Recherche de colonnes similaires dans un lac de données a des applications importantes dans le nettoyage et l'annotation des données, la mise en correspondance de schémas, la découverte de données et l'analyse sur plusieurs sources de données. L'incapacité de trouver et d'analyser avec précision des données provenant de sources disparates représente un tueur d'efficacité potentiel pour tout le monde, des scientifiques des données, des chercheurs médicaux, des universitaires aux analystes financiers et gouvernementaux.
Les solutions conventionnelles impliquent la recherche de mots-clés lexicaux ou la correspondance d'expressions régulières, qui sont sensibles aux problèmes de qualité des données tels que l'absence de noms de colonnes ou différentes conventions de dénomination de colonnes dans divers ensembles de données (par exemple, zip_code, zcode, postalcode).
Dans cet article, nous présentons une solution pour rechercher des colonnes similaires en fonction du nom de la colonne, du contenu de la colonne ou des deux. La solution utilise algorithmes approximatifs des plus proches voisins disponible dans Service Amazon OpenSearch pour rechercher des colonnes sémantiquement similaires. Pour faciliter la recherche, nous créons des représentations de caractéristiques (incorporations) pour des colonnes individuelles dans le lac de données à l'aide de modèles Transformer pré-formés à partir du bibliothèque de transformateurs de phrases in Amazon Sage Maker. Enfin, pour interagir avec et visualiser les résultats de notre solution, nous construisons un Rationalisé application Web s'exécutant sur AWSFargate.
Nous incluons un tutoriel de code pour que vous déployiez les ressources nécessaires à l'exécution de la solution sur des exemples de données ou sur vos propres données.
Vue d'ensemble de la solution
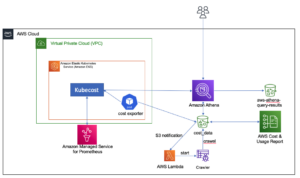
Le diagramme d'architecture suivant illustre le flux de travail en deux étapes pour rechercher des colonnes sémantiquement similaires. La première étape exécute un Fonctions d'étape AWS workflow qui crée des incorporations à partir de colonnes tabulaires et construit l'index de recherche OpenSearch Service. La deuxième étape, ou l'étape d'inférence en ligne, exécute une application Streamlit via Fargate. L'application Web collecte les requêtes de recherche d'entrée et récupère à partir de l'index du service OpenSearch les k colonnes approximatives les plus similaires à la requête.

Figure 1. Architecture de la solution
Le flux de travail automatisé se déroule selon les étapes suivantes :
- L'utilisateur télécharge des ensembles de données tabulaires dans un Service de stockage simple Amazon (Amazon S3), qui appelle un AWS Lambda fonction qui lance le workflow Step Functions.
- Le flux de travail commence par un Colle AWS travail qui convertit les fichiers CSV en Parquet Apache format de données.
- Une tâche de traitement SageMaker crée des intégrations pour chaque colonne à l'aide de modèles pré-formés ou de modèles d'intégration de colonne personnalisés. La tâche de traitement SageMaker enregistre les intégrations de colonnes pour chaque table dans Amazon S3.
- Une fonction Lambda crée le domaine et le cluster OpenSearch Service pour indexer les incorporations de colonnes produites à l'étape précédente.
- Enfin, une application web interactive Streamlit est déployée avec Fargate. L'application Web fournit une interface permettant à l'utilisateur de saisir des requêtes pour rechercher dans le domaine OpenSearch Service des colonnes similaires.
Vous pouvez télécharger le didacticiel de code à partir de GitHub pour essayer cette solution sur des exemples de données ou sur vos propres données. Des instructions sur la façon de déployer les ressources requises pour ce didacticiel sont disponibles sur Github.
Prérequis
Pour mettre en œuvre cette solution, vous avez besoin des éléments suivants :
- An Compte AWS.
- Familiarité de base avec les services AWS tels que le Kit de développement AWS Cloud (AWS CDK), Lambda, OpenSearch Service et SageMaker Processing.
- Un jeu de données tabulaire pour créer l'index de recherche. Vous pouvez apporter vos propres données tabulaires ou télécharger les exemples d'ensembles de données sur GitHub.
Créer un index de recherche
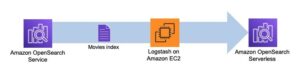
La première étape construit l'index du moteur de recherche de colonne. La figure suivante illustre le workflow Step Functions qui exécute cette étape.

Figure 2 - Flux de travail des fonctions d'étape - plusieurs modèles d'intégration
Jeux de données
Dans cet article, nous construisons un index de recherche pour inclure plus de 400 colonnes à partir de plus de 25 ensembles de données tabulaires. Les ensembles de données proviennent des sources publiques suivantes :
Pour la liste complète des tables incluses dans l'index, consultez le didacticiel de code sur GitHub.
Vous pouvez apporter votre propre ensemble de données tabulaires pour compléter les exemples de données ou créer votre propre index de recherche. Nous incluons deux fonctions Lambda qui lancent le flux de travail Step Functions pour créer l'index de recherche pour des fichiers CSV individuels ou un lot de fichiers CSV, respectivement.
Transformer CSV en parquet
Les fichiers CSV bruts sont convertis au format de données Parquet avec AWS Glue. Parquet est un format de fichier au format orienté colonne préféré dans l'analyse de données volumineuses qui fournit une compression et un encodage efficaces. Dans nos expériences, le format de données Parquet offrait une réduction significative de la taille de stockage par rapport aux fichiers CSV bruts. Nous avons également utilisé Parquet comme format de données commun pour convertir d'autres formats de données (par exemple JSON et NDJSON) car il prend en charge les structures de données imbriquées avancées.
Créer des représentations vectorielles continues de colonnes tabulaires
Pour extraire les représentations incorporées de colonnes de table individuelles dans les exemples d'ensembles de données tabulaires de cet article, nous utilisons les modèles pré-formés suivants à partir du sentence-transformers bibliothèque. Pour d'autres modèles, voir Modèles pré-entraînés.
La tâche de traitement SageMaker s'exécute create_embeddings.py(code) pour un seul modèle. Pour extraire les représentations incorporées de plusieurs modèles, le flux de travail exécute des tâches de traitement SageMaker parallèles, comme indiqué dans le flux de travail Step Functions. Nous utilisons le modèle pour créer deux ensembles d'intégrations :
- nom_colonne_embeddings – Embeddings de noms de colonnes (en-têtes)
- colonne_content_embeddings – Incorporation moyenne de toutes les lignes de la colonne
Pour plus d'informations sur le processus d'intégration de colonnes, consultez le didacticiel de code sur GitHub.
Une alternative à l'étape de traitement SageMaker consiste à créer une transformation par lots SageMaker pour obtenir des incorporations de colonnes sur de grands ensembles de données. Cela nécessiterait de déployer le modèle sur un point de terminaison SageMaker. Pour plus d'informations, voir Utiliser la transformation par lots.
Incorporations d'index avec OpenSearch Service
Dans la dernière étape de cette étape, une fonction Lambda ajoute les intégrations de colonnes à un k-Nearest-Neighbor approximatif du service OpenSearch (kNN) index de recherche. Chaque modèle se voit attribuer son propre index de recherche. Pour plus d'informations sur les paramètres approximatifs de l'index de recherche kNN, voir k-NN.
Inférence en ligne et recherche sémantique avec une application Web
La deuxième étape du workflow exécute une Rationalisé application Web où vous pouvez fournir des entrées et rechercher des colonnes sémantiquement similaires indexées dans OpenSearch Service. La couche application utilise un Équilibreur de charge d'application, Fargate et Lambda. L'infrastructure d'application est automatiquement déployée dans le cadre de la solution.
L'application vous permet de fournir une entrée et de rechercher des noms de colonne, un contenu de colonne ou les deux sémantiquement similaires. De plus, vous pouvez sélectionner le modèle d'intégration et le nombre de voisins les plus proches à renvoyer à partir de la recherche. L'application reçoit des entrées, intègre l'entrée avec le modèle spécifié et utilise Recherche kNN dans le service OpenSearch pour rechercher des représentations incorporées de colonnes indexées et trouver les colonnes les plus similaires à l'entrée donnée. Les résultats de recherche affichés incluent les noms de table, les noms de colonne et les scores de similarité pour les colonnes identifiées, ainsi que les emplacements des données dans Amazon S3 pour une exploration plus approfondie.
La figure suivante montre un exemple de l'application Web. Dans cet exemple, nous avons recherché des colonnes dans notre lac de données qui ont des Column Names (type de charge utile) À district (charge utile). L'application utilisée all-MiniLM-L6-v2 car modèle d'intégration et retourné 10 (k) voisins les plus proches de notre index OpenSearch Service.
La candidature est retournée transit_district, city, boroughet une location comme les quatre colonnes les plus similaires basées sur les données indexées dans OpenSearch Service. Cet exemple démontre la capacité de l'approche de recherche à identifier des colonnes sémantiquement similaires dans des ensembles de données.

Figure 3 : Interface utilisateur de l'application Web
Nettoyer
Pour supprimer les ressources créées par AWS CDK dans ce didacticiel, exécutez la commande suivante :
cdk destroy --allConclusion
Dans cet article, nous avons présenté un workflow de bout en bout pour créer un moteur de recherche sémantique pour les colonnes tabulaires.
Commencez dès aujourd'hui sur vos propres données avec notre tutoriel de code disponible sur GitHub. Si vous souhaitez obtenir de l'aide pour accélérer votre utilisation du ML dans vos produits et processus, veuillez contacter le Laboratoire de solutions Amazon Machine Learning.
À propos des auteurs
![]() Kachi Odoemène est scientifique appliquée chez AWS AI. Il construit des solutions AI/ML pour résoudre les problèmes commerciaux des clients AWS.
Kachi Odoemène est scientifique appliquée chez AWS AI. Il construit des solutions AI/ML pour résoudre les problèmes commerciaux des clients AWS.
![]() Taylor McNally est architecte d'apprentissage en profondeur chez Amazon Machine Learning Solutions Lab. Il aide les clients de divers secteurs à créer des solutions tirant parti de l'IA/ML sur AWS. Il aime une bonne tasse de café, le plein air et passer du temps avec sa famille et son chien énergique.
Taylor McNally est architecte d'apprentissage en profondeur chez Amazon Machine Learning Solutions Lab. Il aide les clients de divers secteurs à créer des solutions tirant parti de l'IA/ML sur AWS. Il aime une bonne tasse de café, le plein air et passer du temps avec sa famille et son chien énergique.
![]() Austin Welch est Data Scientist au Amazon ML Solutions Lab. Il développe des modèles d'apprentissage en profondeur personnalisés pour aider les clients du secteur public d'AWS à accélérer leur adoption de l'IA et du cloud. Dans ses temps libres, il aime lire, voyager et faire du jiu-jitsu.
Austin Welch est Data Scientist au Amazon ML Solutions Lab. Il développe des modèles d'apprentissage en profondeur personnalisés pour aider les clients du secteur public d'AWS à accélérer leur adoption de l'IA et du cloud. Dans ses temps libres, il aime lire, voyager et faire du jiu-jitsu.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- capacité
- A Propos
- absent
- accélérer
- accélérer
- avec précision
- à travers
- Supplémentaire
- En outre
- Ajoute
- Adoption
- Avancée
- AI
- AI / ML
- Tous
- permet
- alternative
- Amazon
- Apprentissage automatique d'Amazon
- Laboratoire de solutions Amazon ML
- Analystes
- analytique
- il analyse
- ainsi que le
- Apache
- Application
- applications
- appliqué
- une approche
- architecture
- attribué
- Automatisation
- automatiquement
- disponibles
- moyen
- AWS
- Colle AWS
- basé
- car
- Big
- Big Data
- apporter
- construire
- Développement
- construit
- la performance des entreprises
- Nettoyage
- le cloud
- adoption du cloud
- Grappe
- code
- Café
- recueille
- Colonne
- Colonnes
- Commun
- par rapport
- contact
- contenu
- Conventions
- convertir
- converti
- engendrent
- créée
- crée des
- Coupe
- Customiser
- Clients
- données
- Analyse de Donnée
- Lac de données
- qualité des données
- Data Scientist
- ensembles de données
- profond
- l'apprentissage en profondeur
- démontrer
- démontre
- déployer
- déployé
- déployer
- détruire
- Développement
- développe
- différent
- découverte
- disparate
- plusieurs
- Chien
- domaine
- download
- chacun
- efficace
- efficace
- end-to-end
- Endpoint
- Moteur
- Ether (ETH)
- tout le monde
- exemple
- exploration
- extrait
- faciliter
- Familiarité
- famille
- Fonctionnalités:
- Figure
- Déposez votre dernière attestation
- Fichiers
- finale
- finalement
- la traduction de documents financiers
- Trouvez
- trouver
- Prénom
- Abonnement
- le format
- De
- plein
- fonction
- fonctions
- plus
- obtenez
- donné
- Bien
- Gouvernement
- têtes
- vous aider
- aide
- Comment
- How To
- HTML
- HTTPS
- identifié
- identifier
- Mettre en oeuvre
- important
- in
- incapacité
- comprendre
- inclus
- indice
- individuel
- secteurs
- d'information
- Infrastructure
- initier
- Initie
- contribution
- Des instructions
- interagir
- Interactif
- Interfaces
- invoque
- impliquer
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- Emploi
- Emplois
- json
- laboratoire
- lac
- gros
- couche
- apprentissage
- en tirant parti
- Bibliothèque
- Liste
- charge
- emplacements
- click
- machine learning
- assorti
- médical
- ML
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- (en fait, presque toutes)
- plusieurs
- prénom
- noms
- nommage
- Besoin
- voisins
- nombre
- présenté
- en ligne
- Autre
- l'extérieur
- propre
- Parallèle
- paramètres
- partie
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- Post
- défaillances
- préféré
- présenté
- précédent
- d'ouvrabilité
- produit
- processus
- les process
- traitement
- Produit
- Produits
- fournir
- fournit
- public
- qualité
- raw
- en cours
- reçoit
- Standard
- représente
- exigent
- conditions
- chercheurs
- Resources
- respectivement
- Résultats
- retourner
- Courir
- pour le running
- sagemaker
- Scientifique
- scientifiques
- Rechercher
- moteur de recherche
- recherche
- Deuxièmement
- secteur
- service
- Services
- Sets
- montré
- Spectacles
- significative
- similaires
- étapes
- unique
- Taille
- sur mesure
- Solutions
- RÉSOUDRE
- Sources
- spécifié
- Étape
- j'ai commencé
- étapes
- Étapes
- storage
- tel
- Les soutiens
- sensible
- table
- La
- leur
- Avec
- fiable
- à
- aujourd'hui
- Transformer
- transformateurs
- Voyages
- tutoriel
- utilisé
- Utilisateur
- Interface utilisateur
- divers
- web
- application Web
- qui
- workflow
- pourra
- Votre
- zéphyrnet