Il s'agit d'un article conjoint co-écrit par AWS et Voxel51. Voxel51 est la société à l'origine de FiftyOne, la boîte à outils open source permettant de créer des ensembles de données et des modèles de vision par ordinateur de haute qualité.
Une entreprise de vente au détail développe une application mobile pour aider les clients à acheter des vêtements. Pour créer cette application, ils ont besoin d'un ensemble de données de haute qualité contenant des images de vêtements, étiquetées avec différentes catégories. Dans cet article, nous montrons comment réutiliser un ensemble de données existant via le nettoyage, le prétraitement et le pré-étiquetage des données avec un modèle de classification à tir zéro dans Cinquante et un, et en ajustant ces étiquettes avec Vérité au sol Amazon SageMaker.
Vous pouvez utiliser Ground Truth et FiftyOne pour accélérer votre projet d'étiquetage des données. Nous illustrons comment utiliser de manière transparente les deux applications ensemble pour créer des ensembles de données étiquetés de haute qualité. Pour notre exemple de cas d'utilisation, nous travaillons avec le Jeu de données Fashion200K, publié à l'ICCV 2017.
Vue d'ensemble de la solution
Ground Truth est un service d'étiquetage de données entièrement autonome et géré qui permet aux scientifiques des données, aux ingénieurs en apprentissage automatique (ML) et aux chercheurs de créer des ensembles de données de haute qualité. Cinquante et un by voxel51 est une boîte à outils open source pour la conservation, la visualisation et l'évaluation des ensembles de données de vision par ordinateur afin que vous puissiez former et analyser de meilleurs modèles en accélérant vos cas d'utilisation.
Dans les sections suivantes, nous montrons comment effectuer les opérations suivantes :
- Visualisez le jeu de données dans FiftyOne
- Nettoyer l'ensemble de données avec filtrage et déduplication d'image dans FiftyOne
- Pré-étiqueter les données nettoyées avec une classification zéro coup dans FiftyOne
- Étiquetez le plus petit ensemble de données organisé avec Ground Truth
- Injectez les résultats étiquetés de Ground Truth dans FiftyOne et examinez les résultats étiquetés dans FiftyOne
Présentation des cas d'utilisation
Supposons que vous possédiez une entreprise de vente au détail et que vous souhaitiez créer une application mobile pour donner des recommandations personnalisées afin d'aider les utilisateurs à décider quoi porter. Vos utilisateurs potentiels recherchent une application qui leur indique quels vêtements de leur garde-robe fonctionnent bien ensemble. Vous voyez ici une opportunité : si vous pouvez identifier de bonnes tenues, vous pouvez l'utiliser pour recommander de nouveaux vêtements qui complètent les vêtements qu'un client possède déjà.
Vous voulez rendre les choses aussi simples que possible pour l'utilisateur final. Idéalement, quelqu'un qui utilise votre application n'a qu'à prendre des photos des vêtements de sa garde-robe, et vos modèles ML opèrent leur magie dans les coulisses. Vous pouvez former un modèle à usage général ou ajuster un modèle au style unique de chaque utilisateur avec une certaine forme de rétroaction.
Cependant, vous devez d'abord identifier le type de vêtement que l'utilisateur capture. Est-ce une chemise ? Une paire de pantalons? Ou autre chose? Après tout, vous ne voudrez probablement pas recommander une tenue qui a plusieurs robes ou plusieurs chapeaux.
Pour relever ce défi initial, vous souhaitez générer un ensemble de données d'entraînement composé d'images de divers vêtements avec différents motifs et styles. Pour créer un prototype avec un budget limité, vous souhaitez démarrer à l'aide d'un jeu de données existant.
Pour illustrer et vous guider tout au long du processus dans cet article, nous utilisons l'ensemble de données Fashion200K publié à l'ICCV 2017. Il s'agit d'un ensemble de données établi et bien cité, mais il n'est pas directement adapté à votre cas d'utilisation.
Bien que les articles vestimentaires soient étiquetés avec des catégories (et sous-catégories) et contiennent une variété d'étiquettes utiles extraites des descriptions originales des produits, les données ne sont pas systématiquement étiquetées avec des informations sur le motif ou le style. Votre objectif est de transformer cet ensemble de données existant en un ensemble de données d'entraînement robuste pour vos modèles de classification de vêtements. Vous devez nettoyer les données, en augmentant le schéma d'étiquetage avec des étiquettes de style. Et vous voulez le faire rapidement et avec le moins de dépenses possible.
Télécharger les données localement
Tout d'abord, téléchargez le fichier zip women.tar et le dossier labels (avec tous ses sous-dossiers) en suivant les instructions fournies dans le Référentiel GitHub de l'ensemble de données Fashion200K. Après les avoir décompressés, créez un répertoire parent fashion200k et déplacez-y les dossiers labels et women. Heureusement, ces images ont déjà été recadrées dans les cadres de détection d'objets, nous pouvons donc nous concentrer sur la classification plutôt que de nous soucier de la détection d'objets.
Malgré le "200K" dans son surnom, le répertoire des femmes que nous avons extrait contient 338,339 200 images. Pour générer l'ensemble de données officiel Fashion300,000K, les auteurs de l'ensemble de données ont exploré plus de XNUMX XNUMX produits en ligne, et seuls les produits dont les descriptions contiennent plus de quatre mots ont été retenus. Pour nos besoins, où la description du produit n'est pas essentielle, nous pouvons utiliser toutes les images explorées.
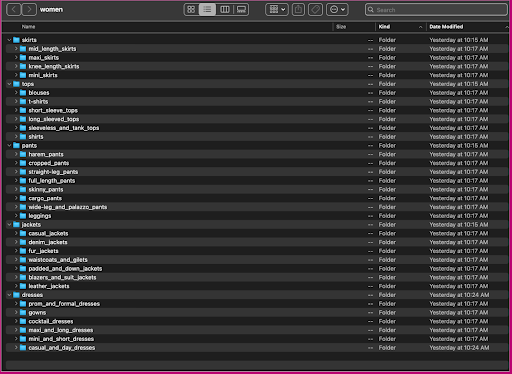
Examinons comment ces données sont organisées : dans le dossier des femmes, les images sont classées par type d'article de niveau supérieur (jupes, hauts, pantalons, vestes et robes) et par sous-catégorie de type d'article (chemisiers, t-shirts, chemises à manches longues hauts).
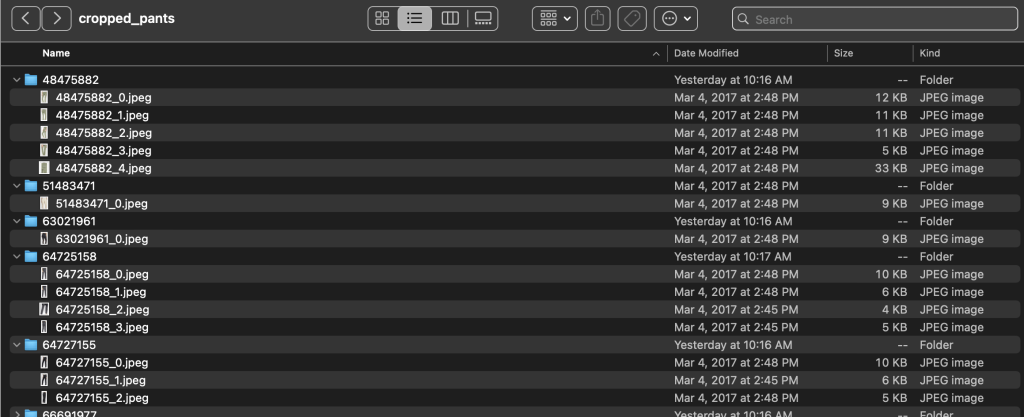
Dans les répertoires de sous-catégories, il existe un sous-répertoire pour chaque liste de produits. Chacun d'eux contient un nombre variable d'images. La sous-catégorie cropped_pants, par exemple, contient les listes de produits suivantes et les images associées.
Le dossier labels contient un fichier texte pour chaque type d'article de niveau supérieur, pour les fractionnements d'apprentissage et de test. Dans chacun de ces fichiers texte se trouve une ligne distincte pour chaque image, spécifiant le chemin d'accès relatif au fichier, un score et des balises de la description du produit.
Parce que nous réaffectons l'ensemble de données, nous combinons toutes les images d'entraînement et de test. Nous les utilisons pour générer un ensemble de données spécifiques à l'application de haute qualité. Une fois ce processus terminé, nous pouvons diviser au hasard l'ensemble de données résultant en de nouvelles divisions d'entraînement et de test.
Injecter, afficher et conserver un ensemble de données dans FiftyOne
Si vous ne l'avez pas déjà fait, installez FiftyOne open-source en utilisant pip :
Une bonne pratique consiste à le faire dans un nouvel environnement virtuel (venv ou conda). Importez ensuite les modules concernés. Importez la bibliothèque de base, fiftyone, le FiftyOne Brain, qui a des méthodes ML intégrées, le FiftyOne Zoo, à partir duquel nous chargerons un modèle qui générera pour nous des étiquettes de tir zéro, et le ViewField, qui nous permet de filtrer efficacement le données dans notre jeu de données :
Vous souhaitez également importer les modules glob et os Python, ce qui nous aidera à travailler avec les chemins et la correspondance de modèle sur le contenu du répertoire :
Nous sommes maintenant prêts à charger le jeu de données dans FiftyOne. Tout d'abord, nous créons un ensemble de données nommé fashion200k et le rendons persistant, ce qui nous permet de sauvegarder les résultats d'opérations intensives en calcul, nous n'avons donc besoin de calculer ces quantités qu'une seule fois.
Nous pouvons maintenant parcourir tous les répertoires de sous-catégories, en ajoutant toutes les images dans les répertoires de produits. Nous ajoutons une étiquette de classification FiftyOne à chaque échantillon avec le nom de champ article_type, rempli par la catégorie d'article de niveau supérieur de l'image. Nous ajoutons également des informations de catégorie et de sous-catégorie sous forme de balises :
À ce stade, nous pouvons visualiser notre jeu de données dans l'application FiftyOne en lançant une session :
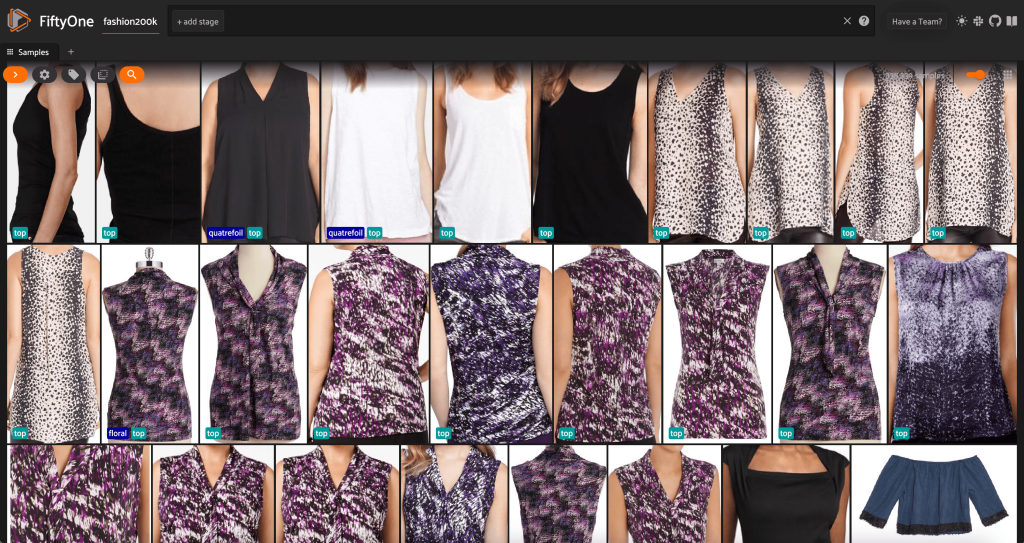
Nous pouvons également imprimer un résumé de l'ensemble de données en Python en exécutant print(dataset):
Nous pouvons également ajouter les balises de la labels répertoire vers les échantillons de notre jeu de données :
En regardant les données, certaines choses deviennent claires :
- Certaines des images sont assez granuleuses, avec une faible résolution. Cela est probablement dû au fait que ces images ont été générées en recadrant les images initiales dans les cadres de détection d'objets.
- Certains vêtements sont portés par une personne et d'autres sont photographiés seuls. Ces détails sont encapsulés par le
viewpointpropriété. - De nombreuses images du même produit sont très similaires, donc au moins au début, inclure plus d'une image par produit peut ne pas ajouter beaucoup de pouvoir prédictif. Dans la plupart des cas, la première image de chaque produit (se terminant par
_0.jpeg) est le plus propre.
Au départ, nous voudrions peut-être former notre modèle de classification des styles vestimentaires sur un sous-ensemble contrôlé de ces images. À cette fin, nous utilisons des images haute résolution de nos produits et limitons notre vue à un échantillon représentatif par produit.
Tout d'abord, nous filtrons les images à basse résolution. Nous utilisons le compute_metadata() méthode pour calculer et stocker la largeur et la hauteur de l'image, en pixels, pour chaque image de l'ensemble de données. Nous employons alors le FiftyOne ViewField pour filtrer les images en fonction des valeurs de largeur et de hauteur minimales autorisées. Voir le code suivant :
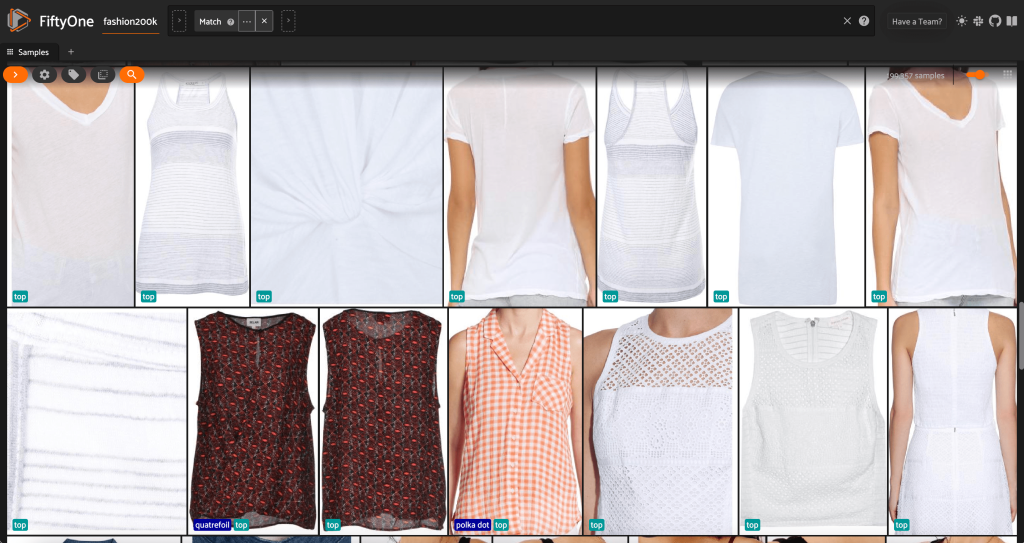
Ce sous-ensemble haute résolution compte un peu moins de 200,000 XNUMX échantillons.
À partir de cette vue, nous pouvons créer une nouvelle vue dans notre ensemble de données contenant un seul échantillon représentatif (au plus) pour chaque produit. Nous utilisons le ViewField encore une fois, la correspondance de modèles pour les chemins de fichiers qui se terminent par _0.jpeg:
Voyons un ordre aléatoire des images dans ce sous-ensemble :
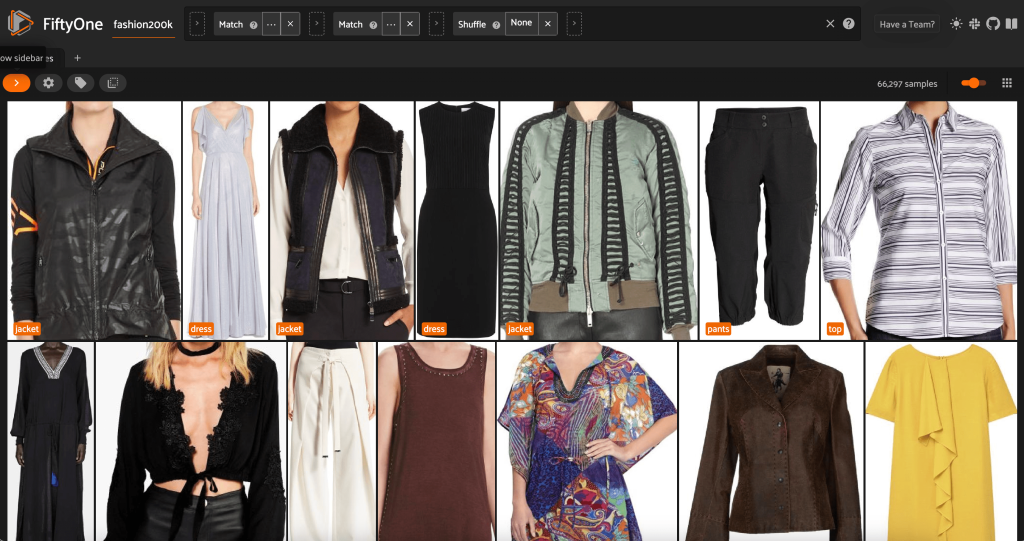
Supprimer les images redondantes dans l'ensemble de données
Cette vue contient 66,297 19 images, soit un peu plus de XNUMX % de l'ensemble de données d'origine. Lorsque nous regardons la vue, cependant, nous voyons qu'il existe de nombreux produits très similaires. Conserver toutes ces copies ne fera probablement qu'ajouter des coûts à notre étiquetage et à la formation des modèles, sans améliorer sensiblement les performances. Au lieu de cela, débarrassons-nous des quasi-doublons pour créer un ensemble de données plus petit qui contient toujours le même punch.
Étant donné que ces images ne sont pas des doublons exacts, nous ne pouvons pas vérifier l'égalité au niveau des pixels. Heureusement, nous pouvons utiliser le FiftyOne Brain pour nous aider à nettoyer notre ensemble de données. En particulier, nous allons calculer une intégration pour chaque image - un vecteur de dimension inférieure représentant l'image - puis rechercher des images dont les vecteurs d'intégration sont proches les uns des autres. Plus les vecteurs sont proches, plus les images sont similaires.
Nous utilisons un modèle CLIP pour générer un vecteur d'intégration à 512 dimensions pour chaque image, et stockons ces incorporations dans les intégrations de champ sur les échantillons de notre ensemble de données :
Ensuite, nous calculons la proximité entre les plongements, en utilisant similitude cosinus, et affirmer que deux vecteurs dont la similarité est supérieure à un certain seuil sont susceptibles d'être proches des doublons. Les scores de similarité cosinus se situent dans la plage [0, 1], et en regardant les données, un score seuil de seuil = 0.5 semble être à peu près correct. Encore une fois, cela n'a pas besoin d'être parfait. Quelques images quasi-dupliquées ne sont pas susceptibles de ruiner notre pouvoir prédictif, et jeter quelques images non dupliquées n'a pas d'impact significatif sur les performances du modèle.
Nous pouvons afficher les prétendus doublons pour vérifier qu'ils sont bien redondants :
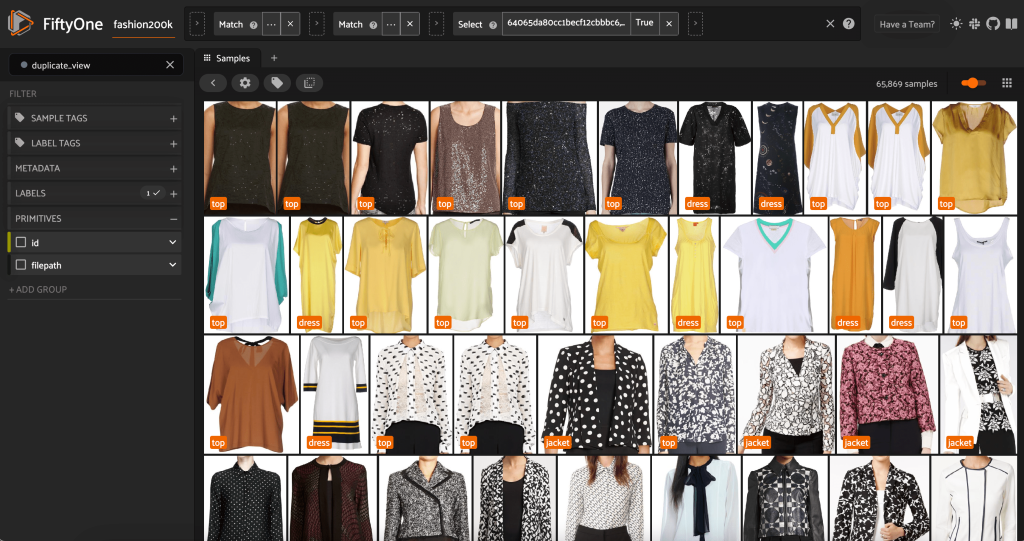
Lorsque nous sommes satisfaits du résultat et pensons que ces images sont effectivement proches des doublons, nous pouvons choisir un échantillon de chaque ensemble d'échantillons similaires à conserver et ignorer les autres :
Maintenant, cette vue contient 3,729 200 images. En nettoyant les données et en identifiant un sous-ensemble de haute qualité de l'ensemble de données Fashion300,000K, FiftyOne nous permet de limiter notre concentration de plus de 4,000 98 images à un peu moins de 90 XNUMX, ce qui représente une réduction de XNUMX %. L'utilisation d'incorporations pour supprimer les images presque en double a réduit de plus de XNUMX % le nombre total d'images à l'étude, avec peu ou pas d'effet sur les modèles à former sur ces données.
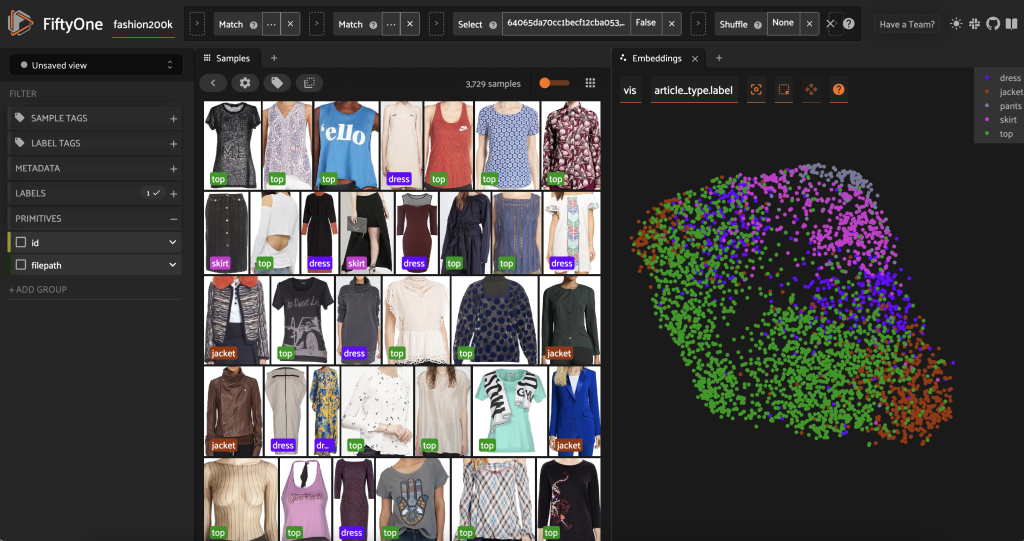
Avant de pré-étiqueter ce sous-ensemble, nous pouvons mieux comprendre les données en visualisant les plongements que nous avons déjà calculés. Nous pouvons utiliser les fonctions intégrées du FiftyOne Brain compute_visualization() , qui utilise la technique d'approximation de variété uniforme (UMAP) pour projeter les vecteurs d'intégration à 512 dimensions dans un espace à deux dimensions afin que nous puissions les visualiser :
Nous ouvrons un nouveau Panneau Incorporations dans l'application FiftyOne et coloration par type d'article, et on voit que ces embeddings encodent grosso modo une notion de type d'article (entre autres !).
Nous sommes maintenant prêts à pré-étiqueter ces données.
En inspectant ces images haute résolution hautement uniques, nous pouvons générer une liste initiale décente de styles à utiliser comme classes dans notre classification de pré-étiquetage zéro coup. Notre objectif dans le pré-étiquetage de ces images n'est pas nécessairement d'étiqueter chaque image correctement. Notre objectif est plutôt de fournir un bon point de départ aux annotateurs humains afin de réduire le temps et les coûts d'étiquetage.
Nous pouvons ensuite instancier un modèle de classification zéro coup pour cette application. Nous utilisons un modèle CLIP, qui est un modèle à usage général entraîné à la fois sur les images et le langage naturel. Nous instancions un modèle CLIP avec l'invite de texte "Vêtements dans le style", de sorte qu'étant donné une image, le modèle affichera la classe pour laquelle "Vêtements dans le style [classe]" est le mieux adapté. CLIP n'est pas formé sur des données spécifiques à la vente au détail ou à la mode, donc ce ne sera pas parfait, mais cela peut vous faire économiser sur les coûts d'étiquetage et d'annotation.
Nous appliquons ensuite ce modèle à notre sous-ensemble réduit et stockons les résultats dans un article_style champ:
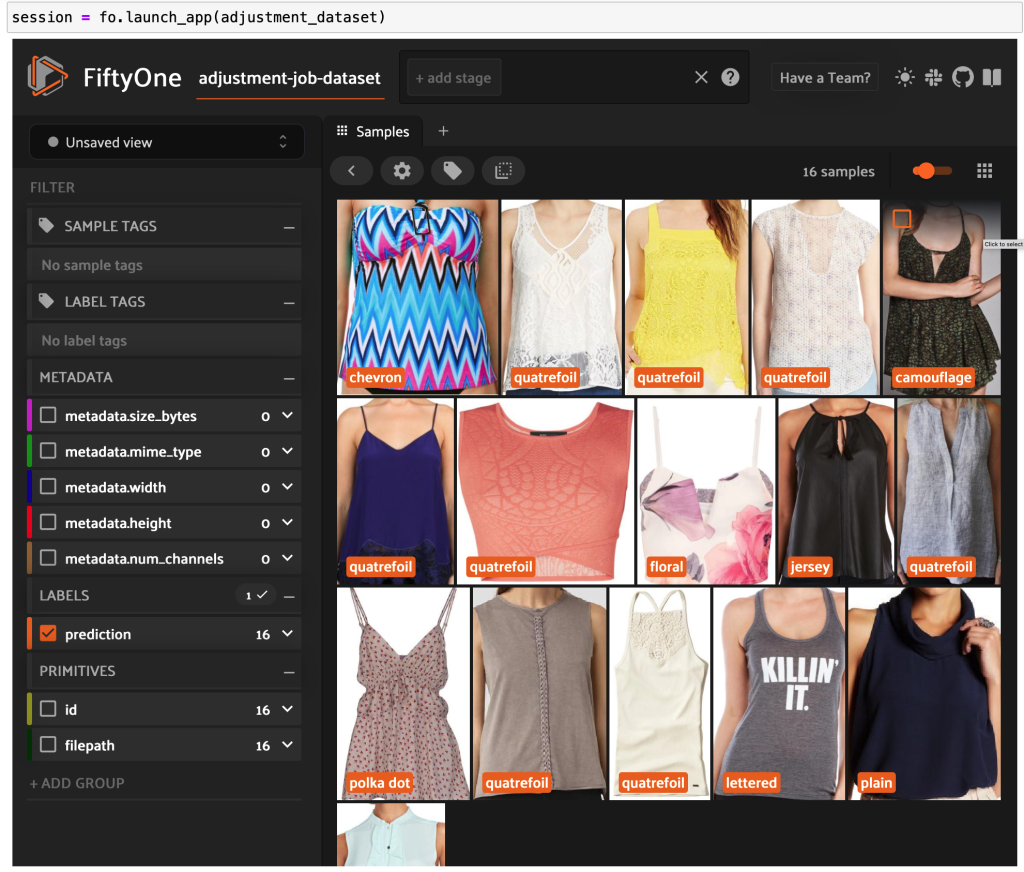
En lançant à nouveau l'application FiftyOne, nous pouvons visualiser les images avec ces étiquettes de style prédites. Nous trions par niveau de fiabilité des prédictions afin d'afficher en premier les prédictions de style les plus fiables :
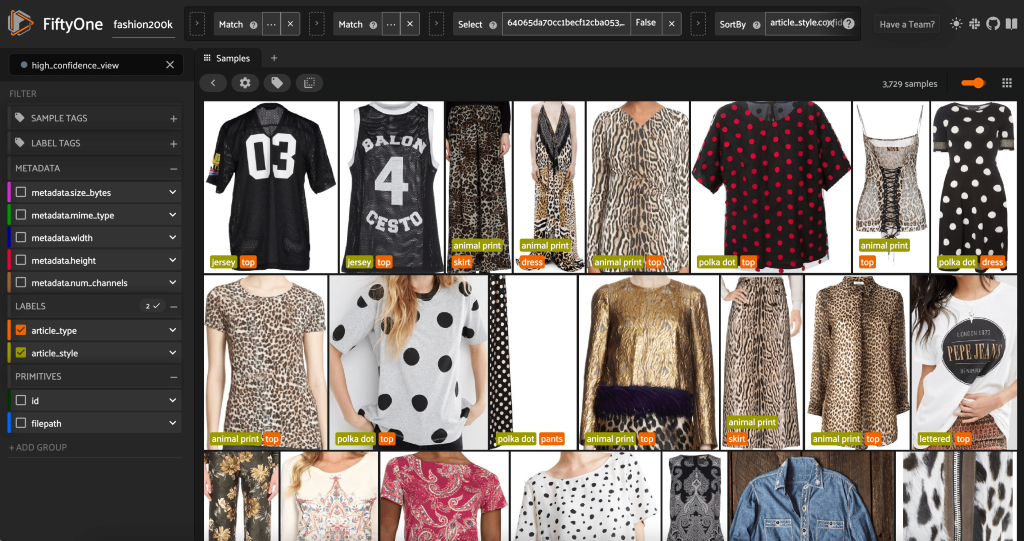
Nous pouvons voir que les prévisions de confiance les plus élevées semblent être pour les styles "jersey", "animal print", "polka dot" et "letter". Cela a du sens, car ces styles sont relativement distincts. Il semble également que, pour la plupart, les étiquettes de style prévues soient exactes.
Nous pouvons également examiner les prédictions de style les moins fiables :
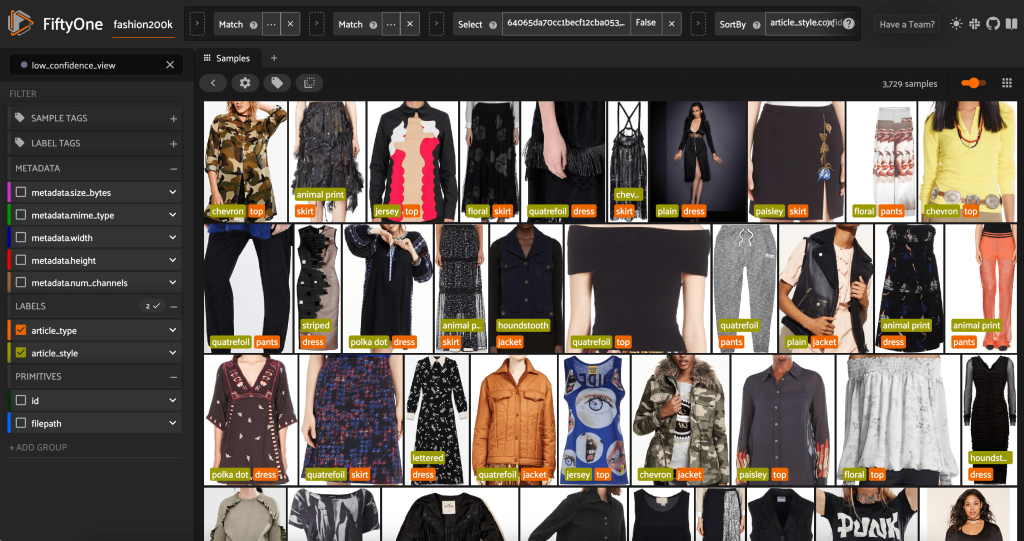
Pour certaines de ces images, la catégorie de style appropriée figure dans la liste fournie et le vêtement est mal étiqueté. La première image de la grille, par exemple, doit clairement être "camouflage" et non "chevron". Dans d'autres cas, cependant, les produits ne rentrent pas parfaitement dans les catégories de style. La robe de la deuxième image de la deuxième rangée, par exemple, n'est pas exactement "rayée", mais avec les mêmes options d'étiquetage, un annotateur humain pourrait également avoir été en conflit. Au fur et à mesure que nous construisons notre ensemble de données, nous devons décider de supprimer des cas extrêmes comme ceux-ci, d'ajouter de nouvelles catégories de style ou d'augmenter l'ensemble de données.
Exporter le jeu de données final depuis FiftyOne
Exportez l'ensemble de données final avec le code suivant :
Nous pouvons exporter un ensemble de données plus petit, par exemple, 16 images, vers le dossier 200kFashionDatasetExportResult-16Images. Nous créons une tâche d'ajustement Ground Truth en l'utilisant :
Chargez l'ensemble de données révisé, convertissez le format d'étiquette en Ground Truth, chargez-le sur Amazon S3 et créez un fichier manifeste pour la tâche d'ajustement
Nous pouvons convertir les étiquettes dans l'ensemble de données pour correspondre à la schéma de manifeste de sortie d'un travail de boîte englobante Ground Truth, et téléchargez les images vers un Service de stockage simple Amazon (Amazon S3) compartiment pour lancer un Travail d'ajustement Ground Truth:
Chargez le fichier manifeste sur Amazon S3 avec le code suivant :
Créez des étiquettes de style corrigées avec Ground Truth
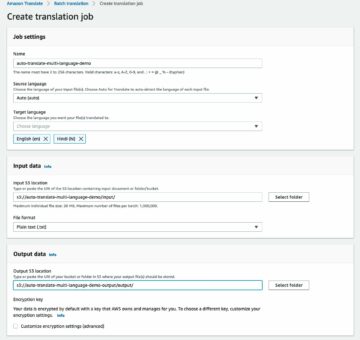
Pour annoter vos données avec des étiquettes de style à l'aide de Ground Truth, effectuez les étapes nécessaires pour démarrer une tâche d'étiquetage de boîte englobante en suivant la procédure décrite dans le Premiers pas avec Ground Truth guide avec l'ensemble de données dans le même compartiment S3.
- Sur la console SageMaker, créez une tâche d'étiquetage Ground Truth.
- Met le Emplacement du jeu de données en entrée être le manifeste que nous avons créé dans les étapes précédentes.
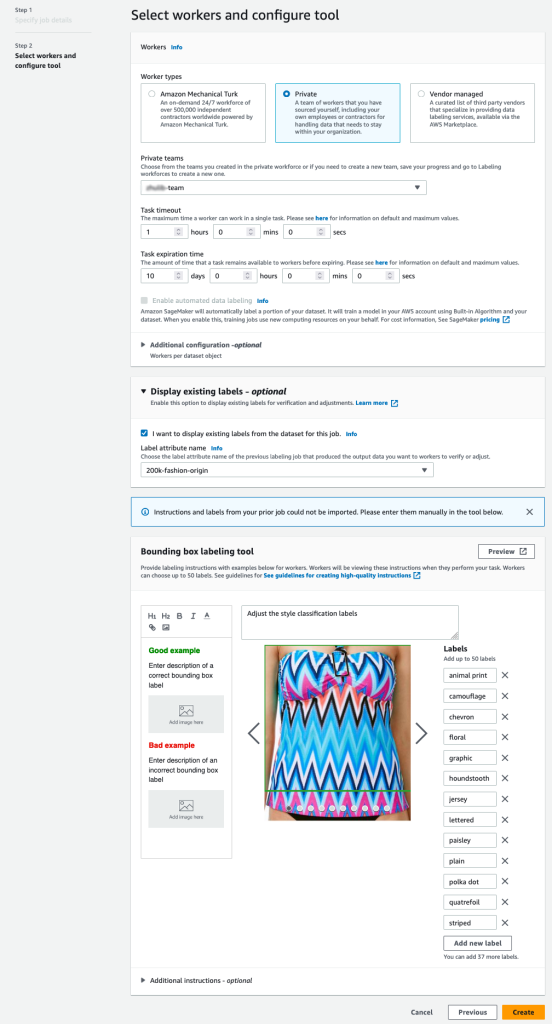
- Spécifiez un chemin S3 pour Emplacement du jeu de données en sortie.
- Pour Rôle IAM, choisissez Saisissez un rôle IAM personnalisé ARN, puis saisissez l'ARN du rôle.
- Pour Catégorie de tâche, choisissez Image(s) et sélectionnez Boîte englobante.
- Selectionnez Suivant.
- Dans le Ouvriers section, choisissez le type de main-d'œuvre que vous souhaitez utiliser.
Vous pouvez sélectionner une main-d'œuvre via Turc mécanique d'Amazon, des fournisseurs tiers ou votre propre main-d'œuvre privée. Pour plus de détails sur vos options de main-d'œuvre, voir Créer et gérer des effectifs. - Développer vous Options d'affichage des libellés existants et sélectionnez Je souhaite afficher les étiquettes existantes de l'ensemble de données pour ce travail.
- Pour Attribut de libellé nom, choisissez le nom de votre manifeste qui correspond aux étiquettes que vous souhaitez afficher pour l'ajustement.
Vous ne verrez que les noms d'attribut d'étiquette pour les étiquettes qui correspondent au type de tâche que vous avez sélectionné dans les étapes précédentes. - Entrez manuellement les étiquettes pour Outil d'étiquetage de boîte englobante.
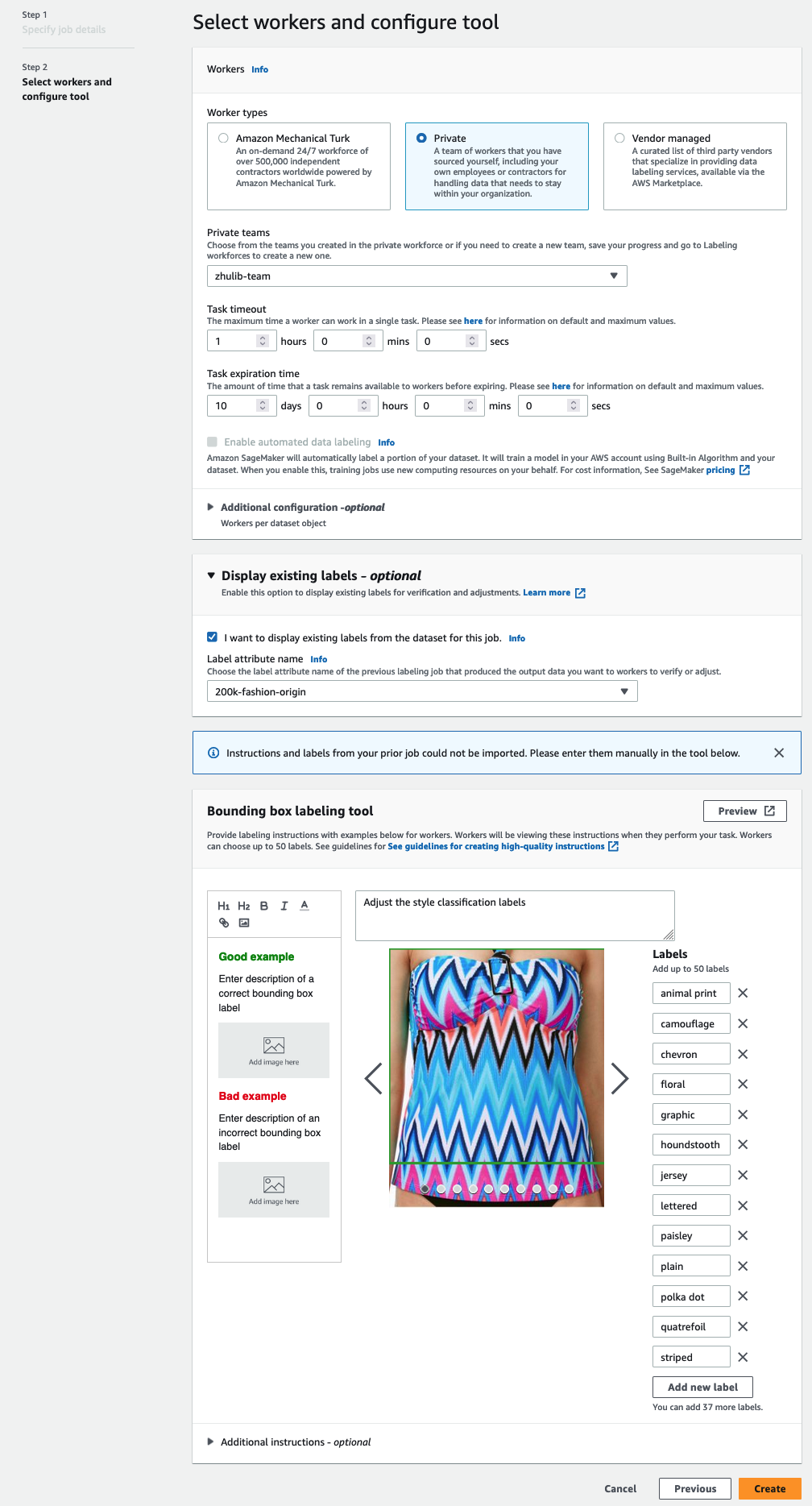 Les libellés doivent contenir les mêmes libellés que ceux utilisés dans l'ensemble de données public. Vous pouvez ajouter de nouvelles étiquettes. La capture d'écran suivante montre comment vous pouvez choisir les travailleurs et configurer l'outil pour votre tâche d'étiquetage.
Les libellés doivent contenir les mêmes libellés que ceux utilisés dans l'ensemble de données public. Vous pouvez ajouter de nouvelles étiquettes. La capture d'écran suivante montre comment vous pouvez choisir les travailleurs et configurer l'outil pour votre tâche d'étiquetage.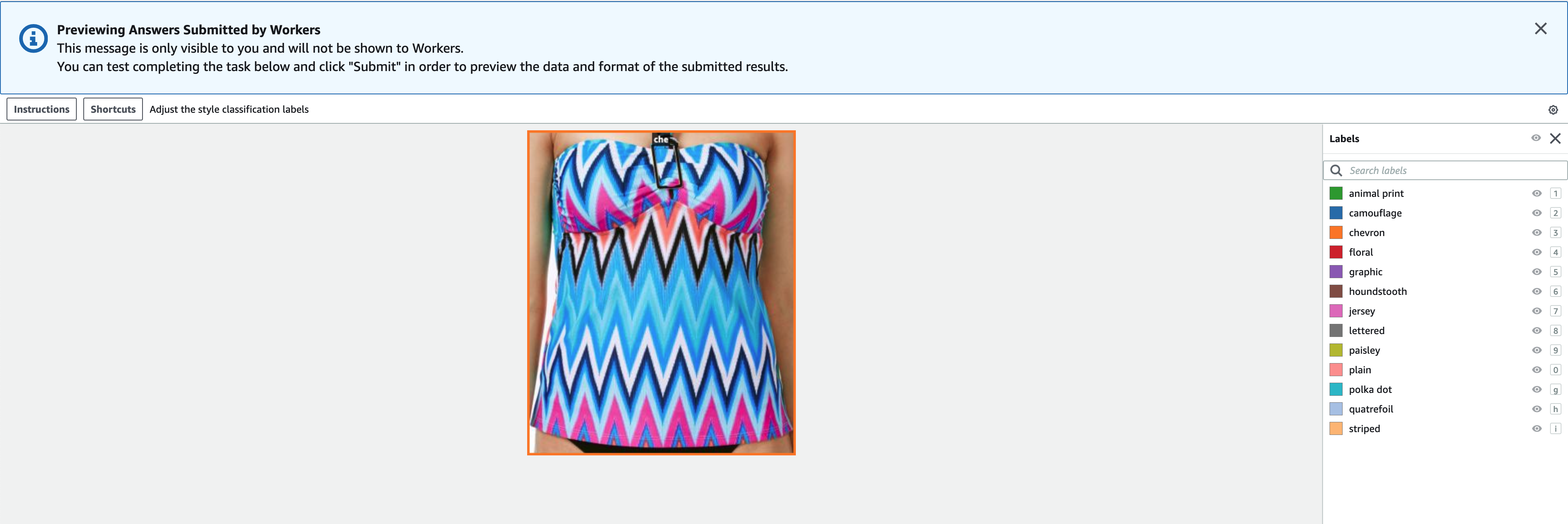
- Selectionnez Aperçu pour prévisualiser l'image et les annotations d'origine.
Nous avons maintenant créé un travail d'étiquetage dans Ground Truth. Une fois notre travail terminé, nous pouvons charger les données étiquetées nouvellement générées dans FiftyOne. Ground Truth produit des données de sortie dans un manifeste de sortie Ground Truth. Pour plus de détails sur le fichier manifeste de sortie, consultez Sortie de travail de boîte englobante. Le code suivant montre un exemple de ce format de manifeste de sortie :
Examinez les résultats étiquetés de Ground Truth dans FiftyOne
Une fois la tâche terminée, téléchargez le manifeste de sortie de la tâche d'étiquetage à partir d'Amazon S3.
Lisez le fichier manifeste de sortie :
Créez un ensemble de données FiftyOne et convertissez les lignes du manifeste en exemples dans l'ensemble de données :
Vous pouvez maintenant voir des données étiquetées de haute qualité de Ground Truth dans FiftyOne.
Conclusion
Dans cet article, nous avons montré comment créer des ensembles de données de haute qualité en combinant la puissance de Cinquante et un by voxel51, une boîte à outils open source qui vous permet de gérer, suivre, visualiser et conserver votre ensemble de données, et Ground Truth, un service d'étiquetage de données qui vous permet d'étiqueter efficacement et avec précision les ensembles de données nécessaires à la formation des systèmes ML en donnant accès à plusieurs construits -dans des modèles de tâches et l'accès à une main-d'œuvre diversifiée via Mechanical Turk, des fournisseurs tiers ou votre propre main-d'œuvre privée.
Nous vous encourageons à essayer cette nouvelle fonctionnalité en installant une instance FiftyOne et en utilisant la console Ground Truth pour commencer. Pour en savoir plus sur Ground Truth, consultez Données d'étiquette, FAQ sur l'étiquetage des données Amazon SageMaker, et le Blog sur l'apprentissage automatique AWS.
Connectez-vous avec le Communauté d'apprentissage automatique et d'IA si vous avez des questions ou des commentaires!
Rejoignez la communauté FiftyOne !
Rejoignez les milliers d'ingénieurs et de scientifiques des données qui utilisent déjà FiftyOne pour résoudre certains des problèmes les plus difficiles de la vision par ordinateur aujourd'hui !
À propos des auteurs
Shalendra Chhabra est actuellement responsable de la gestion des produits pour Amazon SageMaker Human-in-the-Loop (HIL) Services. Auparavant, Shalendra a incubé et dirigé l'intelligence linguistique et conversationnelle pour les réunions des équipes Microsoft, était EIR chez Amazon Alexa Techstars Startup Accelerator, vice-présidente des produits et du marketing chez Discuter.io, Head of Product and Marketing chez Clipboard (acquis par Salesforce) et Lead Product Manager chez Swype (acquis par Nuance). Au total, Shalendra a aidé à construire, expédier et commercialiser des produits qui ont touché plus d'un milliard de vies.
Marques de Jacob est ingénieur en apprentissage automatique et développeur évangéliste chez Voxel51, où il contribue à apporter transparence et clarté aux données mondiales. Avant de rejoindre Voxel51, Jacob a fondé une startup pour aider les musiciens émergents à se connecter et à partager du contenu créatif avec les fans. Avant cela, il a travaillé chez Google X, Samsung Research et Wolfram Research. Dans une vie antérieure, Jacob était un physicien théoricien, complétant son doctorat à Stanford, où il a étudié les phases quantiques de la matière. Pendant son temps libre, Jacob aime grimper, courir et lire des romans de science-fiction.
Jason Corso est co-fondateur et PDG de Voxel51, où il dirige la stratégie pour aider à apporter transparence et clarté aux données mondiales grâce à un logiciel flexible de pointe. Il est également professeur de robotique, de génie électrique et d'informatique à l'Université du Michigan, où il se concentre sur les problèmes de pointe à l'intersection de la vision par ordinateur, du langage naturel et des plates-formes physiques. Pendant son temps libre, Jason aime passer du temps avec sa famille, lire, être dans la nature, jouer à des jeux de société et toutes sortes d'activités créatives.
Brian Moore est co-fondateur et CTO de Voxel51, où il dirige la stratégie et la vision techniques. Il est titulaire d'un doctorat en génie électrique de l'Université du Michigan, où ses recherches ont porté sur des algorithmes efficaces pour les problèmes d'apprentissage automatique à grande échelle, avec un accent particulier sur les applications de vision par ordinateur. Pendant son temps libre, il aime le badminton, le golf, la randonnée et jouer avec ses jumeaux Yorkshire Terriers.
Zhuling Bai est ingénieur en développement logiciel chez Amazon Web Services. Elle travaille sur le développement de systèmes distribués à grande échelle pour résoudre des problèmes d'apprentissage automatique.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- Frapper l'avenir avec Adryenn Ashley. Accéder ici.
- Achetez et vendez des actions de sociétés PRE-IPO avec PREIPO®. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :possède
- :est
- :ne pas
- :où
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Qui sommes-nous
- accélérer
- accélérer
- accélérateur
- accès
- Avec cette connaissance vient le pouvoir de prendre
- avec précision
- a acquise
- activités
- ajouter
- ajoutant
- propos
- Ajusté
- Le réglage
- Après
- encore
- AI
- Alexa
- algorithmes
- Tous
- permet
- seul
- déjà
- aussi
- Amazon
- Amazon alexa
- Amazon Sage Maker
- Vérité au sol Amazon SageMaker
- Amazon Web Services
- parmi
- an
- il analyse
- ainsi que
- animal
- tous
- appli
- Application
- applications
- Appliquer
- approprié
- SONT
- arrangé
- article
- sur notre blog
- AS
- associé
- At
- auteurs
- et
- AWS
- base
- basé
- BE
- car
- devenez
- était
- before
- derrière
- Dans les coulisses
- va
- CROYONS
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Milliards
- planche
- Jeux de société
- OS
- Bootstrap
- tous les deux
- Box
- boîtes
- Cerveau
- Pause
- apporter
- Apporté
- budget
- construire
- Développement
- intégré
- mais
- acheter
- by
- CAN
- Capturer
- maisons
- cas
- catégories
- Catégories
- CEO
- challenge
- difficile
- vérifier
- Selectionnez
- clarté
- classe
- les classes
- classification
- Nettoyage
- clair
- clairement
- client
- Escalade
- Fermer
- plus
- vêtements
- Vêtements
- Co-fondateur
- code
- combiner
- combinant
- Société
- Complément
- complet
- compléter
- calcul
- ordinateur
- Informatique
- Vision par ordinateur
- Applications de vision par ordinateur
- confiance
- confiance
- NOUS CONTACTER
- considération
- Qui consiste
- Console
- contient
- contenu
- contenu
- contrôlée
- de la conversation
- convertir
- copies
- Core
- corrigé
- correspond
- Prix
- Costs
- engendrent
- créée
- Conception
- Lettres de créance
- CTO
- organisée
- curating
- Lecture
- Customiser
- des clients
- Clients
- Cut/Taille
- En investissant dans une technologie de pointe, les restaurants peuvent non seulement rester compétitifs dans un marché en constante évolution, mais aussi améliorer significativement l'expérience de leurs clients.
- données
- ensembles de données
- décider
- démontrer
- Jeans
- profondeur
- la description
- détails
- Détection
- Développeur
- développement
- Développement
- différent
- directement
- répertoires
- Commande
- distinct
- distribué
- systèmes distribués
- plusieurs
- do
- Ne fait pas
- Chien
- faire
- fait
- Ne pas
- DOT
- down
- download
- doublons
- e
- chacun
- Easy
- Edge
- effet
- efficace
- efficacement
- ingénierie électrique
- enrobage
- économies émergentes.
- l'accent
- emploie
- responsabilise
- encapsulé
- encourager
- fin
- ingénieur
- ENGINEERING
- Les ingénieurs
- Entrer
- Environment
- égalité
- essential
- établies
- Ether (ETH)
- évaluer
- Évangéliste
- exactement
- exemple
- existant
- Exporter
- équitablement
- famille
- .fans
- Réactions
- few
- Fiction
- champ
- Des champs
- Déposez votre dernière attestation
- Fichiers
- une fonction filtre
- filtration
- finale
- Prénom
- s'adapter
- flexible
- Focus
- concentré
- se concentre
- Abonnement
- Pour
- formulaire
- le format
- Heureusement
- Fondée
- quatre
- Test d'anglais
- de
- d’étiquettes électroniques entièrement
- Games
- à usage général
- générer
- généré
- obtenez
- GitHub
- Donner
- donné
- objectif
- golf
- Bien
- plus grand
- Grille
- Sol
- Réservation de groupe
- guide
- heureux vous
- Vous avez
- he
- front
- la taille
- aider
- a aidé
- utile
- aide
- ici
- de haute qualité
- haute résolution
- le plus élevé
- très
- randonnée
- sa
- détient
- Comment
- How To
- Cependant
- HTML
- http
- HTTPS
- humain
- i
- IAM
- ID
- identifier
- identifier
- ids
- if
- image
- satellite
- Impact
- importer
- l'amélioration de
- in
- Dans d'autres
- Y compris
- à tort
- incubé
- d'information
- initiale
- possible
- installer
- installer
- instance
- plutôt ;
- Des instructions
- Intelligence
- intersection
- développement
- IT
- SES
- Jersey
- Emploi
- joindre
- joint
- json
- juste
- XNUMX éléments à
- en gardant
- Libellé
- l'étiquetage
- Etiquettes
- langue
- grande échelle
- lancer
- lancement
- conduire
- Conduit
- APPRENTISSAGE
- apprentissage
- au
- LED
- à gauche
- Allons-y
- Bibliothèque
- VIE
- comme
- Probable
- LIMIT
- limité
- Gamme
- lignes
- Liste
- inscription
- Annonces
- peu
- Vit
- charge
- Style
- recherchez-
- Lot
- Faible
- click
- machine learning
- LES PLANTES
- la magie
- faire
- FAIT DU
- gérer
- gérés
- gestion
- manager
- de nombreuses
- Localisation
- Marché
- Stratégie
- Match
- assorti
- matériellement
- Matière
- Mai..
- mécanique
- Médias
- réunions
- Meta
- Métadonnées
- méthode
- méthodes
- Michigan
- Microsoft
- équipes de Microsoft
- pourrait
- minimum
- ML
- Breeze Mobile
- Application Mobile
- modèle
- numériques jumeaux (digital twin models)
- Modules
- PLUS
- (en fait, presque toutes)
- Bougez
- beaucoup
- plusieurs
- musiciens
- must
- prénom
- Nommé
- noms
- Nature
- Langage naturel
- Nature
- Près
- nécessairement
- nécessaire
- Besoin
- Besoins
- Nouveauté
- visiblement
- Notion
- maintenant
- Nuance
- nombre
- objet
- Détection d'objet
- objets
- of
- officiel
- on
- une fois
- ONE
- en ligne
- uniquement
- ouvert
- open source
- Opérations
- Opportunités
- Options
- or
- Organisé
- original
- OS
- Autre
- Autres
- nos
- ande
- décrit
- sortie
- plus de
- propre
- Possède
- Packs
- apparié
- partie
- particulier
- passé
- chemin
- Patron de Couture
- motifs
- parfaite
- performant
- personne
- Personnalisé
- Phases de la matière
- Physique
- en particulier pendant la préparation
- PHOTOS
- PLAID
- Plaine
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- jouer
- Point
- peuplé
- possible
- Post
- power
- pratique
- prédit
- prédiction
- Prédictions
- Aperçu
- précédent
- précédemment
- Imprimé
- Avant
- Privé
- Probablement
- d'ouvrabilité
- processus
- Produit
- gestion des produits
- chef de produit
- Produits
- Professeur
- Projet
- propriété
- éventuel
- prototype
- fournir
- à condition de
- aportando
- public
- des fins
- Python
- Quantum
- fréquemment posées
- vite.
- gamme
- plutôt
- en cours
- solutions
- recommander
- recommandations
- réduire
- Prix Réduit
- réduction
- relativement
- libéré
- pertinent
- supprimez
- représentant
- représentation
- conditions
- un article
- chercheurs
- Résolution
- restreindre
- résultat
- résultant
- Résultats
- détail
- retourner
- Avis
- Débarrasser
- robotique
- robuste
- Rôle
- grossièrement
- RANGÉE
- ruiner
- pour le running
- sagemaker
- Saïd
- force de vente
- même
- Samsung
- Épargnez
- Scènes
- Sciences
- Science-fiction
- scientifiques
- But
- de façon transparente
- Deuxièmement
- Section
- les sections
- sur le lien
- sembler
- semble
- choisi
- sens
- séparé
- service
- Services
- Session
- set
- Partager
- elle
- devrait
- montrer
- Spectacles
- OUI
- similaires
- étapes
- faibles
- So
- Logiciels
- développement de logiciels
- RÉSOUDRE
- quelques
- Quelqu'un
- quelque chose
- Space
- passer
- Dépenses
- scission
- splits
- Stanford
- Commencer
- j'ai commencé
- Commencez
- Commencez
- accélérateur de démarrage
- state-of-the-art
- Étapes
- Encore
- storage
- Boutique
- de Marketing
- Catégorie
- modes
- RÉSUMÉ
- Appareils
- Système
- Prenez
- Tâche
- équipes
- Technique
- TechStars
- raconte
- modèles
- tester
- que
- qui
- La
- leur
- Les
- puis
- théorique
- Là.
- Ces
- l'ont
- des choses
- penser
- des tiers.
- this
- milliers
- порог
- Avec
- Lancement
- fiable
- à
- ensemble
- outil
- Boîte à outils
- top
- haut niveau
- Hauts
- Total
- touché
- suivre
- Train
- qualifié
- Formation
- Transformer
- Transparence
- oui
- Vérité
- TOUR
- deux
- type
- types
- sous
- comprendre
- unique
- université
- Université du Michigan
- Mises à jour
- us
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- utilisateurs
- en utilisant
- Valeurs
- variété
- divers
- fournisseurs
- vérifier
- très
- via
- Voir
- Salle de conférence virtuelle
- vision
- souhaitez
- était
- we
- web
- services Web
- WELL
- ont été
- Quoi
- quand
- que
- qui
- Wikipédia
- sera
- avec
- dans les
- sans
- Femme
- des mots
- Activités principales
- travaillé
- ouvriers
- Workforce
- vos contrats
- monde
- s'inquiéter
- pourra
- écrire
- X
- you
- Votre
- zéphyrnet
- Zip
- ZOO