Dans le monde d'aujourd'hui, les clients gèrent de grandes quantités de données dans leur Service de stockage simple Amazon (Amazon S3) les lacs de données, qui nécessitent des pipelines de données alambiqués pour comprendre en permanence les modifications de la disposition des données et les mettre à la disposition des systèmes consommateurs. Colle AWS Les robots d'exploration offrent un moyen simple de cataloguer les données dans le catalogue de données AWS Glue, ce qui élimine le gros du travail en matière de gestion des schémas et de classification des données. Les robots d'exploration AWS Glue extraient le schéma de données et les partitions d'Amazon S3 pour remplir automatiquement le catalogue de données, en gardant les métadonnées à jour.
Mais avec la croissance exponentielle des données au fil du temps, le nombre de partitions dans une table donnée peut augmenter de manière significative. Parce que les services d'analyse comme Amazone Athéna interroge une table contenant des millions de partitions, le temps nécessaire pour récupérer la partition augmente et peut entraîner une augmentation du temps d'exécution de la requête.
Aujourd'hui, la prise en charge du robot d'exploration AWS Glue a été étendue pour ajouter automatiquement des index de partition pour les tables nouvellement découvertes afin d'optimiser le traitement des requêtes sur l'ensemble de données partitionné. Désormais, lorsque l'analyseur crée une nouvelle table de catalogue de données lors d'une exécution d'analyseur, il crée également un index de partition par défaut, avec la plus grande permutation de toutes les colonnes de partition numériques et de type chaîne en tant que clés. Le catalogue de données crée ensuite un index consultable basé sur ces clés, réduisant ainsi le temps nécessaire pour récupérer et filtrer les métadonnées de partition sur des tables avec des millions de partitions. La création d'index de partition profite aux charges de travail d'analyse exécutées sur Athena, Amazon DME, Spectre Amazon Redshiftet AWS Glue.
Dans cet article, nous décrivons comment créer des index de partition avec un robot d'exploration AWS Glue et comparons l'amélioration des performances des requêtes lors de l'accès aux données analysées avec et sans index de partition d'Athena.
Vue d'ensemble de la solution
Nous utilisons un AWS CloudFormation modèle pour créer nos ressources de solution. Dans les étapes suivantes, nous montrons comment configurer l'analyseur AWS Glue pour créer un index de partition à l'aide de la console AWS Glue ou du Interface de ligne de commande AWS (AWS CLI). Ensuite, nous comparons les améliorations des performances des requêtes à l'aide d'Athena.
Pré-requis
Pour suivre ce post, vous devez avoir accès à un Gestion des identités et des accès AWS (IAM) rôle d'administrateur pour créer des ressources à l'aide d'AWS CloudFormation.
Configurer les ressources de votre solution
Le modèle CloudFormation génère les ressources suivantes :
- Rôles et stratégies IAM
- Une base de données AWS Glue pour contenir le schéma
- Un robot d'exploration AWS Glue pointant vers un ensemble de données hautement partitionné
- Un groupe de travail Athena et un bucket pour stocker les résultats des requêtes
Effectuez les étapes suivantes pour configurer les ressources de la solution :
- Connectez-vous au Console de gestion AWS en tant qu'administrateur IAM.
- Selectionnez Lancer la pile pour déployer le modèle CloudFormation :

- Pour Nom de la base de données, gardez la valeur par défaut
blog_partition_index_crawlerdb.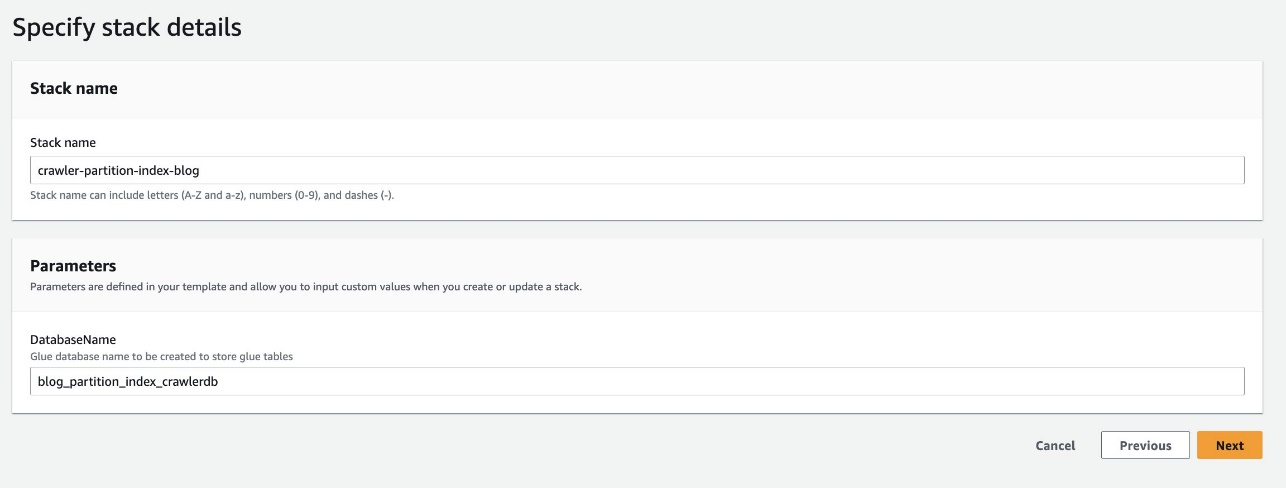
- Selectionnez Suivant.
- Passez en revue les détails sur la dernière page et sélectionnez Je reconnais qu'AWS CloudFormation peut créer des ressources IAM.
- Selectionnez Créer une pile.
- Une fois la pile terminée, sur la console AWS CloudFormation, accédez au Sortie onglet de la pile.
- Notez les valeurs de
DatabaseNameainsi queGlueCrawlerName.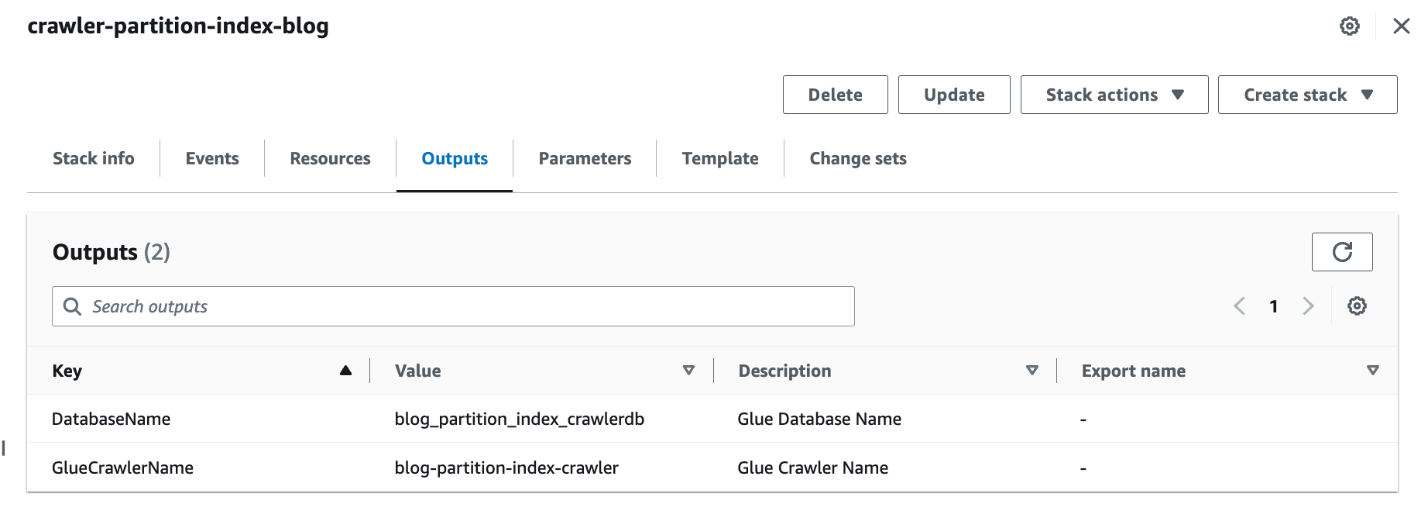
Certaines des ressources déployées par cette pile entraînent des coûts lors de leur utilisation.
Modifier et exécuter le robot d'exploration AWS Glue
Pour configurer et exécuter l'analyseur AWS Glue, procédez comme suit :
- Sur la console AWS Glue, choisissez Rampeurs dans le volet de navigation.
- Localisez le
crawler blog-partition-index-crawleret choisissez Modifier.
- Dans le Définir la sortie et la planification section, sous Options avancées, sélectionnez Créer des index de partition automatiquement.
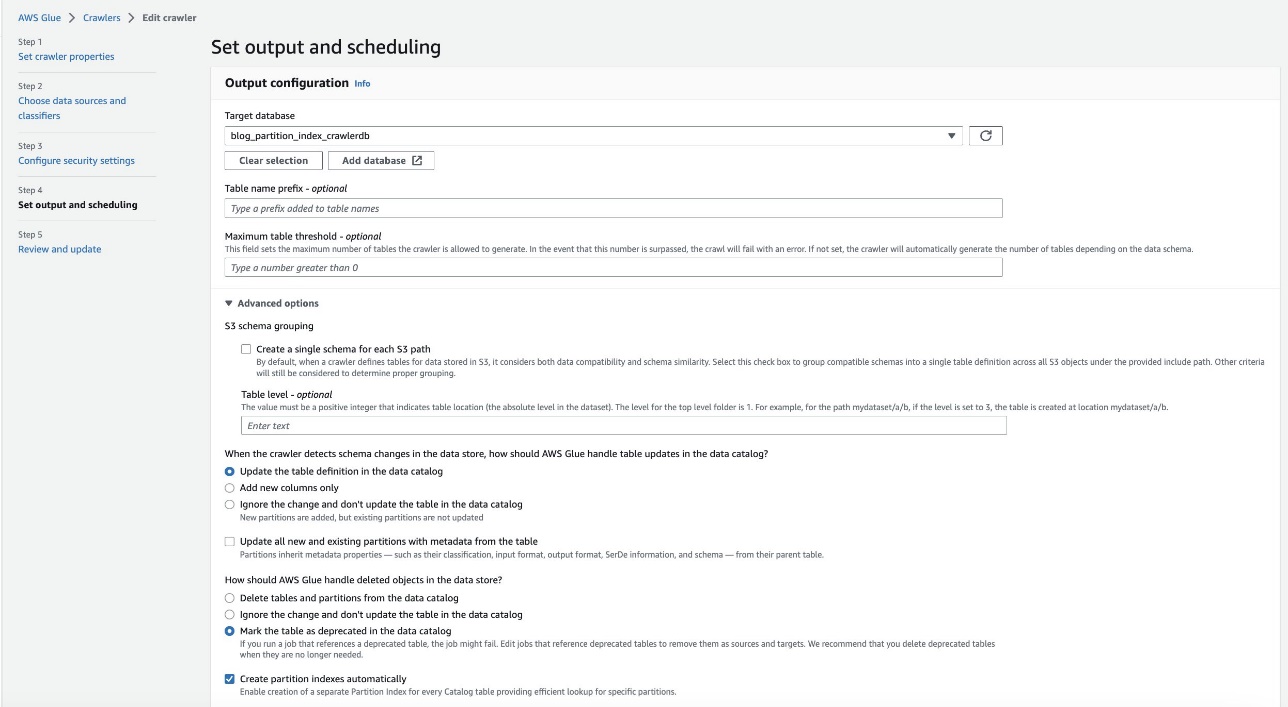
- Vérifiez et mettez à jour les paramètres du robot d'exploration.
Vous pouvez également configurer votre robot d'exploration à l'aide de l'AWS CLI (indiquez votre rôle IAM et votre région) :
- Maintenant, exécutez le robot et vérifiez que l'exécution du robot est terminée.
Il s'agit d'un ensemble de données hautement partitionné qui prendra environ 90 minutes.
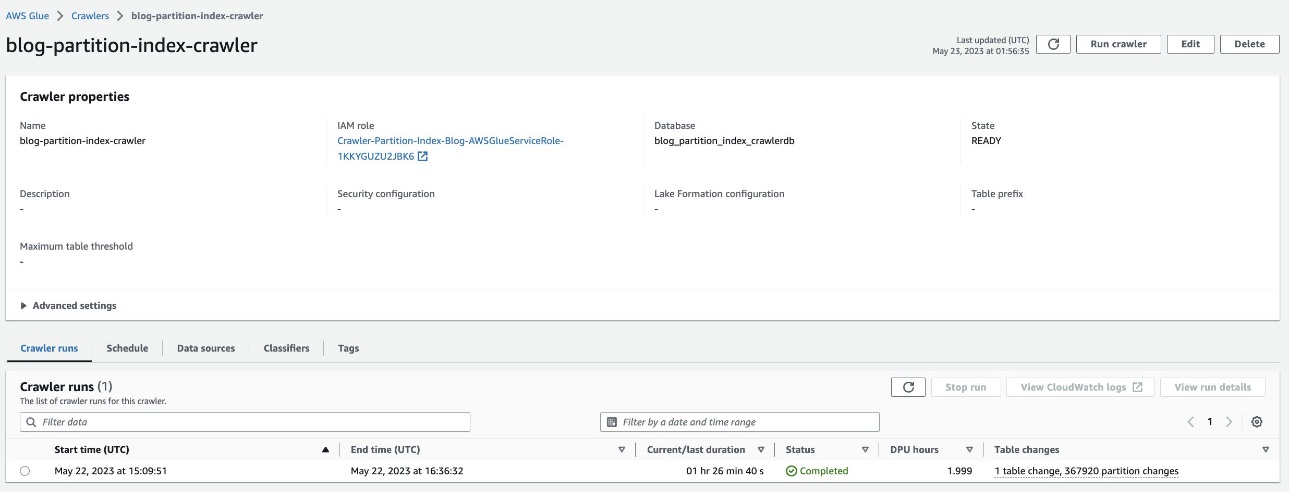
Vérifier la table partitionnée
Dans la base de données AWS Glue blog_partition_index_crawlerdb, vérifiez que le tableau highly_partitioned_table est créé.
Par défaut, le robot d'indexation détermine un index basé sur la plus grande permutation de colonnes de partition de types de colonnes valides dans le même ordre de colonnes de partition, qui sont soit numériques, soit chaîne. Pour la table créée par le robot d'exploration (highly_partitioned_table), nous avons des colonnes de partition year (chaîne), month (chaîne), day (chaîne), et hour (chaîne).
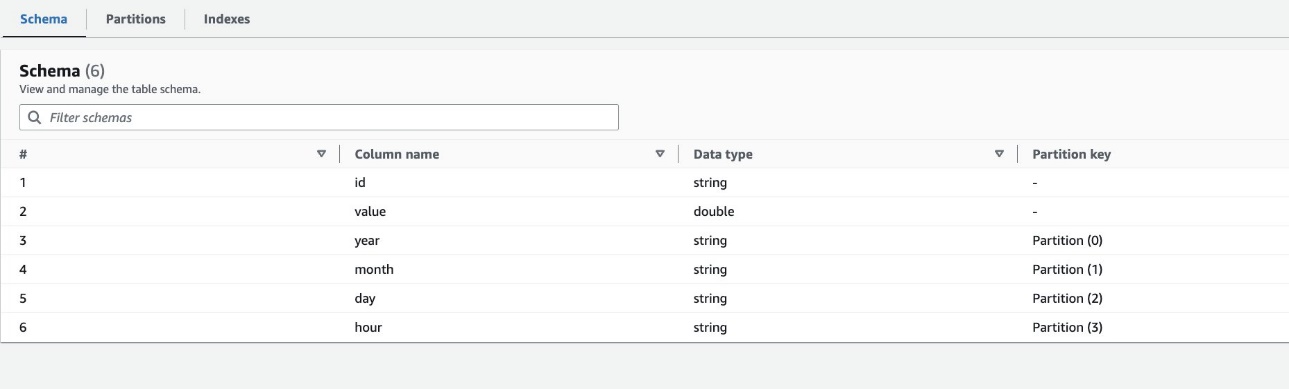
Sur la base de cette définition, le crawler a créé un index sur la permutation de l'année, du mois, du jour et de l'heure. Le robot d'exploration a créé les index préfixés par crawler_ sur n'importe quel index de partition créé par défaut.
Vérifiez la même chose en naviguant vers le tableau highly_partitioned_table sur la console AWS Glue et en choisissant le Index languette.
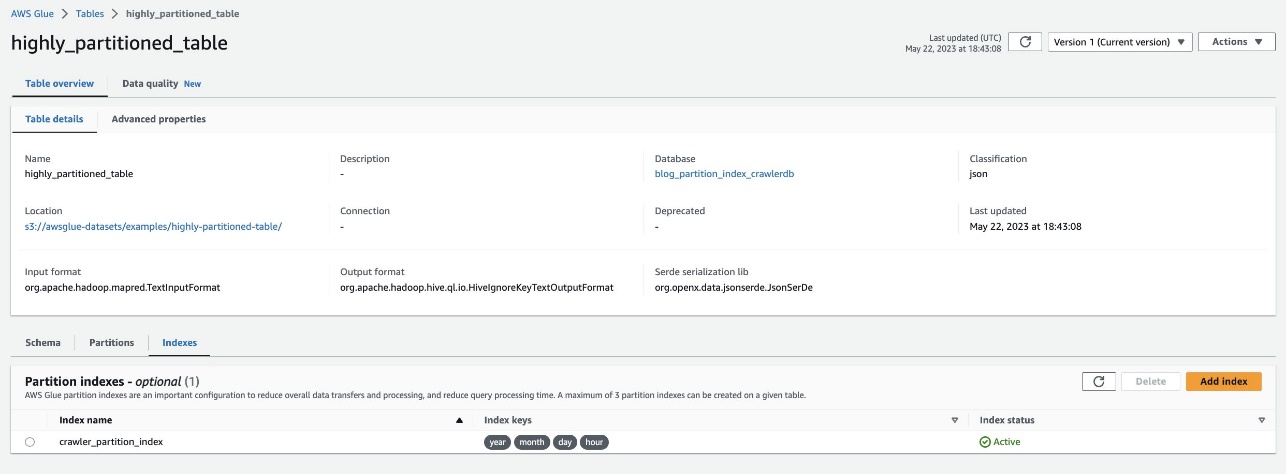
L'analyseur a pu analyser la source de données S3 et remplir avec succès les index de partition pour la table.
Comparez les améliorations des performances des requêtes à l'aide d'Athena
Tout d'abord, nous interrogeons la table dans Athena sans utiliser l'index de partition. Pour vérifier les tables à l'aide d'Athena, procédez comme suit :
- Sur la console Athena, choisissez
crawler-primary-workgroupen tant que groupe de travail Athena et choisissez Reconnaître.
- Exécutez la requête suivante :
La capture d'écran suivante montre que la requête a pris environ 32 secondes sans filtrage activé à l'aide de l'index de partition.
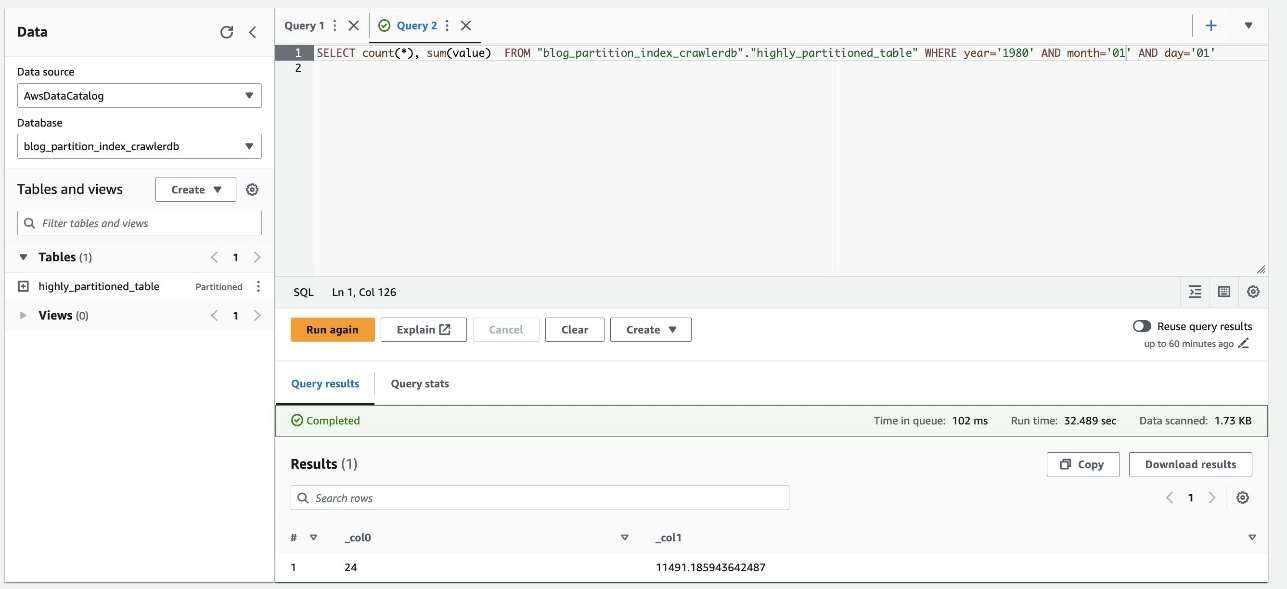
- Nous activons maintenant l'index de partition sur la requête Athena :
- Exécutez à nouveau la requête suivante et notez l'exécution :
La capture d'écran suivante montre que la requête n'a pris que 700 millisecondes, ce qui est beaucoup plus rapide avec le filtrage activé à l'aide de l'index de partition.
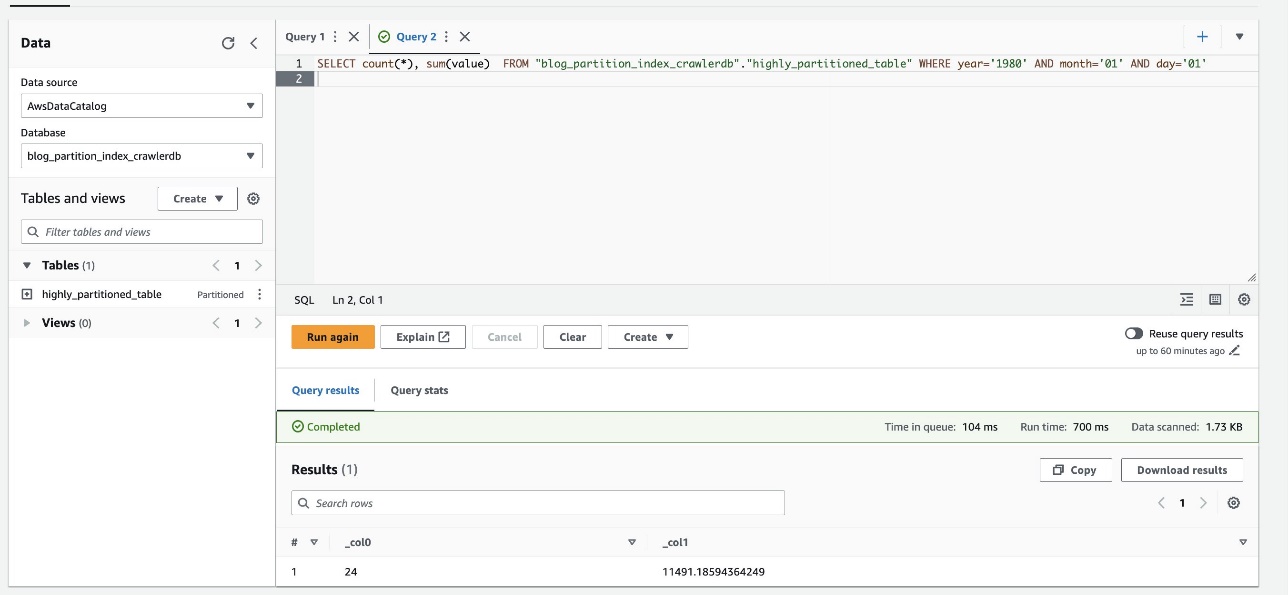
Nettoyer
Pour éviter des frais indésirables sur votre compte AWS, vous pouvez supprimer les ressources AWS :
- Connectez-vous à la console CloudFormation en tant qu'administrateur IAM utilisé pour créer la pile CloudFormation.
- Supprimez la pile CloudFormation que vous avez créée.
Conclusion
Dans cet article, nous avons expliqué comment configurer un robot AWS pour créer des index de partition et comparé les performances des requêtes lors de l'accès aux données avec les index d'Athena.
Si aucun index de partition n'est présent sur la table, AWS Glue charge toutes les partitions de la table, puis filtre les partitions chargées, ce qui entraîne une récupération inefficace des métadonnées. Les services d'analyse tels que Redshift Spectrum, Amazon EMR et AWS Glue ETL Spark DataFrames peuvent désormais utiliser des index pour récupérer des partitions, ce qui se traduit par des performances de requête significatives.
Pour plus d'informations sur les index de partition et les performances des requêtes sur différents moteurs d'analyse, reportez-vous à Améliorez les performances des requêtes Amazon Athena à l'aide des index de partition AWS Glue Data Catalog ainsi que Améliorez les performances des requêtes à l'aide des index de partition AWS Glue.
Remerciements particuliers à tous ceux qui ont contribué au lancement de cette fonctionnalité de robot : Yuhang Chen, Kyle Duong et Mita Gavade.
À propos des auteurs
 Srividya Parthasarathy est architecte Big Data senior au sein de l'équipe AWS Lake Formation. Elle aime créer des solutions de maillage de données et les partager avec la communauté.
Srividya Parthasarathy est architecte Big Data senior au sein de l'équipe AWS Lake Formation. Elle aime créer des solutions de maillage de données et les partager avec la communauté.
 Sandeep Adwankar est chef de produit technique senior chez AWS. Basé dans la région de la baie de Californie, il travaille avec des clients du monde entier pour traduire les exigences commerciales et techniques en produits qui permettent aux clients d'améliorer la façon dont ils gèrent, sécurisent et accèdent aux données.
Sandeep Adwankar est chef de produit technique senior chez AWS. Basé dans la région de la baie de Californie, il travaille avec des clients du monde entier pour traduire les exigences commerciales et techniques en produits qui permettent aux clients d'améliorer la façon dont ils gèrent, sécurisent et accèdent aux données.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Financement EVM. Interface unifiée pour la finance décentralisée. Accéder ici.
- Groupe de médias quantiques. IR/PR amplifié. Accéder ici.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :possède
- :est
- :où
- $UP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Capable
- accès
- accès
- Compte
- reconnaître
- à travers
- ajouter
- admin
- encore
- Tous
- le long de
- aussi
- Amazon
- Amazone Athéna
- Amazon DME
- Amazon Web Services
- quantités
- an
- Analytique
- analytique
- ainsi que
- tous
- d'environ
- SONT
- Réservé
- autour
- AS
- At
- automatiquement
- disponibles
- éviter
- AWS
- AWS CloudFormation
- Colle AWS
- Formation AWS Lake
- basé
- baie
- car
- était
- avantages.
- Big
- Big Data
- Développement
- la performance des entreprises
- by
- Californie
- CAN
- catalogue
- Causes
- Modifications
- des charges
- chen
- Selectionnez
- choose
- classification
- Colonne
- Colonnes
- vient
- Communautés
- comparer
- par rapport
- complet
- Console
- continuellement
- contribué
- Costs
- chenilles
- engendrent
- créée
- crée des
- La création
- création
- Courant
- Clients
- données
- accès aux données
- Lac de données
- Base de données
- journée
- Réglage par défaut
- démontrer
- déployer
- déploie
- décrire
- détails
- détermine
- découvert
- down
- pendant
- efficacement
- non plus
- permettre
- activé
- Moteurs
- Ether (ETH)
- tout le monde
- étendu
- expliqué
- exponentielle
- extrait
- extraire les données
- plus rapide
- Fonctionnalité
- une fonction filtre
- filtration
- filtres
- finale
- suivre
- Abonnement
- Pour
- formation
- De
- génère
- donné
- globe
- Croître
- Croissance
- Vous avez
- he
- lourd
- levage de charges lourdes
- très
- appuyez en continu
- heure
- Comment
- How To
- HTML
- http
- HTTPS
- IAM
- Identite
- améliorer
- amélioration
- améliorations
- in
- Améliore
- Augmente
- indice
- index
- inefficace
- d'information
- développement
- IT
- jpg
- XNUMX éléments à
- en gardant
- clés
- lac
- le plus grand
- lancer
- Disposition
- lifting
- comme
- Gamme
- charges
- a prendre une
- gérer
- gestion
- manager
- engrener
- Métadonnées
- pourrait
- des millions
- minutes
- Mois
- PLUS
- beaucoup
- must
- NAVIGUER
- navigation
- Navigation
- nécessaire
- Nouveauté
- nouvellement
- aucune
- maintenant
- nombre
- of
- on
- uniquement
- Optimiser
- or
- de commander
- nos
- sortie
- plus de
- page
- pain
- chemin
- performant
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Post
- représentent
- traitement
- Produit
- chef de produit
- Produits
- fournir
- réduire
- région
- conditions
- Exigences
- a besoin
- Resources
- résultant
- Résultats
- Rôle
- rôle
- Courir
- pour le running
- même
- secondes
- Section
- sécurisé
- supérieur
- Services
- set
- Paramétres
- partage
- elle
- Spectacles
- significative
- de façon significative
- étapes
- sur mesure
- Solutions
- Identifier
- Spark
- Spectre
- empiler
- Étapes
- storage
- Boutique
- simple
- Chaîne
- Avec succès
- Support
- Système
- table
- Prenez
- équipe
- Technique
- modèle
- à
- qui
- La
- leur
- Les
- puis
- Ces
- l'ont
- this
- fiable
- à
- aujourd'hui
- a
- traduire
- oui
- type
- types
- sous
- comprendre
- indésirable
- Mises à jour
- utilisé
- d'utiliser
- en utilisant
- utiliser
- Plus-value
- Valeurs
- divers
- Vaste
- vérifier
- version
- était
- Façon..
- we
- web
- services Web
- quand
- qui
- WHO
- sera
- comprenant
- sans
- Groupe De Travail
- vos contrats
- world
- yaml
- an
- you
- Votre
- zéphyrnet