Dans l'environnement commercial actuel axé sur les données, les organisations sont confrontées au défi de préparer et de transformer efficacement de grandes quantités de données à des fins d'analyse et de science des données. Les entreprises doivent créer des entrepôts de données et des lacs de données basés sur des données opérationnelles. Cela est motivé par la nécessité de centraliser et d'intégrer des données provenant de sources disparates.
Dans le même temps, les données opérationnelles proviennent souvent d'applications soutenues par des magasins de données hérités. La modernisation des applications nécessite une architecture de microservices, qui à son tour nécessite la consolidation des données provenant de plusieurs sources pour construire un magasin de données opérationnel. Sans modernisation, les applications héritées peuvent entraîner des coûts de maintenance croissants. La modernisation des applications implique de remplacer le moteur de base de données sous-jacent par une base de données documentaire moderne telle que MongoDB.
Ces deux tâches (création de lacs de données ou d'entrepôts de données et modernisation des applications) impliquent le déplacement des données, qui utilise un processus d'extraction, de transformation et de chargement (ETL). Le travail ETL est une fonctionnalité clé pour avoir un processus bien structuré afin de réussir.
Colle AWS est un service d'intégration de données sans serveur qui facilite la découverte, la préparation, le déplacement et l'intégration de données provenant de plusieurs sources pour l'analyse, l'apprentissage automatique (ML) et le développement d'applications. Atlas MongoDB est une suite intégrée de services de base de données et de données cloud qui combine le traitement transactionnel, la recherche basée sur la pertinence, l'analyse en temps réel et la synchronisation des données mobile vers cloud dans une architecture élégante et intégrée.
En utilisant AWS Glue avec MongoDB Atlas, les organisations peuvent rationaliser leurs processus ETL. Avec sa solution de base de données entièrement gérée, évolutive et sécurisée, MongoDB Atlas fournit un environnement flexible et fiable pour le stockage et la gestion des données opérationnelles. Ensemble, AWS Glue ETL et MongoDB Atlas constituent une solution puissante pour les organisations qui cherchent à optimiser la façon dont elles créent des lacs de données et des entrepôts de données, et à moderniser leurs applications, afin d'améliorer les performances commerciales, de réduire les coûts et de stimuler la croissance et le succès.
Dans cet article, nous montrons comment migrer des données depuis Service de stockage simple Amazon (Amazon S3) vers MongoDB Atlas à l'aide d'AWS Glue ETL, et comment extraire des données de MongoDB Atlas dans un lac de données basé sur Amazon S3.
Vue d'ensemble de la solution
Dans cet article, nous explorons les cas d'utilisation suivants :
- Extraire des données de MongoDB – MongoDB est une base de données populaire utilisée par des milliers de clients pour stocker des données d'application à grande échelle. Les entreprises clientes peuvent centraliser et intégrer les données provenant de plusieurs magasins de données en créant des lacs de données et des entrepôts de données. Ce processus implique l'extraction de données à partir des magasins de données opérationnelles. Lorsque les données sont au même endroit, les clients peuvent rapidement les utiliser pour des besoins de business intelligence ou pour le ML.
- Ingérer des données dans MongoDB – MongoDB sert également de base de données no-SQL pour stocker les données d'application et créer des magasins de données opérationnelles. La modernisation des applications implique souvent la migration du magasin opérationnel vers MongoDB. Les clients auraient besoin d'extraire des données existantes de bases de données relationnelles ou de fichiers plats. Les applications mobiles et Web nécessitent souvent que les ingénieurs de données créent des pipelines de données pour créer une vue unique des données dans Atlas tout en ingérant des données provenant de plusieurs sources cloisonnées. Au cours de cette migration, ils auraient besoin de joindre différentes bases de données pour créer des documents. Cette opération de jointure complexe nécessiterait une puissance de calcul importante et ponctuelle. Les développeurs auraient également besoin de le créer rapidement pour migrer les données.
AWS Glue est pratique dans ces cas avec le modèle de paiement à l'utilisation et sa capacité à exécuter des transformations complexes sur d'énormes ensembles de données. Les développeurs peuvent utiliser AWS Glue Studio pour créer efficacement de tels pipelines de données.
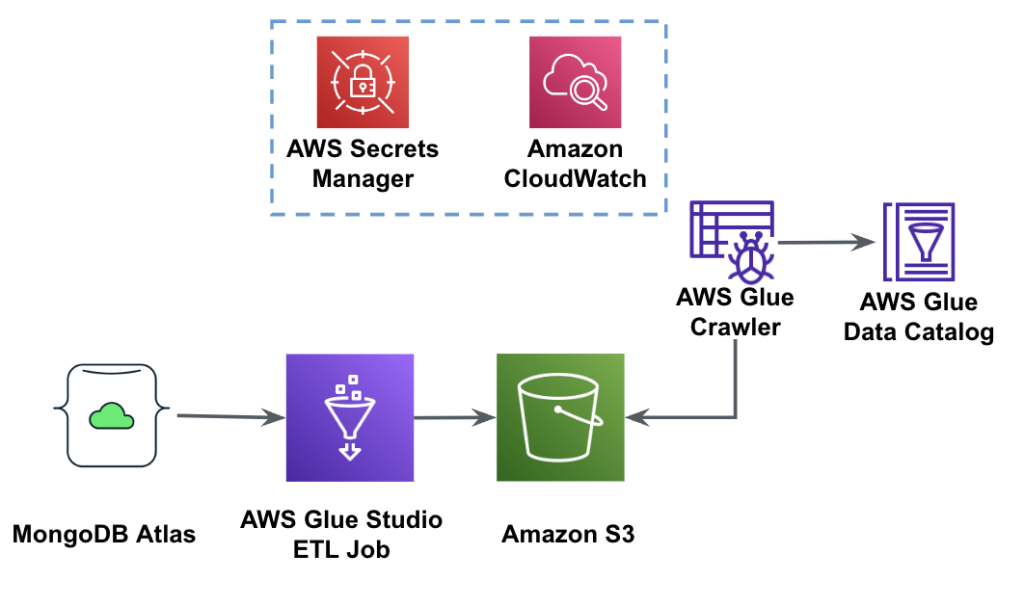
Le diagramme suivant montre le flux de travail d'extraction de données de MongoDB Atlas dans un compartiment S3 à l'aide d'AWS Glue Studio.
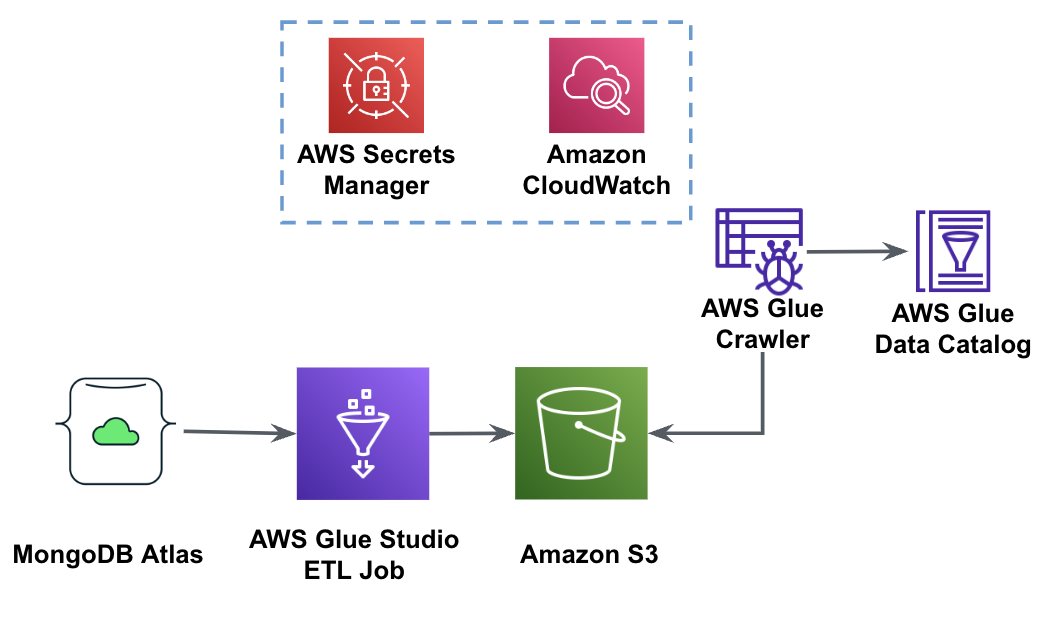
Pour mettre en œuvre cette architecture, vous aurez besoin d'un cluster MongoDB Atlas, d'un bucket S3 et d'un Gestion des identités et des accès AWS (IAM) rôle pour AWS Glue. Pour configurer ces ressources, reportez-vous aux étapes préalables ci-dessous. GitHub repo.
La figure suivante montre le flux de travail de chargement de données d'un compartiment S3 dans MongoDB Atlas à l'aide d'AWS Glue.
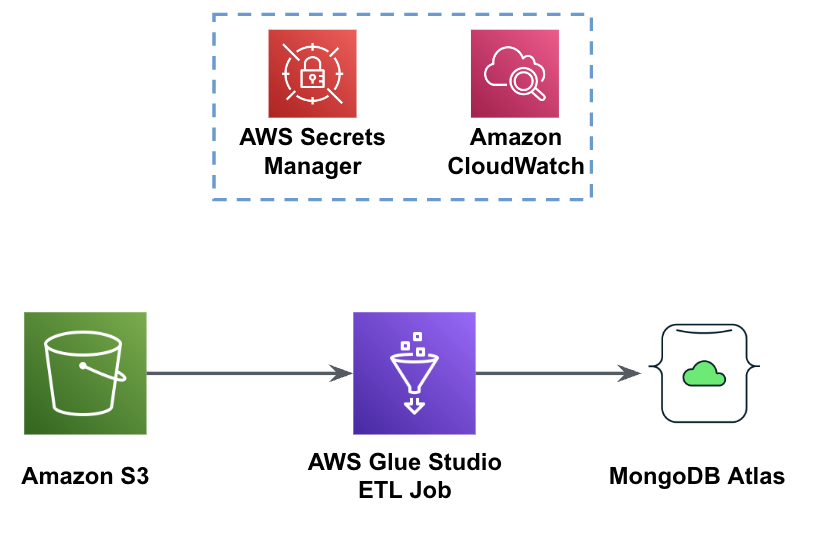
Les mêmes prérequis sont nécessaires ici : un compartiment S3, un rôle IAM et un cluster MongoDB Atlas.
Charger des données d'Amazon S3 vers MongoDB Atlas à l'aide d'AWS Glue
Les étapes suivantes décrivent comment charger les données du compartiment S3 dans MongoDB Atlas à l'aide d'une tâche AWS Glue. Le processus d'extraction de MongoDB Atlas vers Amazon S3 est très similaire, à l'exception du script utilisé. Nous rappelons les différences entre les deux processus.
- Créer un cluster gratuit dans l'Atlas MongoDB.
- Télécharger le exemple de fichier JSON à votre compartiment S3.
- Créez une nouvelle tâche AWS Glue Studio avec le Éditeur de script Spark option.

- Selon que vous souhaitez charger ou extraire des données du cluster MongoDB Atlas, entrez le charger le script or extraire le script dans l'éditeur de script AWS Glue Studio.
La capture d'écran suivante montre un extrait de code pour charger des données dans le cluster MongoDB Atlas.

Le code utilise AWS Secrets Manager pour récupérer le nom, le nom d'utilisateur et le mot de passe du cluster MongoDB Atlas. Ensuite, il crée un DynamicFrame pour le compartiment S3 et le nom de fichier transmis au script en tant que paramètres. Le code récupère les noms de base de données et de collection à partir de la configuration des paramètres de travail. Enfin, le code écrit le DynamicFrame au cluster MongoDB Atlas en utilisant les paramètres récupérés.
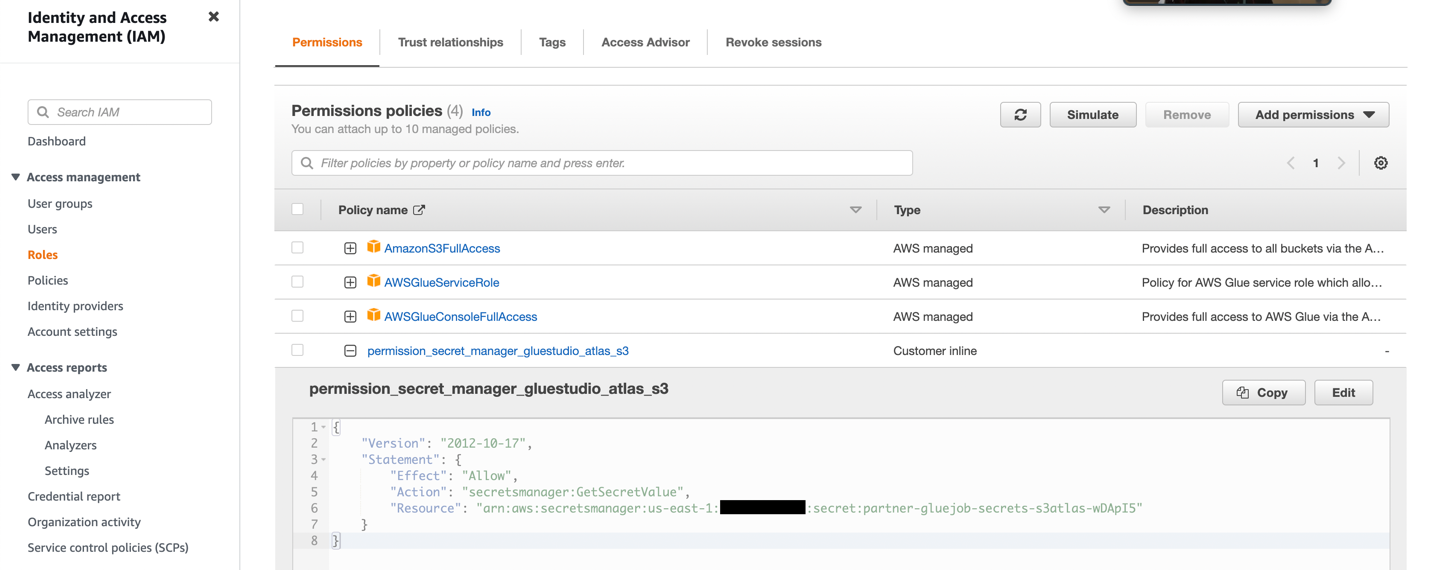
- Créez un rôle IAM avec les autorisations comme indiqué dans la capture d'écran suivante.
Pour plus de détails, reportez-vous à Configurer un rôle IAM pour votre tâche ETL.
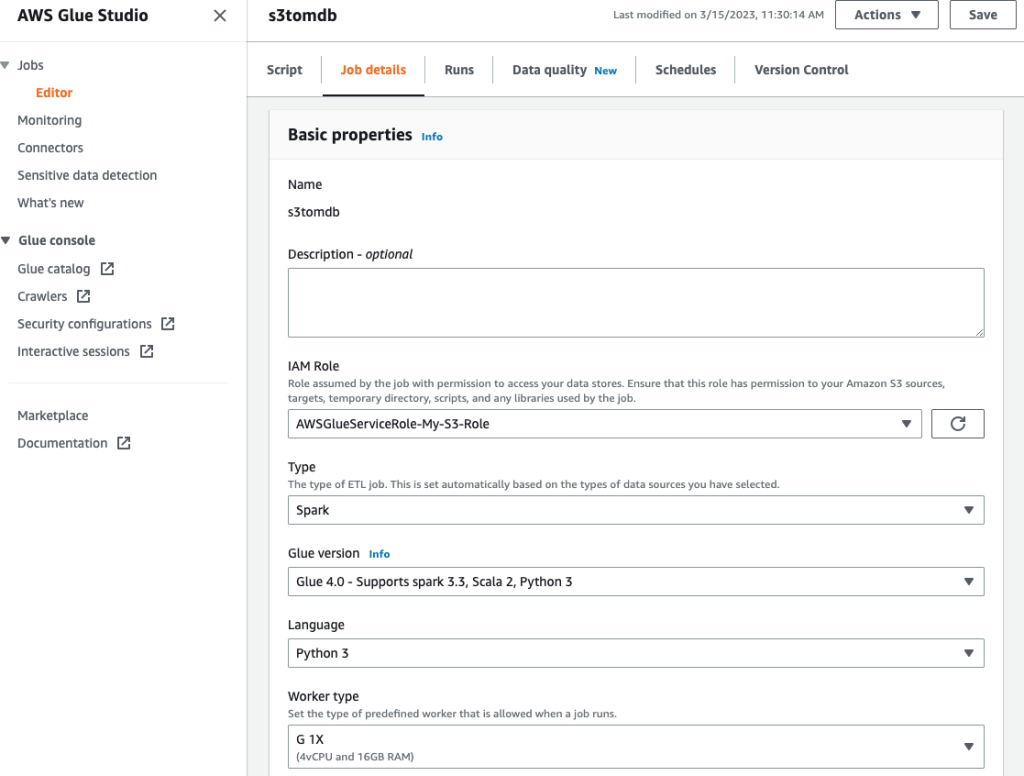
- Donnez un nom au travail et fournissez le rôle IAM créé à l'étape précédente sur le Détails du poste languette.
- Vous pouvez laisser le reste des paramètres par défaut, comme indiqué dans les captures d'écran suivantes.
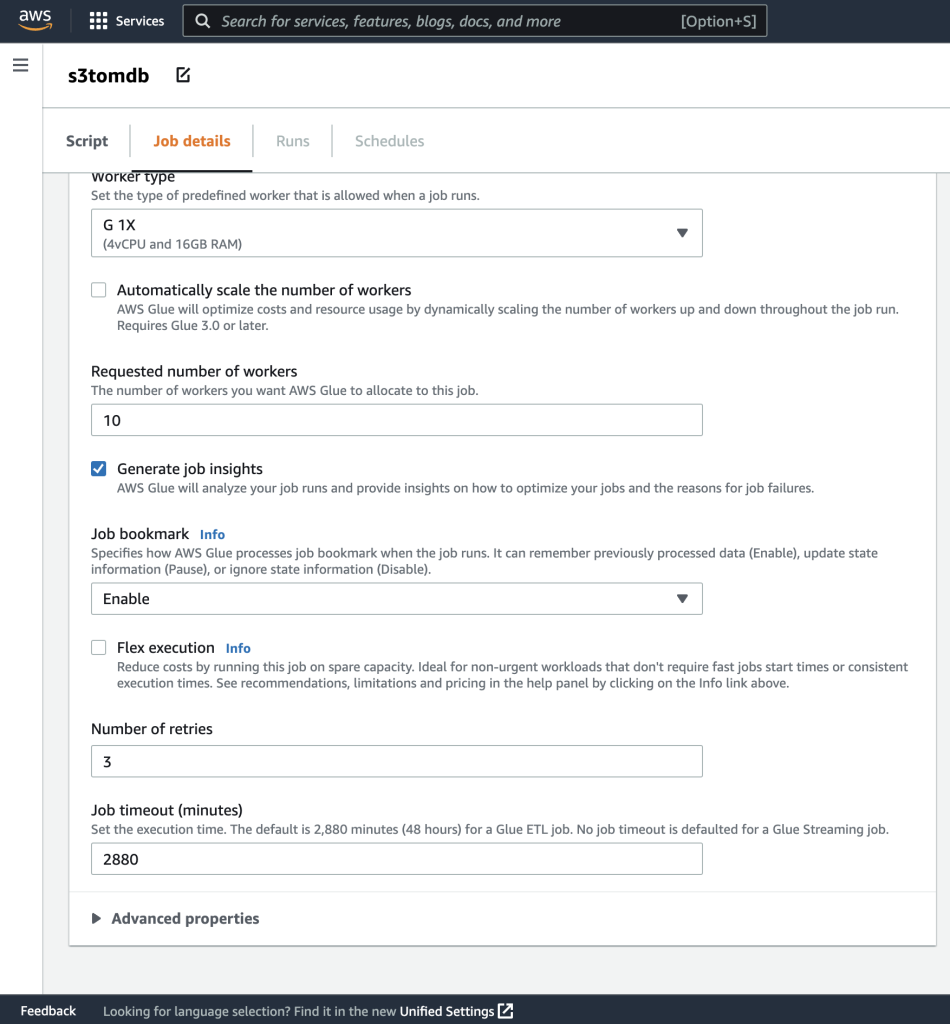
- Ensuite, définissez les paramètres de travail que le script utilise et fournissez les valeurs par défaut.
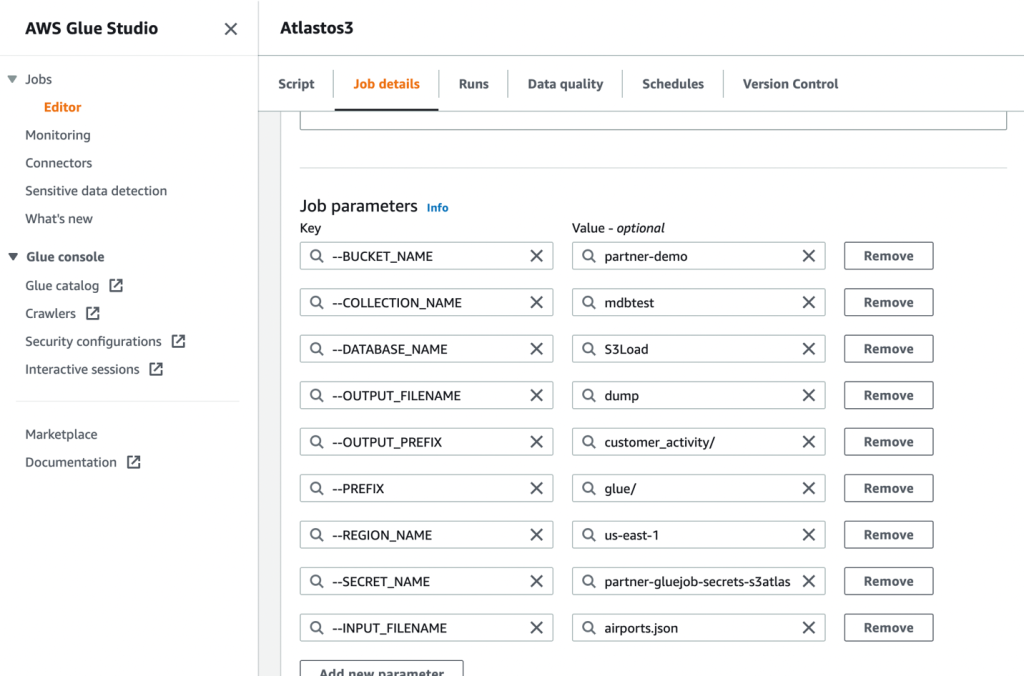
- Enregistrez le travail et exécutez-le.
- Pour confirmer une exécution réussie, observez le contenu de la collection de bases de données MongoDB Atlas si vous chargez les données, ou le compartiment S3 si vous effectuez un extrait.



La capture d'écran suivante montre les résultats d'un chargement de données réussi à partir d'un compartiment Amazon S3 dans le cluster MongoDB Atlas. Les données sont désormais disponibles pour les requêtes dans l'interface utilisateur MongoDB Atlas.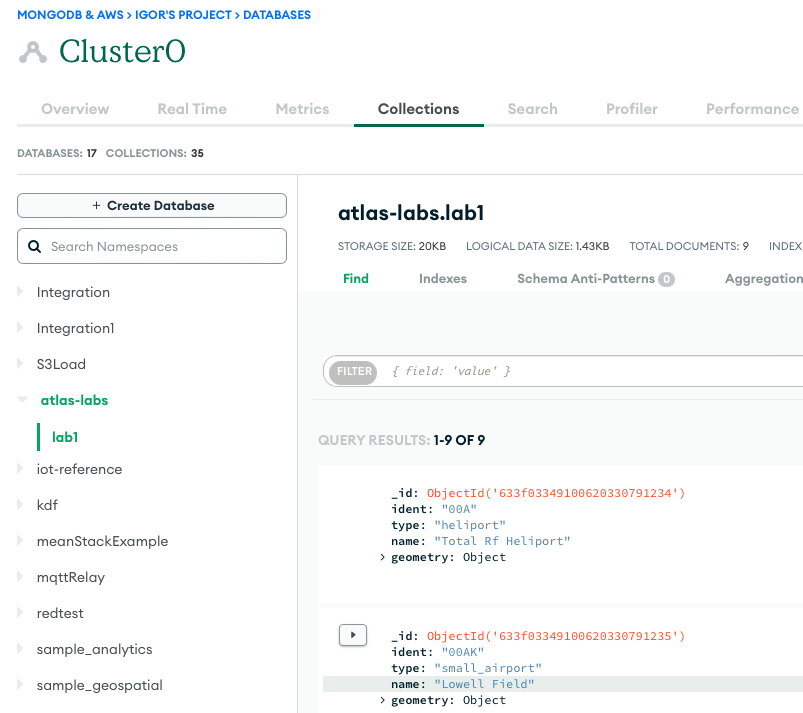
- Pour dépanner vos exécutions, consultez le Amazon Cloud Watch journaux à l'aide du lien sur le travail Courir languette.
La capture d'écran suivante montre que la tâche s'est exécutée avec succès, avec des détails supplémentaires tels que des liens vers les journaux CloudWatch.

Conclusion
Dans cet article, nous avons décrit comment extraire et ingérer des données dans MongoDB Atlas à l'aide d'AWS Glue.
Avec les tâches ETL AWS Glue, nous pouvons désormais transférer les données de MongoDB Atlas vers des sources compatibles avec AWS Glue, et vice versa. Vous pouvez également étendre la solution pour créer des analyses à l'aide des services AWS AI et ML.
Pour en savoir plus, consultez le GitHub référentiel pour obtenir des instructions détaillées et un exemple de code. Vous pouvez vous procurer Atlas MongoDB sur AWS Marketplace.
À propos des auteurs

Igor Alekseev est Senior Partner Solution Architect chez AWS dans le domaine Data and Analytics. Dans son rôle, Igor travaille avec des partenaires stratégiques pour les aider à créer des architectures complexes optimisées pour AWS. Avant de rejoindre AWS, en tant qu'architecte de données/solutions, il a mis en œuvre de nombreux projets dans le domaine du Big Data, y compris plusieurs lacs de données dans l'écosystème Hadoop. En tant qu'ingénieur de données, il a été impliqué dans l'application de l'IA/ML à la détection des fraudes et à la bureautique.
 Babu Srinivasan est un architecte de solutions partenaire principal chez MongoDB. Dans son rôle actuel, il travaille avec AWS pour construire les intégrations techniques et les architectures de référence pour les solutions AWS et MongoDB. Il a plus de deux décennies d'expérience dans les technologies de bases de données et de cloud. Il est passionné par la fourniture de solutions techniques aux clients travaillant avec plusieurs intégrateurs de systèmes mondiaux (GSI) dans plusieurs zones géographiques.
Babu Srinivasan est un architecte de solutions partenaire principal chez MongoDB. Dans son rôle actuel, il travaille avec AWS pour construire les intégrations techniques et les architectures de référence pour les solutions AWS et MongoDB. Il a plus de deux décennies d'expérience dans les technologies de bases de données et de cloud. Il est passionné par la fourniture de solutions techniques aux clients travaillant avec plusieurs intégrateurs de systèmes mondiaux (GSI) dans plusieurs zones géographiques.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- Frapper l'avenir avec Adryenn Ashley. Accéder ici.
- Achetez et vendez des actions de sociétés PRE-IPO avec PREIPO®. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- :possède
- :est
- 100
- 11
- a
- capacité
- Qui sommes-nous
- accès
- à travers
- Supplémentaire
- AI
- AI / ML
- aussi
- Amazon
- quantités
- an
- analytique
- ainsi que
- Application
- Le développement d'applications
- applications
- Application
- applications
- architecture
- SONT
- AS
- At
- atlas
- Automation
- disponibles
- AWS
- Colle AWS
- Marketplace AWS
- soutenu
- basé
- va
- jusqu'à XNUMX fois
- Big
- Big Data
- construire
- Développement
- la performance des entreprises
- l'intelligence d'entreprise
- performance de l'entreprise
- entreprises
- by
- Appelez-nous
- CAN
- cas
- challenge
- en changeant
- le cloud
- Grappe
- code
- collection
- moissonneuses-batteuses
- vient
- Venir
- complexe
- calcul
- configuration
- Confirmer
- consolidation
- construire
- contenu
- a continué
- Costs
- engendrent
- créée
- crée des
- création
- Courant
- Clients
- données
- ingénieur de données
- intégration de données
- Lac de données
- science des données
- entrepôts de données
- data-driven
- Base de données
- bases de données
- ensembles de données
- décennies
- Réglage par défaut
- démontrer
- décrire
- décrit
- détails
- Détection
- mobiles
- Développement
- différences
- différent
- découvrez
- disparate
- INSTITUTIONNELS
- domaine
- motivation
- entraîné
- pendant
- risque numérique
- éditeur
- efficacement
- Moteur
- ingénieur
- Les ingénieurs
- Entrer
- Entreprise
- clients entreprise
- Environment
- Ether (ETH)
- exception
- existant
- Découvrez
- explorez
- étendre
- extrait
- extraction
- Visage
- Figure
- Déposez votre dernière attestation
- Fichiers
- finalement
- plat
- flexible
- Abonnement
- Pour
- fraude
- détection de fraude
- Test d'anglais
- de
- d’étiquettes électroniques entièrement
- géographies
- Global
- Croissance
- Hadoop
- pratique
- ayant
- he
- aider
- ici
- sa
- Comment
- How To
- HTML
- http
- HTTPS
- majeur
- IAM
- Active
- if
- Mettre en oeuvre
- mis en œuvre
- améliorer
- in
- Y compris
- croissant
- contribution
- Des instructions
- intégrer
- des services
- l'intégration
- intégrations
- Intelligence
- développement
- impliquer
- impliqué
- IT
- SES
- Emploi
- Emplois
- rejoindre
- joindre
- json
- ACTIVITES
- lac
- gros
- APPRENTISSAGE
- apprentissage
- Laisser
- Legacy
- comme
- LINK
- Gauche
- charge
- chargement
- recherchez-
- click
- machine learning
- facile
- FAIT DU
- gérés
- les gérer
- de nombreuses
- marché
- Mai..
- émigrer
- migration
- ML
- Breeze Mobile
- modèle
- Villas Modernes
- modernisation
- moderniser
- MongoDB
- PLUS
- Bougez
- mouvement
- plusieurs
- prénom
- noms
- Besoin
- nécessaire
- Besoins
- Nouveauté
- maintenant
- observer
- of
- Bureaux
- souvent
- on
- ONE
- opération
- opérationnel
- Optimiser
- Option
- or
- de commander
- organisations
- ande
- paramètres
- les partenaires
- partenaires,
- passé
- passionné
- Mot de Passe
- performant
- effectuer
- autorisations
- Place
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Populaire
- Post
- power
- solide
- Préparer
- en train de préparer
- conditions préalables
- précédent
- Avant
- processus
- les process
- traitement
- projets
- fournit
- aportando
- des fins
- requêtes
- vite.
- en temps réel
- réduire
- fiable
- exigent
- a besoin
- Ressources
- REST
- Résultats
- Avis
- Rôle
- Courir
- même
- évolutive
- Escaliers intérieurs
- Sciences
- screenshots
- Rechercher
- sécurisé
- supérieur
- Sans serveur
- sert
- service
- Services
- plusieurs
- montré
- Spectacles
- significative
- similaires
- étapes
- unique
- sur mesure
- Solutions
- Sources
- étapes
- Étapes
- storage
- Boutique
- STORES
- simple
- Stratégique
- Partenaires stratégiques
- rationaliser
- studio
- réussir
- succès
- réussi
- Avec succès
- tel
- suite
- la quantité
- synchronisation
- combustion propre
- tâches
- Technique
- Les technologies
- que
- qui
- Les
- leur
- Les
- puis
- Ces
- l'ont
- this
- milliers
- fiable
- à
- aujourd'hui
- ensemble
- transactionnel
- transférer
- Transformer
- transformations
- transformer
- TOUR
- deux
- ui
- sous-jacent
- utilisé
- d'utiliser
- Utilisateur
- en utilisant
- Valeurs
- très
- Voir
- souhaitez
- était
- we
- web
- ont été
- quand
- que
- qui
- tout en
- sera
- comprenant
- sans
- workflow
- de travail
- pourra
- you
- Votre
- zéphyrnet