
تصویر ایجاد شده با DALL-E3
هوش مصنوعی یک انقلاب کامل در دنیای فناوری بوده است.
توانایی آن در تقلید از هوش انسانی و انجام وظایفی که زمانی تنها حوزه های انسانی در نظر گرفته می شدند، هنوز بسیاری از ما را شگفت زده می کند.
با این حال، مهم نیست که این جهشهای اخیر هوش مصنوعی چقدر خوب بوده است، همیشه جایی برای بهبود وجود دارد.
و این دقیقا همان جایی است که مهندسی سریع شروع به کار می کند!
وارد این زمینه شوید که می تواند بهره وری مدل های هوش مصنوعی را به میزان قابل توجهی افزایش دهد.
بیایید همه را با هم کشف کنیم!
مهندسی سریع یک دامنه در حال رشد سریع در هوش مصنوعی است که بر بهبود کارایی و اثربخشی مدلهای زبان تمرکز دارد. همه چیز در مورد ایجاد دستورات عالی برای راهنمایی مدل های هوش مصنوعی برای تولید خروجی های مورد نظر ما است.
به این فکر کنید که یاد بگیرید چگونه دستورات بهتری به کسی بدهید تا مطمئن شوید که یک کار را به درستی درک کرده و اجرا می کند.
چرا مهندسی سریع مهم است
- افزایش بهره وری: با استفاده از درخواستهای با کیفیت بالا، مدلهای هوش مصنوعی میتوانند پاسخهای دقیقتر و مرتبطتری تولید کنند. این بدان معناست که زمان کمتری برای اصلاحات صرف میشود و زمان بیشتری برای استفاده از قابلیتهای هوش مصنوعی صرف میشود.
- کارایی هزینه: آموزش مدل های هوش مصنوعی نیازمند منابع است. مهندسی سریع می تواند نیاز به بازآموزی را با بهینه سازی عملکرد مدل از طریق اعلان های بهتر کاهش دهد.
- تطبیق پذیری: یک درخواست خوب میتواند مدلهای هوش مصنوعی را همهکارهتر کند و به آنها اجازه دهد تا با طیف وسیعتری از وظایف و چالشها مقابله کنند.
قبل از غواصی در پیشرفتهترین تکنیکها، اجازه دهید دو مورد از مفیدترین (و اساسیترین) تکنیکهای مهندسی سریع را یادآوری کنیم.
تفکر متوالی با "بیایید قدم به قدم فکر کنیم"
امروزه به خوبی شناخته شده است که دقت مدل های LLM با اضافه کردن دنباله کلمه "بیایید گام به گام فکر کنیم" به طور قابل توجهی بهبود یافته است.
چرا… ممکن است بپرسید؟
خوب، این به این دلیل است که ما مدل را مجبور می کنیم تا هر کار را به چند مرحله تقسیم کند، بنابراین مطمئن می شویم که مدل زمان کافی برای پردازش هر یک از آنها دارد.
برای مثال، میتوانم GPT3.5 را با دستور زیر به چالش بکشم:
اگر جان 5 گلابی داشته باشد، 2 تا بخورد، 5 تا دیگر بخرد، 3 تا به دوستش بدهد، چند گلابی دارد؟
مدل فوراً به من پاسخ می دهد. با این حال، اگر «بیایید گام به گام فکر کنیم» نهایی را اضافه کنم، مدل را مجبور میکنم که یک فرآیند تفکر با چند مرحله ایجاد کند.
چند شات تحریک
در حالی که دستور Zero-shot به درخواست از مدل برای انجام یک کار بدون ارائه هیچ زمینه یا دانش قبلی اشاره دارد، تکنیک تحریک چند شات به این معنی است که ما LLM را با چند نمونه از خروجی مورد نظر خود همراه با چند سوال خاص ارائه می کنیم.
برای مثال، اگر بخواهیم مدلی ارائه کنیم که هر اصطلاحی را با استفاده از لحن شاعرانه تعریف کند، ممکن است توضیح آن بسیار سخت باشد. درست؟
با این حال، میتوانیم از دستورات چند شات زیر برای هدایت مدل به سمتی که میخواهیم استفاده کنیم.
وظیفه شما این است که به سبکی سازگار با سبک زیر پاسخ دهید.
: تاب آوری را به من بیاموز.
: تاب آوری مانند درختی است که با باد خم می شود اما هرگز نمی شکند.
این توانایی عقب نشینی از ناملایمات و ادامه حرکت رو به جلو است.
: نظر شما اینجاست.
اگر هنوز آن را امتحان نکردهاید، میتوانید GPT را به چالش بکشید.
با این حال، از آنجایی که من تقریباً مطمئن هستم که بسیاری از شما قبلاً این تکنیکهای اساسی را میدانید، سعی میکنم شما را با چند تکنیک پیشرفته به چالش بکشم.
1. زنجیره فکر (CoT) تحریک
معرفی شده توسط گوگل در سال 2022، این روش شامل دستور دادن به مدل برای گذراندن چندین مرحله استدلال قبل از ارائه پاسخ نهایی است.
آشنا به نظر می رسد درست است؟ اگر چنین است، کاملاً حق با شماست.
این مانند ادغام هر دو تفکر متوالی و چند شات است.
چگونه؟
اساساً، درخواست CoT به LLM هدایت می کند تا اطلاعات را به صورت متوالی پردازش کند. این بدان معناست که ما مثال میزنیم که چگونه یک مسئله اول را با استدلال چند مرحلهای حل کنیم و سپس تکلیف واقعی خود را به مدل بفرستیم، انتظار داریم که در هنگام پاسخ دادن به پرس و جوی واقعی که میخواهیم آن را حل کند، یک زنجیره فکری قابل مقایسه را تقلید کند.
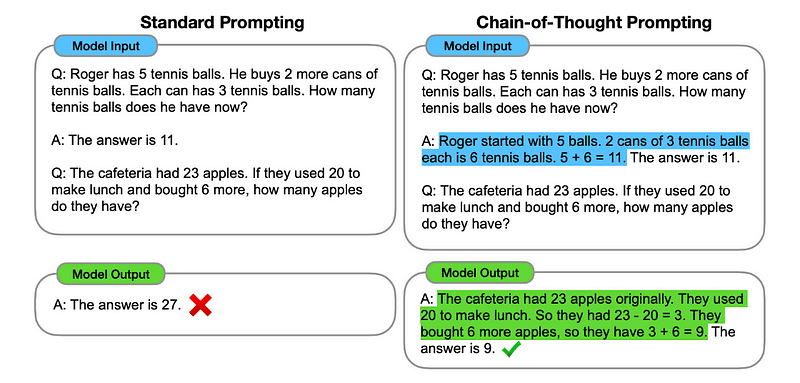
تصویر گرفته شده از مقاله.
بنابراین، به دنبال اولین مثال، میتوانیم یک اعلان با اولین مشکل و توضیح متوالی در مورد چگونگی حل آن ارائه دهیم. سپس، می توانیم ورودی خود را ارسال کنیم و ببینیم که چگونه جادو اتفاق می افتد!
اگر جان 5 گلابی داشته باشد، 2 تا بخورد، 5 تا دیگر بخرد، 3 تا به دوستش بدهد، چند گلابی دارد؟ بیایید قدم به قدم فکر کنیم.
بیایید قدم به قدم پیش برویم. جان با 5 گلابی شروع می کند. او 2 گلابی می خورد، بنابراین 5-2 = 3 گلابی برایش باقی مانده است. سپس 5 گلابی دیگر می خرد. بنابراین، او اکنون 3 + 5 = 8 گلابی دارد. بالاخره 3 گلابی به دوستش می دهد. بنابراین، او 8-3 = 5 گلابی باقی مانده است. پس بعد از تمام این مراحل جان 5 گلابی دارد.
ورودی شما در اینجا
با این حال، بیشتر شما باید فکر کنید... آیا هر زمان که میخواهم در ChatGPT چیزی بپرسم، باید به روشی متوالی برای حل هر مشکلی فکر کنم؟
خب... تو اولین نفر نیستی! و این ما را به سمت…
2. زنجیره افکار خودکار (Auto-CoT)
در 2022، ژانگ و همکاران روشی را برای اجتناب از این فرآیند دستی معرفی کردند. دو دلیل اصلی برای اجتناب از هر کار دستی وجود دارد:
- می تواند خسته کننده باشد.
- It can yield bad results – for instance, when our mental process is wrong.
They suggested using LLMs combined with the “Let’s think step by step” prompt to sequentially produce reasoning chains for each demonstration.
این بدان معناست که از ChatGPT بپرسید که چگونه هر مشکلی را به صورت متوالی حل کند و سپس از همین مثال برای آموزش نحوه حل هر مشکل دیگر استفاده کنید.
3. خود سازگاری
سازگاری با خود یکی دیگر از تکنیکهای انگیزشی جالب است که هدف آن بهبود زنجیره فکری است که مشکلات استدلالی پیچیدهتر را تحریک میکند.
بنابراین ... تفاوت اصلی چیست؟
ایده اصلی در خود سازگاری، آگاهی از این است که میتوانیم مدل را با یک مثال اشتباه آموزش دهیم. فقط تصور کنید که من مشکل قبلی را با یک فرآیند ذهنی اشتباه حل می کنم:
اگر جان 5 گلابی داشته باشد، 2 تا بخورد، 5 تا دیگر بخرد، 3 تا به دوستش بدهد، چند گلابی دارد؟ بیایید قدم به قدم فکر کنیم.
Start with 5 pears. John eats 2 pears. Then, he gives 3 pears to his friend. These actions can be combined: 2 (eaten) + 3 (given) = 5 pears in total affected. Now, subtract the total pears affected from the initial 5 pears: 5 (initial) – 5 (affected) = 0 pears left.
سپس، هر کار دیگری که برای مدل ارسال کنم اشتباه خواهد بود.
به همین دلیل است که خودسازگاری شامل نمونهگیری از مسیرهای استدلالی مختلف است که هر کدام شامل زنجیرهای از فکر است و سپس به LLM اجازه میدهد بهترین و سازگارترین مسیر را برای حل مشکل انتخاب کند.
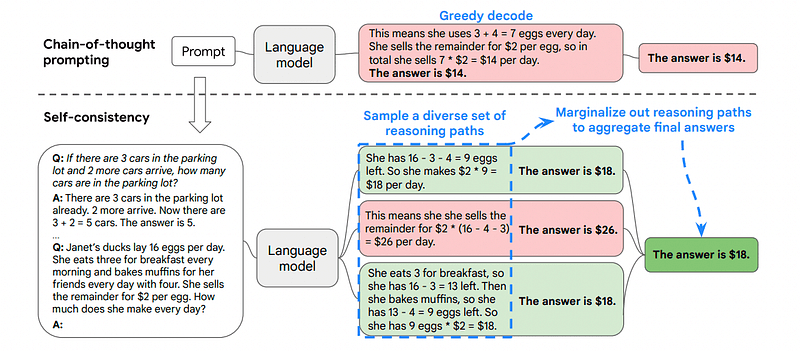
تصویر گرفته شده از مقاله
در این صورت و با پیروی از مثال اول مجدداً میتوانیم راههای مختلف حل مسئله را به مدل نشان دهیم.
اگر جان 5 گلابی داشته باشد، 2 تا بخورد، 5 تا دیگر بخرد، 3 تا به دوستش بدهد، چند گلابی دارد؟
با 5 گلابی شروع کنید. جان 2 گلابی می خورد و 5 تا 2 = 3 گلابی برای او باقی می گذارد. او 5 گلابی دیگر می خرد که مجموع آن را به 3 + 5 = 8 گلابی می رساند. در نهایت او 3 گلابی به دوستش می دهد، بنابراین 8-3 = 5 گلابی برای او باقی مانده است.
اگر جان 5 گلابی داشته باشد، 2 تا بخورد، 5 تا دیگر بخرد، 3 تا به دوستش بدهد، چند گلابی دارد؟
Start with 5 pears. He then buys 5 more pears. John eats 2 pears now. These actions can be combined: 2 (eaten) + 5 (bought) = 7 pears in total. Subtract the pear that Jon has eaten from the total amount of pears 7 (total amount) – 2 (eaten) = 5 pears left.
ورودی شما در اینجا
و در اینجا آخرین تکنیک می آید.
4. ایجاد دانش عمومی
یک روش متداول مهندسی سریع، تقویت یک پرسش با دانش اضافی قبل از ارسال تماس نهایی API به GPT-3 یا GPT-4 است.
مطابق با جیاچنگ لیو و شرکت، ما همیشه می توانیم مقداری دانش را به هر درخواستی اضافه کنیم تا LLM در مورد سؤال بهتر بداند.
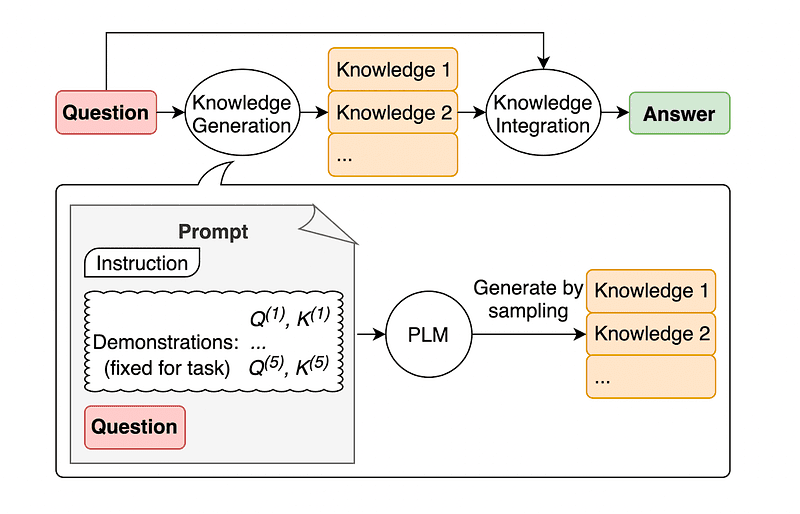
تصویر گرفته شده از مقاله.
بنابراین، برای مثال، وقتی از ChatGPT میپرسیم که آیا بخشی از گلف تلاش میکند تا مجموع امتیاز بالاتری نسبت به سایرین کسب کند، به ما اعتبار میدهد. اما هدف اصلی گلف کاملا برعکس است. به همین دلیل است که میتوانیم دانش قبلی را اضافه کنیم و به آن بگوییم «بازیکنی که امتیاز کمتری دارد برنده میشود».

بنابراین، اگر دقیقاً جواب را به مدل بگوییم، قسمت خندهدار چیست؟
در این مورد، این تکنیک برای بهبود نحوه تعامل LLM با ما استفاده می شود.
So rather than pulling supplementary context from an outside database, the paper’s authors recommend having the LLM produce its own knowledge. This self-generated knowledge is then integrated into the prompt to bolster commonsense reasoning and give better outputs.
بنابراین اینگونه است که LLM ها را می توان بدون افزایش مجموعه داده آموزشی آن بهبود بخشید!
مهندسی سریع به عنوان یک تکنیک محوری در افزایش قابلیت های LLM ظاهر شده است. با تکرار و بهبود اعلانها، میتوانیم به شیوهای مستقیمتر با مدلهای هوش مصنوعی ارتباط برقرار کنیم و بنابراین خروجیهای دقیقتر و مرتبطتری به دست آوریم و در زمان و منابع صرفهجویی کنیم.
برای علاقه مندان به فناوری، دانشمندان داده و سازندگان محتوا به طور یکسان، درک و تسلط بر مهندسی سریع می تواند دارایی ارزشمندی در استفاده از پتانسیل کامل هوش مصنوعی باشد.
با ترکیب دستورات ورودی با دقت طراحی شده با این تکنیک های پیشرفته تر، داشتن مجموعه مهارت های مهندسی سریع بدون شک در سال های آینده به شما برتری خواهد داد.
جوزپ فرر یک مهندس تجزیه و تحلیل از بارسلونا است. او در رشته مهندسی فیزیک فارغ التحصیل شد و در حال حاضر در زمینه علم داده های کاربردی برای تحرک انسان کار می کند. او یک تولید کننده محتوای پاره وقت است که بر علم و فناوری داده تمرکز دارد. می توانید با او تماس بگیرید لینک, توییتر or متوسط.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- توانایی
- درباره ما
- دقت
- دقیق
- اقدامات
- واقعی
- اضافه کردن
- اضافه کردن
- اضافی
- پیشرفته
- پس از
- از نو
- AI
- مدل های هوش مصنوعی
- اهداف
- هم راستا
- به طور یکسان
- معرفی
- اجازه دادن
- در امتداد
- قبلا
- همیشه
- am
- مقدار
- an
- علم تجزیه و تحلیل
- و
- دیگر
- پاسخ
- هر
- API
- اعمال می شود
- هستند
- AS
- پرسیدن
- خواهان
- دارایی
- نویسندگان
- اتوماتیک
- اجتناب از
- مطلع
- دور
- به عقب
- بد
- بارسلونا
- اساسی
- BE
- زیرا
- بوده
- قبل از
- بودن
- بهترین
- بهتر
- تقویت کنید
- بالا بردن
- خسته کننده
- هر دو
- خریداری شده
- گزاف گویی
- شکستن
- می شکند
- به ارمغان می آورد
- گسترده تر
- اما
- خریداری می کند
- by
- صدا
- CAN
- قابلیت های
- Осторожно
- مورد
- زنجیر
- زنجیر
- به چالش
- چالش ها
- GPT چت
- را انتخاب کنید
- همکاران
- ترکیب شده
- ترکیب
- بیا
- می آید
- آینده
- مشترک
- ارتباط
- قابل مقایسه
- کامل
- پیچیده
- در نظر گرفته
- استوار
- تماس
- محتوا
- سازندگان محتوا
- زمینه
- اصلاحات
- به درستی
- میتوانست
- ایجاد شده
- خالق
- سازندگان
- در حال حاضر
- داده ها
- علم اطلاعات
- پایگاه داده
- تعریف می کند
- تحویل
- طراحی
- مطلوب
- تفاوت
- مختلف
- مستقیم
- جهت
- كشف كردن
- غواصی
- do
- میکند
- دامنه
- حوزه
- پایین
- هر
- لبه
- اثر
- بهره وری
- ظهور
- مهندس
- مهندسی
- بالا بردن
- افزایش
- کافی
- اطمینان حاصل شود
- علاقه مندان
- کاملا
- مثال
- مثال ها
- اجرا کردن
- منتظر
- توضیح دهید
- توضیح
- آشنا
- کمی از
- رشته
- نهایی
- سرانجام
- نام خانوادگی
- متمرکز شده است
- تمرکز
- پیروی
- برای
- مجبور
- به جلو
- دوست
- از جانب
- کامل
- خنده دار
- سوالات عمومی
- تولید می کنند
- دریافت کنید
- دادن
- داده
- می دهد
- Go
- هدف
- گلف
- خوب
- راهنمایی
- سخت
- بهره برداری
- آیا
- داشتن
- he
- اینجا کلیک نمایید
- با کیفیت بالا
- بالاتر
- او را
- خود را
- چگونه
- چگونه
- اما
- HTTPS
- انسان
- هوش انسانی
- i
- اندیشه
- if
- تصور کنید
- بهبود
- بهبود یافته
- بهبود
- بهبود
- in
- افزایش
- اطلاعات
- اول
- ورودی
- نمونه
- دستورالعمل
- یکپارچه
- اطلاعات
- در ارتباط بودن
- جالب
- به
- معرفی
- شامل
- IT
- ITS
- جان
- جان
- تنها
- kdnuggets
- نگاه داشتن
- پا زدن
- ضربات
- دانستن
- دانش
- می داند
- زبان
- نام
- دیر
- منجر می شود
- پرش
- یادگیری
- ترک
- ترک کرد
- کمتر
- اجازه
- اجازه دادن
- بهره برداری
- پسندیدن
- لینک
- کاهش
- شعبده بازي
- اصلی
- ساخت
- ساخت
- روش
- کتابچه راهنمای
- بسیاری
- تسلط
- ماده
- me
- به معنی
- روانی
- ادغام
- روش
- قدرت
- تحرک
- مدل
- مدل
- بیش
- اکثر
- متحرک
- چندگانه
- باید
- نیاز
- هرگز
- نه
- اکنون
- گرفتن
- of
- on
- یک بار
- مقابل
- بهینه سازی
- or
- دیگر
- دیگران
- ما
- خارج
- تولید
- خروجی
- خارج از
- خود
- مقاله
- بخش
- مسیر
- کامل
- انجام دادن
- کارایی
- فیزیک
- محوری
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازیکن
- نقطه
- پتانسیل
- تمرین
- دقیقا
- در حال حاضر
- زیبا
- قبلی
- مشکل
- مشکلات
- روند
- تولید کردن
- بهره وری
- ارائه
- ارائه
- کشیدن
- سوال
- کاملا
- محدوده
- نسبتا
- واقعی
- دلایل
- توصیه
- كاهش دادن
- اشاره دارد
- مربوط
- درخواست
- حالت ارتجاعی
- منابع فشرده
- منابع
- پاسخ دادن
- پاسخ
- پاسخ
- نتایج
- بازآموزی
- انقلاب
- راست
- اتاق
- s
- همان
- صرفه جویی کردن
- علم
- علم و تکنولوژی
- دانشمندان
- نمره
- دیدن
- ارسال
- در حال ارسال
- دنباله
- تنظیم
- چند
- نشان
- به طور قابل توجهی
- مهارت
- So
- فقط
- حل
- حل کردن
- برخی از
- کسی
- چیزی
- خاص
- صرف
- مراحل
- شروع
- شروع می شود
- هدایت کردن
- گام
- مراحل
- هنوز
- سبک
- مطمئن
- برخورد با
- صورت گرفته
- کار
- وظایف
- فن آوری
- تکنیک
- تکنیک
- پیشرفته
- گفتن
- مدت
- نسبت به
- که
- La
- آنها
- سپس
- آنجا.
- از این رو
- اینها
- آنها
- فکر می کنم
- تفکر
- این
- فکر
- از طریق
- بدین ترتیب
- زمان
- به
- TONE
- جمع
- کاملا
- قطار
- آموزش
- درخت
- سعی
- امتحان
- تلاش
- دو
- نهایی
- زیر
- تحت تاثیر قرار می گیرد
- فهمیدن
- درک
- بی شک
- us
- استفاده کنید
- استفاده
- با استفاده از
- تصدیق
- ارزشمند
- مختلف
- همه کاره
- بسیار
- می خواهم
- مسیر..
- راه
- we
- معروف
- بود
- چه زمانی
- که
- چرا
- اراده
- باد
- با
- در داخل
- بدون
- کلمه
- کارگر
- جهان
- اشتباه
- سال
- هنوز
- بازده
- شما
- شما
- زفیرنت







