Murmure OpenAI est un modèle avancé de reconnaissance vocale automatique (ASR) avec une licence MIT. La technologie ASR trouve son utilité dans les services de transcription, les assistants vocaux et l’amélioration de l’accessibilité pour les personnes malentendantes. Ce modèle de pointe est formé sur un ensemble de données vaste et diversifié de données supervisées multilingues et multitâches collectées sur le Web. Sa grande précision et son adaptabilité en font un atout précieux pour un large éventail de tâches liées à la voix.
Dans le paysage en constante évolution de l'apprentissage automatique et de l'intelligence artificielle, Amazon Sage Maker fournit un écosystème complet. SageMaker permet aux data scientists, aux développeurs et aux organisations de développer, former, déployer et gérer des modèles d'apprentissage automatique à grande échelle. Offrant une large gamme d'outils et de fonctionnalités, il simplifie l'ensemble du flux de travail d'apprentissage automatique, du prétraitement des données et du développement de modèles au déploiement et à la surveillance sans effort. L’interface conviviale de SageMaker en fait une plate-forme essentielle pour libérer tout le potentiel de l’IA, en faisant une solution révolutionnaire dans le domaine de l’intelligence artificielle.
Dans cet article, nous nous lançons dans une exploration des capacités de SageMaker, en nous concentrant spécifiquement sur l'hébergement de modèles Whisper. Nous allons approfondir deux méthodes pour ce faire : l'une utilisant le modèle Whisper PyTorch et l'autre utilisant l'implémentation Hugging Face du modèle Whisper. De plus, nous procéderons à un examen approfondi des options d'inférence de SageMaker, en les comparant sur des paramètres tels que la vitesse, le coût, la taille de la charge utile et l'évolutivité. Cette analyse permet aux utilisateurs de prendre des décisions éclairées lors de l'intégration des modèles Whisper dans leurs cas d'utilisation et systèmes spécifiques.
Vue d'ensemble de la solution
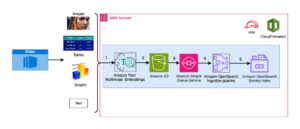
Le diagramme suivant montre les principaux composants de cette solution.
- Afin d'héberger le modèle sur Amazon SageMaker, la première étape consiste à enregistrer les artefacts du modèle. Ces artefacts font référence aux composants essentiels d'un modèle d'apprentissage automatique nécessaires à diverses applications, y compris le déploiement et le recyclage. Ils peuvent inclure des paramètres de modèle, des fichiers de configuration, des composants de prétraitement, ainsi que des métadonnées, telles que les détails de la version, la paternité et toute note relative à ses performances. Il est important de noter que les modèles Whisper pour les implémentations de PyTorch et Hugging Face sont constitués de différents artefacts de modèle.
- Ensuite, nous créons des scripts d'inférence personnalisés. Dans ces scripts, nous définissons comment le modèle doit être chargé et spécifions le processus d'inférence. C'est également là que nous pouvons intégrer des paramètres personnalisés selon nos besoins. De plus, vous pouvez répertorier les packages Python requis dans un
requirements.txtdéposer. Lors du déploiement du modèle, ces packages Python sont automatiquement installés lors de la phase d'initialisation. - Ensuite, nous sélectionnons les conteneurs d'apprentissage profond (DLC) PyTorch ou Hugging Face fournis et maintenus par AWS. Ces conteneurs sont des images Docker prédéfinies avec des frameworks d'apprentissage en profondeur et d'autres packages Python nécessaires. Pour plus d'informations, vous pouvez vérifier ceci lien.
- Avec les artefacts de modèle, les scripts d'inférence personnalisés et les DLC sélectionnés, nous créerons des modèles Amazon SageMaker pour PyTorch et Hugging Face respectivement.
- Enfin, les modèles peuvent être déployés sur SageMaker et utilisés avec les options suivantes : points de terminaison d'inférence en temps réel, tâches de transformation par lots et points de terminaison d'inférence asynchrone. Nous aborderons ces options plus en détail plus loin dans cet article.
L'exemple de notebook et le code de cette solution sont disponibles sur ce site GitHub référentiel.
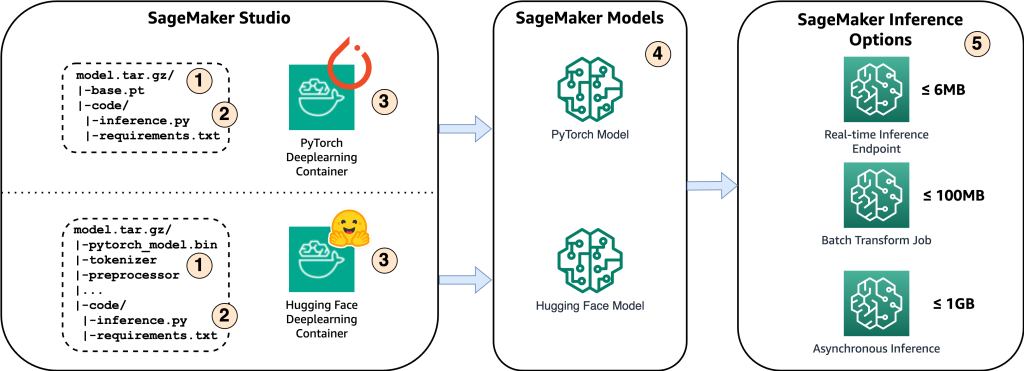
Figure 1. Présentation des composants clés de la solution
Procédure pas à pas
Hébergement du modèle Whisper sur Amazon SageMaker
Dans cette section, nous expliquerons les étapes pour héberger le modèle Whisper sur Amazon SageMaker, en utilisant respectivement PyTorch et Hugging Face Frameworks. Pour expérimenter cette solution, vous avez besoin d'un compte AWS et d'un accès au service Amazon SageMaker.
Cadre PyTorch
- Enregistrer les artefacts du modèle
La première option pour héberger le modèle consiste à utiliser le Paquet Python officiel Whisper, qui peut être installé à l'aide de pip install openai-whisper. Ce package fournit un modèle PyTorch. Lors de l'enregistrement des artefacts du modèle dans le référentiel local, la première étape consiste à enregistrer les paramètres apprenables du modèle, tels que les poids du modèle et les biais de chaque couche du réseau neuronal, sous forme de fichier « pt ». Vous pouvez choisir parmi différentes tailles de modèle, notamment « minuscule », « base », « petit », « moyen » et « grand ». Les tailles de modèle plus grandes offrent des performances de précision plus élevées, mais se font au prix d'une latence d'inférence plus longue. De plus, vous devez enregistrer le dictionnaire d'état du modèle et le dictionnaire de dimensions, qui contiennent un dictionnaire Python qui mappe chaque couche ou paramètre du modèle PyTorch à ses paramètres apprenables correspondants, ainsi qu'à d'autres métadonnées et configurations personnalisées. Le code ci-dessous montre comment enregistrer les artefacts Whisper PyTorch.
- Sélectionnez le DLC
L'étape suivante consiste à sélectionner le DLC pré-construit à partir de ce lien. Soyez prudent lorsque vous choisissez la bonne image en tenant compte des paramètres suivants : framework (PyTorch), version du framework, tâche (inférence), version Python et matériel (c'est-à-dire GPU). Il est recommandé d'utiliser les dernières versions du framework et de Python autant que possible, car cela entraîne de meilleures performances et résout les problèmes et bogues connus des versions précédentes.
- Créer des modèles Amazon SageMaker
Ensuite, nous utilisons le Kit de développement logiciel (SDK) SageMaker Python pour créer des modèles PyTorch. Il est important de penser à ajouter des variables d'environnement lors de la création d'un modèle PyTorch. Par défaut, TorchServe ne peut traiter que des fichiers d'une taille maximale de 6 Mo, quel que soit le type d'inférence utilisé.
Le tableau suivant montre les paramètres des différentes versions de PyTorch :
| Framework | Variables d'environnement |
| PyTorch 1.8 (basé sur TorchServe) | »TS_MAX_REQUEST_SIZE' : '100000000'» TS_MAX_RESPONSE_SIZE' : '100000000'» TS_DEFAULT_RESPONSE_TIMEOUT' : '1000' |
| PyTorch 1.4 (basé sur MMS) | »MMS_MAX_REQUEST_SIZE' : '1000000000'» MMS_MAX_RESPONSE_SIZE' : '1000000000'» MMS_DEFAULT_RESPONSE_TIMEOUT' : '900' |
- Définir la méthode de chargement du modèle dans inference.py
Dans la coutume inference.py script, nous vérifions d'abord la disponibilité d'un GPU compatible CUDA. Si un tel GPU est disponible, alors nous attribuons le 'cuda' appareil au DEVICE variable; sinon, nous attribuons le 'cpu' appareil. Cette étape garantit que le modèle est placé sur le matériel disponible pour un calcul efficace. Nous chargeons le modèle PyTorch à l'aide du package Whisper Python.
Cadre câlin visage
- Enregistrer les artefacts du modèle
La deuxième option consiste à utiliser Le murmure du visage étreint mise en œuvre. Le modèle peut être chargé à l'aide du AutoModelForSpeechSeq2Seq classe de transformateurs. Les paramètres apprenables sont enregistrés dans un fichier binaire (bin) à l'aide du save_pretrained méthode. Le tokenizer et le préprocesseur doivent également être enregistrés séparément pour garantir le bon fonctionnement du modèle Hugging Face. Vous pouvez également déployer un modèle sur Amazon SageMaker directement à partir du Hugging Face Hub en définissant deux variables d'environnement : HF_MODEL_ID ainsi que le HF_TASK. Pour plus d'informations, veuillez vous référer à ceci page web.
- Sélectionnez le DLC
Semblable au framework PyTorch, vous pouvez choisir un DLC Hugging Face pré-construit à partir du même lien. Assurez-vous de sélectionner un DLC prenant en charge les derniers transformateurs Hugging Face et incluant la prise en charge du GPU.
- Créer des modèles Amazon SageMaker
De même, nous utilisons le Kit de développement logiciel (SDK) SageMaker Python pour créer des modèles Hugging Face. Le modèle Hugging Face Whisper a une limitation par défaut où il ne peut traiter que des segments audio d'une durée maximale de 30 secondes. Pour remédier à cette limitation, vous pouvez inclure le chunk_length_s dans la variable d'environnement lors de la création du modèle Hugging Face, puis transmettez ce paramètre dans le script d'inférence personnalisé lors du chargement du modèle. Enfin, définissez les variables d'environnement pour augmenter la taille de la charge utile et le délai d'attente de réponse pour le conteneur Hugging Face.
| Framework | Variables d'environnement |
|
Conteneur d'inférence HuggingFace (basé sur MMS) |
»MMS_MAX_REQUEST_SIZE' : '2000000000'» MMS_MAX_RESPONSE_SIZE' : '2000000000'» MMS_DEFAULT_RESPONSE_TIMEOUT' : '900' |
- Définir la méthode de chargement du modèle dans inference.py
Lors de la création d'un script d'inférence personnalisé pour le modèle Hugging Face, nous utilisons un pipeline, nous permettant de transmettre le chunk_length_s comme paramètre. Ce paramètre permet au modèle de traiter efficacement de longs fichiers audio pendant l'inférence.
Explorer différentes options d'inférence sur Amazon SageMaker
Les étapes de sélection des options d'inférence sont les mêmes pour les modèles PyTorch et Hugging Face, nous ne les différencierons donc pas ci-dessous. Cependant, il convient de noter qu’au moment de la rédaction de cet article, le inférence sans serveur L'option de SageMaker ne prend pas en charge les GPU et, par conséquent, nous excluons cette option pour ce cas d'utilisation.
Nous pouvons déployer le modèle en tant que point de terminaison en temps réel, fournissant des réponses en millisecondes. Cependant, il est important de noter que cette option est limitée au traitement des entrées inférieures à 6 Mo. Nous définissons le sérialiseur comme un sérialiseur audio, chargé de convertir les données d'entrée dans un format adapté au modèle déployé. Nous utilisons une instance GPU pour l'inférence, permettant un traitement accéléré des fichiers audio. L'entrée d'inférence est un fichier audio provenant du référentiel local.
La deuxième option d'inférence est la tâche de transformation par lots, capable de traiter des charges utiles d'entrée allant jusqu'à 100 Mo. Toutefois, cette méthode peut prendre quelques minutes de latence. Chaque instance ne peut gérer qu'une seule demande par lots à la fois, et le lancement et l'arrêt de l'instance nécessitent également quelques minutes. Les résultats de l'inférence sont enregistrés dans un Amazon Simple Storage Service (Amazon S3) compartiment à la fin de la tâche de transformation par lots.
Lors de la configuration du transformateur par lots, assurez-vous d'inclure max_payload = 100 pour gérer efficacement des charges utiles plus importantes. L'entrée d'inférence doit être le chemin Amazon S3 vers un fichier audio ou un dossier Amazon S3 Bucket contenant une liste de fichiers audio, chacun d'une taille inférieure à 100 Mo.
Batch Transform partitionne les objets Amazon S3 dans l'entrée par clé et mappe les objets Amazon S3 aux instances. Par exemple, lorsque vous disposez de plusieurs fichiers audio, une instance peut traiter input1.wav et une autre instance peut traiter le fichier nommé input2.wav pour améliorer l'évolutivité. Batch Transform vous permet de configurer max_concurrent_transforms pour augmenter le nombre de requêtes HTTP adressées à chaque conteneur de transformateur individuel. Cependant, il est important de noter que la valeur de (max_concurrent_transforms* max_payload) ne doit pas dépasser 100 Mo.
Enfin, Amazon SageMaker Asynchronous Inference est idéal pour traiter plusieurs requêtes simultanément, offrant une latence modérée et prenant en charge des charges utiles d'entrée allant jusqu'à 1 Go. Cette option offre une excellente évolutivité, permettant la configuration d'un groupe de mise à l'échelle automatique pour le point de terminaison. Lorsqu'une augmentation des demandes se produit, il évolue automatiquement pour gérer le trafic, et une fois que toutes les demandes sont traitées, le point de terminaison passe à 0 pour réduire les coûts.
Grâce à l'inférence asynchrone, les résultats sont automatiquement enregistrés dans un compartiment Amazon S3. Dans le AsyncInferenceConfig, vous pouvez configurer des notifications pour les achèvements réussis ou échoués. Le chemin d'entrée pointe vers un emplacement Amazon S3 du fichier audio. Pour plus de détails, veuillez vous référer au code sur GitHub.
En option: Comme mentionné précédemment, nous avons la possibilité de configurer un groupe de mise à l'échelle automatique pour le point de terminaison d'inférence asynchrone, ce qui lui permet de gérer une augmentation soudaine des demandes d'inférence. Un exemple de code est fourni dans ce GitHub référentiel. Dans le diagramme suivant, vous pouvez observer un graphique linéaire affichant deux métriques de Amazon Cloud Watch: ApproximateBacklogSize ainsi que le ApproximateBacklogSizePerInstance. Initialement, lorsque 1000 XNUMX requêtes étaient déclenchées, une seule instance était disponible pour gérer l'inférence. Pendant trois minutes, la taille du backlog a systématiquement dépassé trois (veuillez noter que ces chiffres peuvent être configurés) et le groupe de mise à l'échelle automatique a répondu en créant des instances supplémentaires pour éliminer efficacement le retard. Cela s'est traduit par une diminution significative du ApproximateBacklogSizePerInstance, permettant de traiter les demandes en attente beaucoup plus rapidement que lors de la phase initiale.

Figure 2. Graphique linéaire illustrant les changements temporels des métriques Amazon CloudWatch
Analyse comparative des options d'inférence
Les comparaisons des différentes options d'inférence sont basées sur des cas d'utilisation courants du traitement audio. L'inférence en temps réel offre la vitesse d'inférence la plus rapide, mais limite la taille de la charge utile à 6 Mo. Ce type d'inférence convient aux systèmes de commande audio, dans lesquels les utilisateurs contrôlent ou interagissent avec des appareils ou des logiciels à l'aide de commandes vocales ou d'instructions vocales. Les commandes vocales sont généralement de petite taille et une faible latence d'inférence est cruciale pour garantir que les commandes transcrites peuvent déclencher rapidement des actions ultérieures. Batch Transform est idéal pour les tâches hors ligne planifiées, lorsque la taille de chaque fichier audio est inférieure à 100 Mo et qu'il n'y a aucune exigence spécifique pour des temps de réponse d'inférence rapides. L'inférence asynchrone permet des téléchargements allant jusqu'à 1 Go et offre une latence d'inférence modérée. Ce type d'inférence est bien adapté à la transcription de films, de séries télévisées et de conférences enregistrées où des fichiers audio plus volumineux doivent être traités.
Les options d'inférence en temps réel et asynchrone offrent des capacités de mise à l'échelle automatique, permettant aux instances de point de terminaison d'augmenter ou de diminuer automatiquement en fonction du volume de requêtes. En l’absence de requêtes, l’autoscaling supprime les instances inutiles, vous aidant ainsi à éviter les coûts associés aux instances provisionnées qui ne sont pas activement utilisées. Cependant, pour l'inférence en temps réel, au moins une instance persistante doit être conservée, ce qui pourrait entraîner des coûts plus élevés si le point de terminaison fonctionne en continu. En revanche, l'inférence asynchrone permet de réduire le volume de l'instance à 0 lorsqu'elle n'est pas utilisée. Lors de la configuration d'une tâche de transformation par lots, il est possible d'utiliser plusieurs instances pour traiter la tâche et d'ajuster max_concurrent_transforms pour permettre à une instance de gérer plusieurs requêtes. Par conséquent, les trois options d’inférence offrent une grande évolutivité.
Nettoyer
Une fois que vous avez terminé d'utiliser la solution, assurez-vous de supprimer les points de terminaison SageMaker pour éviter d'engager des coûts supplémentaires. Vous pouvez utiliser le code fourni pour supprimer respectivement les points de terminaison d'inférence en temps réel et asynchrone.
Conclusion
Dans cet article, nous vous avons montré comment le déploiement de modèles d'apprentissage automatique pour le traitement audio est devenu de plus en plus essentiel dans divers secteurs. En prenant le modèle Whisper comme exemple, nous avons montré comment héberger des modèles ASR open source sur Amazon SageMaker à l'aide des approches PyTorch ou Hugging Face. L'exploration englobait diverses options d'inférence sur Amazon SageMaker, offrant des informations sur la gestion efficace des données audio, la réalisation de prédictions et la gestion efficace des coûts. Cet article vise à fournir des connaissances aux chercheurs, développeurs et scientifiques des données souhaitant tirer parti du modèle Whisper pour des tâches liées à l'audio et prendre des décisions éclairées sur les stratégies d'inférence.
Pour des informations plus détaillées sur le déploiement de modèles sur SageMaker, veuillez vous référer à ceci Guide du développeur. De plus, le modèle Whisper peut être déployé à l'aide de SageMaker JumpStart. Pour plus de détails, veuillez consulter le Les modèles Whisper pour la reconnaissance vocale automatique sont désormais disponibles dans Amazon SageMaker JumpStart poster.
N'hésitez pas à consulter le notebook et le code de ce projet sur GitHub et partagez-nous votre commentaire.
À propos de l’auteur
 Ying Hou, Ph.D., est architecte de prototypage d'apprentissage automatique chez AWS. Ses principaux domaines d'intérêt englobent le Deep Learning, avec un accent sur GenAI, Computer Vision, NLP et la prédiction de données de séries chronologiques. Dans ses temps libres, elle aime passer des moments de qualité avec sa famille, se plonger dans des romans et faire des randonnées dans les parcs nationaux du Royaume-Uni.
Ying Hou, Ph.D., est architecte de prototypage d'apprentissage automatique chez AWS. Ses principaux domaines d'intérêt englobent le Deep Learning, avec un accent sur GenAI, Computer Vision, NLP et la prédiction de données de séries chronologiques. Dans ses temps libres, elle aime passer des moments de qualité avec sa famille, se plonger dans des romans et faire des randonnées dans les parcs nationaux du Royaume-Uni.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- accéléré
- accès
- accessibilité
- Compte
- précision
- à travers
- actes
- activement
- ajouter
- Supplémentaire
- En outre
- propos
- régler
- Avancée
- AI
- vise
- Tous
- Permettre
- permet
- le long de
- aussi
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- selon une analyse de l’Université de Princeton
- ainsi que le
- Une autre
- tous
- applications
- approches
- SONT
- domaines
- tableau
- artificiel
- intelligence artificielle
- AS
- atout
- assistants
- associé
- At
- acoustique
- Paternité
- Automatique
- automatiquement
- disponibilité
- disponibles
- éviter
- AWS
- base
- basé
- BE
- devenez
- ci-dessous
- Améliorée
- jusqu'à XNUMX fois
- biais
- BIN
- tous les deux
- bogues
- mais
- by
- CAN
- capacités
- capable
- prudent
- cas
- Modifications
- Graphique
- vérifier
- Selectionnez
- choose
- classe
- clair
- code
- comment
- commentaire
- Commun
- comparant
- comparaisons
- Complété
- achèvement
- composants électriques
- complet
- calcul
- ordinateur
- Vision par ordinateur
- Conduire
- conférences
- configuration
- configurée
- Configurer
- considérant
- régulièrement
- contiennent
- Contenant
- Conteneurs
- continuellement
- contraste
- des bactéries
- conversion
- correct
- Correspondant
- Prix
- Costs
- pourriez
- Processeur
- engendrent
- La création
- crucial
- Customiser
- données
- décisions
- diminuer
- profond
- l'apprentissage en profondeur
- Réglage par défaut
- Vous permet de définir
- démontré
- déployer
- déployé
- déployer
- déploiement
- détail
- détaillé
- détails
- développer
- mobiles
- Développement
- dispositif
- Compatibles
- différent
- différencier
- Dimension
- directement
- afficher
- plongeon
- plusieurs
- Docker
- Ne fait pas
- faire
- down
- pendant
- e
- chacun
- Plus tôt
- risque numérique
- de manière efficace
- efficace
- efficacement
- sans effort
- non plus
- d'autre
- embarquer
- responsabilise
- permettre
- permet
- permettant
- englober
- Endpoint
- critères
- de renforcer
- améliorer
- assurer
- Assure
- Tout
- Environment
- essential
- établissement
- Ether (ETH)
- examen
- exemple
- dépassent
- dépassé
- excellent
- expérience
- Expliquer
- exploration
- Explorer
- Visage
- Échoué
- non
- famille
- RAPIDE
- plus rapide
- le plus rapide
- few
- Déposez votre dernière attestation
- Fichiers
- trouve
- Prénom
- Focus
- mettant l'accent
- Abonnement
- Pour
- le format
- Framework
- cadres
- Gratuit
- De
- plein
- GPU
- GPU
- l'
- Réservation de groupe
- manipuler
- Maniabilité
- Matériel
- Vous avez
- entendre
- aider
- ici
- Haute
- augmentation
- randonnée
- hôte
- hébergement
- Comment
- How To
- Cependant
- HTML
- http
- HTTPS
- Moyeu
- Étreindre
- i
- idéal
- if
- illustrant
- image
- satellite
- la mise en oeuvre
- implémentations
- importer
- important
- in
- en profondeur
- comprendre
- inclut
- Y compris
- intégrer
- Améliore
- de plus en plus
- individuel
- individus
- secteurs
- d'information
- Actualités
- initiale
- possible
- initiation
- contribution
- entrées
- idées.
- installer
- instance
- cas
- Des instructions
- Intégration
- Intelligence
- interagir
- intérêt
- intéressé
- Interfaces
- développement
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- SES
- Emploi
- Emplois
- jpg
- ACTIVITES
- spécialisées
- connu
- paysage d'été
- plus importantes
- enfin
- Latence
- plus tard
- Nouveautés
- couche
- conduire
- apprentissage
- au
- en tirant parti
- Licence
- limitation
- limité
- Gamme
- Liste
- charge
- chargement
- locales
- emplacement
- Location
- plus long
- Faible
- click
- machine learning
- LES PLANTES
- Entrée
- a prendre une
- FAIT DU
- Fabrication
- gérer
- les gérer
- Map
- Mai..
- mentionné
- Métadonnées
- méthode
- méthodes
- Métrique
- pourrait
- millisecondes
- minutes
- MIT
- ML
- modèle
- numériques jumeaux (digital twin models)
- modérée
- Des moments
- Stack monitoring
- PLUS
- Films
- beaucoup
- plusieurs
- must
- Nommé
- Nationales
- parcs nationaux
- nécessaire
- Besoin
- nécessaire
- réseau et
- Neural
- Réseau neuronal
- next
- nlp
- aucune
- noter
- cahier
- Notes
- déclaration
- Notifications
- notant
- maintenant
- nombre
- numéros
- objet
- objets
- observer
- of
- code
- offrant
- Offres Speciales
- officiel
- direct
- on
- une fois
- ONE
- uniquement
- open source
- exploite
- Option
- Options
- or
- de commander
- organisations
- OS
- Autre
- autrement
- ande
- vue d'ensemble
- paquet
- Forfaits
- paramètre
- paramètres
- parcs
- pass
- chemin
- effectuer
- performant
- phase
- pipeline
- pivot
- mis
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- des notes bonus
- possible
- Post
- défaillances
- prédiction
- Prédictions
- empêcher
- précédent
- primaire
- processus
- traité
- traitement
- Processeur
- Projet
- correctement
- prototypage
- fournir
- à condition de
- fournit
- aportando
- Python
- pytorch
- qualité
- gamme
- en temps réel
- royaume
- reconnaissance
- recommandé
- enregistré
- Prix Réduit
- reportez-vous
- Indépendamment
- en relation
- de Presse
- rappeler
- supprimez
- supprime
- dépôt
- nécessaire
- demandes
- exigent
- conditions
- exigence
- chercheurs
- respectivement
- réponse
- réponses
- responsables
- résultat
- résulté
- Résultats
- retenu
- recyclage
- retourner
- sagemaker
- même
- Épargnez
- sauvé
- économie
- Évolutivité
- Escaliers intérieurs
- Balance
- prévu
- scientifiques
- scénario
- scripts
- Deuxièmement
- secondes
- Section
- segments
- Sélectionner
- choisi
- la sélection
- Série
- service
- Services
- set
- mise
- Paramétres
- Partager
- elle
- devrait
- montré
- Spectacles
- shutdown
- significative
- étapes
- simplifie
- Taille
- tailles
- petit
- faibles
- So
- Logiciels
- sur mesure
- groupe de neurones
- spécifiquement
- spécifié
- discours
- Reconnaissance vocale
- vitesse
- Dépenses
- parlé
- Commencer
- Région
- state-of-the-art
- étapes
- Étapes
- storage
- les stratégies
- ultérieur
- réussi
- tel
- soudain
- convient
- Support
- Appuyer
- Les soutiens
- sûr
- se pose
- Système
- table
- Prenez
- prise
- Tâche
- tâches
- Technologie
- que
- qui
- La
- au Royaume-Uni
- leur
- Les
- puis
- Là.
- donc
- Ces
- l'ont
- this
- trois
- fiable
- Des séries chronologiques
- fois
- à
- les outils
- torche
- circulation
- Train
- qualifié
- Transformer
- transformateur
- transformateurs
- déclencher
- déclenché
- tv
- Séries TV
- deux
- type
- typiquement
- Uk
- sous
- déverrouillage
- sur
- us
- utilisé
- d'utiliser
- convivial
- utilisateurs
- en utilisant
- utilitaire
- utiliser
- Utilisant
- Précieux
- Plus-value
- variable
- divers
- Vaste
- version
- vision
- Voix
- les commandes vocales
- le volume
- attendez
- souhaitez
- était
- we
- web
- services Web
- WELL
- ont été
- quand
- chaque fois que
- qui
- Chuchotement
- large
- Large gamme
- comprenant
- dans les
- workflow
- vos contrats
- vaut
- écriture
- you
- Votre
- zéphyrnet