دو فناوری جدید الگوریتمی مبتنی بر نرمافزار - رانندگی خودکار (ADAS/AD) و هوش مصنوعی (GenAI) - جامعه مهندسی نیمهرسانا را در شب بیدار نگه میدارند.
در حالی که ADAS در سطح 2 و سطح 3 در مسیر درست قرار دارد، AD در سطوح 4 و 5 با واقعیت فاصله زیادی دارد و باعث کاهش اشتیاق و سرمایه گذاری خطرپذیر می شود. امروزه GenAI مورد توجه قرار گرفته است و VCها مشتاقانه میلیاردها دلار سرمایه گذاری می کنند.
هر دو فناوری مبتنی بر الگوریتم های مدرن و پیچیده هستند. پردازش آموزش و استنتاج آنها دارای چند ویژگی است، برخی مهم، برخی دیگر مهم اما ضروری نیستند: جدول I را ببینید.

پیشرفت نرم افزاری قابل توجه در این فناوری ها تاکنون با پیشرفت های سخت افزاری الگوریتمی برای تسریع در اجرای آنها تکرار نشده است. به عنوان مثال، پردازندههای الگوریتمی پیشرفته، کارایی لازم برای پاسخگویی به پرسشهای ChatGPT-4 را در یک یا دو ثانیه با هزینه ۲ ¢ برای هر پرسوجو ندارند، معیاری که توسط جستجوی Google تعیین شده است، یا پردازش دادههای عظیم را ندارند. توسط حسگرهای AD در کمتر از 2 میلی ثانیه جمع آوری می شود.
این تا زمانی بود که استارتآپ فرانسوی VSORA برای رفع تنگنای حافظه معروف به دیوار حافظه، نیروی مغزی سرمایهگذاری کرد.
دیوار حافظه
دیوار حافظه CPU اولین بار توسط Wulf و McKee در سال 1994 توصیف شد. از آن زمان، دسترسی به حافظه به گلوگاه عملکرد محاسبات تبدیل شده است. پیشرفتها در عملکرد پردازنده در پیشرفت دسترسی به حافظه منعکس نشده است، و باعث میشود که پردازندهها برای دادههای ارائه شده توسط حافظهها بیشتر منتظر بمانند. در پایان، بازده پردازنده بسیار کمتر از 100٪ استفاده می شود.
برای حل این مشکل، صنعت نیمه هادی یک ساختار حافظه سلسله مراتبی چند سطحی با چندین سطح حافظه نهان در نزدیکی پردازنده ایجاد کرد که میزان ترافیک را با حافظه های اصلی و خارجی کندتر کاهش می دهد.
عملکرد پردازنده های AD و GenAI بیش از سایر انواع دستگاه های محاسباتی به پهنای باند حافظه گسترده بستگی دارد.
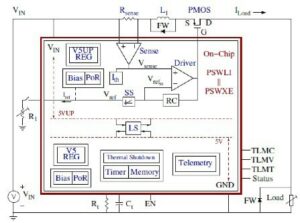
VSORA که در سال 2015 برای هدف قرار دادن برنامههای کاربردی 5G تأسیس شد، یک معماری ثبت اختراع اختراع کرد که ساختار حافظه سلسله مراتبی را در یک حافظه با پهنای باند بالا و محکم جفت شده (TCM) که در یک چرخه ساعت قابل دسترسی است، جمع میکند.
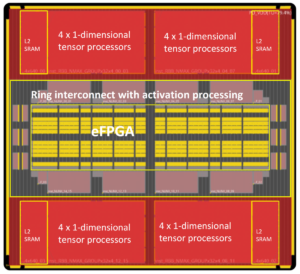
از منظر هسته های پردازنده، TCM به نظر می رسد و مانند دریایی از ثبات ها به مقدار مگابایت در مقابل کیلوبایت ثبات های فیزیکی واقعی عمل می کند. توانایی دسترسی به هر سلول حافظه در TMC در یک چرخه، سرعت اجرای بالا، تأخیر کم و مصرف انرژی کم را به همراه دارد. همچنین به سطح سیلیکونی کمتری نیاز دارد. بارگذاری دادههای جدید از حافظه خارجی در TCM در حالی که دادههای فعلی پردازش میشوند بر توان عملیاتی سیستم تأثیری ندارد. اساساً، معماری امکان استفاده 80+٪ از واحدهای پردازش را از طریق طراحی آن فراهم می کند. با این حال، اگر طراح سیستم بخواهد، امکان اضافه کردن حافظه پنهان و اسکرچ پد وجود دارد. شکل 1 را ببینید.
")
از طریق یک ساختار حافظه رجیستر که تقریباً در تمام حافظه ها در همه برنامه ها پیاده سازی شده است، نمی توان مزیت رویکرد حافظه VSORA را اغراق کرد. به طور معمول، پردازنده های پیشرفته GenAI درصد بازدهی تک رقمی را ارائه می دهند. به عنوان مثال، یک پردازنده GenAI با توان عملیاتی اسمی یک پتافلاپ با کارایی اسمی، اما بازدهی کمتر از 5 درصد، عملکرد قابل استفاده کمتر از 50 ترافلاپس را ارائه می دهد. در عوض، معماری VSORA بیش از 10 برابر بازده بیشتری را به دست می آورد.
شتاب دهنده های الگوریتمی VSORA
VSORA دو دسته از شتاب دهنده های الگوریتمی را معرفی کرد - خانواده Tyr برای برنامه های کاربردی AD و خانواده Jotunn برای شتاب GenAI. هر دو توان عملیاتی ستاره ای، حداقل تأخیر، مصرف کم انرژی را در یک ردپای سیلیکونی کوچک ارائه می دهند.
با عملکرد اسمی حداکثر سه پتافلاپ، آنها دارای راندمان اجرای معمولی 50-80٪ بدون توجه به نوع الگوریتم و حداکثر مصرف انرژی 30 وات / پتافلاپ هستند. اینها ویژگی های ستاره ای هستند که هنوز توسط هیچ شتاب دهنده هوش مصنوعی رقابتی گزارش نشده است.
Tyr و Jotunn کاملاً قابل برنامهریزی هستند و قابلیتهای AI و DSP را، البته در مقادیر متفاوت، ادغام میکنند و از انتخاب محاسباتی در لحظه از 8 بیت تا 64 بیت بر اساس اعداد صحیح یا ممیز شناور پشتیبانی میکنند. قابلیت برنامهریزی آنها مجموعهای از الگوریتمها را در خود جای میدهد و آنها را به الگوریتمهای آگنوستیک تبدیل میکند. چندین نوع مختلف پراکندگی نیز پشتیبانی می شود.
ویژگی های پردازنده های VSORA آنها را به خط مقدم چشم انداز پردازش الگوریتمی رقابتی سوق می دهد.
نرم افزار پشتیبانی VSORA
VSORA یک پلتفرم کامپایل/ اعتبارسنجی منحصر به فرد را طراحی کرد که بر اساس معماری سخت افزاری آن طراحی شده است تا اطمینان حاصل شود که دستگاه های SoC پیچیده و با کارایی بالا از پشتیبانی نرم افزاری فراوانی برخوردار هستند.
برای قرار دادن طراح الگوریتم در کابین خلبان، طیفی از سطوح تأیید/اعتبار سلسله مراتبی – ESL، ترکیبی، RTL و دروازه – – بازخورد دکمهای را به مهندس الگوریتم در پاسخ به کاوشهای فضایی طراحی ارائه میکند. این به او کمک می کند تا بهترین سازش را بین عملکرد، تأخیر، قدرت و مساحت انتخاب کند. کد برنامه نویسی نوشته شده در سطح بالایی از انتزاع را می توان با هدف قرار دادن هسته های پردازشی مختلف به طور شفاف برای کاربر ترسیم کرد.
رابط بین هستهها را میتوان در یک سیلیکون، بین تراشههای روی همان PCB یا از طریق یک اتصال IP پیادهسازی کرد. همگام سازی بین هسته ها به طور خودکار در زمان کامپایل مدیریت می شود و نیازی به عملیات نرم افزاری بلادرنگ ندارد.
سد راه رانندگی خودکار L4/L5 و استنتاج هوش مصنوعی مولد در لبه
یک راه حل موفق باید قابلیت برنامه ریزی در میدان را نیز شامل شود. الگوریتمها بهسرعت تکامل مییابند که توسط ایدههای جدیدی هدایت میشوند که یک شبه منسوخ شدهاند. توانایی ارتقاء یک الگوریتم در این زمینه یک مزیت قابل توجه است.
در حالی که شرکتهای مقیاس بزرگ در حال مونتاژ مزارع محاسباتی بزرگ با تعداد زیادی از پردازندههای با بالاترین کارایی خود برای مدیریت الگوریتمهای نرمافزاری پیشرفته هستند، این رویکرد فقط برای آموزش عملی است، نه برای استنتاج در لبه.
آموزش معمولا بر اساس محاسبات ممیز شناور 32 بیتی یا 64 بیتی است که حجم داده های زیادی تولید می کند. تأخیر سختی ایجاد نمی کند و مصرف انرژی بالا و همچنین هزینه قابل توجهی را تحمل می کند.
استنتاج در لبه معمولاً بر روی محاسبات ممیز شناور 8 بیتی انجام می شود که مقدار کمی داده تولید می کند، اما تأخیر غیر قابل انکار، مصرف انرژی کم و هزینه کم را الزامی می کند.
تأثیر مصرف انرژی بر تأخیر و کارایی
مصرف برق در IC های CMOS تحت سلطه حرکت داده ها است نه پردازش داده ها.
یک مطالعه دانشگاه استنفورد به رهبری پروفسور مارک هوروویتز نشان داد که مصرف انرژی دسترسی به حافظه نسبت به محاسبات منطقی دیجیتال پایه انرژی بیشتری مصرف می کند. جدول II را ببینید.

شتابدهندههای AD و GenAI نمونههای بارز دستگاههایی هستند که تحت تسلط حرکت دادهها هستند که چالشی را برای مهار مصرف انرژی ایجاد میکنند.
نتیجه
استنتاج AD و GenAI چالشهای غیر ضروری را برای دستیابی به پیادهسازی موفق ایجاد میکنند. VSORA میتواند یک راهحل سختافزاری جامع و نرمافزار پشتیبانی را برای برآورده کردن تمام الزامات حیاتی برای رسیدگی به AD L4/L5 و GenAI مانند شتاب GPT-4 با هزینههای تجاری مناسب ارائه دهد.
جزئیات بیشتر در مورد VSORA و Tyr و Jotunn آن را می توانید در اینجا پیدا کنید www.vsora.com.
درباره لورو ریزاتی
Lauro Rizzatti مشاور تجاری است VSORAیک استارتآپ نوآورانه که راهحلهای IP سیلیکونی و تراشههای سیلیکونی را ارائه میدهد، و یک مشاور تأیید صحت و متخصص صنعت در زمینه شبیهسازی سختافزار. او پیش از این سمت هایی در مدیریت، بازاریابی محصول، بازاریابی فنی و مهندسی داشت.
همچنین خواندن:
Soitec در حال مهندسی آینده صنعت نیمه هادی است
ISO 21434 برای توسعه SoC آگاه از امنیت سایبری
تعمیر و نگهداری پیش بینی در زمینه ایمنی عملکردی خودرو
اشتراک گذاری این پست از طریق:
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://semiwiki.com/automotive/336201-long-standing-roadblock-to-viable-l4-l5-autonomous-driving-and-generative-ai-inference-at-the-edge/
- : دارد
- :است
- :نه
- $UP
- 000
- 1
- 10
- 1800
- 1994
- 20
- 30
- 50
- 5G
- a
- توانایی
- درباره ما
- انتزاع - مفهوم - برداشت
- شتاب دادن
- شتاب
- شتاب دهنده
- شتاب دهنده ها
- دسترسی
- قابل دسترسی است
- دسترسی
- رسیدن
- دستیابی به
- در میان
- اعمال
- واقعی
- Ad
- ADA ها
- اضافه کردن
- نشانی
- پیشرفته
- پیشرفت
- مزیت - فایده - سود - منفعت
- مشاور
- اثر
- AI
- الگوریتم
- الگوریتمی
- الگوریتم
- معرفی
- اجازه می دهد تا
- همچنین
- مقدار
- مقدار
- an
- و
- پاسخ
- هر
- برنامه های کاربردی
- روش
- معماری
- هستند
- محدوده
- هنر
- AS
- At
- توجه
- خواص
- بطور خودکار
- خودرو
- خود مختار
- پهنای باند
- مستقر
- اساسی
- اساسا
- BE
- شدن
- بوده
- در زیر
- محک
- بهترین
- میان
- میلیاردها
- هر دو
- کسب و کار
- اما
- by
- نهانگاه
- CAN
- نمی توان
- قابلیت های
- سرمایه
- باعث می شود
- سلول
- به چالش
- چالش ها
- چیپس
- کلاس ها
- ساعت
- اطاقک خلبان در هواپیما
- رمز
- سقوط
- تجاری
- انجمن
- شرکت
- رقابتی
- پیچیده
- بغرنج
- جامع
- سازش
- محاسبات
- محاسبه
- محاسبه
- ارتباط
- مشاور
- مصرف
- شامل
- زمینه
- هزینه
- هزینه
- همراه
- پردازنده
- ایجاد شده
- بحرانی
- جاری
- لبه برش
- چرخه
- داده ها
- پردازش داده ها
- ارائه
- تحویل داده
- ارائه
- متراکم
- بستگی دارد
- شرح داده شده
- طرح
- طراحی
- طراح
- جزئیات
- دستگاه ها
- مختلف
- دیجیتال
- رقم
- do
- میکند
- دلار
- رانده
- رانندگی
- قطره
- قطره
- مشتاقانه
- لبه
- بهره وری
- هر دو
- پایان
- انرژی
- مصرف انرژی
- مهندس
- مهندسی
- اطمینان حاصل شود
- اشتیاق
- ESL
- ضروری است
- تاسیس
- تا کنون
- تکامل یابد
- مثال
- مثال ها
- اعدام
- کارشناس
- خارجی
- خانواده
- بسیار
- مزارع
- باز خورد
- کمی از
- رشته
- شکل
- نام خانوادگی
- شناور
- رد پا
- برای
- خط مقدم
- یافت
- تاسیس
- فرانسوی
- از جانب
- کاملا
- تابعی
- آینده
- تولید می کند
- مولد
- هوش مصنوعی مولد
- گوگل
- جستجوی گوگل
- بیشتر
- دسته
- سخت افزار
- آیا
- he
- برگزار شد
- کمک می کند
- او
- زیاد
- عملکرد بالا
- بالاترین
- او را
- هوروویتس
- HTTP
- HTTPS
- بزرگ
- ترکیبی
- i
- ICS
- ایده ها
- if
- ii
- پیاده سازی
- پیاده سازی ها
- اجرا
- مهم
- تحمیل
- in
- شامل
- صنعت
- کارشناس صنعت
- ابتکاری
- نمونه
- در عوض
- ادغام
- به
- معرفی
- اختراع
- سرمایه گذاری
- سرمایه گذاری
- IP
- IT
- ITS
- JPG
- جهش
- نگهداری
- شناخته شده
- چشم انداز
- بزرگ
- تاخیر
- رهبری
- کمتر
- سطح
- سطح
- پسندیدن
- بارگیری
- منطق
- طولانی مدت
- دیگر
- مطالب
- کم
- اصلی
- نگهداری
- ساخت
- اداره می شود
- مدیریت
- ماموریت ها
- علامت
- بازار یابی (Marketing)
- عظیم
- حداکثر عرض
- دیدار
- خاطرات
- حافظه
- میلی ثانیه
- حداقل
- مدرن
- پول
- بیش
- جنبش
- چندگانه
- جمعیت
- جدید
- شب
- اشاره کرد
- قابل توجه
- اکنون
- منسوخ
- of
- ارائه
- on
- ONE
- فقط
- عملیات
- or
- سفارش
- سفارشات
- دیگر
- دیگران
- روی
- شبانه
- بیش از حد
- ثبت اختراع
- اوج
- برای
- درصد
- کارایی
- انجام
- چشم انداز
- فیزیکی
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- بسیاری
- نقطه
- موقعیت
- امکان
- پست
- قدرت
- عملی
- قبلا
- نخستین
- مشکل
- روند
- پردازش
- در حال پردازش
- پردازنده
- پردازنده ها
- محصول
- معلم
- قابل برنامه ریزی
- برنامه نويسي
- پیشرفت
- پروانه
- قرار دادن
- نمایش ها
- محدوده
- سریعا
- خواندن
- زمان واقعی
- واقعیت
- اخیر
- را کاهش می دهد
- بدون در نظر گرفتن
- ثبت
- قابل توجه
- تکرار شده
- گزارش
- نیاز
- مورد نیاز
- نیاز
- پاسخ
- همان
- SEA
- جستجو
- ثانیه
- دیدن
- انتخاب
- نیمه هادی
- سنسور
- چند
- اشتراک گذاری
- سهام
- باید
- نشان داد
- سیلیکون
- پس از
- تنها
- کوچک
- So
- نرم افزار
- راه حل
- مزایا
- حل
- برخی از
- تاحدی
- منبع
- فضا
- سرعت
- صرف
- استنفورد
- دانشگاه استنفورد
- شروع
- دولت
- وضعیت هنر
- ستارگان
- هنوز
- ساده
- دقیق
- ساختار
- مهاجرت تحصیلی
- قابل توجه
- موفق
- پشتیبانی
- پشتیبانی
- حمایت از
- هماهنگ سازی
- سیستم
- جدول
- طراحی شده
- هدف
- هدف گذاری
- فنی
- فن آوری
- نسبت به
- که
- La
- آینده
- شان
- آنها
- آنجا.
- اینها
- آنها
- این
- سه
- از طریق
- توان
- محکم
- زمان
- بار
- به
- امروز
- مسیر
- سنتی
- ترافیک
- آموزش
- شفاف
- دو
- نوع
- انواع
- نوعی
- به طور معمول
- منحصر به فرد
- واحد
- جهان
- دانشگاه
- تا
- ارتقاء
- قابل استفاده
- کاربر
- با استفاده از
- VC
- ریسک
- سرمایه گذاری
- تایید
- در مقابل
- از طريق
- قابل اعتماد
- عملا
- جلد
- صبر کنيد
- دیوار
- بود
- مسیر..
- خوب
- چه زمانی
- در حین
- وسیع
- خواسته
- با
- در داخل
- کتبی
- هنوز
- بازده
- زفیرنت