در این پست، نحوه استفاده از هرس ساختاری مبتنی بر جستجوی معماری عصبی (NAS) برای فشردهسازی یک مدل BERT تنظیمشده برای بهبود عملکرد مدل و کاهش زمان استنتاج را نشان میدهیم. مدلهای زبانی از پیش آموزشدیده (PLM) در حوزههای ابزارهای بهرهوری، خدمات مشتری، جستجو و توصیهها، اتوماسیون فرآیند کسبوکار و ایجاد محتوا به سرعت در حال پذیرش تجاری و سازمانی هستند. استقرار نقاط پایانی استنتاج PLM معمولاً با تأخیر بالاتر و هزینههای زیرساخت بالاتر به دلیل نیازهای محاسباتی و کاهش کارایی محاسباتی به دلیل تعداد زیاد پارامترها همراه است. هرس کردن یک PLM اندازه و پیچیدگی مدل را کاهش می دهد و در عین حال قابلیت های پیش بینی آن را حفظ می کند. PLM های هرس شده به ردپای حافظه کمتر و تاخیر کمتری دست می یابند. ما نشان میدهیم که با هرس کردن یک PLM و مبادله کردن خطای شمارش پارامتر و اعتبارسنجی برای یک کار هدف خاص، و قادر به دستیابی به زمانهای پاسخ سریعتر در مقایسه با مدل پایه PLM هستیم.
بهینهسازی چند هدفه حوزهای از تصمیمگیری است که بیش از یک تابع هدف مانند مصرف حافظه، زمان آموزش و منابع محاسباتی را برای بهینهسازی همزمان بهینه میکند. هرس ساختاری تکنیکی است برای کاهش اندازه و الزامات محاسباتی PLM با هرس کردن لایهها یا نورونها/گرهها و در عین حال تلاش برای حفظ دقت مدل. با حذف لایهها، هرس ساختاری به نرخهای فشردهسازی بالاتری دست مییابد، که منجر به پراکندگی ساختاری سازگار با سختافزار میشود که زمان اجرا و زمان پاسخ را کاهش میدهد. استفاده از یک تکنیک هرس ساختاری در یک مدل PLM منجر به مدلی با وزن سبکتر با ردپای حافظه کمتری میشود که وقتی به عنوان نقطه پایانی استنتاج در SageMaker میزبانی میشود، در مقایسه با PLM تنظیمشده اولیه، کارایی منابع بهبود یافته و هزینه کاهش مییابد.
مفاهیم نشاندادهشده در این پست را میتوان برای برنامههایی که از ویژگیهای PLM استفاده میکنند، مانند سیستمهای توصیه، تجزیه و تحلیل احساسات و موتورهای جستجو اعمال کرد. به طور خاص، اگر تیمهای یادگیری ماشین (ML) و علم داده اختصاصی دارید که مدلهای PLM خود را با استفاده از مجموعه دادههای دامنه خاص تنظیم میکنند و تعداد زیادی نقطه پایانی استنتاج را با استفاده از آنها به کار میگیرند، میتوانید از این رویکرد استفاده کنید. آمازون SageMaker. یک مثال، یک خردهفروش آنلاین است که تعداد زیادی نقطه پایانی استنتاج را برای خلاصهسازی متن، طبقهبندی کاتالوگ محصول و طبقهبندی احساسات بازخورد محصول به کار میگیرد. مثال دیگر ممکن است ارائهدهنده مراقبتهای بهداشتی باشد که از نقاط پایانی استنتاج PLM برای طبقهبندی اسناد بالینی، شناسایی موجودیت نامگذاری شده از گزارشهای پزشکی، چت رباتهای پزشکی و طبقهبندی ریسک بیمار استفاده میکند.
بررسی اجمالی راه حل
در این بخش، گردش کار کلی را ارائه کرده و رویکرد را توضیح می دهیم. ابتدا از an استفاده می کنیم Amazon SageMaker Studio دفتر یادداشت برای تنظیم دقیق یک مدل BERT از پیش آموزش دیده در یک کار هدف با استفاده از مجموعه داده های دامنه خاص. برت (نمایش رمزگذار دوطرفه از ترانسفورماتورها) یک مدل زبان از پیش آموزش دیده بر اساس معماری ترانسفورماتور برای وظایف پردازش زبان طبیعی (NLP) استفاده می شود. جستجوی معماری عصبی (NAS) رویکردی برای خودکارسازی طراحی شبکههای عصبی مصنوعی است و ارتباط نزدیکی با بهینهسازی فراپارامتر دارد، رویکردی که به طور گسترده در زمینه یادگیری ماشین مورد استفاده قرار میگیرد. هدف NAS یافتن معماری بهینه برای یک مسئله معین با جستجو در مجموعه بزرگی از معماریهای کاندید با استفاده از تکنیکهایی مانند بهینهسازی بدون گرادیان یا با بهینهسازی معیارهای مورد نظر است. عملکرد معماری معمولاً با استفاده از معیارهایی مانند از دست دادن اعتبارسنجی اندازه گیری می شود. تنظیم خودکار مدل SageMaker (AMT) فرآیند خسته کننده و پیچیده یافتن ترکیب های بهینه ابرپارامترهای مدل ML را خودکار می کند که بهترین عملکرد مدل را به همراه دارد. AMT از الگوریتم های جستجوی هوشمند و ارزیابی های تکراری با استفاده از طیف وسیعی از فراپارامترهایی که شما مشخص می کنید استفاده می کند. مقادیر فراپارامتر را انتخاب می کند که مدلی را ایجاد می کند که بهترین عملکرد را دارد، همانطور که با معیارهای عملکرد مانند دقت و امتیاز F-1 اندازه گیری می شود.
رویکرد تنظیم دقیق توضیح داده شده در این پست عمومی است و می تواند برای هر مجموعه داده مبتنی بر متن اعمال شود. وظیفه تعیین شده به BERT PLM می تواند یک کار مبتنی بر متن مانند تجزیه و تحلیل احساسات، طبقه بندی متن یا پرسش و پاسخ باشد. در این نسخه نمایشی، وظیفه هدف یک مسئله طبقهبندی باینری است که در آن BERT برای شناسایی، از مجموعه دادهای که از مجموعهای از جفت قطعات متنی تشکیل شده است، استفاده میشود، که آیا میتوان معنای یک قطعه متن را از قطعه دیگر استنباط کرد یا خیر. ما استفاده می کنیم شناسایی مجموعه داده های متنی از مجموعه معیارهای GLUE. ما یک جستجوی چند هدفه را با استفاده از SageMaker AMT انجام میدهیم تا شبکههای فرعی را شناسایی کنیم که مبادلات بهینه را بین شمارش پارامترها و دقت پیشبینی برای کار هدف ارائه میدهند. هنگام انجام یک جستجوی چند هدفه، با تعریف دقت و شمارش پارامترها به عنوان اهدافی که قصد بهینه سازی آنها را داریم شروع می کنیم.
در شبکه BERT PLM، میتوان شبکههای فرعی مدولار و مستقلی وجود داشت که به مدل اجازه میدهد قابلیتهای تخصصی مانند درک زبان و نمایش دانش را داشته باشد. BERT PLM از یک شبکه فرعی خود توجهی چند سر و یک شبکه فرعی فید فوروارد استفاده می کند. یک لایه چند سر و خودتوجه به BERT اجازه میدهد تا موقعیتهای مختلف یک دنباله را به منظور محاسبه نمایشی از دنباله با اجازه دادن به سرهای متعدد برای توجه به سیگنالهای زمینه متعدد، مرتبط کند. ورودی به چندین زیرفضا تقسیم می شود و توجه به خود به طور جداگانه به هر یک از زیرفضاها اعمال می شود. سرهای متعدد در یک ترانسفورماتور PLM به مدل اجازه می دهد تا به طور مشترک به اطلاعات از زیرفضاهای نمایشی مختلف توجه کند. یک شبکه فرعی فید فوروارد یک شبکه عصبی ساده است که خروجی را از زیرشبکه خودتوجهی چند سر می گیرد، داده ها را پردازش می کند و نمایش های رمزگذار نهایی را برمی گرداند.
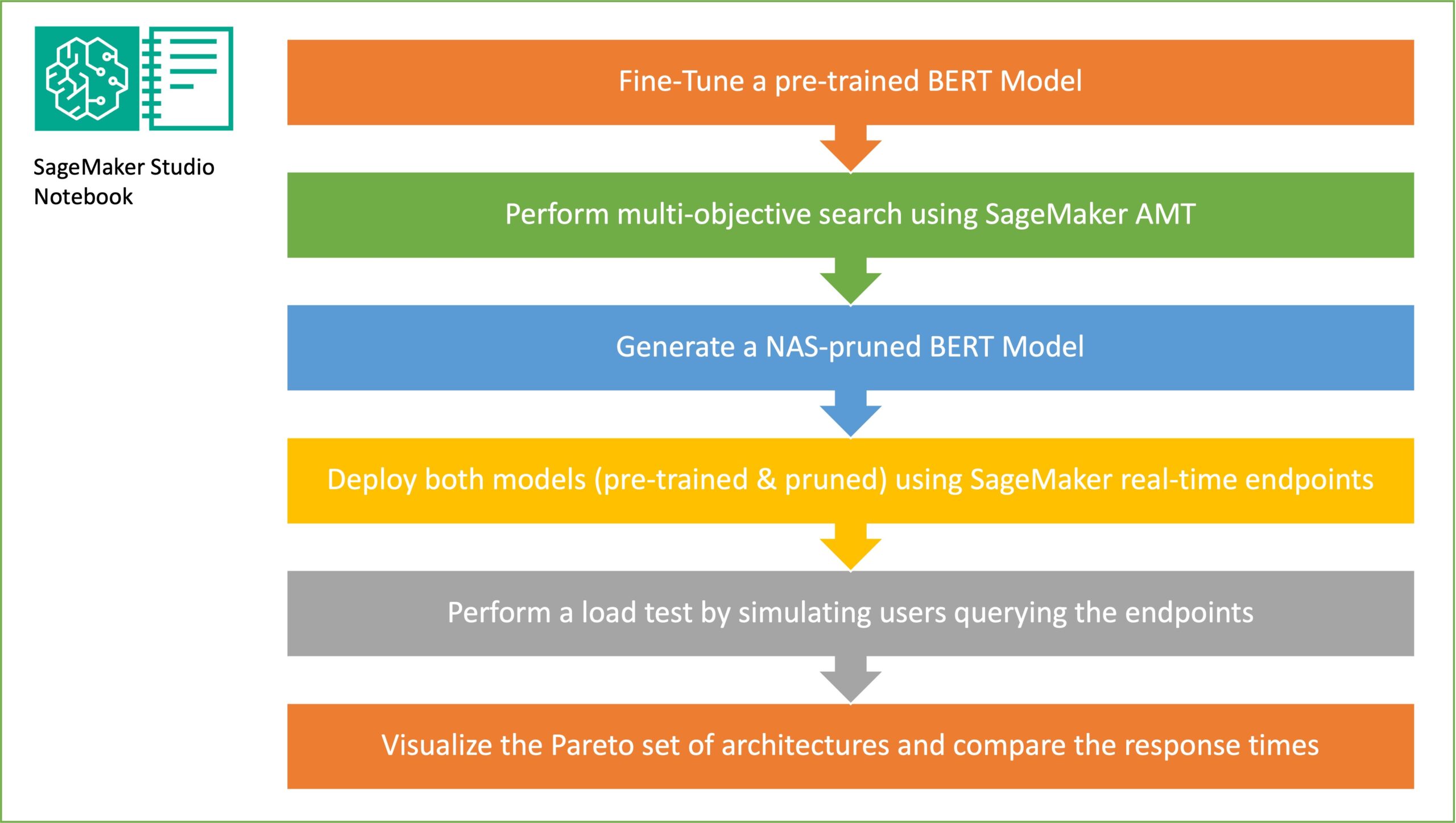
هدف از نمونهگیری تصادفی زیرشبکه، آموزش مدلهای BERT کوچکتر است که میتوانند به اندازه کافی در وظایف هدف خوب عمل کنند. ما 100 شبکه فرعی تصادفی را از مدل BERT پایه تنظیم شده نمونه برداری می کنیم و 10 شبکه را به طور همزمان ارزیابی می کنیم. شبکههای فرعی آموزشدیده برای معیارهای هدف ارزیابی میشوند و مدل نهایی بر اساس مبادلات موجود بین معیارهای هدف انتخاب میشود. ما تجسم می کنیم جلو پارتو برای زیرشبکه های نمونه برداری شده، که شامل مدل هرس شده است که مبادله بهینه بین دقت مدل و اندازه مدل را ارائه می دهد. ما زیرشبکه نامزد (مدل BERT هرس شده NAS) را بر اساس اندازه مدل و دقت مدل انتخاب می کنیم که مایل به معاوضه هستیم. در مرحله بعد، نقاط پایانی، مدل پایه BERT از پیش آموزش دیده، و مدل BERT هرس شده NAS را با استفاده از SageMaker میزبانی می کنیم. برای انجام تست بار استفاده می کنیم ملخ، یک ابزار تست بار منبع باز است که می توانید با استفاده از پایتون پیاده سازی کنید. ما تست بار را روی هر دو نقطه پایانی با استفاده از Locust اجرا می کنیم و نتایج را با استفاده از جلوی پارتو تجسم می کنیم تا مبادله بین زمان پاسخ و دقت را برای هر دو مدل نشان دهیم. نمودار زیر نمای کلی از گردش کار توضیح داده شده در این پست را ارائه می دهد.
پیش نیازها
برای این پست، پیش نیازهای زیر مورد نیاز است:
همچنین باید میزان را افزایش دهید سهمیه خدمات برای دسترسی به حداقل سه نمونه از نمونه های ml.g4dn.xlarge در SageMaker. نوع نمونه ml.g4dn.xlarge نمونه GPU مقرون به صرفه ای است که به شما اجازه می دهد PyTorch را به صورت بومی اجرا کنید. برای افزایش سهمیه خدمات مراحل زیر را انجام دهید:
- در کنسول، به سرویس Quotas بروید.
- برای مدیریت سهمیه ها، انتخاب کنید آمازون SageMaker، پس از آن را انتخاب کنید مشاهده سهمیه ها.

- «ml-g4dn.xlarge for training job use» را جستجو کنید و مورد سهمیه را انتخاب کنید.
- را انتخاب کنید درخواست افزایش در سطح حساب.
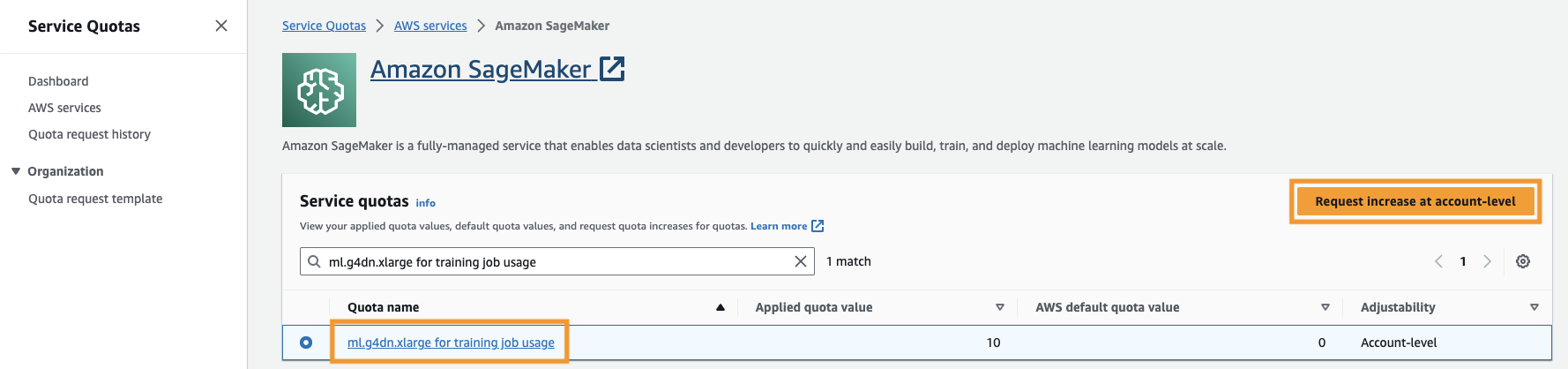
- برای افزایش مقدار سهمیه، مقدار 5 یا بالاتر را وارد کنید.
- را انتخاب کنید درخواست.
بسته به مجوزهای حساب، تأیید سهمیه درخواستی ممکن است مدتی طول بکشد.

- SageMaker Studio را از کنسول SageMaker باز کنید.

- را انتخاب کنید ترمینال سیستم زیر ابزارها و فایل ها.

- دستور زیر را برای کلون کردن اجرا کنید GitHub repo به نمونه SageMaker Studio:
- هدایت به
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - باز کردن فایل
nas_for_llm_with_amt.ipynb. - محیط را با یک تنظیم کنید
ml.g4dn.xlargeنمونه و انتخاب کنید انتخاب کنید.

مدل BERT از پیش آموزش دیده را تنظیم کنید
در این بخش، مجموعه داده Recognizing Textual Entailment را از مجموعه داده وارد می کنیم و مجموعه داده را به مجموعه های آموزشی و اعتبار سنجی تقسیم می کنیم. این مجموعه داده از جفت جمله تشکیل شده است. وظیفه BERT PLM این است که با توجه به دو قطعه متن تشخیص دهد که آیا می توان معنای یک قطعه متن را از قطعه دیگر استنباط کرد یا خیر. در مثال زیر می توان معنای عبارت اول را از عبارت دوم استنباط کرد:
ما مجموعه داده مستلزم شناسایی متنی را از قسمت بارگیری می کنیم GLUE مجموعه محک از طریق کتابخانه مجموعه داده از Hugging Face در اسکریپت آموزشی ما (./training.py). ما مجموعه داده آموزشی اصلی را از GLUE به یک مجموعه آموزشی و اعتبار سنجی تقسیم کردیم. در رویکرد خود، مدل BERT پایه را با استفاده از مجموعه داده آموزشی تنظیم میکنیم، سپس یک جستجوی چند هدفه را برای شناسایی مجموعهای از شبکههای فرعی انجام میدهیم که به طور بهینه بین معیارهای هدف تعادل برقرار میکنند. ما از مجموعه داده آموزشی منحصراً برای تنظیم دقیق مدل BERT استفاده می کنیم. با این حال، ما از دادههای اعتبارسنجی برای جستجوی چند هدفه با اندازهگیری دقت در مجموعه داده اعتبارسنجی نگهدارنده استفاده میکنیم.
BERT PLM را با استفاده از یک مجموعه داده خاص دامنه تنظیم کنید
موارد استفاده معمول برای یک مدل BERT خام شامل پیشبینی جمله بعدی یا مدلسازی زبان پوشانده است. برای استفاده از مدل BERT پایه برای کارهای پایین دستی مانند شناسایی مستلزم متنی، باید مدل را با استفاده از یک مجموعه داده خاص دامنه، بیشتر تنظیم کنیم. میتوانید از مدل BERT تنظیمشده برای کارهایی مانند طبقهبندی توالی، پاسخگویی به سؤال و طبقهبندی نشانهها استفاده کنید. با این حال، برای اهداف این نسخه ی نمایشی، ما از مدل دقیق تنظیم شده برای طبقه بندی باینری استفاده می کنیم. ما مدل BERT از پیش آموزش دیده را با مجموعه داده آموزشی که قبلاً آماده کرده بودیم، با استفاده از فراپارامترهای زیر تنظیم می کنیم:
چک پوینت آموزش مدل را در یک ذخیره می کنیم سرویس ذخیره سازی ساده آمازون (Amazon S3) سطل، به طوری که مدل می تواند در طول جستجوی چند هدفه مبتنی بر NAS بارگذاری شود. قبل از آموزش مدل، معیارهایی مانند دوره، از دست دادن آموزش، تعداد پارامترها و خطای اعتبارسنجی را تعریف می کنیم:
پس از شروع فرآیند تنظیم دقیق، کار آموزشی حدود 15 دقیقه طول می کشد تا تکمیل شود.
برای انتخاب زیرشبکه ها و تجسم نتایج، جستجوی چند هدفه انجام دهید
در مرحله بعد، با نمونهبرداری از شبکههای فرعی تصادفی با استفاده از SageMaker AMT، یک جستجوی چندهدفه بر روی مدل BERT پایه تنظیمشده دقیق انجام میدهیم. برای دسترسی به یک شبکه فرعی در سوپرشبکه (مدل BERT تنظیم شده)، تمام اجزای PLM را که بخشی از شبکه فرعی نیستند، پنهان می کنیم. پوشاندن یک ابر شبکه برای یافتن زیرشبکهها در یک PLM تکنیکی است که برای جداسازی و شناسایی الگوهای رفتار مدل استفاده میشود. توجه داشته باشید که ترانسفورماتور Hugging Face به اندازه پنهان نیاز دارد تا مضربی از تعداد سرها باشد. اندازه پنهان در یک ترانسفورماتور PLM اندازه فضای برداری حالت پنهان را کنترل می کند، که بر توانایی مدل برای یادگیری نمایش ها و الگوهای پیچیده در داده ها تأثیر می گذارد. در BERT PLM، بردار حالت پنهان یک اندازه ثابت است (768). ما نمی توانیم اندازه پنهان را تغییر دهیم، بنابراین تعداد هدها باید در [1، 3، 6، 12] باشد.
برخلاف بهینهسازی تک هدفه، در تنظیمات چند هدفه، ما معمولاً یک راهحل واحد نداریم که به طور همزمان همه اهداف را بهینه کند. در عوض، هدف ما جمعآوری مجموعهای از راهحلها است که بر تمام راهحلهای دیگر در حداقل یک هدف (مانند خطای اعتبارسنجی) غالب است. اکنون میتوانیم جستجوی چند هدفه را از طریق AMT با تنظیم معیارهایی که میخواهیم کاهش دهیم (خطای اعتبارسنجی و تعداد پارامترها) شروع کنیم. زیرشبکه های تصادفی با پارامتر تعریف می شوند max_jobs و تعداد کارهای همزمان با پارامتر تعریف می شود max_parallel_jobs. کد بارگیری مدل بازرسی و ارزیابی شبکه فرعی در موجود است evaluate_subnetwork.py اسکریپت
کار تنظیم AMT تقریباً 2 ساعت و 20 دقیقه طول می کشد. پس از اجرای موفقیت آمیز کار تنظیم AMT، تاریخچه کار را تجزیه می کنیم و پیکربندی های زیرشبکه مانند تعداد هدها، تعداد لایه ها، تعداد واحدها و معیارهای مربوطه مانند خطای اعتبارسنجی و تعداد پارامترها را جمع آوری می کنیم. اسکرین شات زیر خلاصه ای از کار موفق تیونر AMT را نشان می دهد.
در مرحله بعد، نتایج را با استفاده از یک مجموعه پارتو (همچنین به عنوان مرز پارتو یا مجموعه بهینه پارتو شناخته میشود) تجسم میکنیم که به ما کمک میکند مجموعههای بهینه زیرشبکههایی را که بر همه زیرشبکههای دیگر در متریک هدف (خطای اعتبارسنجی) تسلط دارند شناسایی کنیم:
ابتدا داده ها را از کار تنظیم AMT جمع آوری می کنیم. سپس با استفاده از مجموعه پارتو رسم می کنیم matplotlob.pyplot با تعداد پارامترها در محور x و خطای اعتبارسنجی در محور y. این بدان معناست که وقتی از یک زیرشبکه از مجموعه پارتو به شبکه دیگر منتقل میشویم، باید عملکرد یا اندازه مدل را قربانی کنیم، اما دیگری را بهبود ببخشیم. در نهایت، مجموعه پارتو این قابلیت را برای ما فراهم می کند تا بتوانیم زیرشبکه ای را انتخاب کنیم که به بهترین وجه با ترجیحات ما مطابقت دارد. ما می توانیم تصمیم بگیریم که چقدر می خواهیم اندازه شبکه خود را کاهش دهیم و چقدر عملکرد را مایل به قربانی کردن هستیم.

با استفاده از SageMaker، مدل BERT بهینهسازی شده و مدل زیرشبکه بهینهشده NAS را اجرا کنید.
در مرحله بعد، ما بزرگترین مدل را در مجموعه پارتو خود مستقر می کنیم که منجر به کوچکترین انحطاط عملکرد به یک نقطه پایانی SageMaker. بهترین مدل مدلی است که یک مبادله بهینه بین خطای اعتبارسنجی و تعداد پارامترهای مورد استفاده ما فراهم می کند.
مقایسه مدل
ما یک مدل BERT پایه از پیش آموزشدیده گرفتیم، آن را با استفاده از یک مجموعه داده خاص دامنه تنظیم کردیم، یک جستجوی NAS برای شناسایی زیرشبکههای غالب بر اساس معیارهای هدف انجام دادیم، و مدل هرس شده را در نقطه پایانی SageMaker به کار بردیم. علاوه بر این، مدل BERT پایه از پیش آموزش دیده را انتخاب کردیم و مدل پایه را در نقطه پایانی دوم SageMaker مستقر کردیم. بعد دویدیم تست بار با استفاده از Locust در هر دو نقطه پایانی استنتاج و عملکرد را از نظر زمان پاسخ ارزیابی کرد.
ابتدا کتابخانه های Locust و Boto3 لازم را وارد می کنیم. سپس یک فراداده درخواست می سازیم و زمان شروع را برای استفاده برای آزمایش بار ثبت می کنیم. سپس payload از طریق BotoClient به API فراخوانی نقطه پایانی SageMaker ارسال میشود تا درخواستهای واقعی کاربر را شبیهسازی کند. ما از Locust برای ایجاد چندین کاربر مجازی برای ارسال درخواستها به صورت موازی و اندازهگیری عملکرد نقطه پایانی تحت بار استفاده میکنیم. تست ها به ترتیب با افزایش تعداد کاربران برای هر یک از دو نقطه پایانی اجرا می شوند. پس از اتمام تستها، Locust یک فایل CSV آمار درخواست را برای هر یک از مدلهای مستقر شده خروجی میدهد.
سپس، نمودارهای زمان پاسخ را از فایلهای CSV که پس از اجرای آزمایشها با Locust دانلود شدهاند، تولید میکنیم. هدف از ترسیم زمان پاسخ در مقابل تعداد کاربران، تجزیه و تحلیل نتایج آزمایش بار با تجسم تأثیر زمان پاسخ نقاط پایانی مدل است. در نمودار زیر می بینیم که نقطه پایانی مدل هرس شده توسط NAS در مقایسه با نقطه پایانی مدل پایه BERT به زمان پاسخ کمتری می رسد.
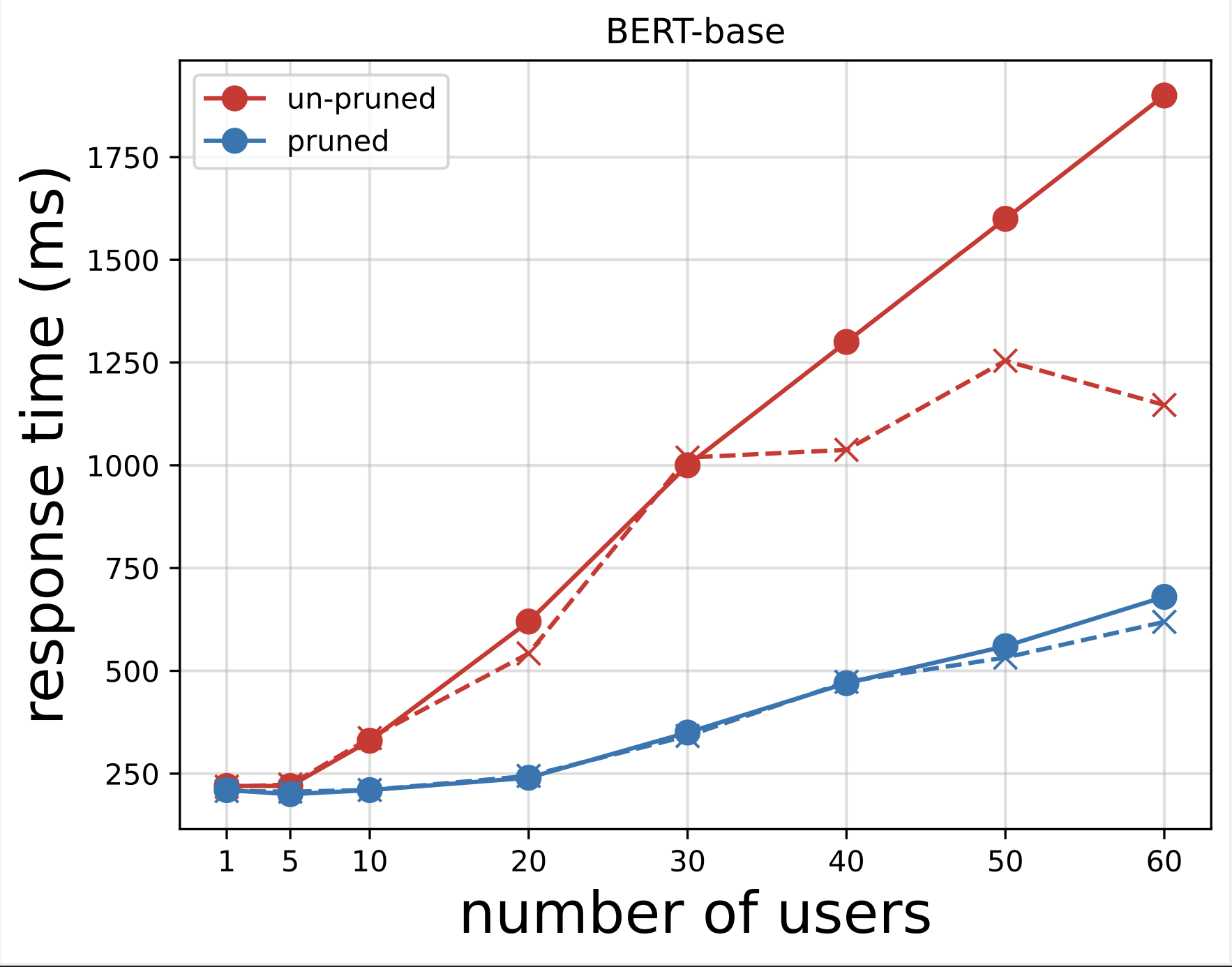
در نمودار دوم، که پسوند نمودار اول است، مشاهده میکنیم که پس از حدود 70 کاربر، SageMaker شروع به دریچهگیری نقطه پایانی مدل BERT پایه میکند و یک استثنا ایجاد میکند. با این حال، برای نقطه پایانی مدل هرس شده توسط NAS، فشار بین 90 تا 100 کاربر و با زمان پاسخ کمتر اتفاق میافتد.

از دو نمودار مشاهده می کنیم که مدل هرس شده زمان پاسخگویی سریع تری دارد و در مقایسه با مدل هرس نشده مقیاس بهتری دارد. همانطور که ما تعداد نقاط پایانی استنتاج را مقیاس بندی می کنیم، همانطور که در مورد کاربرانی که تعداد زیادی نقطه پایانی استنتاج را برای برنامه های کاربردی PLM خود استفاده می کنند، مزایای هزینه و بهبود عملکرد بسیار قابل توجه می شود.
پاک کردن
برای حذف نقاط پایانی SageMaker برای مدل BERT پایه تنظیم شده و مدل هرس شده NAS، مراحل زیر را انجام دهید:
- در کنسول SageMaker، را انتخاب کنید استنباط و نقاط پایان در صفحه ناوبری
- نقطه پایانی را انتخاب کرده و آن را حذف کنید.
از طرف دیگر، از نوت بوک SageMaker Studio، دستورات زیر را با ارائه نام نقطه پایانی اجرا کنید:
نتیجه
در این پست، نحوه استفاده از NAS برای هرس مدل BERT تنظیم شده را مورد بحث قرار دادیم. ما ابتدا یک مدل BERT پایه را با استفاده از داده های دامنه خاص آموزش دادیم و آن را در یک نقطه پایانی SageMaker مستقر کردیم. ما یک جستجوی چند هدفه را بر روی مدل BERT پایه تنظیم شده با استفاده از SageMaker AMT برای یک کار هدف انجام دادیم. ما جلوی پارتو را تجسم کردیم و مدل BERT بهینه پارتو را انتخاب کردیم و مدل را در نقطه پایانی دوم SageMaker مستقر کردیم. ما آزمایش بارگذاری را با استفاده از Locust انجام دادیم تا کاربرانی را که هر دو نقطه پایانی را پرس و جو میکردند، شبیهسازی کنیم و زمانهای پاسخ را در یک فایل CSV اندازهگیری و ثبت کردیم. ما زمان پاسخ را در مقابل تعداد کاربران برای هر دو مدل ترسیم کردیم.
ما مشاهده کردیم که مدل BERT هرس شده به طور قابل توجهی در هر دو زمان پاسخ و آستانه دریچه گاز عملکرد بهتری داشت. ما به این نتیجه رسیدیم که مدل هرس شده با NAS نسبت به افزایش بار در نقطه پایانی انعطافپذیرتر است و زمان پاسخ کمتری را حفظ میکند، حتی زمانی که کاربران بیشتری روی سیستم در مقایسه با مدل BERT پایه فشار میآورند. میتوانید تکنیک NAS را که در این پست توضیح داده شده است، برای هر مدل زبان بزرگی به کار ببرید تا یک مدل هرس شده را پیدا کنید که میتواند کار هدف را با زمان پاسخدهی بسیار کمتری انجام دهد. میتوانید با استفاده از تأخیر بهعنوان پارامتر علاوه بر از دست دادن اعتبارسنجی، رویکرد را بیشتر بهینه کنید.
اگرچه ما در این پست از NAS استفاده می کنیم، کوانتیزاسیون یکی دیگر از روش های رایج مورد استفاده برای بهینه سازی و فشرده سازی مدل های PLM است. کوانتیزه کردن دقت وزنها و فعالسازیها را در یک شبکه آموزشدیده از نقطه شناور ۳۲ بیتی به عرض بیتهای پایینتر مانند اعداد صحیح ۸ بیتی یا ۱۶ بیتی کاهش میدهد که منجر به یک مدل فشرده میشود که استنتاج سریعتری ایجاد میکند. کوانتیزاسیون تعداد پارامترها را کاهش نمی دهد. در عوض دقت پارامترهای موجود را برای بدست آوردن یک مدل فشرده کاهش می دهد. هرس NAS شبکه های اضافی را در یک PLM حذف می کند، که یک مدل پراکنده با پارامترهای کمتر ایجاد می کند. به طور معمول، هرس NAS و کوانتیزاسیون با هم برای فشرده سازی PLM های بزرگ برای حفظ دقت مدل، کاهش تلفات اعتبار سنجی و در عین حال بهبود عملکرد و کاهش اندازه مدل استفاده می شود. سایر تکنیک های رایج برای کاهش اندازه PLM ها عبارتند از تقطیر دانش, فاکتورسازی ماتریسیو آبشارهای تقطیر.
رویکرد پیشنهادی در وبلاگ پست برای تیمهایی مناسب است که از SageMaker برای آموزش و تنظیم دقیق مدلها با استفاده از دادههای دامنه خاص و استقرار نقاط پایانی برای تولید استنتاج استفاده میکنند. اگر به دنبال یک سرویس کاملاً مدیریت شده هستید که انتخابی از مدلهای پایه با کارایی بالا را ارائه میدهد که برای ساخت برنامههای هوش مصنوعی مولد نیاز است، استفاده از آن را در نظر بگیرید. بستر آمازون. اگر به دنبال مدل های از پیش آموزش دیده و منبع باز برای طیف گسترده ای از موارد استفاده تجاری هستید و می خواهید به الگوهای راه حل و نمونه نوت بوک ها دسترسی داشته باشید، استفاده از آن را در نظر بگیرید. Amazon SageMaker JumpStart. یک نسخه از پیش آموزشدیدهشده از مدل محفظه پایه Hugging Face BERT که در این پست استفاده کردیم نیز از SageMaker JumpStart موجود است.
درباره نویسنده
 آپاراجیتان وایدیاناتان یک معمار اصلی راه حل های سازمانی در AWS است. او یک معمار ابر با 24+ سال تجربه در طراحی و توسعه سیستم های نرم افزاری سازمانی، مقیاس بزرگ و توزیع شده است. او در زمینه هوش مصنوعی و مهندسی داده های یادگیری ماشین تخصص دارد. او یک دونده ماراتن مشتاق است و سرگرمی هایش شامل پیاده روی، دوچرخه سواری و گذراندن وقت با همسر و دو پسرش است.
آپاراجیتان وایدیاناتان یک معمار اصلی راه حل های سازمانی در AWS است. او یک معمار ابر با 24+ سال تجربه در طراحی و توسعه سیستم های نرم افزاری سازمانی، مقیاس بزرگ و توزیع شده است. او در زمینه هوش مصنوعی و مهندسی داده های یادگیری ماشین تخصص دارد. او یک دونده ماراتن مشتاق است و سرگرمی هایش شامل پیاده روی، دوچرخه سواری و گذراندن وقت با همسر و دو پسرش است.
 آرون کلین یک دانشمند کاربردی Sr در AWS است که روی روشهای یادگیری ماشین خودکار برای شبکههای عصبی عمیق کار میکند.
آرون کلین یک دانشمند کاربردی Sr در AWS است که روی روشهای یادگیری ماشین خودکار برای شبکههای عصبی عمیق کار میکند.
 یاچک گلبیوفسکی دانشمند کاربردی Sr در AWS است.
یاچک گلبیوفسکی دانشمند کاربردی Sr در AWS است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- : دارد
- :است
- :نه
- :جایی که
- ][پ
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- ٪۱۰۰
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- توانایی
- قادر
- دسترسی
- حساب
- دقت
- رسیدن
- دستیابی به
- فعال سازی ها
- اضافه
- اتخاذ
- پس از
- AI
- هدف
- هدف
- الگوریتم
- معرفی
- اجازه دادن
- اجازه دادن
- اجازه می دهد تا
- همچنین
- آمازون
- آمازون خدمات وب
- مقدار
- an
- تحلیل
- علم تجزیه و تحلیل
- تحلیل
- و
- دیگر
- پاسخ دادن
- هر
- API
- برنامه های کاربردی
- اعمال می شود
- درخواست
- با استفاده از
- روش
- تصویب
- تقریبا
- معماری
- هستند
- محدوده
- مناطق
- استدلال
- دور و بر
- مصنوعی
- شبکه های عصبی مصنوعی
- AS
- مشتاق
- اختصاص داده
- مرتبط است
- At
- تلاش
- مراجعه كردن
- خودکار
- خودکار یادگیری ماشین
- خودکار می کند
- اتوماتیک
- اتوماسیون
- اتوماسیون
- در دسترس
- AWS
- محور
- برج میزان
- پایه
- مستقر
- BE
- شدن
- قبل از
- رفتار
- معیار
- مزایای
- بهترین
- بهتر
- میان
- بیت
- بدن
- هر دو
- ساختن
- کسب و کار
- فرآیند کاری
- اتوماسیون فرآیند تجارت
- اما
- by
- CAN
- نامزد
- قابلیت های
- مورد
- موارد
- کاتالوگ
- تغییر دادن
- چارت سازمانی
- نمودار
- chatbots
- انتخاب
- را انتخاب کنید
- برگزیده
- کلاس
- طبقه بندی
- بالینی
- نزدیک
- ابر
- رمز
- جمع آوری
- مجموعه
- ترکیب
- تجاری
- مشترک
- عموما
- مقایسه
- کامل
- تکمیل شده
- پیچیده
- پیچیدگی
- اجزاء
- محاسباتی
- محاسبه
- مفاهیم
- به این نتیجه رسیدند
- در نظر بگیرید
- تشکیل شده است
- کنسول
- محدودیت ها
- ساختن
- مصرف
- شامل
- محتوا
- تولید محتوا
- زمینه
- ادامه دادن
- کنتراست
- گروه شاهد
- متناظر
- هزینه
- هزینه
- تعداد دفعات مشاهده
- ایجاد
- ایجاد
- ایجاد
- مشتری
- خدمات مشتری
- داده ها
- علم اطلاعات
- مجموعه داده ها
- زمان قرار
- تصمیم گیری
- تصمیم گیری
- اختصاصی
- عمیق
- شبکه های عصبی عمیق
- تعريف كردن
- مشخص
- تعریف کردن
- نسخه ی نمایشی
- نشان دادن
- بستگی دارد
- گسترش
- مستقر
- استقرار
- مستقر می کند
- شرح داده شده
- طرح
- طراحی
- مطلوب
- در حال توسعه
- مختلف
- بحث کردیم
- توزیع شده
- سند
- نمی کند
- غالب
- تسلط
- آیا
- دو
- در طی
- e
- هر
- بهره وری
- موثر
- هر دو
- نقطه پایانی
- نقاط پایان
- مهندسی
- موتورهای حرفه ای
- کافی
- وارد
- سرمایه گذاری
- پذیرش شرکت
- راه حل های سازمانی
- موجودیت
- ورود
- محیط
- دوره
- خطا
- اتر (ETH)
- ارزیابی
- ارزیابی
- ارزیابی
- حتی
- حوادث
- مثال
- جز
- استثنا
- منحصرا
- موجود
- تجربه
- توضیح دهید
- توضیح داده شده
- گسترش
- چهره
- غلط
- سریعتر
- امکانات
- باز خورد
- کمتر
- رشته
- پرونده
- فایل ها
- نهایی
- پیدا کردن
- پیدا کردن
- نام خانوادگی
- ثابت
- انعطاف پذیری
- شناور
- پیروی
- رد پا
- برای
- یافت
- پایه
- از جانب
- جلو
- مرز
- کاملا
- تابع
- بیشتر
- تولید می کنند
- تولید می کند
- مولد
- هوش مصنوعی مولد
- دریافت کنید
- داده
- هدف
- GPU
- خاکستری
- اتفاق می افتد
- آیا
- he
- سر
- سر
- بهداشت و درمان
- کمک می کند
- پنهان
- با عملکرد بالا
- بالاتر
- پیاده روی
- خود را
- تاریخ
- سرگرمی
- میزبان
- میزبانی
- ساعت ها
- چگونه
- چگونه
- اما
- HTML
- HTTP
- HTTPS
- صورت در آغوش گرفته
- بهینه سازی هایپرپارامتر
- تنظیم فراپارامتر
- i
- شناسایی
- IDX
- if
- نشان دادن
- تأثیر
- اثرات
- انجام
- واردات
- بهبود
- بهبود یافته
- بهبود
- بهبود
- in
- شامل
- افزایش
- افزایش
- افزایش
- اطلاعات
- شالوده
- ورودی
- نمونه
- نمونه ها
- در عوض
- هوشمند
- به
- IT
- ITS
- کار
- شغل ها
- JPG
- json
- دانش
- شناخته شده
- زبان
- بزرگ
- در مقیاس بزرگ
- بزرگترین
- تاخیر
- لایه
- لایه
- منجر می شود
- یاد گرفتن
- یادگیری
- کمترین
- اجازه
- کتابخانه ها
- کتابخانه
- لاین
- بار
- ورود به سیستم
- ورود به سیستم
- به دنبال
- خاموش
- تلفات
- کاهش
- دستگاه
- فراگیری ماشین
- حفظ
- نگهداری
- مرد
- اداره می شود
- مسابقه دو ماراتون
- ماسک
- ماتپلوتلب
- بیشترین
- ممکن است..
- معنی
- اندازه
- اندازه گیری
- اندازه گیری
- پزشکی
- دیدار
- حافظه
- متاداده
- روش
- متری
- متریک
- قدرت
- به حداقل رساندن
- دقیقه
- ML
- مدل
- مدل سازی
- مدل
- پیمانهای
- بیش
- حرکت
- بسیار
- چندگانه
- باید
- نام
- تحت عنوان
- نام
- در
- طبیعی
- زبان طبیعی
- پردازش زبان طبیعی
- هدایت
- جهت یابی
- لازم
- نیاز
- ضروری
- نیازهای
- شبکه
- شبکه
- عصبی
- شبکه های عصبی
- شبکه های عصبی
- بعد
- nlp
- هیچ
- توجه داشته باشید
- دفتر یادداشت
- نوت بوک
- اکنون
- عدد
- هدف
- هدف
- اهداف
- مشاهده کردن
- مشاهده
- of
- خاموش
- ارائه
- پیشنهادات
- on
- ONE
- آنلاین
- خرده فروش آنلاین
- فقط
- باز کن
- منبع باز
- بهینه
- بهینه سازی
- بهینه سازی
- بهینه
- بهینه سازی می کند
- بهینه سازی
- or
- سفارش
- اصلی
- دیگر
- ما
- خارج
- تولید
- خروجی
- روی
- به طور کلی
- مروری
- خود
- جفت
- قطعه
- موازی
- پارامتر
- پارامترهای
- پارتو
- بخش
- گذشت
- مسیر
- بیمار
- الگوهای
- انجام دادن
- کارایی
- انجام
- انجام
- انجام می دهد
- مجوز
- افلاطون
- هوش داده افلاطون
- PlatoData
- نقطه
- نقطه
- موقعیت
- پست
- دقت
- پیش گویی
- پیش بینی
- پیشگو
- تنظیمات
- آماده شده
- پیش نیازها
- در حال حاضر
- قبلا
- اصلی
- مشکل
- روند
- خودکارسازی فرایند
- فرآیندهای
- در حال پردازش
- محصول
- بهره وری
- ابزار بهره وری
- پیشنهاد شده
- ارائه دهنده
- فراهم می کند
- ارائه
- کشیدن
- کشد
- هدف
- اهداف
- پــایتــون
- مارماهی
- پرسش و پاسخ
- سوال
- کاملا
- تصادفی
- محدوده
- سریع
- نرخ
- خام
- واقعی
- به رسمیت شناختن
- شناختن
- شناختن
- توصیه
- توصیه
- رکورد
- ثبت
- قرمز
- كاهش دادن
- کاهش
- را کاهش می دهد
- رگرسیون
- مربوط
- حذف می کند
- از بین بردن
- گزارش ها
- نمایندگی
- درخواست
- خواسته
- درخواست
- ضروری
- مورد نیاز
- انعطاف پذیر
- منابع
- منابع
- به ترتیب
- پاسخ
- نتایج
- خرده فروش
- حفظ
- بازده
- سواری
- خطر
- ROW
- دویدن
- دونده
- در حال اجرا
- اجرا می شود
- s
- قربانی
- حکیم ساز
- استنباط SageMaker
- ذخیره
- مقیاس
- مقیاس ها
- علم
- دانشمند
- نمره
- خط
- جستجو
- موتورهای جستجو
- جستجو
- دوم
- بخش
- دیدن
- را انتخاب کنید
- انتخاب شد
- خود
- ارسال
- جمله
- احساس
- دنباله
- سرویس
- خدمات
- جلسه
- تنظیم
- مجموعه
- محیط
- نشان می دهد
- سیگنال
- به طور قابل توجهی
- ساده
- همزمان
- به طور همزمان
- تنها
- اندازه
- کوچکتر
- So
- نرم افزار
- راه حل
- مزایا
- برخی از
- منبع
- فضا
- تخم ریزی
- تخصصی
- تخصص دارد
- خاص
- به طور خاص
- هزینه
- انشعاب
- شروع
- شروع می شود
- دولت
- ارقام
- گام
- مراحل
- ذخیره سازی
- ساختاری
- ساخت یافته
- استودیو
- قابل توجه
- موفق
- موفقیت
- چنین
- مناسب
- دنباله
- خلاصه
- سیستم
- سیستم های
- T
- گرفتن
- طول می کشد
- هدف
- کار
- وظایف
- تیم ها
- تکنیک
- تکنیک
- قالب
- قوانین و مقررات
- تست
- تست
- متن
- طبقه بندی متن
- متن
- نسبت به
- که
- La
- شان
- سپس
- آنجا.
- از این رو
- اینها
- این
- سه
- آستانه
- از طریق
- زمان
- بار
- به
- با هم
- رمز
- در زمان
- ابزار
- ابزار
- تجارت
- تجارت
- قطار
- آموزش دیده
- آموزش
- ترانسفورماتور
- ترانسفورماتور
- درست
- امتحان
- دو
- نوع
- انواع
- نوعی
- به طور معمول
- در نهایت
- زیر
- در حال انجام
- درک
- واحد
- us
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- کاربران
- استفاده
- با استفاده از
- اعتبار سنجی
- ارزش
- ارزشها
- نسخه
- از طريق
- مجازی
- تجسم
- vs
- می خواهم
- بود
- we
- وب
- خدمات وب
- خوب
- چه زمانی
- چه
- که
- در حین
- WHO
- وسیع
- دامنه گسترده
- به طور گسترده ای
- زن
- ویکیپدیا
- اراده
- مایل
- با
- در داخل
- مهاجرت کاری
- گردش کار
- کارگر
- X
- سال
- بازده
- شما
- شما
- زفیرنت