La valeur des données est sensible au temps. Le traitement en temps réel rend les décisions fondées sur les données précises et exploitables en quelques secondes ou minutes au lieu d'heures ou de jours. La capture de données modifiées (CDC) fait référence au processus d'identification et de capture des modifications apportées aux données dans une base de données, puis à la transmission de ces modifications en temps réel à un système en aval. Capturer chaque modification des transactions dans une base de données source et les déplacer vers la cible en temps réel maintient les systèmes synchronisés et facilite les cas d'utilisation d'analyse en temps réel et les migrations de base de données sans temps d'arrêt. Voici quelques avantages du CDC :
- Il élimine le besoin de mise à jour de chargement en bloc et de fenêtres de traitement par lots gênantes en permettant le chargement incrémentiel ou la diffusion en temps réel des modifications de données dans votre référentiel cible.
- Il garantit que les données de plusieurs systèmes restent synchronisées. Ceci est particulièrement important si vous prenez des décisions urgentes dans un environnement de données à grande vitesse.
Kafka Connexion est un composant open source d'Apache Kafka qui fonctionne comme un hub de données centralisé pour une intégration simple des données entre les bases de données, les magasins clé-valeur, les index de recherche et les systèmes de fichiers. Le Registre de schémas AWS Glue vous permet de découvrir, contrôler et faire évoluer de manière centralisée les schémas de flux de données. Kafka Connect et Schema Registry s'intègrent pour capturer les informations de schéma à partir des connecteurs. Kafka Connect fournit un mécanisme pour convertir les données des types de données internes utilisés par Kafka Connect en types de données représentés par Avro, Protobuf ou JSON Schema. AvroConverter, ProtobufConverter et JsonSchemaConverter enregistrent automatiquement les schémas générés par les connecteurs Kafka (source) qui produisent des données vers Kafka. Les connecteurs (récepteurs) qui consomment des données de Kafka reçoivent des informations de schéma en plus des données de chaque message. Cela permet aux connecteurs de récepteur de connaître la structure des données pour fournir des fonctionnalités telles que la maintenance d'un schéma de table de base de données dans un catalogue de données.
Le message montre comment créer un CDC de bout en bout en utilisant Connexion Amazon MSK, un service géré par AWS pour déployer et exécuter les applications Kafka Connect et AWS Glue Schema Registry, qui vous permet de découvrir, contrôler et faire évoluer de manière centralisée les schémas de flux de données.
Vue d'ensemble de la solution
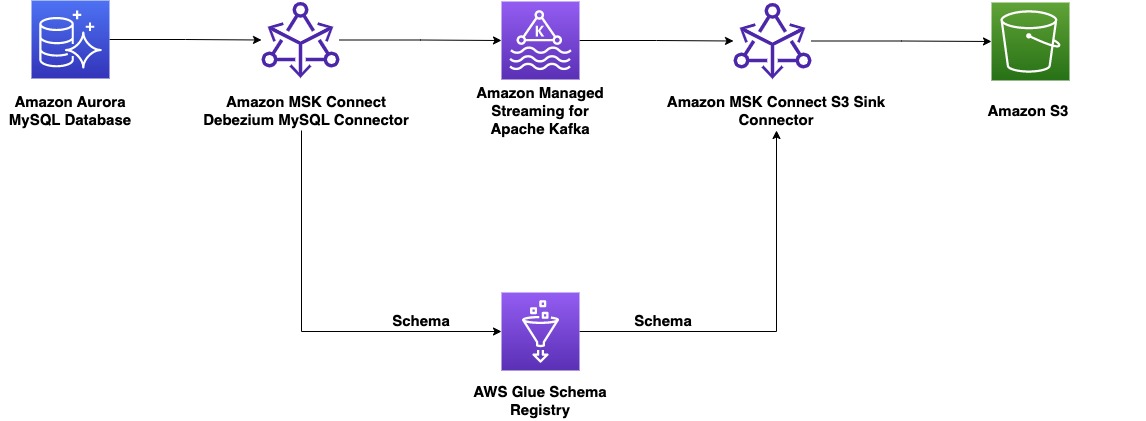
Du côté du producteur, pour cet exemple, nous choisissons un MySQL-compatible Amazon Aurora base de données comme source de données, et nous avons un Débézium Connecteur MySQL pour effectuer CDC. Le connecteur Debezium surveille en permanence les bases de données et transmet les modifications au niveau des lignes à un sujet Kafka. Le connecteur extrait le schéma de la base de données pour sérialiser les enregistrements sous une forme binaire. Si le schéma n'existe pas déjà dans le registre, le schéma sera enregistré. Si le schéma existe mais que le sérialiseur utilise une nouvelle version, le registre de schémas vérifie le le mode de compatibilité du schéma avant de mettre à jour le schéma. Dans cette solution, nous utilisons mode de compatibilité descendante. Le registre de schéma renvoie une erreur si une nouvelle version du schéma n'est pas rétrocompatible, et nous pouvons configurer Kafka Connect pour envoyer des messages incompatibles à la file d'attente de lettres mortes.
Du côté des consommateurs, nous utilisons un Service de stockage simple Amazon (Amazon S3) connecteur de récepteur pour désérialiser l'enregistrement et stocker les modifications dans Amazon S3. Nous construisons et déployons le connecteur Debezium et le récepteur Amazon S3 à l'aide de MSK Connect.
Exemple de schéma
Pour cet article, nous utilisons le schéma suivant comme première version du tableau :
Pré-requis
Avant de configurer les connecteurs producteur et consommateur MSK, nous devons d'abord configurer une source de données, un cluster MSK et un nouveau registre de schémas. Nous fournissons un AWS CloudFormation modèle pour générer les ressources de support nécessaires à la solution :
- Une base de données Aurora compatible MySQL comme source de données. Pour exécuter CDC, nous activons la journalisation binaire dans le Groupe de paramètres de cluster de base de données.
- Un cluster MSK. Pour simplifier la connexion réseau, nous utilisons le même VPC pour la base de données Aurora et le cluster MSK.
- Deux registres de schémas pour gérer les schémas de clé de message et de valeur de message.
- Un compartiment S3 comme récepteur de données.
- Plugins MSK Connect et configuration de travail nécessaires pour cette démo.
- UN Cloud de calcul élastique Amazon (Amazon EC2) pour exécuter des commandes de base de données.
Pour configurer des ressources dans votre compte AWS, effectuez les étapes suivantes dans une région AWS prenant en charge Amazon MSK, MSK Connect et AWS Glue Schema Registry :
- Selectionnez Lancer la pile:
- Selectionnez Suivant.
- Pour Nom de la pile, entrez un nom approprié.
- Pour Mot de passe de la base de données, saisissez le mot de passe souhaité pour l'utilisateur de la base de données.
- Conservez les autres valeurs par défaut.
- Selectionnez Suivant.
- Sur la page suivante, choisissez Suivant.
- Passez en revue les détails sur la dernière page et sélectionnez Je reconnais qu'AWS CloudFormation peut créer des ressources IAM.
- Selectionnez Créer une pile.
Plugin personnalisé pour le connecteur source et destination
Un plug-in personnalisé est un ensemble de fichiers JAR contenant l'implémentation d'un ou plusieurs connecteurs, transformations ou convertisseurs. Amazon MSK installera le plug-in sur les nœuds de calcul du cluster MSK Connect sur lequel le connecteur s'exécute. Dans le cadre de cette démo, pour le connecteur source, nous utilisons open-source Fichiers JAR du connecteur Debezium MySQL, et pour le connecteur de destination, nous utilisons la licence de la communauté Confluent Fichiers JAR de connecteur de récepteur Amazon S3. Les deux plugins sont également ajoutés avec des bibliothèques pour Sérialiseurs et désérialiseurs Avro du registre de schéma AWS Glue. Ces plugins personnalisés sont déjà créés dans le cadre du modèle CloudFormation déployé à l'étape précédente.
Utiliser le registre de schémas AWS Glue avec le connecteur Debezium sur MSK Connect en tant que producteur MSK
Nous déployons d'abord le connecteur source à l'aide du plugin Debezium MySQL pour diffuser des données à partir d'un Édition compatible Amazon Aurora MySQL base de données à Amazon MSK. Effectuez les étapes suivantes :
- Sur la console Amazon MSK, dans le volet de navigation, sous MSK Connecter, choisissez Connecteurs RF.
- Selectionnez Créer un connecteur.
- Selectionnez Utiliser le plugin personnalisé existant puis choisissez le plugin personnalisé avec le nom commençant
msk-blog-debezium-source-plugin. - Selectionnez Suivant.
- Entrez un nom approprié comme
debezium-mysql-connectoret une description facultative. - Pour Grappe Apache Kafka, choisissez Pôle MSK et choisissez le cluster créé par le modèle CloudFormation.
- In Configuration du connecteur, supprimez les valeurs par défaut et utilisez les paires clé-valeur de configuration suivantes et avec les valeurs appropriées :
- prénom – Le nom utilisé pour le connecteur.
- base de données.hostsname – La sortie CloudFormation pour Point de terminaison de la base de données.
- base de données.utilisateur et base de données.mot de passe – Les paramètres passés dans le modèle CloudFormation.
- base de données.history.kafka.bootstrap.servers – La sortie CloudFormation pour Amorçage de Kafka.
- key.converter.region et value.converter.region – Votre Région.
Certains de ces paramètres sont génériques et doivent être spécifiés pour n'importe quel connecteur. Par exemple:
- connector.class est la classe Java du connecteur
- tâches.max est le nombre maximum de tâches qui doivent être créées pour ce connecteur
Certains paramètres (database.*, transforms.*) sont spécifiques au connecteur Debezium MySQL. Faire référence à Propriétés de configuration du connecteur source Debezium MySQL pour plus d'information.
Certains paramètres (key.converter.* ainsi que value.converter.*) sont spécifiques au Schema Registry. Nous utilisons le AWSKafkaAvroConverter du Bibliothèque de registre de schémas AWS Glue comme convertisseur de format. Configurer AWSKafkaAvroConverter, nous utilisons la valeur des propriétés constantes de chaîne dans le AWSSchemaRegistryConstantsAWSSchemaRegistryConstantsAWSSchemaRegistryConstants classe:
key.converterainsi quevalue.convertercontrôler le format des données qui seront écrites dans Kafka pour les connecteurs source ou lues à partir de Kafka pour les connecteurs récepteurs. Nous utilisonsAWSKafkaAvroConverterpour le format Avro.key.converter.registry.nameainsi quevalue.converter.registry.namedéfinir le registre de schéma à utiliser.key.converter.compatibilityainsi quevalue.converter.compatibilitydéfinir le modèle de compatibilité.
Reportez-vous à Utilisation de Kafka Connect avec AWS Glue Schema Registry pour plus d'information.
- Ensuite, nous configurons Capacité du connecteur. Nous pouvons choisir Provisionné et laissez les autres propriétés par défaut
- Pour Configuration du nœud de calcul, choisissez la configuration de nœud de calcul personnalisée dont le nom commence
msk-gsr-blogcréé dans le cadre du modèle CloudFormation. - Pour Autorisations d'accès, Utilisez l' Gestion des identités et des accès AWS (IAM) rôle généré par le modèle CloudFormation
MSKConnectRole. - Selectionnez Suivant.
- Pour Sécurité, choisissez les valeurs par défaut.
- Selectionnez Suivant.
- Pour Livraison de journaux, sélectionnez Diffuser vers Amazon CloudWatch Logs et recherchez le groupe de journaux créé par le modèle CloudFormation (
msk-connector-logs). - Selectionnez Suivant.
- Vérifiez les paramètres et choisissez Créer un connecteur.
Après quelques minutes, le connecteur passe à l'état de fonctionnement.
Utiliser le registre de schémas AWS Glue avec le connecteur de récepteur Confluent S3 exécuté sur MSK Connect en tant que consommateur MSK
Nous déployons le connecteur de récepteur à l'aide du plug-in de récepteur Confluent S3 pour diffuser des données d'Amazon MSK vers Amazon S3. Effectuez les étapes suivantes :
-
- Sur la console Amazon MSK, dans le volet de navigation, sous MSK Connecter, choisissez Connecteurs RF.
- Selectionnez Créer un connecteur.
- Selectionnez Utiliser le plugin personnalisé existant et choisissez le plugin personnalisé avec le nom commençant
msk-blog-S3sink-plugin. - Selectionnez Suivant.
- Entrez un nom approprié comme
s3-sink-connectoret une description facultative. - Pour Grappe Apache Kafka, choisissez Pôle MSK et sélectionnez le cluster créé par le modèle CloudFormation.
- In Configuration du connecteur, supprimez les valeurs par défaut fournies et utilisez les paires clé-valeur de configuration suivantes avec les valeurs appropriées :
-
- prénom – Le même nom utilisé pour le connecteur.
- s3.bucket.nom – La sortie CloudFormation pour Nom du seau.
- s3.region, key.converter.region et value.converter.region – Votre Région.
-
- Ensuite, nous configurons Capacité du connecteur. Nous pouvons choisir Provisionné et laissez les autres propriétés par défaut
- Pour Configuration du nœud de calcul, choisissez la configuration de nœud de calcul personnalisée dont le nom commence
msk-gsr-blogcréé dans le cadre du modèle CloudFormation. - Pour Autorisations d'accès, utilisez le rôle IAM généré par le modèle CloudFormation
MSKConnectRole. - Selectionnez Suivant.
- Pour Sécurité, choisissez les valeurs par défaut.
- Selectionnez Suivant.
- Pour Livraison de journaux, sélectionnez Diffuser vers Amazon CloudWatch Logs et recherchez le groupe de journaux créé par le modèle CloudFormation
msk-connector-logs. - Selectionnez Suivant.
- Vérifiez les paramètres et choisissez Créer un connecteur.
Après quelques minutes, le connecteur fonctionne.
Tester le flux de journaux CDC de bout en bout
Maintenant que les connecteurs de récepteur Debezium et S3 sont opérationnels, procédez comme suit pour tester le CDC de bout en bout :
- Sur la console Amazon EC2, accédez au Groupes de sécurité .
- Sélectionnez le groupe de sécurité
ClientInstanceSecurityGroupet choisissez Modifier les règles entrantes. - Ajoutez une règle entrante autorisant la connexion SSH depuis votre réseau local.
- Sur le Cas page, sélectionnez l'instance
ClientInstanceet choisissez NOUS CONTACTER. - Sur le Connexion à l'instance EC2 onglet, choisissez NOUS CONTACTER.
- Assurez-vous que votre répertoire de travail actuel est
/home/ec2-useret il a les fichierscreate_table.sql,alter_table.sql,initial_insert.sqletinsert_data_with_new_column.sql. - Créez une table dans votre base de données MySQL en exécutant la commande suivante (fournissez le nom d'hôte de la base de données à partir des sorties du modèle CloudFormation) :
- Lorsque vous êtes invité à entrer un mot de passe, entrez le mot de passe à partir des paramètres du modèle CloudFormation.
- Insérez des exemples de données dans le tableau à l'aide de la commande suivante :
- Lorsque vous êtes invité à entrer un mot de passe, entrez le mot de passe à partir des paramètres du modèle CloudFormation.
- Sur la console AWS Glue, choisissez Registres de schéma dans le volet de navigation, puis choisissez Schémas.
- Accédez à
db1.sampledatabase.moviesversion 1 pour vérifier le nouveau schéma créé pour la table movies :
Un dossier S3 distinct est créé pour chaque partition du sujet Kafka et les données du sujet sont écrites dans ce dossier.
- Sur la console Amazon S3, recherchez les données écrites au format Parquet dans le dossier de votre rubrique Kafka.
Évolution du schéma
Une fois le schéma initial défini, les applications peuvent avoir besoin de le faire évoluer au fil du temps. Lorsque cela se produit, il est essentiel que les consommateurs en aval soient en mesure de gérer les données encodées avec l'ancien et le nouveau schéma de manière transparente. Les modes de compatibilité vous permettent de contrôler la manière dont les schémas peuvent ou non évoluer dans le temps. Ces modes forment le contrat entre les applications produisant et consommant des données. Pour des informations détaillées sur les différents modes de compatibilité disponibles dans le registre de schémas AWS Glue, reportez-vous à Registre de schémas AWS Glue. Dans notre exemple, nous utilisons la combabilité descendante pour nous assurer que les consommateurs peuvent lire à la fois les versions de schéma actuelles et précédentes. Effectuez les étapes suivantes :
- Ajoutez une nouvelle colonne au tableau en exécutant la commande suivante :
- Insérez de nouvelles données dans la table en exécutant la commande suivante :
- Sur la console AWS Glue, choisissez Registres de schéma dans le volet de navigation, puis choisissez Schémas.
- Accédez au schéma
db1.sampledatabase.moviesversion 2 pour vérifier la nouvelle version du schéma créé pour la table movies movies incluant la colonne country que vous avez ajoutée :
- Sur la console Amazon S3, recherchez les données écrites au format Parquet dans le dossier de la rubrique Kafka.
Nettoyer
Pour éviter des frais indésirables sur votre compte AWS, supprimez les ressources AWS que vous avez utilisées dans cet article :
- Sur la console Amazon S3, accédez au compartiment S3 créé par le modèle CloudFormation.
- Sélectionnez tous les fichiers et dossiers et choisissez Supprimer.
- Entrez supprimer définitivement comme indiqué et choisissez Supprimer des objets.
- Sur la console AWS CloudFormation, supprimez la pile que vous avez créée.
- Attendez que l'état de la pile passe à DELETE_COMPLETE.
Conclusion
Cet article a montré comment utiliser Amazon MSK, MSK Connect et le registre de schémas AWS Glue pour créer un flux de journaux CDC et faire évoluer les schémas des flux de données à mesure que les besoins de l'entreprise évoluent. Vous pouvez appliquer ce modèle d'architecture à d'autres sources de données avec différents connecteurs Kafka. Pour plus d'informations, reportez-vous au Exemples de MSK Connect.
À propos de l’auteur
 Kalyan Janaki est spécialiste principal du Big Data et de l'analyse chez Amazon Web Services. Il aide les clients à concevoir et à créer des solutions basées sur le cloud hautement évolutives, performantes et sécurisées sur AWS.
Kalyan Janaki est spécialiste principal du Big Data et de l'analyse chez Amazon Web Services. Il aide les clients à concevoir et à créer des solutions basées sur le cloud hautement évolutives, performantes et sécurisées sur AWS.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :est
- $UP
- 1
- 10
- 11
- 7
- 8
- a
- Capable
- Qui sommes-nous
- accès
- Compte
- Avec cette connaissance vient le pouvoir de prendre
- reconnaître
- ajoutée
- ajout
- Tous
- Permettre
- permet
- déjà
- Amazon
- Amazon EC2
- Amazon Web Services
- analytique
- ainsi que
- Apache
- Apache Kafka
- applications
- Appliquer
- approprié
- architecture
- SONT
- AS
- Aurora
- automatiquement
- disponibles
- AWS
- AWS CloudFormation
- Colle AWS
- BE
- before
- avantages.
- jusqu'à XNUMX fois
- Big
- Big Data
- Bootstrap
- construire
- la performance des entreprises
- by
- CAN
- capacités
- capturer
- Capturer
- cas
- catalogue
- CDC
- centralisée
- Change
- Modifications
- des charges
- vérifier
- Contrôles
- Selectionnez
- classe
- Grappe
- Colonne
- Communautés
- compatibilité
- compatible
- complet
- composant
- calcul
- configuration
- ConFluent™
- NOUS CONTACTER
- connexion
- Console
- constant
- consommer
- consommateur
- Les consommateurs
- continuellement
- contrat
- des bactéries
- Pays
- engendrent
- créée
- critique
- Courant
- Customiser
- Clients
- données
- intégration de données
- data-driven
- Base de données
- bases de données
- jours
- décisions
- Réglage par défaut
- par défaut
- défini
- livrer
- Démo
- démontré
- démontre
- déployer
- déployé
- la description
- destination
- détaillé
- détails
- différent
- découvrez
- Ne fait pas
- Goutte
- chacun
- élimine
- permettant
- end-to-end
- assurer
- Assure
- Entrer
- Environment
- erreur
- notamment
- Ether (ETH)
- Chaque
- évolue
- exemple
- existant
- existe
- few
- Des champs
- Déposez votre dernière attestation
- Fichiers
- finale
- Prénom
- Abonnement
- Pour
- formulaire
- le format
- de
- générer
- généré
- Réservation de groupe
- Groupes
- manipuler
- Maniabilité
- arrive
- Vous avez
- aider
- aide
- très
- Histoire
- hôte
- HEURES
- Comment
- How To
- HTML
- http
- HTTPS
- Moyeu
- IAM
- identifier
- Active
- la mise en oeuvre
- important
- in
- Y compris
- index
- d'information
- initiale
- installer
- instance
- plutôt ;
- intégrer
- l'intégration
- interne
- IT
- Java
- jpg
- json
- kafka
- ACTIVITES
- Savoir
- Laisser
- bibliothèques
- Autorisé
- comme
- charge
- chargement
- locales
- Location
- LES PLANTES
- FAIT DU
- Fabrication
- gérés
- maître
- max
- maximales
- mécanisme
- message
- messages
- pourrait
- minutes
- modèle
- modes
- moniteurs
- PLUS
- Films
- en mouvement
- plusieurs
- MySQL
- prénom
- NAVIGUER
- Navigation
- Besoin
- nécessaire
- Besoins
- réseau et
- Nouveauté
- next
- nombre
- of
- Vieux
- on
- ONE
- open source
- Autre
- sortie
- page
- paires
- pain
- paramètre
- paramètres
- partie
- passé
- Mot de Passe
- Patron de Couture
- effectuer
- définitivement
- en particulier pendant la préparation
- Platon
- Intelligence des données Platon
- PlatonDonnées
- plug-in
- plugins
- Post
- empêcher
- précédent
- processus
- traitement
- produire
- producteur
- propriétés
- fournir
- à condition de
- fournit
- Lire
- réal
- en temps réel
- recevoir
- record
- Articles
- se réfère
- région
- vous inscrire
- inscrit
- enregistrement
- dépôt
- représenté
- Ressources
- Retours
- Rôle
- Règle
- Courir
- pour le running
- même
- évolutive
- de façon transparente
- Rechercher
- secondes
- sécurisé
- sécurité
- supérieur
- sensible
- séparé
- service
- Services
- set
- Paramétres
- devrait
- étapes
- simplifier
- sur mesure
- Solutions
- quelques
- Identifier
- Sources
- spécialiste
- groupe de neurones
- spécifié
- empiler
- Commencez
- Statut
- étapes
- Étapes
- storage
- Boutique
- STORES
- courant
- streaming
- flux
- structure
- convient
- Appuyer
- Les soutiens
- synchroniser.
- combustion propre
- Système
- table
- Target
- tâches
- modèle
- tester
- qui
- Les
- La Source
- Les
- Ces
- fiable
- sensibles au temps
- Titre
- à
- sujet
- Transactions
- TOUR
- types
- sous
- indésirable
- la mise à jour
- utilisé
- Utilisateur
- Plus-value
- Valeurs
- version
- web
- services Web
- qui
- sera
- fenêtres
- comprenant
- travailleur
- ouvriers
- de travail
- vos contrats
- code écrit
- Votre
- zéphyrnet