
Image de l'auteur | Créateur d'images Bing
Chariot 2.0 est un grand modèle de langage (LLM) open source, suivi d'instructions, qui a été affiné sur un ensemble de données généré par l'homme. Il peut être utilisé à des fins de recherche et commerciales.
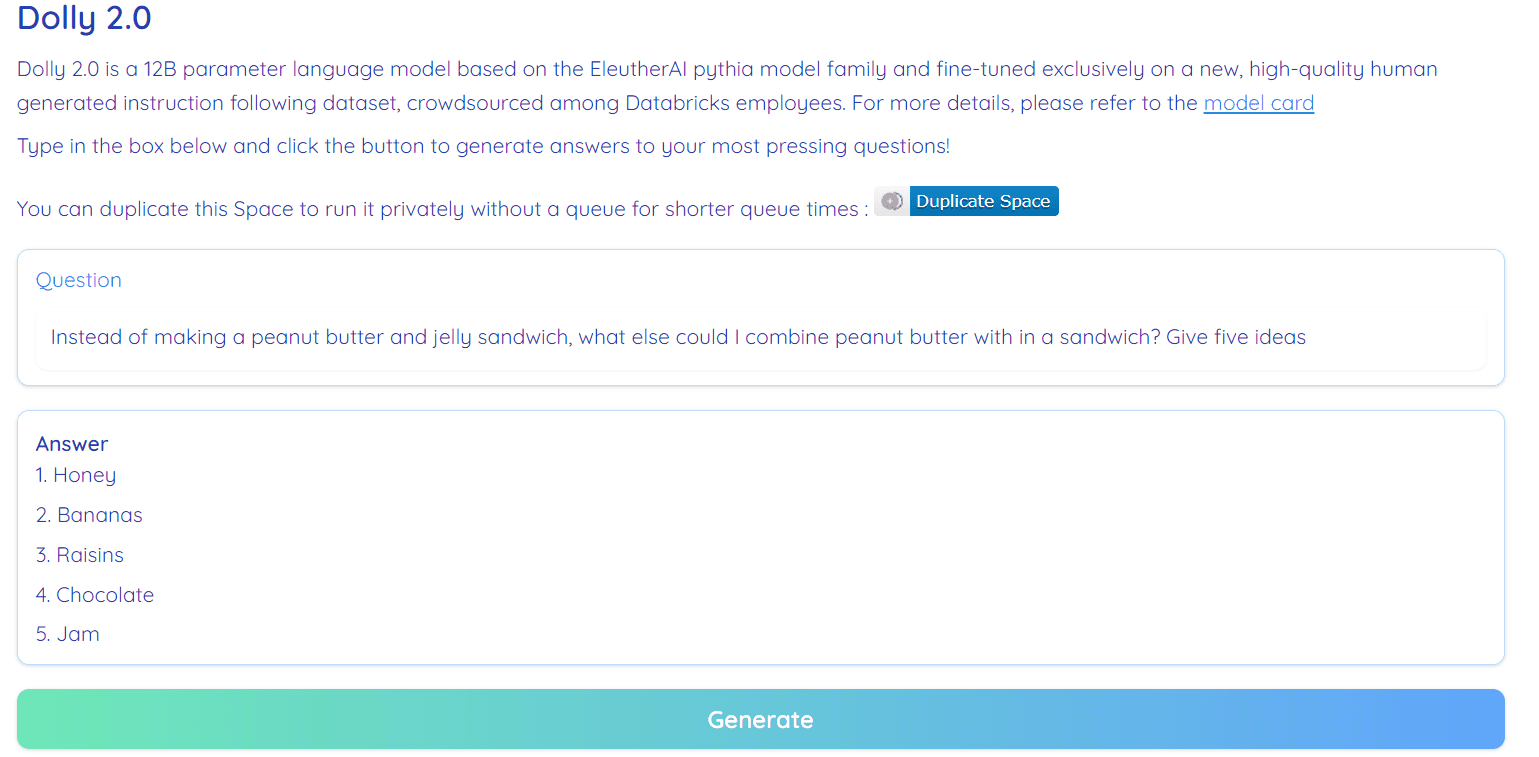
Image de « Espace visage câlin » par RamAnanth1
Auparavant, l'équipe Databricks a publié Chariot 1.0, LLM, qui présente une capacité de suivi d'instruction de type ChatGPT et coûte moins de 30 $ pour s'entraîner. Il utilisait l’ensemble de données de l’équipe Stanford Alpaca, qui était sous licence restreinte (recherche uniquement).
Dolly 2.0 a résolu ce problème en affinant le modèle de langage des paramètres 12B (Pythia) sur une instruction générée par l'homme de haute qualité dans l'ensemble de données suivant, qui a été étiqueté par un employé de Datbricks. Le modèle et l’ensemble de données sont disponibles pour un usage commercial.
Dolly 1.0 a été formé sur un ensemble de données Stanford Alpaca, créé à l'aide de l'API OpenAI. L'ensemble de données contient la sortie de ChatGPT et empêche quiconque de l'utiliser pour concurrencer OpenAI. En bref, vous ne pouvez pas créer un chatbot commercial ou une application linguistique basée sur cet ensemble de données.
La plupart des derniers modèles sortis ces dernières semaines souffraient des mêmes problèmes, des modèles comme Alpaga, Koala, GPT4Touset Vicuna. Pour nous déplacer, nous devons créer de nouveaux ensembles de données de haute qualité pouvant être utilisés à des fins commerciales, et c'est ce que l'équipe Databricks a fait avec l'ensemble de données databricks-dolly-15k.
Le nouvel ensemble de données contient 15,000 XNUMX paires invite/réponse étiquetées par des humains de haute qualité qui peuvent être utilisées pour concevoir des modèles de langage de réglage d’instructions de grande envergure. Le databricks-dolly-15k l'ensemble de données est livré avec Licence Creative Commons Attribution-Partage dans les mêmes conditions 3.0 non portée, ce qui permet à quiconque de l'utiliser, de le modifier et de créer une application commerciale dessus.
Comment ont-ils créé l’ensemble de données databricks-dolly-15k ?
La recherche OpenAI papier indique que le modèle InstructGPT original a été formé sur 13,000 13 invites et réponses. En utilisant ces informations, l'équipe Databricks a commencé à y travailler, et il s'avère que générer 5,000 XNUMX questions et réponses était une tâche difficile. Ils ne peuvent pas utiliser de données synthétiques ou de données génératives d’IA, et doivent générer des réponses originales à chaque question. C'est là qu'ils ont décidé d'utiliser XNUMX XNUMX employés de Databricks pour créer des données générées par l'homme.
Les Databricks ont organisé un concours dans lequel les 20 meilleurs étiqueteurs recevraient une grande récompense. À ce concours ont participé 5,000 XNUMX employés de Databricks très intéressés par les LLM.
Le Dolly-v2-12b n'est pas un modèle à la pointe de la technologie. Il sous-performe Dolly-v1-6b dans certains critères d'évaluation. Cela pourrait être dû à la composition et à la taille des ensembles de données de réglage fin sous-jacents. La famille de modèles Dolly est en cours de développement actif, vous pourriez donc voir une version mise à jour avec de meilleures performances à l'avenir.
En bref, le modèle Dolly-v2-12b a mieux fonctionné qu'EleutherAI/gpt-neox-20b et EleutherAI/pythia-6.9b.

Image de Chariot gratuit
Dolly 2.0 est 100 % open source. Il est livré avec un code de formation, un ensemble de données, des poids de modèle et un pipeline d'inférence. Tous les composants sont adaptés à un usage commercial. Vous pouvez essayer le modèle sur Hugging Face Spaces Dolly V2 par RamAnanth1.
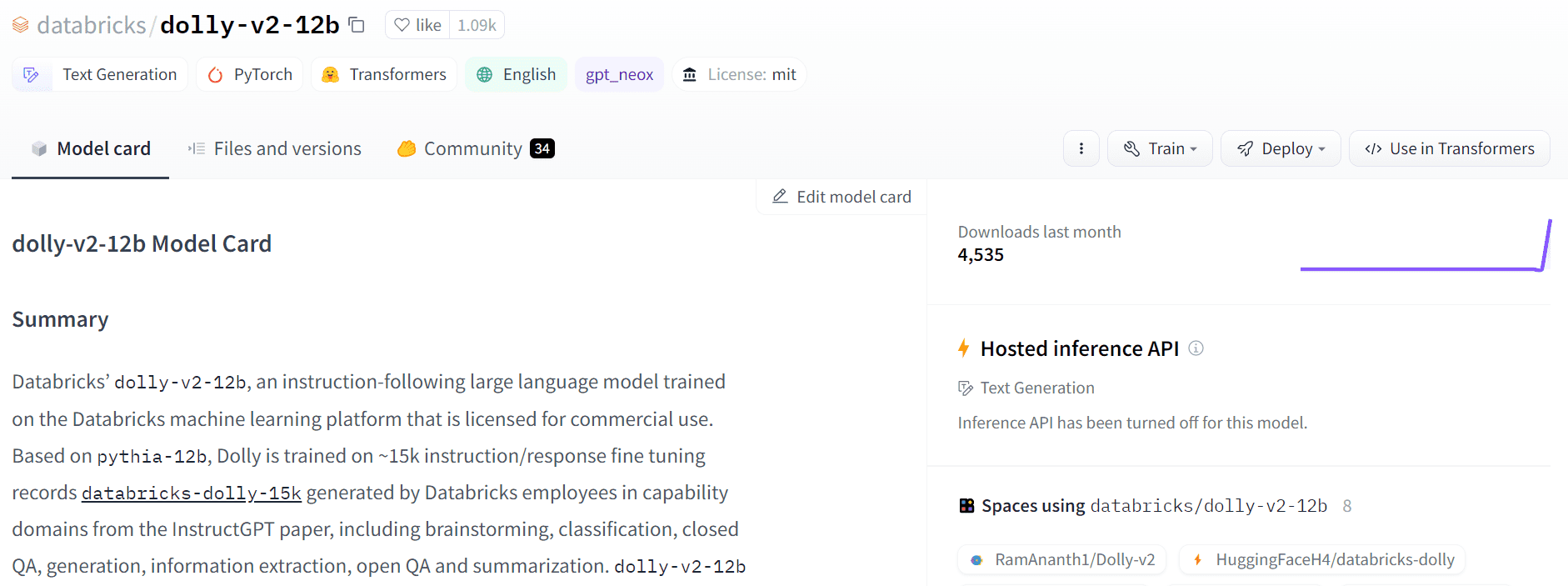
Image de Étreindre le visage
Ressource:
Démo Dolly 2.0 : Dolly V2 par RamAnanth1
Abid Ali Awan (@1abidaliawan) est un spécialiste des données certifié qui aime créer des modèles d'apprentissage automatique. Actuellement, il se concentre sur la création de contenu et la rédaction de blogs techniques sur les technologies d'apprentissage automatique et de science des données. Abid est titulaire d'une maîtrise en gestion de la technologie et d'un baccalauréat en génie des télécommunications. Sa vision est de créer un produit d'IA utilisant un réseau de neurones graphiques pour les étudiants aux prises avec une maladie mentale.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- Frapper l'avenir avec Adryenn Ashley. Accéder ici.
- La source: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :possède
- :est
- :ne pas
- $UP
- 000
- 1
- 20
- a
- capacité
- infection
- AI
- Tous
- permet
- alternative
- an
- ainsi que
- réponses
- chacun.e
- api
- Application
- SONT
- autour
- auteur
- disponibles
- prix
- basé
- BE
- repères
- Berkeley
- Améliorée
- Big
- Bing
- blogue
- tous les deux
- construire
- Développement
- by
- CAN
- ne peut pas
- Support et maintenance de Salesforce
- Chatbot
- ChatGPT
- code
- commercial
- Chambre des communes
- rivaliser
- composants électriques
- contient
- contenu
- création de contenu
- concours
- Costs
- engendrent
- créée
- création
- Lecture
- données
- science des données
- Data Scientist
- Databricks
- ensembles de données
- décidé
- Degré
- Démo
- Conception
- Développement
- DID
- difficile
- Chariot
- Employés
- employés
- ENGINEERING
- évaluation
- Chaque
- expositions
- Visage
- famille
- few
- mettant l'accent
- Abonnement
- Pour
- de
- avenir
- générer
- générateur
- génératif
- obtenez
- graphique
- Réseau neuronal graphique
- Vous avez
- he
- de haute qualité
- détient
- HTML
- HTTPS
- maladie
- image
- in
- d'information
- intéressé
- aide
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- jpg
- KDnuggetsGenericName
- langue
- gros
- Nom de famille
- Nouveautés
- apprentissage
- Licence
- comme
- click
- machine learning
- gestion
- maître
- mental
- Maladie mentale
- pourrait
- modèle
- numériques jumeaux (digital twin models)
- modifier
- Besoin
- réseau et
- Neural
- Réseau neuronal
- Nouveauté
- of
- on
- uniquement
- ouvert
- open source
- OpenAI
- or
- original
- sortie
- paires
- paramètre
- participé
- performant
- pipeline
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Produit
- professionels
- des fins
- question
- fréquemment posées
- libéré
- un article
- résolu
- limité
- s
- même
- Sciences
- Scientifique
- set
- Shorts
- Taille
- So
- quelques
- Identifier
- Space
- espaces
- Stanford
- j'ai commencé
- state-of-the-art
- États
- Luttant
- Étudiante
- convient
- haute
- données synthétiques
- Tâche
- équipe
- Technique
- Les technologies
- Technologie
- télécommunication
- que
- qui
- Les
- El futuro
- l'ont
- this
- à
- top
- Train
- qualifié
- Formation
- sous
- sous-jacent
- a actualisé
- utilisé
- d'utiliser
- en utilisant
- version
- vision
- était
- we
- Semaines
- ont été
- Quoi
- qui
- WHO
- comprenant
- Activités principales
- pourra
- écriture
- you
- zéphyrnet










