Nous vivons à l’ère des données et des informations en temps réel, alimentées par des applications de streaming de données à faible latence. Aujourd’hui, tout le monde s’attend à une expérience personnalisée dans n’importe quelle application, et les organisations innovent constamment pour accélérer leurs opérations commerciales et leur prise de décision. Le volume de données sensibles au temps produit augmente rapidement, avec l'introduction de différents formats de données dans de nouvelles entreprises et dans de nouveaux cas d'utilisation par les clients. Il est donc essentiel que les organisations adoptent une infrastructure de streaming de données à faible latence, évolutive et fiable, afin de fournir des applications métier en temps réel et une meilleure expérience client.
Il s'agit du premier article d'une série de blogs proposant des modèles architecturaux courants pour la création d'infrastructures de streaming de données en temps réel à l'aide de Kinesis Data Streams pour un large éventail de cas d'utilisation. Il vise à fournir un cadre pour créer des applications de streaming à faible latence sur le cloud AWS en utilisant Flux de données Amazon Kinesis ainsi que Services d'analyse de données AWS spécialement conçus.
Dans cet article, nous passerons en revue les modèles architecturaux courants de deux cas d'utilisation : l'analyse de données de séries temporelles et les microservices pilotés par événements. Dans le prochain article de notre série, nous explorerons les modèles architecturaux dans la création de pipelines de streaming pour les tableaux de bord BI en temps réel, les agents de centre de contact, les données du grand livre, les recommandations personnalisées en temps réel, l'analyse des journaux, les données IoT, la capture des données modifiées et les données réelles. -données marketing temporelles. Tous ces modèles d'architecture sont intégrés à Amazon Kinesis Data Streams.
Streaming en temps réel avec Kinesis Data Streams
Amazon Kinesis Data Streams est un service de streaming de données cloud natif et sans serveur qui facilite la capture, le traitement et le stockage de données en temps réel à n'importe quelle échelle. Avec Kinesis Data Streams, vous pouvez collecter et traiter des centaines de gigaoctets de données par seconde provenant de centaines de milliers de sources, ce qui vous permet d'écrire facilement des applications qui traitent les informations en temps réel. Les données collectées sont disponibles en millisecondes pour permettre des cas d'utilisation d'analyse en temps réel, tels que des tableaux de bord en temps réel, la détection d'anomalies en temps réel et la tarification dynamique. Par défaut, les données de Kinesis Data Stream sont stockées pendant 24 heures avec une option permettant d'augmenter la conservation des données à 365 jours. Si les clients souhaitent traiter les mêmes données en temps réel avec plusieurs applications, ils peuvent alors utiliser la fonction Enhanced Fan-Out (EFO). Avant cette fonctionnalité, chaque application consommant des données du flux partageait la sortie de 2 Mo/seconde/fragment. En configurant les consommateurs de flux pour utiliser une distribution améliorée, chaque consommateur de données reçoit un canal dédié de débit de lecture de 2 Mo/seconde par partition afin de réduire davantage la latence de récupération des données.
Pour une disponibilité et une durabilité élevées, Kinesis Data Streams atteint une durabilité élevée en répliquant de manière synchrone les données diffusées en streaming sur trois zones de disponibilité dans une région AWS et vous offre la possibilité de conserver les données jusqu'à 365 jours. Pour des raisons de sécurité, Kinesis Data Streams fournit un chiffrement côté serveur afin que vous puissiez répondre aux exigences strictes de gestion des données en chiffrant vos données au repos et les points de terminaison de l'interface Amazon Virtual Private Cloud (VPC) pour maintenir la confidentialité du trafic entre votre Amazon VPC et Kinesis Data Streams.
Kinesis Data Streams dispose d'intégrations natives avec d'autres services AWS tels que Colle AWS ainsi que Amazon Event Bridge pour créer des applications de streaming en temps réel sur AWS. Reportez-vous aux intégrations Amazon Kinesis Data Streams pour plus de détails.
Architecture de streaming de données moderne avec Kinesis Data Streams
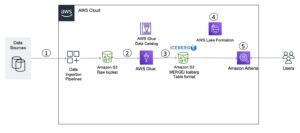
Une architecture de données de streaming moderne avec Kinesis Data Streams peut être conçue comme une pile de cinq couches logiques : chaque couche est composée de plusieurs composants spécialement conçus qui répondent à des exigences spécifiques, comme illustré dans le diagramme suivant :
L'architecture se compose des composants clés suivants :
- Sources de diffusion en continu – Votre source de données de streaming comprend des sources de données telles que les données de parcours, les capteurs, les réseaux sociaux, les appareils Internet des objets (IoT), les fichiers journaux générés par l'utilisation de vos applications Web et mobiles, ainsi que les appareils mobiles qui génèrent des données semi-structurées et non structurées sous forme de flux continus. à grande vitesse.
- Ingestion de flux – La couche d'ingestion de flux est responsable de l'ingestion des données dans la couche de stockage de flux. Il offre la possibilité de collecter des données provenant de dizaines de milliers de sources de données et de les ingérer en temps réel. Vous pouvez utiliser le Kit de développement logiciel Kinesis pour ingérer des données en streaming via des API, le Bibliothèque du producteur Kinesis pour créer des producteurs de streaming performants et durables, ou un Agent Kinésis pour collecter un ensemble de fichiers et les ingérer dans Kinesis Data Streams. De plus, vous pouvez utiliser de nombreuses intégrations pré-build telles que Service de migration de base de données AWS (AWS DMS), Amazon DynamoDBet une Noyau AWS IoT pour ingérer des données sans code. Vous pouvez également ingérer des données provenant de plateformes tierces telles qu'Apache Spark et Apache Kafka Connect.
- Stockage de flux – Kinesis Data Streams propose deux modes pour prendre en charge le débit de données : à la demande et provisionné. Le mode à la demande, désormais choisi par défaut, peut évoluer de manière élastique pour absorber des débits variables, de sorte que les clients n'ont pas à se soucier de la gestion de la capacité et à payer en fonction du débit de données. Le mode à la demande augmente automatiquement de 2 fois la capacité du flux par rapport à son ingestion maximale de données historique pour fournir une capacité suffisante pour faire face aux pics inattendus d'ingestion de données. Alternativement, les clients qui souhaitent un contrôle granulaire sur les ressources de flux peuvent utiliser le mode provisionné et augmenter et réduire de manière proactive le nombre de fragments pour répondre à leurs exigences de débit. De plus, Kinesis Data Streams peut stocker des données de streaming jusqu'à 24 heures par défaut, mais peut s'étendre jusqu'à 7 jours ou 365 jours selon les cas d'utilisation. Plusieurs applications peuvent consommer le même flux.
- Traitement du flux – La couche de traitement de flux est chargée de transformer les données en un état consommable via la validation, le nettoyage, la normalisation, la transformation et l'enrichissement des données. Les enregistrements en streaming sont lus dans l'ordre dans lequel ils sont produits, ce qui permet des analyses en temps réel, la création d'applications événementielles ou le streaming ETL (extraction, transformation et chargement). Vous pouvez utiliser Service géré Amazon pour Apache Flink pour le traitement de données de flux complexes, AWS Lambda pour le traitement des données de flux sans état, et Colle AWS & Amazon DME pour un calcul en temps quasi réel. Vous pouvez également créer des applications grand public personnalisées avec Bibliothèque grand public Kinesis, qui prendra en charge de nombreuses tâches complexes associées à l’informatique distribuée.
- Destination - La couche de destination est comme une destination spécialement conçue en fonction de votre cas d'utilisation. Vous pouvez diffuser des données directement vers Redshift d'Amazon pour l'entreposage de données et Amazon EventBridge pour la création d'applications basées sur des événements. Vous pouvez aussi utiliser Firehose de données Amazon Kinesis pour l'intégration du streaming où vous pouvez alléger le traitement du flux avec AWS Lambda, puis diffuser le streaming traité vers des destinations telles que Amazon S3 lac de données, OpenSearch Service pour l'analyse opérationnelle, un entrepôt de données Redshift, des bases de données No-SQL comme Amazon DynamoDB et des bases de données relationnelles comme Amazon RDS pour consommer des flux en temps réel dans des applications métiers. La destination peut être une application basée sur les événements pour des tableaux de bord en temps réel, des décisions automatiques basées sur des données de streaming traitées, des modifications en temps réel, etc.
Architecture d'analyse en temps réel pour les séries chronologiques
Les données de séries chronologiques sont une séquence de points de données enregistrés sur un intervalle de temps pour mesurer des événements qui changent au fil du temps. Les exemples sont les cours des actions au fil du temps, les flux de clics sur les pages Web et les journaux des appareils au fil du temps. Les clients peuvent utiliser des données de séries chronologiques pour surveiller les changements au fil du temps, afin de pouvoir détecter les anomalies, identifier les modèles et analyser l'influence de certaines variables au fil du temps. Les données de séries chronologiques sont généralement générées à partir de sources multiples en volumes élevés et doivent être collectées de manière rentable et en temps quasi réel.
En règle générale, les clients souhaitent atteindre trois objectifs principaux lors du traitement des données de séries chronologiques :
- Obtenez des informations en temps réel sur les performances du système et détectez les anomalies
- Comprendre le comportement de l'utilisateur final pour suivre les tendances et interroger/créer des visualisations à partir de ces informations
- Disposez d’une solution de stockage durable pour ingérer et stocker les données archivées et fréquemment consultées.
Avec Kinesis Data Streams, les clients peuvent capturer en continu des téraoctets de données de séries chronologiques provenant de milliers de sources à des fins de nettoyage, d'enrichissement, de stockage, d'analyse et de visualisation.
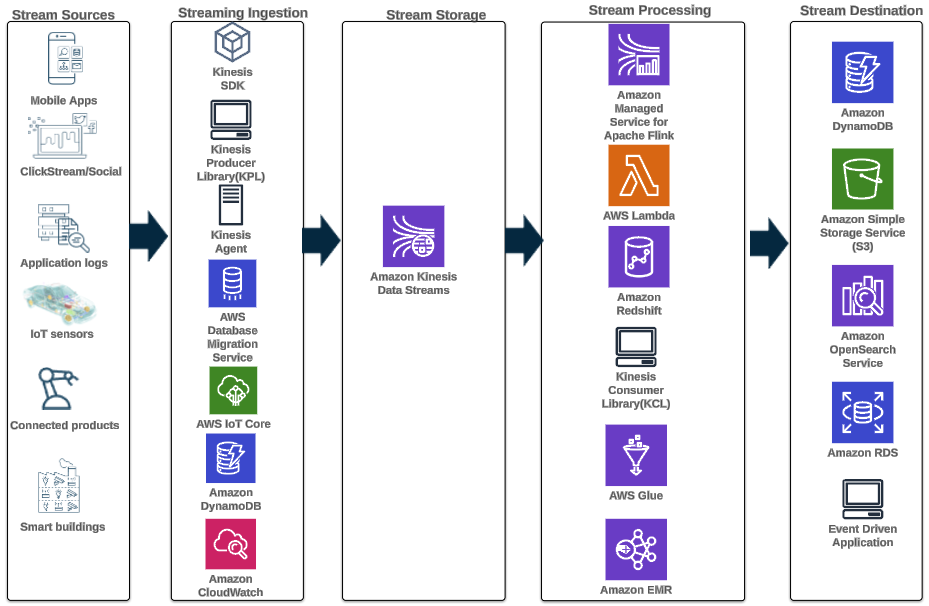
Le modèle d'architecture suivant illustre comment réaliser des analyses en temps réel pour les données de séries temporelles avec Kinesis Data Streams :
Les étapes du flux de travail sont les suivantes :
- Ingestion et stockage de données – Kinesis Data Streams peut capturer et stocker en continu des téraoctets de données provenant de milliers de sources.
- Traitement des flux – Une application créée avec Service géré Amazon pour Apache Flink peut lire les enregistrements du flux de données pour détecter et nettoyer toute erreur dans les données de série chronologique et enrichir les données avec des métadonnées spécifiques pour optimiser l'analyse opérationnelle. L'utilisation d'un flux de données au milieu offre l'avantage d'utiliser les données de séries chronologiques dans d'autres processus et solutions en même temps. Une fonction Lambda est ensuite invoquée avec ces événements et peut effectuer des calculs de séries chronologiques en mémoire.
- Destinations – Après nettoyage et enrichissement, les données de séries chronologiques traitées peuvent être diffusées vers Flux temporel d'Amazon base de données pour la création de tableaux de bord et d'analyses en temps réel, ou stockée dans des bases de données telles que DynamoDB pour les requêtes de l'utilisateur final. Les données brutes peuvent être diffusées sur Amazon S3 pour archivage.
- Visualisation et obtenir des informations – Les clients peuvent interroger, visualiser et créer des alertes à l’aide Service géré Amazon pour Grafana. Grafana prend en charge les sources de données qui sont des backends de stockage pour les données de séries chronologiques. Pour accéder à vos données depuis Timestream, vous devez installer le plugin Timestream pour Grafana. Les utilisateurs finaux peuvent interroger les données de la table DynamoDB avec Passerelle d'API Amazon agissant en qualité de mandataire.
Reportez-vous à Traitement en temps quasi réel avec Amazon Kinesis, Amazon Timestream et Grafana présentant un pipeline de streaming sans serveur pour traiter et stocker les données IoT de télémétrie des appareils dans un magasin de données optimisé pour les séries chronologiques tel qu'Amazon Timestream.
Enrichissement et relecture des données en temps réel pour les microservices de sourcing d'événements
Les microservices sont une approche architecturale et organisationnelle du développement de logiciels dans laquelle les logiciels sont composés de petits services indépendants qui communiquent via des API bien définies. Lors de la création de microservices événementiels, les clients souhaitent atteindre 1. une évolutivité élevée pour gérer le volume d'événements entrants et 2. la fiabilité du traitement des événements et maintenir la fonctionnalité du système face aux pannes.
Les clients utilisent des modèles d'architecture de microservices pour accélérer l'innovation et les délais de commercialisation des nouvelles fonctionnalités, car cela facilite la mise à l'échelle des applications et accélère leur développement. Cependant, il est difficile d'enrichir et de relire les données lors d'un appel réseau vers un autre microservice, car cela peut avoir un impact sur la fiabilité de l'application et rendre difficile le débogage et le traçage des erreurs. Pour résoudre ce problème, la source d'événements est un modèle de conception efficace qui centralise les enregistrements historiques de tous les changements d'état à des fins d'enrichissement et de relecture, et dissocie les charges de travail de lecture des charges de travail d'écriture. Les clients peuvent utiliser Kinesis Data Streams comme magasin d'événements centralisé pour les microservices de sourcing d'événements, car KDS peut 1/ gérer des gigaoctets de débit de données par seconde par flux et diffuser les données en millisecondes, pour répondre aux exigences de haute évolutivité et de quasi-temps réel. latence, 2/ intégrer avec Flink et S3 pour l'enrichissement et la réalisation des données tout en étant complètement découplé des microservices, et 3/ permettre une nouvelle tentative et une lecture asynchrone ultérieurement, car KDS conserve l'enregistrement de données pendant 24 heures par défaut, et en option jusqu'à 365 jours.
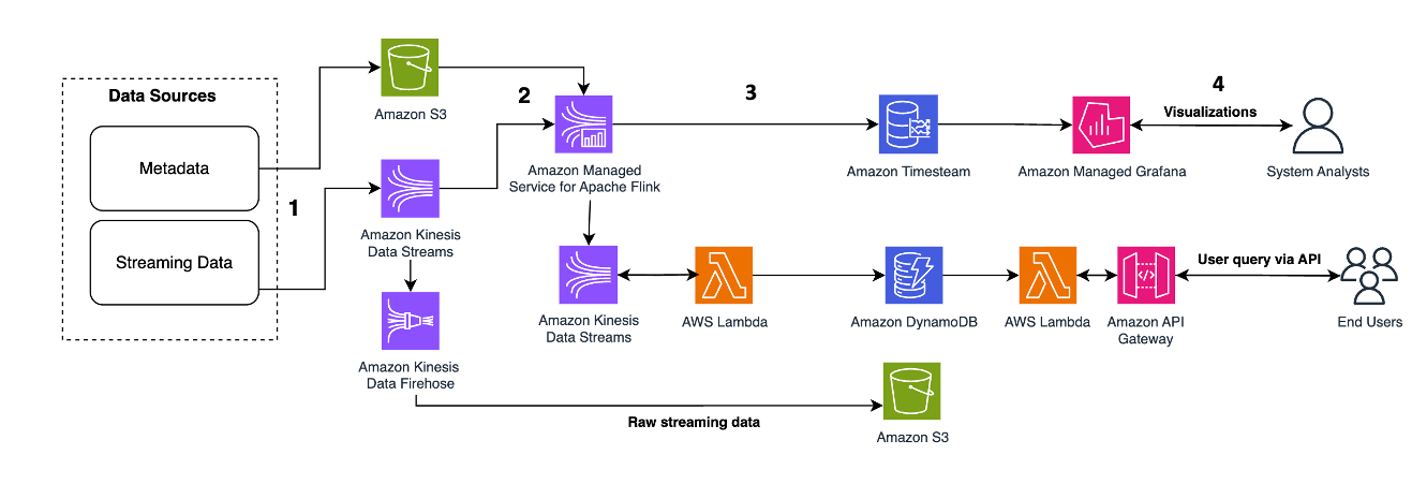
Le modèle architectural suivant est une illustration générique de la façon dont Kinesis Data Streams peut être utilisé pour les microservices de sourcing d'événements :
Les étapes du flux de travail sont les suivantes :
- Ingestion et stockage de données – Vous pouvez regrouper les entrées de vos microservices dans vos flux de données Kinesis pour le stockage.
- Traitement de flux - Fonctions avec état Apache Flink simplifie la création d'applications événementielles distribuées avec état. Il peut recevoir les événements d'un flux de données Kinesis d'entrée et acheminer le flux résultant vers un flux de données de sortie. Vous pouvez créer un cluster de fonctions avec état avec Apache Flink en fonction de la logique métier de votre application.
- Instantané d'état dans Amazon S3 – Vous pouvez stocker l'instantané d'état dans Amazon S3 pour le suivi.
- Flux de sortie – Les flux de sortie peuvent être consommés via les fonctions distantes Lambda via le protocole HTTP/gRPC via API Gateway.
- Fonctions à distance Lambda – Les fonctions Lambda peuvent agir comme des microservices pour diverses applications et logiques métier afin de servir des applications métier et des applications mobiles.
Pour découvrir comment d'autres clients ont créé leurs microservices basés sur des événements avec Kinesis Data Streams, reportez-vous à ce qui suit :
Considérations clés et meilleures pratiques
Voici les considérations et les bonnes pratiques à garder à l’esprit :
- La découverte de données devrait être votre première étape dans la création d'applications modernes de streaming de données. Vous devez définir la valeur commerciale, puis identifier vos sources de données de streaming et vos profils d'utilisateurs pour obtenir les résultats commerciaux souhaités.
- Choisissez votre outil d'ingestion de données en continu en fonction de votre source de données en continu. Par exemple, vous pouvez utiliser le Kit de développement logiciel Kinesis pour ingérer des données en streaming via des API, le Bibliothèque du producteur Kinesis pour créer des producteurs de streaming performants et durables, un Agent Kinésis pour collecter un ensemble de fichiers et les ingérer dans Kinesis Data Streams, AWSDMS pour les cas d'utilisation du streaming CDC, et Noyau AWS IoT pour ingérer les données des appareils IoT dans Kinesis Data Streams. Vous pouvez ingérer des données de streaming directement dans Amazon Redshift pour créer des applications de streaming à faible latence. Vous pouvez également utiliser des bibliothèques tierces comme Apache Spark et Apache Kafka pour ingérer des données en streaming dans Kinesis Data Streams.
- Vous devez choisir vos services de traitement de données en streaming en fonction de votre cas d'utilisation spécifique et des exigences de votre entreprise. Par exemple, vous pouvez utiliser Amazon Kinesis Managed Service pour Apache Flink pour des cas d'utilisation de streaming avancés avec plusieurs destinations de streaming et un traitement de flux avec état complexe ou si vous souhaitez surveiller les métriques commerciales en temps réel (par exemple toutes les heures). Lambda est idéal pour le traitement basé sur les événements et sans état. Vous pouvez utiliser Amazon DME pour le traitement des données en streaming afin d'utiliser vos frameworks Big Data open source préférés. AWS Glue est idéal pour le traitement des données en streaming en temps quasi réel pour des cas d'utilisation tels que le streaming ETL.
- Le mode à la demande Kinesis Data Streams facture en fonction de l'utilisation et augmente automatiquement la capacité des ressources, ce qui le rend idéal pour les charges de travail de streaming pointues et la maintenance mains libres. Le mode provisionné facture en fonction de la capacité et nécessite une gestion proactive de la capacité. Il convient donc aux charges de travail de streaming prévisibles.
- Vous pouvez utiliser le Calculateur partagé Kinesis pour calculer le nombre de fragments nécessaires pour le mode provisionné. Vous n’avez pas à vous soucier des fragments avec le mode à la demande.
- Lorsque vous accordez des autorisations, vous décidez qui obtient quelles autorisations pour quelles ressources Kinesis Data Streams. Vous activez les actions spécifiques que vous souhaitez autoriser sur ces ressources. Par conséquent, vous devez accorder uniquement les autorisations requises pour effectuer une tâche. Vous pouvez également chiffrer les données au repos à l'aide d'une clé gérée par le client (CMK) KMS.
- Vous pouvez mettre à jour la période de conservation via la console Kinesis Data Streams ou en utilisant le Augmenter la période de rétention du flux et par DiminuerStreamRetentionPeriod opérations basées sur vos cas d’utilisation spécifiques.
- Kinesis Data Streams prend en charge repartitionnement. L'API recommandée pour cette fonction est Mettre à jourShardCount, qui vous permet de modifier le nombre de fragments dans votre flux pour vous adapter aux changements de débit de données via le flux. Les API de repartitionnement (Split et Merge) sont généralement utilisées pour gérer les fragments chauds.
Conclusion
Cet article présente divers modèles architecturaux pour créer des applications de streaming à faible latence avec Kinesis Data Streams. Vous pouvez créer vos propres applications de diffusion à faible latence avec Kinesis Data Streams en utilisant les informations contenues dans cet article.
Pour obtenir des modèles architecturaux détaillés, reportez-vous aux ressources suivantes :
Si vous souhaitez construire une vision et une stratégie de données, consultez le Tout basé sur les données AWS (D2E).
À propos des auteurs
 Raghavarao Sodabathina est architecte de solutions principal chez AWS, se concentrant sur l'analyse des données, l'IA/ML et la sécurité du cloud. Il s'engage avec les clients pour créer des solutions innovantes qui répondent aux problèmes commerciaux des clients et pour accélérer l'adoption des services AWS. Dans ses temps libres, Raghavarao aime passer du temps avec sa famille, lire des livres et regarder des films.
Raghavarao Sodabathina est architecte de solutions principal chez AWS, se concentrant sur l'analyse des données, l'IA/ML et la sécurité du cloud. Il s'engage avec les clients pour créer des solutions innovantes qui répondent aux problèmes commerciaux des clients et pour accélérer l'adoption des services AWS. Dans ses temps libres, Raghavarao aime passer du temps avec sa famille, lire des livres et regarder des films.
 Hang Zuo est chef de produit senior au sein de l'équipe Amazon Kinesis Data Streams chez Amazon Web Services. Il est passionné par le développement d'expériences produit intuitives qui résolvent les problèmes complexes des clients et permettent aux clients d'atteindre leurs objectifs commerciaux.
Hang Zuo est chef de produit senior au sein de l'équipe Amazon Kinesis Data Streams chez Amazon Web Services. Il est passionné par le développement d'expériences produit intuitives qui résolvent les problèmes complexes des clients et permettent aux clients d'atteindre leurs objectifs commerciaux.
 Shwetha Radhakrishnan est un architecte de solutions pour AWS avec une spécialisation en analyse de données. Elle a créé des solutions qui favorisent l'adoption du cloud et aident les organisations à prendre des décisions basées sur les données au sein du secteur public. En dehors du travail, elle aime danser, passer du temps avec ses amis et sa famille et voyager.
Shwetha Radhakrishnan est un architecte de solutions pour AWS avec une spécialisation en analyse de données. Elle a créé des solutions qui favorisent l'adoption du cloud et aident les organisations à prendre des décisions basées sur les données au sein du secteur public. En dehors du travail, elle aime danser, passer du temps avec ses amis et sa famille et voyager.
 Bretagne Ly est architecte de solutions chez AWS. Elle s'efforce d'aider les entreprises clientes dans leur parcours d'adoption et de modernisation du cloud et s'intéresse au domaine de la sécurité et de l'analyse. En dehors du travail, elle adore passer du temps avec son chien et jouer au pickleball.
Bretagne Ly est architecte de solutions chez AWS. Elle s'efforce d'aider les entreprises clientes dans leur parcours d'adoption et de modernisation du cloud et s'intéresse au domaine de la sécurité et de l'analyse. En dehors du travail, elle adore passer du temps avec son chien et jouer au pickleball.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 100
- 24
- 7
- a
- capacité
- A Propos
- accélérer
- accès
- accédé
- atteindre
- atteint
- Atteint
- la réalisation de
- à travers
- Agis
- intérim
- actes
- adapter
- ajout
- Supplémentaire
- En outre
- propos
- Adoption
- Avancée
- Avantage
- Après
- âge
- Agent
- agrégat
- AI / ML
- vise
- alertes
- Tous
- permettre
- Permettre
- permet
- aussi
- Amazon
- Amazon Kinésis
- Flux temporel d'Amazon
- Amazon Web Services
- an
- selon une analyse de l’Université de Princeton
- analytique
- il analyse
- ainsi que
- Détection d'une anomalie
- Une autre
- tous
- Apache
- Apache Kafka
- Apache Spark
- api
- Apis
- Application
- applications
- une approche
- applications
- architectural
- architecture
- SONT
- AS
- associé
- At
- Automatique
- automatiquement
- disponibilité
- disponibles
- AWS
- Colle AWS
- AWS Lambda
- basé
- BE
- car
- était
- humain
- va
- LES MEILLEURS
- les meilleures pratiques
- Améliorée
- jusqu'à XNUMX fois
- Big
- Big Data
- Blog
- Livres
- tous les deux
- construire
- Développement
- construit
- la performance des entreprises
- applications commerciales
- entreprises
- mais
- by
- calculer
- Appelez-nous
- CAN
- Compétences
- capturer
- les soins
- maisons
- cas
- CDC
- Canaux centraux
- centralisée
- certaines
- difficile
- Change
- Modifications
- des charges
- vérifier
- le choix
- Selectionnez
- espace extérieur plus propre,
- Nettoyage
- le cloud
- adoption du cloud
- Cloud Security
- Grappe
- recueillir
- Collecte
- Commun
- communiquer
- complètement
- complexe
- composants électriques
- composé
- calcul
- informatique
- concerné
- Configurer
- considérations
- consiste
- Console
- constamment
- consommer
- consommées
- consommateur
- Les consommateurs
- contact
- centre de contact
- continu
- continuellement
- des bactéries
- engendrent
- créée
- critique
- des clients
- Clients
- sont adaptées
- Danse
- tableaux de bord
- données
- l'analyse des données
- Analyse de Donnée
- enrichissement des données
- Lac de données
- gestion des données
- points de données
- informatique
- entrepôt de données
- data-driven
- Base de données
- bases de données
- jours
- décider
- décision
- La prise de décision
- décisions
- découplé
- dévoué
- Réglage par défaut
- Vous permet de définir
- livrer
- démontré
- Selon
- Conception
- un
- voulu
- destination
- destinations
- détaillé
- détails
- détecter
- Détection
- développer
- développement
- Développement
- dispositif
- Compatibles
- différent
- difficile
- directement
- découverte
- distribué
- informatique distribuée
- do
- Chien
- Ne pas
- down
- motivation
- entraîné
- durabilité
- Dynamic
- chacun
- plus facilement
- même
- Easy
- Efficace
- embrasser
- permettre
- chiffrement
- critères
- engage
- améliorée
- enrichir
- Entreprise
- clients entreprise
- Erreurs
- Ether (ETH)
- événement
- événements
- Chaque
- tout le monde
- exemple
- exemples
- attend
- d'experience
- Expériences
- explorez
- étendre
- extrait
- Visage
- échecs
- famille
- Mode
- plus rapide
- Favori
- Fonctionnalité
- Fonctionnalités:
- champ
- Fichiers
- Prénom
- cinq
- flux
- Focus
- concentré
- mettant l'accent
- Abonnement
- suit
- Pour
- Framework
- cadres
- fréquemment
- amis
- De
- fonction
- fonctions
- plus
- Gain
- porte
- générer
- généré
- obtention
- GitHub
- donne
- Objectifs
- Bien
- subvention
- octroi
- manipuler
- Accrochez
- he
- vous aider
- aider
- ici
- Haute
- haute performance
- sa
- historique
- HOT
- heure
- HEURES
- Comment
- Cependant
- HTML
- http
- HTTPS
- Des centaines
- identifier
- if
- illustre
- Impact
- in
- Dans d'autres
- inclut
- Nouveau
- Améliore
- croissant
- indépendant
- influencé
- d'information
- Infrastructure
- infrastructures
- innover
- Innovation
- technologie innovante
- contribution
- idées.
- installer
- intégrer
- des services
- l'intégration
- intégrations
- intérêt
- Interfaces
- Internet
- Internet des objets
- développement
- introduit
- intuitif
- invoqué
- IOT
- Dispositif IoT
- IT
- SES
- chemin
- jpg
- kafka
- XNUMX éléments à
- ACTIVITES
- Flux de données Kinesis
- lac
- Latence
- plus tard
- couche
- poules pondeuses
- APPRENTISSAGE
- Ledger
- bibliothèques
- Bibliothèque
- lumière
- comme
- vie
- charge
- enregistrer
- logique
- logique
- aime
- maintenir
- facile
- a prendre une
- FAIT DU
- Fabrication
- gérés
- gestion
- manager
- de nombreuses
- Stratégie
- maximales
- mesure
- Médias
- Découvrez
- Mémoire
- aller
- Métadonnées
- Métrique
- microservices
- Milieu
- migration
- millisecondes
- l'esprit
- Breeze Mobile
- Applications mobiles
- appareils mobiles
- application mobile
- Mode
- Villas Modernes
- modernisation
- modes
- modifier
- Surveiller
- PLUS
- Films
- plusieurs
- must
- indigène
- Près
- Besoin
- nécessaire
- Besoins
- réseau et
- Nouveauté
- Nouvelles fonctionnalités
- maintenant
- nombre
- of
- code
- Offres Speciales
- on
- À la demande
- uniquement
- ouvert
- open source
- opération
- opérationnel
- Opérations
- Optimiser
- optimisé
- Option
- or
- de commander
- organisationnel
- organisations
- Autre
- nos
- ande
- les résultats
- sortie
- au contrôle
- plus de
- propre
- partie
- passionné
- Patron de Couture
- motifs
- Payer
- /
- effectuer
- performant
- autorisations
- Personnalisé
- pipe
- pipeline
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Jouez
- plug-in
- des notes bonus
- Post
- pratiques
- Prévisible
- Tarifs
- établissement des prix
- primaire
- Directeur
- Avant
- Privé
- Cybersécurité
- Problème
- d'ouvrabilité
- processus
- traité
- les process
- traitement
- Produit
- producteur
- Nos producteurs
- Produit
- chef de produit
- Programme
- protocole
- fournir
- fournit
- procuration
- public
- gamme
- rapidement
- Tarif
- raw
- les données brutes
- Lire
- en cours
- réal
- en temps réel
- données en temps réel à grande vitesse.
- recevoir
- reçoit
- Recommandation
- recommandé
- record
- enregistré
- Articles
- réduire
- reportez-vous
- région
- fiabilité
- fiable
- éloigné
- conditions
- exigence
- Exigences
- a besoin
- ressource
- Resources
- responsables
- REST
- résultant
- conserver
- conserve
- rétention
- Avis
- Itinéraire
- même
- Évolutivité
- évolutive
- Escaliers intérieurs
- Balance
- Deuxièmement
- secteur
- sécurité
- supérieur
- capteur
- Séquence
- Série
- besoin
- Sans serveur
- service
- Services
- set
- commun
- elle
- devrait
- mettre en valeur
- simplifie
- petit
- Instantané
- So
- Réseaux sociaux
- réseaux sociaux
- Logiciels
- développement de logiciels
- sur mesure
- Solutions
- RÉSOUDRE
- Identifier
- Sources
- Spark
- groupe de neurones
- vitesse
- passer
- Dépenses
- pointes
- scission
- empiler
- Région
- étapes
- Étapes
- stock
- storage
- Boutique
- stockée
- de Marketing
- courant
- streaming
- streaming
- flux
- strict
- ultérieur
- tel
- suffisant
- Support
- Les soutiens
- combustion propre
- table
- Prenez
- Tâche
- tâches
- équipe
- dizaines
- qui
- La
- les informations
- L'État
- leur
- Les
- puis
- Là.
- donc
- Ces
- l'ont
- des choses
- des tiers.
- this
- ceux
- milliers
- trois
- Avec
- débit
- fiable
- Des séries chronologiques
- sensibles au temps
- à
- aujourd'hui
- outil
- tracer
- suivre
- Tracking
- circulation
- Transformer
- De La Carrosserie
- transformer
- Voyages
- Trends
- deux
- typiquement
- Inattendu
- sur
- Utilisation
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- en utilisant
- utiliser
- validation
- Plus-value
- variable
- divers
- Rapidité
- via
- Salle de conférence virtuelle
- vision
- visualisation
- visualiser
- le volume
- volumes
- souhaitez
- Entrepots
- Entreposage
- personne(s) regarde(nt) cette fiche produit
- we
- web
- services Web
- bien défini
- Quoi
- quand
- qui
- tout en
- WHO
- large
- Large gamme
- sera
- comprenant
- dans les
- activités principales
- workflow
- s'inquiéter
- écrire
- you
- Votre
- zéphyrnet
- zones