse
- ainsi que
- Une autre
- appliqué
- Application
- SONT
- AS
- Asie
- Asie-Pacifique
- auto
- Automatique
- automatiquement
- disponibles
- AWS
- basé
- BE
- car
- était
- référence
- profiter
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Block
- Blocs
- Bleu
- tous les deux
- Développement
- mais
- by
- CAN
- aptitude
- vérifier
- Selectionnez
- le cloud
- Grappe
- Colonne
- Colonnes
- combinaison
- commentaires
- communément
- par rapport
- Comparaison
- concurrents
- complexe
- concept
- Considérer
- consiste
- Console
- construire
- contient
- Prix
- couvre
- engendrent
- Lecture
- données
- entrepôt de données
- Base de données
- décider
- dévoué
- Vous permet de définir
- Demande
- exigeant
- Conception
- détails
- détecté
- Déterminer
- Développement
- distribué
- distribution
- dominant
- Ne pas
- pendant
- chacun
- Est
- non plus
- activé
- Tout
- égal
- notamment
- Ether (ETH)
- Europe
- évaluation
- Pourtant, la
- évolué
- exemple
- existant
- d'experience
- expressions
- Fonctionnalité
- Réactions
- une fonction filtre
- filtres
- Abonnement
- suit
- Pour
- Avant
- quatre
- De
- fonction
- Réservation de groupe
- main
- Vous avez
- ayant
- he
- entendre
- ici
- historique
- Histoire
- Cependant
- HTML
- HTTPS
- ID
- if
- immédiatement
- améliorer
- améliore
- in
- inclut
- individuel
- leader de l'industrie
- plutôt ;
- interagir
- interne
- intervention
- développement
- introduire
- Découvrez le tout nouveau
- Introduction
- Irlande
- IT
- articles
- ACTIVITES
- clés
- gros
- Disposition
- savant
- apprentissage
- VIE
- comme
- aime
- Location
- Style
- ressembler
- love
- click
- machine learning
- maintient
- manager
- manière
- maximales
- Découvrez
- Métadonnées
- pourrait
- migrer
- l'esprit
- minimum
- PLUS
- (en fait, presque toutes)
- plusieurs
- NAVIGUER
- Besoin
- Nouveauté
- nouvelle fonctionnalité
- New York
- aucune
- maintenant
- numéros
- se produire
- of
- de rabais
- présenté
- Ohio
- on
- ONE
- en cours
- uniquement
- opérateurs
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Optimise
- Option
- or
- de commander
- Oregon
- original
- Autre
- ande
- exceptionnel
- plus de
- Pacifique
- peinture
- partie
- particulier
- Patron de Couture
- performant
- effectué
- personnel
- photographie
- Physique
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- jouer
- Post
- solide
- conservé
- Aperçu
- Produit
- Produit
- chef de produit
- Produits
- Programmation
- propriétés
- fournit
- requêtes
- rapidement
- Lire
- réduction
- reportez-vous
- région
- régions
- répétitif
- Exigences
- restauration
- résultat
- Résultats
- Courir
- pour le running
- fonctionne
- même
- balayage
- balayage
- analyse
- Scientifique
- Saison
- sur le lien
- Sélectionner
- choisi
- sélection
- Sans serveur
- Services
- set
- elle
- montrer
- vitrine
- montré
- montré
- Spectacles
- de façon significative
- unique
- compétence
- So
- Logiciels
- Solutions
- spécialiste
- spécialise
- spécialisation
- STORES
- de Marketing
- Par la suite
- Ces
- tel
- convient
- Appuyer
- combustion propre
- Système
- table
- Prenez
- équipe
- techniques
- tennis
- tester
- Essais
- que
- qui
- La
- leur
- donc
- l'ont
- this
- fiable
- titres
- à
- tokyo
- top
- Total
- traditionnel
- deux
- type
- typiquement
- us
- utilisé
- d'utiliser
- Utilisateur
- utilisateurs
- Usages
- en utilisant
- Plus-value
- Valeurs
- vice
- Voir
- Virginie
- vision
- Entrepots
- était
- Façon..
- we
- web
- Développement Web
- services Web
- Ouest
- quand
- que
- qui
- largement
- sera
- comprenant
- sans
- activités principales
- pourra
- années
- york
- you
- Votre
- zéphyrnet