در چند سال اخیر، مدلهای زبان بزرگ (LLM) به عنوان ابزارهای برجستهای که قادر به درک، تولید و دستکاری متن با مهارت بیسابقه هستند، مطرح شدهاند. کاربردهای بالقوه آنها از عوامل مکالمه تا تولید محتوا و بازیابی اطلاعات را در بر می گیرد و نوید انقلابی در تمام صنایع را می دهد. با این حال، استفاده از این پتانسیل در حالی که حصول اطمینان از استفاده مسئولانه و مؤثر از این مدلها به فرآیند حیاتی ارزیابی LLM بستگی دارد. ارزیابی وظیفه ای است که برای اندازه گیری کیفیت و مسئولیت خروجی یک سرویس LLM یا هوش مصنوعی مولد استفاده می شود. ارزیابی LLM ها نه تنها با تمایل به درک عملکرد یک مدل، بلکه با نیاز به پیاده سازی هوش مصنوعی مسئول و نیاز به کاهش خطر ارائه اطلاعات نادرست یا محتوای مغرضانه و به حداقل رساندن تولید مضر، ناامن، مخرب و غیراخلاقی انگیزه دارد. محتوا. علاوه بر این، ارزیابی LLM ها همچنین می تواند به کاهش خطرات امنیتی کمک کند، به ویژه در زمینه دستکاری سریع داده ها. برای برنامههای مبتنی بر LLM، شناسایی آسیبپذیریها و اجرای تدابیر حفاظتی که در برابر نقضهای احتمالی و دستکاریهای غیرمجاز دادهها محافظت میکند، بسیار مهم است.
با ارائه ابزارهای ضروری برای ارزیابی LLM ها با یک پیکربندی ساده و رویکرد یک کلیک، Amazon SageMaker Clarify قابلیت های ارزیابی LLM به مشتریان امکان دسترسی به بیشتر مزایای ذکر شده را می دهد. با در دست داشتن این ابزارها، چالش بعدی ادغام ارزیابی LLM در چرخه حیات یادگیری ماشین و عملیات (MLOps) برای دستیابی به اتوماسیون و مقیاسپذیری در فرآیند است. در این پست، ما به شما نشان می دهیم که چگونه ارزیابی Amazon SageMaker Clarify LLM را با Amazon SageMaker Pipelines ادغام کنید تا ارزیابی LLM را در مقیاس فعال کنید. علاوه بر این، ما نمونه کدی را در این مورد ارائه می دهیم GitHub مخزن به کاربران امکان می دهد تا با استفاده از نمونه هایی مانند Llama2-7b-f، Falcon-7b، و مدل های Llama2-7b دقیق تنظیم شده، ارزیابی موازی چند مدل را در مقیاس انجام دهند.
چه کسی باید ارزیابی LLM را انجام دهد؟
هرکسی که یک LLM از پیش آموزش دیده را آموزش می دهد، تنظیم دقیق می کند یا به سادگی از آن استفاده می کند، باید آن را به دقت ارزیابی کند تا رفتار برنامه ای که توسط آن LLM طراحی شده است را ارزیابی کند. بر اساس این اصل، میتوانیم کاربران هوش مصنوعی مولد را که به قابلیتهای ارزیابی LLM نیاز دارند، در 3 گروه طبقهبندی کنیم که در شکل زیر نشان داده شده است: ارائهدهندگان مدل، تیونرهای دقیق و مصرفکنندگان.
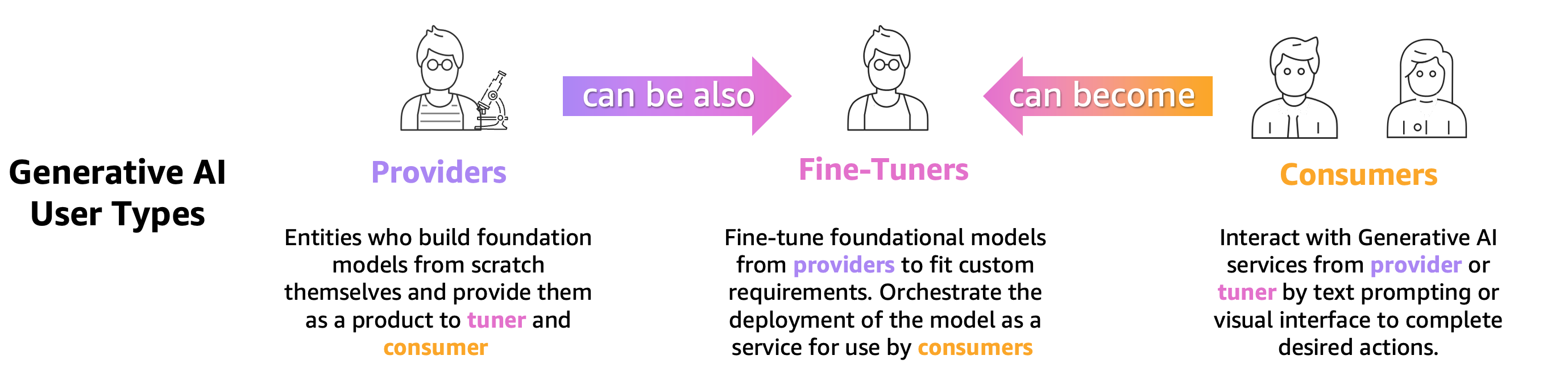
- ارائه دهندگان مدل بنیادی (FM). مدل های قطار که همه منظوره هستند. این مدل ها را می توان برای بسیاری از کارهای پایین دستی، مانند استخراج ویژگی یا تولید محتوا، استفاده کرد. هر مدل آموزش دیده نه تنها برای ارزیابی عملکرد خود، بلکه برای مقایسه آن با سایر مدل های موجود، شناسایی مناطقی که نیاز به بهبود دارند و در نهایت، پیگیری پیشرفت ها در این زمینه، باید در مقابل بسیاری از وظایف محک زده شود. ارائه دهندگان مدل همچنین باید وجود هرگونه سوگیری را بررسی کنند تا از کیفیت مجموعه داده شروع و رفتار صحیح مدل خود اطمینان حاصل کنند. جمع آوری داده های ارزیابی برای ارائه دهندگان مدل حیاتی است. علاوه بر این، این داده ها و معیارها باید برای مطابقت با مقررات آتی جمع آوری شوند. ISO 42001از دستور اجرایی دولت بایدنو قانون هوش مصنوعی اتحادیه اروپا استانداردها، ابزارها و آزمایشهایی را توسعه دهید تا مطمئن شوید که سیستمهای هوش مصنوعی ایمن، مطمئن و قابل اعتماد هستند. به عنوان مثال، قانون هوش مصنوعی اتحادیه اروپا وظیفه دارد اطلاعاتی را در مورد اینکه کدام مجموعه داده برای آموزش استفاده می شود، قدرت محاسباتی مورد نیاز برای اجرای مدل، گزارش نتایج مدل در برابر معیارهای استاندارد عمومی/صنعتی و به اشتراک گذاشتن نتایج آزمایش های داخلی و خارجی ارائه کند.
- مدل تنظیم کننده های دقیق می خواهید وظایف خاصی را حل کنید (مثلاً طبقه بندی احساسات، خلاصه سازی، پاسخ به سؤال) و همچنین مدل های از پیش آموزش دیده برای اتخاذ وظایف خاص حوزه. آنها به معیارهای ارزیابی تولید شده توسط ارائه دهندگان مدل نیاز دارند تا مدل از پیش آموزش دیده مناسب را به عنوان نقطه شروع انتخاب کنند.
آنها باید مدلهای تنظیمشده خود را در برابر مورد مورد نظر خود با مجموعه دادههای خاص وظیفه یا دامنه ارزیابی کنند. اغلب، آنها باید مجموعه دادههای خصوصی خود را مدیریت و ایجاد کنند، زیرا مجموعه دادههای در دسترس عموم، حتی آنهایی که برای یک کار خاص طراحی شدهاند، ممکن است به اندازه کافی تفاوتهای ظریف مورد نیاز برای مورد استفاده خاص خود را دریافت نکنند.
تنظیم دقیق سریعتر و ارزانتر از آموزش کامل است و به تکرار عملیاتی سریعتر برای استقرار و آزمایش نیاز دارد، زیرا مدلهای کاندید زیادی معمولاً تولید میشوند. ارزیابی این مدل ها امکان بهبود مستمر مدل، کالیبراسیون و اشکال زدایی را فراهم می کند. توجه داشته باشید که تیونرهای دقیق زمانی که برنامه های کاربردی دنیای واقعی را توسعه می دهند، می توانند مصرف کننده مدل های خود شوند. - مدل مصرف کنندگان یا توسعه دهندگان مدل، با هدف ارتقای برنامه ها یا خدمات خود از طریق پذیرش LLM، مدل های با هدف کلی یا تنظیم دقیق را در تولید خدمت و نظارت می کنند. اولین چالشی که آنها دارند این است که اطمینان حاصل کنند که LLM انتخاب شده با نیازهای خاص، هزینه و انتظارات عملکرد آنها مطابقت دارد. تفسیر و درک خروجی های مدل یک نگرانی دائمی است، به ویژه هنگامی که حریم خصوصی و امنیت داده ها درگیر هستند (مثلاً برای حسابرسی ریسک و انطباق در صنایع تحت نظارت، مانند بخش مالی). ارزیابی مستمر مدل برای جلوگیری از انتشار سوگیری یا محتوای مضر بسیار مهم است. با اجرای یک چارچوب نظارت و ارزیابی قوی، مصرف کنندگان مدل می توانند به طور فعال رگرسیون را در LLM ها شناسایی کرده و به آن رسیدگی کنند و اطمینان حاصل کنند که این مدل ها اثربخشی و قابلیت اطمینان خود را در طول زمان حفظ می کنند.
نحوه انجام ارزیابی LLM
ارزیابی مدل موثر شامل سه جزء اساسی است: یک یا چند FM یا مدل های تنظیم شده برای ارزیابی مجموعه داده های ورودی (اعلان ها، مکالمات یا ورودی های منظم) و منطق ارزیابی.
برای انتخاب مدلها برای ارزیابی، عوامل مختلفی از جمله ویژگیهای داده، پیچیدگی مسئله، منابع محاسباتی موجود و نتیجه مطلوب باید در نظر گرفته شود. داده های ورودی داده های لازم برای آموزش، تنظیم دقیق و آزمایش مدل انتخاب شده را فراهم می کند. بسیار مهم است که این ذخیرهگاه داده دارای ساختار، نماینده و با کیفیت بالا باشد، زیرا عملکرد مدل به شدت به دادههایی که از آن یاد میگیرد بستگی دارد. در نهایت، منطق ارزیابی معیارها و معیارهای مورد استفاده برای ارزیابی عملکرد مدل را تعریف می کند.
این سه جزء با هم یک چارچوب منسجم را تشکیل میدهند که ارزیابی دقیق و سیستماتیک مدلهای یادگیری ماشین را تضمین میکند و در نهایت منجر به تصمیمگیری آگاهانه و بهبود اثربخشی مدل میشود.
تکنیک های ارزیابی مدل هنوز یک زمینه فعال تحقیقاتی است. بسیاری از معیارها و چارچوب های عمومی توسط جامعه محققین در چند سال گذشته برای پوشش طیف وسیعی از وظایف و سناریوها مانند GLUE, SuperGLUE, سلام, MMLU و نیمکت بزرگ. این معیارها دارای تابلوهای امتیازاتی هستند که می توان از آنها برای مقایسه و مقایسه مدل های ارزیابی شده استفاده کرد. معیارها، مانند HELM، همچنین با هدف ارزیابی معیارها فراتر از اندازهگیریهای دقت، مانند دقت یا امتیاز F1 هستند. معیار HELM شامل معیارهایی برای انصاف، سوگیری و سمیت است که اهمیت یکسانی در امتیاز ارزیابی مدل کلی دارند.
همه این معیارها شامل مجموعهای از معیارها هستند که نحوه عملکرد مدل را در یک کار خاص اندازهگیری میکنند. معروف ترین و رایج ترین معیارها هستند RED (مطالعه فراخوانی گرا برای ارزیابی Gisting)، بلو (دو زبانی Evaluation Understudy)، یا شهاب (متریک برای ارزیابی ترجمه با ترتیب صریح). این معیارها به عنوان یک ابزار مفید برای ارزیابی خودکار عمل میکنند و معیارهای کمی تشابه واژگانی بین متن تولید شده و متن مرجع را ارائه میدهند. با این حال، آنها وسعت کامل تولید زبان شبیه انسان را که شامل درک معنایی، زمینه یا ظرافت های سبکی است، در بر نمی گیرند. به عنوان مثال، HELM جزئیات ارزیابی مربوط به موارد استفاده خاص، راهحلهایی برای آزمایش اعلانهای سفارشی، و نتایجی که به راحتی توسط افراد غیرمتخصص استفاده میشوند را ارائه نمیکند، زیرا این فرآیند میتواند پرهزینه باشد، مقیاسپذیری آن آسان نیست، و فقط برای کارهای خاص.
علاوه بر این، دستیابی به تولید زبانی شبیه به انسان اغلب نیاز به ادغام انسان در حلقه دارد تا ارزیابیهای کیفی و قضاوت انسانی را تکمیل کند تا معیارهای دقت خودکار را تکمیل کند. ارزیابی انسانی روشی ارزشمند برای ارزیابی خروجیهای LLM است، اما همچنین میتواند ذهنی و مستعد سوگیری باشد، زیرا ارزیابهای انسانی مختلف ممکن است نظرات و تفسیرهای مختلفی از کیفیت متن داشته باشند. علاوه بر این، ارزیابی انسانی می تواند منابع فشرده و پرهزینه باشد و می تواند زمان و تلاش قابل توجهی را طلب کند.
بیایید عمیقاً بررسی کنیم که چگونه Amazon SageMaker Clarify به طور یکپارچه نقاط را به هم متصل می کند و به مشتریان در انجام ارزیابی و انتخاب مدل کامل کمک می کند.
ارزیابی LLM با Amazon SageMaker Clarify
Amazon SageMaker Clarify به مشتریان کمک می کند تا با ارائه چارچوبی برای ارزیابی LLM ها، معیارها را خودکار کنند، از جمله دقت، استحکام، سمیت، کلیشه سازی و دانش واقعی برای خودکار، و سبک، انسجام، ارتباط برای ارزیابی مبتنی بر انسان، و روش های ارزیابی. و خدمات مبتنی بر LLM مانند Amazon Bedrock. به عنوان یک سرویس کاملاً مدیریت شده، SageMaker Clarify استفاده از چارچوب های ارزیابی منبع باز را در Amazon SageMaker ساده می کند. مشتریان می توانند مجموعه داده ها و معیارهای ارزیابی مربوطه را برای سناریوهای خود انتخاب کنند و آنها را با مجموعه داده های سریع و الگوریتم های ارزیابی خود گسترش دهند. SageMaker Clarify نتایج ارزیابی را در قالب های متعدد برای پشتیبانی از نقش های مختلف در گردش کار LLM ارائه می دهد. دانشمندان داده میتوانند نتایج دقیق را با تجسمهای SageMaker Clarify در Notebooks، SageMaker Model Cards و گزارشهای PDF تجزیه و تحلیل کنند. در همین حال، تیمهای عملیاتی میتوانند از Amazon SageMaker GroundTruth برای بررسی و حاشیهنویسی موارد پرخطری که SageMaker Clarify شناسایی میکند، استفاده کنند. به عنوان مثال، با کلیشه سازی، سمیت، PII فرار یا دقت پایین.
حاشیه نویسی و یادگیری تقویتی متعاقباً برای کاهش خطرات احتمالی استفاده می شود. توضیحات انسان دوستانه از خطرات شناسایی شده، روند بررسی دستی را تسریع می کند و در نتیجه هزینه ها را کاهش می دهد. گزارشهای خلاصه به ذینفعان کسبوکار معیارهای مقایسهای بین مدلها و نسخههای مختلف ارائه میدهند که تصمیمگیری آگاهانه را تسهیل میکند.
شکل زیر چارچوب ارزیابی LLM و خدمات مبتنی بر LLM را نشان می دهد:

Amazon SageMaker Clarify LLM یک کتابخانه منبع باز ارزیابی مدل بنیادی (FMEval) است که توسط AWS برای کمک به مشتریان برای ارزیابی آسان LLMها توسعه یافته است. تمام قابلیتها نیز در Amazon SageMaker Studio گنجانده شدهاند تا ارزیابی LLM را برای کاربران خود فراهم کند. در بخشهای بعدی، ادغام قابلیتهای ارزیابی Amazon SageMaker Clarify LLM با SageMaker Pipelines را معرفی میکنیم تا ارزیابی LLM را در مقیاس با استفاده از اصول MLOps فعال کنیم.
چرخه عمر Amazon SageMaker MLOps
به عنوان پست ”نقشه راه بنیاد MLOps برای شرکت ها با Amazon SageMakerتوصیف می کند، MLOps ترکیبی از فرآیندها، افراد و فناوری برای تولید موارد استفاده کارآمد از ML است.
شکل زیر چرخه حیات MLOps را نشان می دهد:

یک سفر معمولی با ایجاد یک نوت بوک اثبات مفهوم (PoC) توسط یک دانشمند داده شروع می شود تا ثابت کند که ML می تواند یک مشکل تجاری را حل کند. در طول توسعه اثبات مفهوم (PoC)، این وظیفه دانشمند داده است که شاخصهای عملکرد کلیدی کسب و کار (KPIs) را به معیارهای مدل یادگیری ماشین، مانند دقت یا نرخ مثبت کاذب، تبدیل کند و از یک مجموعه داده آزمایشی محدود برای ارزیابی این موارد استفاده کند. معیارهای. دانشمندان داده با مهندسان ML برای انتقال کد از نوتبوک به مخازن همکاری میکنند و خطوط لوله ML را با استفاده از Amazon SageMaker Pipelines ایجاد میکنند، که مراحل و وظایف مختلف پردازش، از جمله پیش پردازش، آموزش، ارزیابی و پس پردازش را به هم متصل میکند، در حالی که به طور مداوم تولیدات جدید را در بر میگیرد. داده ها. استقرار آمازون SageMaker Pipelines به تعاملات مخزن و فعال سازی خط لوله CI/CD متکی است. خط لوله ML مدل های با کارایی بالا، تصاویر کانتینر، نتایج ارزیابی و اطلاعات وضعیت را در یک رجیستری مدل نگهداری می کند، جایی که ذینفعان مدل عملکرد را ارزیابی می کنند و بر اساس نتایج عملکرد و معیارها در مورد پیشرفت به سمت تولید تصمیم می گیرند و به دنبال آن خط لوله CI/CD دیگری فعال می شود. برای صحنه سازی و استقرار تولید. پس از تولید، مصرف کنندگان ML از مدل از طریق استنتاج ایجاد شده توسط برنامه از طریق فراخوانی مستقیم یا فراخوانی های API، با حلقه های بازخورد به صاحبان مدل برای ارزیابی عملکرد مداوم استفاده می کنند.
Amazon SageMaker Clarify و ادغام MLOps
به دنبال چرخه عمر MLOps، تیونرهای دقیق یا کاربران مدل های منبع باز، مدل های تنظیم شده یا FM را با استفاده از Amazon SageMaker Jumpstart و خدمات MLOps تولید می کنند، همانطور که در توضیح داده شده است. اجرای تمرینات MLOps با مدل های از پیش آموزش دیده Amazon SageMaker JumpStart. این منجر به ایجاد دامنه جدیدی برای عملیات مدل پایه (FMOps) و عملیات LLM (LLMOps) می شود. FMOps/LLMOps: هوش مصنوعی مولد و تفاوت ها با MLO ها را عملیاتی کنید.
شکل زیر چرخه عمر LLMOps end-to-end را نشان می دهد:
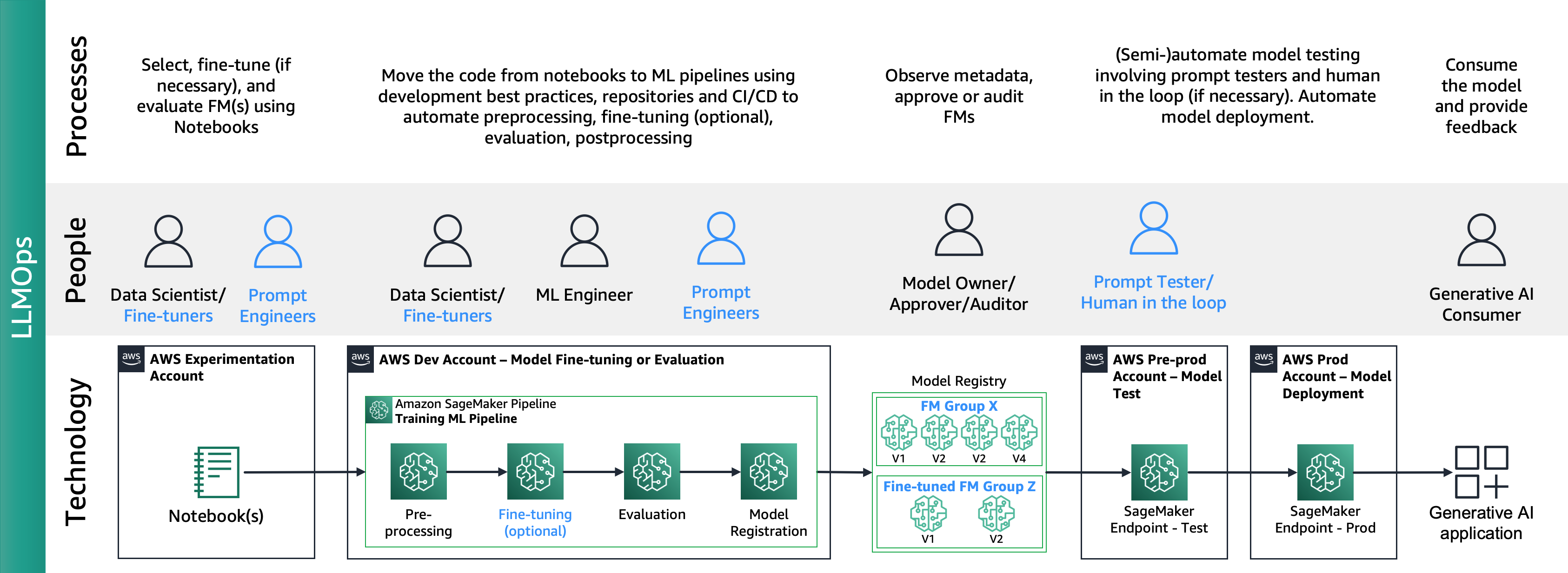
در LLMOps تفاوت های اصلی در مقایسه با MLO ها انتخاب مدل و ارزیابی مدل شامل فرآیندها و معیارهای مختلف است. در مرحله آزمایش اولیه، دانشمندان داده (یا تیونرهای دقیق) FM را انتخاب می کنند که برای یک مورد خاص استفاده از هوش مصنوعی مولد استفاده می شود.
این اغلب منجر به آزمایش و تنظیم دقیق FM های متعدد می شود که برخی از آنها ممکن است نتایج قابل مقایسه ای را به همراه داشته باشند. پس از انتخاب مدل(ها)، مهندسان سریع مسئول تهیه داده های ورودی لازم و خروجی مورد انتظار برای ارزیابی هستند (مثلاً درخواست های ورودی شامل داده های ورودی و پرس و جو) و معیارهایی مانند تشابه و سمیت را تعریف می کنند. علاوه بر این معیارها، دانشمندان داده یا تیونرهای دقیق باید نتایج را تأیید کرده و FM مناسب را نه تنها بر اساس معیارهای دقیق، بلکه در سایر قابلیتها مانند تأخیر و هزینه انتخاب کنند. سپس، آنها می توانند یک مدل را در نقطه پایانی SageMaker مستقر کرده و عملکرد آن را در مقیاس کوچک آزمایش کنند. در حالی که مرحله آزمایش ممکن است شامل یک فرآیند ساده باشد، انتقال به تولید به مشتریان نیاز دارد که فرآیند را خودکار کرده و استحکام راه حل را افزایش دهند. بنابراین، ما باید در مورد چگونگی ارزیابی خودکار، آزمایشکنندگان را قادر به انجام ارزیابی کارآمد در مقیاس و اجرای نظارت بر زمان واقعی ورودی و خروجی مدل کنیم.
ارزیابی خودکار FM
خطوط لوله آمازون SageMaker تمام مراحل پیش پردازش، تنظیم دقیق FM (اختیاری) و ارزیابی در مقیاس را خودکار می کند. با توجه به مدلهای انتخابشده در طول آزمایش، مهندسان سریع باید مجموعه بزرگتری از موارد را با تهیه بسیاری از دستورات و ذخیره آنها در یک مخزن ذخیرهسازی تعیینشده به نام کاتالوگ سریع پوشش دهند. برای اطلاعات بیشتر مراجعه کنید FMOps/LLMOps: هوش مصنوعی مولد و تفاوت ها با MLO ها را عملیاتی کنید. سپس، Amazon SageMaker Pipelines را می توان به صورت زیر ساختار داد:
سناریوی 1 - چندین FM را ارزیابی کنید: در این سناریو، FM ها می توانند موارد استفاده تجاری را بدون تنظیم دقیق پوشش دهند. خط لوله آمازون SageMaker شامل مراحل زیر است: پیش پردازش داده ها، ارزیابی موازی FM های متعدد، مقایسه مدل ها و انتخاب بر اساس دقت و ویژگی های دیگر مانند هزینه یا تأخیر، ثبت مصنوعات مدل انتخاب شده، و ابرداده.
نمودار زیر این معماری را نشان می دهد.

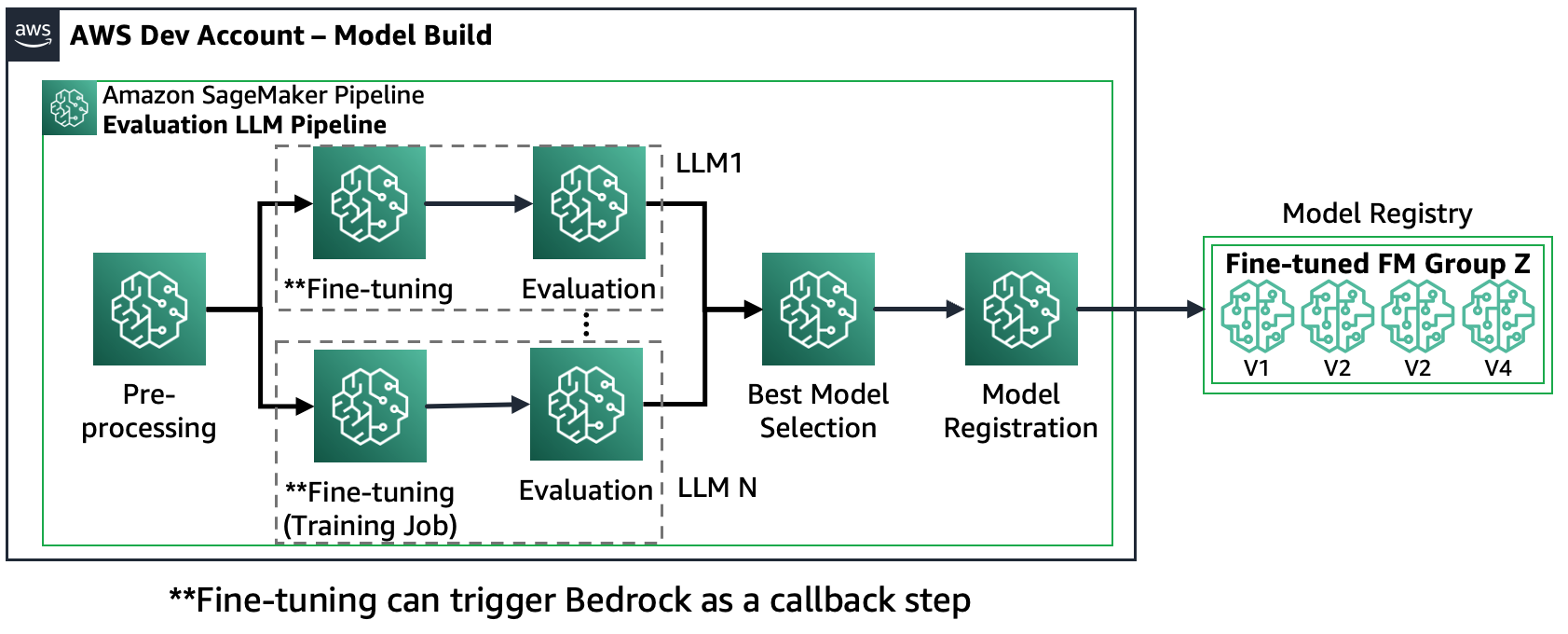
سناریو 2 - تنظیم دقیق و ارزیابی FM های متعدد: در این سناریو، خط لوله آمازون SageMaker بسیار شبیه به سناریو 1 است، اما به موازات مراحل تنظیم دقیق و ارزیابی برای هر FM اجرا می شود. بهترین مدل تنظیم شده در رجیستری مدل ثبت می شود.
نمودار زیر این معماری را نشان می دهد.
سناریو 3 - FM های متعدد و FM های تنظیم شده را ارزیابی کنید: این سناریو ترکیبی از ارزیابی FM های عمومی و FM های تنظیم شده دقیق است. در این مورد، مشتریان می خواهند بررسی کنند که آیا یک مدل تنظیم شده می تواند بهتر از یک FM همه منظوره عمل کند یا خیر.
شکل زیر مراحل حاصل از خط لوله SageMaker را نشان می دهد.
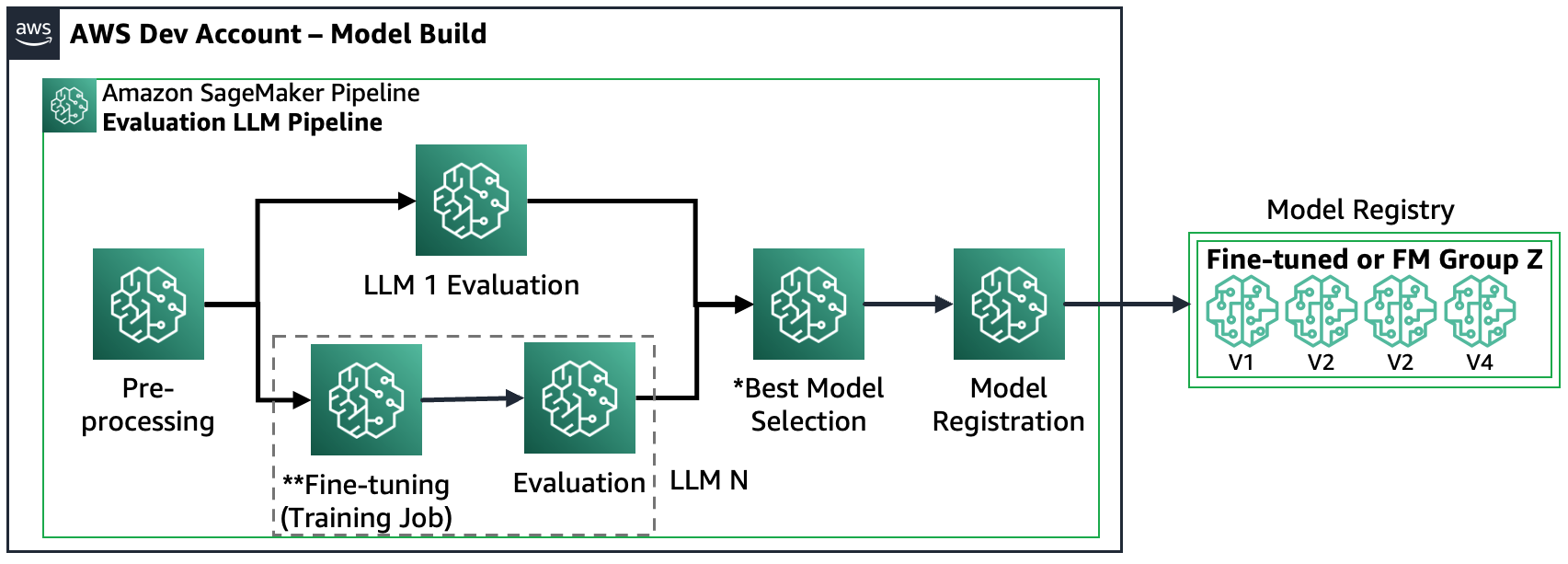
توجه داشته باشید که ثبت مدل از دو الگو پیروی می کند: (الف) ذخیره یک مدل منبع باز و مصنوعات یا (ب) ذخیره یک مرجع به یک FM اختصاصی. برای اطلاعات بیشتر مراجعه کنید FMOps/LLMOps: هوش مصنوعی مولد و تفاوت ها با MLO ها را عملیاتی کنید.
بررسی اجمالی راه حل
برای تسریع سفر شما به ارزیابی LLM در مقیاس، راه حلی ایجاد کردیم که سناریوها را با استفاده از Amazon SageMaker Clarify و Amazon SageMaker Pipelines SDK جدید اجرا می کند. نمونه کد، شامل مجموعه داده ها، نوت بوک های منبع و خطوط لوله SageMaker (گام ها و خط لوله ML)، در دسترس است GitHub. برای توسعه این راه حل مثال، ما از دو FM استفاده کرده ایم: Llama2 و Falcon-7B. در این پست، تمرکز اصلی ما بر روی عناصر کلیدی راه حل SageMaker Pipeline است که به فرآیند ارزیابی مربوط می شود.
پیکربندی ارزیابی: به منظور استانداردسازی روش ارزیابی، ما یک فایل پیکربندی YAML ایجاد کردهایم، (evaluation_config.yaml)، که حاوی جزئیات لازم برای فرآیند ارزیابی از جمله مجموعه داده، مدل(ها) و الگوریتمهایی است که در طول دوره اجرا میشوند. مرحله ارزیابی خط لوله SageMaker. مثال زیر فایل پیکربندی را نشان می دهد:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"مرحله ارزیابی: SageMaker Pipeline SDK جدید انعطافپذیری را برای کاربران فراهم میکند تا مراحل سفارشی را در گردش کار ML با استفاده از دکوراتور Python '@step' تعریف کنند. بنابراین، کاربران باید یک اسکریپت پایتون پایه ایجاد کنند که ارزیابی را انجام دهد، به شرح زیر:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultخط لوله SageMaker: پس از ایجاد مراحل لازم مانند پیش پردازش داده ها، استقرار مدل و ارزیابی مدل، کاربر باید با استفاده از SageMaker Pipeline SDK مراحل را به یکدیگر پیوند دهد. SDK جدید به طور خودکار گردش کار را با تفسیر وابستگی های بین مراحل مختلف هنگام فراخوانی یک API ایجاد خط لوله SageMaker همانطور که در مثال زیر نشان داده شده است ایجاد می کند:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
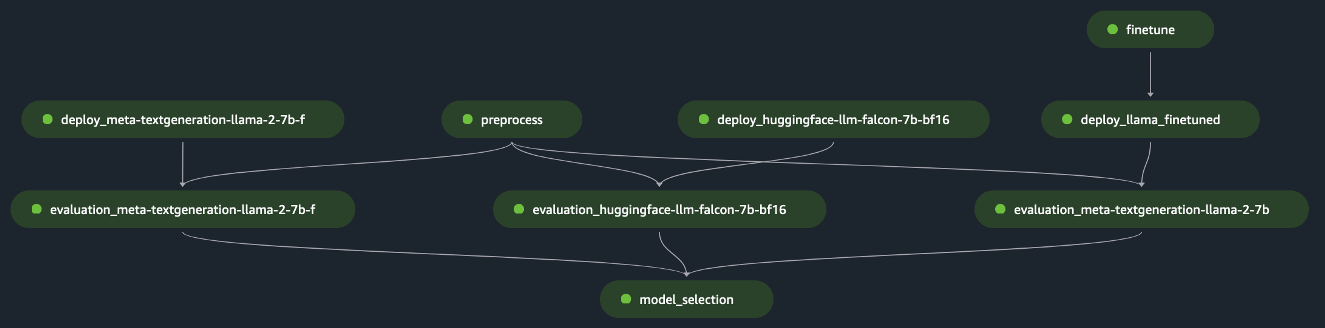
pipeline.start()این مثال ارزیابی یک FM واحد را با پیش پردازش مجموعه داده های اولیه، استقرار مدل و اجرای ارزیابی پیاده سازی می کند. نمودار غیر چرخه ای جهت دار خط لوله تولید شده (DAG) در شکل زیر نشان داده شده است.
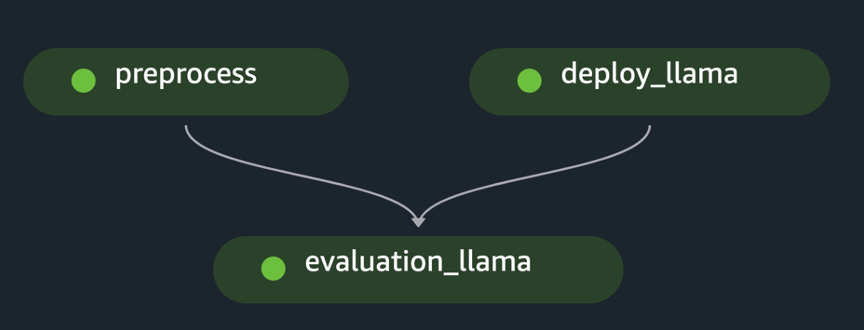
با پیروی از رویکردی مشابه و با استفاده از نمونه و تطبیق آن در مدلهای LLaMA 2 را در SageMaker JumpStart تنظیم کنید، همانطور که در شکل زیر نشان داده شده است، خط لوله را برای ارزیابی یک مدل تنظیم شده ایجاد کردیم.

با استفاده از مراحل قبلی SageMaker Pipeline به عنوان بلوک های "Lego"، ما راه حلی را برای سناریو 1 و سناریو 3، همانطور که در شکل های زیر نشان داده شده است، توسعه دادیم. به طور خاص، GitHub مخزن کاربر را قادر می سازد تا چندین FM را به صورت موازی ارزیابی کند یا ارزیابی پیچیده تری را با ترکیب ارزیابی هر دو مدل پایه و تنظیم دقیق انجام دهد.

عملکردهای اضافی موجود در مخزن شامل موارد زیر است:
- تولید مرحله ارزیابی پویا: راه حل ما تمام مراحل ارزیابی لازم را به صورت پویا بر اساس فایل پیکربندی ایجاد می کند تا کاربران را قادر سازد هر تعداد مدل را ارزیابی کنند. ما راه حل را برای پشتیبانی از ادغام آسان انواع جدید مدل ها، مانند Hugging Face یا Amazon Bedrock گسترش داده ایم.
- جلوگیری از استقرار مجدد نقطه پایانی: اگر یک نقطه پایانی از قبل وجود داشته باشد، از فرآیند استقرار صرفنظر می کنیم. این به کاربر اجازه می دهد تا از نقاط پایانی با FM ها برای ارزیابی مجدد استفاده کند که در نتیجه باعث صرفه جویی در هزینه و کاهش زمان استقرار می شود.
- پاکسازی نقطه پایانی: پس از تکمیل ارزیابی، خط لوله SageMaker نقاط پایانی مستقر شده را از کار انداخت. این قابلیت را می توان برای زنده نگه داشتن نقطه پایانی بهترین مدل گسترش داد.
- مرحله انتخاب مدل: ما یک مکانگردان مرحله انتخاب مدل اضافه کردهایم که به منطق تجاری انتخاب مدل نهایی، از جمله معیارهایی مانند هزینه یا تأخیر نیاز دارد.
- مرحله ثبت نام مدل: بهترین مدل را می توان در Amazon SageMaker Model Registry به عنوان نسخه جدید یک گروه مدل خاص ثبت کرد.
- استخر گرم: استخرهای گرم مدیریت شده SageMaker به شما این امکان را می دهد که پس از اتمام کار، زیرساخت های تدارک دیده شده را حفظ کرده و مجدداً استفاده کنید تا تأخیر بارهای کاری تکراری را کاهش دهید.
شکل زیر این قابلیت ها و یک مثال ارزیابی چند مدلی را نشان می دهد که کاربران می توانند به راحتی و به صورت پویا با استفاده از راه حل ما در این زمینه ایجاد کنند. GitHub مخزن

ما عمداً آماده سازی داده را خارج از محدوده نگه داشتیم زیرا در یک پست متفاوت به طور عمیق توضیح داده خواهد شد، از جمله طرح های کاتالوگ فوری، الگوهای سریع، بهینه سازی سریع. برای اطلاعات بیشتر و تعاریف اجزای مرتبط به آن مراجعه کنید FMOps/LLMOps: هوش مصنوعی مولد و تفاوت ها با MLO ها را عملیاتی کنید.
نتیجه
در این پست، ما بر نحوه خودکارسازی و عملیاتی کردن ارزیابی LLM در مقیاس با استفاده از قابلیتهای ارزیابی Amazon SageMaker Clarify LLM و Amazon SageMaker Pipelines تمرکز کردیم. علاوه بر طرح های معماری نظری، کد نمونه ای در این مورد داریم GitHub مخزن (شامل FM های Llama2 و Falcon-7B) تا مشتریان را قادر سازد تا مکانیسم های ارزیابی مقیاس پذیر خود را توسعه دهند.
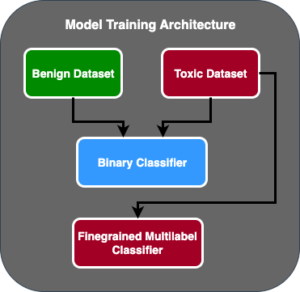
تصویر زیر معماری ارزیابی مدل را نشان می دهد.
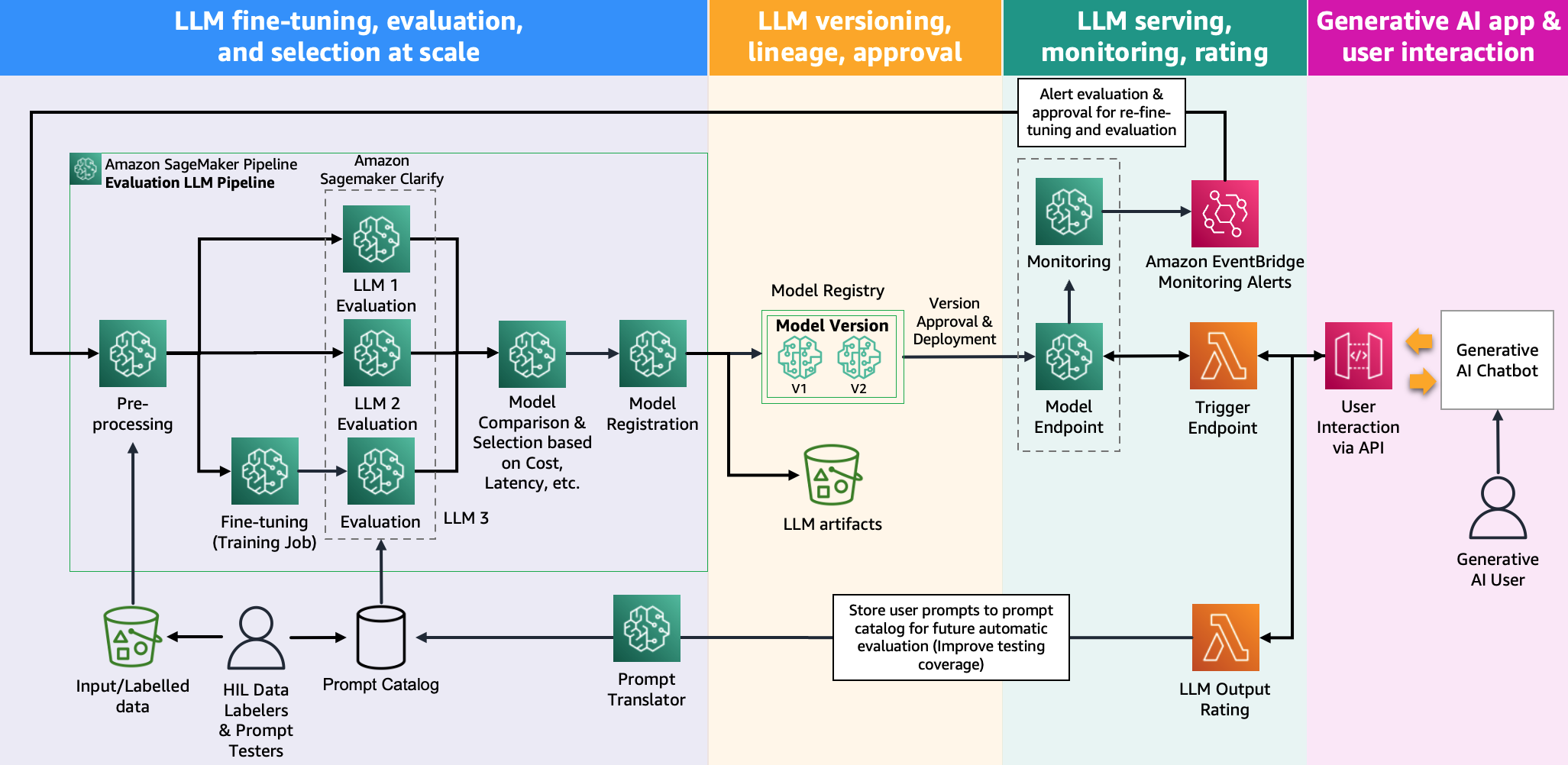
در این پست، ما بر عملیاتی کردن ارزیابی LLM در مقیاس همانطور که در سمت چپ تصویر نشان داده شده است تمرکز کردیم. در آینده، ما بر روی توسعه نمونه هایی تمرکز خواهیم کرد که با پیروی از دستورالعمل شرح داده شده در زیر، چرخه عمر پایان به انتها FM ها را تا تولید انجام می دهند. FMOps/LLMOps: هوش مصنوعی مولد و تفاوت ها با MLO ها را عملیاتی کنید. این شامل خدمات LLM، نظارت، ذخیره رتبهبندی خروجی است که در نهایت باعث ارزیابی مجدد و تنظیم دقیق خودکار میشود و در نهایت، استفاده از انسان در حلقه برای کار بر روی دادههای برچسبگذاری شده یا فهرست درخواستها.
درباره نویسندگان
 دکتر سوکراتیس کارتاکیس یک معمار اصلی راه حل های تخصصی یادگیری ماشین و عملیات برای خدمات وب آمازون است. Sokratis بر روی توانمندسازی مشتریان سازمانی برای صنعتی کردن راهحلهای یادگیری ماشینی (ML) و هوش مصنوعی مولد خود با بهرهبرداری از خدمات AWS و شکلدهی مدل عملیاتی آنها، یعنی پایههای MLOps/FMOps/LLMOps و نقشه راه تحول با بهرهگیری از بهترین شیوههای توسعه تمرکز دارد. او بیش از 15 سال را صرف اختراع، طراحی، رهبری و پیادهسازی راهحلهای نوآورانه ML و AI در سطح تولید نهایی در حوزههای انرژی، خردهفروشی، سلامت، مالی، ورزش موتوری و غیره کرده است.
دکتر سوکراتیس کارتاکیس یک معمار اصلی راه حل های تخصصی یادگیری ماشین و عملیات برای خدمات وب آمازون است. Sokratis بر روی توانمندسازی مشتریان سازمانی برای صنعتی کردن راهحلهای یادگیری ماشینی (ML) و هوش مصنوعی مولد خود با بهرهبرداری از خدمات AWS و شکلدهی مدل عملیاتی آنها، یعنی پایههای MLOps/FMOps/LLMOps و نقشه راه تحول با بهرهگیری از بهترین شیوههای توسعه تمرکز دارد. او بیش از 15 سال را صرف اختراع، طراحی، رهبری و پیادهسازی راهحلهای نوآورانه ML و AI در سطح تولید نهایی در حوزههای انرژی، خردهفروشی، سلامت، مالی، ورزش موتوری و غیره کرده است.
 جاگدیپ سینگ سونی یک معمار ارشد راه حل های شریک در AWS مستقر در هلند است. او از اشتیاق خود برای DevOps، GenAI و ابزارهای سازنده برای کمک به ادغامکنندگان سیستم و شرکای فناوری استفاده میکند. Jagdeep از پیشینه توسعه اپلیکیشن و معماری خود برای هدایت نوآوری در تیم خود و ترویج فناوری های جدید استفاده می کند.
جاگدیپ سینگ سونی یک معمار ارشد راه حل های شریک در AWS مستقر در هلند است. او از اشتیاق خود برای DevOps، GenAI و ابزارهای سازنده برای کمک به ادغامکنندگان سیستم و شرکای فناوری استفاده میکند. Jagdeep از پیشینه توسعه اپلیکیشن و معماری خود برای هدایت نوآوری در تیم خود و ترویج فناوری های جدید استفاده می کند.
 دکتر ریکاردو گاتی یک معمار ارشد راه حل استارتاپی مستقر در ایتالیا است. او یک مشاور فنی برای مشتریان است و به آنها کمک می کند تا با انتخاب ابزارها و فناوری های مناسب برای نوآوری، مقیاس سریع و جهانی شدن در عرض چند دقیقه، کسب و کار خود را توسعه دهند. او همیشه به یادگیری ماشینی و هوش مصنوعی مولد علاقه داشته است و در طول دوران کاری خود این فناوریها را در حوزههای مختلف مورد مطالعه و استفاده قرار داده است. او میزبان و سردبیر پادکست ایتالیایی AWS "Casa Startup" است که به داستانهای بنیانگذاران استارتآپ و روندهای جدید فناوری اختصاص دارد.
دکتر ریکاردو گاتی یک معمار ارشد راه حل استارتاپی مستقر در ایتالیا است. او یک مشاور فنی برای مشتریان است و به آنها کمک می کند تا با انتخاب ابزارها و فناوری های مناسب برای نوآوری، مقیاس سریع و جهانی شدن در عرض چند دقیقه، کسب و کار خود را توسعه دهند. او همیشه به یادگیری ماشینی و هوش مصنوعی مولد علاقه داشته است و در طول دوران کاری خود این فناوریها را در حوزههای مختلف مورد مطالعه و استفاده قرار داده است. او میزبان و سردبیر پادکست ایتالیایی AWS "Casa Startup" است که به داستانهای بنیانگذاران استارتآپ و روندهای جدید فناوری اختصاص دارد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 1
- 100
- 9
- a
- درباره ما
- شتاب دادن
- دسترسی
- دقت
- به درستی
- رسیدن
- دستیابی به
- در میان
- عمل
- فعال سازی
- فعال
- حلقوی
- اضافه
- اضافه
- علاوه بر این
- نشانی
- به اندازه کافی
- حکومت
- تصویب
- اتخاذ
- پیشرفت
- مشاور
- پس از
- در برابر
- عاملان
- AI
- قانون هوش مصنوعی
- سیستم های هوش مصنوعی
- هدف
- هدف
- الگوریتم
- الگوریتم
- تراز می کند
- زنده
- معرفی
- اجازه می دهد تا
- قبلا
- همچنین
- همیشه
- آمازون
- آمازون SageMaker
- Amazon SageMaker JumpStart
- خطوط لوله آمازون SageMaker
- Amazon SageMaker Studio
- آمازون خدمات وب
- an
- تحلیل
- و
- دیگر
- پاسخ
- هر
- API
- کاربرد
- برنامه توسعه
- برنامه های کاربردی
- اعمال می شود
- اعمال میشود
- روش
- مناسب
- معماری
- هستند
- مناطق
- استدلال
- AS
- ارزیابی کنید
- ارزیابی
- ارزیابی
- ارزیابی ها
- At
- حسابرسی
- خودکار بودن
- خودکار
- اتوماتیک
- بطور خودکار
- اتوماسیون
- در دسترس
- AWS
- b
- زمینه
- مستقر
- اساسی
- BE
- زیرا
- شدن
- بوده
- رفتار
- محک
- معیار
- معیار
- مزایای
- بهترین
- بهتر
- میان
- خارج از
- تعصب
- جانبدارانه
- تعصبات
- بلاک ها
- هر دو
- نقض
- وسعت
- به ارمغان بیاورد
- ساختن
- سازنده
- کسب و کار
- اما
- by
- نام
- تماس ها
- CAN
- نامزد
- قابلیت های
- توانا
- گرفتن
- کارت ها
- کاریابی
- مورد
- موارد
- کاتالوگ
- معین
- به چالش
- مشخصات
- ارزان تر
- بررسی
- را انتخاب کنید
- برگزیده
- طبقه بندی
- طبقه بندی کنید
- تمیز
- رمز
- منسجم
- همکاری
- ترکیب
- ترکیب
- مشترک
- انجمن
- قابل مقایسه
- مقايسه كردن
- مقایسه
- مقایسه
- متمم
- اتمام
- پیچیده
- پیچیدگی
- انطباق
- مطابق
- جزء
- اجزاء
- شامل
- محاسباتی
- محاسبه
- مفهوم
- نگرانی
- رفتار
- انجام
- هدایت می کند
- پیکر بندی
- اتصال
- متصل
- در نظر گرفته
- تشکیل شده است
- ساختن
- مصرف کنندگان
- ظرف
- شامل
- محتوا
- زمینه
- به طور مستمر
- مداوم
- کنتراست
- محاورهای
- گفتگو
- تبدیل
- اصلاح
- هزینه
- صرفه جویی در هزینه
- گران
- هزینه
- پوشش
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- ضوابط
- بحرانی
- بسیار سخت
- سفارشی
- مشتریان
- DAG
- داده ها
- آماده سازی داده ها
- دانشمند داده
- امنیت داده ها
- مجموعه داده ها
- دستکاری داده ها
- مجموعه داده ها
- زمان قرار
- تصمیم گیری
- تصمیم گیری
- تصمیم گیری
- اختصاصی
- عمیق
- شیرجه عمیق
- به طور پیش فرض
- تعريف كردن
- تعاریف
- ارائه
- تقاضا
- وابستگی
- بستگی دارد
- گسترش
- مستقر
- استقرار
- گسترش
- عمق
- شرح داده شده
- تعیین شده
- طراحی
- طراحی
- طرح
- میل
- مطلوب
- دقیق
- جزئیات
- توسعه
- توسعه
- در حال توسعه
- پروژه
- DevOps
- تفاوت
- مختلف
- مستقیم
- جهت دار
- شیرجه رفتن
- مختلف
- do
- نمی کند
- دامنه
- حوزه
- راندن
- در طی
- بطور پویا
- e
- هر
- به آسانی
- ساده
- سردبیر
- موثر
- اثر
- موثر
- موثر
- تلاش
- هر دو
- عناصر
- دیگر
- به کار گرفته شده
- قادر ساختن
- را قادر می سازد
- را قادر می سازد
- پشت سر هم
- نقطه پایانی
- نقاط پایان
- انرژی
- مورد تأیید
- بالا بردن
- اطمینان حاصل شود
- تضمین می کند
- حصول اطمینان از
- سرمایه گذاری
- مشتریان سازمانی
- شرکت
- دوره
- به همان اندازه
- به خصوص
- ضروری است
- و غیره
- اتر (ETH)
- EU
- ارزیابی
- ارزیابی
- ارزیابی
- ارزیابی
- حتی
- در نهایت
- مثال
- مثال ها
- اجرایی
- موجود
- انتظارات
- انتظار می رود
- تسریع کردن
- گسترش
- تمدید شده
- خارجی
- استخراج
- f1
- چهره
- تسهیل کننده
- عوامل
- واقعی
- عدالت
- آبشار
- غلط
- معروف
- FAST
- سریعتر
- ویژگی
- ویژگی های
- باز خورد
- کمی از
- رشته
- شکل
- آمار و ارقام
- پرونده
- نهایی
- سرانجام
- سرمایه گذاری
- مالی
- بخش مالی
- نام خانوادگی
- انعطاف پذیری
- تمرکز
- متمرکز شده است
- تمرکز
- به دنبال
- پیروی
- به دنبال آن است
- برای
- فرم
- پایه
- مبانی
- بنیانگذاران
- چارچوب
- چارچوب
- غالبا
- از جانب
- انجام
- کامل
- ویژگی های
- قابلیت
- اساسی
- بعلاوه
- آینده
- جمع آوری
- سوالات عمومی
- همه منظوره
- تولید می کنند
- تولید
- تولید می کند
- مولد
- نسل
- مولد
- هوش مصنوعی مولد
- دریافت کنید
- داده
- جهانی
- Go
- اعطا کردن
- گراف
- گروه
- گروه ها
- در حال رشد
- دست
- مضر
- بهره برداری
- آیا
- داشتن
- he
- سلامتی
- به شدت
- کمک
- کمک
- کمک می کند
- زیاد
- ریسک بالا
- لولا
- خود را
- برگزاری
- میزبان
- چگونه
- چگونه
- اما
- HTML
- HTTPS
- انسان
- i
- IAM
- شناسایی
- شناسایی می کند
- شناسایی
- if
- نشان می دهد
- تصاویر
- انجام
- اجرای
- پیاده سازی می کند
- واردات
- اهمیت
- بهبود
- ارتقاء
- in
- شامل
- شامل
- از جمله
- ادغام شده
- گنجاندن
- شاخص ها
- لوازم
- اطلاعات
- اطلاع
- شالوده
- اول
- نوآوری
- ابداع
- ابتکاری
- ورودی
- ورودی
- ادغام
- ادغام
- از قصد
- فعل و انفعالات
- داخلی
- به
- معرفی
- استناد کرد
- شامل
- گرفتار
- شامل
- شامل
- ISO
- IT
- ایتالیایی
- ایتالیا
- اقلام
- تکرار
- ITS
- کار
- سفر
- JPG
- نگاه داشتن
- نگه داشته شد
- کلید
- دانش
- زبان
- بزرگ
- بزرگتر
- نام
- در آخر
- تاخیر
- رهبری
- مدیران
- برجسته
- یادگیری
- ترک کرد
- اجازه
- بهره برداری
- کتابخانه
- wifecycwe
- پسندیدن
- محدود شده
- ارتباط دادن
- پشم لاما
- محل
- منطق
- کم
- دستگاه
- فراگیری ماشین
- اصلی
- حفظ
- حفظ
- اداره می شود
- دستکاری کردن
- دستکاری
- کتابچه راهنمای
- بسیاری
- ممکن است..
- در ضمن
- اندازه
- معیارهای
- مکانیسم
- متاداده
- روش
- روش
- متری
- متریک
- به حداقل رساندن
- دقیقه
- اطلاعات غلط
- کاهش
- تسکین دهنده
- ML
- MLO ها
- مدل
- مدل
- واحد
- مانیتور
- نظارت بر
- بیش
- اکثر
- انگیزه
- موتورسیکلت
- بسیار
- چندگانه
- باید
- نام
- لازم
- نیاز
- نیازهای
- هلند
- جدید
- فناوری های نوین
- بعد
- غیر متخصص
- توجه داشته باشید
- دفتر یادداشت
- نوت بوک
- تفاوت های ظریف
- عدد
- of
- ارائه
- غالبا
- on
- یک بار
- ONE
- مداوم
- فقط
- منبع باز
- عملیاتی
- عمل
- عملیات
- دیدگاه ها
- بهینه سازی
- or
- OS
- دیگر
- ما
- خارج
- نتیجه
- نتایج
- تولید
- خروجی
- برجسته
- روی
- به طور کلی
- خود
- صاحبان
- موازی
- پارامترهای
- ویژه
- ویژه
- شریک
- شرکای
- شور
- احساساتی
- مسیر
- الگوهای
- مردم
- انجام دادن
- کارایی
- اجرای
- انجام می دهد
- فاز
- پی
- خط لوله
- محل
- حفره یا سوراخ
- افلاطون
- هوش داده افلاطون
- PlatoData
- پوک
- پادکست
- نقطه
- استخر
- استخرها
- پست
- پردازش پس از
- پتانسیل
- قدرت
- صفحه اصلی
- شیوه های
- دقت
- تهیه
- آماده
- حضور
- جلوگیری از
- قبلی
- اصلی
- اصلی
- از اصول
- خلوت
- خصوصی
- مشکل
- روش
- روند
- فرآیندهای
- در حال پردازش
- تولید
- پیشرفت
- برجستگی
- وعده
- ترویج
- پرسیدن
- اثبات
- اثبات مفهوم
- انتشار
- املاک
- اختصاصی
- محافظت از
- ثابت كردن
- ارائه
- ارائه دهندگان
- فراهم می کند
- ارائه
- عمومی
- عمومی
- هدف
- پــایتــون
- کیفی
- کیفیت
- کمی
- سوال
- محدوده
- نرخ
- رتبه
- واقعی
- دنیای واقعی
- زمان واقعی
- كاهش دادن
- کاهش
- کاهش
- مراجعه
- مرجع
- ثبت نام
- ثبت
- رجیستری
- رگرسیون
- منظم
- تنظیم
- صنایع تنظیم شده
- مقررات
- تقویت یادگیری
- مربوط
- ربط
- مربوط
- قابلیت اطمینان
- تکراری
- گزارش
- گزارش
- گزارش ها
- مخزن
- نماینده
- ضروری
- نیاز
- تحقیق
- محققان
- منابع فشرده
- منابع
- مسئوليت
- مسئوليت
- نتیجه
- نتایج
- خرده فروشی
- نگه داشتن
- برگشت
- استفاده مجدد
- این فایل نقد می نویسید:
- انقلابی
- راست
- دقیق
- رسیده
- خطر
- خطرات
- نقشه راه
- تنومند
- نیرومندی
- نقش
- نقش
- دویدن
- در حال اجرا
- اجرا می شود
- s
- امن
- پادمان
- حکیم ساز
- خطوط لوله SageMaker
- پس انداز
- مقیاس پذیری
- مقیاس پذیر
- مقیاس
- سناریو
- سناریوها
- دانشمند
- دانشمندان
- حوزه
- نمره
- خط
- sdk
- یکپارچه
- بخش
- بخش
- امن
- تیم امنیت لاتاری
- خطرات امنیتی
- را انتخاب کنید
- انتخاب شد
- انتخاب
- انتخاب
- ارشد
- احساس
- خدمت
- سرویس
- خدمات
- خدمت
- جلسه
- تنظیم
- شکل دادن
- اشتراک گذاری
- نشان
- نشان داده شده
- نشان می دهد
- طرف
- قابل توجه
- مشابه
- ساده می کند
- به سادگی
- پس از
- تنها
- کوچک
- راه حل
- مزایا
- حل
- برخی از
- منبع
- محدوده
- متخصص
- خاص
- به طور خاص
- صرف
- استقرار
- سهامداران
- استاندارد
- استانداردهای
- استنفورد
- راه افتادن
- شروع می شود
- شروع
- وضعیت
- گام
- مراحل
- هنوز
- ذخیره سازی
- opbevare
- داستان
- ساده
- ساخت یافته
- مورد مطالعه قرار
- استودیو
- سبک
- متعاقبا
- چنین
- خلاصه
- پشتیبانی
- سیستم
- سیستم های
- خیاطی
- کار
- وظایف
- تیم
- تیم ها
- فنی
- تکنیک
- فنی
- فن آوری
- پیشرفته
- قالب
- آزمون
- تسترها
- تست
- تست
- متن
- نسبت به
- که
- La
- آینده
- شان
- آنها
- سپس
- نظری
- در نتیجه
- از این رو
- اینها
- آنها
- این
- کسانی که
- سه
- از طریق
- سراسر
- زمان
- به
- با هم
- ابزار
- ابزار
- مسیر
- قطار
- آموزش دیده
- آموزش
- قطار
- دگرگونی
- انتقال
- گذار
- ترجمه
- روند
- ماشه
- درست
- قابل اعتماد
- دو
- انواع
- نوعی
- در نهایت
- غیر مجاز
- فهمیدن
- درک
- بی سابقه
- نزدیک
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- کاربران
- استفاده
- با استفاده از
- معمولا
- استفاده کنید
- تصدیق
- ارزشمند
- مختلف
- نسخه
- از طريق
- حیاتی
- آسیب پذیری ها
- می خواهم
- گرم
- we
- وب
- خدمات وب
- خوب
- بود
- چی
- چه زمانی
- که
- در حین
- WHO
- وسیع
- دامنه گسترده
- ویکیپدیا
- اراده
- با
- در داخل
- بدون
- مهاجرت کاری
- گردش کار
- کارگر
- جهان
- یامل
- سال
- بازده
- شما
- شما
- زفیرنت