نقاط پایانی چند مدلی (MMEs) یکی از ویژگی های قدرتمند است آمازون SageMaker طراحی شده برای ساده سازی استقرار و عملکرد مدل های یادگیری ماشین (ML). با MME، میتوانید چندین مدل را در یک ظرف سروینگ میزبانی کنید و همه مدلها را در پشت یک نقطه پایانی واحد میزبانی کنید. پلت فرم SageMaker به طور خودکار بارگیری و تخلیه مدل ها را مدیریت می کند و منابع مقیاس را بر اساس الگوهای ترافیکی مدیریت می کند و بار عملیاتی مدیریت تعداد زیادی از مدل ها را کاهش می دهد. این ویژگی به ویژه برای یادگیری عمیق و مدلهای هوش مصنوعی مولد که نیاز به محاسبات سریع دارند مفید است. صرفه جویی در هزینه به دست آمده از طریق به اشتراک گذاری منابع و مدیریت مدل ساده، SageMaker MME را به انتخابی عالی برای میزبانی مدل ها در مقیاس در AWS تبدیل می کند.
اخیراً برنامه های کاربردی هوش مصنوعی مولد توجه و تخیل گسترده ای را به خود جلب کرده اند. مشتریان میخواهند مدلهای هوش مصنوعی تولیدی را روی پردازندههای گرافیکی مستقر کنند، اما در عین حال از هزینهها آگاه هستند. SageMaker MME از نمونههای GPU پشتیبانی میکند و یک گزینه عالی برای این نوع برنامهها است. امروز، ما مشتاقیم که پشتیبانی TorchServe را برای MMEهای SageMaker اعلام کنیم. این مدل جدید پشتیبانی سرور به شما مزیت تمام مزایای MME را می دهد در حالی که هنوز از پشته سرویس استفاده می کنید که مشتریان TorchServe بیشتر با آن آشنا هستند. در این پست، نحوه میزبانی مدلهای هوش مصنوعی مولد، مانند Stable Diffusion و Segment Anything Model را در MMEهای SageMaker با استفاده از TorchServe نشان میدهیم و یک راهحل ویرایش با هدایت زبان ایجاد میکنیم که میتواند به هنرمندان و سازندگان محتوا کمک کند آثار هنری خود را سریعتر توسعه و تکرار کنند.
بررسی اجمالی راه حل
ویرایش مبتنی بر زبان یک مورد رایج استفاده از هوش مصنوعی مولد بین صنعتی است. این میتواند به هنرمندان و سازندگان محتوا کمک کند تا با خودکارسازی وظایف تکراری، بهینهسازی کمپینها، و ارائه تجربهای بیش از حد شخصیسازی شده برای مشتری نهایی، به طور مؤثرتری برای پاسخگویی به تقاضای محتوا کار کنند. کسبوکارها میتوانند از افزایش تولید محتوا، صرفهجویی در هزینه، بهبود شخصیسازی و افزایش تجربه مشتری بهره ببرند. در این پست، نشان میدهیم که چگونه میتوانید ویژگیهای ویرایش به کمک زبان را با استفاده از MME TorchServe بسازید که به شما امکان میدهد هر شی ناخواسته را از یک تصویر پاک کنید و با ارائه یک دستورالعمل متنی، هر شی را در یک تصویر تغییر دهید یا جایگزین کنید.
جریان تجربه کاربر برای هر مورد استفاده به شرح زیر است:
- برای حذف یک شی ناخواسته، شی را از تصویر انتخاب کنید تا برجسته شود. این عمل مختصات پیکسل و تصویر اصلی را به یک مدل هوش مصنوعی مولد می فرستد، که یک ماسک تقسیم بندی برای شی ایجاد می کند. پس از تایید انتخاب صحیح شی، می توانید تصاویر اصلی و ماسک را برای حذف به مدل دوم ارسال کنید. تصویر دقیق این جریان کاربر در زیر نشان داده شده است.
 |
 |
 |
|
مرحله 1: یک شی ("سگ") را از تصویر انتخاب کنید |
مرحله 2: تأیید کنید که شی درست برجسته شده است |
مرحله 3: پاک کردن شی از تصویر |
- برای تغییر یا جایگزینی یک شی، شی مورد نظر را انتخاب و برجسته کنید، همان فرآیندی که در بالا توضیح داده شد. هنگامی که انتخاب صحیح شی را تأیید کردید، می توانید با ارائه تصویر اصلی، ماسک و یک پیام متنی، شی را تغییر دهید. سپس مدل بر اساس دستورالعمل های ارائه شده، شی هایلایت شده را تغییر می دهد. تصویر دقیق این جریان کاربر دوم به شرح زیر است.
 |
 |
 |
|
مرحله 1: یک شی ("گلدان") را از تصویر انتخاب کنید |
مرحله 2: تأیید کنید که شی درست برجسته شده است |
مرحله 3: یک اعلان متنی ("گلدان آینده نگر") برای اصلاح شی ارائه دهید |
برای تقویت این راه حل، ما از سه مدل هوش مصنوعی مولد استفاده می کنیم: مدل Segment Anything (SAM)، مدل Inpainting Mask Large (LaMa) و Inpaint انتشار پایدار (SD). در اینجا نحوه استفاده از این مدل ها در گردش کار تجربه کاربر آمده است:
| برای حذف یک شی ناخواسته | برای تغییر یا جایگزینی یک شی |
 |
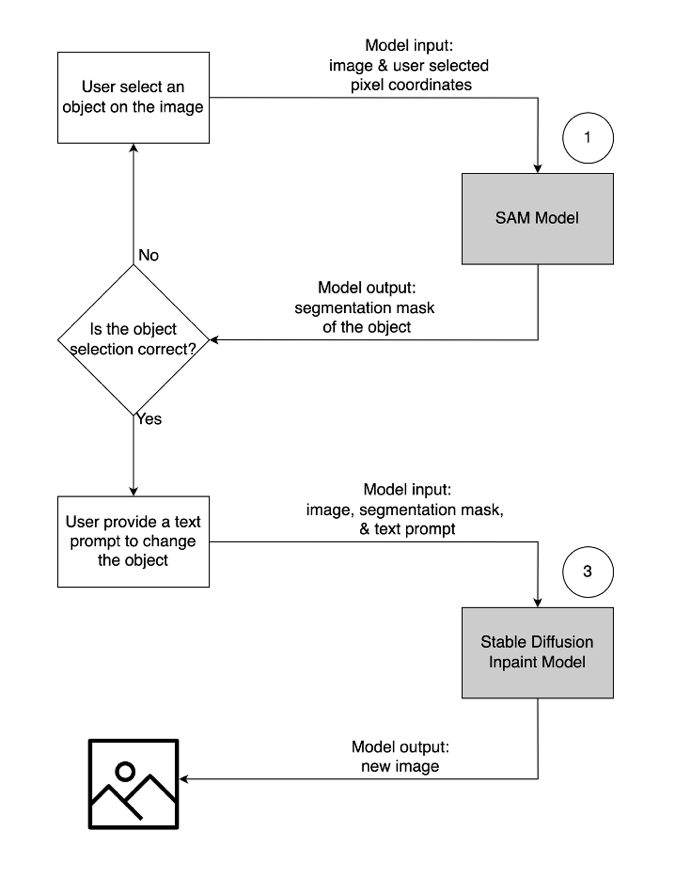 |
- Segment Anything Model (SAM) برای تولید یک ماسک قطعه از شی مورد نظر استفاده می شود. SAM که توسط Meta Research توسعه داده شده است، یک مدل منبع باز است که می تواند هر شی را در یک تصویر تقسیم بندی کند. این مدل بر روی یک مجموعه داده عظیم به نام SA-1B آموزش داده شده است که شامل بیش از 11 میلیون تصویر و 1.1 میلیارد ماسک تقسیمبندی است. برای اطلاعات بیشتر در مورد SAM به آنها مراجعه کنید سایت اینترنتی و مقاله تحقیقاتی.
- LaMa برای حذف هر گونه اشیاء نامطلوب از یک تصویر استفاده می شود. LaMa یک مدل شبکه متخاصم مولد (GAN) است که متخصص در پر کردن قسمتهای از دست رفته تصاویر با استفاده از ماسکهای نامنظم است. معماری مدل شامل زمینه جهانی گسترده تصویر و یک معماری تک مرحله ای است که از کانولوشن های فوریه استفاده می کند و آن را قادر می سازد تا به نتایج پیشرفته با سرعت بیشتری دست یابد. برای جزئیات بیشتر در مورد LaMa، به آنها مراجعه کنید سایت اینترنتی و مقاله تحقیقاتی.
- مدل inpaint SD 2 از Stability AI برای تغییر یا جایگزینی اشیا در یک تصویر استفاده می شود. این مدل به ما این امکان را می دهد که با ارائه یک پیام متنی، شی را در ناحیه ماسک ویرایش کنیم. مدل inpaint بر اساس مدل SD متن به تصویر است که می تواند تصاویر باکیفیت را با یک دستور متن ساده ایجاد کند. این آرگومان های اضافی مانند تصاویر اصلی و ماسک را ارائه می دهد که امکان اصلاح و بازیابی سریع محتوای موجود را فراهم می کند. برای کسب اطلاعات بیشتر در مورد مدل های انتشار پایدار در AWS، مراجعه کنید با مدلهای Stable Diffusion تصاویری با کیفیت بالا ایجاد کنید و با استفاده از آمازون SageMaker آنها را مقرون به صرفه به کار ببرید.
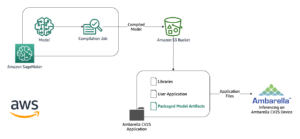
هر سه مدل در MME های SageMaker میزبانی می شوند که بار عملیاتی ناشی از مدیریت چندین نقطه پایانی را کاهش می دهد. علاوه بر آن، استفاده از MME نگرانیها را در مورد استفاده ناکافی از مدلهای خاص به دلیل اشتراک منابع برطرف میکند. شما می توانید مزایای بهبود اشباع نمونه را مشاهده کنید، که در نهایت منجر به صرفه جویی در هزینه می شود. نمودار معماری زیر نشان میدهد که چگونه هر سه مدل با استفاده از SageMaker MME با TorchServe ارائه میشوند.
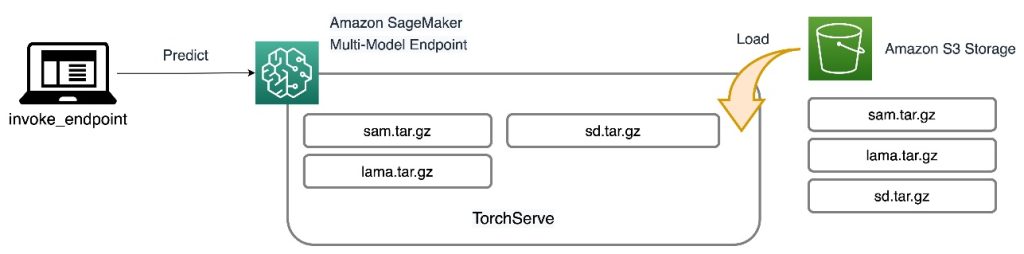
ما کد پیاده سازی این معماری راه حل را در خود منتشر کرده ایم مخزن GitHub. برای دنبال کردن ادامه مطلب از فایل نوت بوک استفاده کنید. توصیه می شود این مثال را روی یک نمونه نوت بوک SageMaker با استفاده از conda_python3 هسته (Python 3.10.10).
ظرف TorchServe را گسترش دهید
اولین قدم تهیه کانتینر هاست مدل است. SageMaker یک کانتینر یادگیری عمیق PyTorch (DLC) را ارائه می دهد که می توانید با استفاده از قطعه کد زیر آن را بازیابی کنید:
از آنجایی که مدل ها به منابع و بسته های اضافی نیاز دارند که در DLC پایه PyTorch نیستند، شما باید یک تصویر Docker بسازید. سپس این تصویر در آپلود می شود رجیستری ظروف الاستیک آمازون (Amazon ECR) تا بتوانیم مستقیماً از SageMaker به آن دسترسی داشته باشیم. کتابخانه های نصب شده سفارشی در فایل Docker فهرست شده اند:
برای ساختن تصویر سفارشی به صورت محلی، فایل فرمان پوسته را اجرا کنید و آن را به Amazon ECR فشار دهید:
مصنوعات مدل را آماده کنید
تفاوت اصلی MME های جدید با پشتیبانی TorchServe این است که چگونه مصنوعات مدل خود را آماده می کنید. مخزن کد یک پوشه اسکلت برای هر مدل (پوشه مدل ها) برای نگهداری فایل های مورد نیاز TorchServe فراهم می کند. برای آماده سازی هر مدل، همان فرآیند چهار مرحله ای را دنبال می کنیم .tar فایل. کد زیر نمونه ای از پوشه اسکلت برای مدل SD است:
اولین قدم این است که چک پوینت های مدل از پیش آموزش دیده را در پوشه مدل ها دانلود کنید:
مرحله بعدی تعریف الف است custom_handler.py فایل. این برای تعریف رفتار مدل در هنگام دریافت درخواست، مانند بارگذاری مدل، پیش پردازش ورودی و پس پردازش خروجی مورد نیاز است. را handle متد نقطه ورودی اصلی درخواست ها است و یک شی درخواست را می پذیرد و یک شی پاسخ را برمی گرداند. ایست های بازرسی مدل از پیش آموزش دیده را بارگذاری می کند و اعمال می کند preprocess و postprocess روش های داده های ورودی و خروجی قطعه کد زیر ساختار ساده ای را نشان می دهد custom_handler.py فایل. برای جزئیات بیشتر، به TorchServe handler API.
آخرین فایل مورد نیاز برای TorchServe است model-config.yaml. فایل پیکربندی سرور مدل، مانند تعداد کارگران و اندازه دسته ای را تعریف می کند. پیکربندی در سطح هر مدل است و نمونه فایل پیکربندی در کد زیر نشان داده شده است. برای لیست کامل پارامترها، به GitHub repo.
مرحله آخر این است که تمام مصنوعات مدل را در یک فایل .tar.gz با استفاده از بسته بندی کنید torch-model-archiver مدول:
نقطه پایانی چند مدلی را ایجاد کنید
مراحل ایجاد SageMaker MME مانند قبل است. در این مثال خاص، شما یک نقطه پایانی را با استفاده از SageMaker SDK می چرخانید. با تعریف یک شروع کنید سرویس ذخیره سازی ساده آمازون مکان (Amazon S3) و کانتینر میزبان. این مکان S3 جایی است که SageMaker به صورت پویا مدل ها را بر اساس الگوهای فراخوانی بارگذاری می کند. کانتینر میزبان، کانتینر سفارشی است که شما ساختید و در مرحله قبل به Amazon ECR فرستادید. کد زیر را ببینید:
سپس می خواهید a را تعریف کنید MulitDataModel که تمام ویژگیهایی مانند مکان مدل، ظرف میزبان و دسترسی به مجوز را میگیرد:
La deploy() تابع یک پیکربندی نقطه پایانی ایجاد می کند و نقطه پایانی را میزبانی می کند:
در مثالی که ارائه کردیم، همچنین نشان میدهیم که چگونه میتوانید مدلها را فهرست کنید و به صورت پویا مدلهای جدید را با استفاده از SDK اضافه کنید. را add_model() تابع مدل محلی شما را کپی می کند .tar فایل ها در مکان MME S3:
مدل ها را فراخوانی کنید
اکنون که هر سه مدل را روی MME میزبانی می کنیم، می توانیم هر مدل را به ترتیب برای ایجاد ویژگی های ویرایش به کمک زبان خود فراخوانی کنیم. برای فراخوانی هر مدل، a target_model پارامتر در predictor.predict() تابع. نام مدل فقط نام مدل است .tar فایلی که آپلود کردیم در زیر یک نمونه کد کد برای مدل SAM است که مختصات پیکسل، برچسب نقطه و اندازه هسته را گشاد میکند و ماسک تقسیمبندی شی را در محل پیکسل ایجاد میکند:
برای حذف یک شی ناخواسته از یک تصویر، ماسک تقسیمبندی تولید شده از SAM را بردارید و آن را با تصویر اصلی به مدل LaMa وارد کنید. تصاویر زیر نمونه ای را نشان می دهد.
 |
 |
|
|
تصویر نمونه |
ماسک تقسیم بندی از SAM |
سگ را با استفاده از LaMa پاک کنید |
برای تغییر یا جایگزینی هر شی در یک تصویر با یک اعلان متنی، ماسک تقسیم بندی را از SAM بگیرید و آن را با تصویر اصلی و پیام متنی به مدل SD وارد کنید، همانطور که در مثال زیر نشان داده شده است.
|
|
 |
|
تصویر نمونه |
ماسک تقسیم بندی از SAM |
با استفاده از مدل SD با اعلان متنی جایگزین کنید "همستر روی نیمکت" |
صرفه جویی در هزینه
مزایای SageMaker MME بر اساس مقیاس ادغام مدل افزایش می یابد. جدول زیر میزان استفاده از حافظه گرافیکی سه مدل در این پست را نشان می دهد. آنها بر روی یک مستقر شده اند g5.2xlarge به عنوان مثال با استفاده از یک SageMaker MME.
| مدل | حافظه GPU (MiB) |
| مدل هر چیزی را بخش بندی کنید | 3,362 |
| انتشار پایدار در رنگ | 3,910 |
| لاما | 852 |
هنگام میزبانی سه مدل با یک نقطه پایانی، می توانید صرفه جویی در هزینه را مشاهده کنید و برای موارد استفاده با صدها یا هزاران مدل، صرفه جویی بسیار بیشتر است.
به عنوان مثال، 100 مدل انتشار پایدار را در نظر بگیرید. هر یک از مدل ها به تنهایی می تواند توسط یک سرویس ارائه شود ml.g5.2xlarge نقطه پایانی (حافظه 4 گیگابایتی)، با هزینه 1.52 دلار به ازای هر ساعت در منطقه شرقی ایالات متحده (N. Virginia). برای ارائه تمام 100 مدل با استفاده از نقطه پایانی خود 218,880 دلار در ماه هزینه دارد. با SageMaker MME، یک نقطه پایانی واحد با استفاده از ml.g5.2xlarge نمونه ها می توانند چهار مدل را به طور همزمان میزبانی کنند. این هزینه های استنباط تولید را 75 درصد کاهش می دهد و به تنها 54,720 دلار در ماه می رسد. جدول زیر تفاوت بین نقاط پایانی تک مدلی و چند مدلی را برای این مثال خلاصه می کند. با توجه به پیکربندی نقطه پایانی با حافظه کافی برای مدلهای هدف شما، تأخیر فراخوانی حالت پایدار پس از بارگیری همه مدلها مشابه نقطه پایانی تک مدلی خواهد بود.
| . | نقطه پایانی تک مدلی | نقطه پایانی چند مدلی |
| قیمت کل نقطه پایانی در ماه | $218,880 | $54,720 |
| نوع نمونه نقطه پایانی | ml.g5.2xlarge | ml.g5.2xlarge |
| ظرفیت حافظه CPU (GiB) | 32 | 32 |
| ظرفیت حافظه GPU (GiB) | 24 | 24 |
| قیمت نقطه پایانی در ساعت | $1.52 | $1.52 |
| تعداد موارد در نقطه پایانی | 2 | 2 |
| نقاط پایانی مورد نیاز برای 100 مدل | 100 | 25 |
پاک کردن
پس از اتمام کار، لطفاً دستورالعملهای موجود در بخش پاکسازی نوتبوک را دنبال کنید تا منابع ارائه شده در این پست را حذف کنید تا از هزینههای غیرضروری جلوگیری کنید. رجوع شود به قیمت گذاری آمازون SageMaker برای جزئیات در مورد هزینه نمونه های استنتاج.
نتیجه
این پست قابلیتهای ویرایش به کمک زبان را نشان میدهد که از طریق استفاده از مدلهای هوش مصنوعی مولد میزبانی شده در SageMaker MME با TorchServe امکانپذیر شده است. مثالی که به اشتراک گذاشتیم نشان میدهد که چگونه میتوانیم از اشتراکگذاری منابع و مدیریت مدل سادهشده با MME SageMaker استفاده کنیم، در حالی که هنوز از TorchServe به عنوان پشته سرویسدهی مدل خود استفاده میکنیم. ما از سه مدل پایه یادگیری عمیق استفاده کردیم: SAM، SD 2 Inpainting و LaMa. این مدلها ما را قادر میسازند قابلیتهای قدرتمندی مانند پاک کردن هر شی ناخواسته از یک تصویر و تغییر یا جایگزینی هر شی در یک تصویر با ارائه یک دستورالعمل متنی ایجاد کنیم. این ویژگیها میتوانند به هنرمندان و سازندگان محتوا کمک کنند تا با خودکارسازی کارهای تکراری، بهینهسازی کمپینها و ارائه تجربهای بیش از حد شخصیشده، کارآمدتر کار کنند و خواستههای محتوای خود را برآورده کنند. ما از شما دعوت می کنیم که مثال ارائه شده در این پست را بررسی کنید و تجربه رابط کاربری خود را با استفاده از TorchServe در SageMaker MME بسازید.
برای شروع، ببینید الگوریتمها، چارچوبها و نمونههای پشتیبانی شده برای نقاط پایانی چند مدل با استفاده از نمونههای پشتیبانی شده توسط GPU.
درباره نویسندگان
 جیمز وو یک معمار ارشد راه حل متخصص AI/ML در AWS است. کمک به مشتریان در طراحی و ساخت راه حل های AI/ML. کار جیمز طیف گستردهای از موارد استفاده از ML را پوشش میدهد، با علاقه اولیه به بینایی رایانه، یادگیری عمیق، و مقیاسبندی ML در سراسر سازمان. قبل از پیوستن به AWS، جیمز بیش از 10 سال معمار، توسعهدهنده و رهبر فناوری بود، از جمله 6 سال در مهندسی و 4 سال در صنایع بازاریابی و تبلیغات.
جیمز وو یک معمار ارشد راه حل متخصص AI/ML در AWS است. کمک به مشتریان در طراحی و ساخت راه حل های AI/ML. کار جیمز طیف گستردهای از موارد استفاده از ML را پوشش میدهد، با علاقه اولیه به بینایی رایانه، یادگیری عمیق، و مقیاسبندی ML در سراسر سازمان. قبل از پیوستن به AWS، جیمز بیش از 10 سال معمار، توسعهدهنده و رهبر فناوری بود، از جمله 6 سال در مهندسی و 4 سال در صنایع بازاریابی و تبلیغات.
 لی نینگ یک مهندس نرم افزار ارشد در AWS با تخصص در ساخت راه حل های هوش مصنوعی در مقیاس بزرگ است. به عنوان یک رهبر فناوری برای TorchServe، پروژه ای که به طور مشترک توسط AWS و Meta توسعه یافته است، اشتیاق او در استفاده از PyTorch و AWS SageMaker برای کمک به مشتریان برای استقبال از هوش مصنوعی برای منافع بیشتر است. خارج از فعالیتهای حرفهایاش، لی از شنا کردن، مسافرت کردن، دنبال کردن آخرین پیشرفتهای فناوری و گذراندن زمان با کیفیت با خانوادهاش لذت میبرد.
لی نینگ یک مهندس نرم افزار ارشد در AWS با تخصص در ساخت راه حل های هوش مصنوعی در مقیاس بزرگ است. به عنوان یک رهبر فناوری برای TorchServe، پروژه ای که به طور مشترک توسط AWS و Meta توسعه یافته است، اشتیاق او در استفاده از PyTorch و AWS SageMaker برای کمک به مشتریان برای استقبال از هوش مصنوعی برای منافع بیشتر است. خارج از فعالیتهای حرفهایاش، لی از شنا کردن، مسافرت کردن، دنبال کردن آخرین پیشرفتهای فناوری و گذراندن زمان با کیفیت با خانوادهاش لذت میبرد.
 آنکیت گوناپال یک مهندس شریک هوش مصنوعی در Meta (PyTorch) است. او مشتاق بهینهسازی مدل و سرویسدهی مدل است، با تجربهای از تأیید RTL، نرمافزار تعبیهشده، بینایی رایانه تا PyTorch. او دارای مدرک کارشناسی ارشد در علوم داده و فوق لیسانس در مخابرات است. خارج از کار، Ankith همچنین یک تولید کننده موسیقی رقص الکترونیکی است.
آنکیت گوناپال یک مهندس شریک هوش مصنوعی در Meta (PyTorch) است. او مشتاق بهینهسازی مدل و سرویسدهی مدل است، با تجربهای از تأیید RTL، نرمافزار تعبیهشده، بینایی رایانه تا PyTorch. او دارای مدرک کارشناسی ارشد در علوم داده و فوق لیسانس در مخابرات است. خارج از کار، Ankith همچنین یک تولید کننده موسیقی رقص الکترونیکی است.
 ساوراب تریکاند مدیر محصول ارشد Amazon SageMaker Inference است. او مشتاق کار با مشتریان است و هدفش دموکراتیک کردن یادگیری ماشین است. او بر چالشهای اصلی مربوط به استقرار برنامههای کاربردی پیچیده ML، مدلهای ML چند مستاجر، بهینهسازی هزینهها و در دسترستر کردن استقرار مدلهای یادگیری عمیق تمرکز میکند. Saurabh در اوقات فراغت خود از پیاده روی، یادگیری در مورد فن آوری های نوآورانه، دنبال کردن TechCrunch و گذراندن وقت با خانواده خود لذت می برد.
ساوراب تریکاند مدیر محصول ارشد Amazon SageMaker Inference است. او مشتاق کار با مشتریان است و هدفش دموکراتیک کردن یادگیری ماشین است. او بر چالشهای اصلی مربوط به استقرار برنامههای کاربردی پیچیده ML، مدلهای ML چند مستاجر، بهینهسازی هزینهها و در دسترستر کردن استقرار مدلهای یادگیری عمیق تمرکز میکند. Saurabh در اوقات فراغت خود از پیاده روی، یادگیری در مورد فن آوری های نوآورانه، دنبال کردن TechCrunch و گذراندن وقت با خانواده خود لذت می برد.
 سابهاش تالوری معمار اصلی راه حل های AI/ML واحد تجاری صنعت مخابرات در خدمات وب آمازون است. او پیشرو در توسعه راه حل های خلاقانه AI/ML برای مشتریان و شرکای مخابراتی در سراسر جهان بوده است. او تخصص میان رشتهای را در مهندسی و علوم کامپیوتر به ارمغان میآورد تا به ساخت راهحلهای AI/ML مقیاسپذیر، ایمن و سازگار از طریق معماریهای بهینهسازی ابری در AWS کمک کند.
سابهاش تالوری معمار اصلی راه حل های AI/ML واحد تجاری صنعت مخابرات در خدمات وب آمازون است. او پیشرو در توسعه راه حل های خلاقانه AI/ML برای مشتریان و شرکای مخابراتی در سراسر جهان بوده است. او تخصص میان رشتهای را در مهندسی و علوم کامپیوتر به ارمغان میآورد تا به ساخت راهحلهای AI/ML مقیاسپذیر، ایمن و سازگار از طریق معماریهای بهینهسازی ابری در AWS کمک کند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. خودرو / خودروهای الکتریکی، کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- ChartPrime. بازی معاملاتی خود را با ChartPrime ارتقا دهید. دسترسی به اینجا.
- BlockOffsets. نوسازی مالکیت افست زیست محیطی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/run-multiple-generative-ai-models-on-gpu-using-amazon-sagemaker-multi-model-endpoints-with-torchserve-and-save-up-to-75-in-inference-costs/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 1
- 10
- 100
- 11
- 12
- 14
- ٪۱۰۰
- 19
- 200
- 28
- 300
- 500
- 52
- 7
- 8
- 9
- a
- درباره ما
- بالاتر
- شتاب دادن
- تسریع شد
- قبول می کند
- دسترسی
- در دسترس
- رسیدن
- دست
- در میان
- عمل
- اضافه کردن
- اضافه
- اضافی
- پیشرفت
- مزیت - فایده - سود - منفعت
- دشمن
- تبلیغات
- پس از
- AI
- مدل های هوش مصنوعی
- AI / ML
- الگوریتم
- معرفی
- اجازه دادن
- اجازه دادن
- اجازه می دهد تا
- در امتداد
- همچنین
- آمازون
- آمازون SageMaker
- آمازون خدمات وب
- an
- و
- اعلام
- هر
- هر چیزی
- API
- برنامه های کاربردی
- معماری
- هستند
- محدوده
- استدلال
- هنرمندان
- آثار هنری
- AS
- At
- توجه
- خواص
- بطور خودکار
- اتوماسیون
- اجتناب از
- AWS
- حمایت کرد
- پایه
- مستقر
- BE
- زیرا
- بوده
- قبل از
- پشت سر
- بودن
- در زیر
- مفید
- سود
- مزایای
- میان
- بیلیون
- به ارمغان می آورد
- ساختن
- بنا
- ساخته
- بار
- کسب و کار
- کسب و کار
- اما
- by
- مبارزات
- CAN
- قابلیت های
- ظرفیت
- اسیر
- جلب
- مورد
- موارد
- معین
- چالش ها
- تغییر دادن
- بار
- انتخاب
- رمز
- مشترک
- کامل
- پیچیده
- موافق
- شامل
- محاسبه
- کامپیوتر
- علم کامپیوتر
- چشم انداز کامپیوتر
- نگرانی ها
- پیکر بندی
- تکرار
- هوشیار
- در نظر بگیرید
- تثبیت
- ظرف
- محتوا
- سازندگان محتوا
- زمینه
- مختصات
- نسخه
- هسته
- اصلاح
- هزینه
- صرفه جویی در هزینه
- هزینه
- میتوانست
- را پوشش می دهد
- ایجاد
- ایجاد
- سازندگان
- سفارشی
- مشتری
- تجربه مشتری
- مشتریان
- رقص
- داده ها
- علم اطلاعات
- زمان قرار
- عمیق
- یادگیری عمیق
- تعريف كردن
- تعریف می کند
- تعریف کردن
- تقاضا
- خواسته
- دموکراتیک کردن
- نشان دادن
- نشان
- نشان می دهد
- گسترش
- مستقر
- استقرار
- گسترش
- شرح داده شده
- طرح
- طراحی
- مطلوب
- جزئیات
- دقیق
- جزئیات
- توسعه
- توسعه
- توسعه دهنده
- پروژه
- تفاوت
- تفاوت
- انتشار
- مستقیما
- کارگر بارانداز
- سگ
- انجام شده
- دانلود
- بطور پویا
- هر
- پیش از آن
- شرق
- ویرایش
- موثر
- الکترونیکی
- حذف می شود
- جاسازی شده
- در اغوش گرفتن
- قادر ساختن
- را قادر می سازد
- پایان
- تلاش می کند
- نقطه پایانی
- نقاط پایان
- مهندس
- مهندسی
- افزایش
- سرمایه گذاری
- ورود
- اتر (ETH)
- مثال
- عالی
- برانگیخته
- موجود
- تجربه
- تخصص
- اکتشاف
- آشنا
- خانواده
- سریعتر
- ویژگی
- امکانات
- پرونده
- فایل ها
- پر کردن
- نهایی
- نام خانوادگی
- جریان
- تمرکز
- به دنبال
- پیروی
- به دنبال آن است
- برای
- پایه
- چهار
- چارچوب
- از جانب
- تابع
- تولید می کنند
- تولید
- تولید می کند
- مولد
- هوش مصنوعی مولد
- دریافت کنید
- GitHub
- داده
- می دهد
- جهانی
- زمینه جهانی
- هدف
- خوب
- GPU
- GPU ها
- بزرگ
- بیشتر
- همستر
- آیا
- he
- کمک
- کمک
- او
- اینجا کلیک نمایید
- با کیفیت بالا
- نماد
- برجسته
- پیاده روی
- خود را
- دارای
- میزبان
- میزبانی
- میزبانی وب
- میزبان
- ساعت
- خانه
- چگونه
- چگونه
- HTTP
- HTTPS
- صدها نفر
- نشان می دهد
- تصویر
- تصاویر
- خیال پردازی
- انجام
- واردات
- بهبود یافته
- in
- از جمله
- شامل
- افزایش
- افزایش
- لوازم
- صنعت
- اطلاعات
- ابتکاری
- فن آوری های نوآورانه
- ورودی
- نصب
- نمونه
- دستورالعمل
- علاقه
- به
- دعوت
- IT
- ITS
- جیمز
- پیوستن
- JPG
- json
- تنها
- شناخته شده
- برچسب
- بزرگ
- در مقیاس بزرگ
- نام
- تاخیر
- آخرین
- رهبری
- رهبر
- برجسته
- منجر می شود
- یاد گرفتن
- یادگیری
- سطح
- بهره برداری
- li
- کتابخانه ها
- نهفته است
- پسندیدن
- فهرست
- ذکر شده
- بار
- بارگیری
- بارهای
- محلی
- به صورت محلی
- محل
- دستگاه
- فراگیری ماشین
- ساخته
- اصلی
- باعث می شود
- ساخت
- اداره می شود
- مدیریت
- مدیر
- مدیریت می کند
- مدیریت
- بازار یابی (Marketing)
- بازاریابی و تبلیغات
- ماسک
- ماسک
- عظیم
- کارشناسی ارشد
- ماتپلوتلب
- دیدار
- حافظه
- متا
- متا تحقیق
- روش
- روش
- میلیون
- گم
- ML
- مدل
- مدل
- تغییر
- واحد
- ماه
- بیش
- اکثر
- انگیزه
- بسیار
- چندگانه
- موسیقی
- نام
- نیاز
- ضروری
- شبکه
- جدید
- بعد
- هیچ
- دفتر یادداشت
- عدد
- هدف
- اشیاء
- مشاهده کردن
- of
- on
- یک بار
- ONE
- فقط
- منبع باز
- عمل
- قابل استفاده
- بهینه سازی
- بهینه سازی
- گزینه
- or
- اصلی
- ما
- تولید
- خارج از
- روی
- خود
- بسته
- بسته
- پارامتر
- پارامترهای
- ویژه
- ویژه
- شریک
- شرکای
- بخش
- شور
- احساساتی
- الگوهای
- برای
- اجازه
- شخصی
- خط لوله
- پیکسل
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- لطفا
- نقطه
- ممکن
- پست
- قدرت
- قوی
- پیشگو
- آماده
- قیمت
- اصلی
- قبلا
- روند
- تهيه كننده
- محصول
- مدیر تولید
- تولید
- حرفه ای
- پروژه
- ارائه
- ارائه
- فراهم می کند
- ارائه
- منتشر شده
- فشار
- تحت فشار قرار دادند
- پــایتــون
- مارماهی
- کیفیت
- مقدار
- سریع
- محدوده
- اعم
- خواندن
- دریافت
- توصیه می شود
- را کاهش می دهد
- کاهش
- منطقه
- مربوط
- برداشت
- برداشتن
- تکراری
- جایگزین کردن
- درخواست
- درخواست
- نیاز
- ضروری
- تحقیق
- منابع
- منابع
- پاسخ
- پاسخ
- REST
- ترمیم
- نتایج
- برگشت
- بازده
- RGB
- دویدن
- حکیم ساز
- استنباط SageMaker
- سام
- همان
- ذخیره
- پس انداز
- مقیاس پذیر
- مقیاس
- مقیاس ها
- مقیاس گذاری
- علم
- SD
- sdk
- دوم
- بخش
- امن
- دیدن
- بخش
- تقسیم بندی
- انتخاب
- خود
- ارسال
- می فرستد
- ارشد
- دنباله
- خدمات
- خدمت
- به اشتراک گذاشته شده
- اشتراک
- صدف
- نشان
- نشان داده شده
- نشان می دهد
- مشابه
- ساده
- ساده شده
- ساده کردن
- به طور همزمان
- تنها
- اندازه
- قطعه
- So
- نرم افزار
- مهندس نرمافزار
- راه حل
- مزایا
- متخصص
- تخصص دارد
- سرعت
- هزینه
- چرخش
- ثبات
- پایدار
- پشته
- شروع
- آغاز شده
- دولت
- وضعیت هنر
- ثابت
- گام
- مراحل
- هنوز
- ذخیره سازی
- ساختار
- چنین
- کافی
- تهیه
- پشتیبانی
- شنا
- جدول
- گرفتن
- طول می کشد
- هدف
- وظایف
- فن آوری
- TechCrunch
- فن آوری
- پیشرفته
- مخابراتی
- ارتباط از راه دور
- جریان تنسور
- متن
- که
- La
- شان
- آنها
- سپس
- اینها
- آنها
- این
- هزاران نفر
- سه
- از طریق
- زمان
- به
- امروز
- مشعل
- ترافیک
- آموزش دیده
- ترانسفورماتور
- سفر
- انواع
- ui
- در نهایت
- واحد
- ناخواسته
- آپلود شده
- us
- استفاده
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- سابقه کاربر
- استفاده
- با استفاده از
- استفاده
- با استفاده از
- تایید
- از طريق
- ویرجینیا
- دید
- بازدید
- می خواهم
- بود
- we
- وب
- خدمات وب
- چه زمانی
- که
- در حین
- وسیع
- دامنه گسترده
- بطور گسترده
- اراده
- با
- مهاجرت کاری
- کارگران
- گردش کار
- کارگر
- در سرتاسر جهان
- خواهد بود
- سال
- شما
- شما
- زفیرنت