Amazone Athéna est un service de requête interactif qui facilite l'analyse des données dans Service de stockage simple Amazon (Amazon S3) et des sources de données résidant dans AWS, sur site ou dans d'autres systèmes cloud utilisant SQL ou Python. Athena est construit sur des moteurs open source Trino et Presto et des frameworks Apache Spark, sans effort de provisionnement ou de configuration requis. Athena est sans serveur, il n'y a donc pas d'infrastructure à gérer et vous ne payez que pour les requêtes que vous exécutez.
Iceberg Apache est un format de tableau ouvert pour les très grands ensembles de données analytiques. Il gère de grandes collections de fichiers sous forme de tables et prend en charge les opérations de lac de données analytiques modernes telles que les requêtes d'insertion, de mise à jour, de suppression et de voyage dans le temps au niveau de l'enregistrement. Athena prend en charge les requêtes de lecture, de voyage dans le temps, d'écriture et DDL pour les tables Apache Iceberg qui utilisent le format Apache Parquet pour les données et le Catalogue de données AWS Glue pour leur metastore.
Ingénierie des fonctionnalités est un processus d'identification et de transformation des données brutes (images, fichiers texte, vidéos, etc.), de remplissage des données manquantes et d'ajout d'un ou plusieurs éléments de données significatifs pour fournir un contexte afin qu'un modèle d'apprentissage automatique (ML) puisse en tirer des enseignements. L'étiquetage des données est requis pour divers cas d'utilisation, notamment la prévision, la vision par ordinateur, le traitement du langage naturel et la reconnaissance vocale.
Combiné aux capacités d'Athena, Apache Iceberg offre un flux de travail simplifié aux data scientists pour créer de nouvelles fonctionnalités de données sans avoir besoin de copier ou de recréer l'intégralité de l'ensemble de données. Vous pouvez créer des fonctionnalités à l'aide de SQL standard sur Athena sans utiliser aucun autre service pour l'ingénierie des fonctionnalités. Les scientifiques des données peuvent réduire le temps passé à préparer et à copier des ensembles de données et se concentrer plutôt sur l'ingénierie des caractéristiques des données, l'expérimentation et l'analyse des données à grande échelle.
Dans cet article, nous passons en revue les avantages de l'utilisation d'Athena avec le format de table ouverte Apache Iceberg et comment il simplifie les tâches courantes d'ingénierie des fonctionnalités pour les scientifiques des données. Nous montrons comment Athena peut convertir une table existante au format Apache Iceberg, puis ajouter des colonnes, supprimer des colonnes et modifier les données de la table sans recréer ni copier l'ensemble de données, et utiliser ces fonctionnalités pour créer de nouvelles fonctionnalités sur les tables Apache Iceberg.
Vue d'ensemble de la solution
Les scientifiques des données sont généralement habitués à travailler avec de grands ensembles de données. Les ensembles de données sont généralement stockés au format JSON, CSV, ORC ou Parquet Apache format, ou des formats similaires optimisés en lecture pour des performances de lecture rapides. Les scientifiques des données créent souvent de nouvelles fonctionnalités de données et remplissent ces fonctionnalités de données avec des données agrégées et auxiliaires. Historiquement, cette tâche était accomplie en créant une vue au-dessus de la table avec les données sous-jacentes au format Apache Parquet, où ces colonnes et données étaient ajoutées au moment de l'exécution ou en créant une nouvelle table avec des colonnes supplémentaires. Bien que ce flux de travail soit bien adapté à de nombreux cas d'utilisation, il est inefficace pour les grands ensembles de données, car les données devraient être générées au moment de l'exécution ou les ensembles de données devraient être copiés et transformés.
Athéna a présenté Transaction ACID (Atomicité, Cohérence, Isolement, Durabilité) capacités qui ajoutent des opérations INSERT, UPDATE, DELETE, MERGE et time travel basées sur Tableaux Apache Iceberg. Ces fonctionnalités permettent aux scientifiques des données de créer de nouvelles fonctionnalités de données et de supprimer des fonctionnalités de données existantes sur des ensembles de données existants sans se soucier de copier ou de transformer l'ensemble de données ou de l'abstraire avec une vue. Les scientifiques des données peuvent se concentrer sur le travail d'ingénierie des fonctionnalités et éviter de copier et de transformer les ensembles de données.
L'opération Athena Iceberg UPDATE écrit les fichiers de suppression de position Apache Iceberg et les lignes nouvellement mises à jour en tant que fichiers de données dans la même transaction. Vous pouvez effectuer des corrections d'enregistrement via une seule instruction UPDATE.
Avec la sortie de la version 3 du moteur Athena, les fonctionnalités des tables Apache Iceberg sont améliorées avec la prise en charge d'opérations telles que CRÉER UNE TABLE COMME SELECT (CTAS) et les commandes MERGE qui rationalisent la gestion du cycle de vie de vos données Iceberg. CTAS permet de créer rapidement et efficacement des tables à partir d'autres formats tels qu'Apache Paquet, et FUSIONNER EN met à jour, supprime ou insère des lignes conditionnelles dans une table Iceberg. Une seule instruction peut combiner des actions de mise à jour, de suppression et d'insertion.
Pré-requis
Configurez un groupe de travail Athena avec la version 3 du moteur Athena pour utiliser les commandes CTAS et MERGE avec une table Apache Iceberg. Pour mettre à niveau votre moteur Athena existant vers la version 3 dans votre groupe de travail Athena, suivez les instructions de Passez à la version 3 du moteur Athena pour augmenter les performances des requêtes et accéder à davantage de fonctionnalités d'analyse ou se référer à Modification de la version du moteur dans la console Athena.
Ensemble de données
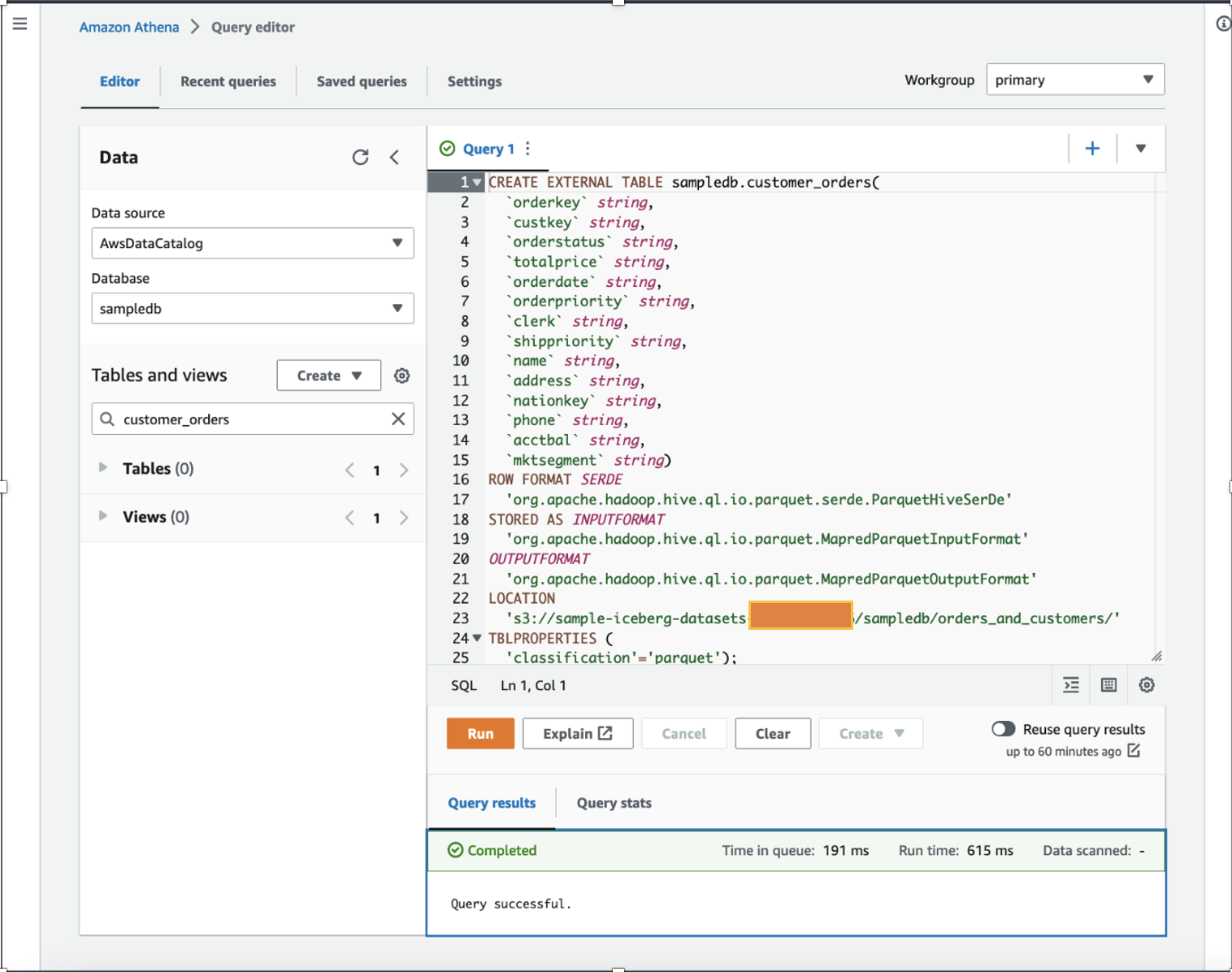
Pour la démonstration, nous utilisons une table Apache Parquet qui contient plusieurs millions d'enregistrements de données de ventes fictives distribuées de manière aléatoire des dernières années stockées dans un compartiment S3. Télécharger l'ensemble de données, décompressez-le sur votre ordinateur local et chargez-le dans votre compartiment S3. Dans cet article, nous avons téléchargé notre ensemble de données sur s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
Le tableau suivant montre la disposition du tableau customer_orders.
| Nom de colonne | Type de données | Description |
| clé de commande | un magnifique | Numéro de commande pour la commande |
| clé de garde | un magnifique | Numéro d'identification du client |
| état de la commande | un magnifique | Statut de la commande |
| prix total | un magnifique | Prix total de la commande |
| date de commande | un magnifique | Date de la commande |
| priorité de commande | un magnifique | Priorité de la commande |
| employé | un magnifique | Nom du commis qui a traité la commande |
| priorité de livraison | un magnifique | Priorité sur l'expédition |
| prénom | un magnifique | Nom du client |
| propos | un magnifique | Adresse du client |
| clé de la nation | un magnifique | Clé de pays client |
| Téléphone | un magnifique | Numéro de téléphone du client |
| crédit | un magnifique | Solde du compte client |
| segment de marché | un magnifique | Segment de marché client |
Réaliser l'ingénierie des fonctionnalités
En tant que data scientist, nous voulons effectuer ingénierie des fonctionnalités sur les données des commandes client en ajoutant les achats totaux calculés sur un an et les achats moyens sur un an pour chaque client dans l'ensemble de données existant. À des fins de démonstration, nous avons créé le customer_orders tableau dans le sampledb base de données à l'aide d'Athena, comme indiqué dans la commande DDL suivante. (Vous pouvez utiliser n'importe lequel de vos ensembles de données existants et suivre les étapes mentionnées dans cet article.) customer_orders l'ensemble de données a été généré et stocké à l'emplacement du compartiment S3 s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ au format Parquet. Cette table n'est pas une table Apache Iceberg.
![]()
Validez les données de la table en exécutant une requête :
![]()
Nous souhaitons ajouter de nouvelles fonctionnalités à ce tableau pour mieux comprendre les ventes des clients, ce qui peut entraîner une formation plus rapide des modèles et des informations plus précieuses. Pour ajouter de nouvelles entités au jeu de données, convertissez le customer_orders Table Athéna à table Apache Iceberg sur Athéna. Émettre un CTAS instruction de requête pour créer une nouvelle table au format Apache Iceberg à partir de customer_orders tableau. Ce faisant, une nouvelle fonctionnalité est ajoutée pour obtenir le montant total des achats au cours de l'année écoulée (année maximale de l'ensemble de données) par chaque client.
Dans la requête CTAS suivante, une nouvelle colonne nommée one_year_sales_aggregate avec la valeur par défaut comme 0.0 du type de données double est ajouté et table_type est fixé à ICEBERG:
![]()
Émettez la requête suivante pour vérifier les données de la table Apache Iceberg avec la nouvelle colonne one_year_sales_aggregate valeurs comme 0.0:
![]()
Nous voulons remplir les valeurs de la nouvelle fonctionnalité one_year_sales_aggregate dans l'ensemble de données pour obtenir le montant total des achats pour chaque client en fonction de ses achats au cours de l'année écoulée (année maximale de l'ensemble de données). Envoyez une instruction de requête MERGE à la table Apache Iceberg à l'aide d'Athena pour renseigner les valeurs de one_year_sales_aggregate fonction:
![]()
Émettez la requête suivante pour valider la valeur mise à jour des dépenses totales de chaque client au cours de l'année écoulée :
![]()
Nous décidons d'ajouter une autre fonctionnalité à une table Apache Iceberg existante pour calculer et stocker le montant moyen des achats de l'année écoulée par chaque client. Émettez une instruction de requête ALTER pour ajouter une nouvelle colonne à une table existante pour la fonctionnalité one_year_sales_average:
![]()
Avant de remplir les valeurs de cette nouvelle fonctionnalité, vous pouvez définir la valeur par défaut de la fonctionnalité one_year_sales_average à 0.0. En utilisant la même table Apache Iceberg sur Athena, émettez une instruction de requête UPDATE pour remplir la valeur de la nouvelle fonctionnalité comme 0.0:
![]()
Émettez la requête suivante pour vérifier que la valeur mise à jour des dépenses moyennes de chaque client au cours de l'année écoulée est définie sur 0.0:
![]()
Maintenant, nous voulons remplir les valeurs de la nouvelle fonctionnalité one_year_sales_average dans l'ensemble de données pour obtenir le montant d'achat moyen pour chaque client en fonction de ses achats au cours de l'année écoulée (année maximale de l'ensemble de données). Envoyez une instruction de requête MERGE à la table Apache Iceberg existante sur Athena à l'aide du moteur Athena pour remplir les valeurs de la fonctionnalité one_year_sales_average:
![]()
Exécutez la requête suivante pour vérifier les valeurs mises à jour des dépenses moyennes de chaque client :
![]()
Une fois que des fonctionnalités de données supplémentaires ont été ajoutées à l'ensemble de données, les scientifiques des données procèdent généralement à la formation de modèles ML et effectuent des inférences à l'aide d'Amazon Sagemaker ou d'un ensemble d'outils équivalent.
Conclusion
Dans cet article, nous avons montré comment effectuer l'ingénierie des fonctionnalités à l'aide d'Athena avec Apache Iceberg. Nous avons également démontré l'utilisation de la requête CTAS pour créer une table Apache Iceberg sur Athena à partir d'un ensemble de données existant au format Apache Parquet, l'ajout de nouvelles fonctionnalités dans une table Apache Iceberg existante sur Athena à l'aide de la requête ALTER et l'utilisation des instructions de requête UPDATE et MERGE pour mettre à jour le les valeurs des caractéristiques des colonnes existantes.
Nous vous encourageons à utiliser les requêtes CTAS pour créer des tables rapidement et efficacement, et à utiliser l'instruction de requête MERGE pour synchroniser les tables en une seule étape afin de simplifier la préparation des données et les tâches de mise à jour lors de la transformation des fonctionnalités à l'aide d'Athena avec Apache Iceberg. Si vous avez des commentaires ou des commentaires, veuillez les laisser dans la section des commentaires.
À propos des auteurs
![]() Vivek Gautam est un architecte de données spécialisé dans les lacs de données chez AWS Professional Services. Il travaille avec des entreprises clientes qui créent des produits de données, des plateformes d'analyse et des solutions sur AWS. Lorsqu'il ne construit pas et ne conçoit pas de plates-formes de données modernes, Vivek est un passionné de gastronomie qui aime également explorer de nouvelles destinations de voyage et faire des randonnées.
Vivek Gautam est un architecte de données spécialisé dans les lacs de données chez AWS Professional Services. Il travaille avec des entreprises clientes qui créent des produits de données, des plateformes d'analyse et des solutions sur AWS. Lorsqu'il ne construit pas et ne conçoit pas de plates-formes de données modernes, Vivek est un passionné de gastronomie qui aime également explorer de nouvelles destinations de voyage et faire des randonnées.
![]() Mikhaïl Vaynshteyn est un architecte de solutions chez Amazon Web Services. Mikhail travaille avec des clients du secteur de la santé et des sciences de la vie pour créer des solutions qui contribuent à améliorer les résultats des patients. Mikhail est spécialisé dans les services d'analyse de données.
Mikhaïl Vaynshteyn est un architecte de solutions chez Amazon Web Services. Mikhail travaille avec des clients du secteur de la santé et des sciences de la vie pour créer des solutions qui contribuent à améliorer les résultats des patients. Mikhail est spécialisé dans les services d'analyse de données.
![]() Naresh Gautam est un leader de l'analyse de données et de l'IA/ML chez AWS avec 20 ans d'expérience, qui aime aider les clients à concevoir des solutions d'analyse de données et d'IA/ML hautement disponibles, performantes et rentables pour permettre aux clients de prendre des décisions basées sur les données . Pendant son temps libre, il aime méditer et cuisiner.
Naresh Gautam est un leader de l'analyse de données et de l'IA/ML chez AWS avec 20 ans d'expérience, qui aime aider les clients à concevoir des solutions d'analyse de données et d'IA/ML hautement disponibles, performantes et rentables pour permettre aux clients de prendre des décisions basées sur les données . Pendant son temps libre, il aime méditer et cuisiner.
![]() Harsha Tadiparthi est un architecte de solutions principal spécialisé, Analytics chez AWS. Il aime résoudre les problèmes complexes des clients dans les bases de données et les analyses et obtenir des résultats positifs. En dehors du travail, il aime passer du temps avec sa famille, regarder des films et voyager autant que possible.
Harsha Tadiparthi est un architecte de solutions principal spécialisé, Analytics chez AWS. Il aime résoudre les problèmes complexes des clients dans les bases de données et les analyses et obtenir des résultats positifs. En dehors du travail, il aime passer du temps avec sa famille, regarder des films et voyager autant que possible.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Financement EVM. Interface unifiée pour la finance décentralisée. Accéder ici.
- Groupe de médias quantiques. IR/PR amplifié. Accéder ici.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- :possède
- :est
- :ne pas
- :où
- $UP
- 10
- 100
- 12
- 17
- 20
- 20 ans
- 23
- 27
- 7
- a
- A Propos
- accélérer
- accès
- accompli
- Compte
- actes
- ajouter
- ajoutée
- ajoutant
- Supplémentaire
- propos
- AI / ML
- aussi
- Bien que
- Amazon
- Amazone Athéna
- Amazon Sage Maker
- Amazon Web Services
- montant
- an
- Analytique
- Analytique
- analytique
- il analyse
- l'analyse
- ainsi que
- Une autre
- tous
- Apache
- Apache Spark
- SONT
- AS
- At
- disponibles
- moyen
- éviter
- AWS
- Services professionnels AWS
- basé
- BE
- car
- était
- avantages.
- construire
- Développement
- construit
- by
- calculé
- CAN
- capacités
- cas
- classification
- le cloud
- collections
- Colonne
- Colonnes
- combiner
- commentaires
- Commun
- complexe
- calcul
- ordinateur
- Vision par ordinateur
- configuration
- contient
- contexte
- convertir
- cuisine
- copier
- Corrections
- rentable
- engendrent
- créée
- La création
- des clients
- Clients
- données
- Analyse de Donnée
- Lac de données
- science des données
- Data Scientist
- data-driven
- Base de données
- bases de données
- ensembles de données
- Date
- décider
- La prise de décision
- profond
- Réglage par défaut
- livrer
- offre
- démontrer
- démontré
- conception
- destinations
- distribué
- faire
- double
- Goutte
- durabilité
- chacun
- Easy
- efficace
- efficacement
- effort
- non plus
- éléments
- vous accompagner
- permettre
- encourager
- Moteur
- ENGINEERING
- Moteurs
- améliorée
- Entreprise
- clients entreprise
- passionné
- Tout
- Équivalent
- Ether (ETH)
- existant
- d'experience
- explorez
- externe
- non
- famille
- RAPIDE
- plus rapide
- Fonctionnalité
- Fonctionnalités:
- Réactions
- Fichiers
- Focus
- suivre
- Abonnement
- nourriture
- Pour
- le format
- cadres
- Gratuit
- De
- généralement
- généré
- obtenez
- Go
- Réservation de groupe
- Hadoop
- Vous avez
- he
- la médecine
- vous aider
- aider
- haute performance
- très
- Randonnées
- sa
- historiquement
- Ruche
- Comment
- How To
- HTML
- HTTPS
- Identification
- identifier
- if
- satellite
- améliorer
- in
- Y compris
- Améliore
- inefficace
- Infrastructure
- Inserts
- idées.
- plutôt ;
- Des instructions
- Interactif
- développement
- introduit
- seul
- aide
- IT
- jpg
- json
- l'étiquetage
- lac
- langue
- gros
- Nom de famille
- Disposition
- leader
- APPRENTISSAGE
- apprentissage
- Laisser
- VIE
- Life Sciences
- vos produits
- LIMIT
- locales
- emplacement
- aime
- click
- machine learning
- a prendre une
- FAIT DU
- gérer
- gestion
- gère
- de nombreuses
- Marché
- appariés
- max
- significative
- Méditation
- mentionné
- aller
- million
- manquant
- ML
- modèle
- numériques jumeaux (digital twin models)
- Villas Modernes
- modifier
- PLUS
- Films
- prénom
- Nommé
- nation
- Nature
- Langage naturel
- Traitement du langage naturel
- Besoin
- besoin
- Nouveauté
- nouvelle fonctionnalité
- Nouvelles fonctionnalités
- nouvellement
- aucune
- nombre
- of
- souvent
- on
- ONE
- uniquement
- ouvert
- open source
- opération
- Opérations
- or
- passer commande
- Autre
- nos
- les résultats
- au contrôle
- passé
- Payer
- effectuer
- performant
- Téléphone
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- position
- possible
- Post
- en train de préparer
- prix
- Directeur
- d'ouvrabilité
- processus
- traité
- traitement
- Produits
- professionels
- fournir
- achat
- achats
- des fins
- Python
- requêtes
- vite.
- raw
- les données brutes
- Lire
- reconnaissance
- record
- Articles
- réduire
- libérer
- conditions
- résultat
- Avis
- RANGÉE
- Courir
- pour le running
- sagemaker
- vente
- même
- Escaliers intérieurs
- Sciences
- STARFLEET SCIENCES
- Scientifique
- scientifiques
- Section
- Sans serveur
- service
- Services
- set
- plusieurs
- montré
- Spectacles
- similaires
- étapes
- simplifié
- simplifier
- unique
- So
- Solutions
- Résoudre
- Sources
- Spark
- spécialiste
- spécialise
- discours
- Reconnaissance vocale
- passer
- dépensé
- SQL
- Standard
- Déclaration
- déclarations
- étapes
- Étapes
- storage
- Boutique
- stockée
- rationaliser
- Chaîne
- réussi
- tel
- Support
- Les soutiens
- Système
- table
- Tâche
- tâches
- qui
- La
- La fusion
- leur
- Les
- puis
- Là.
- Ces
- this
- fiable
- voyage dans le temps
- à
- top
- Total
- Train
- Formation
- transaction
- transactionnel
- transformé
- transformer
- Voyage
- type
- sous-jacent
- compréhension
- Mises à jour
- a actualisé
- Actualités
- améliorer
- téléchargé
- utilisé
- en utilisant
- d'habitude
- VALIDER
- Précieux
- Plus-value
- Valeurs
- divers
- vérifier
- version
- très
- via
- Vidéos
- Voir
- vision
- souhaitez
- était
- Montres
- we
- web
- services Web
- ont été
- quand
- chaque fois que
- qui
- tout en
- WHO
- comprenant
- sans
- activités principales
- workflow
- Groupe De Travail
- de travail
- vos contrats
- pourra
- écrire
- an
- années
- you
- Votre
- zéphyrnet
- Zip