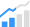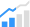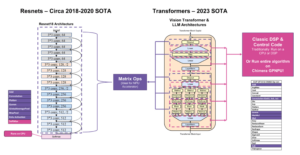
Un article technique intitulé « Massive Data-Centric Parallelism in the Chiplet Era » a été publié par des chercheurs de l’Université de Princeton.
Résumé:
« Traditionnellement, les applications massivement parallèles sont exécutées sur des systèmes distribués, où les nœuds de calcul sont suffisamment éloignés pour que les schémas de parallélisation doivent minimiser la communication et la synchronisation pour assurer l'évolutivité. Le mappage des charges de travail à forte intensité de communication vers des systèmes distribués nécessite un partitionnement complexe des problèmes et un prétraitement des ensembles de données. Avec la tendance actuelle axée sur l’IA consistant à avoir des milliers de processeurs interconnectés par puce, il existe une opportunité de repenser ces charges de travail goulots d’étranglement de communication. Ce goulot d'étranglement provient souvent de traversées de structures de données, qui entraînent des accès irréguliers à la mémoire et une mauvaise localisation du cache.
Des travaux récents ont introduit des schémas de parallélisation basés sur les tâches pour accélérer le parcours des graphes et d'autres charges de travail clairsemées. Les traversées de structure de données sont divisées en tâches et canalisées entre les unités de traitement (PU). Dalorex a démontré la plus grande évolutivité (jusqu'à des milliers de PU sur une seule puce) en disposant de l'intégralité de l'ensemble de données sur la puce, dispersé sur les PU et en exécutant les tâches au niveau du PU où les données sont locales. Cependant, cela a également soulevé des questions sur la manière d'évoluer vers des ensembles de données plus volumineux lorsque toute la mémoire est sur la puce, et à quel prix.
Pour relever ces défis, nous proposons une architecture évolutive composée d'une grille de chiplets Data-Centric Reconfigurable Array (DCRA). La reconfiguration au niveau du package permet de créer des produits à puce qui s'optimisent pour différentes mesures cibles, telles que le temps de mise en œuvre d'une solution, l'énergie ou le coût, tandis que les reconfigurations logicielles évitent la saturation du réseau lors de la mise à l'échelle vers des millions de PU sur de nombreux packages de puces. Nous évaluons six applications et quatre ensembles de données, avec plusieurs configurations et technologies de mémoire, pour fournir une analyse détaillée des performances, de la puissance et du coût de l'exécution de données locales à grande échelle. Notre parallélisation de Breadth-First-Search avec RMAT-26 sur un million de PU atteint 3323 XNUMX GTEPS.
Trouver la technique papier ici. Publié en avril 2023 (prépublication).
Orenes-Vera, Marcelo, Esin Tureci, David Wentzlaf et Margaret Martonosi. « Le parallélisme massif centré sur les données à l'ère des chiplets. » arXiv preprint arXiv: 2304.09389 (2023).
Services Connexes
Des mini-consortiums se forment autour des chiplets
Les marchés commerciaux de chipsets sont encore à un horizon lointain, mais les entreprises démarrent tôt avec des partenariats plus limités.
Risques de sécurité des chiplets sous-estimés
L'ampleur des défis de sécurité pour les puces commerciales est décourageante.
La course vers des chips de fonderie mixte
Les défis liés à l’assemblage de chiplets provenant de différentes fonderies commencent tout juste à émerger.
Considérations de conception et progrès récents dans les chipsets (UC Berkeley/Université de Pékin)
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- Frapper l'avenir avec Adryenn Ashley. Accéder ici.
- La source: https://semiengineering.com/data-centric-reconfigurable-array-dcra-chiplets-princeton/
- :est
- :où
- $UP
- 2023
- a
- accélérer
- atteindre
- à travers
- propos
- progrès
- Tous
- aussi
- an
- selon une analyse de l’Université de Princeton
- ainsi que
- applications
- Avril
- architecture
- SONT
- autour
- tableau
- AS
- At
- Début
- mais
- by
- cachette
- Causes
- globaux
- puce
- commercial
- Communication
- Sociétés
- compliqué
- composé
- informatique
- considérations
- Prix
- La création
- Courant
- données
- ensembles de données
- David
- démontré
- détaillé
- différent
- Loin
- distribué
- systèmes distribués
- "Early Bird"
- permet
- énergie
- assez
- Tout
- Ère
- évaluer
- exécution
- exécution
- Pour
- quatre
- De
- obtention
- graphique
- Grille
- Vous avez
- ayant
- le plus élevé
- horizon
- Comment
- How To
- Cependant
- HTTPS
- in
- interconnecté
- développement
- introduit
- IT
- juste
- plus importantes
- limité
- locales
- de nombreuses
- cartographie
- sur le dark web
- massivement
- Mémoire
- Métrique
- million
- des millions
- PLUS
- réseau et
- nœuds
- of
- on
- Opportunités
- Optimiser
- or
- Autre
- nos
- Forfaits
- Papier
- Parallèle
- partenariats
- Pékin
- performant
- Platon
- Intelligence des données Platon
- PlatonDonnées
- pauvres
- power
- princeton
- Problème
- traitement
- processeurs
- Produits
- proposer
- fournir
- publié
- fréquemment posées
- Race
- collectés
- atteint
- récent
- a besoin
- chercheurs
- risques
- Évolutivité
- évolutive
- Escaliers intérieurs
- mise à l'échelle
- épars
- Schémas
- sécurité
- risques de sécurité
- plusieurs
- unique
- SIX
- Logiciels
- scission
- Commencer
- Encore
- structure
- tel
- synchronisation
- Système
- Target
- tâches
- Technique
- Les technologies
- qui
- La
- Là.
- Ces
- this
- milliers
- titré
- à
- vers
- Trend
- unités
- université
- était
- we
- Quoi
- qui
- tout en
- comprenant
- vos contrats
- zéphyrnet