Il s'agit d'un article invité d'AK Roy de Qualcomm AI.
Cloud Amazon Elastic Compute (Amazon EC2) Les instances DL2q, optimisées par les accélérateurs Qualcomm AI 100 Standard, peuvent être utilisées pour déployer de manière rentable des charges de travail de deep learning (DL) dans le cloud. Ils peuvent également être utilisés pour développer et valider les performances et la précision des charges de travail DL qui seront déployées sur les appareils Qualcomm. Les instances DL2q sont les premières à intégrer la technologie d'intelligence artificielle (IA) de Qualcomm dans le cloud.
Avec huit accélérateurs Qualcomm AI 100 Standard et 128 Go de mémoire d'accélérateur totale, les clients peuvent également utiliser les instances DL2q pour exécuter des applications d'IA générative populaires, telles que la génération de contenu, la synthèse de texte et les assistants virtuels, ainsi que des applications d'IA classiques pour le traitement du langage naturel. et la vision par ordinateur. De plus, les accélérateurs Qualcomm AI 100 disposent de la même technologie d'IA que celle utilisée sur les smartphones, la conduite autonome, les ordinateurs personnels et les casques de réalité étendue, de sorte que les instances DL2q peuvent être utilisées pour développer et valider ces charges de travail d'IA avant le déploiement.
Points forts de la nouvelle instance DL2q
Chaque instance DL2q intègre huit accélérateurs Qualcomm Cloud AI100, avec des performances cumulées de plus de 2.8 PetaOps de performances d'inférence Int8 et de 1.4 PetaFlops de performances d'inférence FP16. L'instance dispose d'un total de 112 cœurs d'IA, d'une capacité de mémoire d'accélérateur de 128 Go et d'une bande passante mémoire de 1.1 To par seconde.
Chaque instance DL2q dispose de 96 vCPU, d'une capacité de mémoire système de 768 Go et prend en charge une bande passante réseau de 100 Gbit/s ainsi que Magasin de blocs Amazon Elastic (Amazon EBS) stockage de 19 Gbit/s.
| Nom de l'instance | vCPU | Accélérateurs Cloud AI100 | Mémoire d'accélérateur | Mémoire d'accélérateur BW (agrégée) | Mémoire d'instance | Mise en réseau d'instances | Bande passante de stockage (Amazon EBS) |
| DL2q.24xlarge | 96 | 8 | 128 GB | 1.088 TB / s | 768 GB | 100 Gbps | 19 Gbps |
Innovation de l'accélérateur Qualcomm Cloud AI100
Le système sur puce (SoC) accélérateur Cloud AI100 est une architecture multicœur spécialement conçue et évolutive, prenant en charge un large éventail de cas d'utilisation d'apprentissage en profondeur, du centre de données à la périphérie. Le SoC utilise des cœurs de calcul scalaires, vectoriels et tensoriels avec une capacité SRAM sur puce de pointe de 126 Mo. Les cœurs sont interconnectés avec un maillage de réseau sur puce (NoC) à large bande passante et à faible latence.
L'accélérateur AI100 prend en charge une gamme large et complète de modèles et de cas d'utilisation. Le tableau ci-dessous met en évidence la gamme de modèles pris en charge.
| Catégorie de modèle | Plusieurs modèles | Exemples |
| PNL | 157 | BERT, BART, FasterTransformer, T5, code Z MOE |
| IA générative – PNL | 40 | LLaMA, CodeGen, GPT, OPT, BLOOM, Jais, Luminous, StarCoder, XGen |
| IA générative – Image | 3 | Diffusion stable v1.5 et v2.1, OpenAI CLIP |
| CV – Classement des images | 45 | ViT, ResNet, ResNext, MobileNet, EfficientNet |
| CV – Détection d’objets | 23 | YOLO v2, v3, v4, v5 et v7, SSD-ResNet, RetinaNet |
| CV – Autre | 15 | LPRNet, super-résolution/SRGAN, ByteTrack |
| Réseaux automobiles* | 53 | Perception et LIDAR, détection de piétons, de voies et de feux tricolores |
| Le total | > 300 |
* La plupart des réseaux automobiles sont des réseaux composites constitués d'une fusion de réseaux individuels.
La grande SRAM intégrée à l'accélérateur DL2q permet une mise en œuvre efficace de techniques de performances avancées telles que la précision du micro-exposant MX6 pour le stockage des poids et la précision du micro-exposant MX9 pour la communication d'accélérateur à accélérateur. La technologie des micro-exposants est décrite dans l'annonce suivante de l'industrie de l'Open Compute Project (OCP) : AMD, Arm, Intel, Meta, Microsoft, NVIDIA et Qualcomm standardisent les formats de données de précision étroite de nouvelle génération pour l'IA » Open Compute Project.
L'utilisateur de l'instance peut utiliser la stratégie suivante pour maximiser les performances par coût :
- Stockez les poids en utilisant la précision du micro-exposant MX6 dans la mémoire DDR sur accélérateur. L'utilisation de la précision MX6 maximise l'utilisation de la capacité de mémoire disponible et de la bande passante mémoire pour offrir un débit et une latence de premier ordre.
- Calculez dans FP16 pour fournir la précision de cas d'utilisation requise, tout en utilisant la SRAM supérieure sur puce et les TOP de rechange sur la carte, pour implémenter des noyaux MX6 à faible latence hautes performances vers FP16.
- Utilisez une stratégie de traitement par lots optimisée et une taille de lot plus élevée en utilisant la grande SRAM sur puce disponible pour maximiser la réutilisation des poids, tout en conservant les activations sur puce au maximum possible.
Pile IA et chaîne d'outils DL2q
L'instance DL2q est accompagnée de Qualcomm AI Stack qui offre une expérience de développeur cohérente sur Qualcomm AI dans le cloud et d'autres produits Qualcomm. La même pile d'IA Qualcomm et la même technologie d'IA de base s'exécutent sur les instances DL2q et les appareils Qualcomm Edge, offrant aux clients une expérience de développement cohérente, avec une API unifiée dans leurs environnements de développement cloud, automobile, ordinateur personnel, réalité étendue et smartphone.
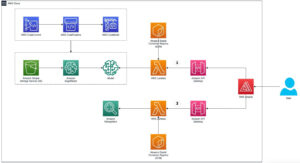
La chaîne d'outils permet à l'utilisateur de l'instance d'intégrer rapidement un modèle préalablement formé, de compiler et d'optimiser le modèle pour les fonctionnalités de l'instance, puis de déployer les modèles compilés pour les cas d'utilisation d'inférence de production en trois étapes illustrées dans la figure suivante.

Pour en savoir plus sur le réglage des performances d'un modèle, consultez le Paramètres de performances clés de Cloud AI 100 Documentation.
Premiers pas avec les instances DL2q
Dans cet exemple, vous compilez et déployez un Modèle BERT De Étreindre le visage sur une instance EC2 DL2q à l'aide d'une AMI DL2q disponible prédéfinie, en quatre étapes.
Vous pouvez utiliser soit un pré-construit Qualcomm DLAMI sur l'instance ou commencez avec une AMI Amazon Linux2 et créez votre propre AMI DL2q avec le SDK Cloud AI 100 Platform and Apps disponible dans ce Service de stockage simple Amazon (Amazon S3) seau: s3://ec2-linux-qualcomm-ai100-sdks/latest/.
Les étapes qui suivent utilisent l'AMI DL2q prédéfinie, Qualcomm Base AL2 DLAMI.
Utilisez SSH pour accéder à votre instance DL2q avec l'AMI Qualcomm Base AL2 DLAMI et suivez les étapes 1 à 4.
Étape 1. Configurez l'environnement et installez les packages requis
- Installez Python 3.8.
- Configurez l'environnement virtuel Python 3.8.
- Activez l'environnement virtuel Python 3.8.
- Installez les packages requis, indiqués dans le document exigences.txt disponible sur le site Github public de Qualcomm.
- Importez les bibliothèques nécessaires.
Étape 2. Importez le modèle
- Importez et tokenisez le modèle.
- Définir un exemple d'entrée et extraire le
inputIdsainsi queattentionMask. - Convertissez le modèle en ONNX, qui peut ensuite être transmis au compilateur.
- Vous exécuterez le modèle avec la précision FP16. Vous devez donc vérifier si le modèle contient des constantes au-delà de la plage FP16. Transmettez le modèle au
fix_onnx_fp16fonction pour générer le nouveau fichier ONNX avec les correctifs requis.
Étape 3. Compiler le modèle
La qaic-exec L'outil de compilation de l'interface de ligne de commande (CLI) est utilisé pour compiler le modèle. L'entrée de ce compilateur est le fichier ONNX généré à l'étape 2. Le compilateur produit un fichier binaire (appelé QPC, Pour Conteneur de programme Qualcomm) dans le chemin défini par -aic-binary-dir argument.
Dans la commande de compilation ci-dessous, vous utilisez quatre cœurs de calcul IA et une taille de lot d'un pour compiler le modèle.
Le QPC est généré dans le bert-base-cased/generatedModels/bert-base-cased_fix_outofrange_fp16_qpc dossier.
Étape 4. Exécutez le modèle
Configurez une session pour exécuter l'inférence sur un accélérateur Cloud AI100 Qualcomm dans l'instance DL2q.
La bibliothèque Qualcomm qaic Python est un ensemble d'API qui prend en charge l'exécution d'inférences sur l'accélérateur Cloud AI100.
- Utilisez l'appel d'API Session pour créer une instance de session. L'appel API Session est le point d'entrée pour utiliser la bibliothèque qaic Python.
- Restructurez les données du tampon de sortie avec
output_shapeainsi queoutput_type. - Décodez le résultat produit.
Voici les résultats de la phrase d'entrée « Le chien [MASQUE] sur le tapis ».
C'est ça. En quelques étapes seulement, vous avez compilé et exécuté un modèle PyTorch sur une instance Amazon EC2 DL2q. Pour en savoir plus sur l'intégration et la compilation de modèles sur l'instance DL2q, consultez le Documentation du didacticiel Cloud AI100.
Pour en savoir plus sur les architectures de modèles DL adaptées aux instances AWS DL2q et sur la matrice de prise en charge actuelle des modèles, consultez le Documentation Qualcomm Cloud AI100.
Disponible dès maintenant
Vous pouvez lancer des instances DL2q dès aujourd'hui dans les régions AWS USA Ouest (Oregon) et Europe (Francfort) en tant que À la demande, Reservéet une Instances ponctuelles, ou dans le cadre d'un Plan d'épargne. Comme d'habitude avec Amazon EC2, vous ne payez que ce que vous utilisez. Pour plus d'informations, voir Tarification Amazon EC2.
Les instances DL2q peuvent être déployées à l'aide AMI d'apprentissage en profondeur AWS (DLAMI), et les images de conteneurs sont disponibles via des services gérés tels que Amazon Sage Maker, Service Amazon Elastic Kubernetes (Amazon EKS), Amazon Elastic Container Service (Amazon ECS)et une AWS ParallelCluster.
Pour en savoir plus, visitez le Instance Amazon EC2 DL2q page et envoyez vos commentaires à AWS re:Post pour EC2 ou via vos contacts AWS Support habituels.
À propos des auteurs
 AK Roy est directeur de la gestion des produits chez Qualcomm, pour les produits et solutions d'IA Cloud et Datacenter. Il a plus de 20 ans d'expérience dans la stratégie et le développement de produits, avec pour objectif actuel les meilleures solutions de bout en bout en termes de performances et de performances/$ pour l'inférence d'IA dans le Cloud, pour un large éventail de cas d'utilisation, y compris GenAI, LLM, Auto et Hybrid AI.
AK Roy est directeur de la gestion des produits chez Qualcomm, pour les produits et solutions d'IA Cloud et Datacenter. Il a plus de 20 ans d'expérience dans la stratégie et le développement de produits, avec pour objectif actuel les meilleures solutions de bout en bout en termes de performances et de performances/$ pour l'inférence d'IA dans le Cloud, pour un large éventail de cas d'utilisation, y compris GenAI, LLM, Auto et Hybrid AI.
 Jianying Lang est architecte de solutions principal chez AWS Worldwide Specialist Organization (WWSO). Elle possède plus de 15 ans d’expérience professionnelle dans le domaine du HPC et de l’IA. Chez AWS, elle s'efforce d'aider les clients à déployer, optimiser et faire évoluer leurs charges de travail IA/ML sur des instances de calcul accélérées. Elle est passionnée par la combinaison des techniques dans les domaines du HPC et de l'IA. Jianying est titulaire d'un doctorat en physique computationnelle de l'Université du Colorado à Boulder.
Jianying Lang est architecte de solutions principal chez AWS Worldwide Specialist Organization (WWSO). Elle possède plus de 15 ans d’expérience professionnelle dans le domaine du HPC et de l’IA. Chez AWS, elle s'efforce d'aider les clients à déployer, optimiser et faire évoluer leurs charges de travail IA/ML sur des instances de calcul accélérées. Elle est passionnée par la combinaison des techniques dans les domaines du HPC et de l'IA. Jianying est titulaire d'un doctorat en physique computationnelle de l'Université du Colorado à Boulder.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/amazon-ec2-dl2q-instance-for-cost-efficient-high-performance-ai-inference-is-now-generally-available/
- :possède
- :est
- $UP
- 1
- 1 TB
- 10
- 100
- 11
- 12
- 13
- 15 ans
- 15%
- 17
- 19
- 20
- 20 ans
- 22
- 23
- 46
- 7
- 75
- 8
- 84
- a
- A Propos
- au dessus de
- accéléré
- accélérateur
- accélérateurs
- accès
- accompagné
- précision
- à travers
- activations
- En outre
- Avancée
- agrégat
- AI
- AI / ML
- Tous
- aussi
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- ainsi que
- NOUVEAUTÉ!
- tous
- api
- Apis
- applications
- applications
- architecture
- SONT
- argument
- BRAS
- artificiel
- AS
- assistants
- At
- auto
- l'automobile
- autonome
- disponibles
- AWS
- HACHES
- Bande passante
- base
- mise en lot
- BE
- before
- ci-dessous
- Au-delà
- BIN
- Block
- Bloom
- apporter
- vaste
- tampon
- construire
- by
- Appelez-nous
- appelé
- CAN
- capacités
- Compétences
- carte
- maisons
- vérifier
- classiques
- le cloud
- Colorado
- combinant
- Communication
- compilé
- complet
- calcul
- calcul
- ordinateur
- Vision par ordinateur
- ordinateurs
- informatique
- cohérent
- Qui consiste
- Contacts
- Contenant
- contient
- contenu
- engendrent
- Courant
- Clients
- données
- Datacenter
- profond
- l'apprentissage en profondeur
- défini
- Degré
- livrer
- offre
- déployer
- déployé
- déploiement
- décrit
- développer
- Développeur
- Développement
- dispositif
- Compatibles
- La diffusion
- Directeur
- Documentation
- Chien
- conduite
- Dynamic
- ebs
- Edge
- efficace
- non plus
- emploie
- permet
- end-to-end
- entrée
- Environment
- environnements
- Ether (ETH)
- Europe
- exemple
- d'experience
- réalité étendue
- extrait
- non
- Fonctionnalité
- Réactions
- few
- champ
- Des champs
- Figure
- Déposez votre dernière attestation
- Prénom
- s'adapter
- correctifs
- Focus
- se concentre
- suivre
- Abonnement
- Pour
- trouvé
- quatre
- Francfort
- De
- fonction
- la fusion
- généralement
- générer
- généré
- génération
- génératif
- IA générative
- GitHub
- donné
- Bien
- GUEST
- Invité Message
- he
- casques
- aider
- ici
- haute performance
- augmentation
- Faits saillants
- détient
- hpc
- HTML
- HTTPS
- Hybride
- i
- IDX
- if
- image
- satellite
- Mettre en oeuvre
- la mise en oeuvre
- importer
- in
- Y compris
- incorpore
- individuel
- industrie
- leader de l'industrie
- d'information
- contribution
- installer
- instance
- cas
- Intel
- Intelligent
- interconnecté
- Interfaces
- IT
- jpg
- juste
- ACTIVITES
- Kubernetes
- Voie
- langue
- gros
- Latence
- lancer
- APPRENTISSAGE
- apprentissage
- bibliothèques
- Bibliothèque
- traiter
- lumière
- Gamme
- charges
- gérés
- gestion
- masque
- Matrice
- max
- Maximisez
- optimise
- maximales
- Mémoire
- engrener
- Meta
- Microsoft
- m.
- modèle
- numériques jumeaux (digital twin models)
- modifié
- PLUS
- (en fait, presque toutes)
- prénom
- Nature
- Langage naturel
- Traitement du langage naturel
- nécessaire
- Besoin
- réseau et
- de mise en réseau
- réseaux
- Nouveauté
- La prochaine génération
- maintenant
- numpy
- Nvidia
- objet
- of
- on
- Débuter
- Onboarding
- ONE
- uniquement
- ouvert
- OpenAI
- Optimiser
- optimisé
- or
- Oregon
- organisation
- OS
- Autre
- ande
- sortie
- sorties
- plus de
- propre
- Forfaits
- page
- partie
- pass
- passé
- passionné
- chemin
- Payer
- /
- performant
- personnel
- Ordinateur personnel
- phd
- Physique
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- Populaire
- possible
- Post
- alimenté
- La précision
- précédemment
- Directeur
- traitement
- Produit
- produit
- Produit
- gestion des produits
- Vidéo
- Produits
- Programme
- Projet
- fournit
- aportando
- public
- Python
- pytorch
- Qualcomm
- vite.
- gamme
- RE
- en cours
- Réalité
- régions
- conditions
- Exigences
- retenue
- retourner
- réutiliser
- roy
- Courir
- pour le running
- fonctionne
- même
- Épargnez
- économie
- évolutive
- Escaliers intérieurs
- Sdk
- Deuxièmement
- sur le lien
- envoyer
- phrase
- Séquence
- service
- Services
- Session
- set
- elle
- montré
- étapes
- simplifier
- site
- Taille
- smartphone
- smartphones
- So
- Solutions
- enjambant
- spécialiste
- empiler
- Standard
- Commencer
- j'ai commencé
- étapes
- Étapes
- storage
- Boutique
- de Marketing
- Par la suite
- tel
- haut
- Support
- Appuyer
- Les soutiens
- combustion propre
- table
- techniques
- Technologie
- texte
- qui
- La
- leur
- puis
- Ces
- l'ont
- this
- trois
- Avec
- débit
- thru
- à
- aujourd'hui
- tokenize
- outil
- Hauts
- torche
- Total
- circulation
- qualifié
- transformateurs
- oui
- tutoriel
- unifiée
- université
- us
- utilisé
- cas d'utilisation
- cas d'utilisation
- d'utiliser
- Utilisateur
- en utilisant
- habituel
- v1
- VAL
- VALIDER
- Plus-value
- Salle de conférence virtuelle
- vision
- Visiter
- we
- web
- services Web
- WELL
- Ouest
- Quoi
- qui
- tout en
- large
- Large gamme
- sera
- comprenant
- Word
- de travail
- partout dans le monde
- années
- you
- Votre
- zéphyrnet