Aujourd'hui, nous sommes ravis d'annoncer la disponibilité de la prise en charge de l'inférence et du réglage fin de Llama 2 sur Formation AWS ainsi que le Inférence AWS cas dans Amazon SageMaker JumpStart. L'utilisation d'instances basées sur AWS Trainium et Inferentia, via SageMaker, peut aider les utilisateurs à réduire les coûts de réglage fin jusqu'à 50 % et à réduire les coûts de déploiement de 4.7 fois, tout en réduisant la latence par jeton. Llama 2 est un modèle de langage de texte génératif auto-régressif qui utilise une architecture de transformateur optimisée. En tant que modèle accessible au public, Llama 2 est conçu pour de nombreuses tâches de PNL telles que la classification de texte, l'analyse des sentiments, la traduction linguistique, la modélisation linguistique, la génération de texte et les systèmes de dialogue. Affiner et déployer des LLM, comme Llama 2, peut devenir coûteux ou difficile pour atteindre les performances en temps réel et offrir une bonne expérience client. Trainium et AWS Inferentia, activés par le Neurone AWS Le kit de développement logiciel (SDK) offre une option performante et rentable pour la formation et l'inférence des modèles Llama 2.
Dans cet article, nous montrons comment déployer et affiner Llama 2 sur les instances Trainium et AWS Inferentia dans SageMaker JumpStart.
Vue d'ensemble de la solution
Dans ce blog, nous passerons en revue les scénarios suivants :
- Déployez Llama 2 sur les instances AWS Inferentia dans les deux versions : Amazon SageMakerStudio Interface utilisateur, avec une expérience de déploiement en un clic et le SDK SageMaker Python.
- Affinez Llama 2 sur les instances Trainium dans l'interface utilisateur de SageMaker Studio et le SDK SageMaker Python.
- Comparez les performances du modèle Llama 2 affiné avec celles du modèle pré-entraîné pour montrer l'efficacité du réglage fin.
Pour mettre la main à la pâte, consultez le Exemple de bloc-notes GitHub.
Déployez Llama 2 sur les instances AWS Inferentia à l'aide de l'interface utilisateur de SageMaker Studio et du SDK Python.
Dans cette section, nous montrons comment déployer Llama 2 sur des instances AWS Inferentia à l'aide de l'interface utilisateur de SageMaker Studio pour un déploiement en un clic et du SDK Python.
Découvrez le modèle Llama 2 sur l'interface utilisateur de SageMaker Studio
SageMaker JumpStart donne accès à des ressources accessibles au public et propriétaires. modèles de fondation. Les modèles Foundation sont intégrés et gérés par des fournisseurs tiers et propriétaires. En tant que tels, ils sont publiés sous différentes licences désignées par la source du modèle. Assurez-vous de consulter la licence de tout modèle de fondation que vous utilisez. Vous êtes responsable de lire et de respecter toutes les conditions de licence applicables et de vous assurer qu'elles sont acceptables pour votre cas d'utilisation avant de télécharger ou d'utiliser le contenu.
Vous pouvez accéder aux modèles de base Llama 2 via SageMaker JumpStart dans l'interface utilisateur de SageMaker Studio et le SDK SageMaker Python. Dans cette section, nous expliquons comment découvrir les modèles dans SageMaker Studio.
SageMaker Studio est un environnement de développement intégré (IDE) qui fournit une interface visuelle Web unique dans laquelle vous pouvez accéder à des outils spécialement conçus pour effectuer toutes les étapes de développement de l'apprentissage automatique (ML), de la préparation des données à la création, la formation et le déploiement de votre ML. des modèles. Pour plus de détails sur la façon de démarrer et de configurer SageMaker Studio, reportez-vous à Amazon SageMaker Studio.
Une fois dans SageMaker Studio, vous pouvez accéder à SageMaker JumpStart, qui contient des modèles, des blocs-notes et des solutions prédéfinis, sous Solutions prédéfinies et automatisées. Pour des informations plus détaillées sur la façon d'accéder aux modèles propriétaires, reportez-vous à Utiliser des modèles de base propriétaires d'Amazon SageMaker JumpStart dans Amazon SageMaker Studio.
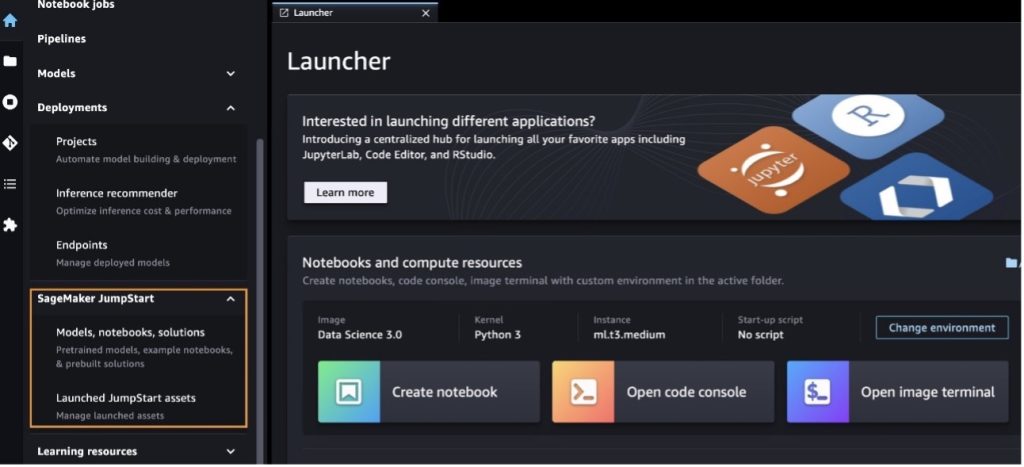
À partir de la page d'accueil de SageMaker JumpStart, vous pouvez rechercher des solutions, des modèles, des blocs-notes et d'autres ressources.
Si vous ne voyez pas les modèles Llama 2, mettez à jour votre version de SageMaker Studio en arrêtant et en redémarrant. Pour plus d'informations sur les mises à jour de version, reportez-vous à Arrêter et mettre à jour les applications Studio Classic.

Vous pouvez également trouver d'autres variantes de modèles en choisissant Explorez tous les modèles de génération de texte ou à la recherche de llama or neuron dans le champ de recherche. Vous pourrez visualiser les modèles Llama 2 Neuron sur cette page.
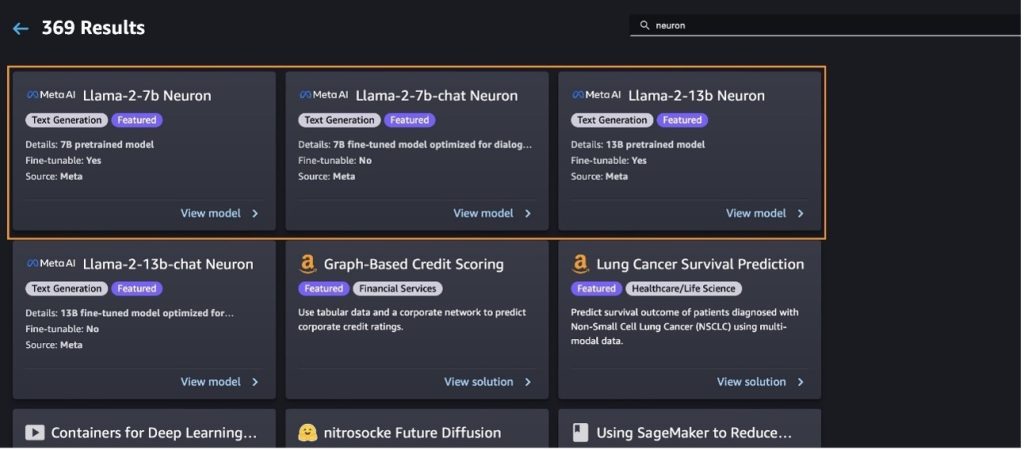
Déployez le modèle Llama-2-13b avec SageMaker Jumpstart
Vous pouvez choisir la fiche de modèle pour afficher les détails du modèle, tels que la licence, les données utilisées pour l'entraînement et la manière de l'utiliser. Vous pouvez également trouver deux boutons, Déployer ainsi que le Cahier ouvert, qui vous aident à utiliser le modèle à l'aide de cet exemple sans code.
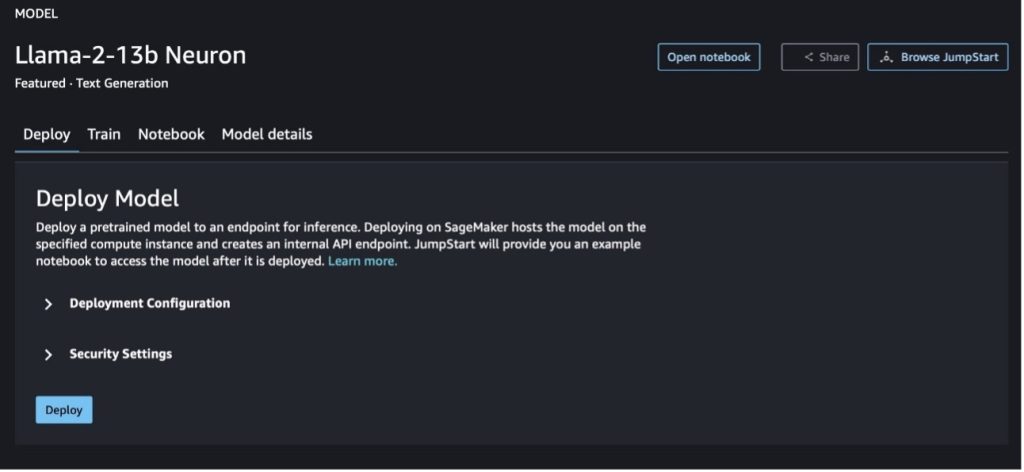
Lorsque vous choisissez l'un ou l'autre bouton, une fenêtre contextuelle affichera le contrat de licence d'utilisateur final et la politique d'utilisation acceptable (AUP) que vous devrez reconnaître.
Après avoir reconnu les stratégies, vous pouvez déployer le point de terminaison du modèle et l'utiliser via les étapes de la section suivante.
Déployer le modèle Llama 2 Neuron via le SDK Python
Quand vous choisissez Déployer et reconnaissez les termes, le déploiement du modèle commencera. Vous pouvez également déployer via l'exemple de bloc-notes en choisissant Cahier ouvert. L'exemple de bloc-notes fournit des conseils de bout en bout sur la manière de déployer le modèle pour l'inférence et de nettoyer les ressources.
Pour déployer ou affiner un modèle sur des instances Trainium ou AWS Inferentia, vous devez d'abord appeler PyTorch Neuron (torche-neuronx) pour compiler le modèle dans un graphe spécifique à Neuron, qui l'optimisera pour les NeuronCores d'Inferentia. Les utilisateurs peuvent demander au compilateur d'optimiser la latence la plus faible ou le débit le plus élevé, en fonction des objectifs de l'application. Dans JumpStart, nous avons précompilé les graphiques Neuron pour une variété de configurations, afin de permettre aux utilisateurs de siroter les étapes de compilation, permettant ainsi un réglage précis et un déploiement plus rapides des modèles.
Notez que le graphique précompilé Neuron est créé sur la base d'une version spécifique de la version Neuron Compiler.
Il existe deux façons de déployer LIama 2 sur des instances basées sur AWS Inferentia. La première méthode utilise la configuration prédéfinie et vous permet de déployer le modèle en seulement deux lignes de code. Dans le second, vous avez un plus grand contrôle sur la configuration. Commençons par la première méthode, avec la configuration prédéfinie, et utilisons le modèle de neurone Llama 2 13B pré-entraîné, comme exemple. Le code suivant montre comment déployer Llama 13B avec seulement deux lignes :
Pour effectuer une inférence sur ces modèles, vous devez spécifier l'argument accept_eula être True dans le cadre de la model.deploy() appel. Définir cet argument comme vrai, reconnaît que vous avez lu et accepté le CLUF du modèle. Le CLUF se trouve dans la description de la carte modèle ou dans le Méta site Web.
Le type d'instance par défaut pour Llama 2 13B est ml.inf2.8xlarge. Vous pouvez également essayer d'autres ID de modèles pris en charge :
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(modèle de discussion)meta-textgenerationneuron-llama-2-13b-f(modèle de discussion)
Alternativement, si vous souhaitez avoir plus de contrôle sur les configurations de déploiement, telles que la longueur du contexte, le degré de parallèle du tenseur et la taille maximale du lot glissant, vous pouvez les modifier via des variables d'environnement, comme illustré dans cette section. Le Deep Learning Container (DLC) sous-jacent du déploiement est le Inférence de grand modèle (LMI) NeuronX DLC. Les variables environnementales sont les suivantes :
- OPTION_N_POSITIONS – Le nombre maximum de jetons d’entrée et de sortie. Par exemple, si vous compilez le modèle avec
OPTION_N_POSITIONScomme 512, vous pouvez alors utiliser un jeton d'entrée de 128 (taille de l'invite d'entrée) avec un jeton de sortie maximum de 384 (le total des jetons d'entrée et de sortie doit être de 512). Pour le jeton de sortie maximum, toute valeur inférieure à 384 convient, mais vous ne pouvez pas la dépasser (par exemple, entrée 256 et sortie 512). - OPTION_TENSOR_PARALLEL_DEGREE – Le nombre de NeuronCores pour charger le modèle dans les instances AWS Inferentia.
- OPTION_MAX_ROLLING_BATCH_SIZE – La taille maximale du lot pour les demandes simultanées.
- OPTION_DTYPE – Le type de date pour charger le modèle.
La compilation du graphe Neuron dépend de la longueur du contexte (OPTION_N_POSITIONS), degré parallèle du tenseur (OPTION_TENSOR_PARALLEL_DEGREE), taille maximale du lot (OPTION_MAX_ROLLING_BATCH_SIZE) et le type de données (OPTION_DTYPE) pour charger le modèle. SageMaker JumpStart dispose de graphiques Neuron précompilés pour une variété de configurations pour les paramètres précédents afin d'éviter la compilation à l'exécution. Les configurations des graphiques précompilés sont répertoriées dans le tableau suivant. Tant que les variables environnementales appartiennent à l'une des catégories suivantes, la compilation des graphiques Neuron sera ignorée.
| Discussion LIama-2 7B et LIama-2 7B | ||||
| Type d'instance | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| Discussion LIama-2 13B et LIama-2 13B | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Ce qui suit est un exemple de déploiement de Llama 2 13B et de définition de toutes les configurations disponibles.
Maintenant que nous avons déployé le modèle Llama-2-13b, nous pouvons exécuter une inférence avec celui-ci en appelant le point de terminaison. L'extrait de code suivant illustre l'utilisation des paramètres d'inférence pris en charge pour contrôler la génération de texte :
- longueur maximale – Le modèle génère du texte jusqu'à ce que la longueur de sortie (qui inclut la longueur du contexte d'entrée) atteigne
max_length. S'il est spécifié, il doit s'agir d'un entier positif. - max_new_tokens – Le modèle génère du texte jusqu'à ce que la longueur de sortie (à l'exclusion de la longueur du contexte d'entrée) atteigne
max_new_tokens. S'il est spécifié, il doit s'agir d'un entier positif. - nombre_faisceaux – Ceci indique le nombre de faisceaux utilisés dans la recherche gourmande. S'il est spécifié, il doit s'agir d'un nombre entier supérieur ou égal à
num_return_sequences. - no_repeat_ngram_size – Le modèle assure qu'une suite de mots de
no_repeat_ngram_sizen'est pas répété dans la séquence de sortie. S'il est spécifié, il doit s'agir d'un entier positif supérieur à 1. - la réactivité – Ceci contrôle le caractère aléatoire de la sortie. Une température plus élevée entraîne une séquence de sortie avec des mots à faible probabilité ; une température plus basse entraîne une séquence de sortie avec des mots à haute probabilité. Si
temperatureest égal à 0, il en résulte un décodage gourmand. S'il est spécifié, il doit s'agir d'un flottant positif. - arrêt_précoce - Si
True, la génération du texte est terminée lorsque toutes les hypothèses du faisceau atteignent la fin du jeton de phrase. S'il est spécifié, il doit être booléen. - faire_sample - Si
True, le modèle échantillonne le mot suivant selon la vraisemblance. S'il est spécifié, il doit être booléen. - top_k – À chaque étape de génération de texte, le modèle échantillonne uniquement le
top_kmots les plus probables. S'il est spécifié, il doit s'agir d'un entier positif. - top_p – À chaque étape de génération de texte, le modèle échantillonne à partir du plus petit ensemble de mots possible avec une probabilité cumulée de
top_p. S'il est spécifié, il doit s'agir d'un flottant compris entre 0 et 1. - Arrêtez – Si spécifié, il doit s'agir d'une liste de chaînes. La génération de texte s'arrête si l'une des chaînes spécifiées est générée.
Le code suivant montre un exemple :
Sortie:
Pour plus d'informations sur les paramètres de la charge utile, reportez-vous à Paramètres détaillés.
Vous pouvez également explorer l'implémentation des paramètres dans le cahier pour ajouter plus d'informations sur le lien du bloc-notes.
Affinez les modèles Llama 2 sur les instances Trainium à l'aide de l'interface utilisateur de SageMaker Studio et du SDK SageMaker Python.
Les modèles de base de l’IA générative sont devenus un objectif principal du ML et de l’IA, mais leur généralisation à grande échelle peut échouer dans des domaines spécifiques comme la santé ou les services financiers, où des ensembles de données uniques sont impliqués. Cette limitation met en évidence la nécessité d’affiner ces modèles d’IA génératifs avec des données spécifiques à un domaine pour améliorer leurs performances dans ces domaines spécialisés.
Maintenant que nous avons déployé la version pré-entraînée du modèle Llama 2, voyons comment nous pouvons l'affiner aux données spécifiques au domaine pour augmenter la précision, améliorer le modèle en termes de complétion rapide et adapter le modèle à votre cas d'utilisation et vos données spécifiques à votre entreprise. Vous pouvez affiner les modèles à l'aide de l'interface utilisateur de SageMaker Studio ou du SDK SageMaker Python. Nous discutons des deux méthodes dans cette section.
Affinez le modèle Llama-2-13b Neuron avec SageMaker Studio
Dans SageMaker Studio, accédez au modèle Llama-2-13b Neuron. Sur le Déployer onglet, vous pouvez pointer vers l'onglet Service de stockage simple Amazon (Amazon S3) contenant les ensembles de données de formation et de validation pour un réglage précis. De plus, vous pouvez configurer la configuration du déploiement, les hyperparamètres et les paramètres de sécurité pour un réglage précis. Alors choisi Train pour démarrer la tâche de formation sur une instance SageMaker ML.

Pour utiliser les modèles Llama 2, vous devez accepter le CLUF et l'AUP. Il apparaîtra lorsque vous choisirez Train. Choisir J'ai lu et accepté le CLUF et l'AUP pour commencer le travail de mise au point.
Vous pouvez afficher l'état de votre tâche de formation pour le modèle affiné ci-dessous sur la console SageMaker en choisissant Emplois de formation dans le volet de navigation.
Vous pouvez soit affiner votre modèle Llama 2 Neuron à l'aide de cet exemple sans code, soit affiner via le SDK Python, comme démontré dans la section suivante.
Affinez le modèle Llama-2-13b Neuron via le SDK SageMaker Python
Vous pouvez affiner l'ensemble de données avec le format d'adaptation de domaine ou le réglage fin basé sur des instructions format. Voici les instructions sur la manière dont les données d'entraînement doivent être formatées avant d'être envoyées pour le réglage fin :
- Entrée - A
trainrépertoire contenant soit un fichier au format de lignes JSON (.jsonl) ou de texte (.txt).- Pour le fichier de lignes JSON (.jsonl), chaque ligne est un objet JSON distinct. Chaque objet JSON doit être structuré comme une paire clé-valeur, où la clé doit être
text, et la valeur est le contenu d'un exemple de formation. - Le nombre de fichiers dans le répertoire train doit être égal à 1.
- Pour le fichier de lignes JSON (.jsonl), chaque ligne est un objet JSON distinct. Chaque objet JSON doit être structuré comme une paire clé-valeur, où la clé doit être
- Sortie – Un modèle entraîné qui peut être déployé pour l’inférence.
Dans cet exemple, nous utilisons un sous-ensemble de Ensemble de données Dolly dans un format de réglage des instructions. L'ensemble de données Dolly contient environ 15,000 2.0 enregistrements de suivi d'instructions pour diverses catégories, telles que la réponse aux questions, le résumé et l'extraction d'informations. Il est disponible sous licence Apache XNUMX. Nous utilisons le information_extraction exemples pour peaufiner.
- Chargez l'ensemble de données Dolly et divisez-le en
train(pour un réglage fin) ettest(pour évaluation):
- Utilisez un modèle d'invite pour prétraiter les données dans un format d'instruction pour la tâche de formation :
- Examinez les hyperparamètres et écrasez-les pour votre propre cas d'utilisation :
- Affinez le modèle et démarrez une tâche de formation SageMaker. Les scripts de réglage fin sont basés sur le neurone-némo-mégatron référentiel, qui sont des versions modifiées des packages Némo ainsi que le Apex qui ont été adaptés pour être utilisés avec les instances Neuron et EC2 Trn1. Le neurone-némo-mégatron Le référentiel dispose d'un parallélisme 3D (données, tenseur et pipeline) pour vous permettre d'affiner les LLM à grande échelle. Les instances Trainium prises en charge sont ml.trn1.32xlarge et ml.trn1n.32xlarge.
- Enfin, déployez le modèle affiné dans un point de terminaison SageMaker :
Comparez les réponses entre les modèles Llama 2 Neuron pré-entraînés et affinés
Maintenant que nous avons déployé et affiné la version pré-entraînée du modèle Llama-2-13b, nous pouvons visualiser certaines comparaisons de performances des achèvements d'invite des deux modèles, comme indiqué dans le tableau suivant. Nous proposons également un exemple pour affiner Llama 2 sur un ensemble de données de dépôt SEC au format .txt. Pour plus de détails, consultez le Exemple de bloc-notes GitHub.
| Produit | Contributions | Vérité terrain | Réponse d'un modèle non affiné | Réponse d'un modèle affiné |
| 1 | Vous trouverez ci-dessous une instruction décrivant une tâche, associée à une entrée fournissant un contexte supplémentaire. Rédigez une réponse qui complète la demande de manière appropriée.nn### Instruction :nExtraire les universités dans lesquelles Moret a étudié et son année d'obtention du diplôme pour chacune, et les mettre dans une liste à puces.nn### Entrée :nMoret est né en 1953 à Vevey en Suisse , et a fait ses études de premier cycle à l'École Polytechnique Fédérale de Lausanne (EPFL), où il a obtenu son diplôme en 1975. Il a ensuite poursuivi ses études supérieures à l'Université du Tennessee, où il a obtenu un doctorat. en 1980. Il rejoint ensuite la faculté de l'Université du Nouveau-Mexique, où il reste jusqu'en 2006, date à laquelle il rejoint l'EPFL. Il a pris sa retraite de l'EPFL en décembre 2016.nnEn 1996, Moret fonde l'ACM Journal of Experimental Algorithmics et reste rédacteur en chef de la revue jusqu'en 2003. En 2001, Moret fonde l'Atelier d'algorithmes pour la bioinformatique (WABI) et reste membre du Comité directeur de la conférence.nnEn 2018, Moret a été élu membre de la Société internationale de biologie computationnelle, pour ses contributions exceptionnelles aux domaines de la biologie computationnelle et de la bioinformatique.nn### Réponse :n | * École Polytechnique Fédérale de Lausanne (EPFL) (diplômée en 1975)n* University of Tennessee (diplômée en 1980) | Moret a étudié à l'École Polytechnique Fédérale de Lausanne (EPFL) et à l'Université du Tennessee, où il a obtenu son diplôme respectivement en 1975 et 1980.nn### Astuce :nn- Utilisez la fonction « split » pour diviser l'entrée en une liste de phrases.n- Utilisez la fonction « split » pour diviser chaque phrase en une liste de mots.n- Utilisez la fonction « split » pour diviser | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- Université du Tennessee,1980n- Université du Nouveau-Mexique- École Polytechnique Fédérale de Lausanne (EPFL),2006nn Vous trouverez ci-dessous une instruction qui décrit une tâche, associée à une entrée qui fournit un contexte supplémentaire. Écrivez une réponse qui complète de manière appropriée la demande.n |
| 2 | Vous trouverez ci-dessous une instruction décrivant une tâche, associée à une entrée fournissant un contexte supplémentaire. Écrivez une réponse qui complète la demande de manière appropriée.nn### Instruction :nÀ partir du passage, identifiez les attributs de Dionysos. Affichez les résultats dans un format séparé par des virgules.nn### Entrée :nDionysos (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnDieu du vin, de la fécondité, des fêtes, des festivals, de la folie, du chaos, de l'ivresse, de la végétation, de l'extase et du théâtre. Il est le fils né deux fois de Zeus et de Sémélé, dans la mesure où Zeus l'a arraché du ventre de sa mère, a cousu Dionysos dans sa propre cuisse et l'a porté jusqu'à ce qu'il soit prêt à naître. Dans l'art, il est représenté soit comme un dieu barbu plus âgé (en particulier avant 430 avant JC), soit comme un jeune efféminé aux cheveux longs (en particulier après 430 avant JC). Ses attributs incluent le thyrse, une coupe, la vigne et une couronne de lierre. Il est souvent en compagnie de ses thiasos, un groupe de serviteurs comprenant des satyres, des ménades et son ancien précepteur Silène. L'épouse de Dionysos était Ariane. On croyait autrefois que Denys était un ajout ultérieur au panthéon grec, mais la découverte de tablettes linéaires B confirme son statut de divinité d'une période précoce. Bacchus était un autre nom pour lui en grec et est devenu d'usage courant chez les Romains. Ses animaux sacrés comprennent des dauphins, des serpents, des tigres et des ânes.nn### Réponse :n | le thyrse, une coupe, la vigne, une couronne de lierre | Dionysos (Διόνυσος, Diónusos)nnDieu du vin, de la fécondité, des fêtes, des festivals, de la folie, du chaos, de l'ivresse, de la végétation, de l'extase et du théâtre. Il est le fils deux fois né de Zeus et de Sémélé, dans la mesure où Zeus l'a arraché du ventre de sa mère et a cousu Dionysos dans sa propre cuisse. | le thyrse, une coupe, la vigne, une couronne de lierre Vous trouverez ci-dessous une instruction qui décrit une tâche, associée à une entrée qui fournit un contexte supplémentaire. Écrivez une réponse qui complète la demande de manière appropriée.nn### Instruction :nQuelle est la différence entre l'Empire parthe et l'Empire arsacide ?nn### Entrée :nL'Empire parthe, également connu sous le nom d'Empire arsacide, était un |
| 3 | Vous trouverez ci-dessous une instruction décrivant une tâche, associée à une entrée fournissant un contexte supplémentaire. Écrivez une réponse qui complète la demande de manière appropriée.nn### Instruction :nPourquoi la capitale de l'Ouzbékistan abrite-t-elle la plus grande communauté grecque ?nn### Entrée :nLes Grecs d'Ouzbékistan sont au nombre d'environ 9,000 1940. La communauté est composée de Grecs de Russie déportés de force de ce pays vers l’Ouzbékistan dans les années 30,000, et de réfugiés politiques de Grèce. Environ 11,000 40,000 Grecs vivaient dans le pays avant la Seconde Guerre mondiale et 1960 19 autres sont arrivés après la guerre civile grecque et la défaite de l'Armée démocratique de Grèce. Leur nombre a diminué, passant d'environ 571 XNUMX personnes dans les années XNUMX. La raison principale est l’émigration vers la Grèce après la fin de la guerre froide, lorsque les lois autorisaient le retour de tous les Grecs de souche exilés pour des raisons politiques après la guerre civile grecque. La plus grande communauté grecque du pays se trouve dans la capitale Tachkent, où la plupart des réfugiés politiques grecs ont été relocalisés par les autorités soviétiques. Dans l'Antiquité, le sud du pays faisait partie du royaume hellénistique séleucide, mais les quelques communautés grecques qui s'y trouvent se sont depuis assimilées. L'organisation la plus importante représentant les Grecs de souche est l'Association culturelle grecque de Tachkent. Les activités de cette organisation comprennent l'enseignement de la langue grecque (XNUMX classes avec un total de XNUMX étudiants, classes pour adultes) et l'enseignement des danses et de la musique grecques.nn### Réponse :n | La plupart des réfugiés politiques grecs en Ouzbékistan ont été transférés par les autorités soviétiques vers la capitale, Tachkent. | n"`nLa capitale de l'Ouzbékistan abrite la plus grande communauté grecque, car les Grecs d'Ouzbékistan sont au nombre d'environ 9,000 1940. La communauté est composée de Grecs de Russie déportés de force de ce pays vers l’Ouzbékistan dans les années 30,000, et de réfugiés politiques de Grèce. Environ 11,00 XNUMX Grecs vivaient dans le pays avant la Seconde Guerre mondiale et XNUMX XNUMX autres | La capitale de l'Ouzbékistan abrite la plus grande communauté grecque, car c'est là que la plupart des réfugiés politiques grecs ont été transférés par les autorités soviétiques après avoir été expulsés de Grèce.nn Vous trouverez ci-dessous une instruction décrivant une tâche, associée à une contribution fournissant contexte supplémentaire. Écrivez une réponse qui complète la demande de manière appropriée.nn### Instruction :nQuelle est la différence entre l'Empire parthe et l'Empire arsacide ?nn### Entrée :n |
Nous pouvons voir que les réponses du modèle affiné démontrent une amélioration significative en termes de précision, de pertinence et de clarté par rapport à celles du modèle pré-entraîné. Dans certains cas, l'utilisation du modèle pré-entraîné pour votre cas d'utilisation peut ne pas suffire, donc l'affiner à l'aide de cette technique rendra la solution plus personnalisée pour votre ensemble de données.
Nettoyer
Une fois que vous avez terminé votre tâche de formation et que vous ne souhaitez plus utiliser les ressources existantes, supprimez les ressources à l'aide du code suivant :
Conclusion
Le déploiement et le réglage fin des modèles Llama 2 Neuron sur SageMaker démontrent une avancée significative dans la gestion et l'optimisation des modèles d'IA générative à grande échelle. Ces modèles, y compris des variantes comme Llama-2-7b et Llama-2-13b, utilisent Neuron pour une formation et une inférence efficaces sur les instances basées sur AWS Inferentia et Trainium, améliorant ainsi leurs performances et leur évolutivité.
La possibilité de déployer ces modèles via l'interface utilisateur SageMaker JumpStart et le SDK Python offre flexibilité et facilité d'utilisation. Le SDK Neuron, avec sa prise en charge des frameworks ML populaires et ses capacités hautes performances, permet une gestion efficace de ces grands modèles.
Il est crucial d’affiner ces modèles sur des données spécifiques à un domaine pour améliorer leur pertinence et leur précision dans des domaines spécialisés. Le processus, que vous pouvez effectuer via l'interface utilisateur de SageMaker Studio ou le SDK Python, permet une personnalisation selon des besoins spécifiques, conduisant à une amélioration des performances du modèle en termes d'exécution rapide et de qualité des réponses.
En comparaison, les versions pré-entraînées de ces modèles, bien que puissantes, peuvent fournir des réponses plus génériques ou répétitives. Un réglage fin adapte le modèle à des contextes spécifiques, ce qui donne lieu à des réponses plus précises, pertinentes et diversifiées. Cette personnalisation est particulièrement évidente lorsque l'on compare les réponses de modèles pré-entraînés et affinés, où ces derniers démontrent une amélioration notable de la qualité et de la spécificité des résultats. En conclusion, le déploiement et le réglage fin des modèles Neuron Llama 2 sur SageMaker représentent un cadre robuste pour la gestion de modèles d'IA avancés, offrant des améliorations significatives en termes de performances et d'applicabilité, en particulier lorsqu'ils sont adaptés à des domaines ou des tâches spécifiques.
Commencez dès aujourd'hui en référençant l'exemple de SageMaker cahier.
Pour plus d'informations sur le déploiement et le réglage fin des modèles Llama 2 pré-entraînés sur des instances basées sur GPU, reportez-vous à Affinez Llama 2 pour la génération de texte sur Amazon SageMaker JumpStart ainsi que le Les modèles de fondation Llama 2 de Meta sont désormais disponibles dans Amazon SageMaker JumpStart.
Les auteurs souhaitent remercier pour leurs contributions techniques Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne et Mike James.
À propos des auteurs
 Xin Huang est un scientifique appliqué senior pour Amazon SageMaker JumpStart et les algorithmes intégrés d'Amazon SageMaker. Il se concentre sur le développement d'algorithmes d'apprentissage automatique évolutifs. Ses intérêts de recherche portent sur le traitement du langage naturel, l'apprentissage en profondeur explicable sur des données tabulaires et l'analyse robuste du clustering spatio-temporel non paramétrique. Il a publié de nombreux articles dans les conférences ACL, ICDM, KDD et Royal Statistical Society: Series A.
Xin Huang est un scientifique appliqué senior pour Amazon SageMaker JumpStart et les algorithmes intégrés d'Amazon SageMaker. Il se concentre sur le développement d'algorithmes d'apprentissage automatique évolutifs. Ses intérêts de recherche portent sur le traitement du langage naturel, l'apprentissage en profondeur explicable sur des données tabulaires et l'analyse robuste du clustering spatio-temporel non paramétrique. Il a publié de nombreux articles dans les conférences ACL, ICDM, KDD et Royal Statistical Society: Series A.
 Nitin Eusèbe est un architecte de solutions d'entreprise senior chez AWS, expérimenté en génie logiciel, en architecture d'entreprise et en IA/ML. Il est profondément passionné par l’exploration des possibilités de l’IA générative. Il collabore avec les clients pour les aider à créer des applications bien architecturées sur la plateforme AWS, et se consacre à résoudre les défis technologiques et à les accompagner dans leur transition vers le cloud.
Nitin Eusèbe est un architecte de solutions d'entreprise senior chez AWS, expérimenté en génie logiciel, en architecture d'entreprise et en IA/ML. Il est profondément passionné par l’exploration des possibilités de l’IA générative. Il collabore avec les clients pour les aider à créer des applications bien architecturées sur la plateforme AWS, et se consacre à résoudre les défis technologiques et à les accompagner dans leur transition vers le cloud.
 Madhur Prashant travaille dans l'espace de l'IA générative chez AWS. Il est passionné par l’intersection de la pensée humaine et de l’IA générative. Ses intérêts résident dans l’IA générative, en particulier dans la création de solutions utiles et inoffensives, et surtout optimales pour les clients. En dehors du travail, il adore faire du yoga, faire de la randonnée, passer du temps avec son jumeau et jouer de la guitare.
Madhur Prashant travaille dans l'espace de l'IA générative chez AWS. Il est passionné par l’intersection de la pensée humaine et de l’IA générative. Ses intérêts résident dans l’IA générative, en particulier dans la création de solutions utiles et inoffensives, et surtout optimales pour les clients. En dehors du travail, il adore faire du yoga, faire de la randonnée, passer du temps avec son jumeau et jouer de la guitare.
 Dewan Choudhury est ingénieur en développement logiciel chez Amazon Web Services. Il travaille sur les algorithmes et les offres JumpStart d'Amazon SageMaker. Outre la construction d'infrastructures AI/ML, il est également passionné par la construction de systèmes distribués évolutifs.
Dewan Choudhury est ingénieur en développement logiciel chez Amazon Web Services. Il travaille sur les algorithmes et les offres JumpStart d'Amazon SageMaker. Outre la construction d'infrastructures AI/ML, il est également passionné par la construction de systèmes distribués évolutifs.
 Hao Zhou est chercheur scientifique chez Amazon SageMaker. Avant cela, il a travaillé sur le développement de méthodes d'apprentissage automatique pour la détection des fraudes pour Amazon Fraud Detector. Il est passionné par l’application des techniques d’apprentissage automatique, d’optimisation et d’IA générative à divers problèmes du monde réel. Il est titulaire d'un doctorat en génie électrique de l'Université Northwestern.
Hao Zhou est chercheur scientifique chez Amazon SageMaker. Avant cela, il a travaillé sur le développement de méthodes d'apprentissage automatique pour la détection des fraudes pour Amazon Fraud Detector. Il est passionné par l’application des techniques d’apprentissage automatique, d’optimisation et d’IA générative à divers problèmes du monde réel. Il est titulaire d'un doctorat en génie électrique de l'Université Northwestern.
 Lan Qing est ingénieur en développement logiciel chez AWS. Il a travaillé sur plusieurs produits stimulants chez Amazon, notamment des solutions d'inférence ML hautes performances et un système de journalisation hautes performances. L'équipe de Qing a lancé avec succès le premier modèle de milliards de paramètres dans Amazon Advertising avec une très faible latence requise. Qing possède une connaissance approfondie de l'optimisation de l'infrastructure et de l'accélération du Deep Learning.
Lan Qing est ingénieur en développement logiciel chez AWS. Il a travaillé sur plusieurs produits stimulants chez Amazon, notamment des solutions d'inférence ML hautes performances et un système de journalisation hautes performances. L'équipe de Qing a lancé avec succès le premier modèle de milliards de paramètres dans Amazon Advertising avec une très faible latence requise. Qing possède une connaissance approfondie de l'optimisation de l'infrastructure et de l'accélération du Deep Learning.
 Dr Ashish Khetan est un scientifique appliqué senior avec les algorithmes intégrés d'Amazon SageMaker et aide à développer des algorithmes d'apprentissage automatique. Il a obtenu son doctorat à l'Université de l'Illinois à Urbana-Champaign. Il est un chercheur actif en apprentissage automatique et en inférence statistique, et a publié de nombreux articles dans les conférences NeurIPS, ICML, ICLR, JMLR, ACL et EMNLP.
Dr Ashish Khetan est un scientifique appliqué senior avec les algorithmes intégrés d'Amazon SageMaker et aide à développer des algorithmes d'apprentissage automatique. Il a obtenu son doctorat à l'Université de l'Illinois à Urbana-Champaign. Il est un chercheur actif en apprentissage automatique et en inférence statistique, et a publié de nombreux articles dans les conférences NeurIPS, ICML, ICLR, JMLR, ACL et EMNLP.
 Dr Li Zhang est un chef de produit principal technique pour les algorithmes intégrés d'Amazon SageMaker JumpStart et d'Amazon SageMaker, un service qui aide les scientifiques des données et les praticiens de l'apprentissage automatique à démarrer la formation et le déploiement de leurs modèles, et utilise l'apprentissage par renforcement avec Amazon SageMaker. Son travail passé en tant que membre principal du personnel de recherche et maître inventeur chez IBM Research a remporté le prix du papier test de l'IEEE INFOCOM.
Dr Li Zhang est un chef de produit principal technique pour les algorithmes intégrés d'Amazon SageMaker JumpStart et d'Amazon SageMaker, un service qui aide les scientifiques des données et les praticiens de l'apprentissage automatique à démarrer la formation et le déploiement de leurs modèles, et utilise l'apprentissage par renforcement avec Amazon SageMaker. Son travail passé en tant que membre principal du personnel de recherche et maître inventeur chez IBM Research a remporté le prix du papier test de l'IEEE INFOCOM.
 Kamran Khan, responsable principal du développement commercial technique pour AWS Inferentina/Trianium chez AWS. Il a plus d'une décennie d'expérience en aidant les clients à déployer et à optimiser les charges de travail de formation et d'inférence en profondeur à l'aide d'AWS Inferentia et d'AWS Trainium.
Kamran Khan, responsable principal du développement commercial technique pour AWS Inferentina/Trianium chez AWS. Il a plus d'une décennie d'expérience en aidant les clients à déployer et à optimiser les charges de travail de formation et d'inférence en profondeur à l'aide d'AWS Inferentia et d'AWS Trainium.
 Joe Senerchia est chef de produit senior chez AWS. Il définit et crée des instances Amazon EC2 pour les charges de travail d'apprentissage profond, d'intelligence artificielle et de calcul haute performance.
Joe Senerchia est chef de produit senior chez AWS. Il définit et crée des instances Amazon EC2 pour les charges de travail d'apprentissage profond, d'intelligence artificielle et de calcul haute performance.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :possède
- :est
- :ne pas
- :où
- $UP
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- capacité
- Capable
- A Propos
- accélération
- Accepter
- acceptable
- accepté
- accès
- précision
- Avec cette connaissance vient le pouvoir de prendre
- reconnaître
- ACM
- infection
- d'activités
- Adam
- adapter
- adaptation
- adapté
- ajouter
- ajout
- adultes
- Avancée
- avancement
- Numérique
- Après
- contrat
- AI
- Modèles AI
- AI / ML
- algorithmes
- Tous
- permettre
- permis
- permet
- aussi
- Amazon
- Amazon EC2
- Détecteur de fraude Amazon
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- Amazon Web Services
- parmi
- an
- selon une analyse de l’Université de Princeton
- Ancien
- ainsi que le
- animaux
- Annoncer
- Une autre
- tous
- plus
- Apache
- A PART
- en vigueur
- Application
- applications
- appliqué
- Application
- de manière appropriée
- d'environ
- architecture
- SONT
- Réservé
- domaines
- argument
- Armée
- arrivé
- Art
- artificiel
- intelligence artificielle
- AS
- assistant
- Association
- At
- Préposés
- attributs
- Pouvoirs publics
- auteurs
- Automatisation
- disponibilité
- disponibles
- éviter
- AWS
- Inférence AWS
- b
- basé
- BE
- Faisceau
- car
- devenez
- était
- before
- va
- CROYONS
- ci-dessous
- jusqu'à XNUMX fois
- Au-delà
- Le plus grand
- biologie
- Blog
- né
- tous les deux
- Box
- vaste
- construire
- Développement
- construit
- intégré
- la performance des entreprises
- Développement des affaires
- mais
- bouton (dans la fenêtre de contrôle qui apparaît maintenant)
- boutons
- by
- Appelez-nous
- venu
- CAN
- capacités
- capital
- carte
- réalisée
- maisons
- cas
- catégories
- Catégories
- globaux
- difficile
- Change
- Chaos
- le chat
- chef
- le choix
- Selectionnez
- choose
- Christopher
- Ville
- civil
- clarté
- les classes
- classiques
- classification
- espace extérieur plus propre,
- le cloud
- regroupement
- code
- du froid
- comité
- Commun
- Communautés
- Communautés
- Société
- par rapport
- comparant
- comparaisons
- Complété
- finalise
- calcul
- informatique
- conclusion
- concurrent
- Conduire
- Congrès
- conférences
- configuration
- Confirmer
- Console
- contiennent
- Contenant
- contient
- contenu
- contexte
- contextes
- contributions
- des bactéries
- contrôles
- Prix
- cher
- Costs
- Pays
- créée
- #
- crucial
- à la diversité
- Coupe
- des clients
- expérience client
- Clients
- personnalisation
- données
- ensembles de données
- Date
- de
- décennie
- Décembre
- Le décryptage
- dévoué
- profond
- l'apprentissage en profondeur
- profondément
- Réglage par défaut
- Définit
- Degré
- livrer
- démocratique
- démontrer
- démontré
- démontre
- Selon
- dépend
- déployer
- déployé
- déployer
- déploiement
- décrit
- la description
- désigné
- un
- détaillé
- détails
- Détection
- développer
- développement
- Développement
- Dialogue
- DID
- différence
- différent
- découvrez
- découverte
- discuter
- Commande
- distribué
- systèmes distribués
- plusieurs
- faire
- Chariot
- domaine
- domaines
- Ne pas
- down
- chacun
- "Early Bird"
- Revenus
- facilité
- facilité d'utilisation
- éditeur
- Efficace
- efficacité
- efficace
- non plus
- élu
- ingénierie électrique
- Empire
- activé
- permet
- permettant
- fin
- end-to-end
- Endpoint
- ingénieur
- ENGINEERING
- de renforcer
- améliorer
- assez
- Assure
- Entreprise
- Solutions d'entreprise
- Environment
- environnementales
- égal
- Équivaut à
- notamment
- Ether (ETH)
- évaluer
- évaluation
- évident
- exemple
- exemples
- excité
- à l'exclusion
- existant
- d'experience
- expérimenté
- expérimental
- explorez
- Explorer
- extraction
- Automne
- non
- plus rapide
- compagnon
- festivals
- few
- Des champs
- Déposez votre dernière attestation
- Fichiers
- Dépôt
- la traduction de documents financiers
- services financiers
- Trouvez
- fin
- Prénom
- Flexibilité
- flotteur
- Focus
- se concentre
- Abonnement
- suit
- Pour
- Force
- le format
- trouvé
- Fondation
- Fondée
- Framework
- cadres
- fraude
- détection de fraude
- De
- fonction
- plus
- généré
- génère
- génération
- génératif
- IA générative
- obtenez
- Go
- Dieu
- Bien
- eu
- diplôme
- graphique
- graphiques
- plus grand
- Grèce
- Gourmand
- grec
- Réservation de groupe
- l'orientation
- guitare
- ait eu
- Maniabilité
- Mains
- heureux vous
- Vous avez
- he
- la médecine
- Tenue
- vous aider
- utile
- aider
- aide
- Haute
- haute performance
- augmentation
- le plus élevé
- Faits saillants
- randonnée
- lui
- sa
- détient
- Comment
- How To
- Cependant
- HTML
- http
- HTTPS
- humain
- i
- IBM
- ICLR
- identifier
- ids
- IEEE
- if
- ii
- Illinois
- la mise en oeuvre
- importer
- important
- améliorer
- amélioré
- amélioration
- améliorations
- in
- en profondeur
- comprendre
- inclut
- Y compris
- Améliore
- indique
- d'information
- extraction d'informations
- Infrastructure
- infrastructures
- contribution
- entrées
- instance
- cas
- Des instructions
- des services
- Intelligence
- intérêts
- Interfaces
- International
- intersection
- développement
- impliqué
- IT
- SES
- Jacques
- Emploi
- Emplois
- rejoint
- jonathan
- Journal
- chemin
- jpg
- json
- juste
- ACTIVITES
- Royaume
- kit
- Trousse (SDK)
- spécialisées
- connu
- atterrissage
- page de destination
- langue
- gros
- grande échelle
- Latence
- plus tard
- lancé
- Lois
- conduisant
- apprentissage
- Longueur
- li
- Licence
- licences
- mensonge
- VIE
- comme
- probabilité
- Probable
- limitation
- Gamme
- lignes
- LINK
- Liste
- Listé
- Flamme
- charge
- locales
- enregistrement
- Location
- Style
- aime
- Faible
- baisser
- abaissement
- le plus bas
- click
- machine learning
- LES PLANTES
- Entrée
- a prendre une
- Fabrication
- manager
- les gérer
- Manan Shah
- de nombreuses
- maître
- maximales
- Mai..
- sens
- Découvrez
- membre
- Meta
- méthode
- méthodes
- Mexique
- pourrait
- micro
- l'esprit
- ML
- modèle
- modélisation statistique
- numériques jumeaux (digital twin models)
- modifié
- modifier
- PLUS
- (en fait, presque toutes)
- déménagé
- Musique
- must
- prénom
- Nature
- Langage naturel
- Traitement du langage naturel
- NAVIGUER
- Navigation
- Besoin
- Besoins
- NeuroIPS
- Nouveauté
- next
- nlp
- Northwestern University
- cahier
- ordinateurs portables
- maintenant
- nombre
- numéros
- objet
- objectifs
- of
- code
- offrant
- Offrandes
- Offres Speciales
- souvent
- Vieux
- plus
- on
- une fois
- ONE
- uniquement
- optimaux
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Optimiser
- optimisé
- l'optimisation
- Option
- or
- organisation
- Autre
- sortie
- au contrôle
- exceptionnel
- plus de
- propre
- Forfaits
- page
- paire
- apparié
- pain
- Papier
- papiers
- Parallèle
- paramètres
- partie
- particulièrement
- les parties
- passage
- passionné
- passé
- /
- effectuer
- performant
- période
- Personnalisé
- phd
- pipeline
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- jouer
- veuillez cliquer
- Point
- politiques
- politique
- politique
- pop-up
- Populaire
- positif
- possibilités
- possible
- Post
- solide
- précédant
- La précision
- en train de préparer
- primaire
- Directeur
- probabilité
- d'ouvrabilité
- processus
- traitement
- Produit
- chef de produit
- Produits
- propriétaire
- fournir
- fournisseurs
- fournit
- publiquement
- publié
- mettre
- Python
- pytorch
- qualité
- question
- aléatoire
- nous joindre
- atteint
- Lire
- solutions
- réal
- monde réel
- en temps réel
- raison
- Les raisons
- Articles
- reportez-vous
- référencement
- réfugiés
- libéré
- pertinence
- pertinent
- Relocalisé
- resté
- reste
- répété
- répétitif
- remplacer
- dépôt
- représentent
- représentation
- nécessaire
- demandes
- conditions
- un article
- chercheur
- Resources
- respectivement
- réponse
- réponses
- responsables
- résultant
- Résultats
- retourner
- Avis
- examen
- robuste
- Roulant
- Royal
- Courir
- Russie
- sagemaker
- Évolutivité
- évolutive
- Escaliers intérieurs
- scénarios
- Scientifique
- scientifiques
- scripts
- Sdk
- Rechercher
- recherche
- SEC
- Dépôt SEC
- Deuxièmement
- Section
- sécurité
- sur le lien
- supérieur
- envoyé
- phrase
- sentiment
- séparé
- Séquence
- Série
- de série A
- service
- Services
- set
- mise
- Paramétres
- plusieurs
- Shorts
- devrait
- montrer
- montré
- Spectacles
- significative
- étapes
- depuis
- unique
- Taille
- Fragment
- So
- Société
- Logiciels
- développement de logiciels
- kit de développement logiciel
- génie logiciel
- sur mesure
- Solutions
- Résoudre
- quelques
- sont
- Identifier
- Région Sud
- soviétique
- Space
- spécialisé
- groupe de neurones
- spécifiquement
- spécificité
- spécifié
- Dépenses
- scission
- L'équipe
- Commencer
- j'ai commencé
- Région
- statistique
- Statut
- pilotage
- étapes
- Étapes
- Arrête
- storage
- structuré
- Étudiante
- étudié
- études
- studio
- Avec succès
- tel
- Support
- Appareils
- sûr
- Suisse
- combustion propre
- Système
- table
- Tâche
- tâches
- Enseignement
- équipe
- Technique
- technique
- techniques
- Technologie
- modèle
- Tennessee
- conditions
- tester
- texte
- Classification du texte
- génération de texte
- que
- qui
- La
- La Région
- Le Capital
- Théâtre
- leur
- Les
- puis
- Là.
- Ces
- l'ont
- En pensant
- des tiers.
- this
- ceux
- Avec
- débit
- les tigres
- fiable
- fois
- à
- aujourd'hui
- jeton
- Tokens
- les outils
- Total
- Train
- qualifié
- Formation
- transformateur
- Traduction
- oui
- Essai
- double
- deux
- type
- ui
- sous
- sous-jacent
- expérience unique et authentique
- Universités
- université
- jusqu'à
- Mises à jour
- Actualités
- Utilisation
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- utilisateurs
- Usages
- en utilisant
- utilise
- Ouzbékistan
- validation
- Plus-value
- variété
- divers
- version
- très
- via
- Voir
- vigne
- visuel
- marcher
- souhaitez
- guerre
- était
- façons
- we
- web
- services Web
- Basé sur le Web
- est allé
- ont été
- quand
- qui
- tout en
- WHO
- sera
- VIN
- comprenant
- A gagné
- Word
- des mots
- activités principales
- travaillé
- de travail
- vos contrats
- atelier
- world
- pourra
- écrire
- an
- Yoga
- you
- Votre
- jeunesse
- zéphyrnet
- Zeus