La résilience joue un rôle central dans le développement de toute charge de travail, et IA générative les charges de travail ne sont pas différentes. Il existe des considérations uniques lors de l’ingénierie des charges de travail d’IA générative dans une optique de résilience. Comprendre et prioriser la résilience est crucial pour que les charges de travail d’IA générative répondent aux exigences de disponibilité organisationnelle et de continuité des activités. Dans cet article, nous discutons des différentes piles d'une charge de travail d'IA générative et de ce que devraient être ces considérations.
IA générative full stack
Bien qu’une grande partie de l’enthousiasme suscité par l’IA générative se concentre sur les modèles, une solution complète implique des personnes, des compétences et des outils issus de plusieurs domaines. Considérez l'image suivante, qui est une vue AWS de la pile d'applications émergentes a16z pour les grands modèles de langage (LLM).
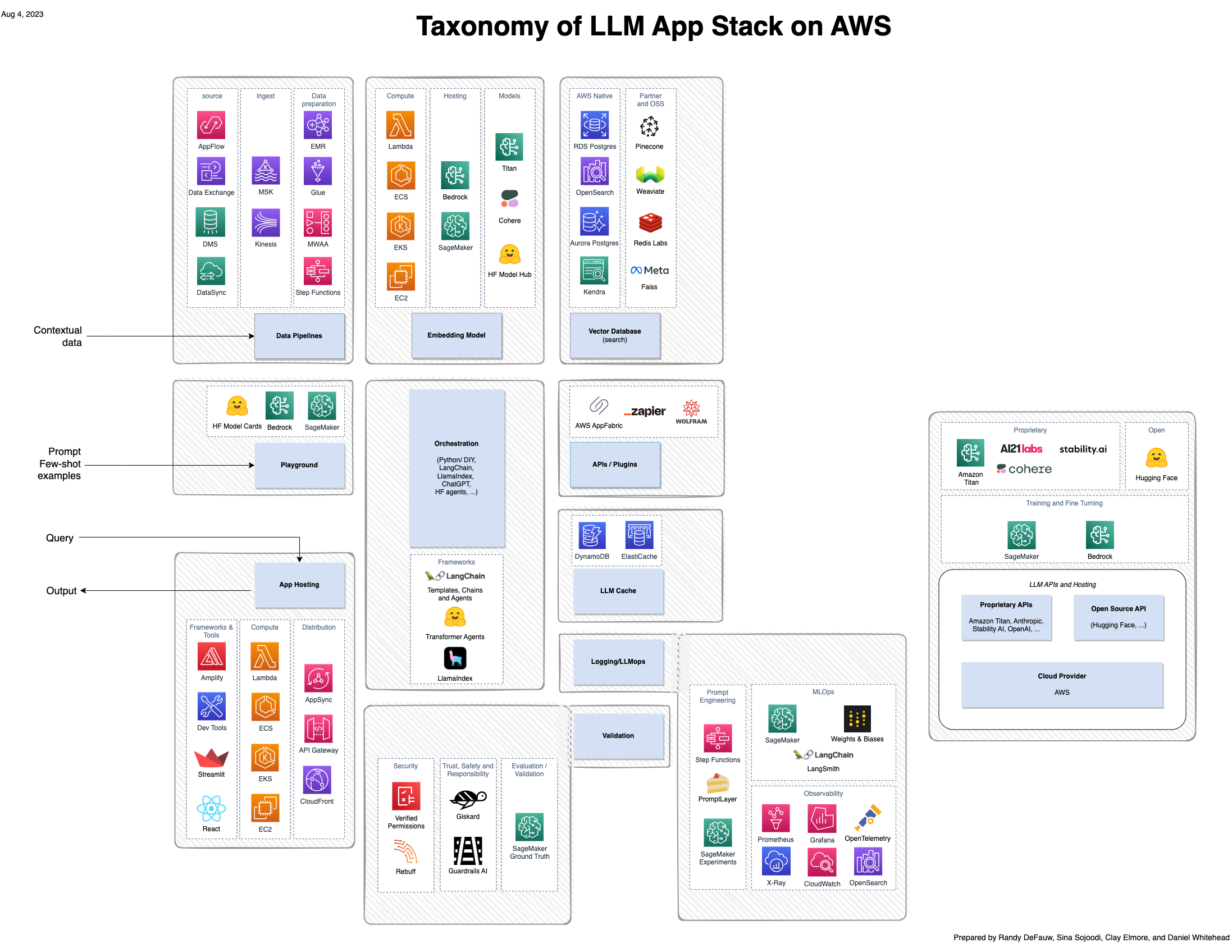
Par rapport à une solution plus traditionnelle construite autour de l’IA et du machine learning (ML), une solution d’IA générative implique désormais les éléments suivants :
- De nouveaux rôles – Vous devez prendre en compte les préparateurs de modèles ainsi que les constructeurs de modèles et les intégrateurs de modèles
- Nouveaux outils – La pile MLOps traditionnelle ne s'étend pas pour couvrir le type de suivi des expériences ou d'observabilité nécessaire à l'ingénierie rapide ou aux agents qui invoquent des outils pour interagir avec d'autres systèmes.
Raisonnement des agents
Contrairement aux modèles d'IA traditionnels, la Retrieval Augmented Generation (RAG) permet d'obtenir des réponses plus précises et contextuellement pertinentes en intégrant des sources de connaissances externes. Voici quelques considérations lors de l’utilisation de RAG :
- La définition de délais d'attente appropriés est importante pour l'expérience client. Rien n’indique plus une mauvaise expérience utilisateur que d’être au milieu d’une conversation et d’être déconnecté.
- Assurez-vous de valider les données d'entrée d'invite et la taille d'entrée d'invite pour les limites de caractères allouées définies par votre modèle.
- Si vous effectuez une ingénierie des invites, vous devez conserver vos invites dans un magasin de données fiable. Cela protégera vos invites en cas de perte accidentelle ou dans le cadre de votre stratégie globale de reprise après sinistre.
Canalisations de données
Dans les cas où vous devez fournir des données contextuelles au modèle de base à l'aide du modèle RAG, vous avez besoin d'un pipeline de données capable d'ingérer les données source, de les convertir en vecteurs d'intégration et de stocker les vecteurs d'intégration dans une base de données vectorielles. Ce pipeline peut être un pipeline par lots si vous préparez des données contextuelles à l'avance, ou un pipeline à faible latence si vous intégrez de nouvelles données contextuelles à la volée. Dans le cas du traitement par lots, il existe quelques défis par rapport aux pipelines de données classiques.
Les sources de données peuvent être des documents PDF sur un système de fichiers, des données provenant d'un système SaaS (Software as a Service) comme un outil CRM, ou des données provenant d'un wiki ou d'une base de connaissances existante. L'ingestion à partir de ces sources est différente des sources de données classiques telles que les données de journal dans un Service de stockage simple Amazon (Amazon S3) ou des données structurées provenant d'une base de données relationnelle. Le niveau de parallélisme que vous pouvez atteindre peut être limité par le système source, vous devez donc tenir compte de la limitation et utiliser des techniques d'attente. Certains systèmes sources peuvent être fragiles, vous devez donc intégrer une gestion des erreurs et une logique de nouvelle tentative.
Le modèle d'intégration peut constituer un goulot d'étranglement en termes de performances, que vous l'exécutiez localement dans le pipeline ou que vous appeliez un modèle externe. Les modèles d'intégration sont des modèles de base qui s'exécutent sur des GPU et n'ont pas une capacité illimitée. Si le modèle s'exécute localement, vous devez attribuer le travail en fonction de la capacité du GPU. Si le modèle s'exécute en externe, vous devez vous assurer que vous ne saturez pas le modèle externe. Dans les deux cas, le niveau de parallélisme que vous pouvez atteindre sera dicté par le modèle d’intégration plutôt que par la quantité de CPU et de RAM dont vous disposez dans le système de traitement par lots.
Dans le cas d'une faible latence, vous devez tenir compte du temps nécessaire pour générer les vecteurs d'intégration. L'application appelante doit appeler le pipeline de manière asynchrone.
Bases de données vectorielles
Une base de données vectorielles a deux fonctions : stocker les vecteurs intégrés et exécuter une recherche de similarité pour trouver les vecteurs les plus proches. k correspond à un nouveau vecteur. Il existe trois types généraux de bases de données vectorielles :
- Options SaaS dédiées comme Pinecone.
- Fonctionnalités de base de données vectorielles intégrées à d'autres services. Cela inclut les services AWS natifs tels que Service Amazon OpenSearch ainsi que les Amazon Aurora.
- Options en mémoire pouvant être utilisées pour les données transitoires dans des scénarios à faible latence.
Nous ne couvrons pas en détail les capacités de recherche de similarité dans cet article. Bien qu’ils soient importants, ils constituent un aspect fonctionnel du système et n’affectent pas directement la résilience. Au lieu de cela, nous nous concentrons sur les aspects de résilience d’une base de données vectorielle en tant que système de stockage :
- Latence – La base de données vectorielles peut-elle fonctionner correctement face à une charge élevée ou imprévisible ? Dans le cas contraire, l’application appelante doit gérer la limitation du débit, l’attente et réessayer.
- Évolutivité – Combien de vecteurs le système peut-il contenir ? Si vous dépassez la capacité de la base de données vectorielle, vous devrez envisager le partitionnement ou d'autres solutions.
- Haute disponibilité et reprise après sinistre – Les vecteurs d’intégration sont des données précieuses et leur recréation peut s’avérer coûteuse. Votre base de données vectorielles est-elle hautement disponible dans une seule région AWS ? A-t-il la capacité de répliquer les données vers une autre région à des fins de reprise après sinistre ?
Niveau d'application
Il existe trois considérations uniques pour le niveau application lors de l’intégration de solutions d’IA générative :
- Latence potentiellement élevée – Les modèles Foundation s'exécutent souvent sur de grandes instances GPU et peuvent avoir une capacité limitée. Assurez-vous d'utiliser les meilleures pratiques en matière de limitation de débit, d'attente et de nouvelle tentative, ainsi que de délestage. Utilisez des conceptions asynchrones afin qu'une latence élevée n'interfère pas avec l'interface principale de l'application.
- Dispositif de sécurité – Si vous utilisez des agents, des outils, des plugins ou d'autres méthodes pour connecter un modèle à d'autres systèmes, portez une attention particulière à votre posture de sécurité. Les modèles peuvent tenter d’interagir avec ces systèmes de manière inattendue. Suivez la pratique normale d'accès avec le moindre privilège, par exemple en restreignant les invites entrantes provenant d'autres systèmes.
- Des cadres en évolution rapide – Les frameworks open source comme LangChain évoluent rapidement. Utilisez une approche microservices pour isoler les autres composants de ces frameworks moins matures.
Compétences
Nous pouvons penser à la capacité dans deux contextes : les pipelines de données de modèles d'inférence et de formation. La capacité est un élément à prendre en compte lorsque les organisations construisent leurs propres pipelines. Les exigences en matière de CPU et de mémoire sont deux des exigences les plus importantes lors du choix des instances pour exécuter vos charges de travail.
Les instances capables de prendre en charge des charges de travail d'IA générative peuvent être plus difficiles à obtenir que votre type d'instance à usage général moyen. La flexibilité de l'instance peut faciliter la capacité et la planification de la capacité. Selon la région AWS dans laquelle vous exécutez votre charge de travail, différents types d'instances sont disponibles.
Pour les parcours utilisateur critiques, les organisations souhaiteront envisager de réserver ou de pré-provisionner des types d'instances pour garantir la disponibilité en cas de besoin. Ce modèle permet d'obtenir une architecture statiquement stable, ce qui constitue une bonne pratique en matière de résilience. Pour en savoir plus sur la stabilité statique dans le pilier de fiabilité d'AWS Well-Architected Framework, reportez-vous à Utiliser la stabilité statique pour empêcher le comportement bimodal.
Observabilité
Outre les mesures de ressources que vous collectez généralement, comme l'utilisation du processeur et de la RAM, vous devez surveiller de près l'utilisation du GPU si vous hébergez un modèle sur Amazon Sage Maker or Cloud de calcul élastique Amazon (Amazon EC2). L'utilisation du GPU peut changer de manière inattendue si le modèle de base ou les données d'entrée changent, et le manque de mémoire GPU peut mettre le système dans un état instable.
Plus haut dans la pile, vous souhaiterez également suivre le flux d’appels à travers le système, en capturant les interactions entre les agents et les outils. Étant donné que l'interface entre les agents et les outils est moins formellement définie qu'un contrat API, vous devez surveiller ces traces non seulement pour en vérifier les performances, mais également pour capturer de nouveaux scénarios d'erreur. Pour surveiller le modèle ou l'agent afin de détecter tout risque ou menace de sécurité, vous pouvez utiliser des outils tels que Service de garde Amazon.
Vous devez également capturer les lignes de base des vecteurs d'intégration, des invites, du contexte et de la sortie, ainsi que les interactions entre ceux-ci. Si ceux-ci changent au fil du temps, cela peut indiquer que les utilisateurs utilisent le système d'une nouvelle manière, que les données de référence ne couvrent pas l'espace des questions de la même manière ou que les résultats du modèle sont soudainement différents.
Reprise après sinistre
Avoir un plan de continuité des activités avec une stratégie de reprise après sinistre est indispensable pour toute charge de travail. Les charges de travail de l’IA générative ne sont pas différentes. Comprendre les modes de défaillance applicables à votre charge de travail vous aidera à orienter votre stratégie. Si vous utilisez des services gérés AWS pour votre charge de travail, tels que Socle amazonien et SageMaker, assurez-vous que le service est disponible dans votre région AWS de récupération. Au moment d'écrire ces lignes, ces services AWS ne prennent pas en charge la réplication native des données dans les régions AWS. Vous devez donc réfléchir à vos stratégies de gestion des données pour la reprise après sinistre, et vous devrez peut-être également effectuer des réglages précis dans plusieurs régions AWS.
Conclusion
Cet article décrit comment prendre en compte la résilience lors de la création de solutions d'IA générative. Bien que les applications d’IA générative présentent certaines nuances intéressantes, les modèles de résilience et les meilleures pratiques existants s’appliquent toujours. Il s'agit simplement d'évaluer chaque partie d'une application d'IA générative et d'appliquer les meilleures pratiques pertinentes.
Pour plus d'informations sur l'IA générative et son utilisation avec les services AWS, consultez les ressources suivantes :
À propos des auteurs
 Jennifer Moran est un architecte de solutions spécialiste senior de la résilience AWS basé à New York. Elle possède une expérience diversifiée, ayant travaillé dans de nombreuses disciplines techniques, notamment le développement de logiciels, le leadership agile et DevOps, et défend les femmes dans la technologie. Elle aime aider les clients à concevoir des solutions résilientes pour améliorer leur posture de résilience et parle publiquement de tous les sujets liés à la résilience.
Jennifer Moran est un architecte de solutions spécialiste senior de la résilience AWS basé à New York. Elle possède une expérience diversifiée, ayant travaillé dans de nombreuses disciplines techniques, notamment le développement de logiciels, le leadership agile et DevOps, et défend les femmes dans la technologie. Elle aime aider les clients à concevoir des solutions résilientes pour améliorer leur posture de résilience et parle publiquement de tous les sujets liés à la résilience.
 Randy DeFauw est architecte principal de solutions senior chez AWS. Il est titulaire d'un MSEE de l'Université du Michigan, où il a travaillé sur la vision par ordinateur pour les véhicules autonomes. Il est également titulaire d'un MBA de la Colorado State University. Randy a occupé divers postes dans le domaine technologique, allant de l'ingénierie logicielle à la gestion de produits. Il est entré dans l’espace du Big Data en 2013 et continue d’explorer ce domaine. Il travaille activement sur des projets dans le domaine du ML et a fait des présentations à de nombreuses conférences, notamment Strata et GlueCon.
Randy DeFauw est architecte principal de solutions senior chez AWS. Il est titulaire d'un MSEE de l'Université du Michigan, où il a travaillé sur la vision par ordinateur pour les véhicules autonomes. Il est également titulaire d'un MBA de la Colorado State University. Randy a occupé divers postes dans le domaine technologique, allant de l'ingénierie logicielle à la gestion de produits. Il est entré dans l’espace du Big Data en 2013 et continue d’explorer ce domaine. Il travaille activement sur des projets dans le domaine du ML et a fait des présentations à de nombreuses conférences, notamment Strata et GlueCon.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/designing-generative-ai-workloads-for-resilience/
- :possède
- :est
- :ne pas
- :où
- $UP
- 100
- 2013
- 90
- a
- a16z
- capacité
- Qui sommes-nous
- accès
- accidentellement
- Compte
- Avec cette connaissance vient le pouvoir de prendre
- atteindre
- Atteint
- à travers
- activement
- avancer
- avocat
- affecter
- à opposer à
- Agent
- agents
- agile
- AI
- Modèles AI
- Tous
- consacrée
- permet
- aussi
- Bien que
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- ainsi que les
- Une autre
- tous
- api
- appli
- en vigueur
- Application
- applications
- Appliquer
- Application
- une approche
- approprié
- architecture
- SONT
- Réservé
- autour
- AS
- d'aspect
- aspects
- At
- précaution
- augmentée
- autonome
- véhicules autonomes
- disponibilité
- disponibles
- moyen
- AWS
- fond
- Mal
- base
- basé
- BE
- car
- va
- LES MEILLEURS
- les meilleures pratiques
- jusqu'à XNUMX fois
- Big
- Big Data
- Le plus grand
- goulot
- construire
- constructeurs
- Développement
- construit
- la performance des entreprises
- continuité de l'activité
- mais
- by
- Appelez-nous
- appel
- Appels
- CAN
- capacités
- Compétences
- capturer
- Capturer
- maisons
- cas
- globaux
- Change
- Modifications
- caractère
- le chat
- choose
- Ville
- étroitement
- recueillir
- Colorado
- par rapport
- complet
- composants électriques
- calcul
- ordinateur
- Vision par ordinateur
- conférences
- Connecter les
- Considérer
- considération
- considérations
- contexte
- contextes
- contextuel
- continue
- continuité
- contrat
- convertir
- pourriez
- Couples
- couverture
- couvrant
- Processeur
- critique
- CRM
- crucial
- des clients
- expérience client
- Clients
- données
- gestion des données
- Base de données
- bases de données
- défini
- Selon
- décrit
- Conception
- conception
- Avec nos Bagues Halo
- détail
- Développement
- DevOps
- dicté
- différent
- difficile
- directement
- catastrophe
- disciplines
- déconnecté
- discuter
- plusieurs
- do
- INSTITUTIONNELS
- Ne fait pas
- domaines
- Ne pas
- chacun
- non plus
- enrobage
- économies émergentes.
- ENGINEERING
- assurer
- entré
- erreur
- Ether (ETH)
- évaluer
- évolution
- exemple
- dépassent
- Excitation
- existant
- cher
- d'experience
- expérience
- explorez
- étendre
- externe
- extérieurement
- supplémentaire
- Échec
- Fonctionnalités:
- Déposez votre dernière attestation
- Trouvez
- Flexibilité
- flux
- Focus
- se concentre
- suivre
- Abonnement
- Pour
- Officiellement
- Fondation
- Framework
- cadres
- de
- fonctionnel
- fonctions
- Général
- à usage général
- générer
- génération
- génératif
- IA générative
- obtention
- GPU
- GPU
- guide
- manipuler
- Maniabilité
- Vous avez
- ayant
- he
- Tenue
- vous aider
- aider
- Haute
- très
- appuyez en continu
- détient
- hôte
- Comment
- How To
- HTML
- http
- HTTPS
- if
- important
- améliorer
- in
- inclut
- Y compris
- Nouveau
- incorporation
- indiquer
- d'information
- contribution
- instance
- cas
- plutôt ;
- Intégration
- interagir
- interactions
- intéressant
- Interfaces
- interférer
- développement
- implique
- IT
- Voyages
- juste
- spécialisées
- langue
- gros
- Latence
- Leadership
- APPRENTISSAGE
- apprentissage
- Lens
- moins
- Niveau
- comme
- limité
- limiter
- limites
- llm
- charge
- localement
- enregistrer
- logique
- Style
- perte
- Lot
- click
- machine learning
- Entrée
- a prendre une
- gérés
- gestion
- de nombreuses
- allumettes
- Matière
- mature
- Mai..
- MBA
- Découvrez
- Mémoire
- méthodes
- Métrique
- Michigan
- microservices
- Milieu
- ML
- MLOps
- modèle
- numériques jumeaux (digital twin models)
- modes
- Surveiller
- PLUS
- beaucoup
- plusieurs
- must
- indigène
- nativement
- nécessaire
- Besoin
- nécessaire
- Besoins
- Nouveauté
- New York
- New York City
- aucune
- Ordinaire
- rien
- maintenant
- nuances
- nombreux
- obtenir
- of
- souvent
- on
- uniquement
- ouvert
- open source
- Options
- or
- organisationnel
- organisations
- Autre
- ande
- sortie
- plus de
- global
- propre
- partie
- Patron de Couture
- motifs
- Payer
- Personnes
- effectuer
- performant
- effectuer
- image
- Pilier
- pipeline
- pivot
- plan
- et la planification de votre patrimoine
- Platon
- Intelligence des données Platon
- PlatonDonnées
- joue
- plugins
- positions
- Post
- pratique
- pratiques
- Préparer
- présenté
- empêcher
- Directeur
- priorisation
- traitement
- Produit
- gestion des produits
- projets
- instructions
- fournir
- publiquement
- des fins
- mettre
- question
- chiffon
- RAM
- allant
- rapidement
- Tarif
- plutôt
- récupération
- reportez-vous
- référence
- Indépendamment
- région
- régions
- en relation
- pertinent
- fiabilité
- fiable
- réplication
- Exigences
- la résilience
- résilient
- ressource
- Resources
- réponses
- restreindre
- récupération
- risques
- Rôle
- Courir
- pour le running
- fonctionne
- SaaS.
- sagemaker
- même
- dit
- scénarios
- Rechercher
- recherche
- sécurité
- risques de sécurité
- supérieur
- service
- Services
- plusieurs
- sharding
- elle
- perte
- devrait
- étapes
- unique
- Taille
- compétences
- So
- Logiciels
- logiciel en tant que service
- développement de logiciels
- génie logiciel
- sur mesure
- Solutions
- quelques
- Identifier
- Sources
- Space
- parle
- spécialiste
- Stabilité
- stable
- empiler
- Combos
- Région
- Encore
- storage
- Boutique
- les stratégies
- de Marketing
- structuré
- tel
- Support
- sûr
- combustion propre
- Système
- Prenez
- prend
- taxonomie
- technologie
- Technique
- techniques
- Technologie
- que
- qui
- Les
- La Source
- leur
- Les
- Là.
- Ces
- l'ont
- penser
- this
- ceux
- des menaces
- trois
- Avec
- étage
- fiable
- à
- outil
- les outils
- Les sujets
- tracer
- Tracking
- traditionnel
- Formation
- Essai
- deux
- type
- types
- débutante
- typiquement
- compréhension
- Inattendu
- expérience unique et authentique
- université
- Université du Michigan
- illimité
- imprévisible
- utilisé
- d'utiliser
- Utilisateur
- Expérience utilisateur
- utilisateurs
- en utilisant
- VALIDER
- Précieux
- variété
- Véhicules
- Voir
- vision
- souhaitez
- Façon..
- façons
- we
- web
- services Web
- WELL
- Quoi
- quand
- que
- qui
- sera
- comprenant
- Femme
- les femmes dans la technologie
- activités principales
- travaillé
- de travail
- écriture
- york
- you
- Votre
- zéphyrnet