Dans cet article, nous apprendrons comment déployer et utiliser le modèle GPT4All sur votre ordinateur uniquement CPU (j'utilise un Macbook Pro sans GPU !)

Utilisez GPT4All sur votre ordinateur — Image de l'auteur
Dans cet article nous allons installer sur notre ordinateur local GPT4All (un LLM puissant) et nous allons découvrir comment interagir avec nos documents avec python. Une collection de PDF ou d'articles en ligne sera la base de connaissances pour nos questions/réponses.
Extrait du site officiel GPT4All il est décrit comme un chatbot gratuit, fonctionnant localement et respectueux de la vie privée. Aucun GPU ou Internet requis.
GTP4All est un écosystème pour former et déployer solide ainsi que les sont adaptées grands modèles de langage qui s'exécutent localement sur les processeurs grand public.
Notre modèle GPT4All est un fichier de 4 Go que vous pouvez télécharger et connecter au logiciel de l'écosystème open source GPT4All. IA Nomique facilite la création d'écosystèmes logiciels sécurisés et de haute qualité, en stimulant les efforts pour permettre aux individus et aux organisations de former et de mettre en œuvre sans effort leurs propres grands modèles de langage localement.
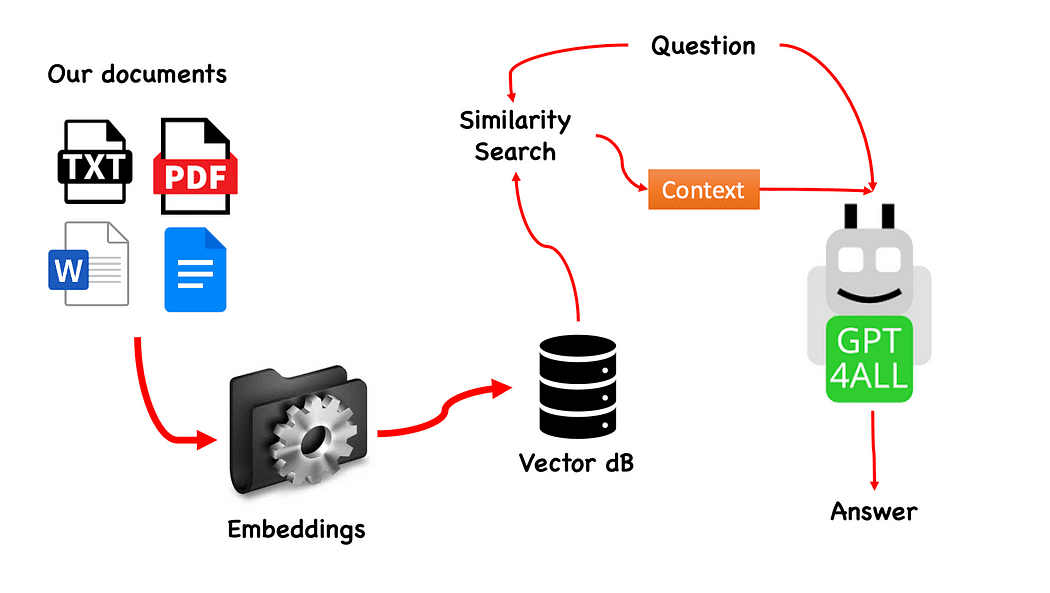
Flux de travail du QnA avec GPT4All — créé par l'auteur
Le processus est très simple (lorsque vous le connaissez) et peut également être répété avec d'autres modèles. Les étapes sont les suivantes:
- charger le modèle GPT4All
- utilisé Langchain pour récupérer nos documents et les charger
- diviser les documents en petits morceaux digestibles par Embeddings
- Utilisez FAISS pour créer notre base de données vectorielle avec les plongements
- Effectuez une recherche de similarité (recherche sémantique) sur notre base de données vectorielles en fonction de la question que nous voulons passer à GPT4All : celle-ci servira de contexte pour notre question
- Envoyez la question et le contexte à GPT4All avec Langchain et attendez la réponse.
Donc, ce dont nous avons besoin, ce sont des incorporations. Une intégration est une représentation numérique d'un élément d'information, par exemple, du texte, des documents, des images, de l'audio, etc. La représentation capture la signification sémantique de ce qui est intégré, et c'est exactement ce dont nous avons besoin. Pour ce projet, nous ne pouvons pas compter sur des modèles GPU lourds : nous allons donc télécharger le modèle natif Alpaca et l'utiliser à partir de Langchain le LamaCppIncorporations. Ne t'inquiète pas! Tout est expliqué étape par étape
Créer un environnement virtuel
Créez un nouveau dossier pour votre nouveau projet Python, par exemple GPT4ALL_Fabio (mettez votre nom...) :
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioEnsuite, créez un nouvel environnement virtuel Python. Si vous avez plusieurs versions de python installées, précisez la version souhaitée : dans ce cas, j'utiliserai mon installation principale, associée à python 3.10.
python3 -m venv .venvLa commande python3 -m venv .venv crée un nouvel environnement virtuel nommé .venv (le point créera un répertoire caché appelé venv).
Un environnement virtuel fournit une installation Python isolée, ce qui vous permet d'installer des packages et des dépendances uniquement pour un projet spécifique sans affecter l'installation Python à l'échelle du système ou d'autres projets. Cet isolement permet de maintenir la cohérence et d'éviter les conflits potentiels entre les différentes exigences du projet.
Une fois l'environnement virtuel créé, vous pouvez l'activer à l'aide de la commande suivante :
source .venv/bin/activate 
Environnement virtuel activé
Les bibliothèques à installer
Pour le projet que nous construisons, nous n'avons pas besoin de trop de packages. Nous n'avons besoin que de :
- liaisons python pour GPT4All
- Langchain pour interagir avec nos documents
LangChain est un framework pour développer des applications alimentées par des modèles de langage. Il vous permet non seulement d'appeler un modèle de langage via une API, mais également de connecter un modèle de langage à d'autres sources de données et de permettre à un modèle de langage d'interagir avec son environnement.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4Pour LangChain, vous voyez que nous avons également spécifié la version. Cette bibliothèque reçoit de nombreuses mises à jour récemment, donc pour être certain que notre configuration fonctionnera également demain, il est préférable de spécifier une version dont nous savons qu'elle fonctionne correctement. Non structuré est une dépendance requise pour le chargeur pdf et pytesseract ainsi que les pdf2image également.
REMARQUE: sur le dépôt GitHub il y a un fichier requirements.txt (suggéré par jl adcr) avec toutes les versions associées à ce projet. Vous pouvez effectuer l'installation en une seule fois, après l'avoir téléchargé dans le répertoire principal du projet avec la commande suivante :
pip install -r requirements.txtA la fin de l'article, j'ai créé un section pour le dépannage. Le repo GitHub a également un READ.ME mis à jour avec toutes ces informations.
Gardez à l'esprit que certains les bibliothèques ont des versions disponibles en fonction de la version de python vous exécutez sur votre environnement virtuel.
Téléchargez sur votre PC les modèles
C'est une étape très importante.
Pour le projet, nous avons certainement besoin de GPT4All. Le processus décrit sur Nomic AI est vraiment compliqué et nécessite du matériel que nous n'avons pas tous (comme moi). Donc voici le lien vers le modèle déjà converti et prêt à être utilisé. Cliquez simplement sur télécharger.
Télécharger le modèle GPT4All
Comme décrit brièvement dans l'introduction, nous avons également besoin du modèle pour les incorporations, un modèle que nous pouvons exécuter sur notre CPU sans écraser. Clique le lien ici pour télécharger le alpaca-native-7B-ggml déjà converti en 4 bits et prêt à être utilisé pour servir de modèle pour l'intégration.

Cliquez sur la flèche de téléchargement à côté de ggml-model-q4_0.bin
Pourquoi avons-nous besoin d'intégrations ? Si vous vous souvenez du diagramme de flux, la première étape requise, après avoir collecté les documents pour notre base de connaissances, consiste à enchâsser eux. Les encastrements LLamaCPP de ce modèle Alpaca conviennent parfaitement et ce modèle est également assez petit (4 Go). Au fait, vous pouvez également utiliser le modèle Alpaca pour votre QnA !
Mise à jour 2023.05.25 : Les utilisateurs de Mani Windows rencontrent des problèmes pour utiliser les intégrations llamaCPP. Cela se produit principalement parce que lors de l'installation du package python llama-cpp-python avec :
pip install llama-cpp-pythonle paquet pip va compiler à partir de la source la bibliothèque. Windows n'a généralement pas CMake ou le compilateur C installé par défaut sur la machine. Mais ne vous inquiétez pas il y a une solution
L'exécution de l'installation de llama-cpp-python, requise par LangChain avec les llamaEmbeddings, sur le compilateur Windows CMake C n'est pas installée par défaut, vous ne pouvez donc pas construire à partir de la source.
Sur les utilisateurs Mac avec Xtools et sur Linux, le compilateur C est généralement déjà disponible sur le système d'exploitation.
Pour éviter le problème vous DEVEZ utiliser une roue pré-conformée.
Rendez-vous ici https://github.com/abetlen/llama-cpp-python/releases
et recherchez la roue conforme pour votre architecture et votre version python — vous DEVEZ prendre Weels Version 0.1.49 car les versions supérieures ne sont pas compatibles.
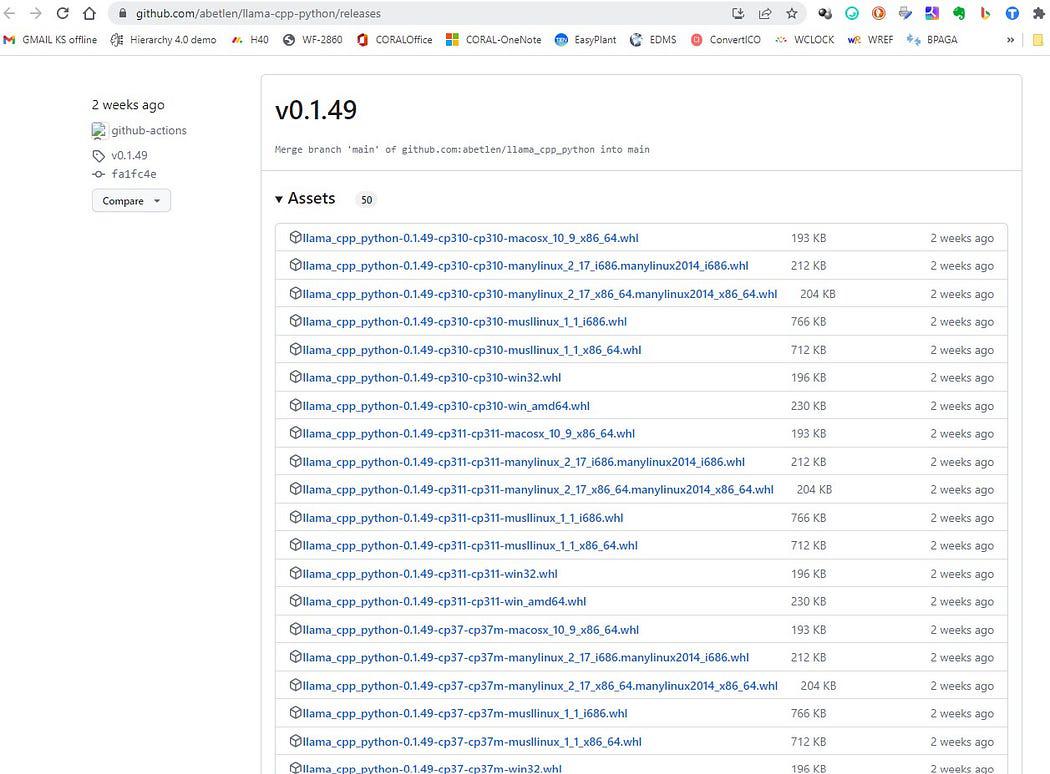
Capture d'écran de https://github.com/abetlen/llama-cpp-python/releases
Dans mon cas, j'ai Windows 10, 64 bits, python 3.10
donc mon fichier est llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
Ce le problème est suivi sur le référentiel GitHub
Après le téléchargement, vous devez placer les deux modèles dans le répertoire des modèles, comme indiqué ci-dessous.

Structure du répertoire et emplacement des fichiers de modèle
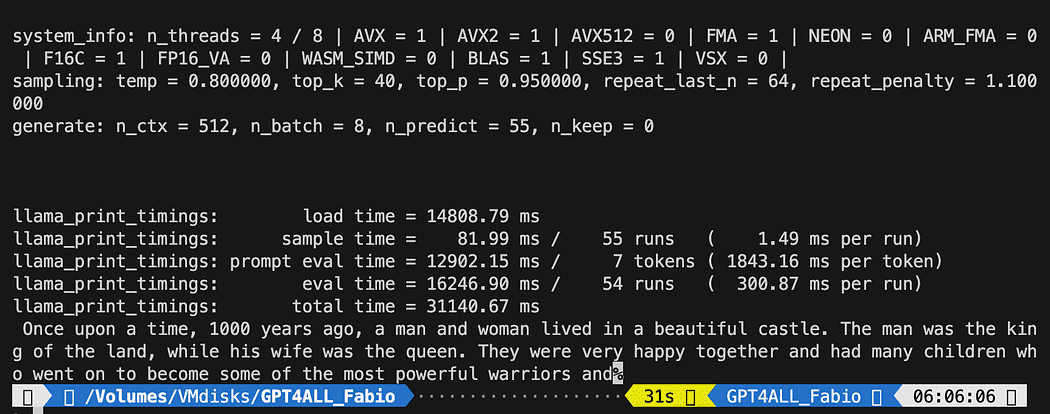
Puisque nous voulons avoir le contrôle de notre interaction avec le modèle GPT, nous devons créer un fichier python (appelons-le pygpt4all_test.py), importez les dépendances et donnez l'instruction au modèle. Vous verrez que c'est assez facile.
from pygpt4all.models.gpt4all import GPT4AllIl s'agit de la liaison python pour notre modèle. Maintenant, nous pouvons l'appeler et commencer à demander. Essayons un créatif.
Nous créons une fonction qui lit le rappel du modèle et nous demandons à GPT4All de compléter notre phrase.
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)La première instruction indique à notre programme où trouver le modèle (rappelez-vous ce que nous avons fait dans la section ci-dessus)
La deuxième instruction demande au modèle de générer une réponse et de compléter notre invite "Il était une fois".
Pour l'exécuter, assurez-vous que l'environnement virtuel est toujours activé et lancez simplement :
python3 pygpt4all_test.pyVous devriez voir un texte de chargement du modèle et l'achèvement de la phrase. Selon vos ressources matérielles, cela peut prendre un peu de temps.
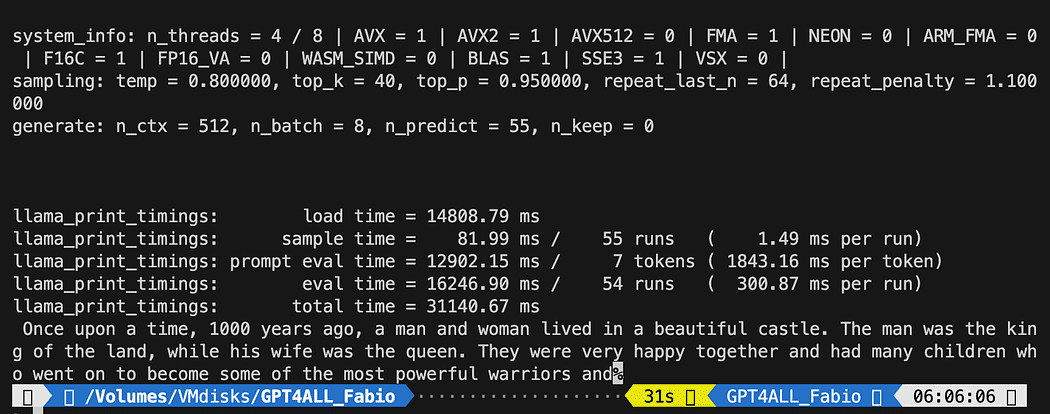
Le résultat peut être différent du vôtre… Mais pour nous, l'important est que cela fonctionne et nous pouvons continuer avec LangChain pour créer des éléments avancés.
REMARQUE (mise à jour 2023.05.23): si vous rencontrez une erreur liée à pygpt4all, consultez la section de dépannage sur ce sujet avec la solution donnée par Rajneesh Aggarwal or d'Oscar Jeong.
Le framework LangChain est une bibliothèque vraiment incroyable. Il offre Composantes pour travailler avec des modèles de langage d'une manière facile à utiliser, et il fournit également Chaînes. Les chaînes peuvent être considérées comme l'assemblage de ces composants de manière particulière afin d'accomplir au mieux un cas d'utilisation particulier. Ceux-ci sont destinés à être une interface de niveau supérieur à travers laquelle les gens peuvent facilement démarrer avec un cas d'utilisation spécifique. Ces chaînes sont également conçues pour être personnalisables.
Dans notre prochain test Python, nous utiliserons un Modèle d'invite. Les modèles de langage prennent du texte en entrée — ce texte est communément appelé une invite. En règle générale, il ne s'agit pas simplement d'une chaîne codée en dur, mais plutôt d'une combinaison d'un modèle, de quelques exemples et d'une entrée utilisateur. LangChain fournit plusieurs classes et fonctions pour faciliter la construction et l'utilisation des invites. Voyons comment nous pouvons le faire aussi.
Créez un nouveau fichier python et appelez-le ma_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])Nous avons importé de LangChain la classe Prompt Template and Chain et GPT4All llm pour pouvoir interagir directement avec notre modèle GPT.
Ensuite, après avoir défini notre chemin llm (comme nous l'avons fait auparavant), nous instancions les gestionnaires de rappel afin de pouvoir attraper les réponses à notre requête.
Pour créer un modèle, c'est très simple : en suivant les tutoriel de documentation nous pouvons utiliser quelque chose comme ça…
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])Les modèle variable est une chaîne multiligne qui contient notre structure d'interaction avec le modèle : entre accolades, nous insérons les variables externes au modèle, dans notre scénario, c'est notre question.
Puisqu'il s'agit d'une variable, vous pouvez décider s'il s'agit d'une question codée en dur ou d'une question saisie par l'utilisateur : voici les deux exemples.
# Hardcoded question
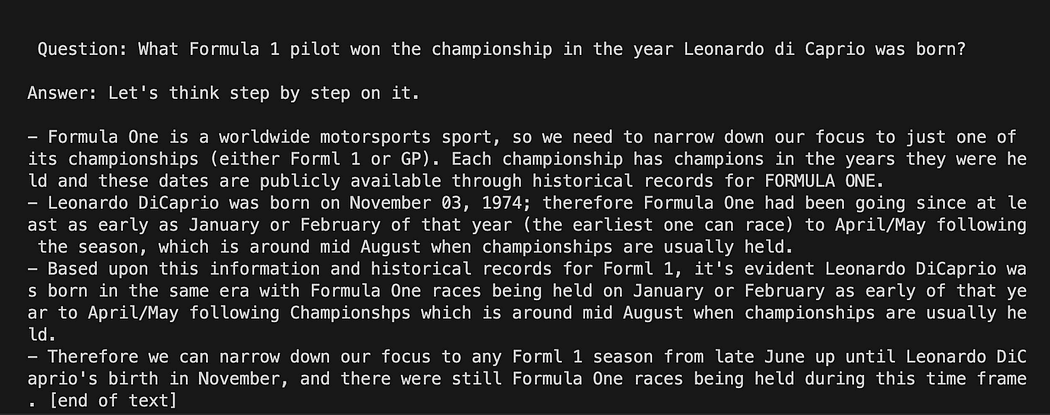
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")Pour notre test, nous commenterons la saisie de l'utilisateur. Il ne nous reste plus qu'à relier notre modèle, la question et le modèle de langage.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)N'oubliez pas de vérifier que votre environnement virtuel est toujours activé et exécutez la commande :
python3 my_langchain.pyVous pouvez obtenir un résultat différent du mien. Ce qui est étonnant, c'est que vous pouvez voir tout le raisonnement suivi par GPT4All essayant d'obtenir une réponse pour vous. Ajuster la question peut également vous donner de meilleurs résultats.
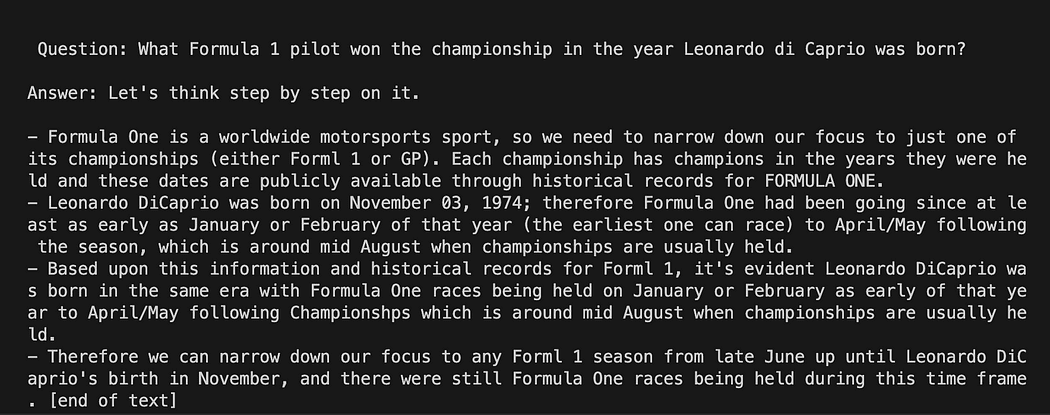
Langchain avec modèle d'invite sur GPT4All
Ici, nous commençons la partie étonnante, car nous allons parler de nos documents en utilisant GPT4All comme un chatbot qui répond à nos questions.
La séquence d'étapes, se référant à Workflow du QnA avec GPT4All, consiste à charger nos fichiers pdf, à les transformer en morceaux. Après cela, nous aurons besoin d'un Vector Store pour nos intégrations. Nous devons alimenter nos documents fragmentés dans un magasin de vecteurs pour la récupération d'informations, puis nous les intégrerons avec la recherche de similarité sur cette base de données comme contexte pour notre requête LLM.
Pour cela nous allons utiliser FAISS directement depuis Langchain bibliothèque. FAISS est une bibliothèque open source de Facebook AI Research, conçue pour trouver rapidement des éléments similaires dans de grandes collections de données de grande dimension. Il propose des méthodes d'indexation et de recherche pour faciliter et accélérer la détection des éléments les plus similaires dans un ensemble de données. C'est particulièrement pratique pour nous car cela simplifie informations de récupération et nous permettent de sauvegarder localement la base de données créée : cela signifie qu'après la première création, elle sera chargée très rapidement pour toute utilisation ultérieure.
Création de l'index vectoriel db
Créez un nouveau fichier et appelez-le mes_connaissances_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeLes premières bibliothèques sont les mêmes que nous utilisions auparavant : en plus, nous utilisons Langchain pour la création de l'index du magasin de vecteurs, le LamaCppIncorporations pour interagir avec notre modèle Alpaca (quantifié à 4 bits et compilé avec la bibliothèque cpp) et le chargeur PDF.
Chargeons également nos LLM avec leurs propres chemins : un pour les intégrations et un pour la génération de texte.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)Pour tester, voyons si nous avons réussi à lire tous les fichiers pfd : la première étape consiste à déclarer 3 fonctions à utiliser sur chaque document. La première consiste à diviser le texte extrait en morceaux, la seconde à créer l'index vectoriel avec les métadonnées (comme les numéros de page, etc.) et la dernière à tester la recherche de similarité (j'expliquerai mieux plus tard).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesNous pouvons maintenant tester la génération d'index pour les documents du docs directory : nous devons y mettre tous nos pdfs. Langchain dispose également d'une méthode pour charger l'intégralité du dossier, quel que soit le type de fichier : comme le post-traitement est compliqué, je l'aborderai dans le prochain article sur les modèles LaMini.

mon répertoire docs contient 4 fichiers pdf
Nous appliquerons nos fonctions au premier document de la liste
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)Dans les premières lignes, nous utilisons la bibliothèque os pour obtenir le liste des fichiers pdf dans le répertoire docs. Nous chargeons ensuite le premier document (liste_doc[0]) du dossier docs avec Langchain, divisé en morceaux, puis nous créons la base de données vectorielle avec le Lama encastrements.
Comme vous l'avez vu, nous utilisons le méthode pyPDF. Celui-ci est un peu plus long à utiliser, puisqu'il faut charger les fichiers un par un, mais charger le PDF en utilisant pypdf dans un tableau de documents vous permet d'avoir un tableau où chaque document contient le contenu de la page et les métadonnées avec page nombre. C'est vraiment pratique quand on veut connaître les sources du contexte qu'on va donner à GPT4All avec notre requête. Voici l'exemple du readthedocs :
Capture d'écran de Documentation Langchain
Nous pouvons exécuter le fichier python avec la commande depuis le terminal :
python3 my_knowledge_qna.pyAprès le chargement du modèle pour les intégrations, vous verrez les jetons à l'œuvre pour l'indexation : ne paniquez pas car cela prendra du temps, surtout si vous ne tournez que sur CPU, comme moi (cela a pris 8 minutes).
Achèvement du premier vecteur db
Comme je l'expliquais, la méthode pyPDF est plus lente mais nous donne des données supplémentaires pour la recherche de similarité. Pour parcourir tous nos fichiers, nous utiliserons une méthode pratique de FAISS qui nous permet de FUSIONNER différentes bases de données ensemble. Ce que nous faisons maintenant, c'est que nous utilisons le code ci-dessus pour générer la première db (nous l'appellerons db0) et avec une boucle for nous créons l'index du fichier suivant dans la liste et le fusionnons immédiatement avec db0.
Voici le code : notez que j'ai ajouté des journaux pour vous donner l'état de la progression à l'aide de dateheure.dateheure.maintenant() et imprimer le delta de l'heure de fin et de l'heure de début pour calculer la durée de l'opération (vous pouvez le supprimer si vous ne l'aimez pas).
Les instructions de fusion sont comme ceci
# merge dbi with the existing db0
db0.merge_from(dbi)L'une des dernières instructions est de sauvegarder notre base de données localement : la génération entière peut prendre même des heures (selon le nombre de documents que vous avez) donc c'est vraiment bien que nous n'ayons à le faire qu'une seule fois !
# Save the databasae locally
db0.save_local("my_faiss_index")Voici le code complet. Nous en commenterons de nombreuses parties lorsque nous interagissons avec GPT4All en chargeant l'index directement à partir de notre dossier.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  L'exécution du fichier python a pris 22 minutes
L'exécution du fichier python a pris 22 minutes
Posez des questions à GPT4All sur vos documents
Maintenant nous sommes ici. Nous avons notre index, nous pouvons le charger et avec un modèle d'invite, nous pouvons demander à GPT4All de répondre à nos questions. Nous commençons par une question codée en dur, puis nous parcourrons nos questions d'entrée.
Mettez le code suivant dans un fichier python db_loading.py et exécutez-le avec la commande du terminal python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])Le texte imprimé est la liste des 3 sources qui correspond le mieux à la requête, nous donnant également le nom du document et le numéro de page.
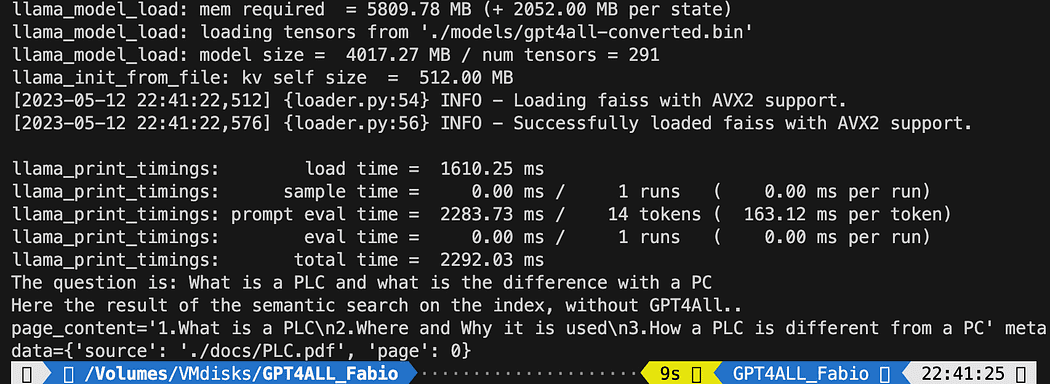
Résultats de la recherche sémantique exécutant le fichier db_loading.py
Nous pouvons maintenant utiliser la recherche de similarité comme contexte pour notre requête à l'aide du modèle d'invite. Après les 3 fonctions, remplacez simplement tout le code par ce qui suit :
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))Après l'exécution, vous obtiendrez un résultat comme celui-ci (mais peut varier). Incroyable non !?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.Si vous souhaitez qu'une question saisie par l'utilisateur remplace la ligne
question = "What is a PLC and what is the difference with a PC"avec quelque chose comme ça :
question = input("Your question: ")Il est temps pour vous d'expérimenter. Posez différentes questions sur tous les sujets liés à vos documents, et voyez les résultats. Il y a une grande marge d'amélioration, certainement sur l'invite et le modèle : vous pouvez jeter un œil ici pour quelques inspirations. Mais Langchain la documentation est vraiment incroyable (je pourrais la suivre !!).
Vous pouvez suivre le code de l'article ou le vérifier sur mon dépôt github.
Fabio Matricardi un éducateur, un enseignant, un ingénieur et un passionné d'apprentissage. Il enseigne depuis 15 ans à de jeunes étudiants, et maintenant il forme de nouveaux employés chez Key Solution Srl. Il a commencé ma carrière en tant qu'ingénieur en automatisation industrielle en 2010. Passionné de programmation depuis son adolescence, il a découvert la beauté des logiciels de construction et des interfaces homme-machine pour donner vie à quelque chose. L'enseignement et le coaching font partie de ma routine quotidienne, ainsi que d'étudier et d'apprendre à être un leader passionné avec des compétences de gestion à jour. Rejoignez-moi dans le voyage vers une meilleure conception, une intégration de système prédictive utilisant l'apprentissage automatique et l'intelligence artificielle tout au long du cycle de vie de l'ingénierie.
ORIGINALE. Republié avec permission.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Financement EVM. Interface unifiée pour la finance décentralisée. Accéder ici.
- Groupe de médias quantiques. IR/PR amplifié. Accéder ici.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 15 ans
- 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- capacité
- Capable
- Qui sommes-nous
- au dessus de
- accomplir
- Agis
- activé
- ajoutée
- ajout
- Supplémentaire
- Avancée
- affectant
- Après
- AI
- recherche ai
- Tous
- permettre
- permet
- déjà
- aussi
- am
- incroyable
- an
- selon une analyse de l’Université de Princeton
- ainsi que les
- répondre
- tous
- api
- applications
- Appliquer
- architecture
- SONT
- tableau
- article
- sur notre blog
- artificiel
- intelligence artificielle
- AS
- associé
- At
- acoustique
- Automatisation
- automatiquement
- Automation
- disponibles
- éviter
- base
- basé
- BE
- Beauté
- car
- était
- before
- va
- ci-dessous
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Au-delà
- Big
- BIN
- propriétés de liant
- Bit
- né
- brièvement
- apporter
- construire
- Développement
- intégré
- Bus
- mais
- by
- calculer
- Appelez-nous
- appelé
- Appels
- CAN
- ne peut pas
- Compétences
- captures
- Carrière
- porter
- maisons
- Attraper
- CD
- certaines
- Assurément
- chaîne
- Chaînes
- championnat
- Chatbot
- ChatGPT
- vérifier
- la chimie
- classe
- les classes
- cliquez
- entraînement
- code
- codes
- recueillir
- collection
- collections
- combinaison
- commentaire
- communément
- communiquer
- Communication
- compatible
- complet
- Complété
- achèvement
- complexe
- compliqué
- composants électriques
- ordinateur
- ordinateurs
- NOUS CONTACTER
- connecté
- la construction
- consommateur
- contient
- contenu
- contexte
- des bactéries
- contrôleur
- contrôles
- Pratique
- converti
- pourriez
- couverture
- Processeur
- engendrent
- créée
- crée des
- La création
- création
- Conception
- critique
- personnalisables
- Tous les jours
- données
- Base de données
- bases de données
- Date
- datetime
- décider
- Réglage par défaut
- défini
- Delta
- Dépendance
- Selon
- dépend
- déployer
- décrit
- Conception
- un
- voulu
- développement
- dispositif
- Compatibles
- DID
- différence
- différent
- digestible
- numérique
- directement
- découvrez
- découvert
- do
- document
- Documentation
- INSTITUTIONNELS
- doesn
- fait
- Ne pas
- DOT
- download
- conduite
- pendant
- chacun
- plus facilement
- même
- Easy
- risque numérique
- Écosystèmes
- effort
- enchâsser
- intégré
- enrobage
- employés
- permettre
- fin
- ingénieur
- ENGINEERING
- Entrer
- passionné
- Tout
- Environment
- erreur
- notamment
- etc
- Ether (ETH)
- Pourtant, la
- peut
- exactement
- exemple
- exemples
- exécution
- existant
- expérience
- Expliquer
- expliqué
- expliquant
- externe
- Visage
- facilite
- RAPIDE
- plus rapide
- Déposez votre dernière attestation
- Fichiers
- Trouvez
- fin
- Prénom
- s'adapter
- flux
- suivre
- suivi
- Abonnement
- suit
- Pour
- formulaire
- le format
- formule
- Formule 1
- Framework
- de
- fonction
- fonctions
- plus
- générer
- générateur
- génération
- obtenez
- GitHub
- Donner
- donné
- donne
- Don
- aller
- Bien
- GPU
- grade
- Maniabilité
- arrive
- Dur
- Matériel
- Vous avez
- he
- lourd
- aide
- ici
- caché
- Haute
- augmentation
- HEURES
- Comment
- How To
- HTML
- http
- HTTPS
- humain
- i
- ICS
- if
- satellite
- immédiatement
- Mettre en oeuvre
- importer
- important
- amélioration
- in
- comprendre
- indice
- index
- individus
- industriel
- l'automatisation industrielle
- secteurs
- d'information
- contribution
- entrée sortie
- entrées
- installer
- installation
- instance
- Des instructions
- l'intégration
- Intelligence
- prévu
- interagir
- l'interaction
- Interfaces
- interfaces
- Internet
- développement
- Introduction
- isolé
- seul
- IT
- articles
- itération
- SES
- Emploi
- rejoindre
- chemin
- juste
- KDnuggetsGenericName
- ACTIVITES
- Savoir
- spécialisées
- langue
- gros
- Nom de famille
- plus tard
- leader
- apprentissage
- Niveau
- bibliothèques
- Bibliothèque
- VIE
- vos produits
- comme
- lignes
- LINK
- linux
- Liste
- peu
- charge
- chargeur
- chargement
- locales
- localement
- logique
- Location
- plus long
- Style
- Lot
- mac
- click
- machine learning
- machinerie
- Entrée
- principalement
- maintenir
- a prendre une
- gérés
- gestion
- manager
- Gestionnaires
- fabrication
- de nombreuses
- Mai..
- sens
- veux dire
- Mémoire
- aller
- fusion
- Métadonnées
- méthode
- méthodes
- l'esprit
- minutes
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- (en fait, presque toutes)
- plusieurs
- must
- my
- prénom
- indigène
- Besoin
- réseaux
- Nouveauté
- next
- maintenant
- nombre
- numéros
- objet
- of
- Offres Speciales
- on
- une fois
- ONE
- en ligne
- uniquement
- open source
- opération
- Opérations
- or
- de commander
- organisations
- OS
- Autre
- nos
- ande
- sortie
- plus de
- propre
- paquet
- Forfaits
- page
- Parallèle
- partie
- particulier
- particulièrement
- pass
- passionné
- chemin
- PC
- Personnes
- effectuer
- autorisation
- personnel
- image
- pièce
- pilote
- plantes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- PLC
- veuillez cliquer
- fiche
- ports
- position
- Post
- défaillances
- power
- centrales
- alimenté
- solide
- pré
- empêcher
- Imprimé
- impression
- d'ouvrabilité
- processus
- traité
- les process
- Programme
- programmé
- Programmation
- Progrès
- Projet
- projets
- protocoles
- fournit
- des fins
- mettre
- Python
- qualité
- question
- fréquemment posées
- vite.
- plutôt
- Lire
- solutions
- vraiment
- recevoir
- récemment
- visée
- se réfère
- Indépendamment
- registres
- en relation
- fiabilité
- compter
- rappeler
- supprimez
- répété
- remplacer
- rapport
- dépôt
- représentation
- conditions
- Exigences
- a besoin
- un article
- Resources
- réponse
- réponses
- résultat
- Résultats
- retourner
- Salle
- Courir
- pour le running
- s
- Sécurité
- même
- Épargnez
- économie
- scénario
- Rechercher
- recherche
- Deuxièmement
- Section
- sécurisé
- sur le lien
- capteur
- phrase
- Séquence
- en série
- mise
- installation
- plusieurs
- coup
- devrait
- montré
- similaires
- étapes
- simplement
- depuis
- unique
- compétences
- petit
- So
- Logiciels
- sur mesure
- quelques
- quelque chose
- Identifier
- Sources
- spécialisé
- spécialement
- groupe de neurones
- spécifié
- scission
- Spot
- Commencer
- j'ai commencé
- Commencez
- Déclaration
- Statut
- étapes
- Étapes
- Encore
- Boutique
- Chaîne
- structure
- Étudiante
- Étudier
- tel
- combustion propre
- Prenez
- discutons-en
- tâches
- professeur
- Enseignement
- adolescent
- modèle
- terminal
- tester
- Essai
- Essais
- génération de texte
- que
- qui
- Les
- leur
- Les
- puis
- Là.
- Ces
- l'ont
- penser
- this
- pensée
- Avec
- tout au long de
- fiable
- à
- ensemble
- Tokens
- demain
- trop
- a
- sujet
- Les sujets
- vers
- Train
- Essai
- deux
- type
- débutante
- typiquement
- a actualisé
- Actualités
- sur
- us
- Utilisation
- usb
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- utilisateurs
- en utilisant
- d'habitude
- utilisé
- divers
- vérifier
- version
- très
- via
- Salle de conférence virtuelle
- W3
- attendez
- souhaitez
- était
- Façon..
- façons
- we
- Site Web
- WELL
- Quoi
- Qu’est ce qu'
- Jante
- quand
- qui
- WHO
- why
- largement
- sera
- fenêtres
- Utilisateurs Windows
- comprenant
- dans les
- sans
- A gagné
- activités principales
- de travail
- an
- années
- you
- jeune
- Votre
- zéphyrnet










