آپاچی هودی یک قالب جدول باز است که قابلیت های پایگاه داده و انبار داده را به دریاچه های داده می آورد. آپاچی هودی به مهندسان داده کمک میکند تا چالشهای پیچیده را مدیریت کنند، مانند مدیریت مجموعه دادههای در حال تکامل مداوم با تراکنشها و در عین حال حفظ عملکرد پرس و جو. مهندسان داده از Apache Hudi برای پخش بارهای کاری و همچنین برای ایجاد خطوط لوله داده افزایشی کارآمد استفاده می کنند. هودی فراهم می کند جداول, معاملات, اضافه و حذف کارآمد, شاخص های پیشرفته, خدمات جذب جریانی، داده ها خوشه بندی و تراکم بهینه سازی و کنترل همزمان، همه در حالی که داده های خود را در قالب های فایل منبع باز نگه می دارید. بهینهسازیهای عملکرد پیشرفته Hudi بارهای کاری تحلیلی را با هر یک از موتورهای جستجوی محبوب از جمله Apache Spark، Presto، Trino، Hive و غیره سریعتر میکند.
بسیاری از مشتریان AWS Apache Hudi را در دریاچه های داده خود که در بالای آمازون S3 ساخته شده اند، استفاده کردند چسب AWSیک سرویس یکپارچه سازی داده بدون سرور که کشف، آماده سازی، انتقال و ادغام داده ها از منابع متعدد برای تجزیه و تحلیل، یادگیری ماشین (ML) و توسعه برنامه را آسان تر می کند. خزنده چسب AWS یکی از اجزای چسب AWS است که به شما امکان می دهد ابرداده های جدول را از محتوای داده به طور خودکار بدون نیاز به تعریف دستی ابرداده ایجاد کنید.
خزنده های AWS Glue اکنون از جداول Apache Hudi پشتیبانی می کنند، ساده سازی پذیرش کاتالوگ داده چسب AWS به عنوان کاتالوگ جداول هودی. یکی از موارد استفاده معمولی ثبت جداول Hudi است که تعریف جدول کاتالوگ ندارد. یکی دیگر از موارد استفاده معمولی مهاجرت از سایر کاتالوگ های Hudi، مانند Hive metastore است. هنگام مهاجرت از سایر کاتالوگهای Hudi، میتوانید یک خزنده چسب AWS ایجاد و زمانبندی کنید و یک یا چند مسیر Amazon S3 را که فایلهای جدول Hudi در آن قرار دارند، ارائه دهید. شما می توانید حداکثر عمق مسیرهای Amazon S3 را که خزنده چسب AWS می تواند طی کند، ارائه دهید. با هر بار اجرا، خزنده های چسب AWS اطلاعات طرح و پارتیشن را استخراج می کنند و کاتالوگ داده چسب AWS را با تغییرات طرح و پارتیشن به روز می کنند. خزنده های چسب AWS آخرین مکان فایل ابرداده را در کاتالوگ داده چسب AWS که موتورهای تحلیلی AWS می توانند مستقیماً استفاده کنند، به روز می کنند.
با این راه اندازی، می توانید یک خزنده چسب AWS برای ثبت جداول Hudi در کاتالوگ داده های چسب AWS ایجاد و برنامه ریزی کنید. سپس می توانید یک یا چند مسیر Amazon S3 را که جداول Hudi در آن قرار دارند ارائه دهید. شما این امکان را دارید که حداکثر عمق مسیرهای Amazon S3 را که خزنده ها می توانند طی کنند، ارائه دهید. با اجرای هر خزنده، خزنده هر یک از مسیرهای S3 را بررسی میکند و اطلاعات طرحواره، مانند جداول جدید، حذفها و بهروزرسانیهای طرحوارهها را در کاتالوگ داده چسب AWS فهرستبندی میکند. خزنده ها اطلاعات پارتیشن را بررسی می کنند و پارتیشن های تازه اضافه شده را به کاتالوگ داده چسب AWS اضافه می کنند. خزنده ها همچنین آخرین مکان فایل ابرداده را در کاتالوگ داده چسب AWS که موتورهای تحلیلی AWS می توانند مستقیماً استفاده کنند، به روز می کنند.
این پست نشان می دهد که چگونه این قابلیت جدید برای خزیدن جداول Hudi کار می کند.
چگونه خزنده چسب AWS با جداول Hudi کار می کند
جداول Hudi دارای دو دسته هستند که برای هر کدام مفاهیم خاصی دارند:
- کپی در نوشتن (CoW) – داده ها در قالب ستونی (Parquet) ذخیره می شوند و هر به روز رسانی نسخه جدیدی از فایل ها را در طول نوشتن ایجاد می کند.
- ادغام در خواندن (MoR) – داده ها با استفاده از ترکیبی از فرمت های ستونی (پارکت) و ردیفی (Avro) ذخیره می شوند. به روز رسانی ها به صورت ردیفی ثبت می شوند
deltaفایل ها و در صورت نیاز فشرده می شوند تا نسخه های جدیدی از فایل های ستونی ایجاد شود.
با مجموعه داده های CoW، هر بار که یک رکورد به روز می شود، فایلی که حاوی رکورد است با مقادیر به روز شده بازنویسی می شود. با یک مجموعه داده MoR، هر بار که یک به روز رسانی وجود دارد، Hudi فقط ردیف را برای رکورد تغییر یافته می نویسد. MoR برای بارهای کاری سنگین برای نوشتن یا تغییر با خواندن کمتر مناسب تر است. CoW برای بارهای خواندنی سنگین روی داده هایی که کمتر تغییر می کنند مناسب تر است.
Hudi سه نوع پرس و جو برای دسترسی به داده ها ارائه می دهد:
- پرس و جوهای عکس فوری - پرس و جوهایی که آخرین عکس فوری جدول را به عنوان یک اقدام معین commit یا compaction می بینند. برای جداول MoR، پرس و جوهای فوری آخرین وضعیت جدول را با ادغام فایل های پایه و دلتا آخرین برش فایل در زمان پرس و جو، نشان می دهند.
- پرس و جوهای افزایشی - پرس و جوها فقط داده های جدید نوشته شده روی جدول را می بینند، زیرا یک commit یا فشرده سازی داده شده است. این به طور موثر جریان های تغییر را برای فعال کردن خطوط لوله داده افزایشی فراهم می کند.
- پرس و جوهای بهینه شده را بخوانید - برای جداول MoR، پرس و جوها آخرین داده های فشرده شده را ببینید. برای جداول CoW، پرس و جوها آخرین داده های تعهد شده را ببینید.
برای جداول کپی در نوشتن، خزنده ها یک جدول واحد در کاتالوگ داده چسب AWS با ReadOptimized Serde ایجاد می کنند. org.apache.hudi.hadoop.HoodieParquetInputFormat.
برای جداول ادغام در خواندن، خزنده ها دو جدول در کاتالوگ داده چسب AWS برای همان مکان جدول ایجاد می کنند:
- جدول با پسوند
_ro، که از ReadOptimized Serde استفاده می کندorg.apache.hudi.hadoop.HoodieParquetInputFormat - جدول با پسوند
_rt، که از RealTime Serde استفاده می کند که به درخواست های Snapshot اجازه می دهد:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
در طول هر خزیدن، برای هر مسیر Hudi ارائه شده، خزندهها یک تماس API لیست آمازون S3 برقرار میکنند و بر اساس .hoodie پوشه ها، و جدیدترین فایل فراداده را در زیر پوشه متاداده جدول Hudi پیدا کنید.
با استفاده از خزنده AWS Glue یک میز Hudi CoW را بخزید
در این بخش، بیایید نحوه خزیدن یک گاو Hudi با استفاده از خزنده های چسب AWS را بررسی کنیم.
پیش نیازها
پیش نیازهای این آموزش عبارتند از:
- نصب و پیکربندی رابط خط فرمان AWS (AWS CLI).
- اگر سطل S3 خود را ندارید آن را ایجاد کنید.
- نقش IAM خود را برای چسب AWS ایجاد کنید اگر آن را ندارید. تو نیاز داری
s3:GetObjectبرایs3://your_s3_bucket/data/sample_hudi_cow_table/. - دستور زیر را اجرا کنید تا نمونه جدول Hudi را در سطل S3 خود کپی کنید. (جایگزین کردن
your_s3_bucketبا نام سطل S3 شما.)
این دستورالعمل شما را راهنمایی می کند تا داده های نمونه را کپی کنید، اما می توانید هر جدول Hudi را به راحتی با استفاده از چسب AWS ایجاد کنید. بیشتر بدانید در معرفی پشتیبانی بومی برای Apache Hudi، Delta Lake و Apache Iceberg در AWS Glue برای Apache Spark، قسمت 2: AWS Glue Studio Visual Editor.
یک خزنده Hudi ایجاد کنید
در این دستورالعمل، خزنده را از طریق کنسول ایجاد کنید. مراحل زیر را برای ایجاد خزنده Hudi انجام دهید:
- در کنسول AWS Glue، را انتخاب کنید خزنده ها.
- را انتخاب کنید خزنده ایجاد کنید.
- برای نام، وارد
hudi_cow_crawler. انتخاب کنید بعدی. - تحت پیکربندی منبع داده، انتخاب کنید منبع داده را اضافه کنید.
- برای منبع اطلاعات، انتخاب کنید هودی.
- برای شامل مسیرهای جدول hudi، وارد
s3://your_s3_bucket/data/sample_hudi_cow_table/. (جایگزین کردنyour_s3_bucketبا نام سطل S3 شما.) - را انتخاب کنید منبع داده Hudi را اضافه کنید.
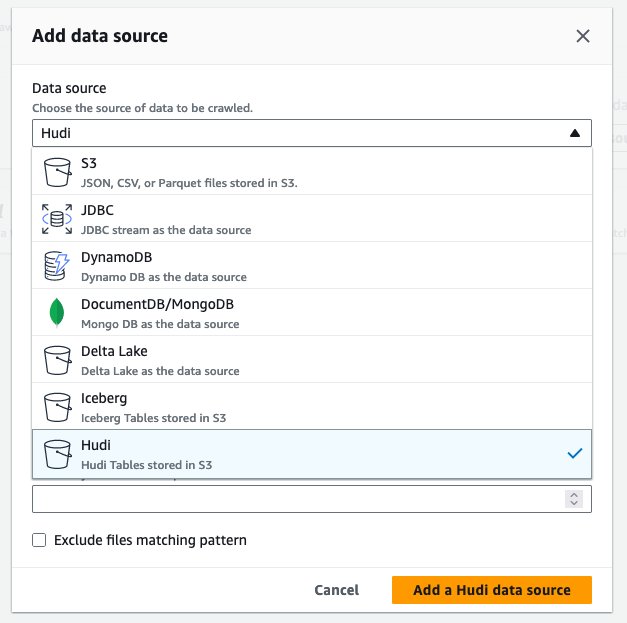
- را انتخاب کنید بعدی.
- برای نقش IAM موجود، نقش IAM خود را انتخاب کنید، سپس انتخاب کنید بعدی.
- برای پایگاه داده هدف، انتخاب کنید افزودن پایگاه داده، سپس افزودن پایگاه داده گفتگو ظاهر می شود برای نام پایگاه داده، وارد
hudi_crawler_blog، پس از آن را انتخاب کنید ساختن. انتخاب کنید بعدی. - را انتخاب کنید خزنده ایجاد کنید.
اکنون یک خزنده جدید Hudi با موفقیت ایجاد شده است. خزنده را می توان برای اجرا از طریق کنسول یا از طریق SDK یا AWS CLI با استفاده از StartCrawl API. همچنین میتوان از طریق کنسول برنامهریزی کرد تا خزندهها را در زمانهای خاصی فعال کند. در این دستورالعمل، خزنده را از طریق کنسول اجرا کنید.
- را انتخاب کنید خزنده را اجرا کنید.
- منتظر بمانید تا خزنده کامل شود.
پس از اجرای خزنده، می توانید تعریف جدول Hudi را در کنسول AWS Glue ببینید:
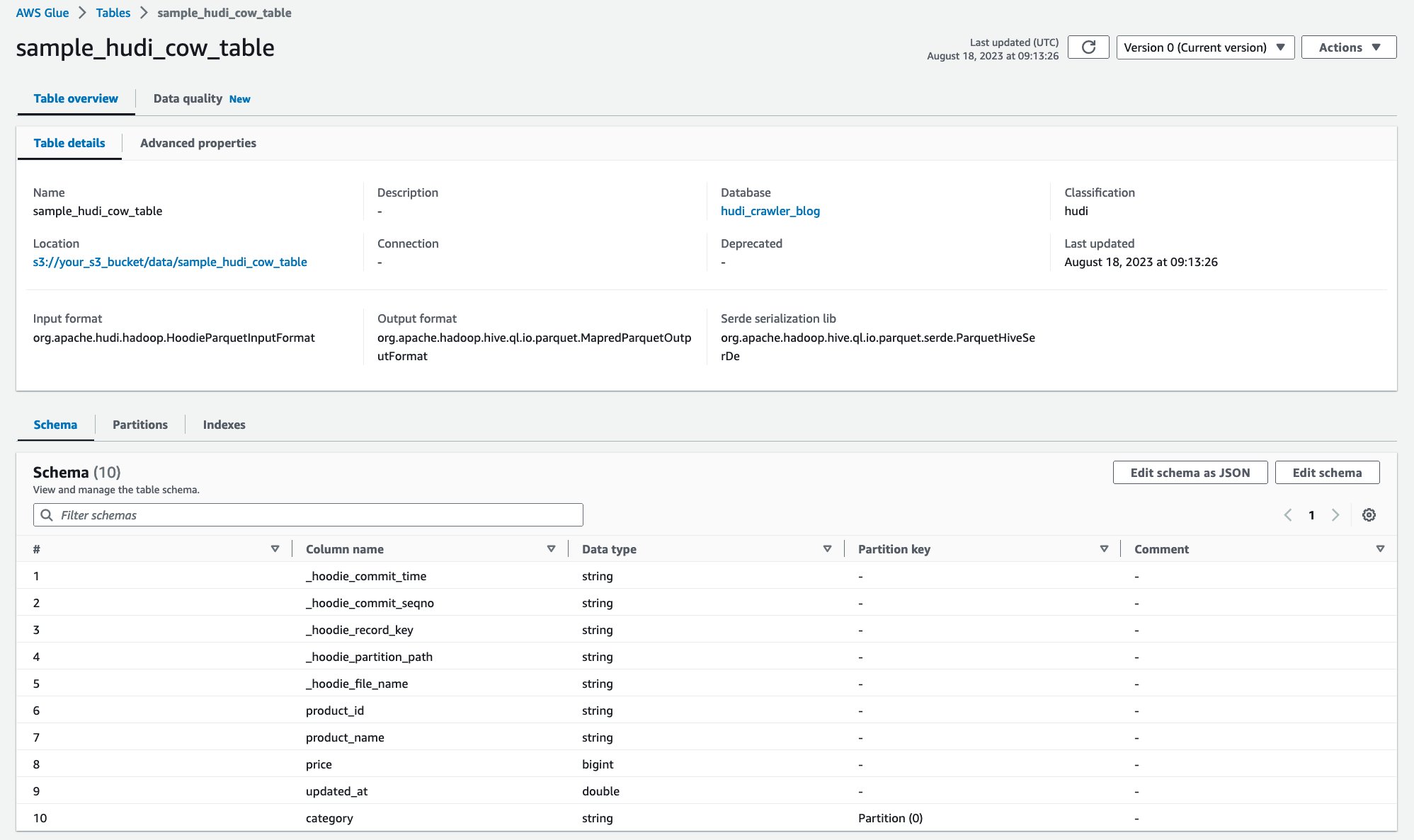
شما با موفقیت جدول Hudi CoR را با دادهها در Amazon S3 خزیدهاید و یک جدول AWS Glue Data Catalog با طرح پر شده ایجاد کردهاید. پس از ایجاد تعریف جدول در کاتالوگ داده چسب AWS، سرویس های تحلیلی AWS مانند آمازون آتنا می توانند جدول Hudi را پرس و جو کنند.
برای شروع پرس و جو در Athena مراحل زیر را کامل کنید:
- کنسول آمازون آتنا را باز کنید.
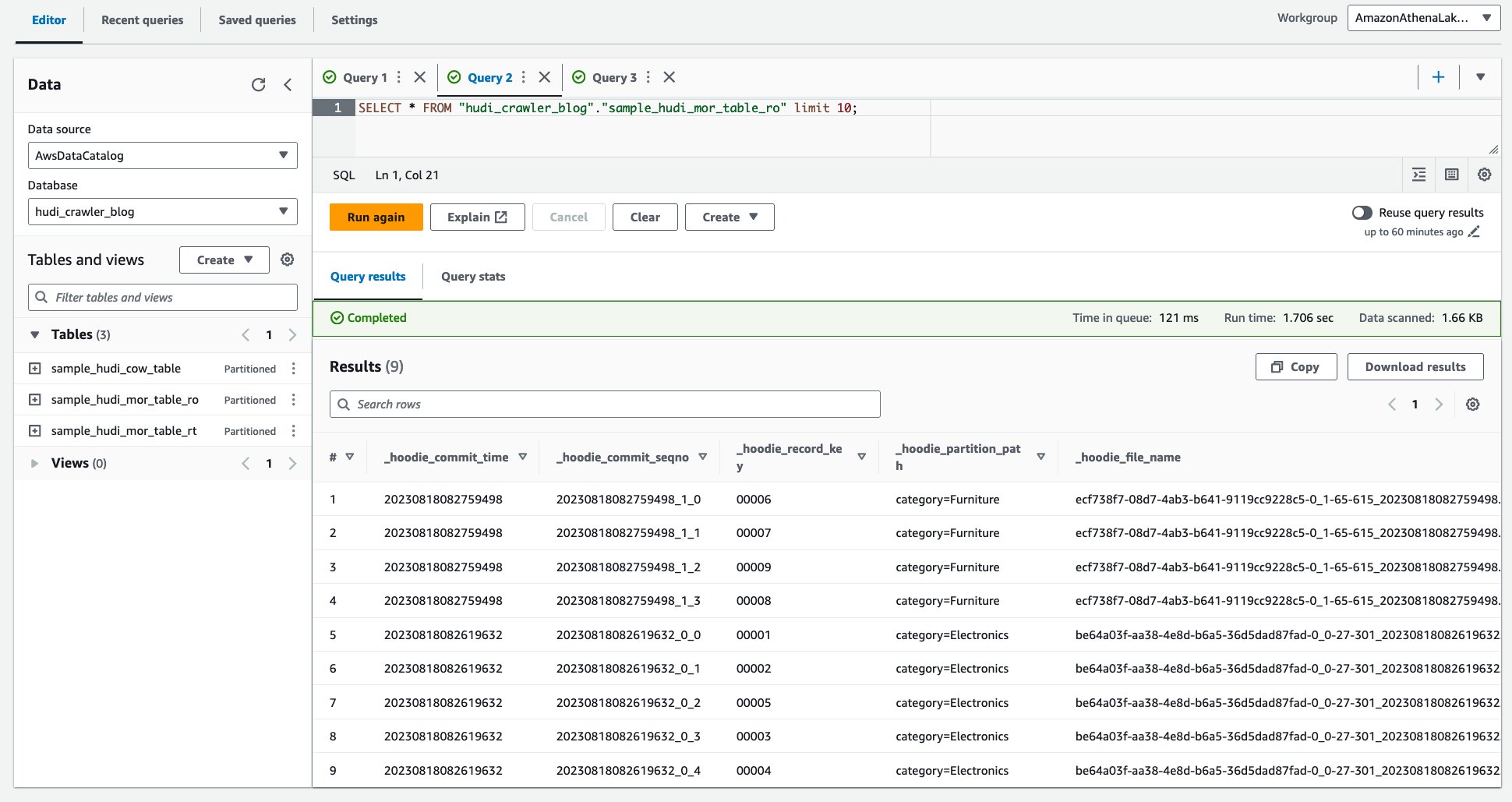
- کوئری زیر را اجرا کنید.
تصویر زیر خروجی ما را نشان می دهد:
خزیدن جدول Hudi MoR با استفاده از خزنده AWS Glue با مجوزهای داده AWS Lake Formation
در این بخش، بیایید نحوه خزیدن جدول Hudi MoR با استفاده از چسب AWS را بررسی کنیم. این بار، شما از مجوز داده AWS Lake Formation برای خزیدن منابع داده آمازون S3 به جای مجوز IAM و Amazon S3 استفاده می کنید. این اختیاری است، اما هنگامی که دریاچه داده شما توسط مجوزهای AWS Lake Formation مدیریت می شود، پیکربندی مجوز را ساده می کند.
پیش نیازها
پیش نیازهای این آموزش عبارتند از:
- نصب و پیکربندی رابط خط فرمان AWS (AWS CLI).
- اگر سطل S3 خود را ندارید آن را ایجاد کنید.
- نقش IAM خود را برای چسب AWS ایجاد کنید اگر آن را ندارید. تو نیاز داری
lakeformation:GetDataAccess. اما شما نیاز نداریدs3:GetObjectبرایs3://your_s3_bucket/data/sample_hudi_mor_table/زیرا ما از مجوز داده Lake Formation برای دسترسی به فایل ها استفاده می کنیم. - دستور زیر را اجرا کنید تا نمونه جدول Hudi را در سطل S3 خود کپی کنید. (جایگزین کردن
your_s3_bucketبا نام سطل S3 شما.)
علاوه بر مراحل پردازش، برای بهروزرسانی تنظیمات AWS Glue Data Catalog برای استفاده از مجوزهای Lake Formation برای کنترل منابع کاتالوگ به جای کنترل دسترسی مبتنی بر IAM، مراحل زیر را تکمیل کنید:
- به عنوان مدیر دریاچه داده به کنسول Lake Formation وارد شوید.
- اگر این اولین بار است که به کنسول Lake Formation دسترسی پیدا می کنید، خود را به عنوان مدیر دریاچه داده اضافه کنید.
- تحت حکومت، انتخاب کنید تنظیمات کاتالوگ داده.
- برای مجوزهای پیش فرض برای پایگاه های داده و جداول جدید ایجاد شده، انتخاب را لغو کنید فقط از کنترل دسترسی IAM برای پایگاه داده های جدید استفاده کنید و فقط از کنترل دسترسی IAM برای جداول جدید در پایگاه داده های جدید استفاده کنید.
- برای تنظیم نسخه متقابل حساب، انتخاب کنید نسخه 3.
- را انتخاب کنید ذخیره.
گام بعدی این است که سطل S3 خود را در مکان های دریاچه داده Lake Formation ثبت کنید:
- در کنسول Lake Formation، را انتخاب کنید مکان های دریاچه داده، و انتخاب کنید ثبت مکان.
- برای مسیر آمازون S3، وارد
s3://your_s3_bucket/. (جایگزین کردنyour_s3_bucketبا نام سطل S3 شما.) - را انتخاب کنید ثبت مکان.
سپس، اجازه دسترسی نقش خزنده Glue به مکان داده را بدهید تا خزنده بتواند از مجوز Lake Formation برای دسترسی به داده ها و ایجاد جداول در مکان استفاده کند:
- در کنسول Lake Formation، را انتخاب کنید مکان های داده و انتخاب کنید گرانت.
- برای کاربران و نقش های IAM، نقش IAM را که برای خزنده استفاده کردید انتخاب کنید.
- برای محل ذخیره سازی، وارد
s3://your_s3_bucket/data/. (جایگزین کردنyour_s3_bucketبا نام سطل S3 شما.) - را انتخاب کنید گرانت.
سپس، نقش خزنده را برای ایجاد جداول در زیر پایگاه داده اعطا کنید hudi_crawler_blog:
- در کنسول Lake Formation، را انتخاب کنید مجوزهای دریاچه داده.
- را انتخاب کنید گرانت.
- برای اصولگرایان، انتخاب کنید کاربران و نقش های IAMو نقش خزنده را انتخاب کنید.
- برای برچسب های LF یا منابع کاتالوگ، انتخاب کنید منابع کاتالوگ داده نامگذاری شده.
- برای پایگاه داده، پایگاه داده را انتخاب کنید
hudi_crawler_blog. - تحت مجوزهای پایگاه داده، انتخاب کنید ایجاد جدول.
- را انتخاب کنید گرانت.
یک خزنده Hudi با مجوزهای داده Lake Formation ایجاد کنید
مراحل زیر را برای ایجاد خزنده Hudi انجام دهید:
- در کنسول AWS Glue، را انتخاب کنید خزنده ها.
- را انتخاب کنید خزنده ایجاد کنید.
- برای نام، وارد
hudi_mor_crawler. انتخاب کنید بعدی. - تحت پیکربندی منبع داده، انتخاب کنید منبع داده را اضافه کنید.
- برای منبع اطلاعات، انتخاب کنید هودی.
- برای شامل مسیرهای جدول hudi، وارد
s3://your_s3_bucket/data/sample_hudi_mor_table/. (جایگزین کردنyour_s3_bucketبا نام سطل S3 شما.) - را انتخاب کنید منبع داده Hudi را اضافه کنید.
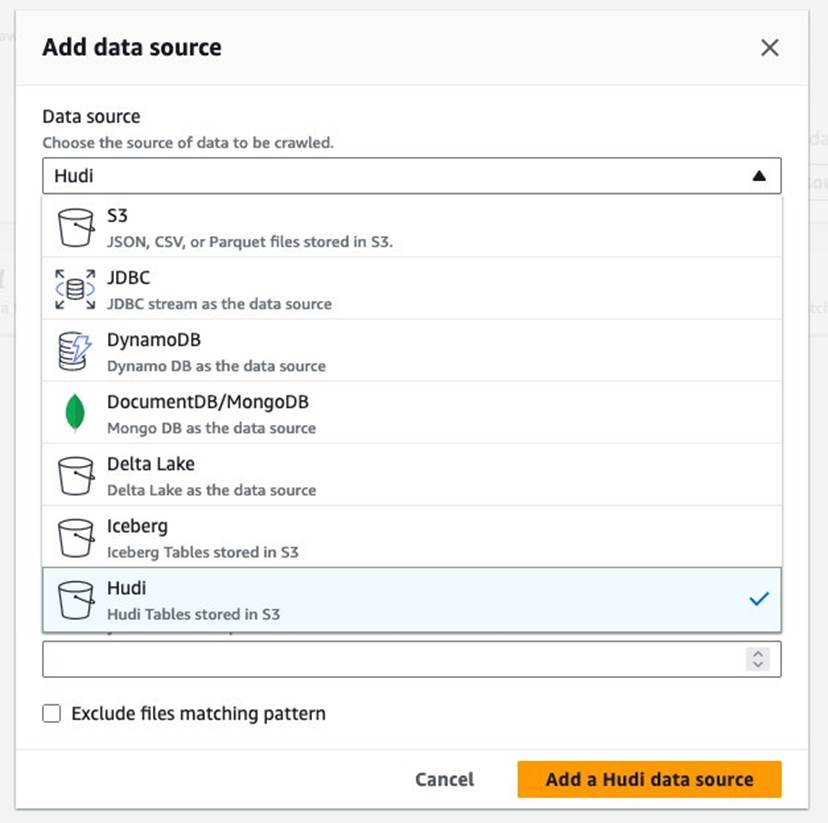
- را انتخاب کنید بعدی.
- برای نقش IAM موجود، نقش IAM خود را انتخاب کنید.
- تحت پیکربندی سازند دریاچه - اختیاری، انتخاب کنید از اعتبارنامه Lake Formation برای خزیدن منبع داده S3 استفاده کنید.
- را انتخاب کنید بعدی.
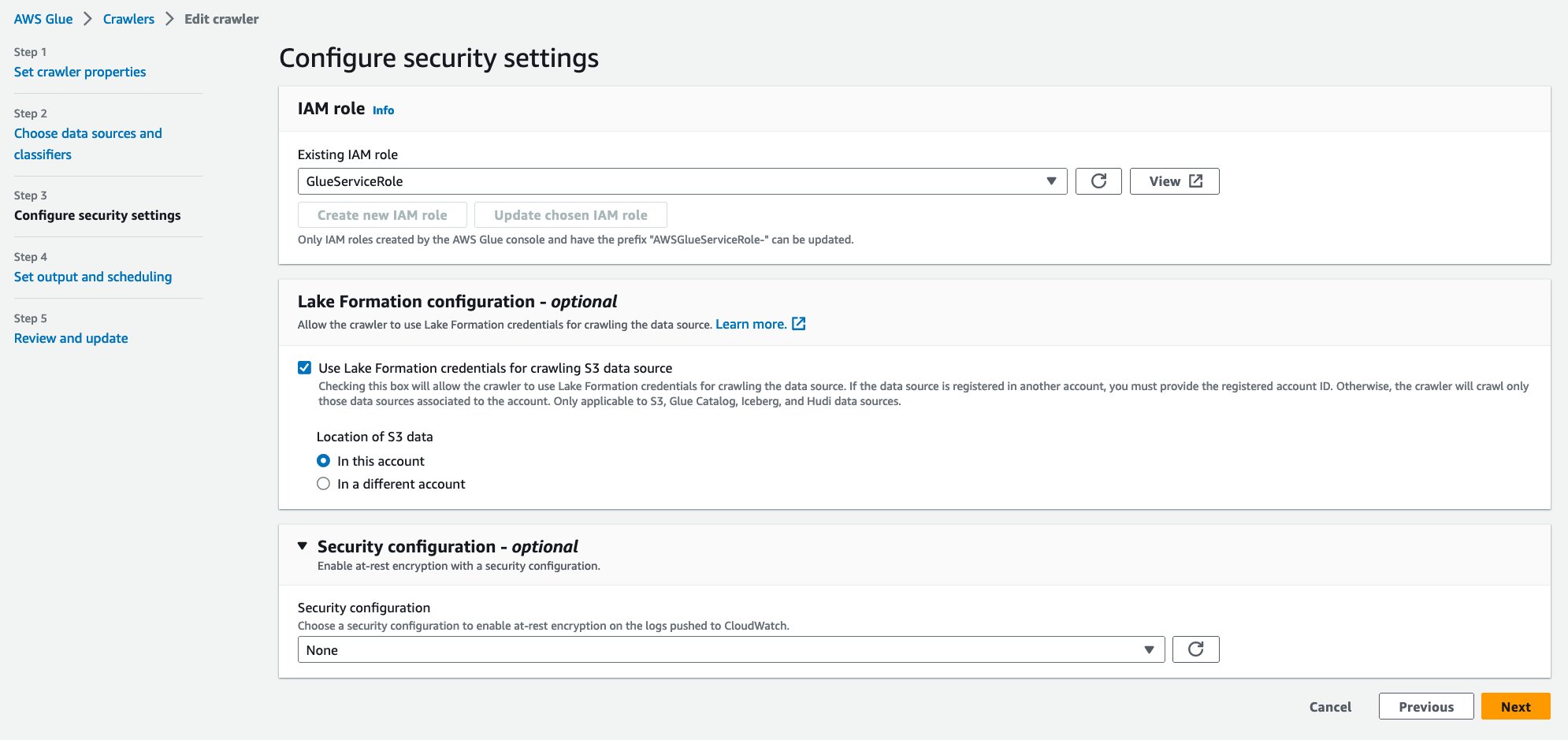
- برای پایگاه داده هدف، انتخاب کنید
hudi_crawler_blog. انتخاب کنید بعدی. - را انتخاب کنید خزنده ایجاد کنید.
اکنون یک خزنده جدید Hudi با موفقیت ایجاد شده است. خزنده از اعتبارنامه Lake Formation برای خزیدن فایل های Amazon S3 استفاده می کند. بیایید خزنده جدید را اجرا کنیم:
- را انتخاب کنید خزنده را اجرا کنید.
- منتظر بمانید تا خزنده کامل شود.
پس از اجرای خزنده، می توانید دو جدول از تعریف جدول Hudi را در کنسول AWS Glue مشاهده کنید:
sample_hudi_mor_table_ro(جدول بهینه شده را بخوانید)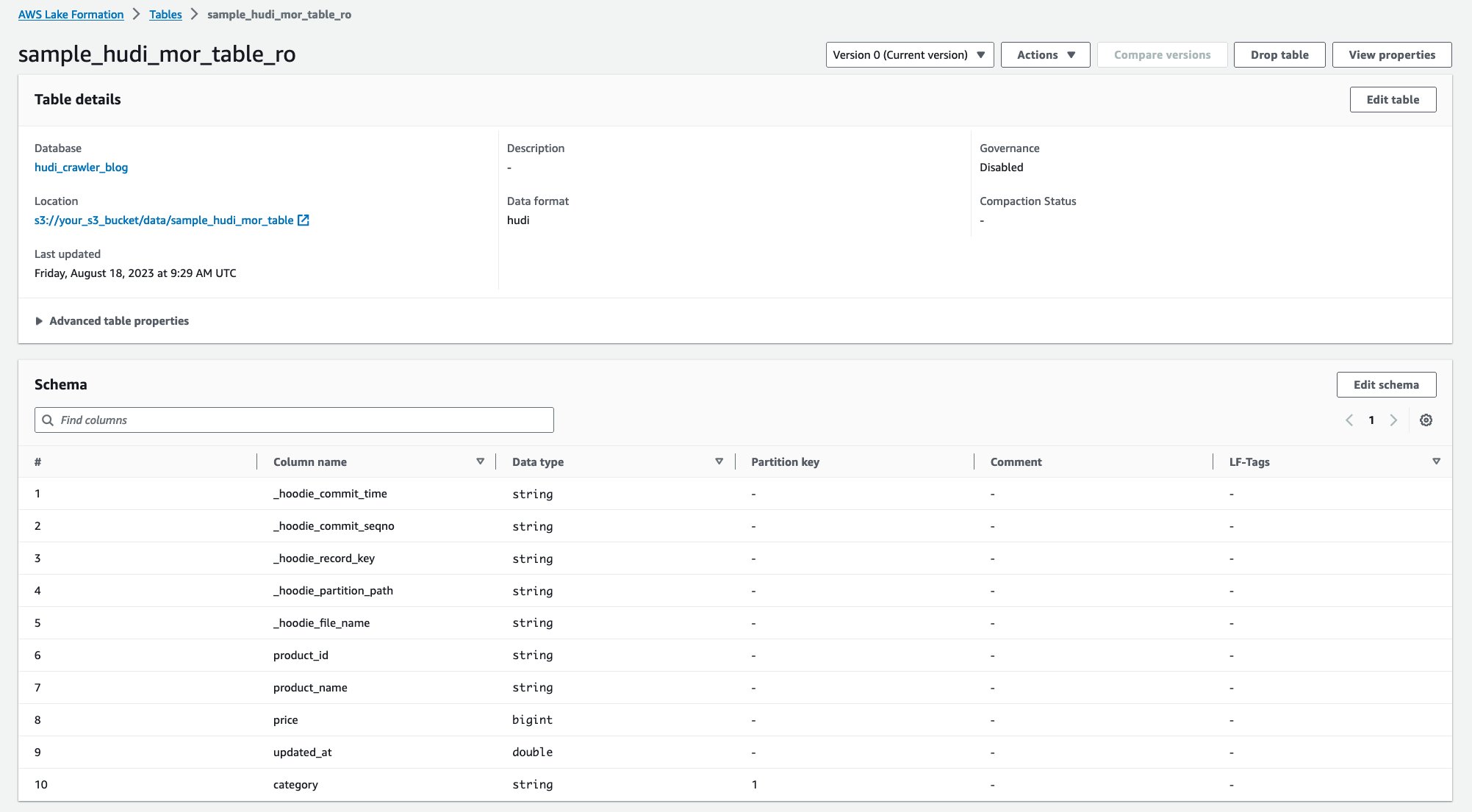
sample_hudi_mor_table_rt(جدول زمان واقعی)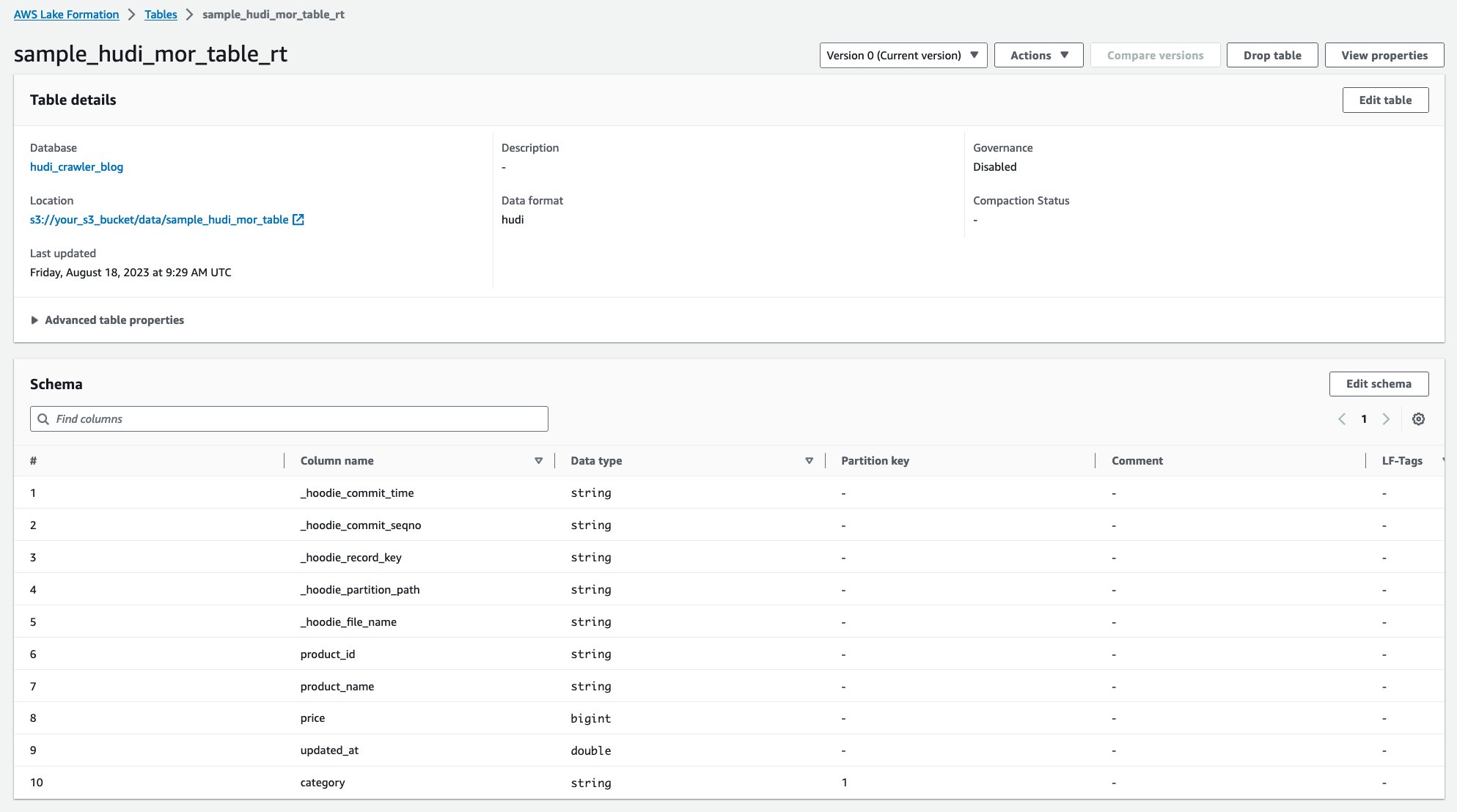
شما سطل دریاچه داده را با Lake Formation ثبت کردید و دسترسی خزیدن به دریاچه داده را با استفاده از مجوزهای Lake Formation فعال کردید. شما با موفقیت جدول Hudi MoR را با دادهها در Amazon S3 خزیدهاید و یک جدول AWS Glue Data Catalog با طرح پر شده ایجاد کردهاید. پس از ایجاد تعاریف جدول در کاتالوگ داده چسب AWS، سرویس های تجزیه و تحلیل AWS مانند آمازون آتنا می توانند جدول Hudi را پرس و جو کنند.
برای شروع پرس و جو در Athena مراحل زیر را کامل کنید:
- کنسول آمازون آتنا را باز کنید.
- کوئری زیر را اجرا کنید.
تصویر زیر خروجی ما را نشان می دهد:
- کوئری زیر را اجرا کنید.
تصویر زیر خروجی ما را نشان می دهد:
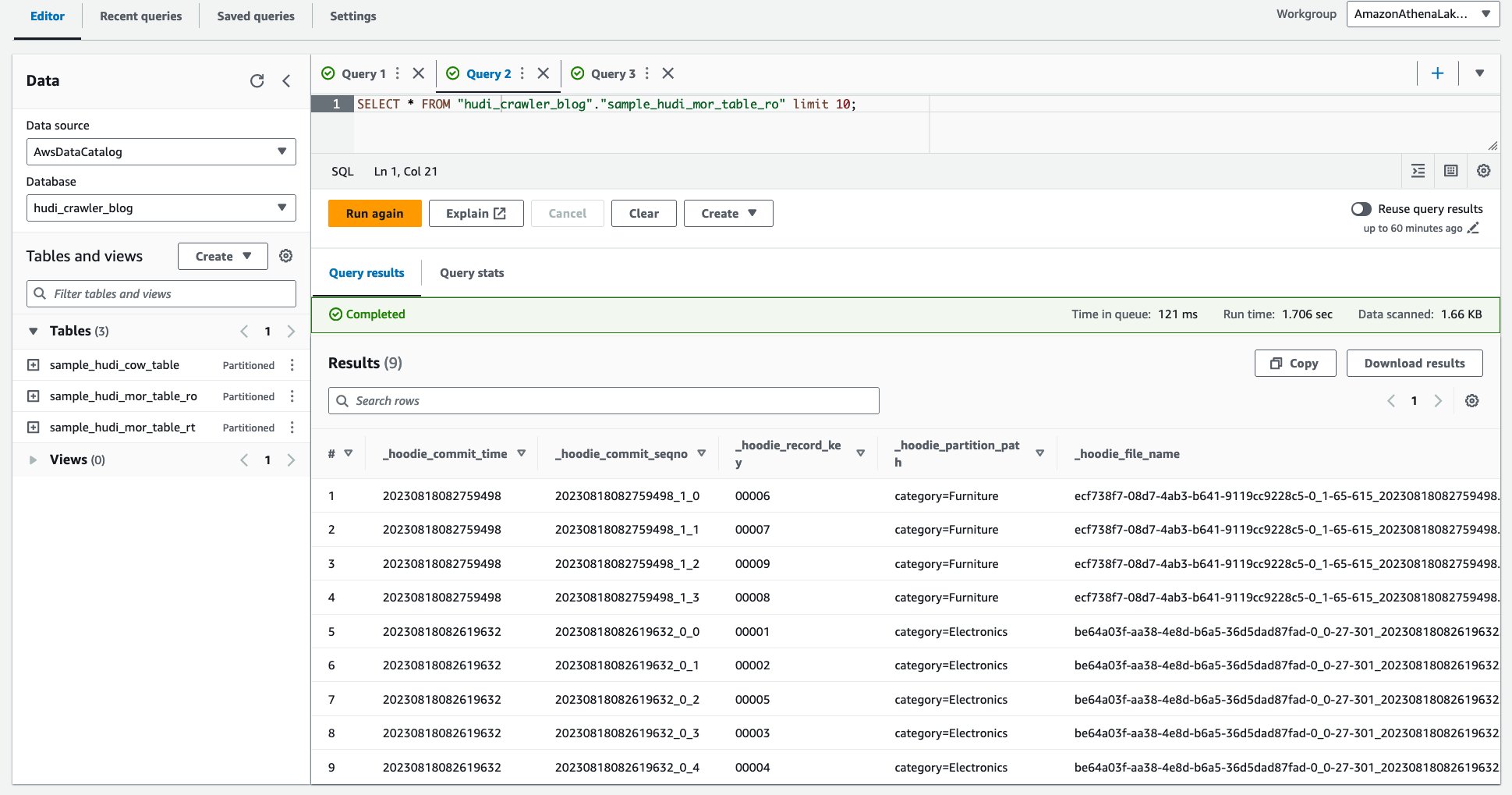
کنترل دسترسی ریز با استفاده از مجوزهای AWS Lake Formation
برای اعمال کنترل دسترسی دقیق در جدول Hudi، می توانید از مجوزهای AWS Lake Formation بهره مند شوید. مجوزهای Lake Formation به شما این امکان را می دهد که دسترسی به جداول، ستون ها یا ردیف های خاص را محدود کنید و سپس جداول Hudi را از طریق Amazon Athena با کنترل دسترسی دقیق جستجو کنید. اجازه دهید اجازه Lake Formation را برای جدول Hudi MoR پیکربندی کنیم.
پیش نیازها
پیش نیازهای این آموزش عبارتند از:
- قسمت قبل را کامل کنید خزیدن جدول Hudi MoR با استفاده از خزنده AWS Glue با مجوزهای داده AWS Lake Formation.
- یک کاربر IAM DataAnalyst ایجاد کنید که دارای خط مشی مدیریت شده AWS باشد AmazonAthenaFullAccess.
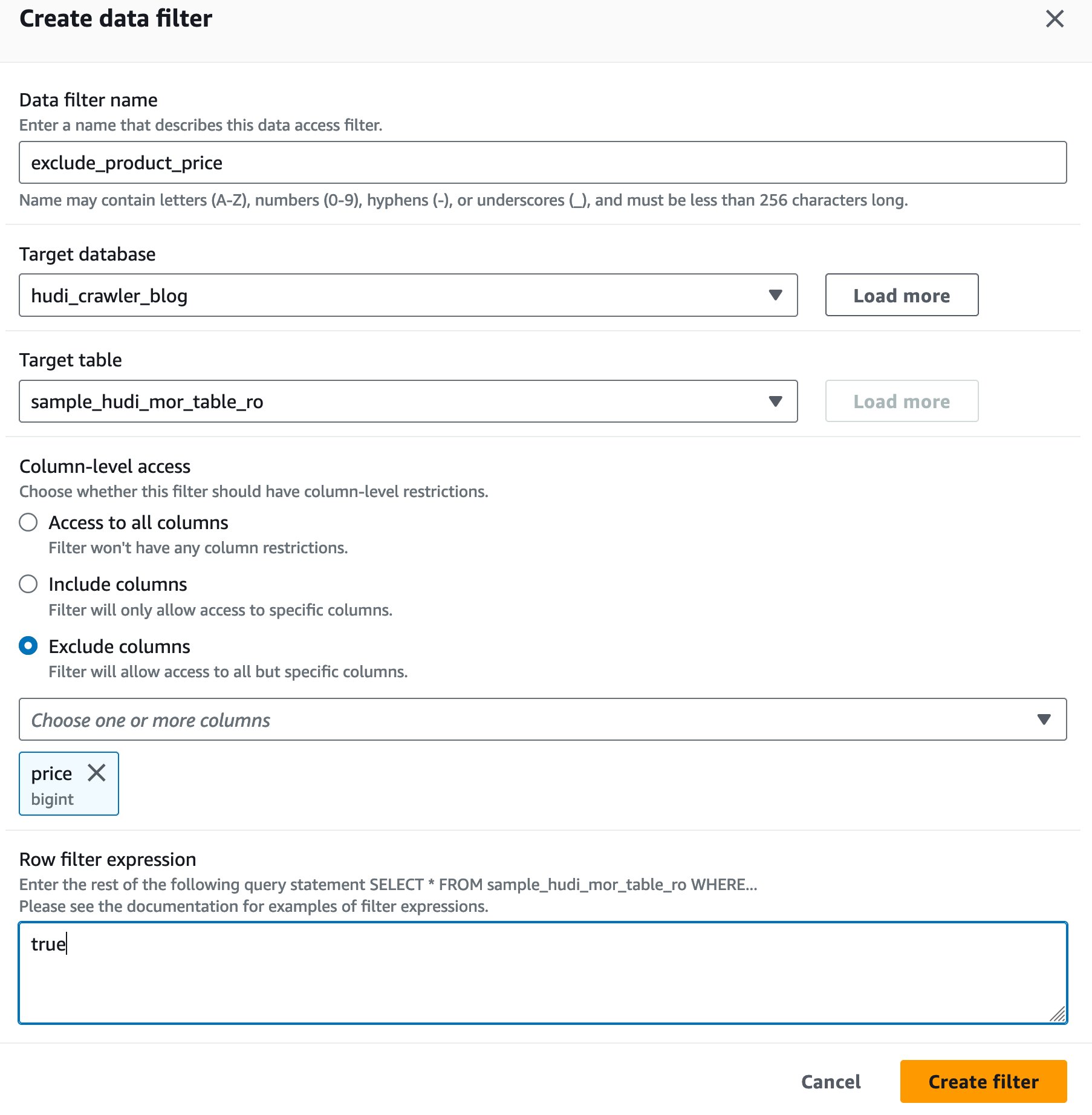
یک فیلتر سلول داده Lake Formation ایجاد کنید
بیایید ابتدا یک فیلتر برای جدول بهینهشده خواندن MoR تنظیم کنیم.
- به عنوان مدیر دریاچه داده به کنسول Lake Formation وارد شوید.
- را انتخاب کنید فیلترهای داده.
- را انتخاب کنید فیلتر جدید ایجاد کنید.
- برای نام فیلتر داده، وارد
exclude_product_price. - برای پایگاه داده هدف، پایگاه داده را انتخاب کنید
hudi_crawler_blog. - برای جدول هدف، جدول را انتخاب کنید
sample_hudi_mor_table_ro. - برای در سطح ستون دسترسی، انتخاب کنید مستثنی کردن ستون هاو قیمت ستون را انتخاب کنید.
- برای عبارت فیلتر ردیفی، وارد
true. - را انتخاب کنید فیلتر ایجاد کنید.
مجوز Lake Formation را به کاربر DataAnalyst اعطا کنید
مراحل زیر را برای اعطای مجوز Lake Formation به انجام دهید DataAnalyst کاربر
- در کنسول Lake Formation، را انتخاب کنید مجوزهای دریاچه داده.
- را انتخاب کنید گرانت.
- برای اصولگرایان، انتخاب کنید کاربران و نقش های IAMو کاربر را انتخاب کنید
DataAnalyst. - برای برچسب های LF یا منابع کاتالوگ، انتخاب کنید منابع کاتالوگ داده نامگذاری شده.
- برای پایگاه داده، پایگاه داده را انتخاب کنید
hudi_crawler_blog. - برای جدول - اختیاری، جدول را انتخاب کنید
sample_hudi_mor_table_ro. - برای فیلترهای داده - اختیاری، انتخاب کنید
exclude_product_price. - برای مجوزهای فیلتر داده، انتخاب کنید انتخاب کنید.
- را انتخاب کنید گرانت.
شما مجوز Lake Formation را در پایگاه داده اعطا کردید hudi_crawler_blog و جدول sample_hudi_mor_table_ro، به استثنای ستون price به کاربر DataAnalyst. اکنون اجازه دهید دسترسی کاربر به داده ها را با استفاده از Athena تأیید کنیم.
- به عنوان کاربر DataAnalyst وارد کنسول Athena شوید.
- در ویرایشگر پرس و جو، کوئری زیر را اجرا کنید:
تصویر زیر خروجی ما را نشان می دهد:
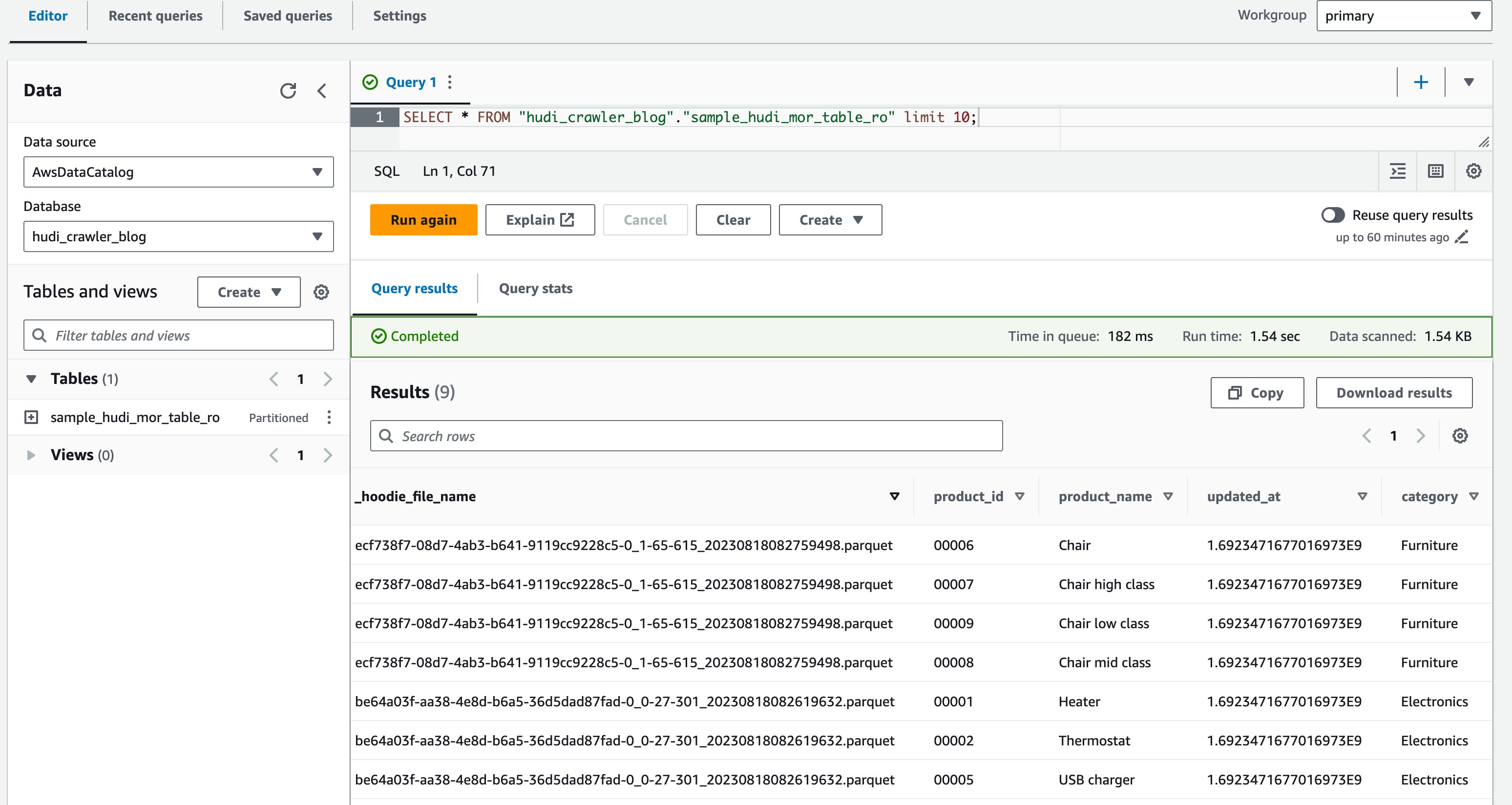
حالا شما آن ستون را تایید کردید price نشان داده نمی شود، اما ستون های دیگر product_id, product_name, update_atو category نشان داده شده.
پاک کردن
برای جلوگیری از هزینه های ناخواسته به حساب AWS خود، منابع AWS زیر را حذف کنید:
- پایگاه داده AWS Glue را حذف کنید
hudi_crawler_blog. - خزنده های چسب AWS را حذف کنید
hudi_cow_crawlerوhudi_mor_crawler. - فایل های Amazon S3 را در زیر حذف کنید
s3://your_s3_bucket/data/sample_hudi_cow_table/وs3://your_s3_bucket/data/sample_hudi_mor_table/.
نتیجه
این پست نشان داد که چگونه خزنده های چسب AWS برای جداول Hudi کار می کنند. با پشتیبانی از خزنده Hudi، می توانید به سرعت به استفاده از کاتالوگ داده چسب AWS به عنوان کاتالوگ جدول اصلی Hudi بروید. میتوانید با استفاده از Hudi در AWS با استفاده از AWS Glue، AWS Glue Data Catalog و Lake Formation برای جداول و فرمتهای پشتیبانی شده توسط موتورهای تحلیلی AWS، ساخت دریاچه داده تراکنشی بدون سرور خود را شروع کنید.
درباره نویسندگان
 نوریتاکا سکیاما یک معمار اصلی داده های بزرگ در تیم AWS Glue است. او در توکیو، ژاپن کار می کند. او مسئول ساخت مصنوعات نرم افزاری برای کمک به مشتریان است. در اوقات فراغت از دوچرخه سواری با دوچرخه جاده لذت می برد.
نوریتاکا سکیاما یک معمار اصلی داده های بزرگ در تیم AWS Glue است. او در توکیو، ژاپن کار می کند. او مسئول ساخت مصنوعات نرم افزاری برای کمک به مشتریان است. در اوقات فراغت از دوچرخه سواری با دوچرخه جاده لذت می برد.
 کایل دوونگ یک مهندس توسعه نرم افزار در تیم AWS Glue and Lake Formation است. او مشتاق ساخت فناوری های کلان داده و سیستم های توزیع شده است.
کایل دوونگ یک مهندس توسعه نرم افزار در تیم AWS Glue and Lake Formation است. او مشتاق ساخت فناوری های کلان داده و سیستم های توزیع شده است.
 ساندیپ ادوانکار یک مدیر ارشد محصول فنی در AWS است. او که در منطقه خلیج کالیفرنیا مستقر است، با مشتریان در سراسر جهان کار می کند تا الزامات تجاری و فنی را به محصولاتی تبدیل کند که مشتریان را قادر می سازد نحوه مدیریت، ایمن سازی و دسترسی به داده ها را بهبود بخشند.
ساندیپ ادوانکار یک مدیر ارشد محصول فنی در AWS است. او که در منطقه خلیج کالیفرنیا مستقر است، با مشتریان در سراسر جهان کار می کند تا الزامات تجاری و فنی را به محصولاتی تبدیل کند که مشتریان را قادر می سازد نحوه مدیریت، ایمن سازی و دسترسی به داده ها را بهبود بخشند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- قادر
- درباره ما
- دسترسی
- دسترسی به داده ها
- دسترسی
- حساب
- عمل
- اضافه کردن
- اضافه
- اضافه
- به تصویب رسید
- اتخاذ
- پیشرفته
- پس از
- معرفی
- اجازه دادن
- اجازه دادن
- اجازه می دهد تا
- همچنین
- آمازون
- آمازون آتنا
- آمازون خدمات وب
- an
- تحلیلی
- علم تجزیه و تحلیل
- و
- دیگر
- هر
- آپاچی
- جرقه آپاچی
- API
- ظاهر می شود
- کاربرد
- برنامه توسعه
- درخواست
- هستند
- محدوده
- دور و بر
- AS
- At
- بطور خودکار
- اجتناب از
- AWS
- چسب AWS
- سازند دریاچه AWS
- پایه
- مستقر
- سرخ مایل به قرمز
- BE
- زیرا
- بوده
- سود
- بهتر
- بزرگ
- بزرگ داده
- به ارمغان می آورد
- بنا
- ساخته
- کسب و کار
- اما
- by
- کالیفرنیا
- صدا
- CAN
- قابلیت های
- قابلیت
- مورد
- کاتالوگ
- کاتالوگ
- دسته
- سلول
- چالش ها
- تغییر دادن
- تغییر
- تبادل
- بار
- را انتخاب کنید
- ستون
- ستون ها
- ترکیب
- مرتکب شدن
- مرتکب شده
- کامل
- پیچیده
- جزء
- پیکر بندی
- کنسول
- شامل
- محتوا
- به طور مداوم
- کنترل
- گروه شاهد
- میتوانست
- خزنده
- ایجاد
- ایجاد شده
- ایجاد
- مجوزها و اعتبارات
- مشتریان
- داده ها
- یکپارچه سازی داده ها
- دریاچه دریاچه
- انبار داده
- پایگاه داده
- پایگاه های داده
- مجموعه داده ها
- تعریف
- تعاریف
- دلتا
- نشان
- نشان می دهد
- عمق
- پروژه
- مستقیما
- كشف كردن
- توزیع شده
- سیستم های توزیع شده
- do
- میکند
- در طی
- هر
- آسان تر
- به آسانی
- سردبیر
- به طور موثر
- موثر
- قادر ساختن
- فعال
- مهندس
- مورد تأیید
- موتورهای حرفه ای
- وارد
- اتر (ETH)
- در حال تحول
- به استثنای
- عصاره
- سریعتر
- کمتر
- پرونده
- فایل ها
- فیلتر
- فیلترها برای تصفیه آب
- پیدا کردن
- نام خانوادگی
- بار اول
- پیروی
- برای
- قالب
- تشکیل
- غالبا
- از جانب
- داده
- زمین
- Go
- اعطا کردن
- اعطا شده
- راهنما
- هادوپ
- آیا
- he
- کمک
- کمک می کند
- خود را
- کندو
- چگونه
- چگونه
- HTML
- HTTPS
- IAM
- if
- پیامدهای
- بهبود
- in
- از جمله
- افزایشی
- اطلاعات
- در عوض
- ادغام
- ادغام
- رابط
- به
- معرفی
- IT
- ژاپن
- JPG
- نگهداری
- دریاچه
- دریاچه ها
- آخرین
- راه اندازی
- یاد گرفتن
- یادگیری
- کمتر
- محدود
- لاین
- فهرست
- واقع شده
- محل
- مکان
- سیستم وارد
- دستگاه
- فراگیری ماشین
- نگهداری
- ساخت
- باعث می شود
- مدیریت
- اداره می شود
- مدیر
- مدیریت
- کتابچه راهنمای
- بیشترین
- ادغام
- متاداده
- مهاجرت
- مهاجرت
- ML
- بیش
- اکثر
- حرکت
- چندگانه
- نام
- بومی
- نیاز
- ضروری
- جدید
- به تازگی
- بعد
- اکنون
- of
- on
- ONE
- فقط
- باز کن
- منبع باز
- بهینه
- گزینه
- or
- دیگر
- ما
- تولید
- بخش
- احساساتی
- مسیر
- راه ها
- کارایی
- اجازه
- مجوز
- افلاطون
- هوش داده افلاطون
- PlatoData
- محبوب
- پر جمعیت
- پست
- آماده
- پیش نیازها
- قبلی
- قیمت
- اصلی
- اصلی
- در حال پردازش
- محصول
- مدیر تولید
- محصولات
- ارائه
- ارائه
- فراهم می کند
- نمایش ها
- به سرعت
- خواندن
- واقعی
- زمان واقعی
- زمان واقعی
- اخیر
- رکورد
- ثبت نام
- ثبت نام
- جایگزین کردن
- مورد نیاز
- منابع
- مسئوليت
- محدود کردن
- جاده
- نقش
- ROW
- دویدن
- همان
- برنامه
- برنامه ریزی
- sdk
- بخش
- امن
- دیدن
- را انتخاب کنید
- ارشد
- بدون سرور
- سرویس
- خدمات
- تنظیم
- تنظیمات
- نشان داده شده
- نشان می دهد
- ساده می کند
- پس از
- تنها
- تکه
- عکس فوری
- So
- نرم افزار
- توسعه نرم افزار
- منبع
- منابع
- جرقه
- خاص
- شروع
- دولت
- گام
- مراحل
- ذخیره شده
- جریان
- جریان
- استودیو
- موفقیت
- چنین
- پشتیبانی
- پشتیبانی
- همگام سازی
- سیستم های
- جدول
- تیم
- فنی
- فن آوری
- که
- La
- شان
- سپس
- آنجا.
- آنها
- این
- سه
- از طریق
- زمان
- بار
- به
- توکیو
- بالا
- معامله ای
- معاملات
- ترجمه کردن
- گذشتن از
- ماشه
- باعث شد
- آموزش
- دو
- انواع
- نوعی
- زیر
- ناخواسته
- بروزرسانی
- به روز شده
- به روز رسانی
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- کاربران
- استفاده
- با استفاده از
- تصدیق
- تایید شده
- ارزشها
- نسخه
- بصری
- انبار کالا
- we
- وب
- خدمات وب
- خوب
- چه زمانی
- که
- در حین
- WHO
- اراده
- با
- بدون
- مهاجرت کاری
- با این نسخهها کار
- نوشتن
- کتبی
- شما
- شما
- خودت
- زفیرنت