در عصر دیجیتال امروزی، داده ها در قلب موفقیت هر سازمانی قرار دارند. یکی از رایج ترین فرمت های مورد استفاده برای تبادل داده ها XML است. تجزیه و تحلیل فایل های XML به چند دلیل بسیار مهم است. اولاً، فایلهای XML در بسیاری از صنایع، از جمله امور مالی، بهداشت و درمان و دولت استفاده میشوند. تجزیه و تحلیل فایلهای XML میتواند به سازمانها کمک کند تا بینشی در مورد دادههای خود کسب کنند و به آنها اجازه میدهد تصمیمات بهتری بگیرند و عملیات خود را بهبود بخشند. تجزیه و تحلیل فایل های XML همچنین می تواند به یکپارچه سازی داده ها کمک کند، زیرا بسیاری از برنامه ها و سیستم ها از XML به عنوان یک فرمت استاندارد داده استفاده می کنند. با تجزیه و تحلیل فایلهای XML، سازمانها میتوانند به راحتی دادهها را از منابع مختلف یکپارچه کنند و از ثبات در سیستمهای خود اطمینان حاصل کنند، با این حال، فایلهای XML حاوی دادههای نیمه ساختاریافته و بسیار تودرتو هستند که دسترسی و تجزیه و تحلیل اطلاعات را دشوار میکند، به خصوص اگر فایل بزرگ و دارای طرح واره پیچیده و بسیار تودرتو
فایلهای XML برای برنامهها مناسب هستند، اما ممکن است برای موتورهای تحلیلی بهینه نباشند. به منظور افزایش عملکرد پرس و جو و امکان دسترسی آسان در موتورهای تحلیلی پایین دستی مانند آمازون آتنا، بسیار مهم است که فایل های XML را در قالبی ستونی مانند پارکت پیش پردازش کنید. این تغییر به بهبود کارایی و قابلیت استفاده در گردش کار تجزیه و تحلیل اجازه می دهد. در این پست، نحوه پردازش داده های XML را با استفاده از آن نشان می دهیم چسب AWS و آتنا
بررسی اجمالی راه حل
ما دو تکنیک متمایز را بررسی می کنیم که می تواند گردش کار پردازش فایل XML شما را ساده کند:
- تکنیک 1: از خزنده چسب AWS و ویرایشگر تصویری AWS Glue استفاده کنید – می توانید از رابط کاربری AWS Glue همراه با یک خزنده برای تعریف ساختار جدول برای فایل های XML خود استفاده کنید. این رویکرد یک رابط کاربر پسند فراهم می کند و به ویژه برای افرادی که رویکرد گرافیکی را برای مدیریت داده های خود ترجیح می دهند مناسب است.
- تکنیک 2: استفاده از AWS Glue DynamicFrames با طرحواره های استنباط شده و ثابت - وقتی نوبت به پردازش یک ردیف در فایل های XML بزرگتر از آن می رسد، خزنده دارای محدودیت است 1 MB. برای غلبه بر این محدودیت، از یک نوت بوک AWS Glue برای ساختن چسب AWS استفاده می کنیم.
DynamicFramesبا استفاده از طرحواره های استنباط شده و ثابت. این روش مدیریت کارآمد فایل های XML با ردیف های بیش از 1 مگابایت را تضمین می کند.
در هر دو رویکرد، هدف نهایی ما تبدیل فایلهای XML به فرمت Apache Parquet است، و آنها را برای پرسوجو با استفاده از Athena به آسانی در دسترس قرار میدهد. با استفاده از این تکنیکها، میتوانید سرعت پردازش و دسترسی به دادههای XML خود را افزایش دهید و به شما امکان میدهد به راحتی بینشهای ارزشمندی را به دست آورید.
پیش نیازها
قبل از شروع این آموزش، پیش نیازهای زیر را تکمیل کنید (این موارد برای هر دو تکنیک اعمال می شود):
- فایل های XML را دانلود کنید تکنیک1.xml و تکنیک2.xml.
- فایل ها را در یک آپلود کنید سرویس ذخیره سازی ساده آمازون سطل (Amazon S3). می توانید آنها را در یک سطل S3 در پوشه های مختلف یا در سطل های مختلف S3 آپلود کنید.
- ایجاد یک هویت AWS و مدیریت دسترسی نقش (IAM) برای شغل یا نوت بوک ETL شما همانطور که در آموزش داده شده است مجوزهای IAM را برای AWS Glue Studio تنظیم کنید.
- یک خط مشی درون خطی را به نقش خود اضافه کنید iam:PassRole عمل:
- با دسترسی به سطل S3 خود، یک خط مشی مجوزها را به نقش اضافه کنید.
حالا که با پیش نیازها تمام شد، به سراغ اجرای تکنیک اول می رویم.
تکنیک 1: از خزنده چسب AWS و ویرایشگر بصری استفاده کنید
نمودار زیر معماری ساده ای را نشان می دهد که می توانید برای پیاده سازی راه حل از آن استفاده کنید.
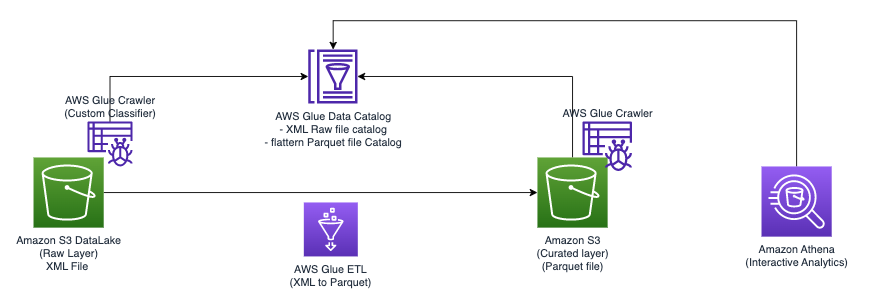
برای تجزیه و تحلیل فایل های XML ذخیره شده در Amazon S3 با استفاده از چسب AWS و Athena، مراحل سطح بالا زیر را تکمیل می کنیم:
- یک خزنده چسب AWS برای استخراج فراداده XML و ایجاد جدول در کاتالوگ داده چسب AWS ایجاد کنید.
- پردازش و تبدیل داده های XML به فرمتی (مانند پارکت) مناسب برای آتنا با استفاده از یک کار استخراج، تبدیل، و بارگذاری AWS Glue (ETL).
- یک کار چسب AWS را از طریق کنسول AWS Glue یا آن تنظیم و اجرا کنید رابط خط فرمان AWS (AWS CLI).
- از داده های پردازش شده (در قالب پارکت) با جداول آتنا استفاده کنید و پرس و جوهای SQL را فعال کنید.
- از رابط کاربر پسند در Athena برای تجزیه و تحلیل داده های XML با پرس و جوهای SQL روی داده های ذخیره شده در Amazon S3 استفاده کنید.
این معماری یک راه حل مقیاس پذیر و مقرون به صرفه برای تجزیه و تحلیل داده های XML در Amazon S3 با استفاده از چسب AWS و Athena است. شما می توانید مجموعه داده های بزرگ را بدون مدیریت زیرساخت پیچیده تجزیه و تحلیل کنید.
ما از خزنده AWS Glue برای استخراج فراداده فایل XML استفاده می کنیم. شما می توانید طبقه بندی کننده چسب پیش فرض AWS را برای طبقه بندی XML همه منظوره انتخاب کنید. به طور خودکار ساختار و طرح داده XML را شناسایی می کند که برای فرمت های رایج مفید است.
ما همچنین از یک طبقه بندی XML سفارشی در این راه حل استفاده می کنیم. این برای طرحها یا قالبهای خاص XML طراحی شده است و امکان استخراج فراداده دقیق را فراهم میکند. این برای فرمت های XML غیر استاندارد یا زمانی که به کنترل دقیق بر طبقه بندی نیاز دارید ایده آل است. یک طبقهبندیکننده سفارشی تضمین میکند که فقط ابردادههای ضروری استخراج میشوند، و وظایف پردازش و تحلیل پاییندستی را ساده میکند. این رویکرد استفاده از فایل های XML شما را بهینه می کند.
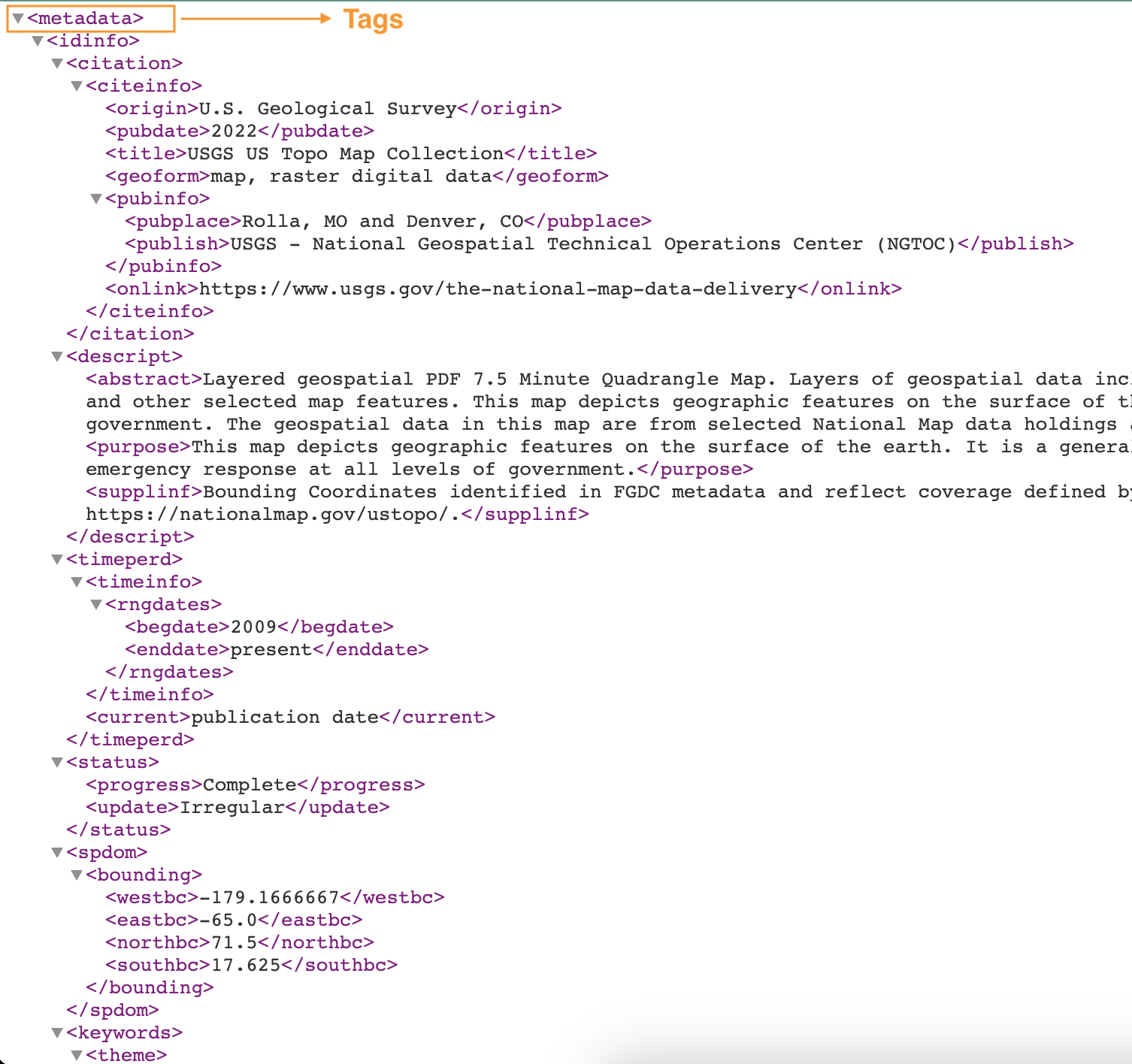
تصویر زیر نمونه ای از یک فایل XML را با برچسب ها نشان می دهد.
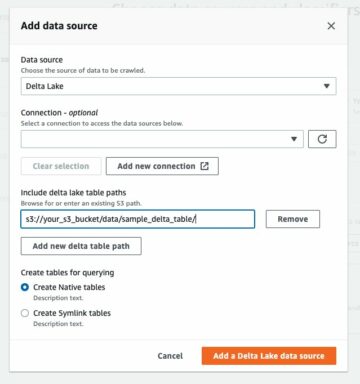
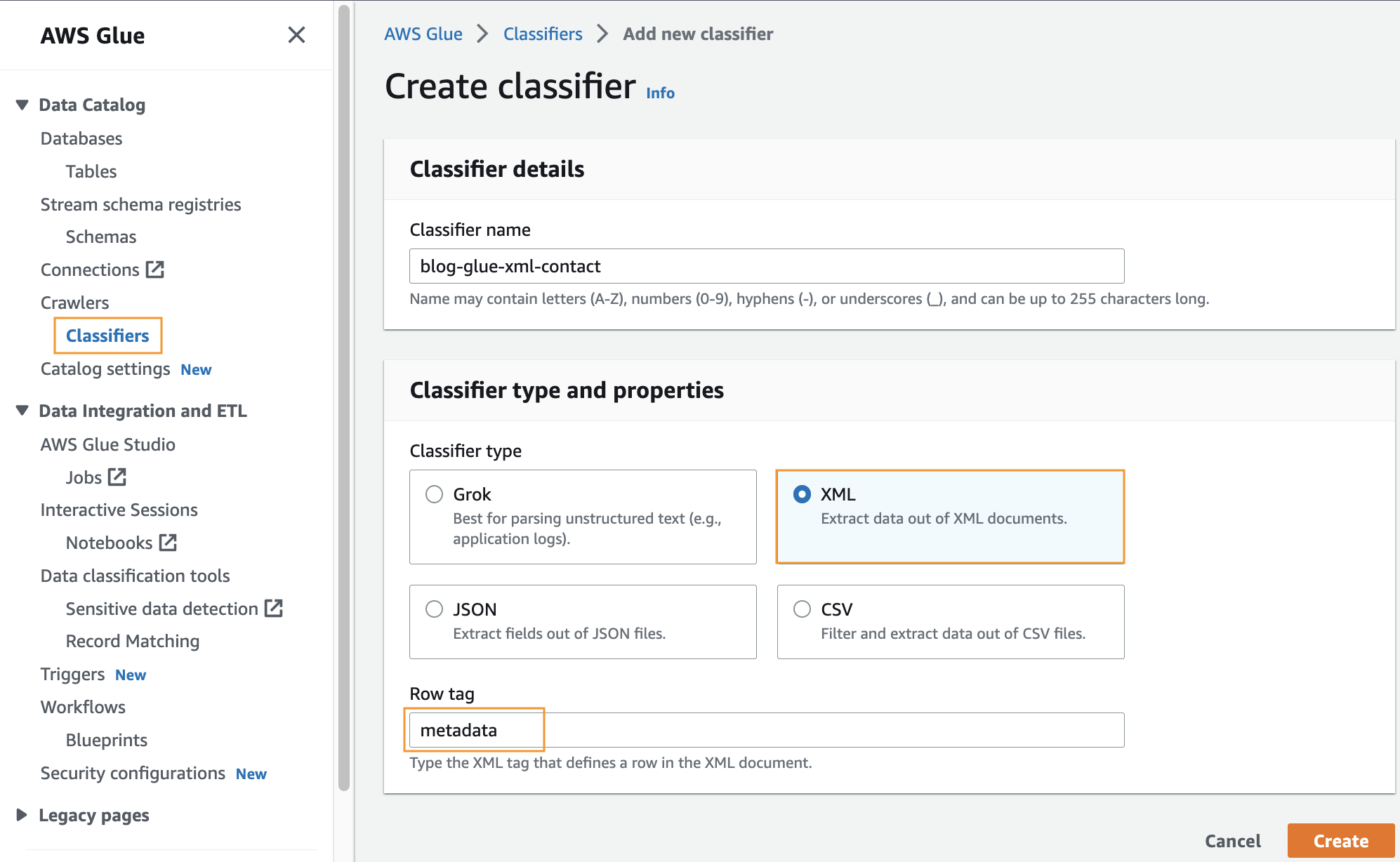
یک طبقه بندی سفارشی ایجاد کنید
در این مرحله، یک طبقهبندیکننده چسب AWS سفارشی برای استخراج ابرداده از یک فایل XML ایجاد میکنید. مراحل زیر را کامل کنید:
- در کنسول AWS Glue، زیر خزنده ها در قسمت ناوبری، را انتخاب کنید طبقه بندی کننده.
- را انتخاب کنید اضافه کردن طبقه بندی.
- انتخاب کنید XML به عنوان نوع طبقه بندی کننده
- یک نام برای طبقه بندی وارد کنید، مانند
blog-glue-xml-contact. - برای برچسب ردیف، نام تگ ریشه که حاوی ابرداده است را وارد کنید (به عنوان مثال،
metadata). - را انتخاب کنید ساختن.
یک AWS Glue Crawler برای خزیدن فایل xml ایجاد کنید
در این بخش، ما در حال ایجاد یک خزنده چسب برای استخراج ابرداده از فایل XML با استفاده از طبقهبندی مشتری ایجاد شده در مرحله قبل هستیم.
یک پایگاه داده ایجاد کنید
- رفتن به کنسول چسب AWS، انتخاب کنید پایگاه داده ها در صفحه ناوبری
- با کلیک بر روی افزودن پایگاه داده
- نامی مانند
blog_glue_xml - را انتخاب کنید ساختن پایگاه داده
یک خزنده ایجاد کنید
مراحل زیر را برای ایجاد اولین خزنده خود انجام دهید:
- در کنسول AWS Glue، را انتخاب کنید خزنده ها در صفحه ناوبری
- را انتخاب کنید خزنده ایجاد کنید.
- بر ویژگی های خزنده را تنظیم کنید صفحه، نامی برای خزنده جدید (مانند
blog-glue-parquet، سپس انتخاب کنید بعدی. - بر منابع داده و طبقه بندی کننده ها را انتخاب کنید صفحه، را انتخاب کنید نه هنوز زیر پیکربندی منبع داده.
- را انتخاب کنید یک فروشگاه داده اضافه کنید.
- برای مسیر S3، مرور به
s3://${BUCKET_NAME}/input/geologicalsurvey/.
مطمئن شوید که پوشه XML را به جای فایل داخل پوشه انتخاب کرده اید.
- بقیه گزینه ها را به عنوان پیش فرض بگذارید و انتخاب کنید یک منبع داده S3 اضافه کنید.
- گسترش طبقه بندی های سفارشی - اختیاری، blog-glue-xml-contact را انتخاب کنید، سپس انتخاب کنید بعدی و بقیه گزینه ها را به عنوان پیش فرض نگه دارید.
- نقش IAM خود را انتخاب کنید یا انتخاب کنید نقش IAM جدید ایجاد کنید، پسوند را اضافه کنید
glue-xml-contact(مثلا،AWSGlueServiceNotebookRoleBlog) و انتخاب کنید بعدی. - بر خروجی و زمان بندی را تنظیم کنید صفحه، زیر پیکربندی خروجی، انتخاب کنید
blog_glue_xmlبرای پایگاه داده هدف. - وارد
console_به عنوان پیشوند اضافه شده به جداول (اختیاری) و زیر برنامه خزنده، فرکانس را روی تنظیم نگه دارید بر اساس تقاضا. - را انتخاب کنید بعدی.
- تمام پارامترها را بررسی کرده و انتخاب کنید خزنده ایجاد کنید.
خزنده را اجرا کنید
پس از ایجاد خزنده، مراحل زیر را برای اجرای آن انجام دهید:
- در کنسول AWS Glue، را انتخاب کنید خزنده ها در صفحه ناوبری
- خزنده ای را که ایجاد کردید باز کنید و انتخاب کنید دویدن.
خزنده 1 تا 2 دقیقه طول می کشد تا تکمیل شود.
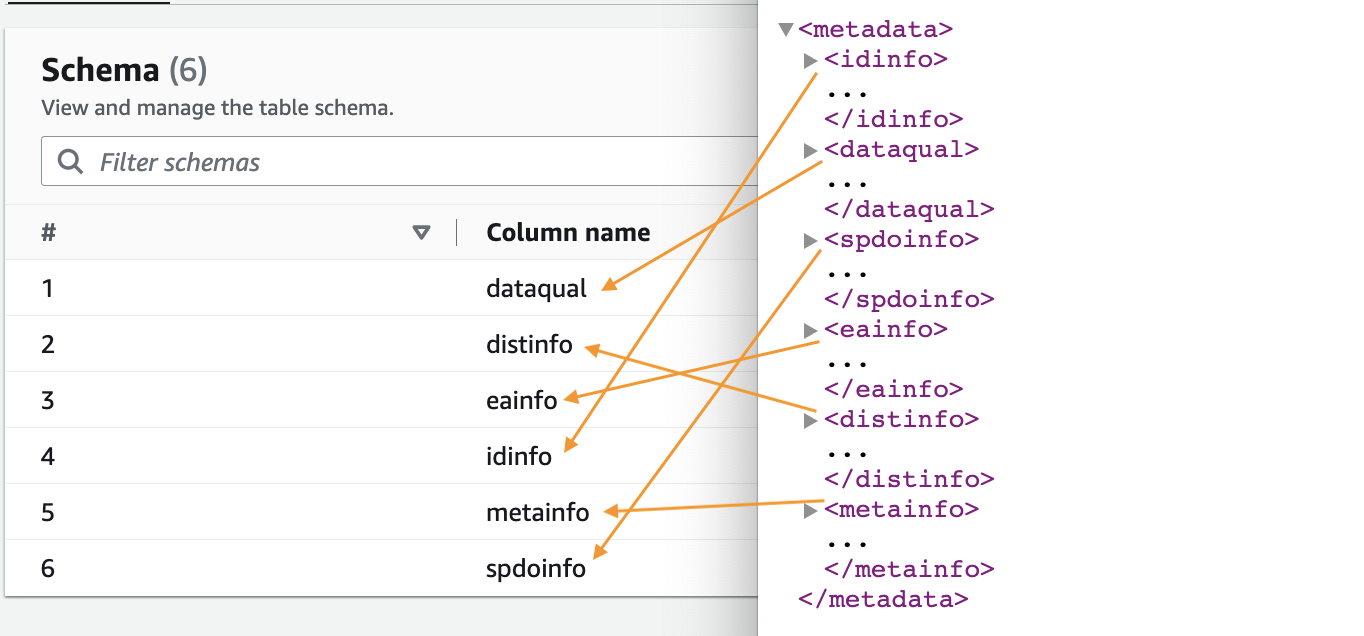
- وقتی خزنده کامل شد، انتخاب کنید پایگاه داده ها در صفحه ناوبری
- پایگاه داده ای را که ایجاد کرده اید انتخاب کنید و نام جدول را انتخاب کنید تا طرحواره استخراج شده توسط خزنده را ببینید.
یک کار چسب AWS برای تبدیل XML به قالب پارکت ایجاد کنید
در این مرحله، یک کار AWS Glue Studio ایجاد میکنید تا فایل XML را به فایل Parquet تبدیل کنید. مراحل زیر را کامل کنید:
- در کنسول AWS Glue، را انتخاب کنید شغل ها در صفحه ناوبری
- تحت ایجاد شغل، انتخاب کنید تصویری با بوم خالی.
- را انتخاب کنید ساختن.
- نام کار را به
blog_glue_xml_job.
اکنون یک ویرایشگر کار بصری AWS Glue Studio خالی دارید. در بالای ویرایشگر زبانه هایی برای نماهای مختلف وجود دارد.
- انتخاب خط برای دیدن یک پوسته خالی از اسکریپت AWS Glue ETL.
همانطور که ما مراحل جدید را در ویرایشگر بصری اضافه می کنیم، اسکریپت به طور خودکار به روز می شود.
- انتخاب جزئیات شغل برای مشاهده تمام تنظیمات کار، را انتخاب کنید.
- برای نقش IAM، انتخاب کنید
AWSGlueServiceNotebookRoleBlog. - برای نسخه چسب، انتخاب کنید Glue 4.0 – پشتیبانی از Spark 3.3، Scala 2، Python 3.
- تنظیم تعداد کارگر درخواستی به 2.
- تنظیم تعداد تلاش های مجدد به 0.
- انتخاب بصری برای بازگشت به ویرایشگر بصری.
- بر منبع منوی کشویی ، را انتخاب کنید کاتالوگ داده چسب AWS.
- بر ویژگی های منبع داده - کاتالوگ داده برگه، اطلاعات زیر را ارائه دهید:
- برای پایگاه داده، انتخاب کنید
blog_glue_xml. - برای جدول، جدولی را انتخاب کنید که با نام console_ که خزنده ایجاد کرده شروع می شود (به عنوان مثال،
console_geologicalsurvey).
- برای پایگاه داده، انتخاب کنید
- بر ویژگی های گره برگه، اطلاعات زیر را ارائه دهید:
- تغییر دادن نام به
geologicalsurveyمجموعه داده - را انتخاب کنید عمل و تحول تغییر طرحواره (اعمال نقشه برداری).
- را انتخاب کنید ویژگی های گره و نام تبدیل را از Change Schema (Apply Mapping) به تغییر دهید
ApplyMapping. - بر هدف منو ، انتخاب کنید S3.
- تغییر دادن نام به
- بر ویژگی های منبع داده - S3 برگه، اطلاعات زیر را ارائه دهید:
- برای قالب، انتخاب کنید با چوب فرش کردن.
- برای نوع فشرده سازی، انتخاب کنید فشرده نشده.
- برای نوع منبع S3، انتخاب کنید مکان S3.
- برای آدرس S3، وارد
s3://${BUCKET_NAME}/output/parquet/. - را انتخاب کنید ویژگی های گره و نام را به
Output.
- را انتخاب کنید ذخیره برای نجات کار
- را انتخاب کنید دویدن برای اجرای کار
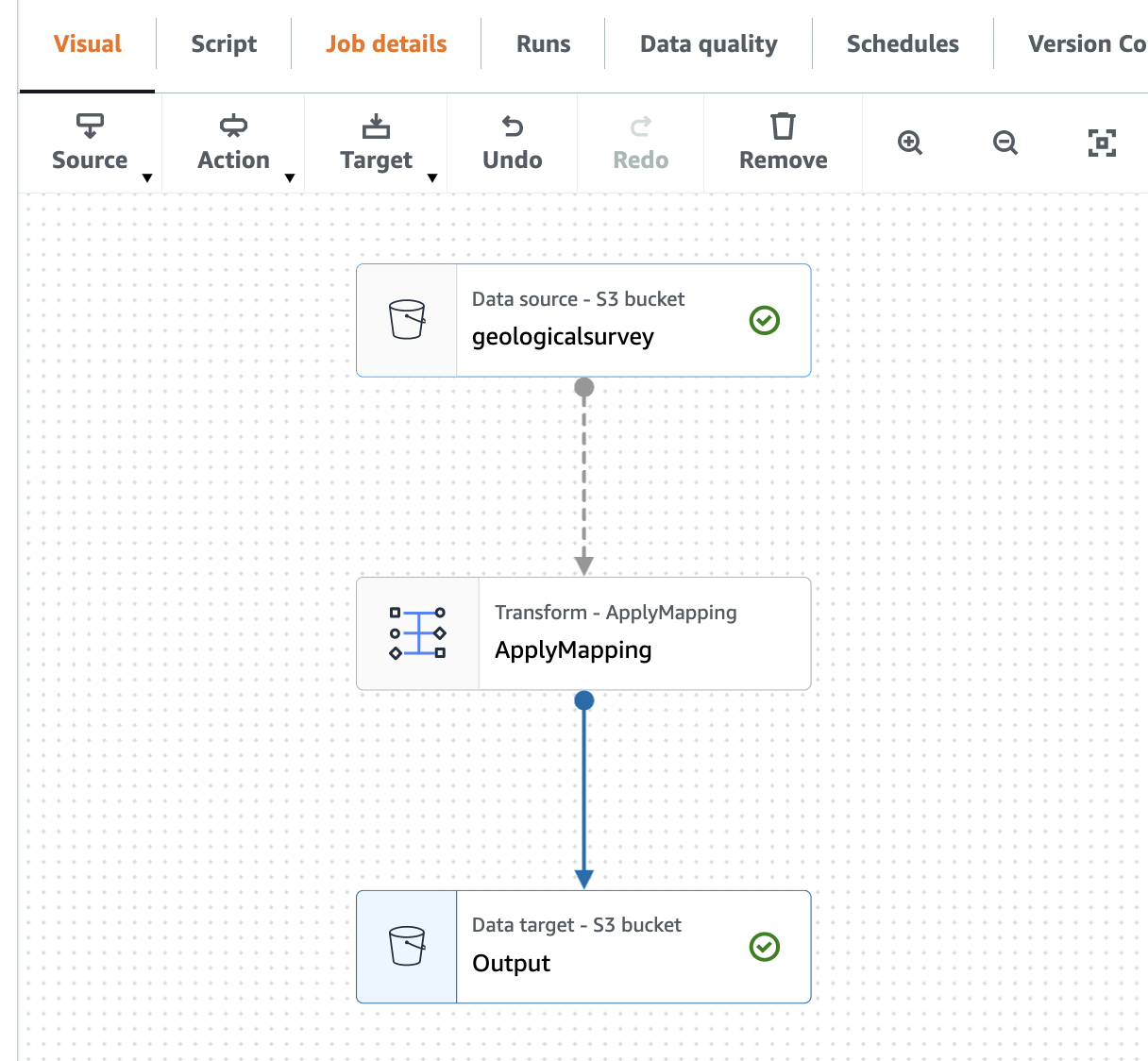
تصویر زیر کار را در ویرایشگر بصری نشان می دهد.
یک خزنده AWS Gue برای خزیدن در فایل پارکت ایجاد کنید
در این مرحله، یک خزنده AWS Glue ایجاد میکنید تا متادیتا را از فایل Parquet که با استفاده از یک کار AWS Glue Studio ایجاد کردهاید استخراج کنید. این بار از طبقه بندی پیش فرض استفاده می کنید. مراحل زیر را کامل کنید:
- در کنسول AWS Glue، را انتخاب کنید خزنده ها در صفحه ناوبری
- را انتخاب کنید خزنده ایجاد کنید.
- بر ویژگی های خزنده را تنظیم کنید صفحه، یک نام برای خزنده جدید، مانند وبلاگ-چسب-پارکت-مخاطب ارائه دهید، سپس انتخاب کنید بعدی.
- بر منابع داده و طبقه بندی کننده ها را انتخاب کنید صفحه، را انتخاب کنید نه هنوز برای پیکربندی منبع داده.
- را انتخاب کنید یک فروشگاه داده اضافه کنید.
- برای مسیر S3، مرور به
s3://${BUCKET_NAME}/output/parquet/.
مطمئن شوید که آن را انتخاب کرده اید parquet پوشه به جای فایل داخل پوشه.
- نقش IAM خود را که در قسمت پیش نیاز ایجاد شده است انتخاب کنید یا انتخاب کنید نقش IAM جدید ایجاد کنید (مثلا،
AWSGlueServiceNotebookRoleBlog) و انتخاب کنید بعدی. - بر خروجی و زمان بندی را تنظیم کنید صفحه، زیر پیکربندی خروجی، انتخاب کنید
blog_glue_xmlبرای پایگاه داده. - وارد
parquet_به عنوان پیشوند اضافه شده به جداول (اختیاری) و زیر برنامه خزنده، فرکانس را روی تنظیم نگه دارید بر اساس تقاضا. - را انتخاب کنید بعدی.
- تمام پارامترها را بررسی کرده و انتخاب کنید خزنده ایجاد کنید.
اکنون می توانید خزنده را اجرا کنید که تکمیل آن 1 تا 2 دقیقه طول می کشد.

شما می توانید طرح تازه ایجاد شده برای فایل Parquet را در کاتالوگ داده چسب AWS مشاهده کنید، که شبیه به طرحواره فایل XML است.
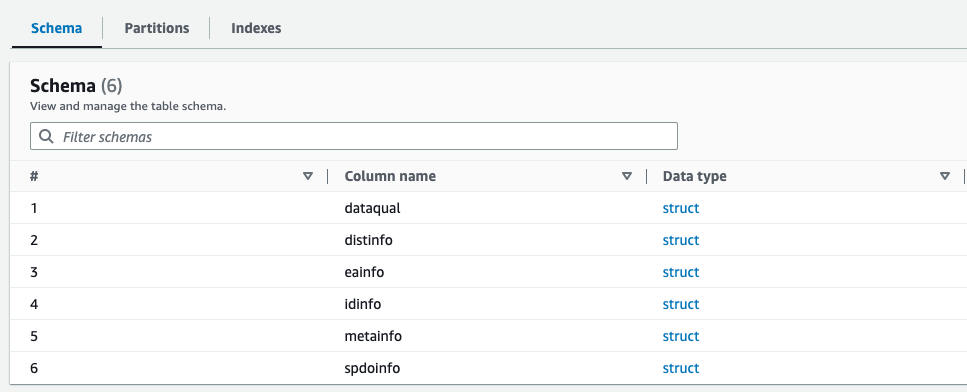
ما اکنون داده هایی داریم که برای استفاده با آتنا مناسب است. در بخش بعدی، کوئری های داده را با استفاده از Athena انجام می دهیم.
فایل پارکت را با استفاده از آتنا پرس و جو کنید
آتنا از پرس و جو پشتیبانی نمی کند فرمت فایل XMLبه همین دلیل است که فایل XML را برای جستجو و استفاده کارآمدتر از داده ها به پارکت تبدیل کردید نماد نقطه برای پرس و جو انواع پیچیده و ساختارهای تودرتو.
کد مثال زیر از نماد نقطه برای جستجوی داده های تودرتو استفاده می کند:
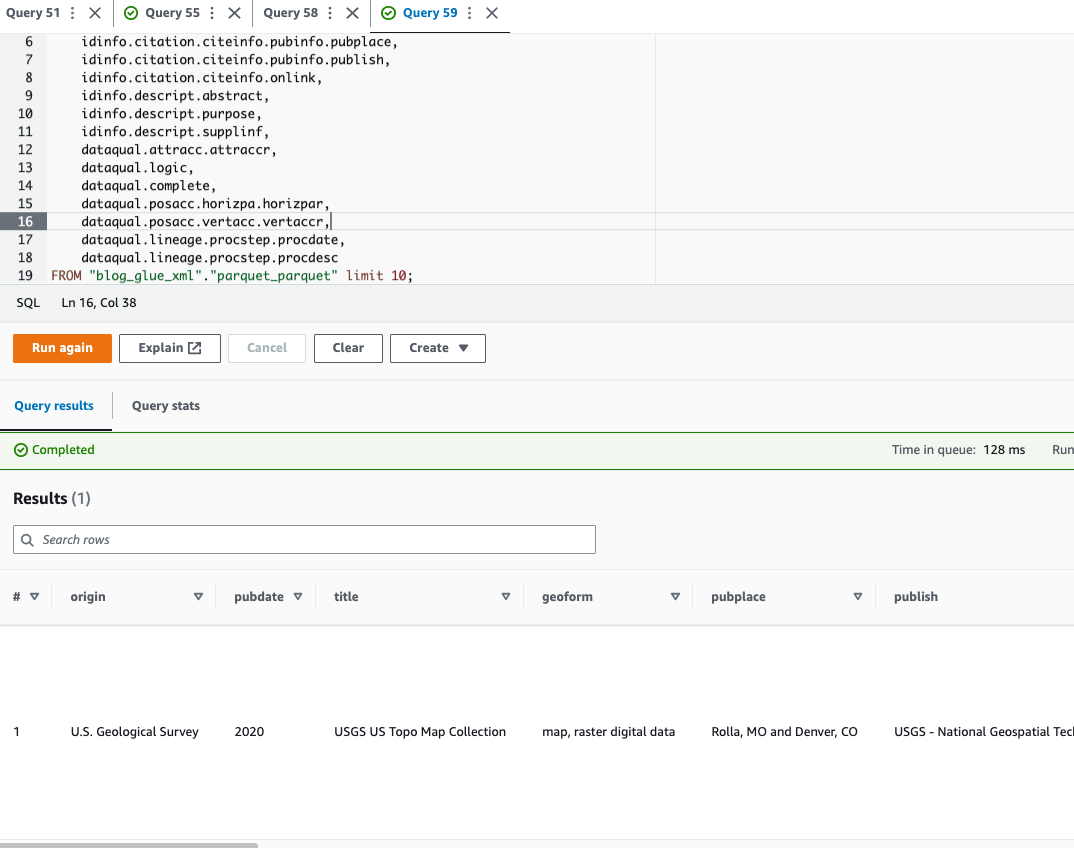
اکنون که تکنیک 1 را کامل کردیم، بیایید با تکنیک 2 آشنا شویم.
تکنیک 2: استفاده از AWS Glue DynamicFrames با طرحواره های استنباط شده و ثابت
در بخش قبل، فرآیند مدیریت یک فایل XML کوچک با استفاده از خزنده چسب AWS برای تولید جدول، کار چسب AWS برای تبدیل فایل به فرمت پارکت و آتنا برای دسترسی به دادههای پارکت را پوشش دادیم. با این حال، خزنده هنگام پردازش فایلهای XML با محدودیتهایی مواجه میشود که بیش از حد مجاز است حجم 1 مگابایت. در این بخش، به موضوع پردازش دستهای فایلهای XML بزرگتر میپردازیم، که نیاز به تجزیه بیشتر برای استخراج رویدادهای فردی و انجام تجزیه و تحلیل با استفاده از Athena دارد.
رویکرد ما شامل خواندن فایلهای XML از طریق چسب AWS است Dynamic Frames، از طرحواره های استنتاجی و ثابت استفاده می کند. سپس رویدادهای فردی را با استفاده از قالب پارکت استخراج می کنیم رابطه ای کردن تبدیل، ما را قادر می سازد تا با استفاده از Athena به طور یکپارچه آنها را پرس و جو و تجزیه و تحلیل کنیم.
برای پیاده سازی این راه حل، مراحل سطح بالا زیر را انجام دهید:
- برای خواندن و تجزیه و تحلیل فایل XML یک نوت بوک AWS Glue ایجاد کنید.
- استفاده کنید
DynamicFramesباInferSchemaبرای خواندن فایل XML - از تابع رابطهای برای جداسازی آرایهها استفاده کنید.
- داده ها را به فرمت پارکت تبدیل کنید.
- داده های پارکت را با استفاده از آتنا پرس و جو کنید.
- مراحل قبلی را تکرار کنید، اما این بار یک طرحواره را به آن ارسال کنید
DynamicFramesبجای استفاده ازInferSchema.
فایل XML داده جمعیت خودروهای الکتریکی دارای یک است response برچسب در سطح ریشه آن این تگ شامل آرایه ای از row برچسب هایی که درون آن قرار گرفته اند. تگ ردیف آرایهای است که شامل مجموعهای از تگهای ردیف دیگر است که اطلاعاتی در مورد یک وسیله نقلیه از جمله ساخت، مدل و سایر جزئیات مربوطه ارائه میکند. تصویر زیر یک مثال را نشان می دهد.

یک نوت بوک چسب AWS ایجاد کنید
برای ایجاد یک نوت بوک AWS Glue، مراحل زیر را انجام دهید:
- باز کردن AWS Glue Studio کنسول، انتخاب کنید شغل ها در صفحه ناوبری
- انتخاب کنید نوت بوک ژوپیتر و انتخاب کنید ساختن.
- یک نام برای کار چسب AWS خود وارد کنید، مانند
blog_glue_xml_job_Jupyter. - نقشی را که در پیش نیازها ایجاد کردید انتخاب کنید (
AWSGlueServiceNotebookRoleBlog).
نوت بوک AWS Glue همراه با یک مثال از قبل موجود است که نشان می دهد چگونه یک پایگاه داده را پرس و جو کنید و خروجی را در Amazon S3 بنویسید.
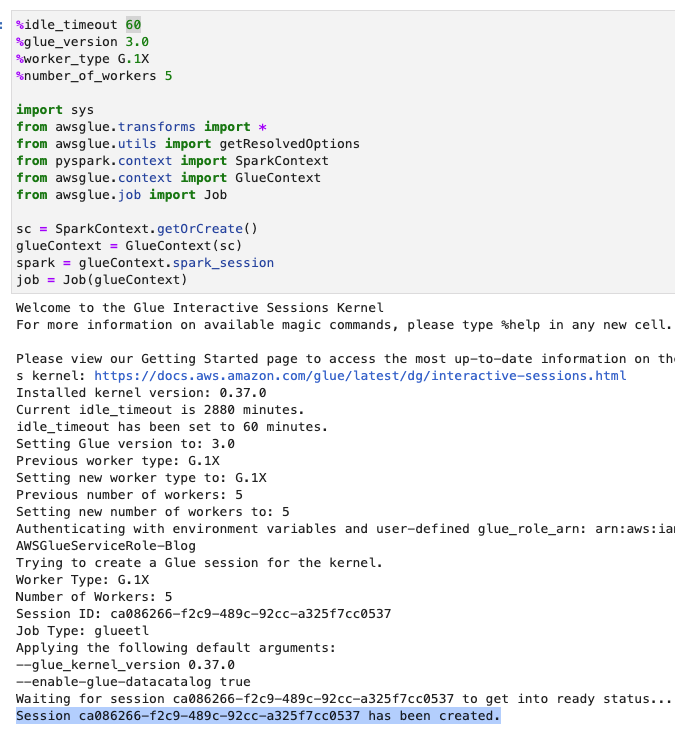
- همانطور که در تصویر زیر نشان داده شده است، تایم اوت را (در دقیقه) تنظیم کنید و سلول را اجرا کنید تا جلسه تعاملی AWS Glue ایجاد شود.
ایجاد متغیرهای اساسی
پس از ایجاد جلسه تعاملی، در انتهای نوت بوک، یک سلول جدید با متغیرهای زیر ایجاد کنید (نام سطل خود را ارائه دهید):
فایل XML استنباط کننده طرحواره را بخوانید
اگر شما طرحی را به DynamicFrame، شمای فایل ها را استنتاج می کند. برای خواندن داده ها با استفاده از یک فریم پویا، می توانید از دستور زیر استفاده کنید:
طرحواره DynamicFrame را چاپ کنید
طرحواره را با کد زیر چاپ کنید:
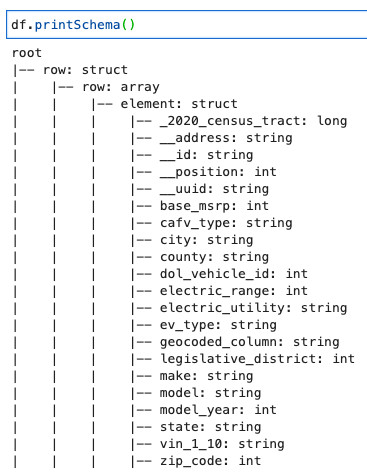
این طرح یک ساختار تودرتو با a را نشان می دهد row آرایه ای حاوی عناصر متعدد برای جدا کردن این ساختار در خطوط، می توانید از چسب AWS استفاده کنید رابطه ای کردن دگرگونی:
ما فقط به اطلاعات موجود در آرایه ردیف علاقه مند هستیم و می توانیم با استفاده از دستور زیر طرحواره را مشاهده کنیم:
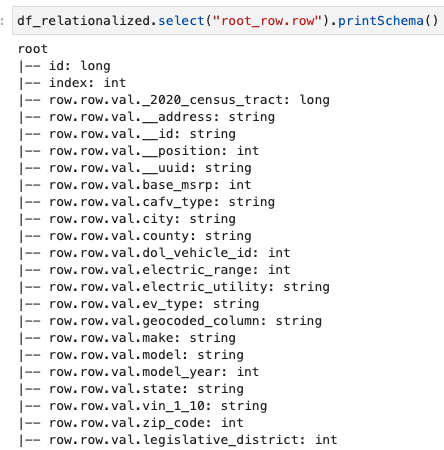
نام ستون ها شامل row.row، که با ساختار آرایه و ستون آرایه در مجموعه داده مطابقت دارد. ما نام ستون ها را در این پست تغییر نمی دهیم. برای دستورالعمل های انجام این کار، مراجعه کنید نگاشت پویا و تغییر نام نام ستون ها در فایل های داده را با استفاده از چسب AWS به صورت خودکار انجام دهید: قسمت 1. سپس می توانید داده ها را به فرمت Parquet تبدیل کنید و جدول AWS Glue را با استفاده از دستور زیر ایجاد کنید:
چسب AWS DynamicFrame ویژگی هایی را ارائه می دهد که می توانید در اسکریپت ETL خود برای ایجاد و به روز رسانی طرحواره در کاتالوگ داده استفاده کنید. ما استفاده می کنیم updateBehavior پارامتر برای ایجاد جدول به طور مستقیم در کاتالوگ داده. با این رویکرد، پس از اتمام کار چسب AWS، نیازی به اجرای خزنده چسب AWS نداریم.

با تنظیم یک طرح، فایل XML را بخوانید
یک راه جایگزین برای خواندن فایل، از پیش تعریف یک طرح واره است. برای این کار مراحل زیر را انجام دهید:
- انواع داده AWS Glue را وارد کنید:
- یک طرحواره برای فایل XML ایجاد کنید:
- هنگام خواندن فایل XML، طرحواره را پاس کنید:
- مجموعه داده را مانند قبل از هم جدا کنید:
- مجموعه داده را به Parquet تبدیل کنید و جدول AWS Glue را ایجاد کنید:
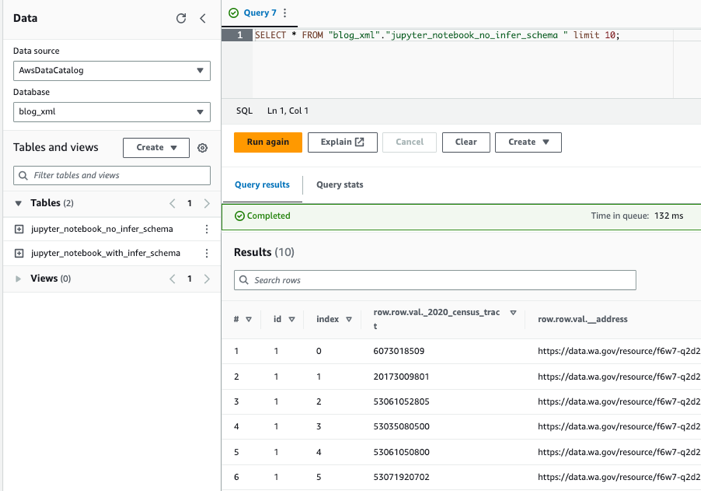
جداول را با استفاده از آتنا پرس و جو کنید
اکنون که هر دو جدول را ایجاد کرده ایم، می توانیم جداول را با استفاده از Athena پرس و جو کنیم. به عنوان مثال می توانیم از کوئری زیر استفاده کنیم:
پاکسازی
در این پست، یک نقش IAM، یک نوت بوک AWS Glue Jupyter و دو جدول در کاتالوگ داده چسب AWS ایجاد کردیم. ما همچنین تعدادی فایل را در یک سطل S3 آپلود کردیم. برای تمیز کردن این اشیا، مراحل زیر را انجام دهید:
- در کنسول IAM، نقشی را که ایجاد کردید حذف کنید.
- در کنسول AWS Glue Studio، طبقهبندیکننده سفارشی، خزنده، مشاغل ETL و نوتبوک Jupyter را حذف کنید.
- به کاتالوگ داده چسب AWS بروید و جداول ایجاد شده را حذف کنید.
- در کنسول آمازون S3، به سطلی که ایجاد کرده اید بروید و پوشه های نامگذاری شده را حذف کنید
temp,infer_schemaوno_infer_schema.
گیرنده های کلیدی
در چسب AWS، یک ویژگی به نام وجود دارد InferSchema در چسب AWS DynamicFrames. این به طور خودکار ساختار یک قاب داده را بر اساس داده هایی که در آن موجود است مشخص می کند. در مقابل، تعریف طرحواره به معنای بیان صریح ساختار قاب داده قبل از بارگذاری داده ها است.
XML که یک قالب مبتنی بر متن است، انواع داده های ستون های خود را محدود نمی کند. این می تواند مشکلاتی را در عملکرد InferSchema ایجاد کند. به عنوان مثال، در اولین اجرا، یک فایل با ستون A با مقدار 2 منجر به یک فایل Parquet با ستون A به عنوان یک عدد صحیح می شود. در اجرای دوم، یک فایل جدید دارای ستون A با مقدار C است که منجر به یک فایل Parquet با ستون A به عنوان رشته می شود. اکنون دو فایل در S3 وجود دارد که هر کدام دارای ستون A با انواع داده های مختلف است که می تواند مشکلاتی را در پایین دست ایجاد کند.
همین امر در مورد انواع داده های پیچیده مانند ساختارهای تودرتو یا آرایه ها اتفاق می افتد. به عنوان مثال، اگر یک فایل دارای یک ورودی برچسب نامیده شده باشد transaction، به عنوان یک ساختار استنباط می شود. اما اگر فایل دیگری دارای تگ مشابه باشد، به عنوان یک آرایه استنباط می شود
با وجود این مشکلات نوع داده، InferSchema زمانی مفید است که شما طرحواره را نمی دانید یا تعریف آن به صورت دستی غیرعملی است. با این حال، برای مجموعه داده های بزرگ یا دائماً در حال تغییر ایده آل نیست. تعریف یک طرحواره دقیق تر است، به خصوص با انواع داده های پیچیده، اما مسائل خاص خود را دارد، مانند نیاز به تلاش دستی و انعطاف ناپذیر بودن در برابر تغییرات داده ها.
InferSchema دارای محدودیت هایی مانند استنتاج نادرست نوع داده و مشکلات مربوط به مدیریت مقادیر تهی است. تعریف یک طرحواره محدودیت هایی مانند تلاش دستی و خطاهای احتمالی نیز دارد.
انتخاب بین استنباط و تعریف طرحواره به نیازهای پروژه بستگی دارد. InferSchema برای کاوش سریع مجموعه داده های کوچک عالی است، در حالی که تعریف یک طرح واره برای مجموعه داده های بزرگتر و پیچیده که نیاز به دقت و سازگاری دارند بهتر است. مبادلات و محدودیت های هر روش را در نظر بگیرید تا بهترین گزینه را برای پروژه شما انتخاب کنید.
نتیجه
در این پست، ما دو تکنیک را برای مدیریت دادههای XML با استفاده از چسب AWS بررسی کردیم که هر کدام برای رفع نیازها و چالشهایی که ممکن است با آنها روبرو شوید طراحی شدهاند.
Technique 1 یک مسیر کاربرپسند را برای کسانی که یک رابط گرافیکی را ترجیح می دهند ارائه می دهد. میتوانید از خزنده چسب AWS و ویرایشگر بصری برای تعریف بدون زحمت ساختار جدول برای فایلهای XML خود استفاده کنید. این رویکرد فرآیند مدیریت داده ها را ساده می کند و به ویژه برای کسانی که به دنبال راهی ساده برای مدیریت داده های خود هستند جذاب است.
با این حال، میدانیم که خزنده محدودیتهای خود را دارد، بهویژه وقتی با فایلهای XML سروکار داریم که ردیفهای بزرگتر از ۱ مگابایت دارند. اینجاست که تکنیک 1 به کمک می آید. با مهار چسب AWS DynamicFrames با طرحوارههای استنباطشده و ثابت، و استفاده از یک نوتبوک چسب AWS، میتوانید فایلهای XML را با هر اندازهای کارآمد مدیریت کنید. این روش یک راه حل قوی ارائه می دهد که پردازش یکپارچه را حتی برای فایل های XML با ردیف های بیش از محدودیت 1 مگابایت تضمین می کند.
همانطور که در دنیای مدیریت داده ها پیمایش می کنید، داشتن این تکنیک ها در جعبه ابزار به شما این امکان را می دهد که بر اساس نیازهای خاص پروژه خود تصمیمات آگاهانه بگیرید. چه سادگی تکنیک 1 را ترجیح دهید یا مقیاس پذیری تکنیک 2، چسب AWS انعطاف پذیری لازم را برای مدیریت موثر داده های XML فراهم می کند.
درباره نویسنده
 ناونیت شوکلابه عنوان یک معمار راه حل متخصص AWS با تمرکز بر تجزیه و تحلیل عمل می کند. او اشتیاق زیادی برای کمک به مشتریان در کشف بینش های ارزشمند از داده های آنها دارد. او از طریق تخصص خود، راه حل های نوآورانه ای ایجاد می کند که کسب و کارها را برای دستیابی به انتخاب های آگاهانه و مبتنی بر داده ها توانمند می کند. شایان ذکر است، ناونیت شوکلا نویسنده برجسته کتابی با عنوان «جدال داده در AWS است.
ناونیت شوکلابه عنوان یک معمار راه حل متخصص AWS با تمرکز بر تجزیه و تحلیل عمل می کند. او اشتیاق زیادی برای کمک به مشتریان در کشف بینش های ارزشمند از داده های آنها دارد. او از طریق تخصص خود، راه حل های نوآورانه ای ایجاد می کند که کسب و کارها را برای دستیابی به انتخاب های آگاهانه و مبتنی بر داده ها توانمند می کند. شایان ذکر است، ناونیت شوکلا نویسنده برجسته کتابی با عنوان «جدال داده در AWS است.
 پاتریک مولر به عنوان یک معمار ارشد آزمایشگاه داده در AWS کار می کند. مسئولیت اصلی او کمک به مشتریان در تبدیل ایده های خود به محصول داده آماده تولید است. پاتریک در اوقات فراغت خود از بازی فوتبال، تماشای فیلم و مسافرت لذت می برد.
پاتریک مولر به عنوان یک معمار ارشد آزمایشگاه داده در AWS کار می کند. مسئولیت اصلی او کمک به مشتریان در تبدیل ایده های خود به محصول داده آماده تولید است. پاتریک در اوقات فراغت خود از بازی فوتبال، تماشای فیلم و مسافرت لذت می برد.
 عموغ گایکواد یک توسعه دهنده ارشد راه حل در خدمات وب آمازون است. او به مشتریان جهانی کمک می کند تا راه حل های AI/ML را در AWS بسازند و به کار گیرند. کار او عمدتاً بر روی بینایی کامپیوتر و پردازش زبان طبیعی و کمک به مشتریان برای بهینهسازی حجم کاری AI/ML برای پایداری متمرکز است. عموق فوق لیسانس خود را در رشته علوم کامپیوتر با تخصص در یادگیری ماشین دریافت کرده است.
عموغ گایکواد یک توسعه دهنده ارشد راه حل در خدمات وب آمازون است. او به مشتریان جهانی کمک می کند تا راه حل های AI/ML را در AWS بسازند و به کار گیرند. کار او عمدتاً بر روی بینایی کامپیوتر و پردازش زبان طبیعی و کمک به مشتریان برای بهینهسازی حجم کاری AI/ML برای پایداری متمرکز است. عموق فوق لیسانس خود را در رشته علوم کامپیوتر با تخصص در یادگیری ماشین دریافت کرده است.
 شیلا سونونه یک معمار مقیم ارشد در AWS است. او به مشتریان AWS کمک میکند تا انتخابهای آگاهانه و مبادلهای درباره سرعت بخشیدن به دادهها، تحلیلها، و حجم کاری و پیادهسازی AI/ML داشته باشند. او در اوقات فراغت خود از گذراندن وقت با خانواده اش لذت می برد - معمولاً در زمین های تنیس.
شیلا سونونه یک معمار مقیم ارشد در AWS است. او به مشتریان AWS کمک میکند تا انتخابهای آگاهانه و مبادلهای درباره سرعت بخشیدن به دادهها، تحلیلها، و حجم کاری و پیادهسازی AI/ML داشته باشند. او در اوقات فراغت خود از گذراندن وقت با خانواده اش لذت می برد - معمولاً در زمین های تنیس.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- درباره ما
- چکیده
- تسریع
- دسترسی
- دسترسی
- انجام
- دقت
- در میان
- عمل
- اضافه کردن
- اضافه
- اضافی
- نشانی
- پس از
- سن
- AI / ML
- معرفی
- اجازه دادن
- اجازه دادن
- اجازه می دهد تا
- همچنین
- جایگزین
- آمازون
- آمازون آتنا
- آمازون خدمات وب
- an
- تحلیل
- علم تجزیه و تحلیل
- تحلیل
- تجزیه و تحلیل
- و
- دیگر
- هر
- آپاچی
- جذاب
- برنامه های کاربردی
- درخواست
- روش
- رویکردها
- معماری
- هستند
- صف
- AS
- همکاری
- کمک کردن
- At
- نویسنده
- بطور خودکار
- در دسترس
- AWS
- چسب AWS
- به عقب
- مستقر
- اساسی
- BE
- زیرا
- قبل از
- شروع
- بودن
- بهترین
- بهتر
- میان
- سفید
- کتاب
- هر دو
- ساختن
- کسب و کار
- اما
- by
- نام
- CAN
- کاتالوگ
- علت
- سلول
- چالش ها
- تغییر دادن
- تبادل
- متغیر
- انتخاب
- را انتخاب کنید
- شهر:
- طبقه بندی
- مشتریان
- رمز
- ستون
- ستون ها
- COM
- می آید
- مشترک
- عموما
- کامل
- تکمیل شده
- پیچیده
- کامپیوتر
- علم کامپیوتر
- چشم انداز کامپیوتر
- شرط
- رفتار
- پیوستگی
- در نظر بگیرید
- کنسول
- به طور مداوم
- محدودیت ها
- ساختن
- شامل
- موجود
- شامل
- کنتراست
- کنترل
- تبدیل
- مبدل
- مقرون به صرفه
- راه حل مقرون به صرفه
- شهرستان
- دادگاه
- پوشش داده شده
- خزنده
- ایجاد
- ایجاد شده
- ایجاد
- بسیار سخت
- سفارشی
- مشتری
- مشتریان
- داده ها
- یکپارچه سازی داده ها
- مدیریت اطلاعات
- داده محور
- پایگاه داده
- مجموعه داده ها
- معامله
- تصمیم گیری
- به طور پیش فرض
- تعريف كردن
- تعریف کردن
- غرق کردن
- نشان می دهد
- بستگی دارد
- گسترش
- طراحی
- دقیق
- جزئیات
- توسعه دهنده
- مختلف
- مشکل
- دیجیتال
- عصر دیجیتال
- مستقیما
- کشف
- متمایز
- do
- نمی کند
- انجام شده
- آیا
- DOT
- در طی
- پویا
- هر
- سهولت
- به آسانی
- ساده
- سردبیر
- اثر
- به طور موثر
- بهره وری
- موثر
- موثر
- تلاش
- زحمت
- برقی
- خودرو الکتریکی
- عناصر
- استخدام
- قدرت دادن
- توانمندسازی
- خالی
- قادر ساختن
- را قادر می سازد
- رویارویی
- پایان
- موتورهای حرفه ای
- بالا بردن
- اطمینان حاصل شود
- تضمین می کند
- وارد
- اشتیاق
- ورود
- خطاهای
- به خصوص
- اتر (ETH)
- حتی
- حوادث
- هر
- مثال
- تجاوز
- مبادله
- تخصص
- اکتشاف
- اکتشاف
- کشف
- عصاره
- استخراج
- خانواده
- ویژگی
- امکانات
- آمار و ارقام
- پرونده
- فایل ها
- سرمایه گذاری
- نام خانوادگی
- ثابت
- انعطاف پذیری
- تمرکز
- متمرکز شده است
- پیروی
- برای
- قالب
- FRAME
- رایگان
- فرکانس
- از جانب
- تابع
- افزایش
- همه منظوره
- تولید می کنند
- جهانی
- Go
- هدف
- دولت
- بزرگ
- دسته
- اداره
- اتفاق می افتد
- بهره برداری
- آیا
- داشتن
- he
- بهداشت و درمان
- قلب
- کمک
- کمک
- کمک می کند
- او
- در سطح بالا
- خیلی
- خود را
- چگونه
- چگونه
- اما
- HTML
- HTTP
- HTTPS
- IAM
- دلخواه
- ایده ها
- هویت
- if
- نشان می دهد
- انجام
- پیاده سازی ها
- اجرای
- واردات
- بهبود
- بهبود یافته
- in
- از جمله
- فرد
- افراد
- لوازم
- اطلاعات
- اطلاع
- شالوده
- ابتکاری
- داخل
- بینش
- در عوض
- دستورالعمل
- ادغام
- ادغام
- تعاملی
- علاقه مند
- رابط
- به
- شامل
- مسائل
- IT
- ITS
- کار
- شغل ها
- JPG
- json
- نوت بوک ژوپیتر
- نگاه داشتن
- دانستن
- آزمایشگاه
- زبان
- بزرگ
- بزرگتر
- برجسته
- یاد گرفتن
- یادگیری
- سطح
- پسندیدن
- محدود
- محدودیت
- محدودیت
- لاین
- خطوط
- بار
- بارگیری
- منطق
- به دنبال
- دستگاه
- فراگیری ماشین
- اصلی
- عمدتا
- ساخت
- ساخت
- مدیریت
- مدیریت
- کتابچه راهنمای
- دستی
- بسیاری
- نقشه برداری
- کارشناسی ارشد
- ممکن است..
- به معنی
- فهرست
- متاداده
- روش
- دقیقه
- مدل
- بیش
- کارآمدتر
- اکثر
- حرکت
- فیلم ها
- چندگانه
- نام
- تحت عنوان
- نام
- طبیعی
- زبان طبیعی
- پردازش زبان طبیعی
- هدایت
- جهت یابی
- لازم
- نیاز
- نیازهای
- جدید
- به تازگی
- بعد
- به ویژه
- دفتر یادداشت
- اکنون
- عدد
- اشیاء
- of
- پیشنهادات
- on
- ONE
- فقط
- عملیات
- بهینه
- بهینه سازی
- بهینه سازی می کند
- گزینه
- or
- سفارش
- سازمان های
- منشاء
- دیگر
- ما
- خارج
- تولید
- روی
- غلبه بر
- خود
- با ما
- قطعه
- پارامتر
- پارامترهای
- بخش
- ویژه
- عبور
- مسیر
- پاتریک
- انجام دادن
- کارایی
- مجوز
- انتخاب کنید
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازی
- سیاست
- جمعیت
- داشتن
- پست
- پتانسیل
- دقیق
- ترجیح می دهند
- پیش نیازها
- پیش نمایش
- قبلی
- مشکلات
- روند
- پردازش
- در حال پردازش
- محصول
- پروژه
- پروژه ها
- املاک
- ارائه
- فراهم می کند
- منتشر کردن
- هدف
- پــایتــون
- نمایش ها
- سریع
- نسبتا
- خواندن
- به راحتی
- مطالعه
- دلایل
- اخذ شده
- شناختن
- مراجعه
- مربوط
- مورد نیاز
- نجات
- منابع
- پاسخ
- مسئوليت
- REST
- محدود کردن
- محدودیت
- نتایج
- تنومند
- نقش
- ریشه
- ROW
- دویدن
- همان
- ذخیره
- اسکالا
- مقیاس پذیری
- مقیاس پذیر
- علم
- خط
- بدون درز
- یکپارچه
- دوم
- بخش
- دیدن
- ارشد
- خدمات
- جلسه
- تنظیم
- محیط
- چند
- او
- صدف
- باید
- نشان
- نشان داده شده
- نشان می دهد
- مشابه
- ساده
- سادگی
- ساده
- تنها
- اندازه
- کوچک
- So
- فوتبال
- راه حل
- مزایا
- برخی از
- منبع
- منابع
- جرقه
- متخصص
- متخصص
- خاص
- به طور خاص
- سرعت
- هزینه
- SQL
- استاندارد
- شروع می شود
- دولت
- بیانیه
- حاکی
- گام
- مراحل
- ذخیره سازی
- ذخیره شده
- ساده
- ساده کردن
- رشته
- قوی
- ساختار
- ساختار
- استودیو
- موفقیت
- چنین
- مناسب
- پشتیبانی
- مطمئن
- پایداری
- سیستم های
- جدول
- TAG
- طراحی شده
- گرفتن
- طول می کشد
- وظایف
- تکنیک
- تنیس
- نسبت به
- که
- La
- اطلاعات
- جهان
- شان
- آنها
- سپس
- آنجا.
- اینها
- آنها
- این
- کسانی که
- از طریق
- زمان
- عنوان
- با عنوان
- به
- امروز
- ابزار
- بالا
- موضوع
- دگرگون کردن
- دگرگونی
- سفر
- عطف
- آموزش
- دو
- نوع
- انواع
- نهایی
- زیر
- بروزرسانی
- به روز شده
- آپلود شده
- us
- قابلیت استفاده
- استفاده کنید
- استفاده
- کاربر
- رابط کاربری
- کاربر پسند
- استفاده
- با استفاده از
- معمولا
- با استفاده از
- ارزشمند
- ارزش
- ارزشها
- وسیله نقلیه
- نسخه
- از طريق
- چشم انداز
- نمایش ها
- دید
- تماشای
- مسیر..
- we
- وب
- خدمات وب
- چی
- چه زمانی
- در حالیکه
- چه
- که
- WHO
- چرا
- اراده
- با
- در داخل
- بدون
- مهاجرت کاری
- گردش کار
- گردش کار
- با این نسخهها کار
- جهان
- نوشتن
- XML
- شما
- شما
- زفیرنت