AWS Glue Studio یک رابط گرافیکی است که ایجاد، اجرا، و نظارت بر استخراج، تبدیل و بارگذاری (ETL) کارها را آسان می کند. چسب AWS. این به شما اجازه می دهد تا به صورت بصری جریان های کاری تبدیل داده را با استفاده از گره هایی که مراحل مختلف مدیریت داده را نشان می دهند، بسازید، که بعداً به طور خودکار به کد برای اجرا تبدیل می شوند.
AWS Glue Studio به تازگی منتشر شده 10 تغییر بصری دیگر برای ایجاد مشاغل پیشرفته تر به روش بصری بدون مهارت های کدنویسی. در این پست، موارد استفاده بالقوه را که نشان دهنده نیازهای رایج ETL است، مورد بحث قرار می دهیم.
تبدیلهای جدیدی که در این پست نشان داده میشوند عبارتند از: Concatenate، Split String، Array To Columns، Add Current Stamp، Pivot Rows To Columns، Unpivot Columns to Rows، Lookup، Explode Array or Map Into Columns، ستون مشتق شده و پردازش تعادل خودکار .
بررسی اجمالی راه حل
در این مورد، ما چند فایل JSON با عملیات سهام اختیار داریم. ما میخواهیم قبل از ذخیرهسازی دادهها تغییراتی ایجاد کنیم تا تجزیه و تحلیل آن آسانتر شود، و همچنین میخواهیم یک خلاصه مجموعه داده جداگانه تولید کنیم.
در این مجموعه داده، هر ردیف نشان دهنده معامله قراردادهای اختیار معامله است. گزینهها ابزارهای مالی هستند که حق خرید یا فروش سهام سهام را با قیمت ثابت (به نام قیمت اعتصاب) قبل از تاریخ انقضای تعریف شده.
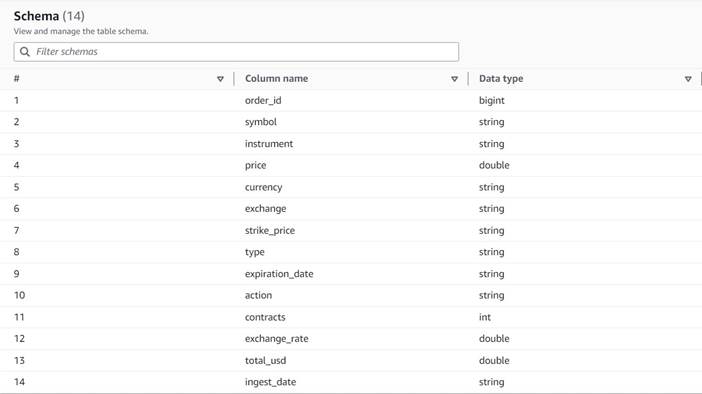
داده های ورودی
داده ها از طرح زیر پیروی می کنند:
- شماره سفارش - شناسه منحصر به فرد
- نماد - کدی که عموماً بر اساس چند حرف برای شناسایی شرکتی که سهام اصلی را منتشر می کند.
- سند - نامی که مشخص کننده گزینه خرید یا فروش خاص است
- پول – کد ارز ISO که قیمت در آن بیان می شود
- قیمت - مبلغی که برای خرید هر قرارداد اختیار معامله پرداخت شده است (در اکثر بورس ها، یک قرارداد به شما امکان خرید یا فروش 100 سهم را می دهد)
- تبادل – کد مرکز مبادلات یا محل معامله که گزینه معامله شده است
- فروخته شده - فهرستی از تعداد قراردادهایی که برای تکمیل سفارش فروش تخصیص داده شده است، زمانی که این معامله فروش است
- خریداری شده – فهرستی از تعداد قراردادهایی که برای تکمیل سفارش خرید در زمانی که این معامله خرید اختصاص داده شده است
نمونه زیر نمونه ای از داده های مصنوعی تولید شده برای این پست است:
الزامات ETL
این داده ها دارای تعدادی ویژگی منحصر به فرد هستند که اغلب در سیستم های قدیمی یافت می شوند که استفاده از داده ها را سخت تر می کند.
موارد زیر الزامات ETL هستند:
- نام ابزار دارای اطلاعات ارزشمندی است که برای درک انسان در نظر گرفته شده است. ما می خواهیم آن را در ستون های جداگانه برای تجزیه و تحلیل آسان تر نرمال کنیم.
- صفات
boughtوsoldمتقابل منحصر به فرد هستند. میتوانیم آنها را در یک ستون با شمارههای قرارداد ادغام کنیم و ستون دیگری داشته باشیم که نشان میدهد آیا قراردادها به این ترتیب خریداری یا فروخته شدهاند. - ما میخواهیم اطلاعات مربوط به تخصیص قراردادهای فردی را حفظ کنیم اما بهعنوان ردیفهای جداگانه به جای اینکه کاربران را مجبور کنیم با مجموعهای از اعداد سروکار داشته باشند. میتوانیم اعداد را جمع کنیم، اما اطلاعات مربوط به نحوه تکمیل سفارش را از دست میدهیم (نشان دهنده نقدینگی بازار). در عوض، ما جدول را غیرعادی می کنیم تا هر سطر دارای یک تعداد قرارداد باشد و سفارشات با چندین شماره را به ردیف های جداگانه تقسیم کنیم. در یک قالب ستونی فشرده، اندازه مجموعه داده اضافی این تکرار اغلب زمانی که فشرده سازی اعمال می شود کوچک است، بنابراین قابل قبول است که پرس و جو از مجموعه داده آسان تر شود.
- ما می خواهیم یک جدول خلاصه از حجم برای هر نوع گزینه (تماس و قرار دادن) برای هر سهام ایجاد کنیم. این نشانه ای از احساسات بازار برای هر سهم و بازار به طور کلی (طمع در مقابل ترس) ارائه می دهد.
- برای فعال کردن خلاصههای کلی تجارت، میخواهیم کل کل را برای هر عملیات ارائه کنیم و با استفاده از یک مرجع تبدیل تقریبی، ارز را به دلار آمریکا استاندارد کنیم.
- ما میخواهیم تاریخی را اضافه کنیم که این تحولات رخ داده است. این میتواند مفید باشد، برای مثال، برای ارجاع به زمان تبدیل ارز.
بر اساس آن الزامات، کار دو خروجی تولید می کند:
- یک فایل CSV با خلاصه ای از تعداد قراردادها برای هر نماد و نوع
- یک جدول کاتالوگ برای نگهداری تاریخچه سفارش، پس از انجام تغییرات نشان داده شده
پیش نیازها
برای دنبال کردن این مورد، به سطل S3 خود نیاز دارید. برای ایجاد یک سطل جدید مراجعه کنید ایجاد یک سطل.
داده های مصنوعی تولید کنید
برای دنبال کردن این پست (یا آزمایش این نوع داده ها به تنهایی)، می توانید این مجموعه داده را به صورت مصنوعی تولید کنید. اسکریپت پایتون زیر را می توان در محیط پایتون با نصب Boto3 و دسترسی به آن اجرا کرد سرویس ذخیره سازی ساده آمازون (Amazon S3).
برای تولید داده ها مراحل زیر را انجام دهید:
- در AWS Glue Studio، یک کار جدید با این گزینه ایجاد کنید ویرایشگر اسکریپت پوسته پایتون.
- به کار یک نام و بر روی جزئیات شغل برگه، a را انتخاب کنید نقش مناسب و نامی برای اسکریپت پایتون.
- در جزئیات شغل بخش، گسترش خواص پیشرفته و رفتن به پایین پارامترهای شغلی.
- پارامتری به نام وارد کنید
--bucketو نام سطلی را که می خواهید برای ذخیره داده های نمونه استفاده کنید به عنوان مقدار اختصاص دهید. - اسکریپت زیر را در ویرایشگر پوسته AWS Glue وارد کنید:
- کار را اجرا کنید و منتظر بمانید تا در تب Runs با موفقیت کامل شده باشد (فقط چند ثانیه طول بکشد).
هر اجرا یک فایل JSON با 1,000 ردیف در زیر سطل و پیشوند مشخص شده تولید می کند. transformsblog/inputdata/. اگر میخواهید با فایلهای ورودی بیشتری آزمایش کنید، میتوانید کار را چندین بار اجرا کنید.
هر خط در داده های مصنوعی یک ردیف داده است که یک شی JSON مانند زیر را نشان می دهد:
کار تصویری AWS Glue را ایجاد کنید
برای ایجاد کار تصویری AWS Glue، مراحل زیر را انجام دهید:
- به AWS Glue Studio بروید و با استفاده از این گزینه یک کار ایجاد کنید تصویری با بوم خالی.
- ویرایش
Untitled jobنام گذاری و اختصاص دادن به آن نقشی مناسب برای چسب AWS در جزئیات شغل تب. - یک منبع داده S3 اضافه کنید (می توانید آن را نام ببرید
JSON files source) و URL S3 را که فایل ها در آن ذخیره می شوند وارد کنید (به عنوان مثال،s3://<your bucket name>/transformsblog/inputdata/)، سپس انتخاب کنید JSON به عنوان فرمت داده - انتخاب کنید استنباط طرحواره بنابراین طرح واره خروجی را بر اساس داده ها تنظیم می کند.
از این گره منبع، تبدیلها را زنجیرهای خواهید کرد. هنگام اضافه کردن هر تبدیل، مطمئن شوید که گره انتخاب شده آخرین گره اضافه شده است تا به عنوان والد اختصاص داده شود، مگر اینکه در دستورالعمل ها به شکل دیگری مشخص شده باشد.
اگر والد مناسبی را انتخاب نکردهاید، همیشه میتوانید با انتخاب آن و انتخاب والد دیگری در صفحه پیکربندی، آن را ویرایش کنید.
برای هر گره اضافه شده، یک نام خاص به آن می دهید (بنابراین هدف گره در نمودار نشان داده می شود) و پیکربندی روی گره دگرگون کردن تب.
هر بار که یک تبدیل طرح را تغییر می دهد (به عنوان مثال، یک ستون جدید اضافه کنید)، طرح خروجی باید به روز شود تا برای تبدیل های پایین دستی قابل مشاهده باشد. شما می توانید طرح خروجی را به صورت دستی ویرایش کنید، اما انجام آن با استفاده از پیش نمایش داده ها عملی تر و ایمن تر است.
علاوه بر این، از این طریق می توانید تأیید کنید که تغییر شکل تا آنجا که انتظار می رود کار می کند. برای انجام این کار، را باز کنید پیش نمایش داده ها تب با تبدیل انتخاب شده و شروع یک جلسه پیش نمایش. بعد از اینکه بررسی کردید که داده های تبدیل شده مطابق انتظار به نظر می رسند، به قسمت بروید طرح واره خروجی برگه را انتخاب کنید و انتخاب کنید از طرح پیش نمایش داده استفاده کنید برای به روز رسانی خودکار طرحواره
همانطور که انواع جدیدی از تبدیل ها را اضافه می کنید، پیش نمایش ممکن است پیامی در مورد یک وابستگی از دست رفته نشان دهد. وقتی این اتفاق افتاد، انتخاب کنید پایان جلسه و یک گره جدید را شروع کنید، بنابراین پیش نمایش نوع جدیدی از گره را انتخاب می کند.
استخراج اطلاعات ابزار
بیایید با پرداختن به اطلاعات روی نام ابزار شروع کنیم تا آن را به ستون هایی تبدیل کنیم که دسترسی آسان تر در جدول خروجی به دست آمده است.
- اضافه کردن رشته را تقسیم کنید گره و نام گذاری کنید
Split instrument، که ستون ابزار را با استفاده از یک regex فضای خالی نشانه گذاری می کند:s+(یک فضای واحد در این مورد انجام می دهد، اما این راه انعطاف پذیرتر و از نظر بصری واضح تر است). - ما می خواهیم اطلاعات ابزار اصلی را همانطور که هست نگه داریم، بنابراین یک نام ستون جدید برای آرایه تقسیم شده وارد کنید:
instrument_arr.
- اضافه کردن آرایه به ستون گره و نام گذاری کنید
Instrument columnsبرای تبدیل ستون آرایه ایجاد شده به فیلدهای جدید، به جز برایsymbol، که قبلاً یک ستون برای آن داریم. - ستون را انتخاب کنید
instrument_arr، اولین نشانه را رد کنید و به آن بگویید که ستون های خروجی را استخراج کندmonth, day, year, strike_price, typeبا استفاده از شاخص ها2, 3, 4, 5, 6(فضاهای بعد از کاما برای خوانایی هستند، روی پیکربندی تأثیری ندارند).
سال استخراج شده تنها با دو رقم بیان می شود. اگر فقط از دو رقم استفاده می کنند، اجازه دهید یک نقطه توقف ایجاد کنیم تا فرض کنیم در این قرن است.
- اضافه کردن ستون مشتق شده گره و نام گذاری کنید
Four digits year. - وارد
yearبه عنوان ستون مشتق شده، آن را باطل می کند، و عبارت SQL زیر را وارد کنید:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
برای راحتی، ما یک expiration_date فیلدی که کاربر می تواند به عنوان مرجع آخرین تاریخ داشته باشد، این گزینه می تواند اعمال شود.
- اضافه کردن به هم پیوستن ستون ها گره و نام گذاری کنید
Build expiration date. - ستون جدید را نامگذاری کنید
expiration_date، ستون ها را انتخاب کنیدyear,monthوday(به ترتیب)، و خط فاصله به عنوان فاصله.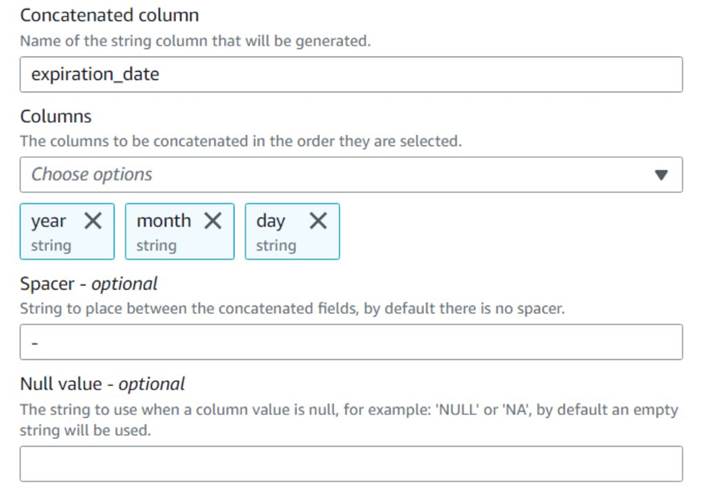
نمودار تا اینجا باید مانند مثال زیر باشد.
![]()
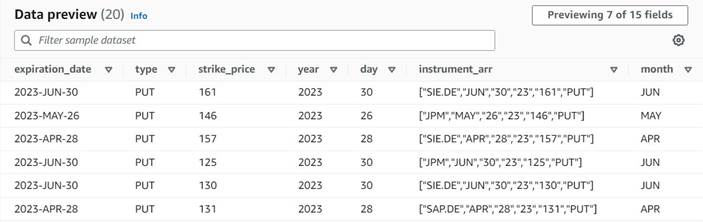
پیش نمایش داده های ستون های جدید تا کنون باید مانند تصویر زیر باشد.
تعداد قراردادها را عادی کنید
هر یک از ردیفهای موجود در دادهها تعداد قراردادهای هر گزینه خریداری یا فروخته شده و دستههایی را که سفارشها بر اساس آنها پر شده است را نشان میدهد. بدون از دست دادن اطلاعات مربوط به دستههای جداگانه، میخواهیم هر مقدار را در یک ردیف جداگانه با یک مقدار واحد داشته باشیم، در حالی که بقیه اطلاعات در هر ردیف تولید شده تکرار میشوند.
ابتدا، بیایید مقادیر را در یک ستون ادغام کنیم.
- اضافه کردن ستون ها را به ردیف باز کنید گره و نام گذاری کنید
Unpivot actions. - ستون ها را انتخاب کنید
boughtوsoldبرای برداشتن و ذخیره نام ها و مقادیر در ستون های نامگذاری شدهactionوcontractsبود.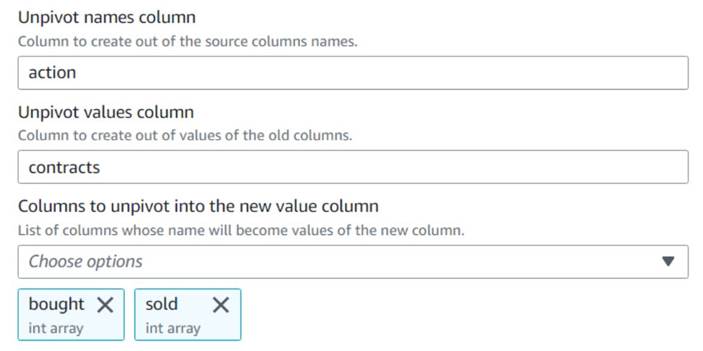
در پیش نمایش توجه کنید که ستون جدیدcontractsهنوز هم آرایه ای از اعداد پس از این تبدیل است.
- اضافه کردن منفجر کردن آرایه یا نقشه به ردیف ردیف به نام
Explode contracts. - انتخاب
contractsستون و وارد کنیدcontractsبه عنوان ستون جدید برای لغو آن (نیازی به نگه داشتن آرایه اصلی نداریم).
اکنون پیشنمایش نشان میدهد که هر ردیف دارای یک تک است contracts مقدار و بقیه فیلدها یکسان است.
این نیز به این معنی است order_id دیگر یک کلید منحصر به فرد نیست. برای موارد استفاده خودتان، باید تصمیم بگیرید که چگونه داده های خود را مدل کنید و آیا می خواهید غیرعادی کنید یا خیر.
اسکرین شات زیر نمونه ای از شکل ظاهری ستون های جدید پس از تحولات تاکنون است.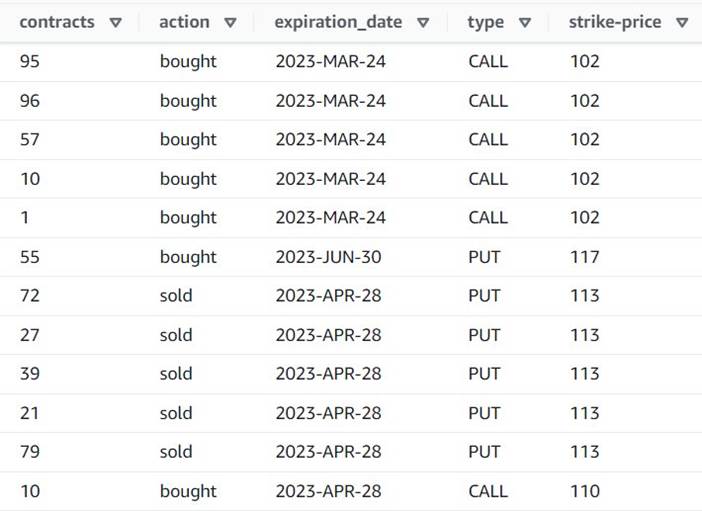
یک جدول خلاصه ایجاد کنید
اکنون یک جدول خلاصه با تعداد قراردادهای معامله شده برای هر نوع و هر نماد سهام ایجاد می کنید.
برای مثال فرض کنید فایلهای پردازششده متعلق به یک روز است، بنابراین این خلاصه اطلاعاتی در مورد علاقه و احساسات بازار در آن روز به کاربران تجاری میدهد.
- اضافه کردن زمینه ها را انتخاب کنید گره را انتخاب کنید و ستون های زیر را برای حفظ خلاصه انتخاب کنید:
symbol,typeوcontracts.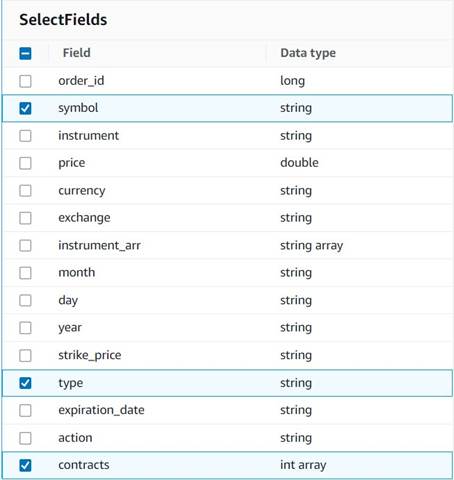
- اضافه کردن ردیفها را به ستونها بپیچید گره و نام گذاری کنید
Pivot summary. - تجمع بر روی
contractsستون با استفاده ازsumو تبدیل آن را انتخاب کنیدtypeستون.
به طور معمول، شما آن را در یک پایگاه داده یا فایل خارجی برای مرجع ذخیره می کنید. در این مثال، ما آن را به عنوان یک فایل CSV در آمازون S3 ذخیره می کنیم.
- اضافه کردن پردازش تعادل خودکار گره و نام گذاری کنید
Single output file. - اگرچه این نوع تبدیل معمولاً برای بهینهسازی موازیسازی استفاده میشود، در اینجا ما از آن برای کاهش خروجی به یک فایل استفاده میکنیم. بنابراین، وارد شوید
1در پیکربندی تعداد پارتیشن ها
- یک هدف S3 اضافه کنید و نام آن را بگذارید
CSV Contract summary. - CSV را به عنوان قالب داده انتخاب کنید و یک مسیر S3 را وارد کنید که در آن نقش شغل مجاز به ذخیره فایلها است.
قسمت آخر کار اکنون باید مانند مثال زیر باشد.![]()
- کار را ذخیره و اجرا کنید. استفاده کنید اجرا می شود برای بررسی اینکه چه زمانی با موفقیت به پایان رسیده است.
با وجود نداشتن پسوند، فایلی را در زیر آن مسیر پیدا خواهید کرد که CSV است. احتمالاً باید پس از دانلود آن افزونه را اضافه کنید تا باز شود.
در ابزاری که می تواند CSV را بخواند، خلاصه باید چیزی شبیه به مثال زیر باشد.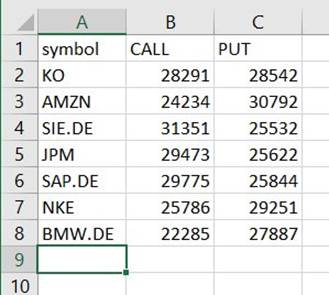
ستون های موقت را تمیز کنید
در آماده سازی برای ذخیره سفارشات در یک جدول تاریخی برای تجزیه و تحلیل آینده، اجازه دهید برخی از ستون های موقت ایجاد شده در طول مسیر را پاکسازی کنیم.
- اضافه کردن فیلدها را رها کنید گره با
Explode contractsگره به عنوان والد انتخاب شده است (ما در حال انشعاب خط لوله داده برای تولید یک خروجی جداگانه هستیم). - فیلدهایی را که قرار است حذف شوند را انتخاب کنید:
instrument_arr,month,dayوyear.
بقیه را که میخواهیم نگه داریم تا در جدول تاریخی که بعداً ایجاد خواهیم کرد، ذخیره شوند.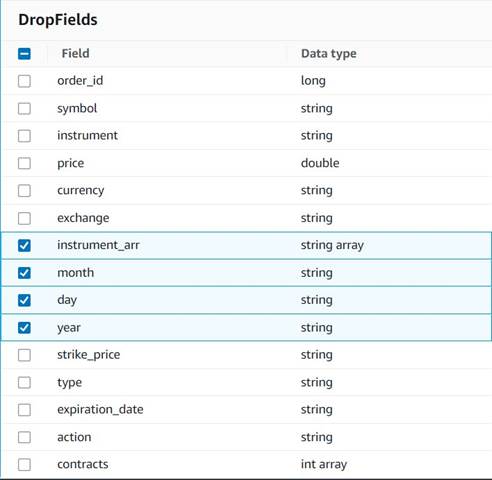
استانداردسازی ارز
این دادههای مصنوعی شامل عملیات تخیلی روی دو ارز است، اما در یک سیستم واقعی میتوانید ارزها را از بازارهای سراسر جهان دریافت کنید. استانداردسازی ارزهای مورد استفاده در یک ارز مرجع واحد مفید است تا بتوان آنها را به راحتی برای گزارش و تجزیه و تحلیل مقایسه و تجمیع کرد.
استفاده می کنیم آمازون آتنا برای شبیهسازی جدولی با تبدیلهای تقریبی ارز که بهطور دورهای بهروزرسانی میشود (در اینجا فرض میکنیم که سفارشها را بهاندازه کافی پردازش میکنیم که تبدیل نماینده معقولی برای مقاصد مقایسه باشد).
- کنسول Athena را در همان منطقه ای که از چسب AWS استفاده می کنید باز کنید.
- پرس و جوی زیر را برای ایجاد جدول با تنظیم یک مکان S3 که در آن نقش Athena و AWS Glue شما می توانند بخوانند و بنویسند، اجرا کنید. همچنین، ممکن است بخواهید جدول را در پایگاه داده دیگری ذخیره کنید
default(اگر این کار را انجام می دهید، نام واجد شرایط جدول را مطابق با مثال های ارائه شده به روز کنید). - چند تبدیل نمونه را در جدول وارد کنید:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - اکنون باید بتوانید جدول را با پرس و جو زیر مشاهده کنید:
SELECT * FROM default.exchange_rates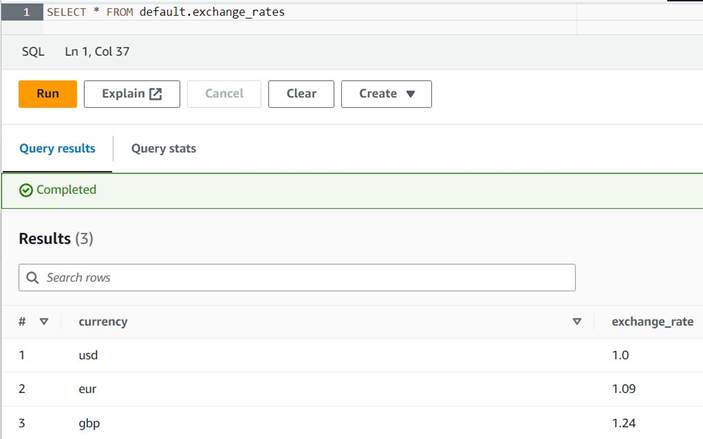
- به کار بصری چسب AWS، یک را اضافه کنید گرین کارت آمریکا گره (به عنوان فرزند
Drop Fields) و نام ببریدExchange rate. - نام با کیفیت جدولی را که به تازگی ایجاد کرده اید، با استفاده از آن وارد کنید
currencyبه عنوان کلید و انتخاب کنیدexchange_rateزمینه برای استفاده
از آنجایی که نام فیلد هم در داده ها و هم در جدول جستجو یکسان است، فقط می توانیم نام را وارد کنیمcurrencyو نیازی به تعریف نقشه نیست.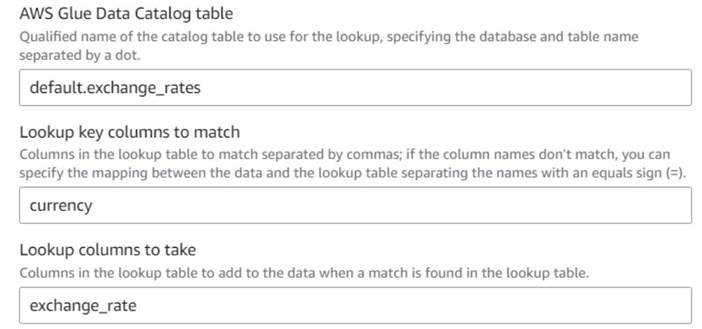
در زمان نوشتن این مقاله، تبدیل Lookup در پیش نمایش داده ها پشتیبانی نمی شود و خطای عدم وجود جدول را نشان می دهد. این فقط برای پیش نمایش داده است و مانع از اجرای صحیح کار نمی شود. چند مرحله باقی مانده از پست نیازی به به روز رسانی طرحواره ندارد. اگر نیاز به اجرای پیش نمایش داده روی گره های دیگر دارید، می توانید گره جستجو را به طور موقت حذف کرده و سپس آن را دوباره برگردانید. - اضافه کردن ستون مشتق شده گره و نام گذاری کنید
Total in usd. - ستون مشتق شده را نام ببرید
total_usdو از عبارت SQL زیر استفاده کنید:round(contracts * price * exchange_rate, 2)
- اضافه کردن مُهر زمانی فعلی را اضافه کنید گره و نام ستون
ingest_date. - از قالب استفاده کنید
%Y-%m-%dبرای مهر زمانی شما (برای اهداف نمایشی، ما فقط از تاریخ استفاده می کنیم؛ اگر بخواهید می توانید آن را دقیق تر کنید).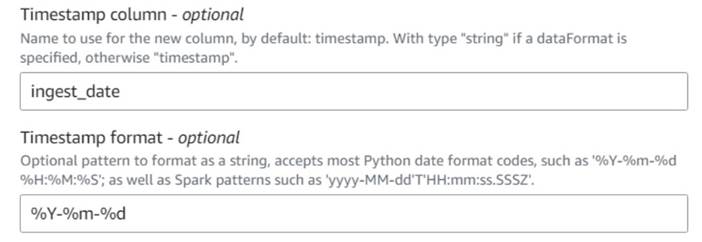
جدول سفارشات تاریخی را ذخیره کنید
برای ذخیره جدول سفارشات تاریخی، مراحل زیر را انجام دهید:
- یک گره هدف S3 اضافه کنید و آن را نامگذاری کنید
Orders table. - قالب پارکت را با فشرده سازی سریع پیکربندی کنید و یک مسیر هدف S3 برای ذخیره نتایج (جدا از خلاصه) در زیر آن ارائه دهید.
- انتخاب کنید ایجاد یک جدول در کاتالوگ داده و در اجراهای بعدی، به روز رسانی طرح و اضافه کردن پارتیشن های جدید.
- یک پایگاه داده هدف و یک نام برای جدول جدید وارد کنید، به عنوان مثال:
option_orders.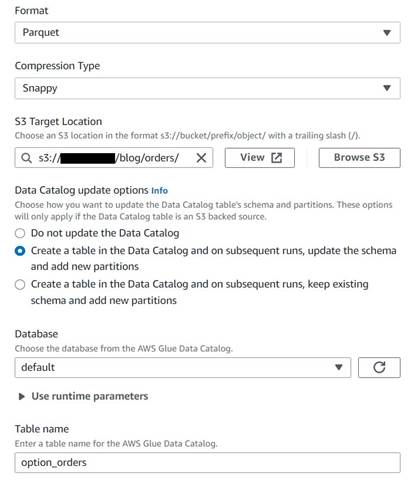
بخش آخر نمودار اکنون باید شبیه به شکل زیر باشد، با دو شاخه برای دو خروجی مجزا.![]()
پس از اجرای موفقیت آمیز کار، می توانید از ابزاری مانند Athena برای بررسی داده هایی که کار تولید کرده است با جستجو در جدول جدید استفاده کنید. می توانید جدول را در لیست آتنا پیدا کنید و انتخاب کنید پیش نمایش جدول یا فقط یک کوئری SELECT (به روز رسانی نام جدول به نام و کاتالوگ مورد استفاده خود) اجرا کنید:
SELECT * FROM default.option_orders limit 10
محتوای جدول شما باید شبیه تصویر زیر باشد.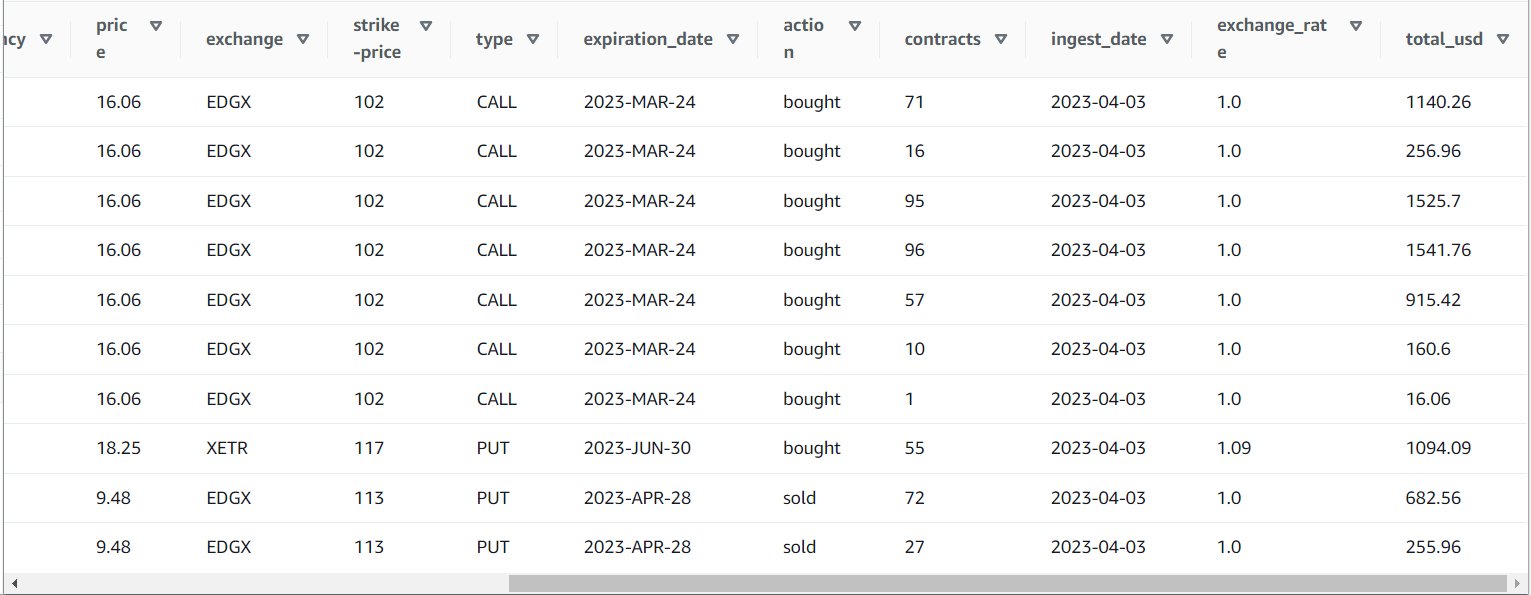
پاک کردن
اگر نمیخواهید این مثال را حفظ کنید، دو شغلی که ایجاد کردهاید، دو جدول در آتنا و مسیرهای S3 که فایلهای ورودی و خروجی در آن ذخیره شدهاند را حذف کنید.
نتیجه
در این پست نشان دادیم که چگونه تبدیلهای جدید در AWS Glue Studio میتواند به شما کمک کند تا تحولات پیشرفتهتری را با حداقل پیکربندی انجام دهید. این بدان معنی است که می توانید موارد استفاده بیشتری از ETL را بدون نیاز به نوشتن و نگهداری کد پیاده سازی کنید. تبدیلهای جدید در حال حاضر در AWS Glue Studio موجود است، بنابراین میتوانید از تبدیلهای جدید امروز در کارهای بصری خود استفاده کنید.
درباره نویسنده
![]() گونزالو هرروس یک معمار ارشد داده های بزرگ در تیم AWS Glue است.
گونزالو هرروس یک معمار ارشد داده های بزرگ در تیم AWS Glue است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoAiStream. Web3 Data Intelligence دانش تقویت شده دسترسی به اینجا.
- ضرب کردن آینده با آدرین اشلی. دسترسی به اینجا.
- خرید و فروش سهام در شرکت های PRE-IPO با PREIPO®. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- ٪۱۰۰
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- قادر
- درباره ما
- قابل قبول
- دسترسی
- بر این اساس
- اضافه کردن
- اضافه
- اضافه کردن
- پیشرفته
- پس از
- معرفی
- اختصاص داده شده است
- تخصیص ها
- اجازه دادن
- اجازه می دهد تا
- در امتداد
- قبلا
- همچنین
- همیشه
- آمازون
- مقدار
- مقدار
- an
- تحلیل
- تحلیل
- و
- دیگر
- هر
- اعمال می شود
- تقریبی
- آوریل
- هستند
- استدلال
- صف
- AS
- اختصاص داده
- At
- خواص
- بطور خودکار
- در دسترس
- AWS
- چسب AWS
- به عقب
- مستقر
- BE
- قبل از
- بودن
- بزرگ
- بزرگ داده
- سفید
- BMW
- هر دو
- خریداری شده
- شاخه ها
- ساختن
- کسب و کار
- اما
- خرید
- by
- صدا
- CAN
- مورد
- موارد
- کاتالوگ
- مرکز
- قرن
- تبادل
- مشخصات
- بررسی
- کودک
- را انتخاب کنید
- انتخاب
- واضح تر
- رمز
- برنامه نویسی
- ستون
- ستون ها
- مشترک
- مقایسه
- مقایسه
- کامل
- تکمیل شده
- پیکر بندی
- کنسول
- محکم کردن
- شامل
- محتوا
- قرارداد
- قرارداد
- راحتی
- تبدیل
- تبدیل
- تبدیل
- مبدل
- شرکت
- میتوانست
- ایجاد
- ایجاد شده
- ایجاد
- ارز
- واحد پول
- جاری
- DAG
- داده ها
- پایگاه داده
- تاریخ
- تاریخ
- زمان قرار
- روز
- مقدار
- معامله
- تصمیم گیری
- به طور پیش فرض
- مشخص
- نشان
- وابستگی
- نشات گرفته
- با وجود
- جزئیات
- مختلف
- رقم
- بحث و تبادل نظر
- do
- نمی کند
- عمل
- دلار
- آیا
- دو برابر
- پایین
- قطره
- کاهش یافته است
- هر
- آسان تر
- به آسانی
- ساده
- سردبیر
- قادر ساختن
- کافی
- وارد
- محیط
- خطا
- اتر (ETH)
- EUR
- مثال
- مثال ها
- جز
- تبادل
- مبادلات
- انحصاری
- وجود داشته باشد
- گسترش
- انتظار می رود
- تجربه
- انقضاء
- بیان
- گسترش
- خارجی
- اضافی
- عصاره
- بسیار
- ترس
- کمی از
- تخیلی
- رشته
- زمینه
- پرونده
- فایل ها
- پر کردن
- پر شده
- مالی
- ابزارهای مالی
- پیدا کردن
- نام خانوادگی
- ثابت
- قابل انعطاف
- به دنبال
- پیروی
- به دنبال آن است
- برای
- قالب
- یافت
- از جانب
- آینده
- GBP
- سوالات عمومی
- عموما
- تولید می کنند
- تولید
- دریافت کنید
- دادن
- می دهد
- Go
- گراف
- طمع
- اداره
- اتفاق می افتد
- آیا
- داشتن
- کمک
- اینجا کلیک نمایید
- تاریخی
- تاریخ
- چگونه
- چگونه
- HTML
- HTTP
- HTTPS
- انسان
- i
- شناسایی می کند
- شناسایی
- if
- تأثیر
- انجام
- واردات
- in
- فهرستها
- نشان داد
- نشان می دهد
- نشان دادن
- نشانه
- فرد
- اطلاعات
- ورودی
- نمونه
- در عوض
- دستورالعمل
- سند
- ابزار
- علاقه
- رابط
- به
- ISO
- IT
- ITS
- کار
- شغل ها
- JPG
- json
- تنها
- نگاه داشتن
- کلید
- نوع
- نام
- بعد
- پسندیدن
- محدود
- لاین
- نقدینگی
- فهرست
- بار
- محل
- دیگر
- نگاه کنيد
- شبیه
- مطالب
- مراجعه
- از دست دادن
- شکست
- ساخته
- حفظ
- ساخت
- باعث می شود
- دستی
- نقشه
- نقشه برداری
- بازار
- احساسات بازار
- بازارها
- ممکن است..
- به معنی
- ادغام کردن
- پیام
- قدرت
- حد اقل
- گم
- مدل
- مانیتور
- بیش
- اکثر
- چندگانه
- متقابلا
- نام
- تحت عنوان
- نام
- نیاز
- نیازهای
- جدید
- نه
- گره
- گره
- به طور معمول
- اکنون
- عدد
- تعداد
- هدف
- of
- غالبا
- on
- ONE
- فقط
- باز کن
- عمل
- عملیات
- بهینه سازی
- گزینه
- گزینه
- or
- سفارش
- سفارشات
- اصلی
- دیگر
- در غیر این صورت
- تولید
- روی
- به طور کلی
- باطل کردن
- خود
- پرداخت
- قطعه
- پارامتر
- بخش
- مسیر
- کلاهبرداری
- خط لوله
- محور
- محل
- افلاطون
- هوش داده افلاطون
- PlatoData
- پست
- پتانسیل
- عملی
- دقیق
- جلوگیری از
- پیش نمایش
- قیمت
- شاید
- روند
- در حال پردازش
- تولید کردن
- ساخته
- ارائه
- ارائه
- فراهم می کند
- خرید
- هدف
- اهداف
- قرار دادن
- پــایتــون
- واجد شرایط
- بالا بردن
- تصادفی
- خواندن
- واقعی
- معقول
- كاهش دادن
- بازتاب
- منطقه
- باقی مانده
- برداشتن
- تکرار شده
- گزارش
- نشان دادن
- نماینده
- نمایندگی
- نشان دهنده
- نیاز
- مورد نیاز
- نیاز
- به ترتیب
- REST
- نتیجه
- نتایج
- این فایل نقد می نویسید:
- نقش
- نقش
- ROW
- دویدن
- در حال اجرا
- امن تر
- همان
- شیره
- ذخیره
- صرفه جویی کردن
- حرکت
- ثانیه
- انتخاب شد
- انتخاب
- فروش
- ارشد
- احساس
- جداگانه
- جلسه
- مجموعه
- محیط
- سهام
- صدف
- باید
- نشان
- نشان می دهد
- مشابه
- ساده
- تنها
- اندازه
- مهارت ها
- کوچک
- So
- تا حالا
- فروخته شده
- برخی از
- چیزی
- منبع
- فضا
- فضاها
- خاص
- مشخص شده
- انشعاب
- صفحه گسترده
- SQL
- شروع
- مراحل
- هنوز
- موجودی
- ذخیره سازی
- opbevare
- ذخیره شده
- رشته
- استودیو
- متعاقب
- موفقیت
- مناسب
- خلاصه
- پشتیبانی
- نماد
- ترکیبی
- داده های مصنوعی
- مصنوعی
- سیستم
- سیستم های
- جدول
- گرفتن
- هدف
- تیم
- گفتن
- موقت
- ده
- آزمون
- نسبت به
- که
- La
- نمودار
- اطلاعات
- جهان
- آنها
- سپس
- از این رو
- اینها
- آنها
- این
- کسانی که
- زمان
- بار
- برچسب زمان
- به
- امروز
- رمز
- tokenize
- در زمان
- ابزار
- جمع
- تجارت
- داد و ستد
- دگرگون کردن
- دگرگونی
- تحولات
- مبدل
- دو
- نوع
- زیر
- اساسی
- فهمیدن
- منحصر به فرد
- تا
- بروزرسانی
- به روز شده
- به روز رسانی
- URL
- us
- دلار
- دلار آمریکا
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- کاربران
- با استفاده از
- ارزشمند
- اطلاعات ارزشمند
- ارزش
- ارزشها
- محل برگزاری
- تایید
- بررسی
- چشم انداز
- قابل رویت
- حجم
- vs
- صبر کنيد
- می خواهم
- بود
- مسیر..
- we
- بود
- چی
- چه زمانی
- که
- در حین
- اراده
- با
- بدون
- گردش کار
- کارگر
- جهان
- خواهد بود
- نوشتن
- نوشته
- سال
- شما
- شما
- زفیرنت











