Les chercheurs continuent de développer de nouvelles architectures de modèles pour les tâches courantes d'apprentissage automatique (ML). L'une de ces tâches est la classification d'images, où les images sont acceptées en entrée et le modèle tente de classer l'image dans son ensemble avec des sorties d'étiquette d'objet. Avec de nombreux modèles disponibles aujourd'hui qui effectuent cette tâche de classification d'images, un praticien ML peut poser des questions telles que : "Quel modèle dois-je affiner puis déployer pour obtenir les meilleures performances sur mon ensemble de données ?" Et un chercheur en ML peut poser des questions telles que : "Comment puis-je générer ma propre comparaison équitable de plusieurs architectures de modèles par rapport à un ensemble de données spécifié tout en contrôlant les hyperparamètres de formation et les spécifications informatiques, telles que les GPU, les CPU et la RAM ?" La première question porte sur la sélection de modèles dans les architectures de modèles, tandis que la dernière question concerne l'analyse comparative des modèles formés par rapport à un ensemble de données de test.
Dans cet article, vous verrez comment le Classification d'images TensorFlow algorithme de Amazon SageMaker JumpStart peut simplifier les implémentations requises pour répondre à ces questions. Avec les détails de mise en œuvre dans un document correspondant exemple de bloc-notes Jupyter, vous disposerez d'outils pour effectuer la sélection de modèles en explorant les frontières de Pareto, où l'amélioration d'une métrique de performance, telle que la précision, n'est pas possible sans aggraver une autre métrique, telle que le débit.
Vue d'ensemble de la solution
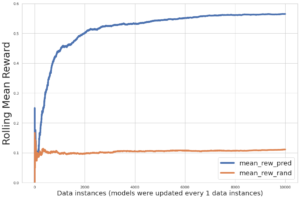
La figure suivante illustre le compromis de sélection de modèle pour un grand nombre de modèles de classification d'images affinés sur le Caltech-256 dataset, qui est un ensemble complexe de 30,607 256 images du monde réel couvrant XNUMX catégories d'objets. Chaque point représente un modèle unique, les tailles de point sont mises à l'échelle par rapport au nombre de paramètres composant le modèle, et les points sont codés par couleur en fonction de leur architecture de modèle. Par exemple, les points vert clair représentent l'architecture EfficientNet ; chaque point vert clair est une configuration différente de cette architecture avec des mesures de performances de modèle uniques et affinées. La figure montre l'existence d'une frontière de Pareto pour la sélection du modèle, où une plus grande précision est échangée contre un débit plus faible. En fin de compte, la sélection d'un modèle le long de la frontière de Pareto, ou de l'ensemble de solutions efficaces de Pareto, dépend des exigences de performances de déploiement de votre modèle.
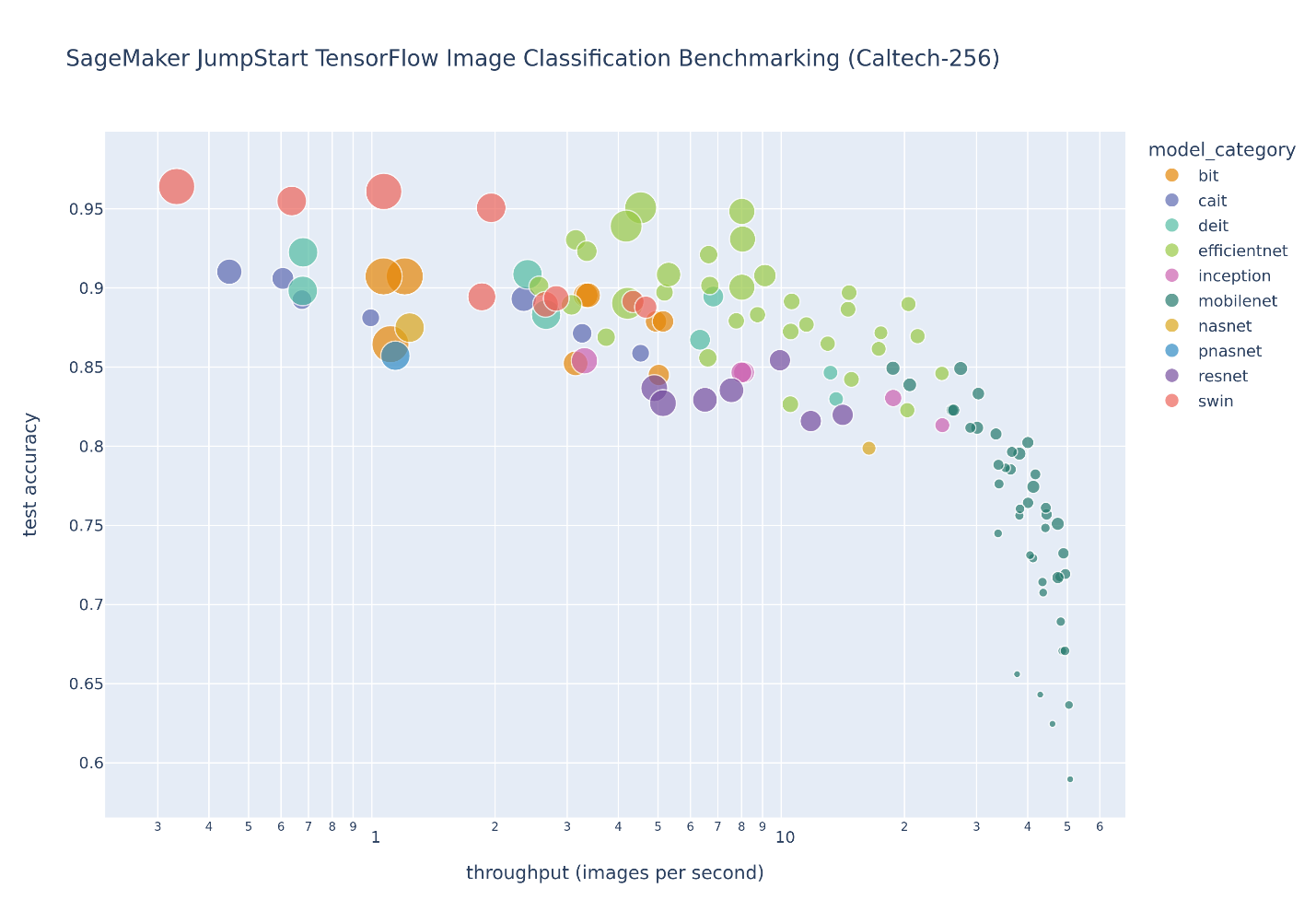
Si vous observez la précision du test et testez les frontières de débit d'intérêt, l'ensemble des solutions efficaces de Pareto sur la figure précédente sont extraites dans le tableau suivant. Les lignes sont triées de sorte que le débit du test augmente et que la précision du test diminue.
| Nom du modèle | Nombre de paramètres | Test de précision | Tester la précision des 5 meilleurs | Débit (images/s) | Durée par époque(s) |
| swin-large-patch4-window12-384 | 195.6M | 96.4% | 99.5% | 0.3 | 2278.6 |
| swin-large-patch4-window7-224 | 195.4M | 96.1% | 99.5% | 1.1 | 698.0 |
| efficacenet-v2-imagenet21k-ft1k-l | 118.1M | 95.1% | 99.2% | 4.5 | 1434.7 |
| efficacenet-v2-imagenet21k-ft1k-m | 53.5M | 94.8% | 99.1% | 8.0 | 769.1 |
| efficacenet-v2-imagenet21k-m | 53.5M | 93.1% | 98.5% | 8.0 | 765.1 |
| efficacenet-b5 | 29.0M | 90.8% | 98.1% | 9.1 | 668.6 |
| efficacenet-v2-imagenet21k-ft1k-b1 | 7.3M | 89.7% | 97.3% | 14.6 | 54.3 |
| efficacenet-v2-imagenet21k-ft1k-b0 | 6.2M | 89.0% | 97.0% | 20.5 | 38.3 |
| efficacenet-v2-imagenet21k-b0 | 6.2M | 87.0% | 95.6% | 21.5 | 38.2 |
| mobilenet-v3-large-100-224 | 4.6M | 84.9% | 95.4% | 27.4 | 28.8 |
| mobilenet-v3-large-075-224 | 3.1M | 83.3% | 95.2% | 30.3 | 26.6 |
| mobilenet-v2-100-192 | 2.6M | 80.8% | 93.5% | 33.5 | 23.9 |
| mobilenet-v2-100-160 | 2.6M | 80.2% | 93.2% | 40.0 | 19.6 |
| mobilenet-v2-075-160 | 1.7M | 78.2% | 92.8% | 41.8 | 19.3 |
| mobilenet-v2-075-128 | 1.7M | 76.1% | 91.1% | 44.3 | 18.3 |
| mobilenet-v1-075-160 | 2.0M | 75.7% | 91.0% | 44.5 | 18.2 |
| mobilenet-v1-100-128 | 3.5M | 75.1% | 90.7% | 47.4 | 17.4 |
| mobilenet-v1-075-128 | 2.0M | 73.2% | 90.0% | 48.9 | 16.8 |
| mobilenet-v2-075-96 | 1.7M | 71.9% | 88.5% | 49.4 | 16.6 |
| mobilenet-v2-035-96 | 0.7M | 63.7% | 83.1% | 50.4 | 16.3 |
| mobilenet-v1-025-128 | 0.3M | 59.0% | 80.7% | 50.8 | 16.2 |
Cet article fournit des détails sur la façon de mettre en œuvre à grande échelle Amazon Sage Maker tâches d'analyse comparative et de sélection de modèles. Tout d'abord, nous présentons JumpStart et les algorithmes de classification d'images TensorFlow intégrés. Nous discutons ensuite des considérations d'implémentation de haut niveau, telles que les configurations d'hyperparamètres JumpStart, l'extraction de métriques à partir de Journaux Amazon CloudWatch, et lancer des tâches de réglage d'hyperparamètres asynchrones. Enfin, nous couvrons l'environnement d'implémentation et le paramétrage conduisant aux solutions efficaces de Pareto dans le tableau et la figure précédents.
Introduction à la classification d'images JumpStart TensorFlow
JumpStart permet d'ajuster et de déployer en un clic une grande variété de modèles pré-formés pour les tâches ML courantes, ainsi qu'une sélection de solutions de bout en bout qui résolvent les problèmes commerciaux courants. Ces fonctionnalités simplifient chaque étape du processus de ML, ce qui facilite le développement de modèles de haute qualité et réduit le temps de déploiement. Le API JumpStart vous permettent de déployer et d'affiner par programme une vaste sélection de modèles pré-formés sur vos propres ensembles de données.
Le hub de modèles JumpStart donne accès à un grand nombre de Modèles de classification d'images TensorFlow qui permettent l'apprentissage par transfert et le réglage fin sur des ensembles de données personnalisés. Au moment d'écrire ces lignes, le hub de modèles JumpStart contient 135 modèles de classification d'images TensorFlow dans une variété d'architectures de modèles populaires de Hub TensorFlow, pour inclure les réseaux résiduels (ResNet), Réseau mobile, EfficaceNet, Début, Réseaux de recherche d'architecture neuronale (NASNet), gros transfert (BiT), fenêtre décalée (Swin) transformateurs, Class-Attention dans les transformateurs d'image (CAIT) et les transformateurs d'image efficaces en données (DEIT).
Des structures internes très différentes composent chaque architecture de modèle. Par exemple, les modèles ResNet utilisent des connexions de saut pour permettre des réseaux beaucoup plus profonds, tandis que les modèles basés sur des transformateurs utilisent des mécanismes d'auto-attention qui éliminent la localité intrinsèque des opérations de convolution en faveur de champs récepteurs plus globaux. En plus des divers ensembles de fonctionnalités fournis par ces différentes structures, chaque architecture de modèle a plusieurs configurations qui ajustent la taille, la forme et la complexité du modèle au sein de cette architecture. Cela se traduit par des centaines de modèles de classification d'images uniques disponibles sur le hub de modèles JumpStart. Combinée à l'apprentissage par transfert intégré et aux scripts d'inférence qui englobent de nombreuses fonctionnalités SageMaker, l'API JumpStart est un excellent point de départ pour les praticiens ML pour commencer à former et à déployer rapidement des modèles.
Reportez-vous à Transfert d'apprentissage pour les modèles de classification d'images TensorFlow dans Amazon SageMaker et les suivants exemple de cahier pour en savoir plus sur la classification d'images SageMaker TensorFlow, y compris comment exécuter l'inférence sur un modèle pré-formé et affiner le modèle pré-formé sur un ensemble de données personnalisé.
Considérations sur la sélection de modèles à grande échelle
La sélection de modèles est le processus de sélection du meilleur modèle parmi un ensemble de modèles candidats. Ce processus peut être appliqué sur des modèles du même type avec des pondérations de paramètres différentes et sur des modèles de types différents. Des exemples de sélection de modèles parmi des modèles du même type incluent l'ajustement du même modèle avec différents hyperparamètres (par exemple, le taux d'apprentissage) et l'arrêt précoce pour éviter le surajustement des poids du modèle à l'ensemble de données de train. La sélection de modèles parmi des modèles de différents types comprend la sélection de la meilleure architecture de modèle (par exemple, Swin contre MobileNet) et la sélection des meilleures configurations de modèle au sein d'une architecture de modèle unique (par exemple, mobilenet-v1-025-128 vs. mobilenet-v3-large-100-224).
Les considérations décrites dans cette section permettent tous ces processus de sélection de modèles sur un jeu de données de validation.
Sélectionner les configurations d'hyperparamètres
La classification d'images TensorFlow dans JumpStart dispose d'un grand nombre de hyperparamètres qui peut ajuster les comportements du script d'apprentissage de transfert de manière uniforme pour toutes les architectures de modèle. Ces hyperparamètres concernent l'augmentation et le prétraitement des données, la spécification de l'optimiseur, les contrôles de surajustement et les indicateurs de couche entraînables. Nous vous encourageons à ajuster les valeurs par défaut de ces hyperparamètres selon les besoins de votre application :
Pour cette analyse et le bloc-notes associé, tous les hyperparamètres sont définis sur les valeurs par défaut, à l'exception du taux d'apprentissage, du nombre d'époques et de la spécification d'arrêt précoce. Le taux d'apprentissage est ajusté comme un paramètre catégoriel par The Réglage automatique du modèle SageMaker emploi. Étant donné que chaque modèle a des valeurs d'hyperparamètres par défaut uniques, la liste discrète des taux d'apprentissage possibles inclut le taux d'apprentissage par défaut ainsi qu'un cinquième du taux d'apprentissage par défaut. Cela lance deux tâches de formation pour une seule tâche de réglage d'hyperparamètres, et la tâche de formation avec les meilleures performances signalées sur l'ensemble de données de validation est sélectionnée. Étant donné que le nombre d'époques est défini sur 10, ce qui est supérieur au paramètre d'hyperparamètre par défaut, la meilleure tâche d'entraînement sélectionnée ne correspond pas toujours au taux d'apprentissage par défaut. Enfin, un critère d'arrêt précoce est utilisé avec une patience, ou le nombre d'époques pour continuer l'entraînement sans amélioration, de trois époques.
Un paramètre d'hyperparamètre par défaut d'une importance particulière est train_only_on_top_layer, où, si défini sur True, les couches d'extraction d'entités du modèle ne sont pas ajustées sur l'ensemble de données d'apprentissage fourni. L'optimiseur entraînera uniquement les paramètres dans la couche de classification supérieure entièrement connectée avec une dimensionnalité de sortie égale au nombre d'étiquettes de classe dans l'ensemble de données. Par défaut, cet hyperparamètre est défini sur True, qui est un paramètre ciblé pour l'apprentissage par transfert sur de petits ensembles de données. Vous pouvez avoir un jeu de données personnalisé où l'extraction de caractéristiques de la pré-formation sur le jeu de données ImageNet n'est pas suffisante. Dans ces cas, vous devez définir train_only_on_top_layer à False. Bien que ce paramètre augmente le temps de formation, vous extrayez des caractéristiques plus significatives pour votre problème d'intérêt, augmentant ainsi la précision.
Extraire des métriques de CloudWatch Logs
L'algorithme de classification d'images JumpStart TensorFlow enregistre de manière fiable une variété de mesures pendant la formation qui sont accessibles à SageMaker Estimator et les objets HyperparameterTuner. Le constructeur d'un SageMaker Estimator possède de metric_definitions argument de mot-clé, qui peut être utilisé pour évaluer la tâche d'entraînement en fournissant une liste de dictionnaires avec deux clés : Nom pour le nom de la métrique, et Regex pour l'expression régulière utilisée pour extraire la métrique des journaux. L'accompagnement cahier montre les détails de la mise en œuvre. Le tableau suivant répertorie les métriques disponibles et les expressions régulières associées pour tous les modèles de classification d'images JumpStart TensorFlow.
| Nom de la métrique | Expression régulière |
| nombre de paramètres | "- Nombre de paramètres : ([0-9\.]+)" |
| nombre de paramètres entraînables | "- Nombre de paramètres entraînables : ([0-9\.]+)" |
| nombre de paramètres non entraînables | "- Nombre de paramètres non entraînables : ([0-9\.]+)" |
| métrique de l'ensemble de données de train | f"- {métrique} : ([0-9\.]+)" |
| métrique de l'ensemble de données de validation | f"- val_{metric} : ([0-9\.]+)" |
| mesure de l'ensemble de données de test | f"- Tester {métrique} : ([0-9\.]+)" |
| durée du train | "- Durée totale de l'entraînement : ([0-9\.]+)" |
| durée du train par époque | "- Durée moyenne d'entraînement par époque : ([0-9\.]+)" |
| test de latence d'évaluation | "- Tester la latence d'évaluation : ([0-9\.]+)" |
| latence de test par échantillon | "- Latence de test moyenne par échantillon : ([0-9\.]+)" |
| débit de test | "- Débit de test moyen : ([0-9\.]+)" |
Le script d'apprentissage par transfert intégré fournit une variété de métriques d'ensemble de données d'entraînement, de validation et de test dans ces définitions, telles que représentées par les valeurs de remplacement de la chaîne f. Les mesures exactes disponibles varient en fonction du type de classification effectuée. Tous les modèles compilés ont un loss métrique, qui est représentée par une perte d'entropie croisée pour un problème de classification binaire ou catégorique. Le premier est utilisé lorsqu'il y a une étiquette de classe ; ce dernier est utilisé s'il y a deux étiquettes de classe ou plus. S'il n'y a qu'une seule étiquette de classe, les métriques suivantes sont calculées, enregistrées et extractibles via les expressions régulières f-string dans le tableau précédent : nombre de vrais positifs (true_pos), nombre de faux positifs (false_pos), nombre de vrais négatifs (true_neg), nombre de faux négatifs (false_neg), precision, recall, aire sous la courbe des caractéristiques de fonctionnement du récepteur (ROC) (auc), et l'aire sous la courbe de précision-rappel (PR) (prc). De même, s'il y a six étiquettes de classe ou plus, une métrique de précision parmi les 5 premières (top_5_accuracy) est également calculé, journalisé et extractible via les expressions régulières précédentes.
Pendant la formation, les métriques spécifiées à un SageMaker Estimator sont émis vers CloudWatch Logs. Lorsque la formation est terminée, vous pouvez invoquer le API SageMaker DescribeTrainingJob et inspectez le FinalMetricDataList clé dans la réponse JSON :
Cette API nécessite que seul le nom de la tâche soit fourni à la requête. Ainsi, une fois terminée, les métriques peuvent être obtenues dans les analyses futures tant que le nom de la tâche de formation est correctement enregistré et récupérable. Pour cette tâche de sélection de modèle, les noms des tâches de réglage des hyperparamètres sont stockés et les analyses ultérieures rattachent un HyperparameterTuner objet étant donné le nom de la tâche de réglage, extrayez le meilleur nom de tâche de formation à partir du tuner d'hyperparamètres attaché, puis appelez le DescribeTrainingJob API comme décrit précédemment pour obtenir des métriques associées au meilleur travail de formation.
Lancer des tâches de réglage d'hyperparamètres asynchrones
Reportez-vous au correspondant cahier pour plus de détails sur la mise en œuvre du lancement asynchrone de tâches de réglage d'hyperparamètres, qui utilise la bibliothèque standard Python futurs concurrents module, une interface de haut niveau pour l'exécution asynchrone d'appelables. Plusieurs considérations liées à SageMaker sont implémentées dans cette solution :
- Chaque compte AWS est affilié à Quotas de service SageMaker. Vous devez afficher vos limites actuelles pour utiliser pleinement vos ressources et éventuellement demander des augmentations de limite de ressources si nécessaire.
- Des appels d'API fréquents pour créer de nombreuses tâches de réglage d'hyperparamètres simultanées peuvent dépasser le taux du SDK Python et lever des exceptions de limitation. Une solution consiste à créer un client SageMaker Boto3 avec une configuration de nouvelle tentative personnalisée.
- Que se passe-t-il si votre script rencontre une erreur ou s'il est arrêté avant la fin ? Pour une si grande sélection de modèles ou une étude comparative, vous pouvez enregistrer les noms des tâches de réglage et fournir des fonctions pratiques pour rattacher les tâches de réglage des hyperparamètres qui existent déjà :
Détails de l'analyse et discussion
L'analyse de cet article effectue un apprentissage par transfert pour ID de modèle dans l'algorithme de classification d'images JumpStart TensorFlow sur l'ensemble de données Caltech-256. Toutes les tâches de formation ont été effectuées sur l'instance de formation SageMaker ml.g4dn.xlarge, qui contient un seul GPU NVIDIA T4.
L'ensemble de données de test est évalué sur l'instance d'entraînement à la fin de l'entraînement. La sélection du modèle est effectuée avant l'évaluation de l'ensemble de données de test pour définir les pondérations du modèle sur l'époque avec les meilleures performances de l'ensemble de validation. Le débit de test n'est pas optimisé : la taille du lot de l'ensemble de données est définie sur la taille du lot d'hyperparamètres d'entraînement par défaut, qui n'est pas ajustée pour optimiser l'utilisation de la mémoire GPU ; le débit de test signalé inclut le temps de chargement des données, car l'ensemble de données n'est pas pré-caché ; et l'inférence distribuée sur plusieurs GPU n'est pas utilisée. Pour ces raisons, ce débit est une bonne mesure relative, mais le débit réel dépendra fortement de vos configurations de déploiement de point de terminaison d'inférence pour le modèle entraîné.
Bien que le concentrateur de modèles JumpStart contienne de nombreux types d'architecture de classification d'images, cette frontière de Pareto est dominée par certains modèles Swin, EfficientNet et MobileNet. Les modèles Swin sont plus grands et relativement plus précis, tandis que les modèles MobileNet sont plus petits, relativement moins précis et adaptés aux contraintes de ressources des appareils mobiles. Il est important de noter que cette frontière est conditionnée par une variété de facteurs, y compris l'ensemble de données exact utilisé et les hyperparamètres de réglage fin sélectionnés. Vous constaterez peut-être que votre jeu de données personnalisé produit un ensemble différent de solutions efficaces de Pareto, et vous souhaiterez peut-être des temps de formation plus longs avec différents hyperparamètres, comme une augmentation de données ou un réglage plus fin que la couche de classification supérieure du modèle.
Conclusion
Dans cet article, nous avons montré comment exécuter des tâches de sélection ou d'analyse comparative de modèles à grande échelle à l'aide du hub de modèles JumpStart. Cette solution peut vous aider à choisir le meilleur modèle pour vos besoins. Nous vous encourageons à essayer et à explorer ce sur mesure sur votre propre ensemble de données.
Bibliographie
Plus d'informations sont disponibles sur les ressources suivantes :
À propos des auteurs
 Dr Kyle Ulrich est un scientifique appliqué avec le Algorithmes intégrés d'Amazon SageMaker équipe. Ses intérêts de recherche comprennent les algorithmes d'apprentissage automatique évolutifs, la vision par ordinateur, les séries chronologiques, les processus bayésiens non paramétriques et gaussiens. Son doctorat est de l'Université Duke et il a publié des articles dans NeurIPS, Cell et Neuron.
Dr Kyle Ulrich est un scientifique appliqué avec le Algorithmes intégrés d'Amazon SageMaker équipe. Ses intérêts de recherche comprennent les algorithmes d'apprentissage automatique évolutifs, la vision par ordinateur, les séries chronologiques, les processus bayésiens non paramétriques et gaussiens. Son doctorat est de l'Université Duke et il a publié des articles dans NeurIPS, Cell et Neuron.
 Dr Ashish Khetan est un scientifique appliqué senior avec Algorithmes intégrés d'Amazon SageMaker et aide à développer des algorithmes d'apprentissage automatique. Il a obtenu son doctorat à l'Université de l'Illinois Urbana Champaign. Il est un chercheur actif en apprentissage automatique et en inférence statistique et a publié de nombreux articles dans les conférences NeurIPS, ICML, ICLR, JMLR, ACL et EMNLP.
Dr Ashish Khetan est un scientifique appliqué senior avec Algorithmes intégrés d'Amazon SageMaker et aide à développer des algorithmes d'apprentissage automatique. Il a obtenu son doctorat à l'Université de l'Illinois Urbana Champaign. Il est un chercheur actif en apprentissage automatique et en inférence statistique et a publié de nombreux articles dans les conférences NeurIPS, ICML, ICLR, JMLR, ACL et EMNLP.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/image-classification-model-selection-using-amazon-sagemaker-jumpstart/
- 10
- 100
- 9
- a
- À propos
- accès
- accessible
- Compte
- précision
- Avec cette connaissance vient le pouvoir de prendre
- atteindre
- à travers
- infection
- ajout
- propos
- adresses
- Ajusté
- Affilié
- à opposer à
- algorithme
- algorithmes
- Tous
- déjà
- Bien que
- toujours
- Amazon
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- selon une analyse de l’Université de Princeton
- ainsi que
- Une autre
- api
- Candidature
- appliqué
- de manière appropriée
- architecture
- Réservé
- argument
- associé
- joindre
- Tentatives
- Automatique
- disponibles
- moyen
- AWS
- basé
- Bayésien
- car
- before
- va
- LES MEILLEURS
- Big
- intégré
- la performance des entreprises
- Appels
- candidat
- cas
- catégories
- difficile
- caractéristique
- Selectionnez
- classe
- classification
- Classer
- client
- combiné
- Commun
- Comparaison
- complet
- Complété
- achèvement
- complexité
- ordinateur
- Vision par ordinateur
- Préoccupations
- conférences
- configuration
- connecté
- Connexions
- considérations
- contraintes
- contient
- continuer
- contrôle
- contrôles
- commodité
- Correspondant
- couverture
- engendrent
- Courant
- courbe
- Customiser
- données
- ensembles de données
- profond
- Réglage par défaut
- dépend
- déployer
- déployer
- déploiement
- profondeur
- décrit
- la description
- détails
- développer
- Compatibles
- différent
- discuter
- distribué
- plusieurs
- Ne fait pas
- Duc
- université de Duke
- pendant
- chacun
- Plus tôt
- "Early Bird"
- plus facilement
- efficace
- non plus
- éliminé
- permettre
- encourager
- encouragés
- end-to-end
- Endpoint
- Environment
- époque
- époques
- erreur
- Ether (ETH)
- évaluer
- évalué
- évaluation
- exemple
- exemples
- Sauf
- explorez
- Explorant
- expressions
- extrait
- extraction
- facteurs
- juste
- favoriser
- Fonctionnalité
- Fonctionnalités:
- Des champs
- Figure
- finalement
- Trouvez
- Prénom
- raccord
- Abonnement
- Ancien
- de
- frontière
- Frontières
- d’étiquettes électroniques entièrement
- fonctions
- avenir
- Contrats à terme
- générer
- obtenez
- donné
- Global
- Bien
- GPU
- GPU
- l'
- plus grand
- Vert
- arrive
- fortement
- aider
- aide
- de haut niveau
- de haute qualité
- augmentation
- Comment
- How To
- HTML
- HTTPS
- Moyeu
- Des centaines
- Réglage des hyperparamètres
- ICLR
- Illinois
- image
- Classification des images
- ImageNet
- satellite
- Mettre en oeuvre
- la mise en oeuvre
- mis en œuvre
- importance
- important
- amélioration
- l'amélioration de
- in
- comprendre
- inclut
- Y compris
- Améliore
- Augmente
- croissant
- Indicateurs
- d'information
- contribution
- instance
- intérêt
- intérêts
- Interfaces
- interne
- intrinsèque
- introduire
- IT
- Emploi
- Emplois
- json
- clés / KEY :
- clés
- Libellé
- Etiquettes
- gros
- grande échelle
- plus importantes
- Latence
- lance
- lancement
- couche
- poules pondeuses
- conduisant
- APPRENTISSAGE
- apprentissage
- lifting
- lumière
- LIMIT
- limites
- Liste
- Liste
- chargement
- Location
- plus long
- perte
- click
- machine learning
- Fabrication
- de nombreuses
- Maximisez
- significative
- des mesures
- Mémoire
- métrique
- Métrique
- ML
- Breeze Mobile
- appareils mobiles
- modèle
- numériques jumeaux (digital twin models)
- module
- PLUS
- plusieurs
- prénom
- noms
- nécessaire
- nécessaire
- Besoins
- réseaux
- Neural
- NeuroIPS
- Nouveauté
- cahier
- nombre
- Nvidia
- objet
- objets
- observer
- obtenir
- obtenu
- ONE
- d'exploitation
- Opérations
- optimisé
- décrit
- propre
- papiers
- paramètre
- paramètres
- particulier
- Patience
- effectuer
- performant
- effectue
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- des notes bonus
- Populaire
- possible
- Post
- l'éventualité
- pr
- empêcher
- Avant
- Problème
- d'ouvrabilité
- processus
- les process
- fournir
- à condition de
- fournit
- aportando
- publié
- Python
- question
- fréquemment posées
- vite.
- RAM
- Tarif
- Tarifs
- monde réel
- Les raisons
- réduire
- Standard
- relativement
- supprimez
- Signalé
- représentent
- représenté
- représente
- nécessaire
- conditions
- Exigences
- a besoin
- un article
- chercheur
- Résolution
- ressource
- Ressources
- réponse
- Résultats
- Courir
- pour le running
- sagemaker
- même
- évolutive
- Scientifique
- scripts
- Sdk
- Rechercher
- Section
- choisi
- la sélection
- sélection
- supérieur
- Série
- service
- Session
- set
- Sets
- mise
- plusieurs
- Forme
- devrait
- Spectacles
- De même
- simplifier
- simultané
- unique
- SIX
- Taille
- tailles
- petit
- faibles
- So
- sur mesure
- Solutions
- RÉSOUDRE
- spécification
- caractéristiques
- spécifié
- Standard
- j'ai commencé
- statistique
- étapes
- arrêté
- arrêt
- stockée
- Étude
- ultérieur
- substantiellement
- tel
- suffisant
- convient
- table
- des campagnes marketing ciblées,
- Tâche
- tâches
- équipe
- tensorflow
- tester
- La
- leur
- ainsi
- trois
- débit
- fiable
- Des séries chronologiques
- fois
- à
- aujourd'hui
- ensemble
- les outils
- top
- haut 5
- Total
- Train
- qualifié
- Formation
- transférer
- transformateurs
- oui
- types
- En fin de compte
- sous
- unique
- université
- Utilisation
- utilisé
- utiliser
- utilisé
- validation
- Valeurs
- variété
- Vaste
- via
- Voir
- vision
- qui
- tout en
- large
- sera
- dans les
- sans
- pourra
- écriture
- Votre
- zéphyrnet