تصویر توسط نویسنده
در این پست، مدل جدید منبع باز جدید به نام Mixtral 8x7b را بررسی خواهیم کرد. ما همچنین یاد خواهیم گرفت که چگونه با استفاده از کتابخانه LLaMA C++ به آن دسترسی داشته باشیم و چگونه مدل های زبانی بزرگ را با محاسبات و حافظه کم اجرا کنیم.
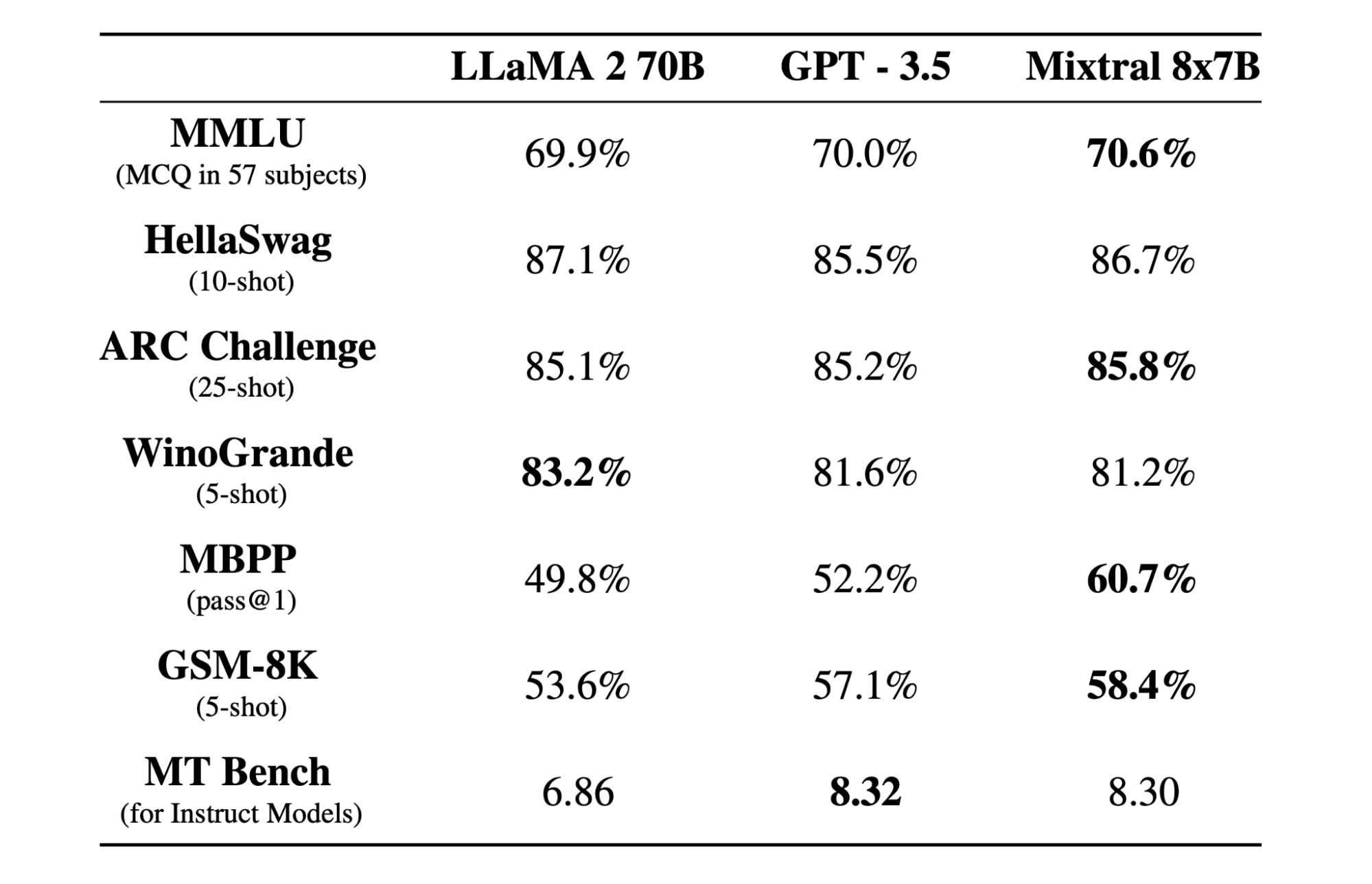
Mixtral 8x7b یک مدل باکیفیت پراکنده از کارشناسان (SMoE) با وزنه های باز است که توسط Mistral AI ایجاد شده است. تحت مجوز Apache 2.0 است و در اکثر معیارها بهتر از Llama 2 70B عمل می کند در حالی که استنتاج 6 برابر سریعتر دارد. Mixtral در اکثر معیارهای استاندارد با GPT3.5 مطابقت دارد یا میبیند و بهترین مدل وزن باز از نظر هزینه/عملکرد است.
تصویر از ترکیبی از متخصصان
Mixtral 8x7B از یک شبکه ترکیبی متخصصان که فقط دارای رمزگشا هستند استفاده می کند. این شامل یک بلوک پیشخور است که از بین 8 گروه پارامتر انتخاب میکند، با یک شبکه مسیریاب، دو تا از این گروهها را برای هر توکن انتخاب میکند و خروجیهای آنها را به صورت افزودنی ترکیب میکند. این روش ضمن مدیریت هزینه و تأخیر، تعداد پارامترهای مدل را افزایش میدهد و علیرغم داشتن 12.9 بایت پارامتر کل، آن را به اندازه یک مدل 46.7B کارآمد میکند.
مدل Mixtral 8x7B در مدیریت زمینه وسیعی از 32 هزار توکن عالی است و از چندین زبان از جمله انگلیسی، فرانسوی، ایتالیایی، آلمانی و اسپانیایی پشتیبانی میکند. این عملکرد قوی را در تولید کد نشان میدهد و میتوان آن را در یک مدل پیروی از دستورالعمل تنظیم کرد و در معیارهایی مانند MT-Bench به امتیازات بالایی دست یافت.
LLaMA.cpp یک کتابخانه C/C++ است که رابطی با کارایی بالا برای مدلهای زبان بزرگ (LLM) بر اساس معماری LLM فیسبوک ارائه میکند. این یک کتابخانه سبک وزن و کارآمد است که می تواند برای کارهای مختلف از جمله تولید متن، ترجمه و پاسخگویی به سؤالات استفاده شود. LLaMA.cpp از طیف گسترده ای از LLM ها، از جمله LLaMA، LLaMA 2، Falcon، Alpaca، Mistral 7B، Mixtral 8x7B و GPT4ALL پشتیبانی می کند. این با تمام سیستم عامل ها سازگار است و می تواند بر روی CPU و GPU کار کند.
در این بخش، برنامه وب llama.cpp را در Colab اجرا می کنیم. با نوشتن چند خط کد، میتوانید عملکرد جدید و پیشرفته مدل را در رایانه شخصی خود یا Google Colab تجربه کنید.
شروع شدن
ابتدا با استفاده از خط فرمان زیر، مخزن llama.cpp GitHub را دانلود می کنیم:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitپس از آن، دایرکتوری را به مخزن تغییر می دهیم و llama.cpp را با استفاده از دستور «make» نصب می کنیم. ما در حال نصب llama.cpp برای پردازنده گرافیکی NVidia با نصب CUDA هستیم.
%cd llama.cpp
!make LLAMA_CUBLAS=1مدل را دانلود کنید
می توانیم با انتخاب نسخه مناسب فایل مدل `.gguf` مدل را از Hugging Face Hub دانلود کنیم. اطلاعات بیشتر در مورد نسخه های مختلف را می توانید در اینجا پیدا کنید TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
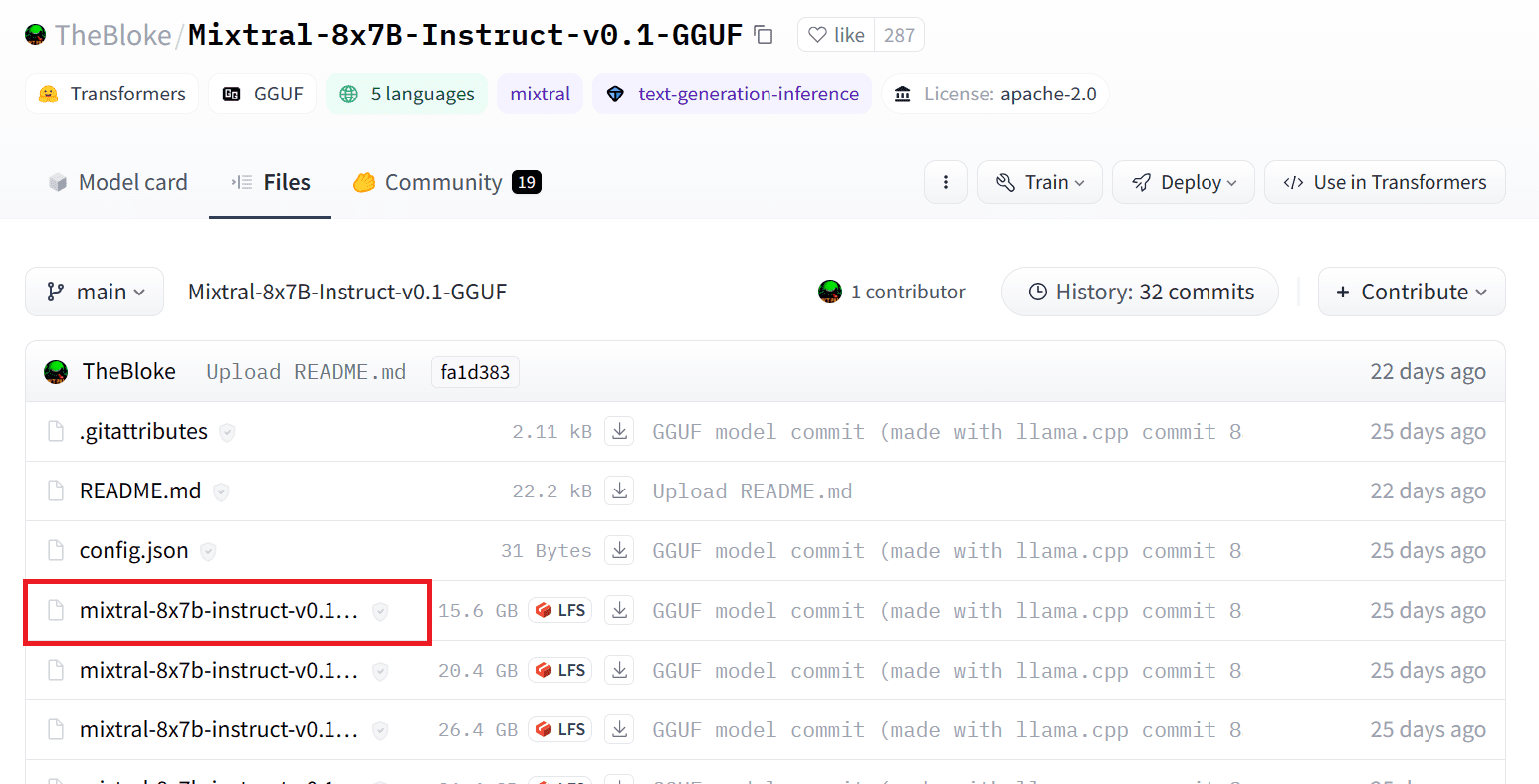
تصویر از TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
میتوانید از دستور wget برای دانلود مدل در فهرست فعلی استفاده کنید.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufآدرس خارجی سرور LLaMA
هنگامی که سرور LLaMA را اجرا می کنیم، یک IP لوکال هاست به ما می دهد که برای ما در Colab بی فایده است. ما نیاز به اتصال به پروکسی لوکال هاست با استفاده از پورت پروکسی کرنل Colab داریم.
پس از اجرای کد زیر، هایپرلینک جهانی را دریافت خواهید کرد. ما از این پیوند برای دسترسی به برنامه وب خود در آینده استفاده خواهیم کرد.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/در حال اجرا سرور
برای اجرای سرور LLaMA C++، باید دستور سرور را با محل فایل مدل و شماره پورت صحیح ارائه دهید. مهم است که مطمئن شوید شماره پورت با شماره ای که در مرحله قبل برای پورت پراکسی شروع کردیم مطابقت دارد.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
از آنجایی که سرور به صورت محلی اجرا نمی شود، می توان با کلیک بر روی پیوند پورت پروکسی در مرحله قبل به برنامه وب چت دسترسی داشت.
برنامه وب LLaMA C++
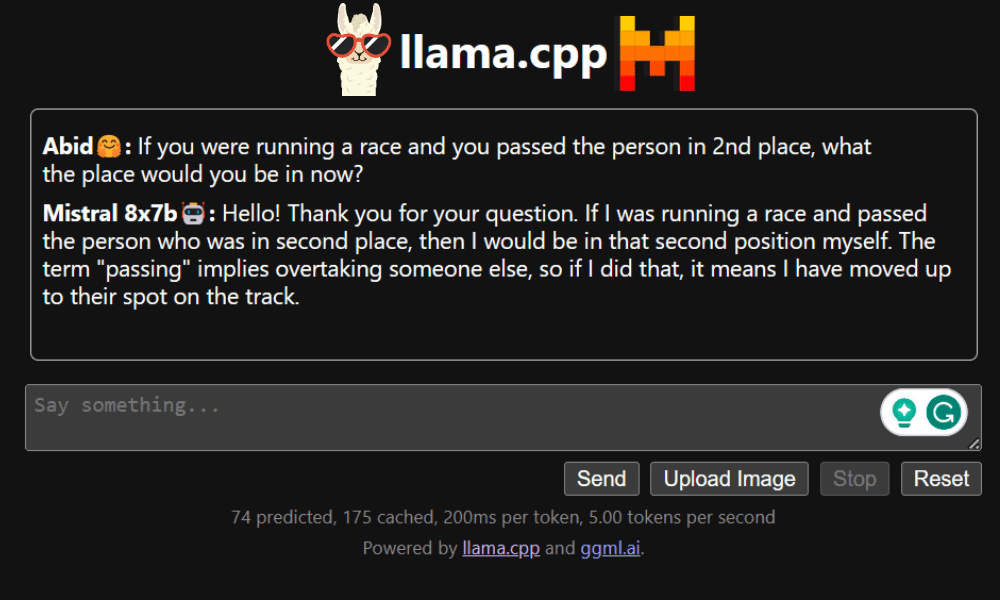
قبل از شروع استفاده از چت بات، باید آن را سفارشی کنیم. نام مدل خود را در قسمت prompt جایگزین «LLaMA» کنید. علاوه بر این، نام کاربری و نام ربات را تغییر دهید تا بین پاسخ های تولید شده تمایز قائل شوید.
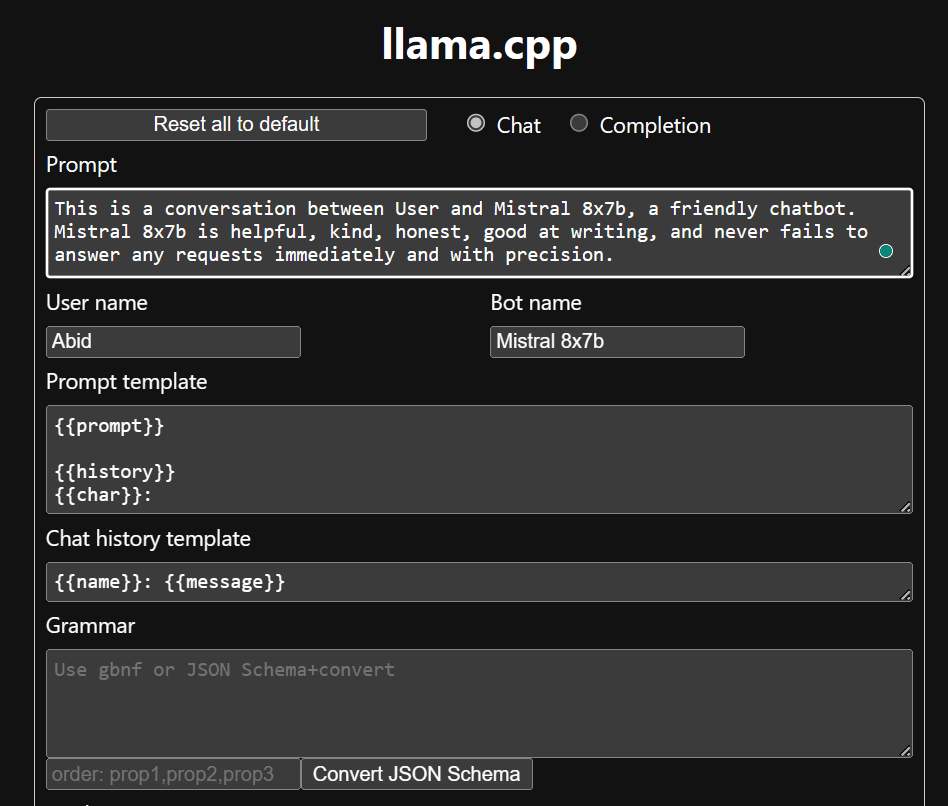
با اسکرول کردن به پایین و تایپ کردن در بخش چت، چت را شروع کنید. در صورت تمایل سوالات فنی بپرسید که سایر مدل های منبع باز نتوانسته اند به درستی به آنها پاسخ دهند.
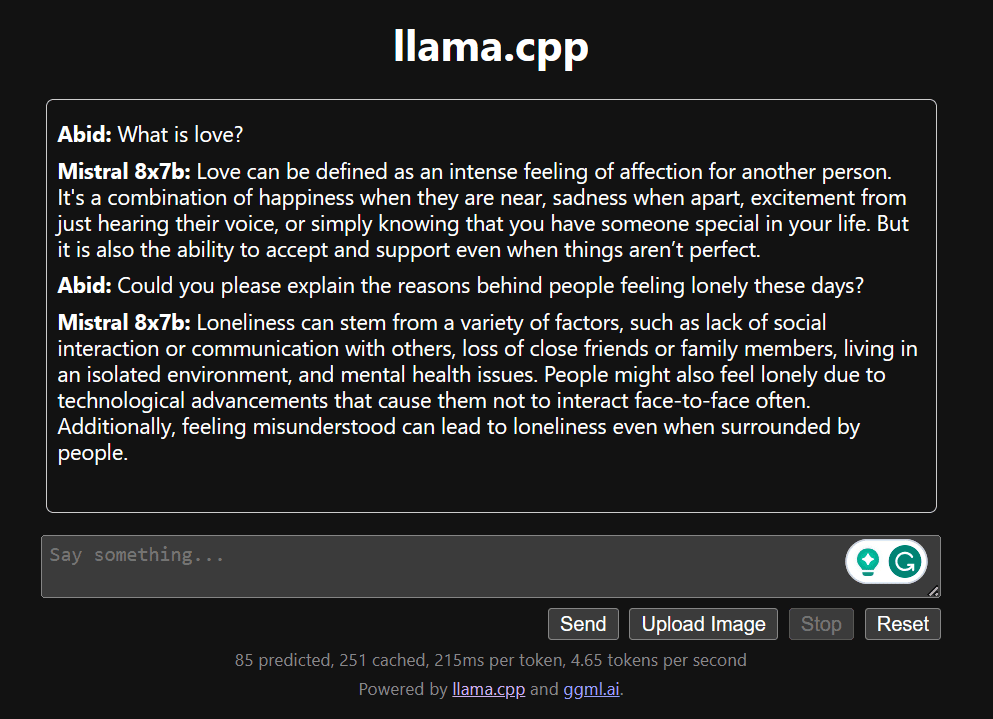
اگر با مشکلی در برنامه مواجه شدید، میتوانید آن را به تنهایی با استفاده از Google Colab من اجرا کنید: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
این آموزش راهنمای جامعی در مورد نحوه اجرای مدل متنباز پیشرفته Mixtral 8x7b در Google Colab با استفاده از کتابخانه LLaMA C++ ارائه میکند. در مقایسه با مدلهای دیگر، Mixtral 8x7b عملکرد و کارایی بالاتری ارائه میدهد، و آن را به یک راهحل عالی برای کسانی تبدیل میکند که میخواهند با مدلهای زبان بزرگ آزمایش کنند اما منابع محاسباتی گستردهای ندارند. شما به راحتی می توانید آن را بر روی لپ تاپ خود یا در یک محاسبات ابری رایگان اجرا کنید. کاربر پسند است و حتی می توانید برنامه چت خود را برای استفاده و آزمایش دیگران به کار ببرید.
امیدوارم این راه حل ساده برای اجرای مدل بزرگ برای شما مفید بوده باشد. من همیشه به دنبال گزینه های ساده و بهتر هستم. اگر راه حل بهتری دارید، لطفاً به من بگویید، دفعه بعد آن را پوشش خواهم داد.
عابد علی اعوان (@1abidaliawan) یک متخصص دانشمند داده معتبر است که عاشق ساخت مدل های یادگیری ماشینی است. در حال حاضر، او بر تولید محتوا و نوشتن وبلاگ های فنی در زمینه یادگیری ماشین و فناوری های علم داده تمرکز دارد. عابد دارای مدرک کارشناسی ارشد در رشته مدیریت فناوری و مدرک کارشناسی در رشته مهندسی مخابرات است. چشم انداز او ساخت یک محصول هوش مصنوعی با استفاده از یک شبکه عصبی نمودار برای دانش آموزانی است که با بیماری های روانی دست و پنجه نرم می کنند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :است
- :نه
- 1
- 12
- 27
- 46
- 7
- 8
- a
- قادر
- دسترسی
- قابل دسترسی است
- دستیابی به
- علاوه بر این
- نشانی
- پیشرفته
- AI
- معرفی
- همچنین
- همیشه
- am
- an
- و
- پاسخ
- آپاچی
- نرم افزار
- کاربرد
- مناسب
- معماری
- هستند
- AS
- پرسیدن
- مستقر
- BE
- شروع
- در زیر
- معیار
- بهترین
- بهتر
- میان
- مسدود کردن
- وبلاگ ها
- ربات
- هر دو
- ساختن
- بنا
- اما
- by
- ++C
- نام
- CAN
- مهندسان
- تغییر دادن
- گپ
- chatbot
- چت
- انتخاب
- ابر
- رمز
- ترکیب
- مقایسه
- سازگار
- جامع
- محاسباتی
- محاسبه
- محاسبه
- ارتباط
- محتوا
- تولید محتوا
- زمینه
- اصلاح
- هزینه
- پوشش
- ایجاد شده
- ایجاد
- جاری
- در حال حاضر
- سفارشی
- داده ها
- علم اطلاعات
- دانشمند داده
- درجه
- ارائه
- نشان می دهد
- گسترش
- با وجود
- تمیز دادن
- do
- پایین
- دانلود
- هر
- به آسانی
- بهره وری
- موثر
- رویارویی
- مهندسی
- انگلیسی
- افزایش می یابد
- حتی
- عالی
- تجربه
- تجربه
- کارشناسان
- اکتشاف
- وسیع
- چهره
- فیس بوک
- ناموفق
- شاهین
- سریعتر
- احساس
- کمی از
- پرونده
- تمرکز
- برای
- یافت
- رایگان
- فرانسوی
- از جانب
- تابع
- تولید
- نسل
- آلمانی
- دریافت کنید
- GitHub
- دادن
- جهانی
- گوگل
- GPU
- GPU ها
- گراف
- شبکه عصبی گراف
- گروه ها
- راهنمایی
- اداره
- آیا
- داشتن
- he
- مفید
- زیاد
- عملکرد بالا
- با کیفیت بالا
- خود را
- دارای
- امید
- چگونه
- چگونه
- HTTPS
- قطب
- i
- if
- بیماری
- واردات
- مهم
- in
- از جمله
- اطلاعات
- آغاز
- نصب
- نصب کردن
- رابط
- به
- شامل
- IP
- مسائل
- IT
- ایتالیایی
- kdnuggets
- دانستن
- زبان
- زبان ها
- لپ تاپ
- بزرگ
- تاخیر
- بعد
- یاد گرفتن
- یادگیری
- اجازه
- کتابخانه
- مجاز
- سبک وزن
- پسندیدن
- لاین
- خطوط
- ارتباط دادن
- لینک
- پشم لاما
- به صورت محلی
- محل
- به دنبال
- دوست دارد
- دستگاه
- فراگیری ماشین
- ساخت
- ساخت
- مدیریت
- مدیریت
- استاد
- کبریت
- me
- حافظه
- روانی
- بیماری روانی
- روش
- مخلوط
- مدل
- مدل
- تغییر
- بیش
- اکثر
- چندگانه
- my
- نام
- نیاز
- شبکه
- عصبی
- شبکه های عصبی
- جدید
- بعد
- عدد
- کارت گرافیک Nvidia
- of
- on
- ONE
- باز کن
- منبع باز
- عملیاتی
- سیستم های عامل
- گزینه
- or
- دیگر
- دیگران
- ما
- عملکرد بهتر
- تولید
- خروجی
- خود
- پارامتر
- پارامترهای
- PC
- کارایی
- افلاطون
- هوش داده افلاطون
- PlatoData
- لطفا
- پست
- قبلی
- محصول
- حرفه ای
- به درستی
- ارائه
- فراهم می کند
- پروکسی
- سوال
- سوالات
- محدوده
- کاهش
- با توجه
- جایگزین کردن
- مخزن
- تحقیق
- منابع
- پاسخ
- روتر
- دویدن
- در حال اجرا
- s
- علم
- دانشمند
- نمرات
- پیمایش
- بخش
- انتخاب
- سرور
- ساده
- پس از
- راه حل
- منبع
- اسپانیایی
- استاندارد
- وضعیت هنر
- گام
- قوی
- تلاش
- دانشجویان
- برتر
- پشتیبانی از
- مطمئن
- سیستم های
- وظایف
- فنی
- فن آوری
- پیشرفته
- ارتباط از راه دور
- متن
- تولید متن
- که
- La
- شان
- اینها
- این
- کسانی که
- زمان
- به
- رمز
- نشانه
- جمع
- ترجمه
- امتحان
- آموزش
- دو
- زیر
- us
- استفاده کنید
- استفاده
- کاربر
- کاربر پسند
- استفاده
- با استفاده از
- تنوع
- مختلف
- نسخه
- دید
- می خواهم
- we
- وب
- برنامه تحت وب
- که
- در حین
- WHO
- وسیع
- دامنه گسترده
- اراده
- با
- نوشته
- شما
- شما
- زفیرنت