Redshift d'Amazon est un entrepôt de données cloud entièrement géré et à l'échelle du pétaoctet utilisé par des dizaines de milliers de clients pour traiter chaque jour des exaoctets de données afin d'alimenter leur charge de travail d'analyse. Vous pouvez structurer vos données, mesurer les processus métier et obtenir rapidement des informations précieuses en utilisant un modèle dimensionnel. Amazon Redshift fournit des fonctionnalités intégrées pour accélérer le processus de modélisation, d'orchestration et de création de rapports à partir d'un modèle dimensionnel.
Dans cet article, nous expliquons comment implémenter un modèle dimensionnel, en particulier le Méthodologie Kimball. Nous discutons de la mise en œuvre des dimensions et des faits dans Amazon Redshift. Nous montrons comment effectuer l'extraction, la transformation et le chargement (ELT), un processus d'intégration axé sur l'obtention des données brutes d'un lac de données dans une couche intermédiaire pour effectuer la modélisation. Dans l'ensemble, l'article vous expliquera clairement comment utiliser la modélisation dimensionnelle dans Amazon Redshift.
Vue d'ensemble de la solution
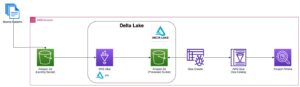
Le diagramme suivant illustre l'architecture de la solution.

Dans les sections suivantes, nous discutons et démontrons d'abord les aspects clés du modèle dimensionnel. Après cela, nous créons un magasin de données à l'aide d'Amazon Redshift avec un modèle de données dimensionnel comprenant des tables de dimensions et de faits. Les données sont chargées et mises en scène à l'aide du COPY commande, les données des dimensions sont chargées à l'aide de la FUSIONNER déclaration, et les faits seront joints aux dimensions d'où les idées sont dérivées. Nous planifions le chargement des dimensions et des faits en utilisant le Éditeur de requête Amazon Redshift V2. Enfin, nous utilisons Amazon QuickSight pour obtenir des informations sur les données modélisées sous la forme d'un tableau de bord QuickSight.
Pour cette solution, nous utilisons un exemple d'ensemble de données (normalisé) fourni par Amazon Redshift pour les ventes de billets d'événement. Pour cet article, nous avons réduit l'ensemble de données à des fins de simplicité et de démonstration. Les tableaux suivants montrent des exemples de données pour les ventes de billets et les lieux.


Selon le Méthodologie de modélisation dimensionnelle Kimball, la conception d'un modèle dimensionnel comporte quatre étapes clés :
- Identifier le processus métier.
- Déclarez le grain de vos données.
- Identifier et mettre en œuvre les dimensions.
- Identifier et mettre en œuvre les faits.
De plus, nous ajoutons une cinquième étape à des fins de démonstration, qui consiste à signaler et analyser les événements commerciaux.
Pré-requis
Pour cette procédure pas à pas, vous devez disposer des prérequis suivants:
Identifier le processus métier
En termes simples, l'identification du processus métier consiste à identifier un événement mesurable qui génère des données au sein d'une organisation. Habituellement, les entreprises ont une sorte de système source opérationnel qui génère leurs données dans leur format brut. C'est un bon point de départ pour identifier les différentes sources d'un processus métier.
Le processus métier est ensuite persisté en tant que data mart sous forme de dimensions et de faits. En regardant notre exemple d'ensemble de données mentionné précédemment, nous pouvons clairement voir que le processus commercial correspond aux ventes réalisées pour un événement donné.
Une erreur courante consiste à utiliser les services d'une entreprise comme processus métier. Les données (processus métier) doivent être intégrées dans différents départements, dans ce cas, le marketing peut accéder aux données de vente. Il est essentiel d'identifier le bon processus métier. Une erreur dans cette étape peut avoir un impact sur l'ensemble du magasin de données (cela peut entraîner la duplication du grain et des métriques incorrectes sur les rapports finaux).
Déclarez le grain de vos données
Déclarer le grain consiste à identifier de manière unique un enregistrement dans votre source de données. Le grain est utilisé dans la table de faits pour mesurer avec précision les données et vous permettre de remonter plus loin. Dans notre exemple, il peut s'agir d'un élément de ligne dans le processus commercial de vente.
Dans notre cas d'utilisation, une vente peut être identifiée de manière unique en examinant le moment de la transaction au moment où la vente a eu lieu ; ce sera le niveau le plus atomique.

Identifier et mettre en œuvre les dimensions
Votre table de dimension décrit votre table de faits et ses attributs. Lors de l'identification du contexte descriptif de votre processus métier, vous stockez le texte dans une table séparée, en gardant à l'esprit le grain de la table de faits. Lorsque vous joignez la table de dimensions à la table de faits, il ne doit y avoir qu'une seule ligne associée à la table de faits. Dans notre exemple, nous utilisons le tableau suivant pour être séparé en un tableau de dimensions ; ces champs décrivent les faits que nous allons mesurer.
Lors de la conception de la structure du modèle dimensionnel (le schéma), vous pouvez soit créer un étoile or flocon de neige schéma. La structure doit être étroitement alignée sur le processus métier ; par conséquent, un schéma en étoile convient le mieux à notre exemple. La figure suivante montre notre Entity Relationship Diagram (ERD).

Dans les sections suivantes, nous détaillons les étapes pour implémenter les dimensions.
Mettre en scène les données sources
Avant de pouvoir créer et charger le tableau des dimensions, nous avons besoin des données source. Par conséquent, nous organisons les données source dans une table intermédiaire ou temporaire. Ceci est souvent appelé le couche intermédiaire, qui est la copie brute des données source. Pour ce faire dans Amazon Redshift, nous utilisons le commande COPIER pour charger les données à partir du compartiment S3 public Dimensional-Modeling-in-Amazon-Redshift situé sur le us-east-1 Région. Notez que la commande COPY utilise un Gestion des identités et des accès AWS (IAM) rôle avec accès à Amazon S3. Le rôle doit être associé au cluster. Effectuez les étapes suivantes pour préparer les données sources :
- Créez la
venuetableau sources :
- Chargez les données du lieu :
- Créez la
salestableau sources :
- Chargez les données de la source des ventes :
- Créez la
calendartable:
- Chargez les données du calendrier :
Créer le tableau des dimensions
La conception du tableau des dimensions peut dépendre des besoins de votre entreprise. Par exemple, avez-vous besoin de suivre les modifications apportées aux données au fil du temps ? Il y a sept types de dimensions différents. Pour notre exemple, nous utilisons Type 1 parce que nous n'avons pas besoin de suivre les changements historiques. Pour plus d'informations sur le type 2, reportez-vous à Simplifiez le chargement des données dans les dimensions à évolution lente de type 2 dans Amazon Redshift. La table des dimensions sera dénormalisée avec une clé primaire, une clé de substitution et quelques champs ajoutés pour indiquer les modifications apportées à la table. Voir le code suivant :
Quelques notes sur la création de la création du tableau des dimensions :
- Les noms de champs sont transformés en noms commerciaux
- Notre clé primaire est
VenueID, que nous utilisons pour identifier de manière unique un lieu où la vente a eu lieu - Deux lignes supplémentaires seront ajoutées, indiquant quand un enregistrement a été inséré et mis à jour (pour suivre les modifications)
- Nous utilisons un Style de distribution AUTO donner à Amazon Redshift la responsabilité de choisir et d'ajuster le style de distribution
Un autre facteur important à considérer dans la modélisation dimensionnelle est l'utilisation de clés de substitution. Les clés de substitution sont des clés artificielles utilisées dans la modélisation dimensionnelle pour identifier de manière unique chaque enregistrement dans une table de dimension. Ils sont généralement générés sous la forme d'un entier séquentiel et n'ont aucune signification dans le domaine métier. Ils offrent plusieurs avantages, tels que la garantie de l'unicité et l'amélioration des performances dans les jointures, car ils sont généralement plus petits que les clés naturelles et, en tant que clés de substitution, ils ne changent pas au fil du temps. Cela nous permet d'être cohérents et de joindre faits et dimensions plus facilement.
Dans Amazon Redshift, les clés de substitution sont généralement créées à l'aide du mot clé IDENTITY. Par exemple, l'instruction CREATE précédente crée une table de dimension avec un VenueSkey Clé de substitution. Le VenueSkey La colonne est automatiquement remplie avec des valeurs uniques lorsque de nouvelles lignes sont ajoutées au tableau. Cette colonne peut ensuite être utilisée pour joindre la table venue à la FactSaleTransactions tableau.
Quelques conseils pour concevoir des clés de substitution :
- Utilisez un petit type de données à largeur fixe pour la clé de substitution. Cela améliorera les performances et réduira l'espace de stockage.
- Utilisez le mot clé IDENTITY ou générez la clé de substitution à l'aide d'une valeur séquentielle ou GUID. Cela garantira que la clé de substitution est unique et ne peut pas être modifiée.
Charger la table de gradation à l'aide de MERGE
Il existe de nombreuses façons de charger votre table de gradation. Certains facteurs doivent être pris en compte, par exemple les performances, le volume de données et peut-être les temps de chargement des SLA. Avec le FUSIONNER , nous effectuons une upsert sans avoir besoin de spécifier plusieurs commandes d'insertion et de mise à jour. Vous pouvez configurer le FUSIONNER déclaration dans un procédure stockée pour remplir les données. Vous planifiez ensuite la procédure stockée pour qu'elle s'exécute par programme via l'éditeur de requête, ce que nous démontrons plus loin dans l'article. Le code suivant crée une procédure stockée appelée SalesMart.DimVenueLoad:
Quelques notes sur le chargement des dimensions :
- Lorsqu'un enregistrement est inséré pour la première fois, la date insérée et la date mise à jour seront renseignées. Lorsque des valeurs changent, les données sont mises à jour et la date de mise à jour reflète la date à laquelle elle a été modifiée. La date insérée reste.
- Étant donné que les données seront utilisées par des utilisateurs professionnels, nous devons remplacer les valeurs NULL, le cas échéant, par des valeurs plus adaptées à l'entreprise.
Identifier et mettre en œuvre les faits
Maintenant que nous avons déclaré que notre grain était l'événement d'une vente qui a eu lieu à un moment précis, notre table de faits stockera les faits numériques pour notre processus commercial.
Nous avons identifié les faits numériques suivants à mesurer :
- Quantité de billets vendus par vente
- Commission pour la vente
Mettre en œuvre le fait
Il y a trois types de tables de faits (table de faits de transaction, table de faits d'instantanés périodiques et table de faits d'instantanés cumulés). Chacun offre une vision différente du processus métier. Pour notre exemple, nous utilisons une table de faits de transaction. Effectuez les étapes suivantes :
- Créer la table de faits
Une date insérée avec une valeur par défaut est ajoutée, indiquant si et quand un enregistrement a été chargé. Vous pouvez l'utiliser lors du rechargement de la table de faits pour supprimer les données déjà chargées afin d'éviter les doublons.
Le chargement de la table de faits consiste en une simple instruction d'insertion joignant vos dimensions associées. Nous rejoignons de la DimVenue tableau qui a été créé, qui décrit nos faits. C'est la meilleure pratique mais facultatif d'avoir date du calendrier dimensions, qui permettent à l'utilisateur final de naviguer dans la table de faits. Les données peuvent être soit chargées lorsqu'il y a une nouvelle vente, soit quotidiennement ; c'est là que la date insérée ou la date de chargement est utile.
Nous chargeons la table de faits à l'aide d'une procédure stockée et utilisons un paramètre de date.
- Créez la procédure stockée avec le code suivant. Pour conserver la même intégrité des données que celle que nous avons appliquée dans le chargement de la dimension, nous remplaçons les valeurs NULL, le cas échéant, par des valeurs plus appropriées :
- Chargez les données en appelant la procédure avec la commande suivante :
Planifier le chargement des données
Nous pouvons désormais automatiser le processus de modélisation en planifiant les procédures stockées dans Amazon Redshift Query Editor V2. Effectuez les étapes suivantes :
- Nous appelons d'abord le chargement de dimension et une fois le chargement de dimension exécuté avec succès, le chargement de fait commence :
Si le chargement de la dimension échoue, le chargement des faits ne s'exécutera pas. Cela garantit la cohérence des données car nous ne voulons pas charger la table de faits avec des dimensions obsolètes.
- Pour programmer le chargement, choisissez Horaires dans l'éditeur de requête V2.

- Nous planifions l'exécution de la requête tous les jours à 5h00.
- En option, vous pouvez ajouter des notifications d'échec en activant Service de notification simple d'Amazon (Amazon SNS).

Rapporter et analyser les données dans Amazon Quicksight
QuickSight est un service d'intelligence d'affaires qui facilite la fourniture d'informations. En tant que service entièrement géré, QuickSight vous permet de créer et de publier facilement des tableaux de bord interactifs accessibles depuis n'importe quel appareil et intégrés à vos applications, portails et sites Web.
Nous utilisons notre data mart pour présenter visuellement les faits sous forme de tableau de bord. Pour démarrer et configurer QuickSight, reportez-vous à Créer un ensemble de données à l'aide d'une base de données qui n'est pas découverte automatiquement.
Après avoir créé votre source de données dans QuickSight, nous joignons les données modélisées (data mart) en fonction de notre clé de substitution skey. Nous utilisons cet ensemble de données pour visualiser le magasin de données.

Notre tableau de bord final contiendra les informations du magasin de données et répondra aux questions commerciales critiques, telles que la commission totale par lieu et les dates avec les ventes les plus élevées. La capture d'écran suivante montre le produit final du magasin de données.

Nettoyer
Pour éviter d'encourir des frais futurs, supprimez toutes les ressources que vous avez créées dans le cadre de cette publication.
Conclusion
Nous avons maintenant mis en place avec succès un magasin de données à l'aide de notre DimVenue, DimCalendaret une FactSaleTransactions les tables. Notre entrepôt n'est pas complet; car nous pouvons étendre le data mart avec plus de faits et mettre en œuvre plus de marts, et à mesure que le processus métier et les exigences augmentent avec le temps, l'entrepôt de données augmentera également. Dans cet article, nous avons donné une vue de bout en bout sur la compréhension et la mise en œuvre de la modélisation dimensionnelle dans Amazon Redshift.
Commencez avec votre Redshift d'Amazon modèle dimensionnel aujourd'hui.
À propos des auteurs
 Bernard Verser est un ingénieur cloud expérimenté avec des années d'expérience dans la création de modèles de données évolutifs et efficaces, la définition de stratégies d'intégration de données et la garantie de la gouvernance et de la sécurité des données. Il est passionné par l'utilisation des données pour générer des informations, tout en s'alignant sur les exigences et les objectifs de l'entreprise.
Bernard Verser est un ingénieur cloud expérimenté avec des années d'expérience dans la création de modèles de données évolutifs et efficaces, la définition de stratégies d'intégration de données et la garantie de la gouvernance et de la sécurité des données. Il est passionné par l'utilisation des données pour générer des informations, tout en s'alignant sur les exigences et les objectifs de l'entreprise.
 Casserole Abhishek est un spécialiste WWSO SA-Analytics travaillant avec les clients du secteur public d'AWS Inde. Il s'engage avec les clients pour définir une stratégie basée sur les données, fournir des sessions approfondies sur les cas d'utilisation de l'analyse et concevoir des applications analytiques évolutives et performantes. Il a 12 ans d'expérience et est passionné par les bases de données, l'analyse et l'IA/ML. Il est un grand voyageur et essaie de capturer le monde à travers l'objectif de son appareil photo.
Casserole Abhishek est un spécialiste WWSO SA-Analytics travaillant avec les clients du secteur public d'AWS Inde. Il s'engage avec les clients pour définir une stratégie basée sur les données, fournir des sessions approfondies sur les cas d'utilisation de l'analyse et concevoir des applications analytiques évolutives et performantes. Il a 12 ans d'expérience et est passionné par les bases de données, l'analyse et l'IA/ML. Il est un grand voyageur et essaie de capturer le monde à travers l'objectif de son appareil photo.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- A Propos
- accélérer
- accès
- accédé
- avec précision
- à travers
- Agis
- ajouter
- ajoutée
- Supplémentaire
- Après
- AI / ML
- aligner
- aligner
- permettre
- permet
- déjà
- am
- Amazon
- Amazon Web Services
- an
- selon une analyse de l’Université de Princeton
- Analytique
- analytique
- il analyse
- ainsi que le
- répondre
- tous
- applications
- appliqué
- approprié
- architecture
- SONT
- artificiel
- AS
- aspects
- associé
- At
- attributs
- auto
- automatiser
- automatiquement
- éviter
- AWS
- b
- basé
- BE
- car
- commencer
- avantages.
- LES MEILLEURS
- intégré
- la performance des entreprises
- l'intelligence d'entreprise
- PROCESSUS D'AFFAIRE
- processus d'affaires
- mais
- by
- Calendrier
- Appelez-nous
- appelé
- appel
- appareil photo
- CAN
- capturer
- maisons
- cas
- Causes
- certaines
- Change
- modifié
- Modifications
- en changeant
- caractère
- des charges
- Selectionnez
- clair
- clairement
- étroitement
- le cloud
- code
- Colonne
- vient
- commission
- Commun
- Sociétés
- Société
- complet
- Considérer
- cohérent
- consiste
- contexte
- correct
- pourriez
- engendrent
- créée
- crée des
- La création
- création
- critique
- Clients
- Tous les jours
- tableau de bord
- tableaux de bord
- données
- intégration de données
- Lac de données
- entrepôt de données
- data-driven
- Stratégie axée sur les données
- Base de données
- bases de données
- Date
- Dates
- datetime
- journée
- profond
- plongée profonde
- Réglage par défaut
- définir
- livrer
- démontrer
- départements
- Dérivé
- décrire
- Conception
- conception
- détail
- dispositif
- différent
- Dimension
- dimensions
- discuter
- distinct
- distribution
- do
- domaine
- fait
- Ne pas
- down
- motivation
- doublons
- chacun
- Plus tôt
- même
- Easy
- éditeur
- efficace
- non plus
- intégré
- permettre
- permettant
- fin
- end-to-end
- engage
- ingénieur
- assurer
- Assure
- assurer
- Tout
- entité
- Ether (ETH)
- événement
- événements
- Chaque
- tous les jours
- exemple
- exemples
- Développer vous
- d'experience
- expérimenté
- Exposition
- extrait
- fait
- facteur
- facteurs
- réalités
- échoue
- Échec
- Fonctionnalités:
- few
- champ
- Des champs
- cinquième
- Figure
- une fonction filtre
- finale
- Prénom
- première fois
- s'adapter
- concentré
- Abonnement
- Pour
- formulaire
- le format
- quatre
- De
- d’étiquettes électroniques entièrement
- plus
- avenir
- Gain
- générer
- généré
- génère
- obtenez
- obtention
- Donner
- donné
- Bien
- gouvernance
- Croître
- pratique
- Vous avez
- he
- le plus élevé
- sa
- historique
- Idées
- Comment
- How To
- HTML
- http
- HTTPS
- IAM
- identifié
- identifier
- identifier
- Identite
- if
- illustre
- Impact
- Mettre en oeuvre
- mis en œuvre
- la mise en œuvre
- important
- améliorer
- l'amélioration de
- in
- Y compris
- Inde
- indiquer
- indiquant
- info
- idées.
- des services
- l'intégration
- intégrité
- Intelligence
- Interactif
- développement
- IT
- SES
- rejoindre
- rejoint
- joindre
- Joint
- jpg
- XNUMX éléments à
- en gardant
- ACTIVITES
- clés
- lac
- langue
- plus tard
- Nouveautés
- couche
- à gauche
- Lens
- Allons-y
- Niveau
- Gamme
- charge
- chargement
- charges
- situé
- recherchez-
- LES PLANTES
- FAIT DU
- gérés
- Stratégie
- appariés
- sens
- mesurer
- mentionné
- aller
- Métrique
- l'esprit
- erreur
- modèle
- modélisation statistique
- la modélisation
- numériques jumeaux (digital twin models)
- Mois
- PLUS
- (en fait, presque toutes)
- plusieurs
- noms
- Nature
- NAVIGUER
- Besoin
- besoin
- Besoins
- Nouveauté
- Notes
- déclaration
- Notifications
- maintenant
- nombreux
- objectifs
- of
- code
- souvent
- on
- uniquement
- opérationnel
- or
- organisation
- nos
- plus de
- global
- paramètre
- partie
- passionné
- /
- effectuer
- performant
- être
- périodique
- Place
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- peuplé
- Post
- power
- pratique
- conditions préalables
- représentent
- primaire
- procédure
- procédures
- processus
- les process
- Produit
- fournir
- à condition de
- fournit
- public
- publier
- des fins
- fréquemment posées
- vite.
- augmenter
- raw
- les données brutes
- record
- Articles
- réduire
- visée
- reflète
- région
- relation amoureuse
- reste
- supprimez
- remplacer
- rapport
- Rapports
- Rapports
- Exigences
- Resources
- responsabilité
- Rôle
- Roulent
- RANGÉE
- Courir
- fonctionne
- SOLDE
- vente
- même
- Exemple d'ensemble de données
- évolutive
- calendrier
- ordonnancement
- les sections
- secteur
- sécurité
- sur le lien
- séparé
- sert
- service
- Services
- brainstorming
- set
- plusieurs
- devrait
- montrer
- Spectacles
- étapes
- simplicité
- unique
- Lentement
- petit
- faibles
- Instantané
- So
- vendu
- sur mesure
- quelques
- Identifier
- Sources
- Space
- spécialiste
- groupe de neurones
- spécifiquement
- Étape
- mise en scène
- Étoile
- j'ai commencé
- Commencez
- Déclaration
- étapes
- Étapes
- storage
- Boutique
- stockée
- les stratégies
- de Marketing
- structure
- réussi
- Avec succès
- tel
- combustion propre
- table
- temporaire
- dizaines
- conditions
- que
- qui
- La
- La Source
- le monde
- leur
- puis
- Là.
- donc
- Ces
- l'ont
- this
- milliers
- Avec
- billet
- la vente de billets
- billets
- fiable
- fois
- horodatage
- conseils
- à
- aujourd'hui
- ensemble
- a
- Total
- suivre
- transaction
- Transformer
- transformé
- voyageur
- type
- types
- typiquement
- compréhension
- expérience unique et authentique
- uniquement
- unicité
- inconnu
- Mises à jour
- a actualisé
- us
- Utilisation
- utilisé
- cas d'utilisation
- d'utiliser
- utilisateurs
- Usages
- en utilisant
- d'habitude
- Précieux
- Plus-value
- Valeurs
- divers
- Lieu
- lieux
- via
- Voir
- le volume
- walkthrough
- souhaitez
- Entrepots
- était
- façons
- we
- web
- services Web
- sites Internet
- semaine
- quand
- qui
- tout en
- sera
- comprenant
- dans les
- sans
- de travail
- world
- faux
- an
- années
- you
- Votre
- zéphyrnet