
تصویر توسط نویسنده
هنگام کار با داده ها و متغیرهای مختلف، تخصیص یک متغیر یا مقدار بزرگتر از دیگری آسان است. ممکن است فرض کنیم که یک متغیر یا نقطه داده خاص تأثیر بیشتری بر خروجی داشته است، اما چقدر مطمئن هستیم که سایر متغیرها تأثیر یکسانی دارند؟
در آمار، نرخ پایه را میتوان بهعنوان احتمالات طبقاتی دید که بر اساس «شواهد ویژه» بدون قید و شرط هستند. می توانید نرخ پایه را به عنوان فرض احتمال قبلی خود ببینید.
نرخ های پایه ابزار مهمی در تحقیق هستند. به عنوان مثال، اگر ما یک شرکت داروسازی هستیم و در حال توسعه و ارسال واکسیناسیون جدید هستیم، میخواهیم موفقیت درمان را بررسی کنیم. اگر 4000 نفر مایل به انجام این واکسیناسیون هستند و نرخ پایه ما 1/25 است.
این بدان معناست که از 160 نفر تنها 4000 نفر با درمان با موفقیت درمان می شوند. در دنیای داروسازی، این میزان موفقیت بسیار پایین است. به این ترتیب می توان از نرخ های پایه برای بهبود تحقیقات و دقت و اطمینان از عملکرد خوب محصول استفاده کرد.
اگر کلمات را تقسیم کنیم، درک بهتری به ما می دهد. مغالطه به معنای باور اشتباه یا استدلال نادرست است. اگر اکنون آن را با تعریف خود از نرخ پایه بالا ترکیب کنیم.
مغالطه نرخ پایه، همچنین به عنوان سوگیری نرخ پایه و نادیده گرفتن نرخ پایه شناخته می شود، احتمال قضاوت در مورد یک موقعیت خاص است، در حالی که تمام داده های مرتبط را در نظر نمی گیرد.
مغالطه نرخ پایه اطلاعاتی در مورد نرخ پایه و همچنین سایر اطلاعات مرتبط دارد. این می تواند به دلایل مختلفی از جمله عدم بررسی و تجزیه و تحلیل کامل داده ها و یا ناآگاهی به نفع بخشی خاص از داده ها باشد.
مغالطه نرخ پایه تمایل به نادیده گرفتن اطلاعات نرخ پایه موجود، فشار دادن و حمایت از اطلاعات جدید را توصیف می کند. این برخلاف قواعد اساسی استدلال مبتنی بر شواهد است.
شما معمولاً در مورد این اتفاق در صنعت مالی خواهید شنید. برای مثال، سرمایهگذاران تاکتیکهای خرید یا اشتراکگذاری خود را بر اساس اطلاعات غیرمنطقی استوار میکنند، که منجر به نوسانات در بازار میشود - علیرغم داشتن نرخ پایه برای دانش خود.
بنابراین اکنون درک بهتری از اشتباه نرخ پایه و نرخ پایه داریم. ارتباط و تأثیر آن در علم داده چیست؟
ما در مورد "احتمالات کلاس ها" و "در نظر گرفتن تمام داده های مرتبط" صحبت کرده ایم. اگر یک دانشمند داده، یا مهندس یادگیری ماشین هستید، یا پای خود را به در میکنید - میدانید که احتمالات و دادههای مرتبط چقدر برای تولید خروجیهای دقیق، فرآیند یادگیری مدل یادگیری ماشین شما و تولید مدلهای با کارایی بالا اهمیت دارد.
برای تجزیه و تحلیل و پیشبینی در مورد دادهها یا مدل یادگیری ماشین شما برای تولید خروجیهای دقیق - باید تک تک دادهها را در نظر بگیرید. از آنجایی که برای اولین بار دادههای خود را اسکن میکنید، ممکن است برخی از بخشها را مرتبط و برخی دیگر را نامربوط در نظر بگیرید. با این حال، این قضاوت شما است و تا زمانی که تجزیه و تحلیل مناسب صورت نگیرد، هنوز واقعی نیست.
همانطور که در بالا ذکر شد، نرخ پایه اولیه به شما کمک می کند تا از دقت اطمینان حاصل کنید و مدل های با کارایی بالا تولید کنید. بنابراین چگونه می توانیم این کار را در Data Science انجام دهیم؟
ماتریس سردرگمی
ماتریس سردرگمی یک اندازهگیری عملکرد است که خلاصهای از نتایج پیشبینی را در یک مسئله طبقهبندی ارائه میکند. ماتریس های سردرگمی همه بر اساس نتیجه هستند: درست، نادرست، مثبت و منفی.
ماتریس سردرگمی نشان دهنده پیش بینی های مدل ما در مرحله آزمایش است. منفی کاذب و مثبت کاذب در ماتریس سردرگمی نمونه هایی از اشتباه نرخ پایه هستند.
- مثبت واقعی (TP) - مدل شما مثبت پیش بینی کرده و مثبت است
- منفی واقعی (TN) - مدل شما منفی را پیش بینی کرده و منفی است
- مثبت کاذب (FP) - مدل شما مثبت و منفی است
- منفی کاذب (FN) - مدل شما منفی را پیشبینی کرده و مثبت است
یک ماتریس سردرگمی می تواند 5 معیار مختلف را محاسبه کند تا به ما کمک کند اعتبار مدل خود را اندازه گیری کنیم:
- طبقه بندی اشتباه = FP + FN / TP + TN + FP + FN
- دقت = TP / TP + FP
- دقت = TP + TN / TP + TN + FP + FN
- ویژگی = TN / TN + FP
- حساسیت به نام Recall = TP / TP + FN
برای درک بهتر یک ماتریس سردرگمی، بهتر است به یک تجسم نگاه کنید:
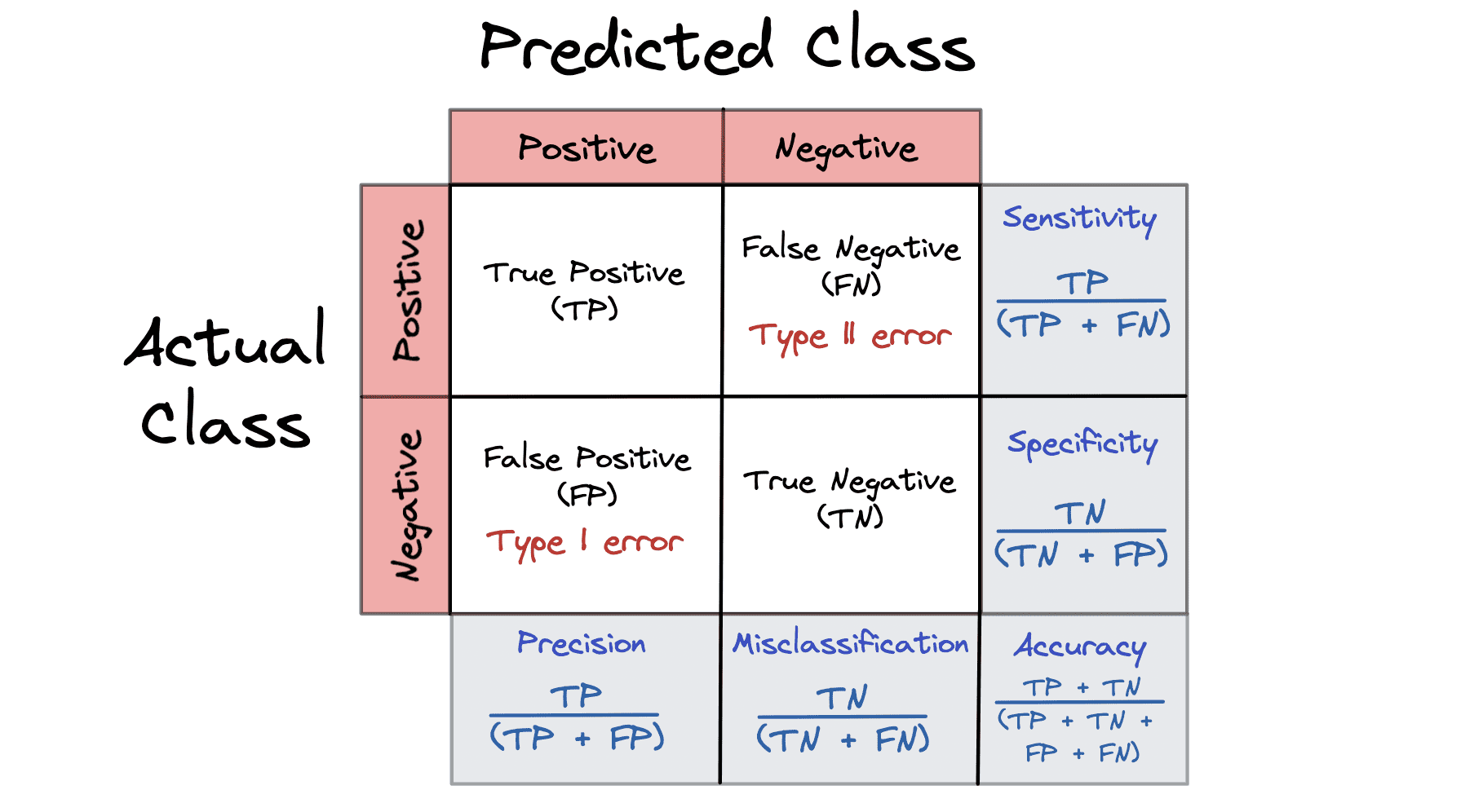
تصویر توسط نویسنده
همانطور که در حال بررسی این مقاله هستید، احتمالاً می توانید به دلایل مختلفی برای اشتباه در نرخ پایه فکر کنید، مانند در نظر نگرفتن همه داده های مربوطه، خطای انسانی یا عدم دقت.
اگرچه همه اینها درست است و به علت اشتباه نرخ پایه می افزاید. همه آنها در وهله اول به بزرگترین مشکل نادیده گرفتن اطلاعات نرخ پایه مربوط می شوند. اطلاعات نرخ پایه اغلب نادیده گرفته می شود زیرا نامربوط در نظر گرفته می شود، با این حال، اطلاعات نرخ پایه می تواند در زمان و هزینه افراد صرفه جویی زیادی کند. استفاده از اطلاعات نرخ پایه موجود به شما این امکان را می دهد که در مورد احتمالات در مورد اینکه آیا یک رویداد خاص رخ می دهد یا خیر، دقیق تر باشید.
استفاده از اطلاعات نرخ پایه به شما کمک می کند تا از اشتباه در نرخ پایه جلوگیری کنید.
آگاهی از اشتباهاتی مانند نظرات، فرآیندهای خودکار، و غیره - به شما این امکان را می دهد که با موضوع اشتباه نرخ پایه مبارزه کنید و خطاهای احتمالی را کاهش دهید. هنگامی که شما در حال اندازه گیری احتمال وقوع یک رویداد خاص هستید، روش های بیزی می توانند به کاهش اشتباه نرخ پایه کمک کنند.
نرخ پایه در علم داده مهم است زیرا شما را با درک پایه ای از نحوه ارزیابی مطالعه یا پروژه خود و تنظیم دقیق مدل خود مجهز می کند - افزایش کلی در دقت و عملکرد را فراهم می کند.
اگر میخواهید ویدیویی درباره اشتباه نرخ پایه در زمینه پزشکی تماشا کنید، این ویدیو را ببینید: پارادوکس تست پزشکی
نیشا آریا دانشمند داده، نویسنده فنی آزاد و مدیر انجمن در KDnuggets است. او به ویژه علاقه مند به ارائه مشاوره شغلی یا آموزش های علم داده و دانش مبتنی بر نظریه در مورد علم داده است. او همچنین مایل است راههای مختلفی را که هوش مصنوعی میتواند به طول عمر انسان کمک کند، کشف کند. یک یادگیرنده مشتاق که به دنبال گسترش دانش فنی و مهارت های نوشتاری خود است و در عین حال به راهنمایی دیگران کمک می کند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- ضرب کردن آینده با آدرین اشلی. دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/2023/04/base-rate-fallacy-impact-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-base-rate-fallacy-and-its-impact-on-data-science
- : دارد
- :است
- :نه
- $UP
- a
- درباره ما
- بالاتر
- دقت
- دقیق
- نصیحت
- در برابر
- معرفی
- اجازه می دهد تا
- همچنین
- an
- تحلیل
- تحلیل
- تجزیه و تحلیل
- و
- هستند
- دور و بر
- مقاله
- مصنوعی
- هوش مصنوعی
- AS
- فرض
- At
- اتوماتیک
- در دسترس
- پایه
- مستقر
- بیزی
- BE
- باور
- سود
- بهتر
- تعصب
- بزرگترین
- بیت
- گسترده تر
- خریداری کردن
- by
- محاسبه
- CAN
- کاریابی
- علت
- علل
- معین
- بررسی
- کلاس ها
- طبقه بندی
- مبارزه با
- ترکیب
- انجمن
- شرکت
- گیجی
- در نظر بگیرید
- توجه
- در نظر گرفته
- داده ها
- علم اطلاعات
- دانشمند داده
- با وجود
- در حال توسعه
- مختلف
- توسط
- در طی
- مهندس
- اطمینان حاصل شود
- خطا
- خطاهای
- و غیره
- واقعه
- هر
- مدرک
- در حال بررسی
- مثال
- مثال ها
- موجود
- اکتشاف
- واقعی
- معیوب
- رشته
- مالی
- نام خانوادگی
- بار اول
- نوسان
- پا
- برای
- آزاد
- اساسی
- گرفتن
- دادن
- داده
- می رود
- رفتن
- بیشتر
- راهنمایی
- اتفاق می افتد
- آیا
- داشتن
- شنیدن
- کمک
- کمک
- کمک می کند
- عملکرد بالا
- چگونه
- چگونه
- اما
- HTTPS
- انسان
- جهل
- تأثیر
- مهم
- بهبود
- in
- افزایش
- صنعت
- اطلاعات
- اول
- اطلاعات
- علاقه مند
- به
- سرمایه گذاران
- موضوع
- IT
- ITS
- kdnuggets
- مشتاق
- دانستن
- دانش
- شناخته شده
- عدم
- منجر می شود
- فراگیر
- یادگیری
- زندگی
- پسندیدن
- لینک
- طول عمر
- نگاه کنيد
- خیلی
- کم
- دستگاه
- فراگیری ماشین
- ساخت
- ساخت
- مدیر
- بازار
- ماتریس
- ممکن است..
- به معنی
- اندازه
- اندازه گیری
- پزشکی
- ذکر شده
- روش
- متریک
- قدرت
- مدل
- مدل
- پول
- بیش
- نیاز
- منفی
- جدید
- اکنون
- of
- on
- ONE
- فقط
- دیدگاه ها
- or
- دیگر
- دیگران
- ما
- نتیجه
- تولید
- به طور کلی
- بخش
- ویژه
- بخش
- مردم
- انجام دادن
- کارایی
- دارویی
- فاز
- محل
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- مثبت
- پتانسیل
- دقیق
- دقت
- پیش بینی
- پیش گویی
- پیش بینی
- قبلا
- احتمال
- شاید
- مشکل
- روند
- فرآیندهای
- تولید کردن
- محصول
- پروژه
- مناسب
- به درستی
- فراهم می کند
- ارائه
- فشار
- نرخ
- نرخ
- دلایل
- كاهش دادن
- ربط
- مربوط
- نشان دهنده
- تحقیق
- نتایج
- قوانین
- s
- ذخیره
- پویش
- علم
- دانشمند
- به دنبال
- اشتراک
- وضعیت
- مهارت ها
- So
- برخی از
- کسی
- خاص
- انشعاب
- ارقام
- مهاجرت تحصیلی
- موفقیت
- موفقیت
- چنین
- خلاصه
- تاکتیک
- گرفتن
- مصرف
- فن آوری
- فنی
- آزمون
- تست
- نسبت به
- که
- La
- شان
- اینها
- این
- به طور کامل
- از طریق
- زمان
- به
- ابزار
- رفتار
- درست
- آموزش
- به طور معمول
- بدون قید و شرط
- فهمیدن
- درک
- us
- استفاده
- ارزش
- تنوع
- مختلف
- تصویری
- تماشا کردن
- راه
- we
- خوب
- چی
- چه شده است
- چه
- که
- در حالیکه
- WHO
- اراده
- مایل
- خواسته
- با
- کلمات
- کارگر
- جهان
- خواهد بود
- نویسنده
- نوشته
- شما
- شما
- زفیرنت








